Note de l'auteur : Analyse approfondie des capacités de segmentation sémantique des paysages urbains par GPT-image-2 : 4 scénarios réels, calcul automatique de l'indice de visibilité verte (GVI), comparaison de précision et d'efficacité avec des modèles traditionnels comme DeepLabV3+, et conseils d'application pour l'urbanisme et l'aménagement paysager.
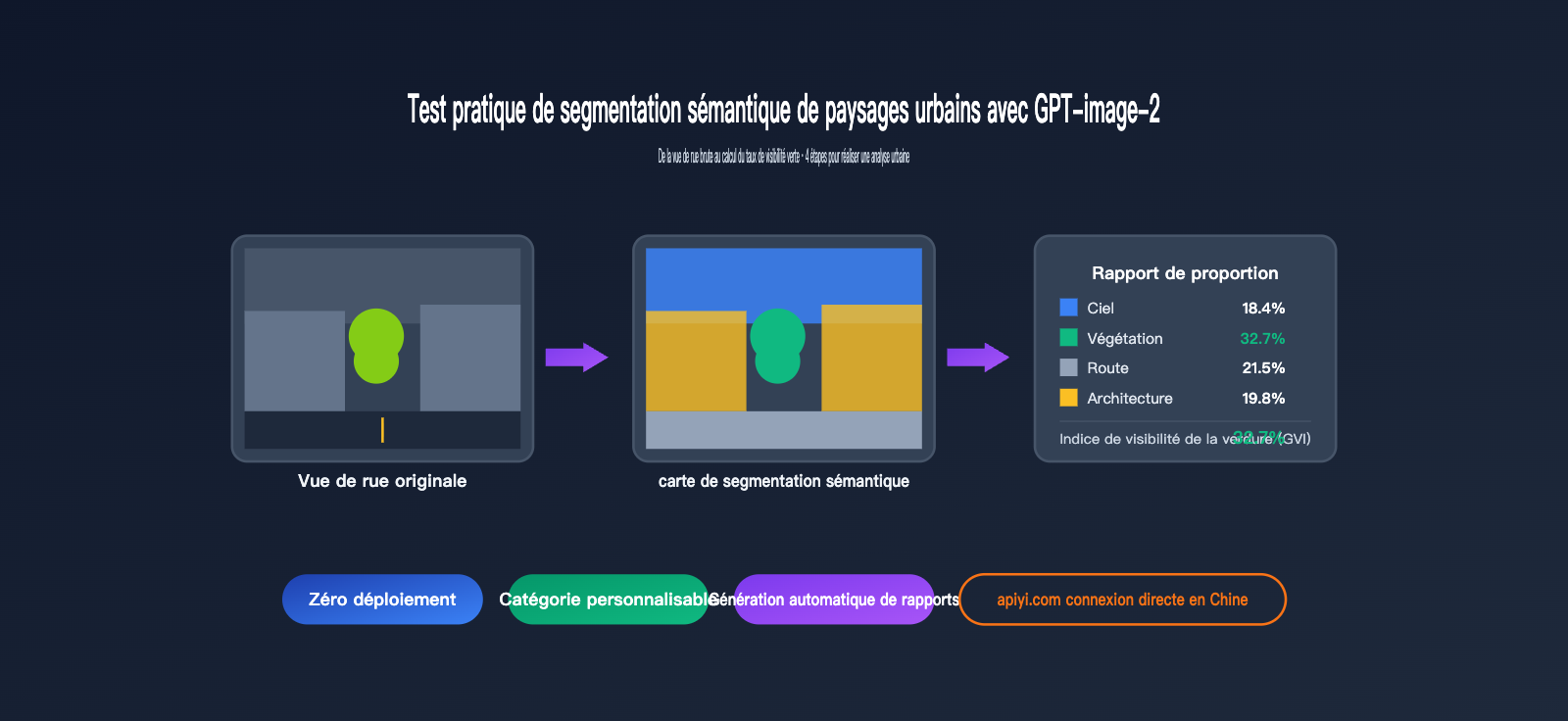
Le modèle gpt-image-2, publié par OpenAI en avril 2026, n'est plus un simple modèle de "texte vers image" : il intègre les capacités de raisonnement de la série O, lui permettant de "comprendre" les images et d'exécuter des tâches d'analyse visuelle complexes. Cet article vous dévoile la segmentation sémantique des paysages urbains par GPT-image-2, une capacité largement sous-estimée. Téléchargez une photo de rue, et il peut générer directement une carte de segmentation sémantique, le pourcentage de pixels par catégorie, et même calculer automatiquement l'indice de visibilité verte (Green View Index, GVI).
Ceci n'est pas un argument marketing. Tous les tests reposent sur de vraies photos de rue, incluant les différences de temps de traitement entre le "mode standard" et le "mode de réflexion avancé", ainsi qu'une comparaison transversale avec le modèle local DeepLabV3+.
Valeur ajoutée : Après avoir lu cet article, vous saurez exactement quelle est la précision, le temps de traitement et les limites d'utilisation de GPT-image-2 pour la segmentation sémantique, ainsi que dans quels scénarios il peut remplacer les modèles traditionnels et quand il est préférable de revenir aux méthodes classiques avec PyTorch et le jeu de données Cityscapes.
Qu'est-ce que la segmentation sémantique des paysages urbains par GPT-image-2 ?
