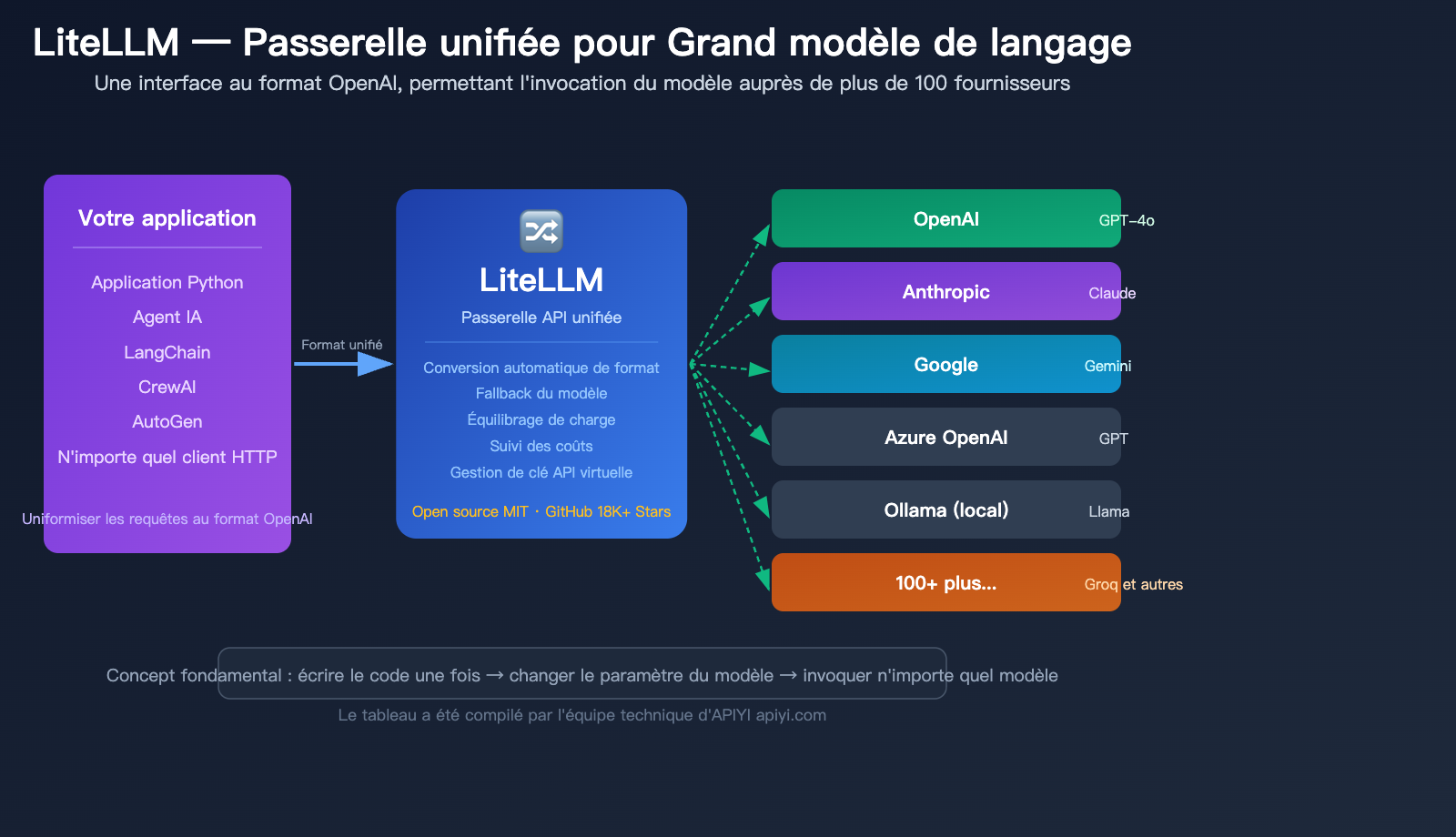
Avez-vous déjà été confronté à ce casse-tête : votre projet utilise simultanément GPT d'OpenAI, Claude d'Anthropic et Gemini de Google, mais chaque modèle possède son propre SDK, son propre format d'API et même sa propre gestion des erreurs ? Résultat : le moindre changement de modèle vous oblige à réécrire une grande partie de votre code.
