Note de l'auteur : Fondée sur 6 benchmarks essentiels, dont SWE-bench Pro, Terminal-Bench 2.0 et LiveCodeBench, voici une analyse comparative approfondie des capacités de programmation en conditions réelles du GPT-5.5 et du Claude Opus 4.7, accompagnée de recommandations claires pour vos choix technologiques.
La bataille pour la suprématie en programmation entre GPT-5.5 et Claude Opus 4.7 est le sujet le plus brûlant dans le monde de l'IA en avril 2026. Cet article compare le OpenAI GPT-5.5 (nom de code Spud) et le Anthropic Claude Opus 4.7. Nous évaluons leurs performances via SWE-bench Pro, Terminal-Bench 2.0, la recherche dans de larges contextes, l'efficacité des jetons et la tarification de l'API pour vous orienter vers le meilleur choix.
Ceci n'est pas une analyse tiède du type "chacun ses points forts" ; en nous appuyant sur les données officielles des benchmarks, nous formulons des recommandations précises selon les différents cas d'usage. Anthropic a lancé Claude Opus 4.7 le 16 avril 2026, suivi de près par OpenAI le 23 avril avec GPT-5.5. Ces deux modèles de premier plan, apparus à seulement 7 jours d'intervalle, marquent le début d'un duel sans précédent dans le domaine du codage assisté par IA.
Valeur ajoutée : À la lecture de cet article, vous saurez exactement quel modèle choisir entre GPT-5.5 et Claude Opus 4.7 pour quatre scénarios types : la résolution d'issues GitHub, la programmation par agents, la refactorisation de larges contextes et le développement interactif.

Aperçu des différences clés entre GPT-5.5 et Claude Opus 4.7
Le positionnement de ces deux modèles diffère radicalement, ce qui influence directement leurs forces respectives en programmation. Le tableau ci-dessous résume leurs divergences majeures :
| Dimension de comparaison | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Date de sortie | 23-04-2026 | 16-04-2026 |
| Nom de code | Spud | – |
| Fenêtre de contexte | 1M tokens | 1M tokens |
| Sortie max | 128K tokens | 128K tokens |
| Points forts | Programmation par agents, recherche longue portée | Correction d'issues GitHub, raisonnement architectural |
| TTFT typique | ~3 secondes | ~0,5 seconde |
| Efficacité jetons | 72 % moins de jetons en sortie que Opus | Consommation élevée, mais haute précision |
| Entrée API | 5 $ / M tokens | 5 $ / M tokens |
| Sortie API | 30 $ / M tokens | 25 $ / M tokens |
| Surtaxe large invite | Pas de surcoût au-delà de 200K | Doublement du tarif au-delà de 200K (10 $/37,50 $) |
Positionnement de la programmation avec GPT-5.5
GPT-5.5 est, à ce jour, le modèle de programmation par agents le plus puissant d'OpenAI. Il excelle dans les flux de travail terminaux, la recherche dans de longs contextes et la coordination multi-outils, ce qui le rend particulièrement adapté aux processus automatisés complexes nécessitant de multiples étapes. OpenAI le positionne comme le choix de prédilection pour les "tâches de programmation de longue haleine", démontrant sur les benchmarks internes Expert-SWE une capacité à traiter des tâches équivalentes à 20 heures de travail humain.
Positionnement de la programmation avec Claude Opus 4.7
Claude Opus 4.7 a repris sa couronne sur les tâches réelles d'ingénierie logicielle. Avec un score de 87,6 % sur SWE-bench Verified et 64,3 % sur SWE-bench Pro, il surclasse nettement tous ses concurrents actuels. Les tests d'Anthropic sur le Rakuten-SWE-Bench indiquent qu'Opus 4.7 résout 3 fois plus de tâches de production que l'Opus 4.6, ce qui en fait l'outil idéal pour la correction d'issues GitHub et la refactorisation de grandes bases de code exigeant un raisonnement architectural approfondi.
