Note de l'auteur : Explication détaillée des raisons pour lesquelles les Tokens de sortie de Gemini 3.1 Pro Preview dépassent largement le texte visible : le mécanisme de chaîne de raisonnement Thinking Tokens, les règles de facturation, et les astuces pour économiser de l'argent en ajustant le paramètre thinking_level.
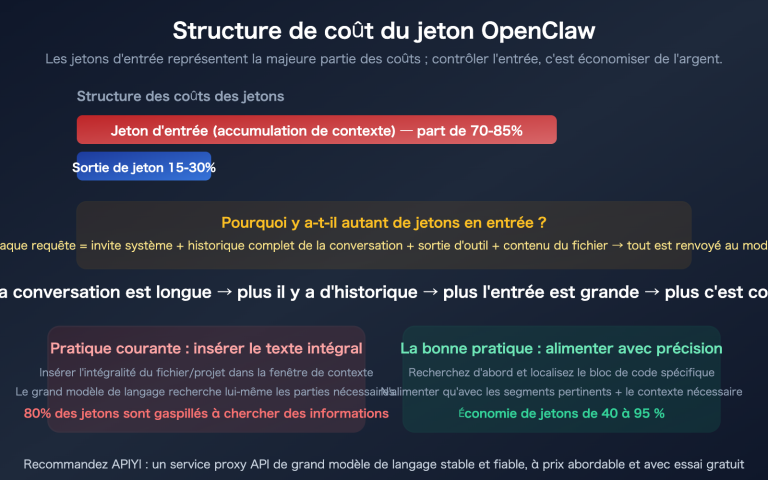
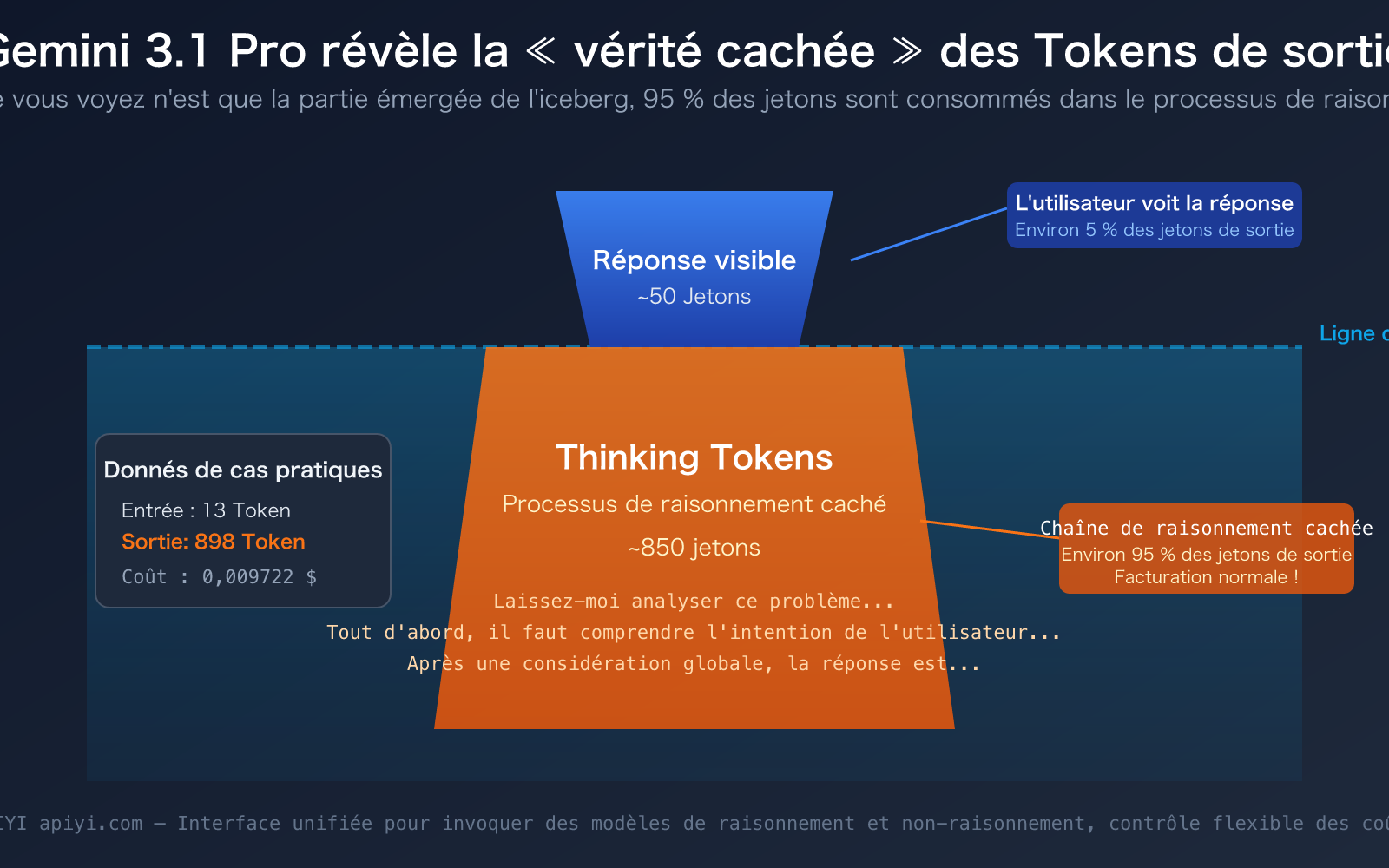
« J'ai juste envoyé une phrase, le modèle n'a répondu qu'avec une dizaine de mots, alors pourquoi les Tokens de sortie affichent près de 900 ? Où est passé l'argent ? » — C'est la véritable perplexité de nombreux développeurs lors de leur première utilisation de Gemini 3.1 Pro Preview. Les données de la capture d'écran illustrent clairement ce phénomène : 13 Tokens en entrée, mais jusqu'à 898 Tokens en sortie.
La réponse réside dans les Thinking Tokens (Tokens de raisonnement). Gemini 3.1 Pro est un modèle de raisonnement. Avant de vous donner une réponse, il effectue un long processus de réflexion et de raisonnement « dans sa tête ». Ce contenu de raisonnement n'est pas affiché par défaut, mais il est comptabilisé dans les Tokens de sortie et facturé normalement.
Valeur clé : Après avoir lu cet article, vous comprendrez parfaitement le mécanisme des Thinking Tokens des modèles de raisonnement, apprendrez à utiliser le paramètre thinking_level pour contrôler la profondeur du raisonnement, et pourrez réduire vos coûts en Tokens de sortie de 50 à 80 % tout en garantissant la qualité.
Points clés des Thinking Tokens de Gemini 3.1 Pro
La plus grande différence entre un modèle de raisonnement et un modèle de dialogue ordinaire réside dans la composition complètement différente des Tokens de sortie. Voici les concepts clés que vous devez comprendre :
| Point | Explication | Impact pratique |
|---|---|---|
| Token de sortie = Réflexion + Réponse | Les Tokens de sortie de Gemini 3.1 Pro comprennent deux parties : les Thinking Tokens (chaîne de raisonnement) et la réponse réelle. | Le texte visible est court, mais le nombre total de Tokens est élevé. |
