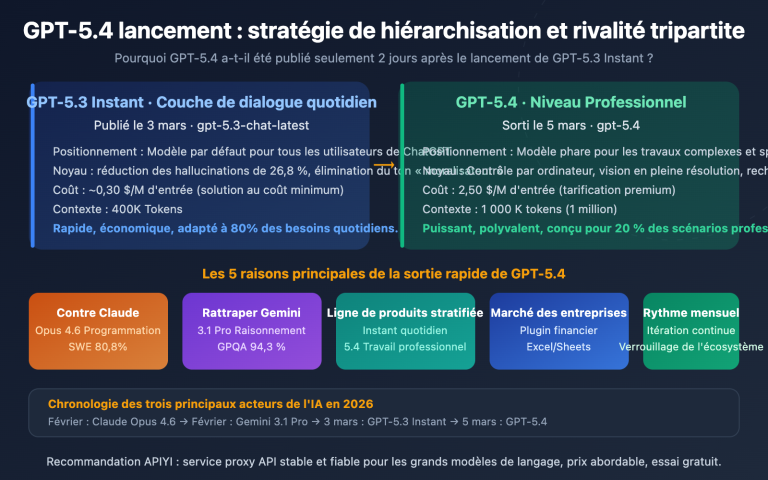
Note de l'auteur : Analyse approfondie des capacités fondamentales, des benchmarks de performance et des méthodes d'intégration API des modèles MiniMax-M2.7 et M2.7-highspeed, pour aider les développeurs à accéder à une puissance d'IA de niveau "flagship" à un coût extrêmement réduit.
MiniMax a lancé le grand modèle de langage phare MiniMax-M2.7 le 18 mars 2026, le premier modèle d'IA à participer activement à son propre processus d'évolution. Avec seulement 10B de paramètres activés, il atteint des performances de niveau Tier-1, comparables à Claude Opus 4.6 et GPT-5, tout en coûtant 50 fois moins cher que les modèles phares actuels. La version MiniMax-M2.7-highspeed, lancée simultanément, augmente la vitesse de sortie de 66 %, atteignant 100 tps.
Valeur ajoutée : Grâce à des données de benchmark réelles et à des tutoriels d'intégration, déterminez si le MiniMax-M2.7 est le modèle phare au meilleur rapport qualité-prix actuellement disponible.

Points clés du MiniMax-M2.7
| Point clé | Description | Valeur |
|---|---|---|
| 230B paramètres totaux / 10B activés | Architecture MoE (Mixture-of-Experts), n'active que 10B paramètres par inférence | Performance phare + coût d'inférence ultra-faible |
| Entraînement par auto-évolution récursive | Le modèle exécute de manière autonome plus de 100 cycles d'itération pour optimiser son propre processus d'entraînement | Amélioration de 30 % des performances sans intervention humaine |
| SWE-bench 78 % | Benchmark d'ingénierie logicielle largement supérieur aux 55 % de l'Opus 4.6 | Premier choix pour la programmation et les tâches d'ingénierie |
| Prix 50 fois inférieur à Opus | 0,30 $/M en entrée, 1,20 $/M tokens en sortie | Réduction drastique des coûts pour les déploiements à grande échelle |
Analyse détaillée de l'architecture technique du MiniMax-M2.7
Le MiniMax-M2.7 utilise une architecture Transformer à mélange d'experts clairsemé (Sparse Mixture-of-Experts), avec un total de 230B de paramètres, mais n'activant que 10B de paramètres par jeton. Cette conception fait du M2.7 le modèle le plus compact de sa catégorie de performance, utilisant un minimum de ressources de calcul pour atteindre un niveau de performance Tier-1 comparable à Claude Opus 4.6 et GPT-5.
La fenêtre de contexte atteint 205K jetons (environ 307 pages de documents A4), prenant en charge l'analyse de longs documents et la compréhension de bases de code volumineuses. Dans l'évaluation de l'Artificial Analysis Intelligence Index, le M2.7 s'est classé premier parmi 136 modèles de même catégorie avec un score parfait de 50/50.
