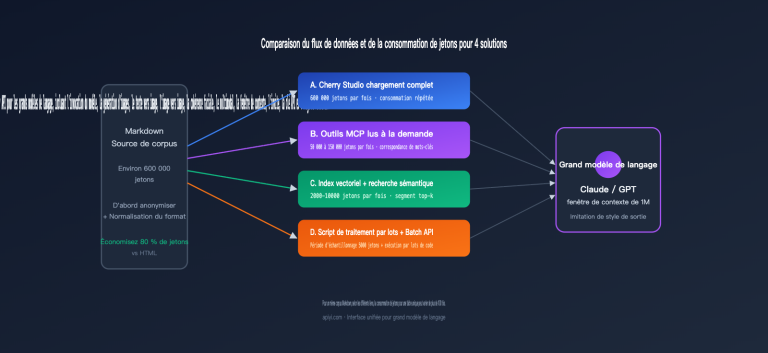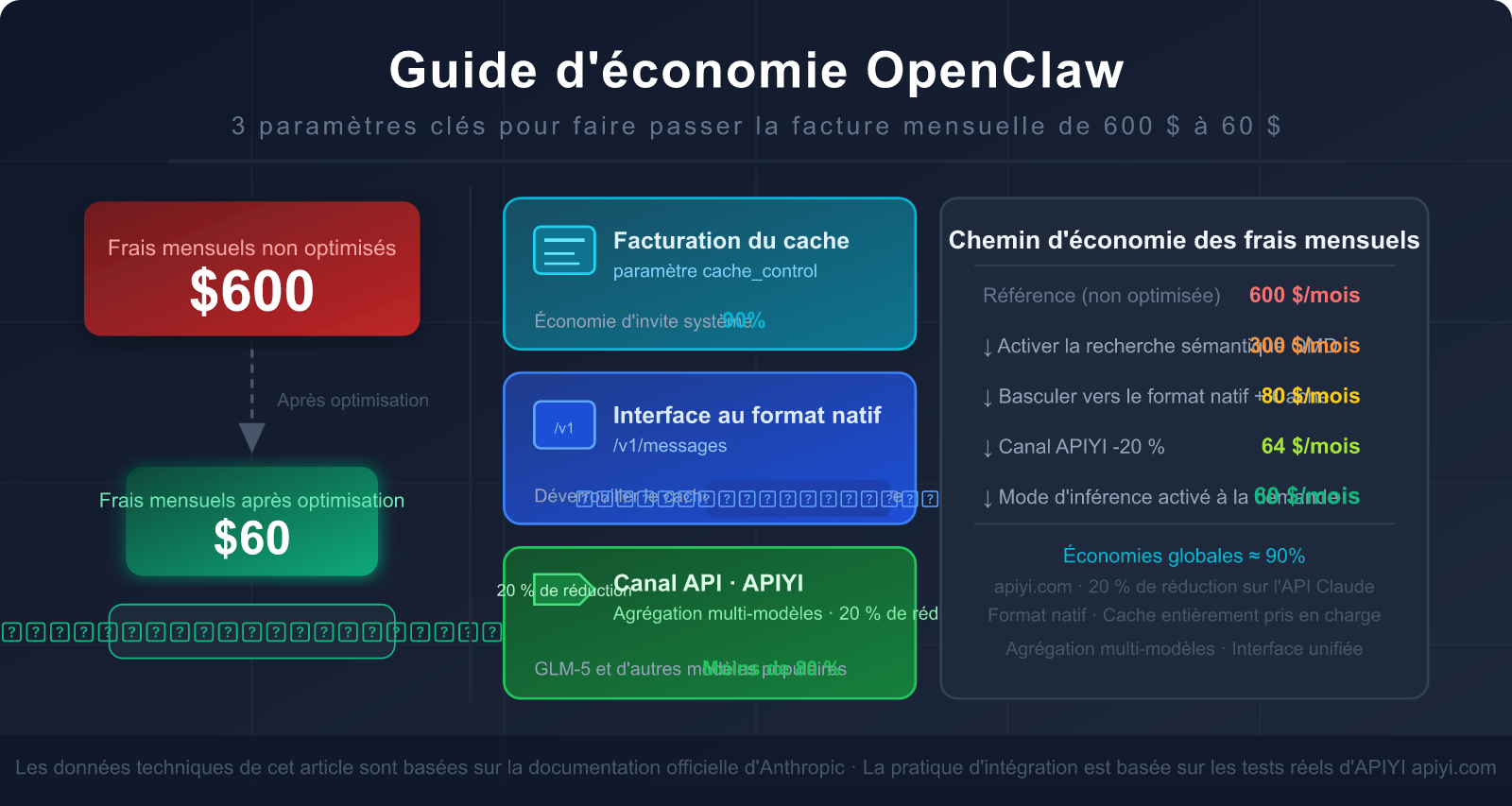
Vous utilisez OpenClaw pour vos flux de travail quotidiens, mais vous avez un petit pincement au cœur en voyant la facture API chaque mois — 300 $, 500 $, voire plus de 600 $ ?