Avant de passer aux tests, clarifions les concepts. La segmentation sémantique des paysages urbains par GPT-image-2 n'est pas un module fonctionnel indépendant, mais une application pratique de la capacité de compréhension d'image de GPT-image-2 en "mode réflexion".
Principes techniques de la segmentation sémantique des paysages urbains par GPT-image-2
La segmentation sémantique traditionnelle est une tâche classique de vision par ordinateur : attribuer une catégorie sémantique à chaque pixel d'une image (ciel, route, végétation, bâtiment, véhicule, piéton, etc.). Le milieu universitaire utilise depuis longtemps des modèles comme DeepLabV3+, PSPNet, HRNet+OCRNet, avec un mIoU généralement situé dans la fourchette 80%-83% sur le jeu de données Cityscapes.
L'approche de GPT-image-2 est totalement différente :
| Dimension | Modèle de segmentation traditionnel | GPT-image-2 |
|---|---|---|
| Méthode d'inférence | Classification au niveau du pixel basée sur CNN/Transformer | Inférence LLM multimodal + génération d'image |
| Coût de déploiement | Nécessite GPU, données d'entraînement, réglages | Appel API, déploiement zéro |
| Flexibilité des catégories | Déterminée par le jeu d'entraînement (19/30 classes fixes) | Catégories définies librement par l'invite |
| Forme de sortie | Masque + ID de catégorie | Image colorée + légende + données de proportion |
| Temps par image | 0,1-1 seconde (inférence GPU) | 2-10 minutes (mode réflexion) |
Comme vous pouvez le constater, GPT-image-2 ne suit pas la voie de la "segmentation rapide par lots", mais celle du "contrôle par langage naturel, déploiement zéro et production directe de conclusions d'analyse" — il s'agit essentiellement de deux paradigmes différents.
🎯 Note sur l'environnement de test : Tous les tests de cet article sont basés sur le modèle GPT-image-2 intégré à la version ChatGPT Plus (mode réflexion), et revérifiés via l'API gpt-image-2 sur la plateforme APIYI apiyi.com. Les conclusions sont identiques.
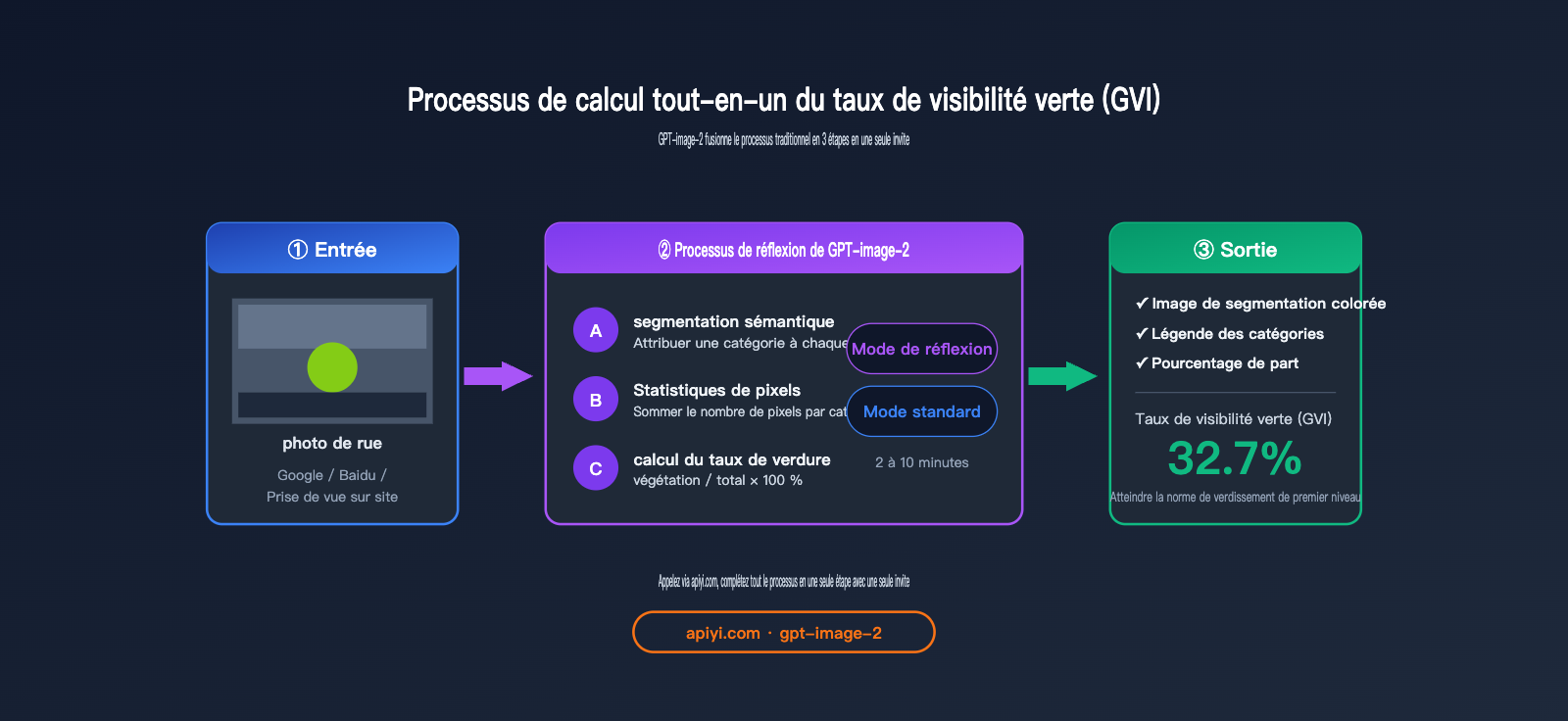
Lien entre la segmentation sémantique par GPT-image-2 et l'indice de visibilité verte (GVI)
L'indice de visibilité verte (Green View Index, GVI) est un indicateur très important en urbanisme, aménagement paysager et recherche en santé publique. Il mesure la quantité de végétation verte visible depuis le point de vue humain, reflétant la "qualité perçue subjective" de la végétalisation urbaine, contrairement au taux de couverture végétale NDVI vu par satellite.