C'est précisément le problème que résout LiteLLM. Pour faire simple, LiteLLM est le « traducteur universel » des grands modèles de langage : vous n'avez besoin d'apprendre qu'une seule méthode d'appel (le format OpenAI), et il se charge de la traduire vers les formats API de plus de 100 fournisseurs de modèles.
Valeur ajoutée : En lisant cet article, vous comprendrez ce qu'est LiteLLM, pourquoi les frameworks d'IA Agents l'adoptent massivement et comment le prendre en main en moins de 5 minutes.
Qu'est-ce que LiteLLM : 5 concepts clés
Avant de commencer, comprenons les 5 concepts fondamentaux de LiteLLM de la manière la plus simple possible. Une fois ces bases maîtrisées, tout le reste deviendra un jeu d'enfant.
| Concept clé | Explication simple | Problème résolu |
|---|---|---|
| Interface unifiée | Tous les modèles sont appelés de la même façon | Plus besoin d'apprendre un SDK par modèle |
| Provider (Fournisseur) | Fabricants de modèles comme OpenAI, Anthropic, etc. | Gestion des connexions aux différents fournisseurs |
| Fallback (Basculement) | Passage automatique au modèle B si le modèle A échoue | Garantie de continuité de service |
| Virtual Key (Clé virtuelle) | Création de "sous-comptes" pour les membres de l'équipe | Contrôle de l'utilisation et du budget |
| Proxy (Passerelle) | Serveur relais fonctionnant indépendamment | Intégration possible avec n'importe quel langage ou outil |
Quels problèmes LiteLLM résout-il ?
Imaginez un monde sans LiteLLM :
Appel à OpenAI :
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Bonjour"}]
)
Appel à Anthropic :
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Obligatoire chez Anthropic
messages=[{"role": "user", "content": "Bonjour"}]
)
Appel à Google Gemini :
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Bonjour")
Vous voyez ? Trois modèles, trois SDK différents, trois syntaxes. Si votre projet doit supporter le changement de modèle, votre code sera parsemé de conditions if provider == "openai"... elif provider == "anthropic"....
Avec LiteLLM :
import litellm
# Appel à OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Bonjour"}])
# Appel à Anthropic — même syntaxe
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Bonjour"}])
# Appel à Gemini — toujours la même syntaxe
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Bonjour"}])
Une seule fonction litellm.completion(), il suffit de changer le paramètre model. LiteLLM gère automatiquement en arrière-plan la conversion de format, l'adaptation des paramètres et la standardisation des réponses.
🎯 Conseil technique : Le concept d'interface unifiée de LiteLLM est similaire à APIYI (apiyi.com) — tous deux permettent d'appeler plusieurs modèles via une interface unique. La différence est que LiteLLM est une solution open-source à auto-héberger, tandis qu'APIYI est un service managé sans déploiement requis. Choisissez en fonction des capacités techniques de votre équipe.
Explication détaillée des deux modes d'utilisation de LiteLLM
LiteLLM propose deux modes d'utilisation adaptés à différents scénarios. Comprendre la différence entre ces deux modes est essentiel pour faire le bon choix.