Ce n'est pas de votre faute, c'est dû à la conception même de l'architecture d'OpenClaw. Une instance OpenClaw non optimisée envoie une quantité massive de « contenu inutile » au modèle AI lors de chaque tâche, consommant des tokens pour rien.
La bonne nouvelle : quelques réglages clés peuvent réduire votre facture de 80 à 90 %, et la plupart des gens ignorent l'astuce la plus efficace — utiliser l'interface au format natif Claude plutôt que le mode de compatibilité OpenAI.
Cet article analyse en profondeur la cause fondamentale de la consommation élevée de tokens sur OpenClaw et vous guide pas à pas pour utiliser les bonnes interfaces, configurer le cache et choisir les bons canaux API (comme APIYI) afin de faire passer votre facture mensuelle de 600 $ à 60 $.
I. Pourquoi OpenClaw est-il si gourmand en tokens : 3 raisons clés
Raison 1 : Renvoyer tout l'historique de la conversation à chaque requête
C'est la raison la plus souvent ignorée, mais celle qui a le plus d'impact.
OpenClaw est conçu selon le principe du "contexte complet" : chaque fois qu'une requête est envoyée au modèle d'IA, tous les messages historiques depuis le début de la conversation sont renvoyés. C'est ainsi que le modèle peut "se souvenir" de ce qui a été fait et dit précédemment.
Par exemple :
Tour 1 : l'utilisateur envoie 50 tokens, l'IA répond 200 tokens → 250 tokens envoyés
Tour 2 : l'utilisateur envoie 50 tokens, l'IA répond 200 tokens → 500 tokens envoyés (inclut le tour 1)
Tour 3 : l'utilisateur envoie 50 tokens, l'IA répond 200 tokens → 750 tokens envoyés (inclut les tours 1+2)
...
Tour 10 : seulement 250 nouveaux tokens sont réellement ajoutés, mais le volume envoyé est déjà de 2 500 tokens
Dans un flux de travail OpenClaw traitant des tâches complexes, cet "effet boule de neige" fait grimper la consommation de tokens de manière exponentielle. L'historique du contexte représente généralement 40 à 50 % de la consommation totale de tokens.
Raison 2 : L'invite système est renvoyée à chaque fois
L'invite système (System Prompt) d'OpenClaw définit l'identité de l'agent, ses limites de capacités, la liste des outils disponibles, les règles de comportement, etc. Elle contient généralement entre 5 000 et 10 000 tokens.
Le problème majeur : cet énorme System Prompt est renvoyé intégralement à chaque appel d'API.
Supposons que vous utilisiez OpenClaw pour traiter 50 tâches par jour, avec un System Prompt de 8 000 tokens à chaque fois :
Consommation quotidienne du System Prompt = 50 × 8 000 = 400 000 tokens
Consommation mensuelle ≈ 12 000 000 tokens (uniquement pour le System Prompt !)