| Les Thinking Tokens sont facturés normalement | Le processus de raisonnement, bien qu'invisible, est facturé au prix des Tokens de sortie (12 $/million de Tokens). | Une question simple peut coûter 5 à 10 fois plus cher qu'avec un modèle ordinaire. |
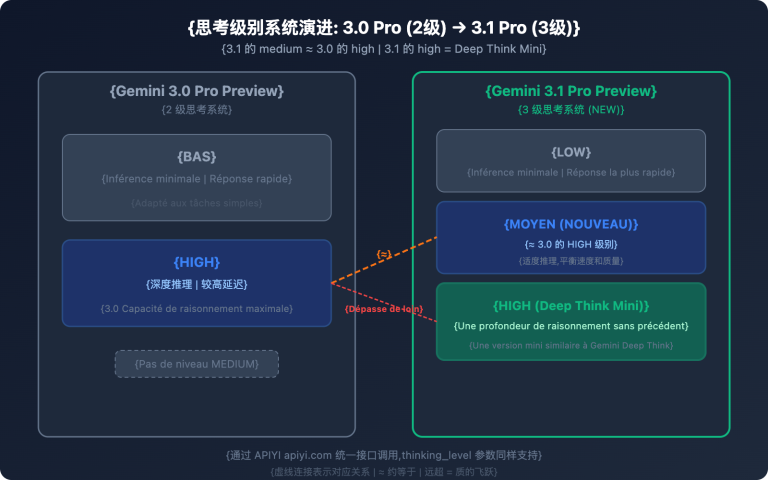
thinking_level est ajustable |
Prend en charge trois niveaux de contrôle de la profondeur du raisonnement : LOW/MEDIUM/HIGH. | Le niveau LOW peut économiser plus de 80 % des Tokens de sortie. |
| Les modèles non raisonnés n'ont pas ce problème | Les modèles comme GPT-4o, Claude Sonnet 4.6 (avec Extended Thinking désactivé) sont du type "ce que vous voyez est ce que vous obtenez". | Pour les tâches simples, utiliser un modèle non raisonné est plus économique. |
Cas réel de consommation des Thinking Tokens de Gemini 3.1 Pro
Revenons à l'exemple de la capture d'écran. L'utilisateur a posé une question simple, le modèle a répondu avec environ une dizaine de mots, mais les Tokens de sortie affichaient 891-898. La composition de ces Tokens est approximativement la suivante :
- Réponse visible : environ 30-50 Tokens (la dizaine de mots que vous voyez)
- Thinking Tokens : environ 840-860 Tokens (le processus de raisonnement interne du modèle)
En d'autres termes, plus de 95 % des Tokens de sortie sont invisibles pour vous, consommés dans la chaîne de raisonnement du modèle. C'est comme si vous demandiez à un professeur de mathématiques « combien font 1+1 ? », que le professeur ne dit à voix haute que « égal à 2 », mais qu'en réalité, il pense dans sa tête : « C'est un problème d'arithmétique de base, nécessitant une opération d'addition… » — et que vous payez pour l'ensemble du processus de réflexion du professeur.
Ce mécanisme n'est pas un bug, c'est une caractéristique de conception des modèles de raisonnement. La raison pour laquelle Gemini 3.1 Pro performe mieux sur des problèmes complexes (95,1 % sur le benchmark MATH, 77,1 % sur ARC-AGI-2) est précisément qu'il effectue un raisonnement approfondi avant de répondre.

Mécanisme de fonctionnement des Thinking Tokens du modèle de raisonnement Gemini 3.1 Pro
Différence fondamentale entre un modèle de raisonnement et un modèle standard