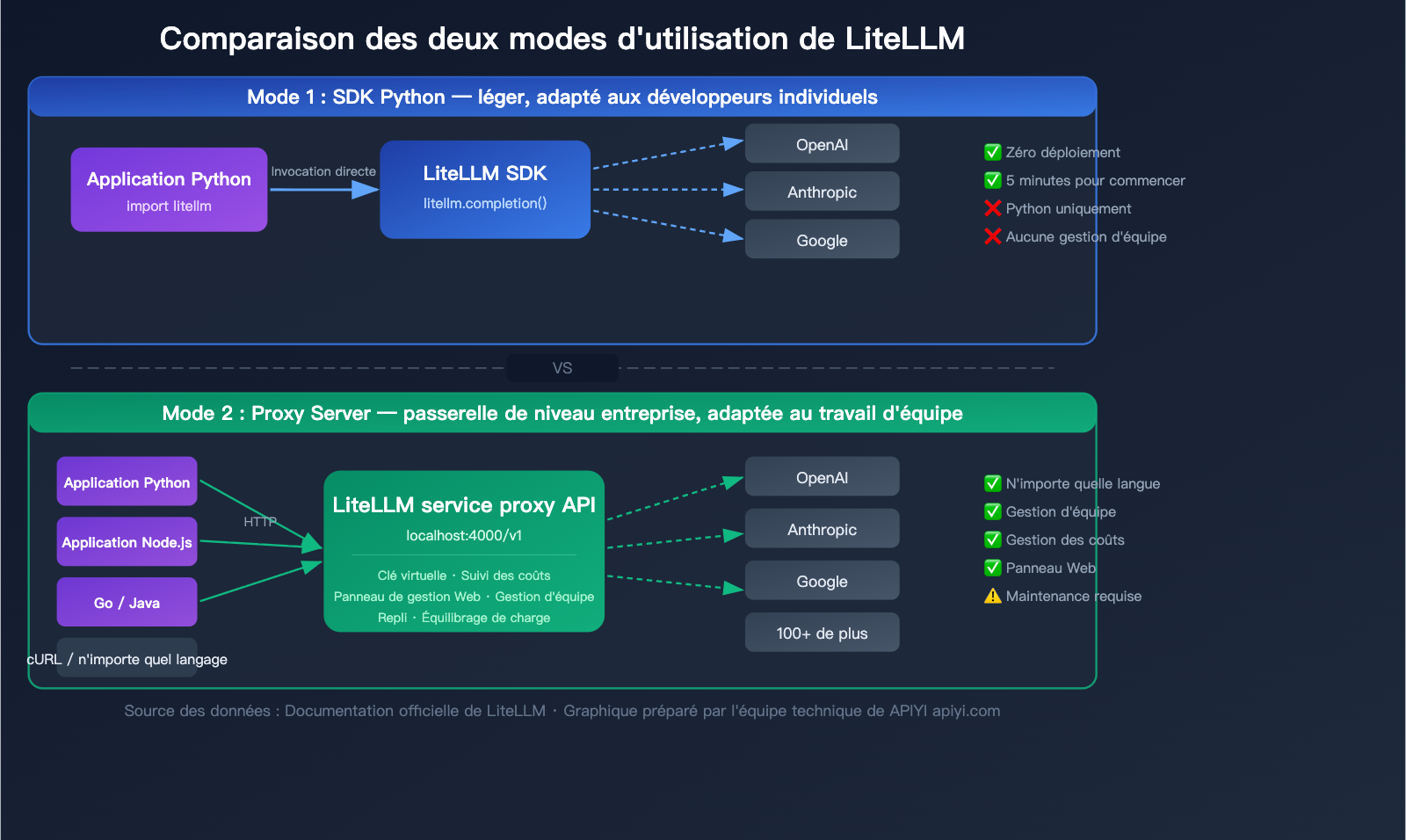
Mode 1 : SDK Python (Léger)
Importez directement le package litellm dans votre code Python et utilisez-le comme n'importe quelle fonction.
Cas d'utilisation :
- Développeurs individuels
- Projets 100% Python
- Prototypage rapide
- Pas besoin de gestion d'équipe
Installation :
pip install litellm
Utilisation de base :
import litellm
import os
# Configuration de la clé API (via variables d'environnement)
os.environ["OPENAI_API_KEY"] = "sk-votre-clé"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-votre-clé"
# Appel à n'importe quel modèle
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Explique ce qu'est une passerelle API"}]
)
print(response.choices[0].message.content)
Mode 2 : Serveur Proxy (Passerelle d'entreprise)
Fonctionne comme un serveur indépendant, exposant une interface HTTP compatible avec OpenAI. N'importe quel langage de programmation ou outil capable d'envoyer des requêtes HTTP peut l'utiliser.
Cas d'utilisation :
- Collaboration en équipe
- Projets multi-langages (Java, Go, Node.js, etc.)
