Si vous avez récemment entendu parler de "Magi AI" ou "MAGI-1" sans savoir ce qui le distingue de Sora, Kling ou Veo, cet article est fait pour vous. Magi AI est un modèle de génération vidéo très intéressant open-source développé par Sand AI — il s'agit du premier "modèle de génération vidéo autorégressif" au monde à atteindre un niveau de performance de premier plan, tout en prenant en charge la génération de vidéos de longueur infinie.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez ce qu'est Magi AI, pourquoi il suit une voie différente de celle de Sora ou Kling, ce qu'il permet de faire et comment le faire fonctionner en 5 minutes.

Qu'est-ce que Magi AI : points clés
Définition en une phrase : Magi AI = un modèle de génération vidéo open-source basé sur une architecture hybride "autorégressive + diffusion" par Sand AI.
Il a été développé par l'équipe de Sand.ai (dont le PDG est Yue Cao, co-auteur de l'article classique sur le Swin Transformer). MAGI-1 a été publié pour la première fois le 21 avril 2025, et a évolué vers Magi-1.1 en 2026. Le code, les poids et les outils d'inférence sont tous disponibles sur GitHub et Hugging Face sous licence Apache 2.0.
| Point clé | Description | Valeur |
|---|---|---|
| Licence open-source | Apache 2.0 | Entièrement commercialisable |
| Échelle du modèle | Versions 4.5B / 24B | Couvre tout, du particulier à l'entreprise |
| Architecture centrale | Autorégressif + Diffusion Transformer | Premier modèle vidéo autorégressif de premier plan |
| Fonctionnalité phare | Génération de vidéo de longueur infinie | Impossible pour Sora/Kling |
| Bloc de base | Génération par blocs (chunk) de 24 images | Supporte la génération en flux |
| Compréhension physique | Physics-IQ 56.02% | Dépasse largement ses pairs |
| Contrôlabilité | Invite par bloc (chunk-wise) | Contrôle précis au niveau de l'image |
| GitHub | SandAI-org/MAGI-1 | Code complet + poids |