Un modèle standard (comme GPT-4o) génère directement une réponse après avoir reçu votre question. Vous voyez combien de mots, vous consommez autant de Tokens de sortie. C'est le principe du « ce que vous voyez est ce que vous payez ».
Un modèle de raisonnement (comme Gemini 3.1 Pro Preview), après avoir reçu la question, génère d'abord une chaîne de raisonnement interne (Chain of Thought), puis produit la réponse finale basée sur ce raisonnement. Vous ne voyez que la réponse finale, mais la facturation inclut le nombre total de Tokens pour « la chaîne de raisonnement + la réponse ».
| Type de modèle | Modèle représentatif | Composition des Tokens de sortie | Coût pour une question simple | Avantage pour les questions complexes |
|---|---|---|---|---|
| Modèle standard | GPT-4o, Claude Sonnet 4.6 | 100% réponse visible | Faible (ce que vous voyez est ce que vous payez) | Capacité de raisonnement générale |
| Modèle de raisonnement | Gemini 3.1 Pro, GPT-5.4 Thinking | Chaîne de raisonnement + réponse visible | Élevé (5 à 10 fois plus ou plus) | Forte capacité de raisonnement complexe |
| Modèle à bascule | Claude Sonnet 4.6 (Extended Thinking) | Possibilité d'activer ou non le raisonnement | Bascule flexible | Active le raisonnement selon les besoins |
3 détails clés sur les Thinking Tokens de Gemini 3.1 Pro
Détail 1 : Mode de facturation des Thinking Tokens. Selon la documentation officielle de Google, les Thinking Tokens sont facturés au tarif standard des Tokens de sortie. Le prix des Tokens de sortie pour Gemini 3.1 Pro est de 12 $ par million de Tokens. Lorsque le modèle utilise 4000 Tokens pour raisonner et 500 Tokens pour répondre, vous payez pour 4500 Tokens de sortie – et non pour 500.
Détail 2 : Comment les distinguer dans la réponse de l'API. Dans la réponse de l'API Gemini, le champ usage_metadata renverra séparément thoughts_token_count (nombre de Tokens de raisonnement) et candidates_token_count (nombre total de Tokens de sortie). Mais attention : le candidatesTokenCount de l'API Gemini inclut déjà les Thinking Tokens, tandis que celui de Vertex AI ne les inclut pas.