- Besoin de suivi des coûts et gestion budgétaire
- Besoin d'attribuer des clés virtuelles à différentes équipes
- Intégration avec des frameworks d'IA Agents
Installation et démarrage :
# Installation
pip install 'litellm[proxy]'
# Démarrage avec un fichier de configuration
litellm --config config.yaml --port 4000
# Ou via Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
Une fois lancé, n'importe quelle application peut l'appeler comme s'il s'agissait d'OpenAI :
from openai import OpenAI
# Pointez base_url vers le Proxy LiteLLM
client = OpenAI(
api_key="sk-votre-clé-virtuelle",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Bonjour"}]
)
Comparaison : SDK LiteLLM vs Mode Proxy
| Dimension de comparaison | SDK Python | Serveur Proxy |
|---|---|---|
| Installation | pip install litellm |
pip install 'litellm[proxy]' ou Docker |
| Mode d'appel | Appel de fonction Python | API HTTP (tous langages) |
| Configuration | Dans le code | Fichier config.yaml |
| Gestion des clés virtuelles | Non supporté | Supporté, avec plafonds budgétaires |
| Panneau d'administration Web | Aucun | Inclus, gestion visuelle |
| Gestion d'équipe | Non supporté | Supporté (utilisateurs/équipes/budgets) |
| Suivi des coûts | Basique (au niveau du code) | Complet (persistance en base de données) |
| Complexité de déploiement | Zéro | Nécessite une maintenance serveur |
| Public cible | Développeurs individuels | Équipes / Entreprises |
💡 Conseil de choix : Si vous êtes un développeur individuel faisant du prototypage, le mode SDK est opérationnel en 5 minutes. Si vous travaillez en équipe ou en environnement de production, le mode Proxy est plus adapté. Bien sûr, si vous ne souhaitez pas déployer et maintenir de serveur vous-même, vous pouvez également utiliser un service d'interface unifiée managé comme APIYI (apiyi.com), prêt à l'emploi.
Guide de démarrage rapide de LiteLLM
Voici les étapes complètes pour utiliser LiteLLM à partir de zéro.
Démarrage rapide avec le mode SDK LiteLLM
Étape 1 : Installation
pip install litellm
Étape 2 : Configuration des variables d'environnement
# macOS / Linux
export OPENAI_API_KEY="sk-votre-clé"
export ANTHROPIC_API_KEY="sk-ant-votre-clé"
# Windows
set OPENAI_API_KEY=sk-votre-clé
Étape 3 : Écriture du code
import litellm
# Invocation de base
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Vous êtes un assistant technique"},
{"role": "user", "content": "Qu'est-ce qu'une passerelle LLM ?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Consommation de jetons : {response.usage.total_tokens}")
print(f"Coût estimé : ${response._hidden_params.get('response_cost', 'N/A')}")
Voir le code complet : avec Fallback et streaming
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-votre-clé"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-votre-clé"
# Appel avec Fallback : bascule automatiquement vers Claude si GPT-4o échoue
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Expliquez l'API RESTful"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Sortie en streaming
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Écrivez un poème sur la programmation"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
Démarrage rapide avec le mode Proxy LiteLLM
Étape 1 : Création du fichier de configuration config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Étape 2 : Lancement du Proxy
litellm --config config.yaml --port 4000
Étape 3 : Utilisation via le SDK OpenAI standard
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Appel de GPT-4o (via le Proxy LiteLLM)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Bonjour"}]
)
print(response.choices[0].message.content)
Vous pouvez également utiliser cURL pour un appel direct :
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 Démarrage rapide : Le Proxy LiteLLM nécessite la gestion de votre propre serveur et de vos clés API. Si vous souhaitez utiliser une interface unifiée sans déploiement, essayez APIYI (apiyi.com). Il prend également en charge le format compatible OpenAI pour plus de 100 modèles, sans aucune infrastructure à gérer.
Le rôle central de LiteLLM dans les agents IA
C'est une question que beaucoup de débutants se posent : pourquoi presque tous les frameworks d'agents IA populaires prennent-ils en charge, voire recommandent, l'utilisation de LiteLLM ?
Pourquoi les agents IA ont-ils besoin de LiteLLM ?
Lorsqu'un agent IA exécute des tâches, il doit souvent :
- Invoquer différents modèles : utiliser des petits modèles économiques pour les tâches simples et des grands modèles pour le raisonnement complexe.
- Gérer les dégradations automatiques : basculer automatiquement vers un modèle de secours si le modèle principal est limité ou hors service.