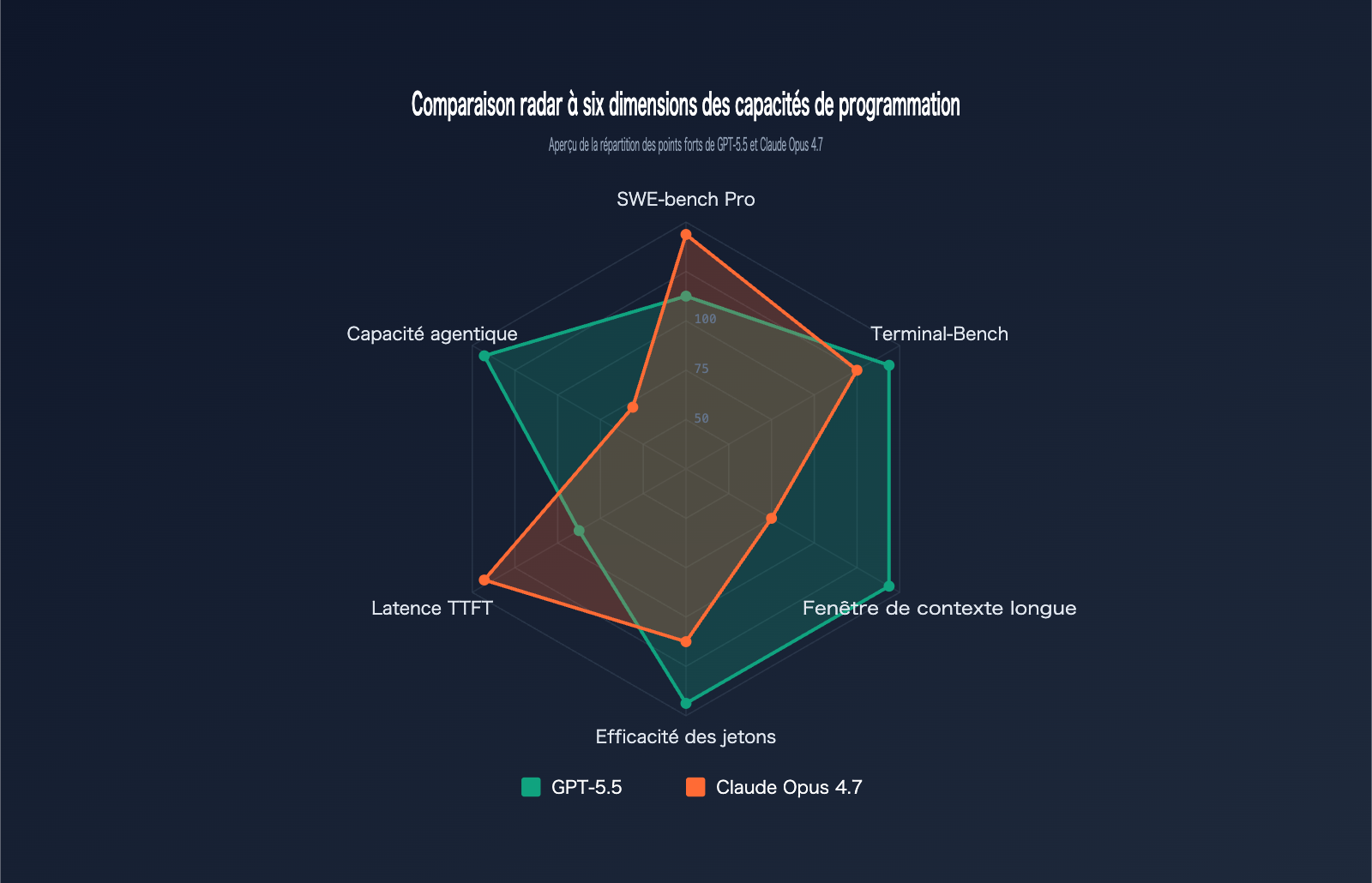
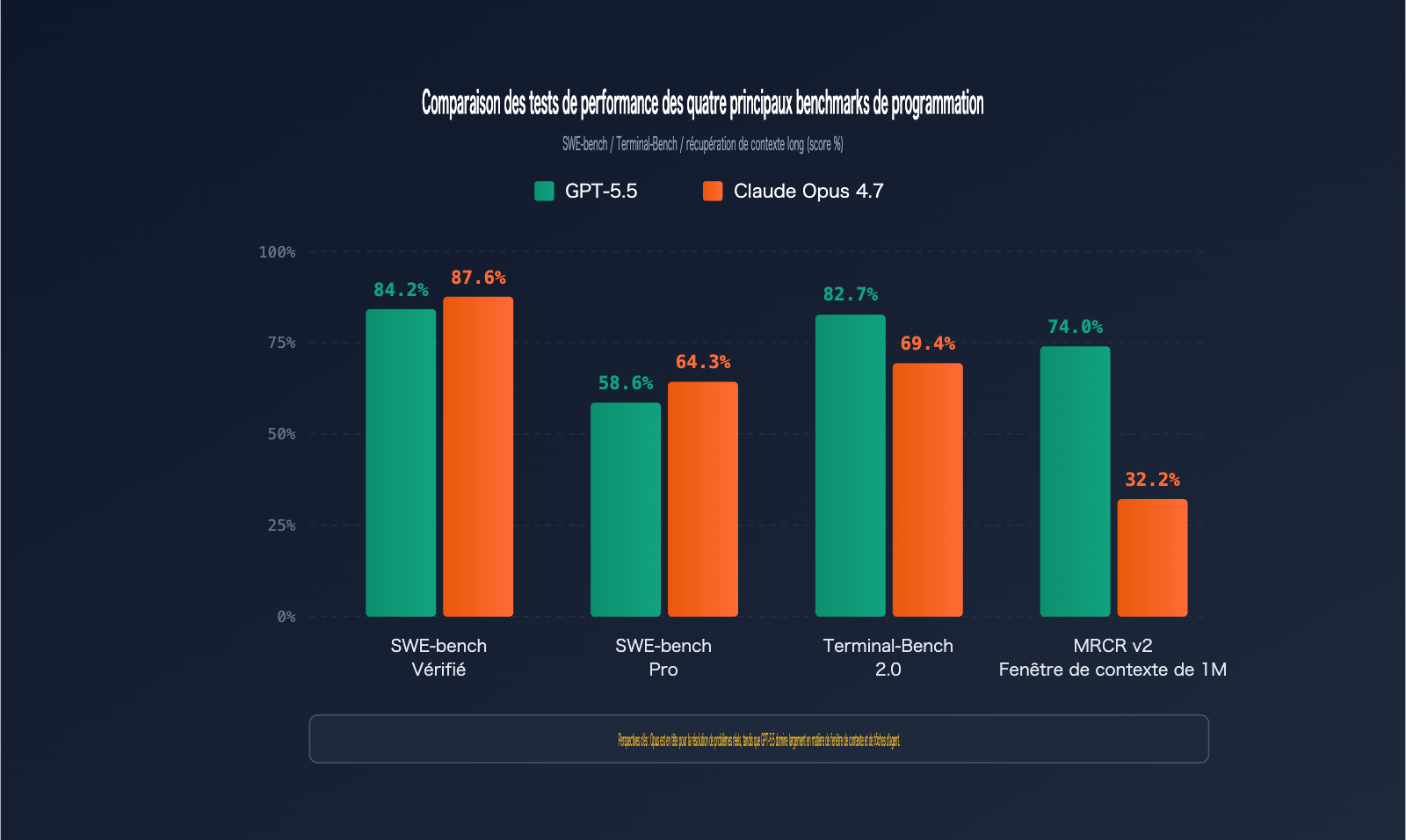
Analyse comparative des benchmarks : GPT-5.5 vs Claude Opus 4.7
Les benchmarks sont l'étalon-or pour évaluer objectivement les capacités de programmation. Nous avons compilé les données officielles des deux modèles sur six tests de référence majeurs :
| Benchmark | Contenu du test | GPT-5.5 | Claude Opus 4.7 | Vainqueur |
|---|---|---|---|---|
| SWE-bench Verified | Correction d'issues GitHub vérifiées | 84,2 % | 87,6 % | Opus 4.7 |
| SWE-bench Pro | Correction d'issues complexes multi-fichiers | 58,6 % | 64,3 % | Opus 4.7 |
| Terminal-Bench 2.0 | Flux de travail avec commandes terminal | 82,7 % | 69,4 % | GPT-5.5 |
| Expert-SWE | Programmation longue durée (médiane 20h) | 73,1 % | – | GPT-5.5 |
| OSWorld-Verified | Tâches d'agent sur bureau | 78,7 % | 78,0 % | GPT-5.5 (court) |
| MRCR v2 (512K-1M) | Récupération 8-needle en contexte long | 74,0 % | 32,2 % | GPT-5.5 |
Analyse pratique : SWE-bench Pro
Le SWE-bench Pro est la référence ultime pour mesurer la capacité d'un modèle à corriger de vraies issues GitHub. Claude Opus 4.7 domine avec 64,3 % contre 58,6 % pour GPT-5.5, ce qui signifie que pour chaque tranche de 100 bugs corrigés, Opus 4.7 en résout environ 6 de plus.