Au prix d'entrée de Claude Sonnet 3.5 (environ 3 $/million de tokens), le System Prompt seul vous coûterait 36 $ par mois. Et cela ne comprend même pas le contenu de la conversation ni la sortie.
Raison 3 : Le mode raisonnement fait exploser les tokens de 10 à 50 fois
Lorsqu'OpenClaw rencontre une tâche complexe, il active la "chaîne de pensée" ou le "mode raisonnement" (Thinking/Reasoning). Ce mode permet à l'IA de "réfléchir avant de répondre", ce qui améliore la qualité de la sortie — mais au prix d'une explosion de la consommation de tokens.
Caractéristiques de la consommation des tokens de raisonnement :
- Le processus de réflexion génère une grande quantité de tokens intermédiaires (souvent invisibles, mais facturés).
- Le processus de raisonnement pour une tâche complexe peut générer entre 10 000 et 50 000 tokens.
- Sans contrôle, quelques tâches complexes peuvent épuiser votre budget quotidien.
| Scénario de consommation | Mode normal | Mode raisonnement | Écart (multiplicateur) |
|---|---|---|---|
| Tâche simple de Q&A | ~500 tokens | ~2 000 tokens | 4x |
| Flux de traitement d'e-mails | ~2 000 tokens | ~15 000 tokens | 7,5x |
| Tâche d'analyse de code | ~5 000 tokens | ~80 000 tokens | 16x |
| Recherche complexe en plusieurs étapes | ~10 000 tokens | ~200 000 tokens | 20x+ |
🎯 Diagnostic rapide : Si votre facture OpenClaw est anormalement élevée, vérifiez d'abord l'utilisation du mode raisonnement dans vos journaux de tokens.
Désactiver le mode raisonnement pour les tâches non essentielles est l'un des moyens les plus immédiats pour économiser.
Passer à un modèle plus adapté peut également réduire considérablement les coûts — via APIYI (apiyi.com), vous pouvez rapidement basculer entre différents modèles pour faire des tests.