Détail 3 : Le contenu de la chaîne de raisonnement est invisible par défaut. Vous pouvez obtenir un résumé du processus de raisonnement (pas la chaîne complète) en définissant includeThoughts: true. Vous pouvez également activer l'affichage de la chaîne de raisonnement dans des outils comme Cherry Studio pour voir le processus de réflexion du modèle.
🎯 Conseil pour économiser : Si vous avez simplement besoin de dialogue ou de traduction, sans raisonnement approfondi, il est recommandé de basculer vers un modèle standard (comme GPT-4o-mini ou Claude Sonnet 4.6). APIYI apiyi.com permet de changer de modèle en modifiant simplement un paramètre
model, sans avoir à modifier le reste du code.
Optimisation des Thinking Tokens de Gemini 3.1 Pro : 3 stratégies pour économiser
Stratégie 1 : Utiliser le paramètre thinking_level pour contrôler la profondeur du raisonnement
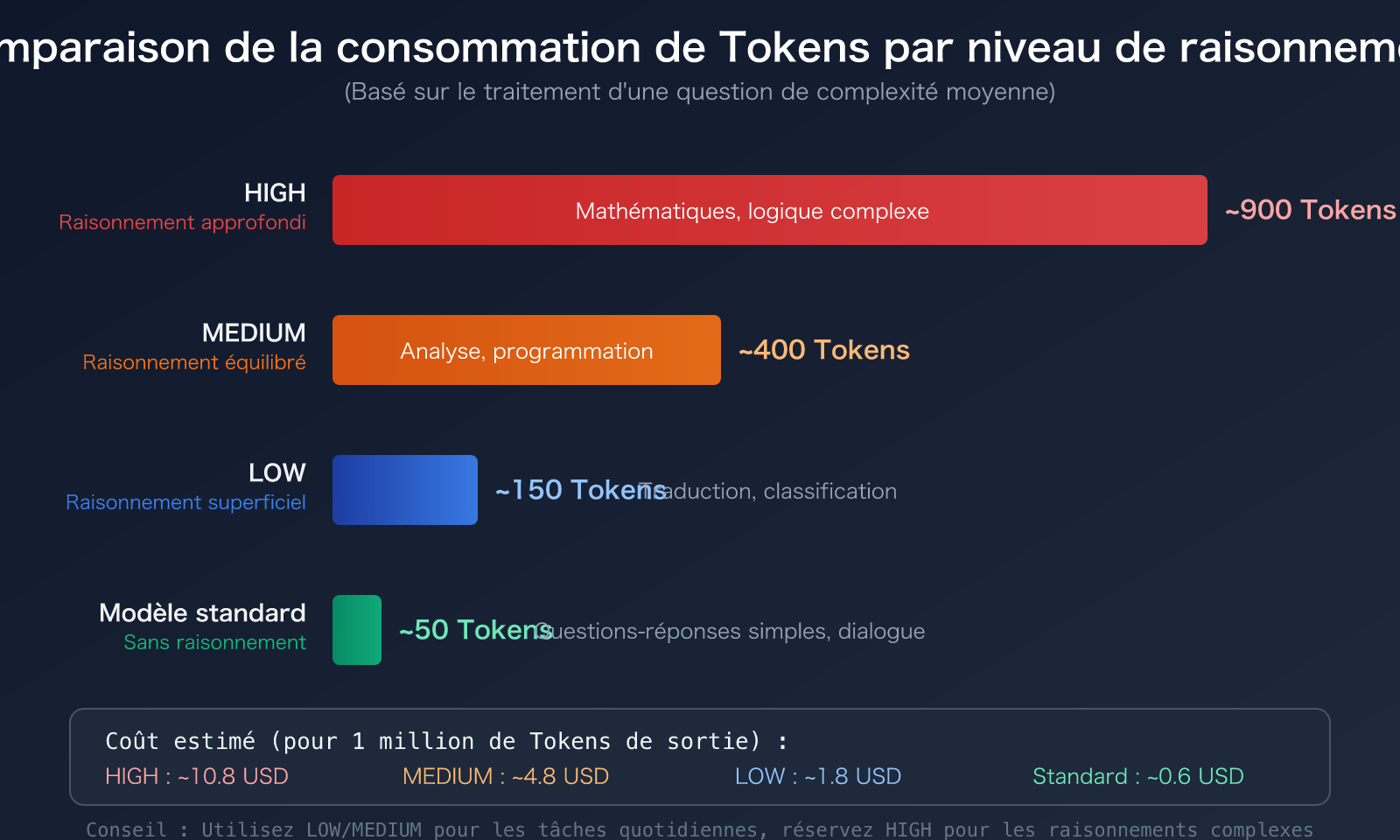
Gemini 3.1 Pro propose le paramètre thinking_level, qui supporte trois niveaux : LOW, MEDIUM, HIGH. La consommation de Tokens varie énormément selon le niveau :
| thinking_level | Profondeur de raisonnement | Consommation de Tokens | Scénario d'utilisation | Comparaison avec HIGH |
|---|---|---|---|---|
| LOW | Raisonnement superficiel | La plus faible | Traduction, classification, questions-réponses simples | Économie d'environ 80%+ |
| MEDIUM | Raisonnement équilibré | Moyenne | Programmation quotidienne, génération de documents, analyse générale | Économie d'environ 50% |
| HIGH | Raisonnement approfondi | La plus élevée | Dérivation mathématique, problèmes scientifiques, logique complexe | Ligne de base |
Voici un exemple de code pour définir thinking_level :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Utiliser LOW pour les tâches simples, réduit considérablement les Thinking Tokens
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Voir le code complet de routage intelligent (choisit automatiquement la profondeur de raisonnement selon la complexité)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Appel intelligent à Gemini 3.1 Pro, choisit automatiquement la profondeur de raisonnement selon la complexité de la tâche
Args:
prompt: Entrée utilisateur
complexity: "low" / "medium" / "high" / "auto"
api_key: Clé API
Returns:
Dictionnaire contenant la réponse et les statistiques d'utilisation des Tokens
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Détermination automatique de la complexité