Plus impressionnant encore, Opus 4.7 affiche une progression de 10,9 points par rapport à la génération précédente (Opus 4.6 à 53,4 %), un saut qualitatif rare pour une simple itération. Pour les équipes dont le flux de travail principal repose sur la résolution d'issues GitHub, Claude Opus 4.7 est le choix actuel le plus performant.
Conseil de test : Vous voulez vérifier la différence entre ces modèles sur votre propre base de code ? Utilisez la plateforme APIYI (apiyi.com) pour des tests en parallèle. Elle prend en charge les appels d'interface unifiés pour GPT-5.5 et Claude Opus 4.7, facilitant ainsi une comparaison rapide.
Analyse pratique : Terminal-Bench 2.0
Le Terminal-Bench 2.0 évalue la capacité d'un modèle à exécuter des tâches complexes dans un environnement terminal, incluant la planification, l'itération et la coordination d'outils. Ici, GPT-5.5 prend une avance considérable avec 82,7 % contre 69,4 % pour Opus 4.7, soit un écart de 13 points.
Cet avantage s'explique par les optimisations de GPT-5.5 sur les flux de travail orientés "Agent" : il sélectionne les outils avec plus de précision, gère les tâches multi-étapes de manière plus stable et récupère plus efficacement en cas d'erreur. Si votre flux de travail implique de nombreuses commandes shell, des manipulations de fichiers ou une intégration CI/CD, GPT-5.5 est l'option la plus fiable.
Écart dans les capacités de récupération en contexte long
Dans le test MRCR v2 (récupération 8-needle dans une fenêtre de 512K-1M tokens), GPT-5.5 écrase la concurrence avec 74,0 % contre 32,2 % pour Opus 4.7 — un fossé de 41,8 points.
Cela signifie que si vous devez faire comprendre à un modèle l'intégralité d'un référentiel de code (plus de 500K tokens), GPT-5.5 offre une précision de rappel sur le contexte profond nettement supérieure. Pour des scénarios comme le "refactoring basé sur un monorepo complet", GPT-5.5 ne se contente pas d'être "meilleur", il fait la différence entre ce qui est réalisable et ce qui ne l'est pas.
Recommandations pratiques : GPT-5.5 vs Claude Opus 4.7 dans vos projets de développement
Les benchmarks ne prennent tout leur sens que lorsqu'ils sont appliqués à des cas d'usage réels. Le tableau ci-dessous présente des recommandations claires pour cinq scénarios de programmation typiques :
| Scénario de programmation | Modèle recommandé | Raison principale | Bénéfice attendu |
|---|---|---|---|
| Correction de GitHub Issue | Claude Opus 4.7 | 5,7 points d'avance sur SWE-bench Pro | Taux de réussite en hausse de 10 % |
| Refactoring de gros Codebase | Claude Opus 4.7 | Meilleur raisonnement architectural multi-fichiers | Moins de risques de casser l'architecture |
| Flux automatisés (Agentic) | GPT-5.5 | 13,3 points d'avance sur Terminal-Bench | Meilleure stabilité pour les tâches multi-étapes |
| Compréhension longue fenêtre (>500K) | GPT-5.5 | 41,8 points d'avance sur MRCR v2 | Extraction fiable dans un contexte profond |
| Pair Programming interactif | Claude Opus 4.7 | TTFT de seulement 0,5s, réponse plus rapide | Flux de codage plus fluide |
| Génération de code en masse | GPT-5.5 | Efficacité des jetons +72 %, coût réduit | Meilleur rapport coût-efficacité |
Scénario 1 : Correction de GitHub Issue → Choisissez Claude Opus 4.7
Si votre besoin principal est de "recevoir la description d'une issue et demander à l'IA de générer une PR fusionnable", Claude Opus 4.7 est sans conteste le meilleur choix. Son score de 87,6 % sur SWE-bench Verified signifie qu'environ neuf tâches de correction de bugs bien définies sur dix peuvent être livrées directement.