💡 Compréhension rapide : Magi AI suit une voie totalement différente de celle de Sora, Veo et Kling. Ces modèles grand public génèrent tout le segment en une seule fois, ce qui limite leur durée ; tandis que Magi-1 génère de manière autorégressive par blocs (chunks), ce qui permet théoriquement une génération continue. Il s'agit d'une innovation différenciante majeure dans le domaine de la vidéo par IA. Si vous souhaitez comparer les modèles de génération vidéo actuels, vous pouvez utiliser APIYI (apiyi.com) pour accéder facilement à Veo, Kling, Wan, etc., et les combiner avec Magi en local pour obtenir le meilleur rapport qualité-prix en termes de comparaison.
Architecture technique fondamentale de Magi AI
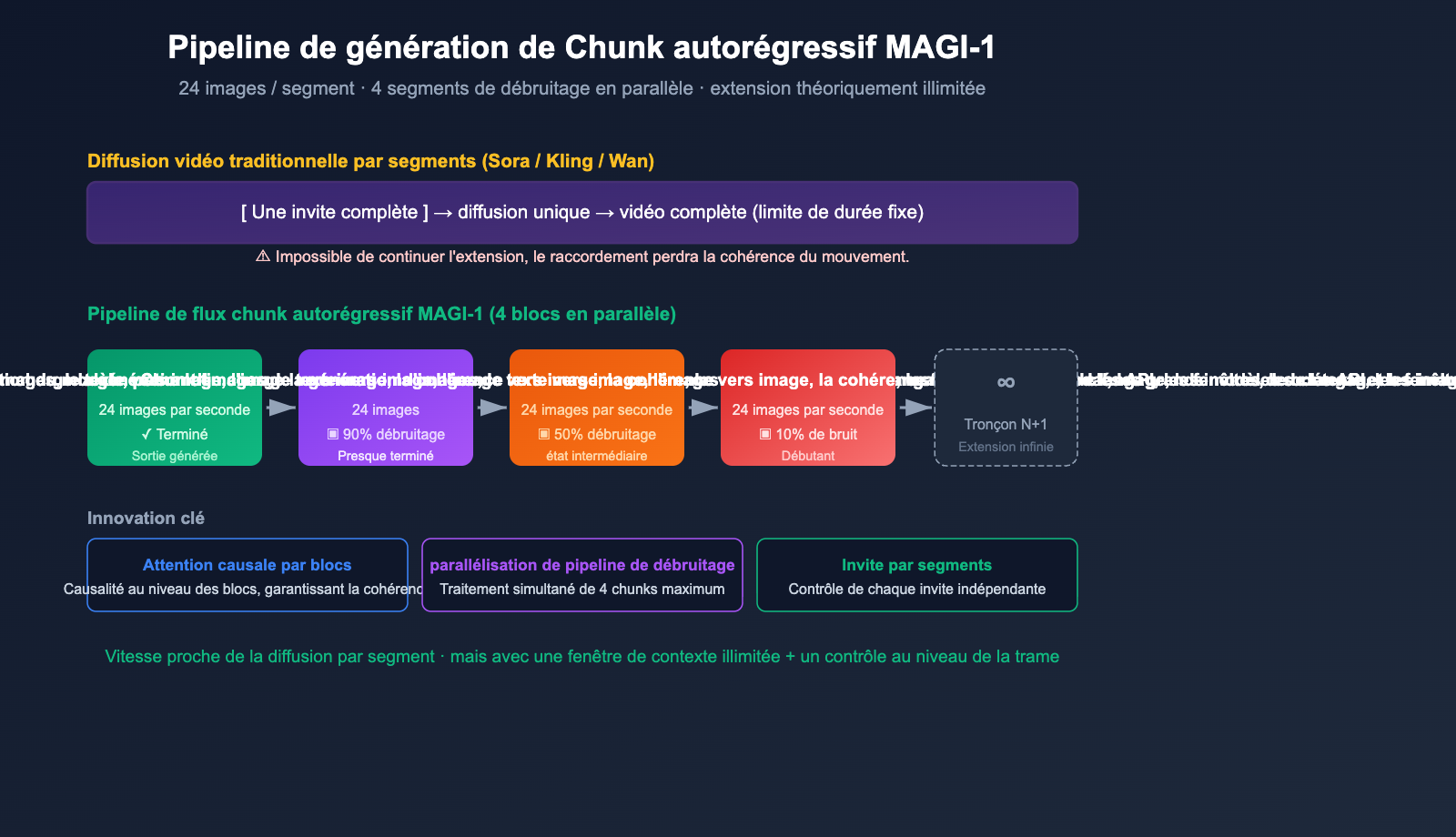
Pour comprendre ce qui rend Magi AI unique, il faut se pencher sur son mécanisme de "génération autorégressive par blocs" (chunk). C'est là que réside sa différence majeure avec les autres modèles vidéo actuels.
Génération autorégressive bloc par bloc
La grande majorité des modèles vidéo dominants (Sora, Veo, Kling, Wan, etc.) utilisent une approche de diffusion globale :
[Vidéo complète via invite] → [Diffusion et débruitage en une fois] → [Sortie vidéo complète]
Le problème avec cette méthode ? La limite de durée est fixe. Sora 1.0 est limité à 60 secondes, Kling à 5-10 secondes. Pour aller plus loin, il faut "raccorder" les séquences, ce qui entraîne souvent une perte de cohérence dans les mouvements.
Magi-1 adopte une approche hybride : autorégressive + diffusion par blocs :
invite → 1er bloc (24 images) diffusion/débruitage → 2e bloc (24 images) → 3e bloc → ... → ∞
Chaque bloc bénéficie d'une diffusion pour garantir la qualité, mais les blocs sont liés de manière autorégressive : le bloc suivant se base sur le précédent pour continuer la génération. C'est ce qui permet de débloquer la génération de "vidéos de longueur infinie", une capacité absente chez les autres modèles.