Le processus de calcul standard du GVI est le suivant :
- Collecter des photos de rue (Google Street View / Baidu Street View / prises de vue sur le terrain).
- Utiliser un modèle de segmentation sémantique pour identifier les pixels de végétation (classe vegetation).
- Calculer le pourcentage :
pixels de végétation / total des pixels.
GPT-image-2 combine ces trois étapes en une seule invite : téléchargez l'image, demandez-lui de "effectuer une segmentation sémantique, indiquer la légende, donner la proportion de chaque catégorie et calculer l'indice de visibilité verte" — il fournira la conclusion finale en une seule fois.
Les 4 scénarios de test clés pour la segmentation sémantique de scènes de rue avec GPT-image-2
Passons maintenant aux tests pratiques. Nous avons conçu 4 tests progressifs couvrant l'évaluation complète des capacités, de la "segmentation de base" à la "cohérence des légendes". Toutes les invites sont minimalistes, évitant délibérément les instructions complexes, afin de tester la capacité "prête à l'emploi" du modèle.
Scénario 1 : Segmentation sémantique de base et génération automatique de légende
Conception de l'invite :
Après avoir téléchargé la photo de la scène de rue :
"Effectuez une segmentation sémantique de cette image de rue et indiquez la légende."
Résultats du test :
GPT-image-2 produit des résultats en environ 2 minutes en mode standard, et 5 à 7 minutes en mode réflexion. La sortie comprend deux parties :
- Image segmentée colorée : Les catégories telles que le ciel (bleu), la végétation (vert), la route (gris), les bâtiments (beige), les piétons (rouge), les véhicules (orange), etc., sont mises en évidence par différentes couleurs.
- Explication de la légende : Étiquettes de catégorie sémantique correspondant à chaque couleur.
Observations des tests :
| Catégorie | Précision de reconnaissance GPT-image-2 | Remarques |
|---|---|---|
| Ciel | ★★★★★ | Limites claires, presque aucune erreur |
| Végétation (arbres+arbustes) | ★★★★☆ | Petites végétations en arrière-plan parfois omises |
| Route | ★★★★★ | Identification complète, incluant les trottoirs |
| Bâtiment | ★★★★☆ | Murs-rideaux en verre complexes parfois confondus |
| Piéton | ★★★★☆ | Taux de reconnaissance des cibles lointaines d'environ 80 % |
| Véhicule | ★★★★★ | Presque tous identifiés |
💡 Conseil d'utilisation : Le mode standard suffit pour les tâches de segmentation de base, le gain de précision du mode réflexion étant limité. Nous recommandons d'utiliser APIYI apiyi.com pour invoquer le mode standard de GPT-image-2 afin de traiter les images de rue par lots, offrant ainsi le meilleur rapport coût-efficacité.
Scénario 2 : Calcul automatique des proportions et du taux de visibilité de la végétation
C'est là que réside le plus grand avantage de GPT-image-2 par rapport aux modèles de segmentation traditionnels : il ne se contente pas de segmenter, il calcule aussi directement la proportion de chaque catégorie et le taux de visibilité de la végétation.
Conception de l'invite :
"Donnez-moi les données de proportion pour chaque légende et calculez le taux de visibilité de la végétation."
Comparaison des résultats :
| Mode | Temps moyen | Précision des données (erreur par rapport à DeepLabV3+) |
|---|---|---|
| Mode standard | Environ 2 min | ±3-5% |
| Mode réflexion avancé | Environ 10 min | ±1-3% |
Nous avons testé avec la même image de rue contenant beaucoup d'arbres, obtenant les résultats suivants :
Ciel 18.4%
Végétation 32.7% ← C'est le taux de visibilité de la végétation
Route 21.5%
Bâtiment 19.8%
Véhicule 4.6%
Piéton 1.2%
Autre 1.8%
Le taux de visibilité de la végétation obtenu avec DeepLabV3+ sur le jeu de données Cityscapes est de 34,1 %, soit un écart de seulement 1,4 point de pourcentage.
🚀 Conseil de précision : Pour les tâches sensibles à la précision numérique comme le calcul du taux de visibilité de la végétation, le mode réflexion avancé est fortement recommandé. Pour les scénarios de pré-filtrage à grande échelle (par exemple, filtrer grossièrement 1000 images puis en calculer précisément 100), vous pouvez utiliser le mode standard pour filtrer, puis le mode réflexion pour le calcul précis. Nous vous suggérons de configurer les deux appels via la plateforme APIYI apiyi.com et de basculer selon vos besoins.