Notez que 87,6 % ne signifie pas que 87,6 % de votre travail d'ingénierie sera automatisé — il s'agit d'un test théorique basé sur des "cahiers des charges parfaits". Dans un flux de travail réel, la qualité de la description de l'issue impactera significativement le taux de réussite.
Scénario 2 : Compréhension de code avec longue fenêtre → Choisissez GPT-5.5
Lorsque vous devez demander au modèle de lire l'intégralité d'un monorepo (généralement 500K-1M jetons) avant de prendre une décision, GPT-5.5 est la seule option fiable actuellement. La précision de recherche 8-needle d'Opus 4.7 dans la plage de contexte de 1M n'est que de 32,2 %, ce qui signifie que le modèle risque fort de "passer à côté" de définitions clés au fin fond du code source.
Cet écart est structurel : si votre flux de travail dépend d'une vision globale du code (ex: renommage global, vérification de compatibilité d'API), Opus 4.7 pourrait tout simplement ne pas assurer le suivi.
Scénario 3 : Flux de programmation Agentic → Choisissez GPT-5.5
La programmation "Agentic" désigne les flux de travail où l'IA planifie, appelle des outils et corrige ses erreurs de manière autonome. Le score de 82,7 % de GPT-5.5 sur Terminal-Bench 2.0 surpasse largement Opus 4.7, se montrant particulièrement stable dans les tâches suivantes :
- Écriture et exécution de scripts de déploiement automatisés
- Débogage multi-services et analyse de logs
- Identification de problèmes dans les pipelines CI/CD
- Construction et monitoring de pipelines de données
Conseil d'intégration : Lors de la construction de flux de programmation Agentic, il est conseillé d'utiliser GPT-5.5 via des plateformes d'agrégation comme APIYI (apiyi.com). Cela facilite la gestion centralisée de votre clé API, le suivi des coûts d'invocation et le passage rapide à un modèle de secours si nécessaire.
Scénario 4 : Pair Programming interactif → Choisissez Claude Opus 4.7
L'expérience de codage interactif est extrêmement sensible à la latence. Le TTFT (latence du premier jeton) d'Opus 4.7 est d'environ 0,5 seconde, contre environ 3 secondes pour GPT-5.5. Cet écart de 6 fois est très perceptible lors d'interactions fréquentes.
Si vous utilisez des outils intégrés aux IDE comme Cursor, Claude Code ou Continue pour des complétions de code fréquentes, la faible latence d'Opus 4.7 garantira un rythme de codage beaucoup plus fluide.

Exemples d'invocation d'API pour GPT-5.5 et Claude Opus 4.7
Voici deux exemples d'invocation minimalistes pour ces modèles, afin de vous permettre de tester rapidement. Les deux sont compatibles avec le format SDK d'OpenAI, ce qui rend la migration extrêmement simple.
Invocation minimaliste de GPT-5.5
import openai
# Initialisation du client avec l'URL de base d'APIYI
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Invocation du modèle
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implémente le tri rapide (quicksort) en Python"}]
)
print(response.choices[0].message.content)
Invocation minimaliste de Claude Opus 4.7
import openai
# Initialisation du client
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Invocation du modèle
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implémente le tri rapide (quicksort) en Python"}]
)
print(response.choices[0].message.content)
Voir le code de test comparatif parallèle pour les deux modèles
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Test le temps de réponse et la longueur de sortie d'un modèle unique"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Test comparatif de capacités de programmation
test_prompt = """
Veuillez implémenter une classe de cache LRU en Python, avec les exigences suivantes :
1. Supporte les méthodes get(key) et put(key, value)
2. Élimine automatiquement l'élément le moins récemment utilisé lorsque la capacité est atteinte
3. Complexité temporelle O(1) pour toutes les opérations
4. Inclut des tests unitaires complets
"""
# Test parallèle des deux modèles
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5 : {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7 : {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
Conseil de test : Obtenez des crédits de test gratuits via APIYI sur apiyi.com. Vous pouvez tester GPT-5.5 et Claude Opus 4.7 en parallèle sous le même compte, en utilisant une base_url et une clé API uniformes, sans avoir à créer de comptes séparés chez OpenAI et Anthropic.