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Exemple d'utilisation
# Tâche simple → choix automatique de LOW
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Tâche complexe → choix automatique de HIGH
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Conseil : Lors de l'appel à Gemini 3.1 Pro via APIYI apiyi.com, le paramètre
thinking_levelest supporté. Il est recommandé de le définir sur MEDIUM pour un usage quotidien, et de n'utiliser HIGH que pour les scénarios de raisonnement complexes comme les mathématiques ou les sciences.
Stratégie 2 : Utiliser directement un modèle non raisonné pour les tâches simples
Tous les scénarios ne nécessitent pas un modèle de raisonnement. Pour des tâches comme la traduction, la conversion de format, ou les questions-réponses simples, utiliser un modèle non raisonné peut réduire la consommation de Tokens de 5 à 10 fois :
- GPT-4o-mini : Rapport qualité-prix excellent, premier choix pour le dialogue quotidien
- Claude Sonnet 4.6 (avec Extended Thinking désactivé) : Qualité de sortie élevée, Tokens facturés à l'identique
- Gemini 3.1 Flash : Modèle léger de Google, rapide et peu coûteux
Stratégie 3 : Définir max_tokens pour limiter la sortie
Ajouter le paramètre max_tokens à l'appel API peut empêcher le modèle de raisonnement de « trop réfléchir ». Mais attention : max_tokens limite la sortie totale (raisonnement + réponse). Une valeur trop basse peut entraîner une réponse tronquée. Il est recommandé de la définir à 2-3 fois la longueur de réponse attendue.
🎯 Conseil global : Sur la plateforme APIYI apiyi.com, vous pouvez utiliser une interface unifiée pour accéder simultanément aux modèles de raisonnement et aux modèles standards, en basculant dynamiquement selon le type de tâche. Une seule clé API suffit pour appeler toute la gamme des modèles Gemini, Claude et GPT.
Questions fréquentes
Q1 : Pourquoi le processus de raisonnement des Thinking Tokens de Gemini 3.1 Pro n’est-il pas affiché par défaut ?
C'est un choix de conception de Google. La chaîne de raisonnement complète peut contenir des milliers de tokens de déductions intermédiaires. Les afficher directement impacterait fortement l'expérience utilisateur. Vous pouvez obtenir un résumé du raisonnement en définissant le paramètre includeThoughts: true, ou activer l'affichage de la chaîne de raisonnement dans des clients comme Cherry Studio pour voir le processus de réflexion.