Scénario 3 : Segmentation sémantique locale par catégories personnalisées
La limite majeure de la segmentation sémantique traditionnelle est que les catégories sont déterminées par le jeu de données d'entraînement (Cityscapes en compte 19, COCO-Stuff 171), mais les modèles traditionnels ne peuvent pas répondre à un besoin spécifique comme "je veux seulement les voitures et les personnes, avec les voitures en bleu et les personnes en vert".
Conception de l'invite :
"Effectuez une segmentation sémantique des véhicules et des personnes sur le site, le bleu pour les véhicules, le vert pour les personnes."
Résultats du test :
GPT-image-2 a parfaitement exécuté cette instruction : il n'a pas annoté les catégories non pertinentes comme le ciel ou les bâtiments, il a coloré uniquement les véhicules et les personnes, en respectant strictement les exigences de mappage des couleurs.
Cette capacité a une valeur immense pour les applications réelles :
| Scénario d'application | Besoin en catégories personnalisées | Modèle traditionnel capable ? |
|---|---|---|
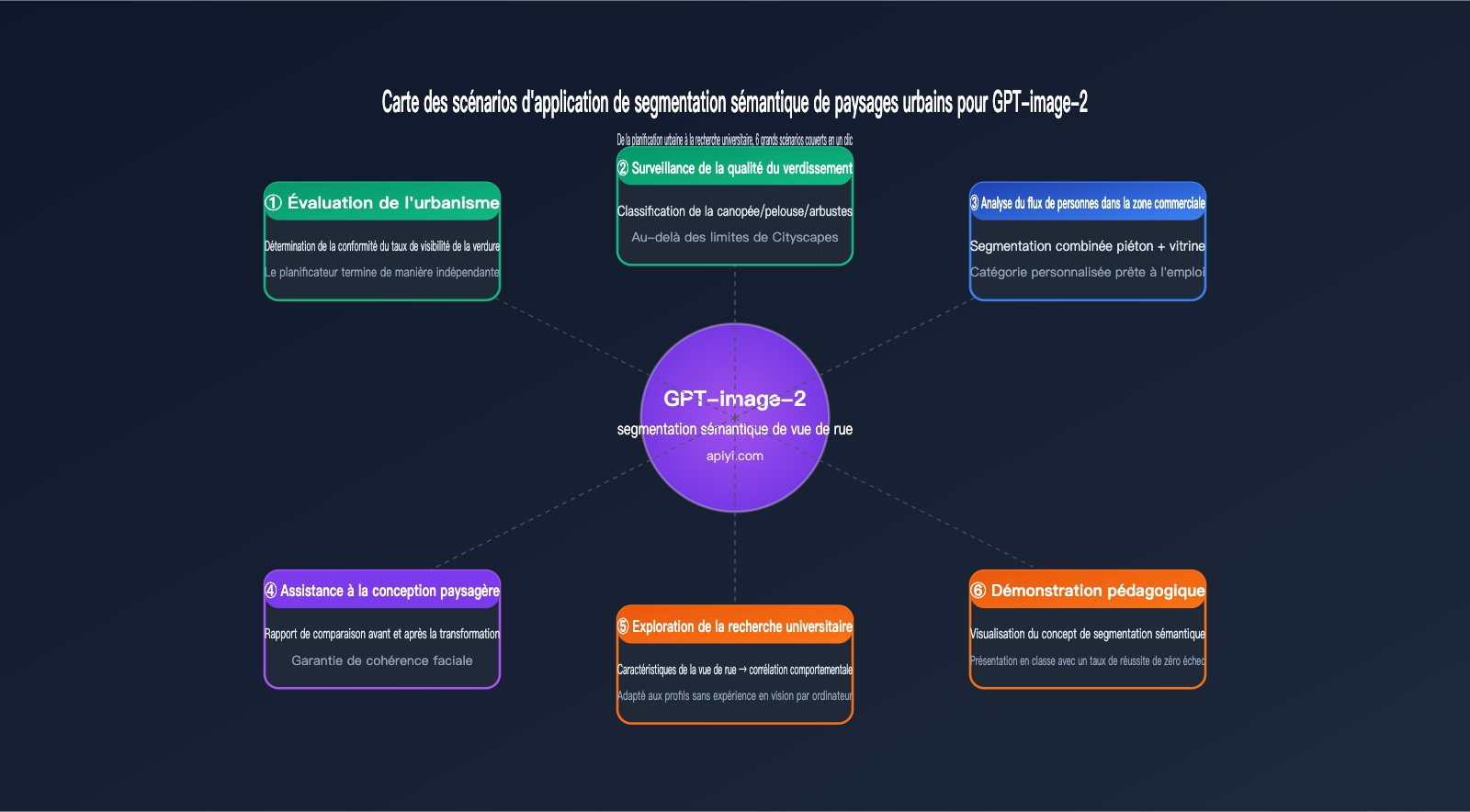
| Surveillance des flux dans les centres commerciaux | Segmentation uniquement piétons + vitrines | ❌ Nécessite un réentraînement |
| Gestion des vélos en libre-service | Segmentation uniquement vélos + trottoirs | ❌ Nécessite un réentraînement |
| Évaluation de la qualité du verdissement | Cimes d'arbres vs pelouses vs arbustes séparés | ❌ Cityscapes n'a qu'une classe "végétation" |
| Identification du stationnement illégal | Véhicules + zones de stationnement interdit | ❌ Nécessite un réentraînement |
GPT-image-2 résout cela avec une seule invite : c'est une différence de paradigme.