Répartition de la consommation des trois causes principales
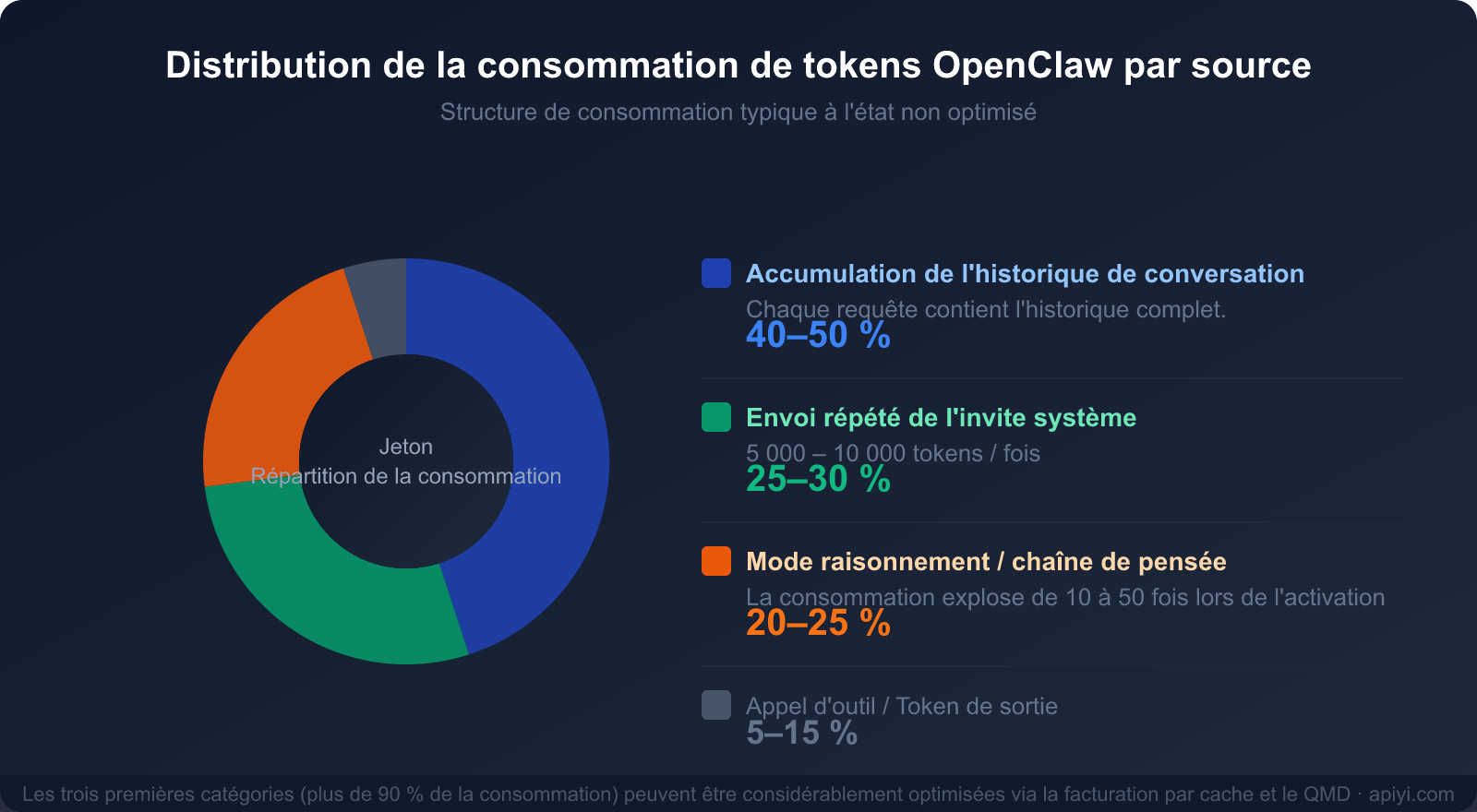
Comprendre ces trois sources de consommation est le préalable indispensable à l'élaboration d'une stratégie d'économie :
| Source de consommation | Part de la consommation totale | Optimisable ? | Principaux moyens d'optimisation |
|---|---|---|---|
| Historique de conversation (accumulation du contexte) | 40-50 % | ✅ Hautement optimisable | Mise en cache, nettoyage périodique, QMD |
| Envoi redondant de l'invite système | 25-30 % | ✅ Hautement optimisable | Facturation par cache (économie de 90 %) |
| Mode Raisonnement / Chaîne de pensée | 20-25 % | ✅ Selon les besoins | Activer uniquement pour les tâches complexes |
| Appel d'outils et sortie | 5-15 % | ⚡ Optimisation limitée | Simplification des descriptions d'outils |
II. Le secret le mieux gardé pour réduire vos coûts : le cache Claude
Qu'est-ce que la facturation par cache de Claude ?
Le Prompt Caching (mise en cache des invites) est une fonctionnalité native lancée par Anthropic fin 2024. Le principe de base est simple : le contenu fréquemment répété est mis en cache côté serveur. Lors des appels suivants, le système lit directement le cache au lieu de retraiter l'intégralité du texte.
Le prix de lecture du cache : seulement 10 % du prix d'entrée normal (soit 90 % d'économie).
Concrètement : si vous envoyez un System Prompt de 8 000 tokens, une fois le cache activé, chaque répétition (hit) ne vous sera facturée que sur la base de 800 tokens. Pour un utilisateur d'OpenClaw qui envoie des dizaines de requêtes par jour, cette optimisation peut représenter une économie de plusieurs centaines de dollars par mois.