- Contrôler les coûts : suivre et limiter la consommation de jetons pour plusieurs agents fonctionnant en parallèle.
- Collaboration d'équipe : partager un pool de ressources API entre différents développeurs.
LiteLLM répond parfaitement à ces besoins. Il agit comme un « centre de routage » entre l'agent et le modèle.
Intégration de LiteLLM avec les frameworks d'agents IA populaires
| Framework d'agent | Méthode d'intégration | Usage typique |
|---|---|---|
| LangChain / LangGraph | Support SDK natif | ChatLiteLLM comme backend LLM |
| CrewAI | Connexion Proxy | Pool de modèles partagé entre agents |
| AutoGen (Microsoft) | Connexion Proxy | Accès via point de terminaison compatible OpenAI |
| Dify | Fournisseur personnalisé | Configuré comme point de terminaison compatible OpenAI |
| Open WebUI | Connexion Proxy | Point de terminaison API backend |
| Aider | Connexion Proxy | Couche modèle pour l'agent de génération de code |
| Continue.dev | Connexion Proxy | Backend pour l'assistant de codage IA dans l'IDE |
Architecture typique de LiteLLM dans un système multi-agents
Dans un système multi-agents, le Proxy LiteLLM fonctionne généralement comme suit :
- Agent de planification → appelle Claude Opus (modèle de raisonnement puissant)
- Agent d'exécution → appelle GPT-4o (performance équilibrée)
- Agent de vérification → appelle GPT-4o-mini (rapide et économique)
- Agent de synthèse → appelle Gemini Flash (grande fenêtre de contexte)
Tous les agents passent par le même point de terminaison Proxy LiteLLM, qui route automatiquement vers le bon modèle backend. L'administrateur peut visualiser la consommation de jetons et les coûts de tous les agents via un tableau de bord unifié.

🎯 Conseil technique : Dans un système multi-agents en production, le Proxy LiteLLM doit être couplé à PostgreSQL et Redis pour bénéficier pleinement des fonctionnalités de suivi des coûts et de mise en cache. Si votre équipe est petite ou si vous souhaitez éviter la maintenance d'infrastructures supplémentaires, APIYI (apiyi.com) propose des capacités d'interface unifiée similaires, avec un suivi des coûts et des statistiques d'utilisation intégrés, sans déploiement de base de données requis.
Analyse détaillée des fonctionnalités avancées de LiteLLM
Une fois les bases maîtrisées, les 3 fonctionnalités avancées suivantes sont les plus couramment utilisées en environnement de production.
Fonctionnalité avancée 1 : Fallback de modèle (basculement en cas de panne)
Lorsque le modèle principal rencontre une limitation de débit, un délai d'attente ou une erreur, LiteLLM bascule automatiquement vers un modèle de secours pour garantir la continuité du service.
Configuration du Fallback dans le SDK :
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Logique d'exécution : essai avec GPT-4o → en cas d'échec, essai avec Claude Sonnet → en cas de nouvel échec, essai avec Gemini Flash.
Configuration du Fallback dans le Proxy (config.yaml) :
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Fonctionnalité avancée 2 : Équilibrage de charge
En configurant plusieurs déploiements backend pour un même nom de modèle, LiteLLM répartit automatiquement les requêtes.
model_list:
# Un même nom de modèle, deux backends différents
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Priorité au moins occupé
# Autres stratégies : simple-shuffle, latency-based
Lors de l'invocation du modèle, il suffit de spécifier model="gpt-4o", et LiteLLM répartit automatiquement le trafic entre la connexion directe OpenAI et le déploiement Azure.
Fonctionnalité avancée 3 : Suivi des coûts et clés virtuelles
Génération d'une clé virtuelle (mode Proxy) :
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Cela génère une clé virtuelle avec un budget mensuel plafonné à 50 $, limitée à l'utilisation de GPT-4o et Claude Sonnet.