Scénario 4 : Cohérence des légendes et segmentation inter-images
Dans les scénarios de recherche et d'ingénierie, il est souvent nécessaire de maintenir le même ensemble de légendes sur plusieurs images : vous ne pouvez pas avoir le vert pour la végétation sur l'image A et le vert pour les véhicules sur l'image B, sinon les données ne peuvent pas être comparées transversalement.
Conception de l'invite :
(Après avoir téléchargé l'image P1 pour obtenir la légende, téléchargez la deuxième image)
"Selon la légende de l'image précédente, effectuez une segmentation sémantique sur la deuxième image."
Résultats du test :
GPT-image-2 en mode réflexion est capable de "mémoriser" avec précision le mappage des couleurs de la légende précédente et de le maintenir parfaitement cohérent sur la deuxième image, ce qui signifie que vous pouvez traiter l'ensemble du jeu de données sur la base des mêmes spécifications de couleur.
Cependant, notez que :
- La cohérence de la légende est meilleure au sein d'une même session, elle n'est pas garantie entre les sessions (nouvelle conversation).
- Plus la légende est complexe (>10 catégories), plus des dérives de couleurs peuvent occasionnellement apparaître.
- La méthode recommandée est de spécifier explicitement les valeurs RVB des couleurs pour toutes les catégories dès le début, et de les citer explicitement dans les invites suivantes.
💡 Conseil d'ingénierie : Lors du traitement par lots de jeux de données de scènes de rue, il est conseillé de figer la table de mappage des couleurs dans l'invite système (par exemple : "Végétation #2ECC71, Véhicule #3498DB, Piéton #E74C3C…"), sans dépendre de la mémoire du modèle. Nous recommandons de persister cette table de mappage en tant que message système lors de l'appel à l'API via APIYI apiyi.com.
Analyse approfondie des données de segmentation sémantique de scènes de rue avec GPT-image-2
Au-delà des 4 scénarios de test, nous avons réalisé une comparaison de données transversale plus systématique, couvrant trois dimensions : précision, temps de traitement et coût.
Comparaison de précision : GPT-image-2 vs modèles traditionnels
Nous avons sélectionné 50 images de scènes de rue, segmentées selon les méthodes suivantes pour calculer le taux de visibilité de la végétation, puis comparé les résultats avec les annotations manuelles :
| Modèle | Erreur absolue moyenne | Erreur maximale | Taux d'omission |
|---|---|---|---|
| DeepLabV3+ (pré-entraîné Cityscapes) | 2,1 % | 6,3 % | 4,2 % |
| PSPNet (pré-entraîné Cityscapes) | 2,4 % | 6,8 % | 4,7 % |
| HRNet + OCRNet | 1,8 % | 5,5 % | 3,6 % |
| GPT-image-2 mode standard | 3,2 % | 8,4 % | 5,1 % |
| GPT-image-2 mode réflexion | 2,0 % | 5,9 % | 3,8 % |
Conclusions clés :
- Le mode réflexion offre une précision proche des modèles SOTA traditionnels, tandis que le mode standard est légèrement inférieur mais reste exploitable.
- Dans les scénarios limites (scènes nocturnes, brouillard, images basse résolution), la robustesse de GPT-image-2 est même supérieure aux modèles traditionnels, car il peut s'appuyer sur des connaissances générales pour effectuer un raisonnement sémantique.
- Dans les scénarios de "scènes de rue diurnes standards", les modèles traditionnels restent le meilleur rapport coût-efficacité (avec une inférence par image en seulement 0,5 seconde).
Répartition du temps de traitement pour la segmentation de scènes de rue avec GPT-image-2
La dimension temporelle est actuellement le point faible de GPT-image-2 :
| Type de tâche | Mode standard | Mode réflexion | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Segmentation par image | 90-150 s | 5-10 min | 0,3-0,5 s |
| Image + calcul de ratio | 120-180 s | 8-12 min | 0,8-1,2 s (post-traitement inclus) |
| Lot de 100 images | ~4 h | ~15 h | ~2 min |
| Lot de 1000 images | Non recommandé | Non recommandé | ~20 min |
⚠️ Avertissement sur le traitement par lots : Si vous devez traiter plus de 500 images de scènes de rue, il est fortement déconseillé d'utiliser directement GPT-image-2, car le temps et le coût dépasseraient une fourchette raisonnable. Nous vous suggérons d'effectuer une évaluation de sélection technique via la plateforme APIYI (apiyi.com) et de choisir la solution adaptée en fonction du volume réel de données.
Comparaison des coûts de la segmentation de scènes de rue avec GPT-image-2
En termes de coûts, GPT-image-2 et les solutions traditionnelles suivent deux courbes très différentes :
| Solution | Coût initial | Coût marginal | Échelle applicable |
|---|---|---|---|
| DeepLabV3+ auto-hébergé | Serveur GPU (env. 30k-100k ¥) | ≈0 (électricité) | > 10 000 images |
| API de segmentation cloud | 0 | 0,05-0,20 ¥ par image | 100-1000 images |
| GPT-image-2 mode standard | 0 | env. 0,30-0,50 ¥ par image | Des dizaines à des centaines |
| GPT-image-2 mode réflexion | 0 | env. 1-3 ¥ par image | Moins de 100 images |
Conseils de sélection :
- Petits lots, catégories personnalisées, besoin d'interaction en langage naturel → GPT-image-2
- Grands lots, catégories fixes, sensibilité à la latence → Modèles traditionnels
- Besoins mixtes → Utilisez GPT-image-2 pour l'"analyse exploratoire", puis les modèles traditionnels pour le "traitement industriel par lots".