Parallélisme de pipeline : débruitage simultané de 4 blocs
Plus astucieux encore, Magi-1 ne vous oblige pas à attendre que le "1er bloc soit totalement terminé pour commencer le 2e". Son architecture de pipeline permet de traiter jusqu'à 4 blocs simultanément : dès qu'un bloc est suffisamment débruité, le suivant peut commencer sa phase de préchauffage. Résultat : la vitesse de génération autorégressive est quasi équivalente à celle d'une diffusion globale.
Diffusion Transformer + innovations multiples
Magi-1 repose sur une architecture Diffusion Transformer (DiT) et intègre de nombreuses optimisations pour l'efficacité de l'entraînement :
| Point technique | Rôle |
|---|---|
| Block-Causal Attention | Attention causale par blocs, garantit la cohérence autorégressive |
| Parallel Attention Block | Bloc d'attention parallèle, accélère le processus |
| QK-Norm + GQA | Stabilité de l'entraînement + efficacité de l'inférence |
| Sandwich Normalization in FFN | Stabilité pour les grands modèles de langage |
| SwiGLU | Fonction d'activation moderne |
| Softcap Modulation | Contrôle l'explosion des scores d'attention |
Cette pile technologique est quasiment identique à l'"arsenal Transformer moderne" utilisé par les LLM de premier plan comme Llama 3 ou Mistral. C'est la raison fondamentale pour laquelle Magi-1 atteint une qualité vidéo de premier ordre avec des paramètres de 4,5B/24B, des tailles tout à fait gérables pour un utilisateur individuel.
Deux versions : 4.5B / 24B
| Version | Paramètres | Cas d'usage | Configuration matérielle |
|---|---|---|---|
| MAGI-1 4.5B | 4,5 B | Développeurs indépendants, expérimentations locales | Une seule carte (24 Go+) |
| MAGI-1 24B | 24 B | Déploiement en production, qualité maximale | Multi-GPU / H100 recommandé |
Sand AI a publié les deux versions en open source : la 4,5B est conçue pour permettre aux "développeurs indépendants de s'amuser", tandis que la 24B est le modèle phare destiné aux performances de pointe.
Capacités principales de Magi AI

Capacité 1 : Génération de vidéo à longueur infinie
C'est l'atout le plus unique de Magi-1, une prouesse que les autres modèles vidéo grand public ne maîtrisent pas. La documentation officielle est claire : "Magi-1 est le seul modèle de génération vidéo par IA à offrir des capacités d'extension vidéo infinies."
Concrètement : vous pouvez demander à Magi-1 de générer une vidéo continue de 5, 10 minutes, voire d'une heure, avec une cohérence de mouvement et de scène bien supérieure aux méthodes de "raccordement" classiques. C'est un avantage majeur pour les mini-séries, les publicités longues ou les vidéos pédagogiques.
Capacité 2 : Compréhension physique de haut niveau
Sur le benchmark Physics-IQ, Magi-1 atteint un score de 56,02 %, dépassant largement tous les modèles concurrents actuels. Physics-IQ évalue la capacité du modèle à prédire "comment le monde physique va évoluer" : la trajectoire d'un ballon, l'écoulement de l'eau ou le mouvement d'un vêtement.
Grâce à cette meilleure compréhension physique, l'aspect "artificiel" de l'image diminue, rendant les mouvements bien plus proches de la réalité.
Capacité 3 : Contrôle précis par trame (Chunk-wise Prompting)
Comme la génération se fait bloc par bloc (chunk-by-chunk), Magi-1 permet d'attribuer une invite spécifique à chaque bloc de 24 images :
bloc 1 : "un chat court dans l'herbe"
bloc 2 : "le chat commence à sauter"
bloc 3 : "le chat est attiré par un papillon et s'arrête"
bloc 4 : "le chat poursuit le papillon vers le ciel"
Ce niveau de contrôle fin est quasiment impossible avec les modèles de diffusion traditionnels. Cela simplifie considérablement la création de "storyboards vidéo longs", rendant le processus réellement exploitable.
Capacité 4 : Image vers vidéo (I2V) performant
Magi-1 excelle particulièrement dans les tâches d'image vers vidéo. À partir d'une image fixe et d'une description textuelle, il génère une vidéo parfaitement cohérente avec l'image, tout en conservant des mouvements naturels. C'est une approche plus contrôlable que le simple texte vers image (T2V), idéale pour les besoins de production réels.