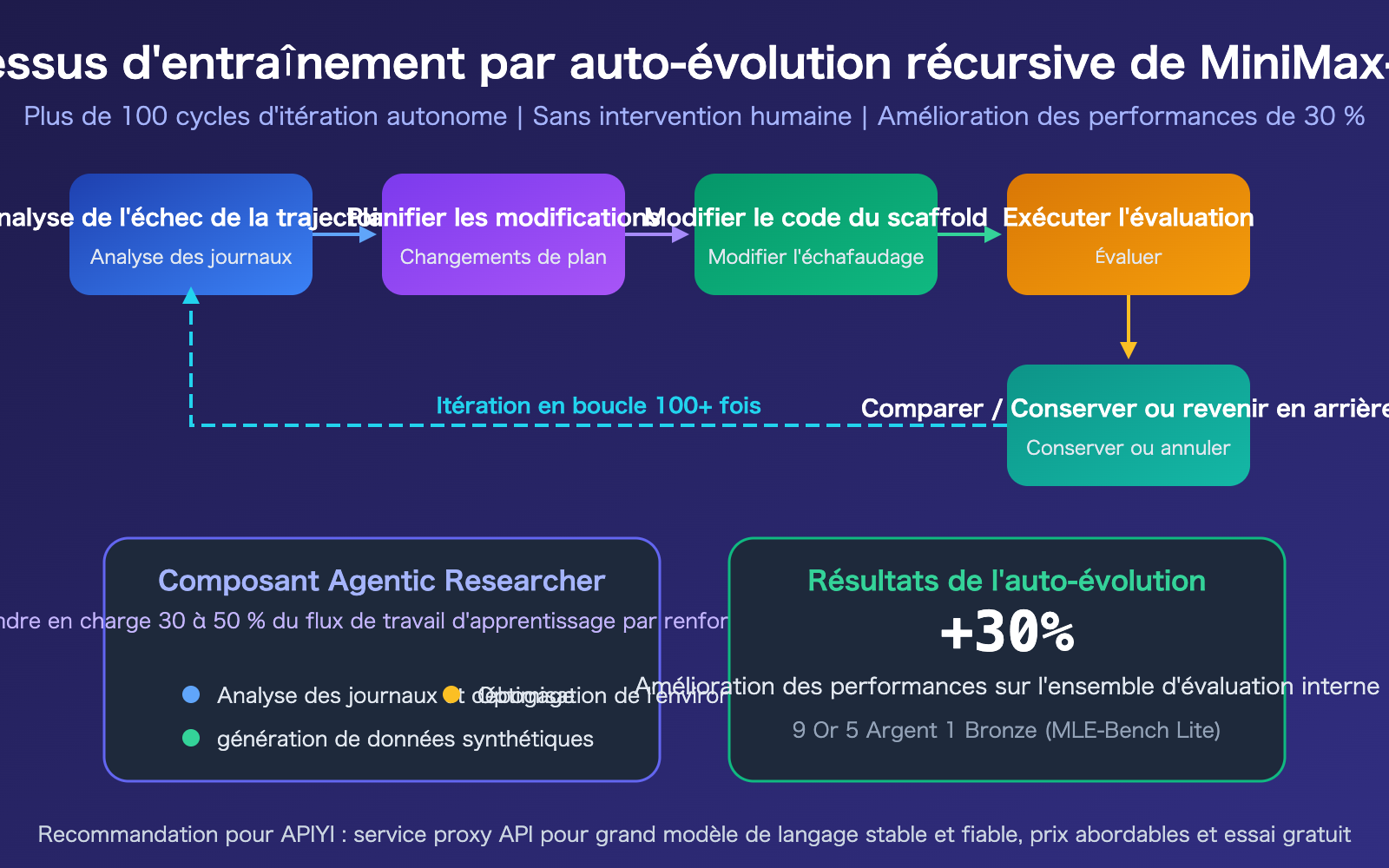
Mécanisme d'auto-évolution récursive du MiniMax-M2.7
L'"auto-évolution récursive" est la caractéristique technique la plus révolutionnaire du M2.7. Au cours de l'entraînement, le modèle exécute de manière autonome un cycle itératif complet : analyse des trajectoires d'échec → planification des modifications → modification du code de l'échafaudage d'entraînement → exécution de l'évaluation → comparaison des résultats → décision de conserver ou d'annuler. Ce processus a été exécuté de manière totalement autonome pendant plus de 100 cycles.
Son composant central, le "Chercheur Agentique" (Agentic Researcher), a pris en charge 30 à 50 % du flux de travail d'apprentissage par renforcement, incluant l'analyse des journaux et le débogage, la génération de données synthétiques et l'optimisation de l'environnement d'entraînement. Cela a permis d'obtenir une amélioration de 30 % des performances sans aucune intervention humaine.