Analyse globale des coûts : GPT-5.5 vs Claude Opus 4.7
La tarification de l'API est un facteur déterminant pour le choix technologique. En apparence, les jetons (tokens) de sortie d'Opus 4.7 sont 17 % moins chers, mais après une analyse approfondie, la réalité est différente :
| Dimension de coût | GPT-5.5 | Claude Opus 4.7 | Impact réel |
|---|---|---|---|
| Tarif d'entrée | 5 $ / M tokens | 5 $ / M tokens | Identique |
| Tarif de sortie | 30 $ / M tokens | 25 $ / M tokens | Opus est 17 % moins cher |
| >200K Prompt | Prix inchangé | Double à 10 $ / 37,50 $ | Avantage GPT sur longue fenêtre |
| Tokens de sortie (tâche identique) | 100 % base | 72 % de plus que GPT | GPT est globalement moins cher |
| Latence TTFT | ~3 secondes | ~0,5 seconde | Opus offre une meilleure expérience |
| Coût réel (tâches en volume) | 1,0x base | 1,4-1,5x base | GPT est plus économique |
Conclusions clés sur la comparaison des coûts
L'efficacité des jetons change la nature de la comparaison des prix. Pour une tâche de programmation identique, GPT-5.5 consomme en moyenne 72 % de jetons de sortie en moins qu'Opus 4.7. Même si le prix unitaire d'Opus est 17 % moins élevé, une fois multiplié par une consommation de jetons 1,72 fois supérieure, le coût réel de la tâche pour GPT-5.5 s'avère plus faible.
L'écart se creuse davantage sur les scénarios à longue fenêtre de contexte. Lorsque l'invite dépasse 200 000 jetons, les prix d'entrée et de sortie d'Opus 4.7 doublent (10 $ et 37,50 $), tandis que ceux de GPT-5.5 restent inchangés. Pour des flux de travail nécessitant une compréhension de contexte étendu (comme l'analyse complète d'un monorepo), l'avantage en termes de coût de GPT-5.5 peut atteindre un facteur de 2 à 3.
Interprétation de la comparaison
Profil de coût de Claude Opus 4.7 : Son prix par jeton est compétitif parmi les modèles de pointe actuels. Cependant, dans les scénarios de génération en volume, sa consommation élevée de jetons alourdit la facture totale ; dans les contextes étendus, son mécanisme de doublement de prix au-delà de 200K jetons augmente considérablement les contraintes budgétaires.
Profil de coût de GPT-5.5 : Son prix par jeton est légèrement plus élevé, mais son excellente efficacité en jetons et l'absence de surcoût sur les fenêtres de contexte longues en font une solution plus économique pour les cas d'usage intensifs et à large contexte. Il est clair qu'OpenAI a pris en compte la structure des coûts des flux de travail autonomes (Agentic) lors de la conception de sa tarification.
Conseil pour l'estimation des coûts : Le coût réel d'un projet dépend de nombreux facteurs tels que la longueur de l'invite, la longueur de la sortie et la fréquence d'appel. Nous vous recommandons de connecter les deux modèles via la plateforme APIYI sur apiyi.com, qui fournit une facturation détaillée, facilitant ainsi des décisions basées sur des données réelles.
FAQ Questions fréquentes
Q1 : Lequel de GPT-5.5 ou Claude Opus 4.7 possède les meilleures capacités de programmation ?
Il n'y a pas de réponse absolue, cela dépend de la tâche. Claude Opus 4.7 est en tête sur SWE-bench Pro (64,3 % contre 58,6 %) et Verified (87,6 %), ce qui le rend plus adapté à la résolution de véritables problèmes GitHub et à la refactorisation de grands référentiels de code. GPT-5.5 excelle sur Terminal-Bench 2.0 (82,7 % contre 69,4 %) et sur la récupération à long contexte (74,0 % contre 32,2 %), étant ainsi plus efficace pour les flux de programmation par agents et la compréhension de code sur l'ensemble d'un monorepo.
Q2 : Quelle est la différence de tarification API entre GPT-5.5 et Claude Opus 4.7 ?