Capacité 5 : Respect des invites de haut vol
Dans son article, Sand AI a spécifiquement testé le respect des instructions. Les résultats montrent que la capacité de Magi-1 à suivre les consignes est nettement supérieure à celle de Wan 2.1 et HunyuanVideo, rivalisant même avec le modèle fermé Hailuo i2v-01. En clair : vos invites sont réellement prises en compte, sans "interprétation libre" excessive de la part du modèle.
Comparaison entre Magi AI et les principaux modèles vidéo
L'une des questions les plus fréquentes chez les nouveaux utilisateurs est : « Comment Magi se situe-t-il par rapport à Sora, Kling ou Wan ? » Voici un tableau comparatif clair pour vous aider à y voir plus clair.
| Dimension de comparaison | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| Open Source | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| Architecture | Autorégressif + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| Longueur illimitée | ✅ Seul supporté | ❌ | ❌ | ❌ | ❌ |
| Contrôle par segment | ✅ | ❌ | ❌ | ❌ | ❌ |
| Nombre de paramètres | 4.5B / 24B | Non public | Non public | 14B | 13B |
| Physics-IQ | 56.02% | — | — | Moyen | Moyen |
| Respect de l'invite | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Exécution locale | ✅ 4.5B (1 GPU) | ❌ | ❌ | ✅ | ✅ |
| Commercialisable | ✅ Apache 2.0 | ⚠ Usage restreint | ⚠ Selon plan | ✅ | ⚠ Voir licence |
🎯 Conclusion : Si vous recherchez la « meilleure qualité d'image + une vidéo courte en une seule fois », Sora 2 / Kling 2 restent les meilleurs choix. Si vous avez besoin d'une solution « open source + vidéo longue + contrôle image par image », Magi AI est actuellement la seule réponse. Si vous souhaitez « exécuter localement tout en utilisant des API pour comparer », je vous conseille de déployer MAGI-1 4.5B en local et d'utiliser le service proxy API APIYI (apiyi.com) pour invoquer simultanément des modèles propriétaires comme Veo ou Sora, afin de réaliser les tests comparatifs les plus complets.
Prise en main rapide de Magi AI

Méthode 1 : Essai en ligne via Web (le plus rapide)
Le moyen le plus simple est d'accéder directement à l'application Web officielle :
- Accès :
magi.sand.ai/app/projects - Créez un compte pour commencer à utiliser le service.
- Aucune configuration d'environnement nécessaire, tout fonctionne depuis votre navigateur.
Idéal pour les utilisateurs qui veulent « voir le résultat avant de s'engager ».
Méthode 2 : Déploiement local via le code source GitHub
Si vous souhaitez faire de la recherche ou utiliser le modèle sur le long terme en local, clonez le dépôt GitHub :
# Cloner le dépôt
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# Installer les dépendances
pip install -r requirements.txt
# Télécharger les poids 4.5B (environ 9 Go)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# Exécuter un exemple minimal
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 Conseil : Pour une première exécution locale, je recommande d'utiliser le modèle 4.5B avec une carte graphique disposant de 24 Go de VRAM (RTX 3090/4090 suffisent). La version 24B offre une meilleure qualité, mais nécessite plusieurs cartes H100, ce qui augmente considérablement les coûts.
Méthode 3 : Téléchargement direct des poids via Hugging Face
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
Les poids sont stockés au format standard safetensors et peuvent être chargés directement avec diffusers ou transformers.
Flux de travail recommandé : Magi en local + API propriétaires
Pour les développeurs, le flux de travail le plus pragmatique est le suivant :
- Exécuter localement MAGI-1 4.5B : Pour bénéficier de ses capacités uniques (vidéos de longueur illimitée, contrôle image par image).
- Appel d'API pour Veo / Sora / Kling : Pour obtenir la meilleure qualité d'image sur des séquences courtes.
- Accès unifié : Utilisez APIYI (apiyi.com) pour accéder en une seule fois aux meilleurs modèles vidéo propriétaires internationaux, évitant ainsi les problèmes de gestion de comptes, de réseau et de facturation.