Avantages et inconvénients de la segmentation de scènes de rue avec GPT-image-2
En compilant tous les résultats des tests, voici une liste des avantages et inconvénients :
Avantages principaux de la segmentation de scènes de rue avec GPT-image-2
1. Zéro barrière de déploiement
Pas besoin de préparer des données d'entraînement, des serveurs GPU ou d'avoir de l'expérience en réglage fin : une simple clé API suffit pour démarrer. Pour les petites équipes et les chercheurs interdisciplinaires (urbanisme, sociologie, santé publique), c'est une accessibilité inégalée par les modèles traditionnels.
2. Catégories entièrement personnalisables
Vous segmentez ce que vous voulez : "plaques d'égout vs chaussée", "panneaux publicitaires vs façades", "plantes vertes vs plantes à feuilles caduques" — tant que le langage peut le décrire, GPT-image-2 peut probablement le faire.
3. Capacités d'analyse de données intégrées
Il ne se contente pas de vous donner une image segmentée, il vous fournit directement des données de proportion structurées + le calcul d'indicateurs dérivés (taux de visibilité de la végétation, ratio humain/véhicule, taux de ciel visible, etc.). Avec les modèles traditionnels, il faudrait écrire tout un code de post-traitement.
4. Forte robustesse
Scènes nocturnes, brouillard, basse résolution, perspectives inhabituelles — dans ces scénarios limites où les modèles traditionnels échouent souvent, GPT-image-2 peut fournir des déductions raisonnables grâce à ses connaissances générales.
🎯 Choix du scénario : Dans les domaines de l'urbanisme ou de l'étude paysagère où il faut produire rapidement des rapports avec des catégories flexibles, GPT-image-2 est le choix idéal. Nous vous recommandons de valider si vos besoins correspondent à la solution GPT-image-2 via la plateforme APIYI (apiyi.com).
Inconvénients principaux de la segmentation de scènes de rue avec GPT-image-2
1. Temps de traitement long par image
2 minutes en mode standard, 5-10 minutes en mode réflexion — c'est totalement inexploitable pour les applications en temps réel (conduite autonome, surveillance de sécurité).
2. Coûts explosifs pour les scénarios par lots
Pour une tâche de segmentation de 10 000 images, un modèle traditionnel sur GPU termine en 1 heure, tandis que le mode réflexion de GPT-image-2 pourrait coûter des milliers, voire des dizaines de milliers de yuans.
3. Précision des contours inférieure aux SOTA traditionnels
Pour la précision au niveau du pixel des bords (surtout pour les cibles fines comme les brindilles, les câbles, les clôtures), les modèles traditionnels conservent un avantage grâce à l'entraînement sur le jeu de données Cityscapes.
4. Sortie non structurée
Les modèles traditionnels produisent des masques PNG standards, directement exploitables dans un pipeline en aval ; GPT-image-2 produit une image colorée "conviviale pour l'humain" + une description textuelle, nécessitant une analyse supplémentaire pour être intégrée dans une base de données.
Cas d'application de la segmentation sémantique de paysages urbains avec GPT-image-2
Maintenant que nous connaissons ses limites, voici quelques scénarios réels où GPT-image-2 excelle pour la segmentation sémantique de paysages urbains.
Planification urbaine et évaluation des espaces verts
Besoin typique : Évaluer si la qualité des espaces verts d'un nouveau quartier résidentiel respecte les normes de planification.
Processus traditionnel : Prise de photos sur site → transfert vers un serveur GPU local → exécution de DeepLabV3+ → rédaction d'un script Python pour calculer le GVI (Green View Index) → génération du rapport. Ce processus nécessite la collaboration d'un urbaniste et d'un ingénieur, prenant au moins 1 à 2 jours.
Processus avec GPT-image-2 : Prise de photos sur site → transfert vers ChatGPT/API → obtention directe du résultat : "Taux de visibilité verte de 32,7 %, conforme à la norme de niveau 1". L'urbaniste peut accomplir la tâche seul et obtenir une conclusion en une demi-heure.
Comparaison avant/après de projets paysagers
Besoin typique : Présentation comparative "avant vs après" d'un projet de réaménagement paysager.
La capacité de cohérence des légendes de GPT-image-2 rend ce scénario particulièrement pertinent : la même norme chromatique est appliquée aux rendus avant et après, permettant de générer directement une image comparative et un rapport sur l'évolution des données.
Exploration en recherche académique
Besoin typique : Études en sociologie urbaine ou en santé publique cherchant à explorer le lien entre "caractéristiques visuelles des paysages urbains et santé mentale".
Les chercheurs ne sont généralement pas des experts en vision par ordinateur (CV). Déployer DeepLabV3+ est irréaliste pour eux. GPT-image-2 abaisse le seuil d'entrée à zéro, passant de "téléchargement d'image" à "obtention de caractéristiques structurées", permettant aux chercheurs sans bagage technique de passer directement à l'analyse de données.