Suivi des coûts :
LiteLLM intègre une grille tarifaire pour chaque modèle et calcule automatiquement les coûts à chaque invocation du modèle. Vous pouvez consulter les données dans le tableau de bord du Proxy :
- Coûts totaux par modèle
- Détail des dépenses par utilisateur/équipe
- Tendances des coûts par période
- Statistiques de consommation de jetons (tokens)
💰 Optimisation des coûts : La fonction de suivi des coûts de LiteLLM vous aide à identifier les invocations de modèles les plus onéreuses. Associée aux avantages tarifaires d'APIYI (apiyi.com), vous pouvez obtenir des prix plus compétitifs pour les mêmes invocations de modèles, réduisant ainsi davantage les coûts d'exploitation de vos applications IA.
Aperçu des 100+ fournisseurs de modèles pris en charge par LiteLLM
LiteLLM prend en charge un nombre impressionnant de fournisseurs. Voici les catégories les plus couramment utilisées :
| Catégorie | Fournisseur | Préfixe du modèle | Modèles représentatifs |
|---|---|---|---|
| Grands modèles commerciaux | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Plateformes Cloud | Azure OpenAI | azure/ |
Série GPT déployée sur Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama hébergés sur Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini hébergé sur Vertex | |
| Accélération d'inférence | Groq | groq/ |
Llama 3.1 70B (inférence ultra-rapide) |
| Together AI | together_ai/ |
Divers modèles open source | |
| Fireworks AI | fireworks_ai/ |
Inférence haute performance | |
| Déploiement local | Ollama | ollama/ |
Llama/Mistral en exécution locale |
| vLLM | openai/ (base personnalisée) |
Moteur d'inférence auto-hébergé | |
| Modèles nationaux | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Recherche augmentée | Perplexity | perplexity/ |
Sonar Pro |
| Plateformes d'agrégation | OpenRouter | openrouter/ |
Divers modèles |
🎯 Conseils de sélection : Le choix du modèle dépend de votre cas d'usage spécifique. Si vous n'êtes pas sûr du modèle à utiliser, vous pouvez tester rapidement les performances de différents modèles via la plateforme APIYI (apiyi.com), qui prend également en charge les appels via l'interface compatible OpenAI pour la plupart des modèles mentionnés ci-dessus.

FAQ sur LiteLLM
Q1 : Quelle est la différence entre LiteLLM et l’utilisation directe du SDK OpenAI ?
Le SDK OpenAI ne permet d'appeler que les modèles d'OpenAI. LiteLLM étend les capacités du SDK OpenAI, vous permettant d'utiliser le même format de code pour appeler plus de 100 fournisseurs de modèles tels qu'Anthropic, Google, Azure, etc. Si votre projet n'utilise que des modèles OpenAI, le SDK OpenAI suffit. Mais si vous avez besoin d'une prise en charge multi-modèles, de basculement en cas de panne ou de gestion des coûts, LiteLLM est un meilleur choix.
Q2 : LiteLLM est-il gratuit ?
Les fonctionnalités principales de LiteLLM sont entièrement open source et gratuites (licence MIT). Cependant, attention : LiteLLM lui-même est gratuit, mais les API des modèles que vous appelez sont payantes. Vous devez obtenir vos propres clés API auprès d'OpenAI, Anthropic, etc., et payer pour chaque invocation du modèle. Si vous ne souhaitez pas gérer plusieurs clés API séparément, vous pouvez utiliser une plateforme d'interface unifiée comme APIYI (apiyi.com) pour simplifier la gestion des clés.
Q3 : Quelle configuration serveur est nécessaire pour le Proxy LiteLLM ?
Le Proxy LiteLLM est très léger ; un serveur avec 1 cœur et 1 Go de RAM suffit pour le faire tourner. Cependant, si vous avez besoin de fonctionnalités complètes (suivi des coûts, gestion de clés virtuelles), vous aurez également besoin d'une base de données PostgreSQL et de Redis. Pour un environnement de production, nous recommandons au moins 2 cœurs, 4 Go de RAM, PostgreSQL et Redis.
Q4 : Quelle est la différence entre LiteLLM et OpenRouter ?
La plus grande différence : LiteLLM est une solution open source auto-hébergée, tandis qu'OpenRouter est un service managé.
- LiteLLM : Gratuit, auto-hébergé, vous gérez vos propres clés API, contrôle total sur le flux de données.
- OpenRouter : Prêt à l'emploi, mais avec une majoration sur les prix des appels API, et les données transitent par un tiers.