Le système de tarification complet du cache
| Type de cache | Multiplicateur de coût | Durée de validité | Cas d'utilisation |
|---|---|---|---|
| Token d'entrée normal | 1× prix de base | Pas de cache | Traitement à chaque fois |
| Écriture en cache (initiale) | 1.25× | TTL de 5 min | Création du cache |
| Écriture en cache (longue durée) | 2× | TTL de 1 heure | Scénarios d'appels fréquents |
| Lecture du cache (Hit) | 0.1× (-90 %) | Pendant la validité | Requêtes répétées |
Exemple de calcul des économies réelles :
Scénario : System Prompt OpenClaw de 8 000 tokens
50 appels par jour, dont 48 "hits" (succès du cache)
Sans cache : 50 × 8 000 = 400 000 tokens
Coût = 400 000 × 3 $/1M = 1,20 $/jour = 36 $/mois
Avec cache : 2 écritures : 2 × 8 000 × 1,25 = 20 000 tokens = 0,06 $
48 hits : 48 × 8 000 × 0,1 = 38 400 tokens = 0,12 $
Coût journalier ≈ 0,18 $ → Mensuel ≈ 5,40 $
Économies : 36 $ - 5,40 $ = 30,60 $/mois (uniquement sur le System Prompt)
Taux d'économie : 85 %
Comment activer la facturation par cache dans OpenClaw
L'activation de la facturation par cache nécessite une condition sine qua non : vous devez utiliser l'interface au format natif Anthropic (/v1/messages) et non le mode de compatibilité OpenAI (/v1/chat/completions).
Configuration correcte (exemple avec le SDK Python) :
import anthropic
# Vous devez utiliser le SDK natif Anthropic, pas celui d'OpenAI
client = anthropic.Anthropic(
api_key="votre-clé-api",
base_url="https://api.apiyi.com/v1" # APIYI supporte le format natif Anthropic
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Tu es un assistant AI professionnel... [System Prompt de 8000 tokens]",
"cache_control": {"type": "ephemeral"} # ← CRUCIAL : marque ce contenu pour la mise en cache
}
],
messages=[
{"role": "user", "content": "Aide-moi à organiser mes emails d'aujourd'hui"}
]
)
Contraintes techniques du cache :
- Maximum 4 points d'arrêt de cache (marqueurs
cache_control) - Série Sonnet : contenu minimal mis en cache ≥ 1 024 tokens
- Opus / Haiku 4.5 : contenu minimal mis en cache ≥ 4 096 tokens
- Modèles compatibles : Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3, etc.
🎯 Note importante : APIYI (apiyi.com) supporte intégralement les appels au format natif Anthropic, y compris le paramètre
cache_control. En utilisant le format natif pour appeler les modèles Claude sur APIYI, vous cumulez la facturation par cache (jusqu'à 90 % d'économie) + la réduction de 20 % d'APIYI, pour un effet d'économie massif.
III. Concept clé : pourquoi le mode compatibilité OpenAI ne permet pas d'économiser des tokens
C'est ici que la plupart des utilisateurs d'OpenClaw tombent dans le piège.
La différence fondamentale entre les deux formats d'interface
De nombreux outils IA tiers et services proxy proposent un mode de compatibilité OpenAI pour faciliter la tâche des utilisateurs : cela permet d'utiliser le format d'interface /v1/chat/completions d'OpenAI pour appeler des modèles non-OpenAI comme Claude.
En apparence, cela permet d'utiliser "un seul code pour tous les modèles". Mais il y a un défaut majeur :
Le format d'interface /v1/chat/completions ne prévoit pas d'emplacement pour le paramètre cache_control — car c'est une fonctionnalité native exclusive à Anthropic.
Lorsque vous appelez Claude via le format compatible OpenAI :
- Votre requête est convertie au format OpenAI.
- Le service proxy/agent la convertit ensuite au format natif Anthropic.
- Mais l'information
cache_controlest déjà perdue dès la première étape. - Le serveur Claude reçoit une requête sans marqueur de cache et facture donc chaque token au prix fort.