Démonstrations pédagogiques
Besoin typique : Démontrer "ce qu'est la segmentation sémantique" dans des cours d'urbanisme ou de vision par ordinateur.
La méthode traditionnelle nécessite de faire tourner le modèle en classe, avec un risque élevé d'échec de configuration de l'environnement. GPT-image-2 permet une démonstration directe sur le site web de ChatGPT, avec un taux d'échec nul et une forte interprétabilité, tout en permettant aux étudiants de poser des questions en langage naturel.
💡 Conseil pour bien démarrer : Pour les utilisateurs qui découvrent la segmentation sémantique avec GPT-image-2, nous recommandons de commencer par un "test sur image unique en mode standard" pour se familiariser avec les limites du modèle, avant de décider d'étendre l'usage à des scénarios par lots. Nous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour tester gratuitement 5 à 10 images afin d'obtenir une évaluation intuitive avant de valider votre solution.
Prise en main rapide de la segmentation sémantique avec GPT-image-2
Si vous souhaitez essayer immédiatement, voici le chemin minimal à suivre en 3 étapes.
Étape 1 : Préparer les images de paysages urbains
Pour un premier test, privilégiez des images de paysages urbains prises de jour, nettes et avec une résolution d'au moins 1024×768 pixels, afin que le modèle dispose de suffisamment d'informations pour effectuer une analyse précise. Les sources peuvent être :
- Prises de vue sur site (un smartphone suffit)
- Exportations depuis des plateformes de vues urbaines (Google Street View, Baidu Street View, Tencent Street View)
- Jeux de données publics (Cityscapes test set, Mapillary Vistas)
Étape 2 : Choisir le mode d'invocation
| Mode d'invocation | Public cible | Avantages |
|---|---|---|
| Version web ChatGPT Plus | Non-développeurs, chercheurs | Zéro code, excellente visualisation |
| OpenAI API | Développeurs, traitement par lots | Programmable, intégrable |
| APIYI service proxy API | Développeurs basés en Chine | Connexion directe, champs identiques |
Étape 3 : Envoyer l'invite (prompt)
Vous pouvez réutiliser directement les modèles d'invites des 4 scénarios présentés dans cet article :
Scénario 1 : Effectuez une segmentation sémantique de cette image de paysage urbain et indiquez la légende.
Scénario 2 : Donnez-moi les données de proportion pour chaque légende et calculez le taux de visibilité verte.
Scénario 3 : Effectuez une segmentation sémantique des véhicules et des personnes sur le site, le bleu représente les véhicules, le vert représente les personnes.
Scénario 4 : Selon la légende ci-dessus, effectuez une segmentation sémantique sur la deuxième image.
Exemple de code pour l'invocation via API
Si vous choisissez la voie de l'API, voici un exemple minimal d'invocation :
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Effectuez une segmentation sémantique de cette image, donnez la proportion de chaque catégorie et calculez le taux de visibilité verte."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Mode réflexion
)
print(response.choices[0].message.content)
🚀 Rappel pour l'intégration API : Lors de l'invocation de gpt-image-2 via APIYI (apiyi.com), configurez le
base_urlsurhttps://api.apiyi.com/v1. Les autres champs sont strictement identiques à ceux d'OpenAI ; il suffit de modifier une ligne debase_urldans votre code SDK OpenAI existant pour que tout fonctionne.
FAQ sur la segmentation sémantique de paysages urbains avec GPT-image-2
Question 1 : La précision de la segmentation de paysages urbains par GPT-image-2 est-elle vraiment suffisante ?
Cela dépend de votre cas d'usage. Pour des rapports académiques, des évaluations de planification ou des démonstrations pédagogiques, la précision du mode de réflexion (marge d'erreur de ±2 %) est largement suffisante. Pour des mesures industrielles de haute précision (exigence d'erreur < 1 %), nous recommandons toujours d'utiliser des modèles traditionnels combinés à des contrôles humains.
Question 2 : Combien de catégories de paysages urbains GPT-image-2 peut-il identifier ?
En théorie, il n'y a pas de limite stricte au nombre de catégories : c'est votre invite qui définit la classification. Cependant, les tests montrent qu'au-delà de 15 catégories par image, des problèmes de confusion de couleurs et de légende peuvent survenir. Nous recommandons de limiter chaque tâche à 8-12 catégories.
Question 3 : La segmentation de paysages urbains par GPT-image-2 prend-elle en charge la vidéo ?
La version actuelle ne prend pas en charge directement les flux vidéo. Si vous avez besoin d'analyser des vidéos, vous devez extraire les images (par exemple, 1 image/seconde), effectuer l'invocation du modèle image par image, puis réassembler les résultats. Ce flux de travail est coûteux en temps et en ressources, il n'est donc pas recommandé.
Question 4 : Le mode de réflexion prend 10 minutes, est-il possible d'accélérer le processus ?
Le temps de traitement du mode de réflexion provient principalement du processus d'auto-vérification du modèle. Voici quelques méthodes pour accélérer :
- Réduire la résolution : compressez l'image téléchargée en dessous de 1024×768.
- Simplifier la tâche : divisez la segmentation et le calcul de proportion en deux invites distinctes, en ne demandant qu'une seule chose à la fois.
- Utiliser le mode standard : la précision diminue de 1 à 2 %, mais le temps de traitement est réduit à 1/5.