Si vous accordez de l'importance à la confidentialité des données ou si vous avez vos propres clés API, choisissez LiteLLM. Si vous souhaitez une utilisation rapide sans déploiement, envisagez des solutions managées comme APIYI (apiyi.com).
Q5 : LiteLLM prend-il en charge le streaming ?
Oui. Que ce soit en mode SDK ou Proxy, LiteLLM prend entièrement en charge le streaming SSE. Les réponses en streaming de tous les fournisseurs sont uniformément converties en morceaux (chunks) au format OpenAI, garantissant une expérience de streaming cohérente.
# Exemple de streaming avec LiteLLM
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Écris une histoire"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6 : En tant que débutant, dois-je choisir le mode SDK ou le mode Proxy ?
Si vous êtes un développeur Python et que vous débutez, le mode SDK est le plus simple : pip install litellm et quelques lignes de code suffisent. Lorsque vous aurez besoin de collaboration en équipe, d'intégration multilingue ou de déploiement en production, vous pourrez migrer vers le mode Proxy. Le mode d'invocation principal est identique pour les deux, ce qui rend la migration très simple.
Q7 : Où placer le fichier de configuration config.yaml de LiteLLM ?
Il n'y a pas d'emplacement fixe. Il suffit de spécifier le chemin via le paramètre --config lors du lancement du Proxy :
litellm --config /chemin/vers/votre/config.yaml
Il est généralement recommandé de le placer à la racine du projet ou dans un répertoire de configuration dédié. Si vous utilisez Docker, montez-le dans le conteneur via un volume.
Guide de décision rapide pour LiteLLM
Choisissez la solution la plus adaptée à votre situation :
| Votre situation | Solution recommandée | Raison |
|---|---|---|
| Développeur individuel, projet Python | SDK LiteLLM | Aucun déploiement, prêt en 5 minutes |
| Développement en équipe, besoin de suivi budgétaire | Proxy LiteLLM | Clés virtuelles + suivi des coûts |
| Pas envie de gérer l'infrastructure | APIYI (apiyi.com) | Service managé, prêt à l'emploi |
| Système multi-agents | Proxy LiteLLM | Routage unifié + équilibrage de charge |
| Utilisation exclusive de modèles OpenAI | SDK OpenAI direct | Aucune couche supplémentaire nécessaire |
| Confidentialité des données prioritaire | Auto-hébergement LiteLLM | Les données ne transitent pas par un tiers |
Résumé
LiteLLM est un outil d'infrastructure extrêmement pratique pour le développement d'applications IA. Sa valeur fondamentale tient en une phrase : utilisez un format de code unique (celui d'OpenAI) pour appeler les API de plus de 100 fournisseurs de modèles.
Pour les débutants, voici les points essentiels à retenir :
- LiteLLM est un « traducteur » : il vous aide à traduire des requêtes au format unifié vers le format API spécifique de chaque modèle.
- Deux modes disponibles : SDK (package Python léger) et Proxy (serveur passerelle indépendant).
- Valeur ajoutée : interface unifiée, mécanisme de repli (fallback), équilibrage de charge et suivi des coûts.
- Standard pour les frameworks d'agents : LangChain, CrewAI, AutoGen et bien d'autres prennent presque tous en charge LiteLLM.
- Entièrement open source et gratuit : sous licence MIT, aucun frais pour l'auto-hébergement.
Si vous trouvez que les coûts opérationnels liés à l'auto-hébergement d'un Proxy LiteLLM sont trop élevés, vous pouvez également utiliser des services d'interface unifiée gérés comme APIYI (apiyi.com). Vous obtiendrez le même résultat — appeler tous les modèles principaux avec une seule clé API — tout en vous épargnant les contraintes de déploiement et de maintenance.
Auteur de l'article : Équipe technique APIYI
Échanges techniques : Visitez APIYI (apiyi.com) pour obtenir plus de tutoriels sur l'invocation du modèle et un support technique.
Date de mise à jour : Avril 2026
Version applicable : LiteLLM v1.x+
Références :
- Documentation officielle de LiteLLM : docs.litellm.ai
- Dépôt GitHub de LiteLLM : github.com/BerriAI/litellm
- Site officiel de LiteLLM : litellm.ai
- Site officiel de BerriAI : berri.ai