Pour les deux modèles, le coût des jetons en entrée est de 5 $/M. Pour les jetons en sortie, Opus 4.7 (25 $/M) est 17 % moins cher que GPT-5.5 (30 $/M). Cependant, le prix d'Opus 4.7 double lorsque l'invite dépasse 200 000 jetons, alors que GPT-5.5 conserve son tarif. Si l'on considère que GPT-5.5 consomme 72 % de jetons en sortie en moins qu'Opus, GPT-5.5 s'avère plus rentable pour les tâches à gros volume.
Q3 : Quand GPT-5.5 et Claude Opus 4.7 ont-ils été publiés ?
Claude Opus 4.7 a été publié par Anthropic le 16 avril 2026 et est déjà pleinement disponible via l'API Claude, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry. GPT-5.5 (nom de code interne Spud) a été publié par OpenAI le 23 avril 2026. Ces deux modèles de programmation de pointe sont arrivés à seulement 7 jours d'intervalle, marquant une concurrence intense.
Q4 : Pour quels scénarios de programmation choisir Claude Opus 4.7 ?
Privilégiez Opus 4.7 pour les scénarios suivants :
- Correction de problèmes GitHub : 5,7 points de pourcentage d'avance sur SWE-bench Pro.
- Refactorisation de grands référentiels : meilleure capacité de raisonnement architectural inter-fichiers.
- Programmation en binôme interactive : TTFT (Time To First Token) de seulement 0,5 seconde, soit 6 fois plus rapide.
- Revue de qualité de code : scores de qualité de code plus élevés lors des tests Rakuten-SWE-Bench.
Q5 : Comment appeler rapidement GPT-5.5 et Claude Opus 4.7 via une API ?
Nous recommandons d'utiliser une plateforme d'agrégation API compatible avec les deux modèles pour vos tests :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte.
- Obtenez une clé API unifiée et des crédits de test gratuits.
- Utilisez l'exemple de code de cet article (en remplaçant
base_urlparhttps://vip.apiyi.com/v1) et spécifiez le modèlegpt-5.5ouclaude-opus-4-7pour effectuer l'invocation du modèle.
APIYI prend en charge une interface unifiée pour les principaux modèles comme OpenAI, Anthropic et Google, ce qui permet de comparer rapidement les performances réelles de GPT-5.5 et Claude Opus 4.7 sans avoir à gérer plusieurs comptes.
Q6 : Quelles sont les limites connues de GPT-5.5 et Claude Opus 4.7 ?
Limites de GPT-5.5 :
- Latence TTFT d'environ 3 secondes, expérience moins fluide pour les scénarios interactifs.
- Moins performant qu'Opus 4.7 pour la résolution de problèmes réels sur SWE-bench.
Limites de Claude Opus 4.7 :
- Capacité de récupération à long contexte faible (32,2 % sur une plage de 1M).
- Prix doublé pour une invite > 200K, pression sur les coûts liés aux longs contextes.
- Consommation élevée de jetons en sortie, coût global plus important sur les tâches massives.
- Performances inférieures à GPT-5.5 sur les tâches d'agents comme Terminal-Bench.
Q7 : Est-il nécessaire d’utiliser à la fois GPT-5.5 et Claude Opus 4.7 ?
Pour les équipes de développement professionnelles, il est vivement conseillé de combiner les deux. Stratégie de répartition typique : utilisez Opus 4.7 pour la correction de problèmes GitHub, la revue de code et les décisions architecturales critiques ; utilisez GPT-5.5 pour l'analyse de longs contextes, les flux de travail automatisés par agents et la génération de code en volume. Ce mode hybride permet de tirer parti des forces de chaque modèle tout en équilibrant coûts et expérience utilisateur.
Points clés à retenir (Key Takeaways)
- Pour la résolution de problèmes réels, choisissez Opus : Claude Opus 4.7 est le premier choix pour corriger de véritables problèmes GitHub, dominant à la fois sur SWE-bench Pro et Verified.
- Pour la programmation par agents, choisissez GPT : GPT-5.5 affiche 13 points de pourcentage d'avance sur Terminal-Bench 2.0, offrant une utilisation d'outils multi-étapes plus stable.