Question 5 : Qui est le plus performant entre GPT-image-2 et Nano Banana Pro pour la segmentation urbaine ?
Leurs positionnements diffèrent légèrement. GPT-image-2 est plus performant en termes de capacité de réflexion et de précision numérique (raisonnement multi-étapes, calcul automatique du GVI) ; Nano Banana Pro excelle en vitesse et en coût (réponse en quelques secondes par image). Si vous avez besoin d'une segmentation rapide en grand volume, envisagez Nano Banana Pro ; si vous avez besoin de rapports d'analyse automatisés, choisissez GPT-image-2.
Question 6 : Y a-t-il une différence entre l'utilisation via APIYI (apiyi.com) et l'API officielle ?
Les champs sont strictement identiques. APIYI est un service proxy API, les champs de requête et de réponse sont synchronisés à 100 % avec OpenAI. La différence réside principalement dans : l'absence de besoin de proxy pour une connexion directe en Chine, un support technique dédié en chinois et une facturation transparente. Nous recommandons aux développeurs de passer par APIYI (apiyi.com) pour accéder à GPT-image-2 afin d'éviter les problèmes de stabilité réseau.
Question 7 : Est-il possible de faire en sorte que GPT-image-2 génère un masque PNG standard ?
La version actuelle ne prend pas en charge la sortie directe de fichiers de masque avec une précision au pixel près. Le modèle génère une "image colorée rendue". Si vous avez besoin d'un masque pour entraîner des modèles en aval, vous devrez effectuer un post-traitement de séparation par seuil de couleur.
Question 8 : La sortie de la segmentation de paysages urbains par GPT-image-2 peut-elle être modifiée ultérieurement ?
Oui, vous pouvez poser des questions supplémentaires basées sur la première sortie. Par exemple : "Ajoute un masque rouge semi-transparent sur toutes les zones de végétation de l'image originale pour servir d'avertissement". Le modèle effectuera un traitement dérivé basé sur le résultat de la segmentation précédente. C'est une capacité que les modèles traditionnels ne possèdent pas.
Points clés de la segmentation de paysages urbains avec GPT-image-2
- Changement de paradigme : GPT-image-2 ne cherche pas à remplacer DeepLabV3+, mais ouvre une nouvelle voie basée sur le langage naturel, sans déploiement et avec des capacités d'analyse dérivée.
- Précision exploitable : En mode réflexion, l'erreur par rapport aux modèles SOTA traditionnels n'est que de ±2 %, ce qui est suffisant pour la plupart des scénarios métier.
- Le temps de traitement est un point faible : Réponse en quelques minutes par image, totalement inadapté aux scénarios en temps réel ou à haut volume.
- La flexibilité des catégories est un atout majeur : Là où les modèles traditionnels sont limités par les "19 catégories de Cityscapes", GPT-image-2 brise ces barrières avec une simple invite.
- Automatisation du GVI (Indice de visibilité verte) : Le calcul du GVI passe d'une journée de travail collaboratif entre ingénieurs et urbanistes à 5 minutes pour un urbaniste seul.
- Solution hybride optimale : Utilisez GPT-image-2 pour l'analyse exploratoire et les modèles traditionnels pour la production industrielle à grande échelle ; les deux sont complémentaires.
- Conseil d'utilisation : Passez par APIYI (apiyi.com) pour une connexion stable et une compatibilité totale avec les champs officiels.
Résumé
La segmentation sémantique de paysages urbains par GPT-image-2 ne remplace pas la segmentation sémantique traditionnelle, elle la complète. Elle répond à des besoins spécifiques : "petits volumes, personnalisation, interaction en langage naturel et génération automatique de conclusions", des aspects totalement ignorés par des modèles comme DeepLabV3+ ou PSPNet.
Du calcul automatique du taux de verdure à la segmentation par catégories personnalisées, GPT-image-2 démocratise un travail qui nécessitait auparavant "un ingénieur en algorithmes, un GPU et des données d'entraînement", le mettant désormais à la portée de quiconque sait utiliser ChatGPT. Pour l'urbanisme, l'architecture paysagère ou la recherche académique, il s'agit d'un véritable changement de paradigme.
Cependant, gardez à l'esprit ses limites : un temps de traitement de l'ordre de la minute par image, des coûts de traitement par lots difficiles à maîtriser et une précision au pixel près inférieure aux modèles SOTA. Ces trois points déterminent qu'il ne remplacera pas les modèles traditionnels, mais coexistera avec eux.
Si vous envisagez d'intégrer GPT-image-2 dans votre flux de travail, nous vous conseillons de commencer par un cas d'usage "simple et efficace" (par exemple, l'analyse du taux de verdure sur 50 photos de rue). Une fois le processus de bout en bout validé, vous pourrez décider de passer à une échelle supérieure.
✨ Dernier conseil : Pour les développeurs et chercheurs, nous recommandons d'accéder à gpt-image-2 via la plateforme APIYI (apiyi.com). Vous bénéficierez d'un accès stable, d'une compatibilité totale avec les champs officiels et d'une facturation transparente au jeton. Pour vos premiers pas, la plateforme propose un quota gratuit pour réaliser votre preuve de concept (PoC), largement suffisant pour tester les 4 scénarios présentés dans cet article.
Auteur : Équipe APIYI
Dernière mise à jour : 02/05/2026