- Comparaison transversale : Exécutez les deux solutions avec la même invite (prompt) et choisissez le résultat le plus adapté à votre tâche actuelle.
À qui s'adresse Magi AI ?
Scénario 1 : Créateurs de vidéos longues
Séries courtes, publicités longues, vidéos pédagogiques, documentaires — dans ces domaines, la méthode traditionnelle consistant à "assembler des clips de 5 secondes" a atteint ses limites. La génération de longueur illimitée de Magi-1 est actuellement la seule solution prête à l'emploi.
Scénario 2 : Réalisateurs ayant besoin d'un contrôle précis du découpage
Le "chunk-wise prompting" (invite par segment) vous permet de contrôler chaque séquence comme si vous rédigiez un storyboard. C'est extrêmement utile pour les créateurs de vidéos courtes, les storyboarders d'animation et les réalisateurs de publicités.
Scénario 3 : Chercheurs en génération vidéo / Contributeurs open source
Avec sa licence Apache 2.0, ses poids complets, son article de recherche et son dépôt GitHub, Magi est actuellement la meilleure implémentation open source de référence pour étudier la "génération vidéo autorégressive". Si vous menez des recherches dans ce domaine, Magi-1 est un projet incontournable.
Scénario 4 : Petites et moyennes équipes souhaitant un déploiement local
Les modèles fermés comme Sora ou Kling ne sont accessibles que via API, ce qui empêche un contrôle total des données. Magi-1 est sous licence Apache 2.0, ses poids sont téléchargeables et il peut être entièrement déployé dans votre propre cloud privé, ce qui est idéal pour les secteurs sensibles aux données (santé, finance, éducation).
FAQ sur Magi AI
Q1 : Magi AI est-il gratuit ? Peut-on l’utiliser à des fins commerciales ?
C'est entièrement gratuit et totalement utilisable commercialement sous licence Apache 2.0. C'est l'un des avantages majeurs de Magi par rapport aux modèles fermés comme Sora ou Kling. Vous n'avez qu'à supporter les coûts de matériel / GPU ; il n'y a pas de frais d'invocation du modèle, pas d'abonnement mensuel et aucune restriction commerciale.
Q2 : Lequel est le meilleur entre Magi-1, Wan 2.6 et HunyuanVideo ?
Selon les données comparatives de l'article de Sand AI, Magi-1 surpasse Wan 2.1 et HunyuanVideo sur trois indicateurs : compréhension physique (Physics-IQ), respect de l'invite et qualité du mouvement. Cependant, Wan 2.6 est une version plus récente avec un écosystème communautaire et une chaîne d'outils plus matures. Conseil pratique : utilisez Wan 2.6 pour les vidéos courtes et la haute qualité, et Magi-1 pour les vidéos longues et le contrôle précis. Les deux ne sont pas incompatibles.
Q3 : La « vidéo de longueur illimitée » est-elle vraiment illimitée ?
En théorie, oui. Le mécanisme de génération par segments (chunk) autorégressifs de Magi-1 n'a pas de limite de longueur intrinsèque ; vous pouvez le laisser générer indéfiniment. Les limites réelles proviennent principalement de la mémoire vidéo (VRAM) et du temps : la VRAM n'a besoin de conserver que l'état des quelques segments en cours, donc il n'y a pas de risque de saturation ; quant au temps, il augmente de manière linéaire — une vidéo de 5 minutes prend environ 5 fois plus de temps qu'une vidéo d'une minute.
Q4 : Quelle est la différence entre la version 4.5B et la version 24B ?
La version 4.5B est le "modèle vidéo autorégressif le plus puissant pouvant tourner sur une carte graphique grand public". Sa qualité dépasse déjà la plupart des premiers modèles fermés, bien qu'elle reste en retrait par rapport aux fleurons comme Sora 2 ou Kling 2. La version 24B est la véritable "version de compétition", dont la qualité se rapproche des meilleurs modèles fermés. Si vous êtes un créateur individuel ou un chercheur, la 4.5B est largement suffisante. Pour une production commerciale, nous recommandons la 24B avec plusieurs cartes H100.