Q2 : Comment voir la consommation détaillée des Thinking Tokens dans la réponse de l’API ?
Consultez le champ thoughts_token_count dans les métadonnées d'utilisation (usage_metadata) renvoyées par l'API Gemini. Si vous effectuez l'appel via APIYI (apiyi.com), vous pouvez consulter la décomposition détaillée des tokens (entrée/sortie/raisonnement) pour chaque appel sur la page des statistiques d'utilisation de la plateforme, ce qui facilite le suivi et l'optimisation des coûts.
Q3 : Quels autres modèles ont un mécanisme similaire aux Thinking Tokens, en dehors de Gemini 3.1 Pro ?
Les principaux modèles de raisonnement ont des mécanismes similaires :
- GPT-5.4 Thinking : Le modèle de raisonnement d'OpenAI, où les tokens de raisonnement sont également facturés comme tokens de sortie.
- Claude Sonnet 4.6 Extended Thinking : Le mode de raisonnement d'Anthropic, qui peut être activé de manière sélective.
- DeepSeek-R1 : Un modèle de raisonnement open source, où la chaîne de raisonnement est entièrement visible.
La différence clé réside dans le fait que certains modèles (comme Claude) permettent d'activer ou de désactiver le mode de raisonnement, tandis que d'autres (comme Gemini 3.1 Pro) l'activent par défaut. Via APIYI (apiyi.com), vous pouvez utiliser une interface unifiée pour tester et comparer la consommation réelle de tokens de ces modèles.
Conclusion
Les points essentiels concernant les Thinking Tokens de Gemini 3.1 Pro :
- Les tokens de sortie incluent une chaîne de raisonnement cachée : Vous ne voyez que la partie réponse, mais plus de 95 % de la consommation de tokens de sortie se fait dans les Thinking Tokens invisibles.
- Les Thinking Tokens sont facturés normalement : Ils sont facturés au tarif standard des tokens de sortie. Le coût pour une question simple peut être 5 à 10 fois supérieur à celui des modèles non raisonneurs.
- Utilisez le paramètre
thinking_levelpour économiser : Le niveauLOWpeut réduire les tokens de plus de 80 %,MEDIUMconvient à un usage quotidien, et réservezHIGHuniquement pour les tâches complexes. - Choisissez un modèle non raisonneur pour les tâches simples : Pour la traduction, la classification, les questions-réponses simples, etc., il est plus économique d'utiliser directement GPT-4o-mini ou Claude Sonnet 4.6.
Comprendre le mécanisme des Thinking Tokens vous permet d'allouer votre budget de raisonnement de manière rationnelle. Nous recommandons de gérer les appels multi-modèles via l'interface unifiée d'APIYI (apiyi.com), en choisissant dynamiquement un modèle raisonneur ou non raisonneur en fonction de la complexité de la tâche, pour atteindre le meilleur équilibre qualité/coût.
📚 Références
-
Documentation Google Cloud – Mode Thinking (raisonnement) : Documentation technique officielle des modèles de raisonnement Gemini
- Lien :
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Description : Source faisant autorité sur les règles de facturation des Thinking Tokens et la configuration du paramètre
thinking_level
- Lien :
-
Documentation Google AI pour développeurs – Comptage des Tokens : Explication officielle du comptage des tokens et du champ
usage_metadata- Lien :
ai.google.dev/gemini-api/docs/tokens - Description : Comment distinguer
thoughts_token_countetcandidates_token_countdans la réponse de l'API
- Lien :
-
Google DeepMind – Fiche technique du modèle Gemini 3.1 Pro : Détails sur les capacités du modèle et les tests de référence en raisonnement
- Lien :
deepmind.google/models/model-cards/gemini-3-1-pro/ - Description : Source officielle des données de performance comme MATH 95,1 % et ARC-AGI-2 77,1 %
- Lien :
-
OpenRouter – Meilleures pratiques pour les Tokens de raisonnement : Meilleures pratiques communautaires pour la gestion des tokens dans les modèles de raisonnement
- Lien :
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Description : Comparaison des règles de facturation des tokens de raisonnement entre modèles et conseils d'optimisation
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager vos expériences d'optimisation des tokens pour les modèles de raisonnement dans les commentaires. Pour plus de tutoriels sur l'invocation des modèles, visitez le centre de documentation APIYI docs.apiyi.com.