- Pour les longs contextes, choisissez GPT : Dans les tests MRCR v2, GPT-5.5 (74 %) surpasse largement Opus (32,2 %), ce qui en fait l'unique choix fiable pour 1M de fenêtre de contexte.
- Pour la réactivité, choisissez Opus : Avec un TTFT de seulement 0,5 s, Opus est 6 fois plus rapide que GPT, offrant une expérience de codage interactif plus fluide.
- Pour la maîtrise des coûts, choisissez GPT : GPT-5.5 consomme 72 % de jetons en sortie en moins qu'Opus, réduisant les coûts pour les tâches à grande échelle.
- Test rapide et parallèle : Grâce à APIYI (apiyi.com), un seul compte suffit pour appeler les deux modèles et les comparer en conditions réelles.
Résumé
Voici les conclusions principales de la comparaison des capacités de programmation entre GPT-5.5 et Claude Opus 4.7 :
- Pas de champion universel : Les deux modèles possèdent des points forts distincts. Chercher aveuglément le "meilleur modèle" est une approche erronée.
- Choix basé sur les tâches : Identifiez d'abord votre scénario de programmation prioritaire (correction de tickets/issues, agents autonomes, longue fenêtre de contexte ou développement interactif) avant de choisir votre modèle principal.
- Approche hybride recommandée : Les équipes de développement professionnelles devraient intégrer les deux modèles et router les tâches vers l'option la plus adaptée pour maximiser la productivité.
Si vous ne pouvez en choisir qu'un seul : pour la correction quotidienne de tickets GitHub et la revue de code, optez pour Claude Opus 4.7 ; pour l'automatisation par agents et l'analyse de longs contextes, privilégiez GPT-5.5.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement votre choix. La plateforme propose une interface unifiée pour GPT-5.5 et Claude Opus 4.7, des crédits de test gratuits et une facturation détaillée. C'est le moyen le plus simple pour prendre une décision basée sur des données concrètes.
Lectures complémentaires
Si cette comparaison entre GPT-5.5 et Claude Opus 4.7 vous a intéressé, voici quelques suggestions :
- 📘 Test complet de Claude Opus 4.7 : L'ingénierie derrière les 87,6 % de score au SWE-bench – Analyse approfondie des capacités d'Opus 4.7.
- 📊 Guide pratique de GPT-5.5 Spud : 8 astuces pour maîtriser le nouveau roi de la programmation par agents – Apprivoisez les fonctionnalités avancées de GPT-5.5.
- 🚀 Guide de sélection des modèles de programmation IA 2026 : Panorama comparatif de GPT à Claude – Explorez une méthodologie de sélection plus globale.
📚 Références
-
Présentation officielle de GPT-5.5 par OpenAI : Benchmarks clés et description des capacités
- Lien :
openai.com/index/introducing-gpt-5-5 - Description : Document de lancement officiel de GPT-5.5, incluant les benchmarks clés tels que SWE-bench et Terminal-Bench.
- Lien :
-
Notes de version de Claude Opus 4.7 par Anthropic : Positionnement du modèle et données de performance
- Lien :
anthropic.com/news/claude-opus-4-7 - Description : Document de lancement officiel d'Opus 4.7, contenant des données détaillées sur SWE-bench Verified/Pro.
- Lien :
-
Classement public SWE-Bench Pro : Vérification tierce indépendante
- Lien :
labs.scale.com/leaderboard/swe_bench_pro_public - Description : Classement public SWE-Bench Pro maintenu par Scale AI, permettant de vérifier le classement réel des deux modèles.
- Lien :
-
Vellum LLM Leaderboard 2026 : Comparatif complet des modèles d'IA
- Lien :
vellum.ai/llm-leaderboard - Description : Plateforme de comparaison complète couvrant le développement, le raisonnement, la fenêtre de contexte étendue et bien plus encore.
- Lien :
-
Comparatif de modèles par Artificial Analysis : Analyse des performances et des coûts
- Lien :
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Description : Fournit des données comparatives granulaires sur le TTFT, le débit (throughput) et le coût global.
- Lien :
Auteur : Équipe technique d'APIYI
Échanges techniques : N'hésitez pas à en discuter dans l'espace commentaires. Pour plus de ressources, consultez le centre de documentation d'APIYI sur docs.apiyi.com