Q5 : Dois-je remplacer mon utilisation actuelle de Sora / Kling par Magi ?
Il n'est pas nécessaire de les remplacer, nous suggérons une utilisation complémentaire. Sora et Kling conservent un avantage sur la qualité d'image par segment et le langage cinématographique, tandis que Magi excelle dans la longueur, le contrôle et l'autonomie open source. La stratégie optimale est la suivante : utilisez le service proxy API APIYI (apiyi.com) pour accéder aux modèles fermés étrangers pour vos courts-métrages de haute qualité, et utilisez Magi en déploiement local pour les vidéos longues et le contrôle précis, en choisissant l'outil le plus adapté à chaque scénario.
Q6 : Comment les développeurs chinois peuvent-ils télécharger les poids de Magi-1 ?
Il suffit de les télécharger directement sur Hugging Face (huggingface.co/sand-ai/MAGI-1). En cas de problème de réseau, vous pouvez utiliser les miroirs hf-mirror ou modelscope. Sand AI est une startup chinoise spécialisée dans l'IA, très ouverte aux développeurs locaux, et la communauté propose de nombreux tutoriels et discussions en chinois.
Résumé
Magi AI est l'un des projets les plus innovants dans le domaine de la génération vidéo open source pour 2025-2026. Il marque trois avancées majeures :
- Validation de l'approche de génération vidéo autorégressive : Magi-1 est le premier modèle vidéo autorégressif au monde à atteindre un niveau de performance de premier plan, prouvant que la méthode "chunk-by-chunk + diffusion" est une alternative viable à la "diffusion par segment complet".
- La vidéo à durée illimitée devient réalité : C'est une capacité que Sora, Kling ou Veo ne proposent pas encore, et que Magi rend accessible pour la première fois en open source.
- L'écosystème vidéo open source franchit un nouveau cap : Grâce à la licence Apache 2.0, aux poids complets et à une version 4.5B adaptée au matériel grand public, il est désormais possible pour les développeurs indépendants d'utiliser des modèles vidéo de pointe.
🚀 Conseils pratiques : Si vous souhaitez tester les capacités de Magi AI dès aujourd'hui, voici la marche à suivre : premièrement, créez un compte sur
magi.sand.ai/app/projectspour essayer l'outil en ligne ; deuxièmement, si les résultats vous convainquent, déployez la version 4.5B en local en suivant le README sur GitHub ; troisièmement, comparez les sorties de Magi (en local) avec celles de Veo, Sora ou Kling (accessibles via le service proxy API APIYI apiyi.com) pour constituer votre propre "boîte à outils de modèles". Vous aurez ainsi l'arme idéale, que ce soit pour créer des vidéos longues, des storyboards détaillés ou pour viser la meilleure qualité possible sur des séquences courtes.
Auteur : L'équipe APIYI — Spécialisée dans l'accès stable aux principaux grands modèles de langage pour les développeurs. Visitez apiyi.com pour en savoir plus.
Références
-
Dépôt GitHub principal de MAGI-1
- Lien :
github.com/SandAI-org/MAGI-1 - Description : Code source, scripts de téléchargement des poids et exemples d'inférence.
- Lien :
-
Fiche modèle Hugging Face de MAGI-1
- Lien :
huggingface.co/sand-ai/MAGI-1 - Description : Poids et documentation pour les versions 4.5B et 24B.
- Lien :
-
Article scientifique officiel de MAGI-1 (PDF)
- Lien :
static.magi.world/static/files/MAGI_1.pdf - Description : Détails techniques complets et résultats des benchmarks.
- Lien :
-
Page de présentation officielle de Magi par Sand AI
- Lien :
sand.ai/magi - Description : Page d'accueil du projet et présentation du produit.
- Lien :
-
Application Web en ligne MAGI-1
- Lien :
magi.sand.ai/app/projects - Description : Essai direct depuis votre navigateur.
- Lien :
-
Wiki ComfyUI – Rapport sur MAGI-1
- Lien :
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - Description : Analyse approfondie et comparatifs par des tiers.
- Lien :