Analyse comparative et benchmarks du MiniMax-M2.7
Résultats des benchmarks du MiniMax-M2.7
| Benchmark | Score M2.7 | Claude Opus 4.6 | Série GPT-5 | Note |
|---|---|---|---|---|
| SWE-bench Verified | 78% | 55% | — | Ingénierie logicielle réelle, avance significative |
| SWE-Pro | 56.2% | ~57% | 56.2% (Codex) | Niveau proche des modèles phares |
| VIBE-Pro | 55.6% | — | — | Livraison de projets de bout en bout |
| Terminal Bench 2 | 57.0% | — | — | Systèmes d'ingénierie complexes |
| MLE-Bench Lite | 66.6% | 75.7% | 71.2% (5.4) | Compétitions ML, 9 or, 5 argent, 1 bronze |
| GDPval-AA ELO | 1495 | — | — | N°1 en productivité bureautique |
Comparaison des prix du MiniMax-M2.7
La stratégie tarifaire du M2.7 est extrêmement agressive : pour des performances quasi équivalentes, le coût est des dizaines de fois inférieur à celui des modèles phares du marché :
| Indicateur | MiniMax-M2.7 | Claude Opus 4.6 | GPT-5 | Différence |
|---|---|---|---|---|
| Prix entrée | 0,30 $/M | 15 $/M | 10 $/M | 50x / 33x moins cher |
| Prix sortie | 1,20 $/M | 75 $/M | 30 $/M | 62x / 25x moins cher |
| Fenêtre de contexte | 205K | 1M | 128K | Entre les deux |
| Paramètres actifs | 10B | — | — | Le plus petit modèle Tier-1 |
🎯 Conseil de choix : Le MiniMax-M2.7 excelle dans les tâches de programmation et d'ingénierie avec un rapport qualité-prix exceptionnel. Nous vous recommandons de tester son intégration via la plateforme APIYI (apiyi.com), qui prend en charge une interface unifiée pour le MiniMax-M2.7 et le M2.7-highspeed, facilitant ainsi les comparaisons réelles avec d'autres modèles phares.
Présentation détaillée du MiniMax-M2.7-highspeed
Le MiniMax-M2.7-highspeed est une version optimisée de la gamme phare M2.7. Il produit exactement les mêmes résultats que la version standard — le niveau d'intelligence est identique, mais la version highspeed est spécifiquement conçue pour les applications sensibles à la latence.
Avantages clés du MiniMax-M2.7-highspeed
- Vitesse de sortie : Jusqu'à 100 tokens/s, soit une amélioration de 66 % par rapport à la version standard.
- Latence sub-seconde : Temps de réponse optimisé pour le premier token, idéal pour les interactions en temps réel.
- Architecture d'inférence renforcée : Moteur d'inférence sous-jacent optimisé, il ne s'agit pas d'une simple dégradation par quantification.
- Cohérence des résultats : Sorties strictement identiques à la version standard, sans compromis sur l'intelligence.
Scénarios d'utilisation du MiniMax-M2.7-highspeed
| Scénario | Description | Pourquoi choisir highspeed |
|---|---|---|
| Assistant de programmation interactif | Complétion et refactorisation de code en temps réel dans l'IDE | Réponse sub-seconde pour une meilleure expérience de codage |
| Boucles d'agents en temps réel | Inférence multi-étapes dans une boucle d'Agent | Réduit l'attente à chaque étape, accélère le processus global |
| Pipelines d'entreprise à haut débit | Traitement de documents par lots, extraction de données | 100 tps réduisant considérablement le temps de traitement |
| Systèmes de service client en ligne | Dialogue et réponse aux questions en temps réel | Réponse rapide imperceptible pour l'utilisateur |
Conseil : Si votre application exige une réactivité stricte, le MiniMax-M2.7-highspeed est l'un des choix les plus rapides parmi les modèles de niveau phare actuels. Vous pouvez appeler ce modèle directement via APIYI (apiyi.com).
Démarrage rapide avec l'API MiniMax-M2.7
Exemple minimaliste
Voici le code le plus simple pour invoquer le modèle MiniMax-M2.7 via la plateforme APIYI. Il suffit de 10 lignes pour le faire fonctionner :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "Analyse les goulots d'étranglement de performance de ce code et propose des optimisations"}]
)
print(response.choices[0].message.content)
Voir le code d’implémentation complet (incluant le basculement vers la version highspeed)
import openai
from typing import Optional
def call_minimax_m27(
prompt: str,
model: str = "MiniMax-M2.7",
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
use_highspeed: bool = False
) -> str:
"""
Appel de MiniMax-M2.7 ou M2.7-highspeed
Args:
prompt: Entrée utilisateur
model: Nom du modèle
system_prompt: Invite système
max_tokens: Nombre maximal de jetons en sortie
use_highspeed: Utiliser la version highspeed ou non
"""
if use_highspeed:
model = "MiniMax-M2.7-highspeed"
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
# Appel de la version standard
result = call_minimax_m27(
prompt="Implémente un cache LRU efficace en Python",
system_prompt="Tu es un ingénieur Python expérimenté"
)
# Appel de la version highspeed (adapté aux scénarios temps réel)
fast_result = call_minimax_m27(
prompt="Explique rapidement le rôle de ce code",
use_highspeed=True
)
Conseil : Obtenez un crédit de test gratuit via la plateforme APIYI (apiyi.com) pour vérifier rapidement les performances de MiniMax-M2.7 dans vos cas d'usage. La plateforme permet de basculer instantanément entre la version standard et la version highspeed.
Comparaison de MiniMax-M2.7 avec les modèles concurrents

| Solution | Caractéristiques clés | Cas d'usage | Rapport qualité-prix |
|---|---|---|---|
| MiniMax-M2.7 | 10B paramètres actifs, SWE-bench 78% | Programmation, flux de travail Agent, déploiement massif | Très élevé ($0.30/$1.20) |
| M2.7-highspeed | 100 tps, 66% d'accélération | Interaction en temps réel, intégration IDE, boucle Agent | Très élevé + rapide |
| Claude Opus 4.6 | 1M fenêtre de contexte, capacités globales supérieures | Documents longs, raisonnement complexe, tâches polyvalentes | Moyen ($15/$75) |
| GPT-5 | Écosystème mature, support multimodal | Scénarios généraux, applications multimodales | Moyen ($10/$30) |
Note sur la comparaison : Les données ci-dessus proviennent des benchmarks officiels et des évaluations tierces d'Artificial Analysis. Vous pouvez effectuer une comparaison réelle via la plateforme APIYI (apiyi.com).
FAQ
Q1 : Y a-t-il une différence entre les résultats de MiniMax-M2.7 et M2.7-highspeed ?
Les résultats sont strictement identiques. La version highspeed optimise le moteur d'inférence pour atteindre une vitesse de génération de jetons plus rapide (100 tps), sans pour autant altérer l'intelligence ou la qualité de sortie du modèle. Si votre cas d'usage n'est pas sensible à la latence, la version standard suffit amplement.
Q2 : L’« auto-évolution récursive » de MiniMax-M2.7 signifie-t-elle que le modèle change en permanence ?
Non. L'auto-évolution récursive est une technique utilisée par MiniMax lors de la phase d'entraînement : le modèle a optimisé de manière autonome son propre processus d'entraînement et ses paramètres. Une fois publié, les poids du modèle sont figés. Les appels à l'API vous garantissent donc des résultats stables et cohérents.
Q3 : Comment commencer rapidement à tester MiniMax-M2.7 ?
Nous vous recommandons d'utiliser une plateforme d'agrégation d'API prenant en charge plusieurs modèles pour vos tests :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte.
- Obtenez votre clé API et profitez du crédit gratuit.
- Utilisez les exemples de code fournis dans cet article pour une vérification rapide.
- Modifiez simplement le paramètre
modelpour basculer entre la version standard et la version highspeed.
Conclusion
Les points clés à retenir pour l'invocation du modèle MiniMax-M2.7 :
- Rapport qualité-prix exceptionnel : Avec 10B de paramètres actifs atteignant des performances de niveau Tier-1 pour un coût 50 fois inférieur à celui d'Opus, c'est le choix idéal pour les déploiements à grande échelle.
- Capacités de programmation remarquables : Avec un score de 78 % sur SWE-bench Verified, il devance largement ses concurrents, offrant des performances excellentes pour les tâches d'ingénierie logicielle.
- Version highspeed : Sa vitesse de 100 tps est parfaitement adaptée aux interactions en temps réel et aux boucles d'agents, tout en conservant le même niveau d'intelligence que la version standard.
Pour les développeurs et les entreprises en quête de rentabilité, MiniMax-M2.7 est l'un des modèles phares les plus intéressants du marché actuel.
Nous vous recommandons de tester ses capacités via APIYI (apiyi.com), qui propose des crédits gratuits, une interface unifiée pour de nombreux modèles et permet de basculer instantanément entre les versions standard et highspeed de MiniMax-M2.7.
📚 Références
-
Publication officielle de MiniMax M2.7 : Détails sur l'architecture du modèle et la technologie d'auto-évolution
- Lien :
minimax.io/news/minimax-m27-en - Description : Blog technique officiel, incluant les benchmarks et les détails architecturaux
- Lien :
-
Page du modèle MiniMax M2.7 : Spécifications techniques et documentation API
- Lien :
minimax.io/models/text/m27 - Description : Paramètres du modèle, tarification et méthodes d'accès
- Lien :
-
Évaluation par Artificial Analysis : Évaluation indépendante des performances par un tiers
- Lien :
artificialanalysis.ai/models/minimax-m2-7 - Description : Données d'évaluation indépendantes sur la vitesse et l'indice d'intelligence
- Lien :
-
Documentation de la plateforme APIYI : Accès rapide à MiniMax-M2.7
- Lien :
docs.apiyi.com - Description : Obtention de la clé API, liste des modèles et exemples d'invocation du modèle
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans la section des commentaires. Pour plus de ressources, consultez la documentation d'APIYI sur docs.apiyi.com.