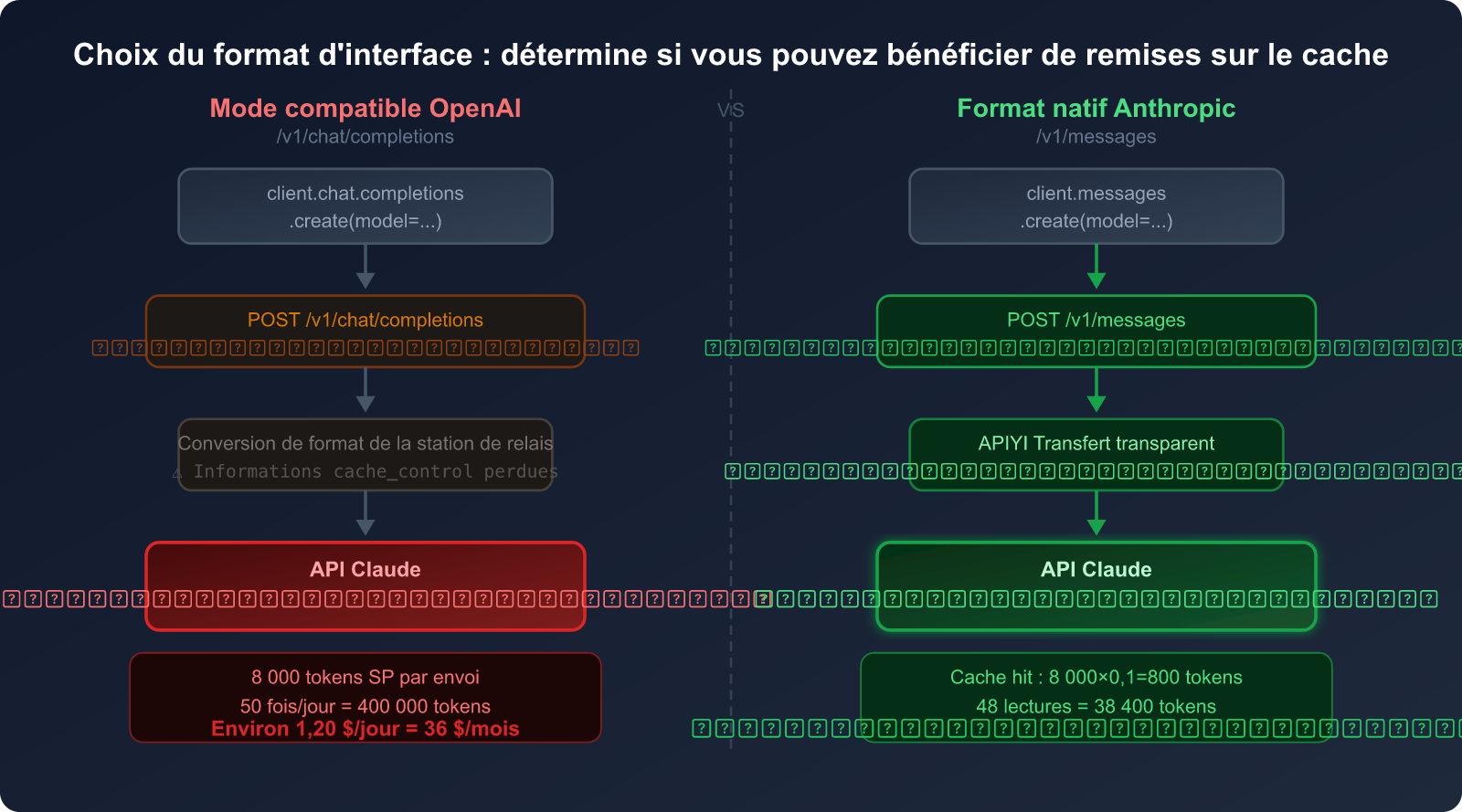
Comparaison : Mode compatibilité OpenAI vs Format natif Anthropic
| Dimension de comparaison | Mode compatibilité OpenAI | Format natif Anthropic |
|---|---|---|
| Chemin de l'interface | /v1/chat/completions |
/v1/messages |
| Support du cache Claude | ❌ Non supporté | ✅ Support complet |
Paramètre cache_control |
❌ Champ inexistant | ✅ Supporte 4 points d'arrêt |
| Facturation System Prompt | 💸 Plein tarif (1× prix) | 💰 Lecture cache (0.1× prix) |
| Complexité du code | Faible (code générique) | Moyenne (nécessite le SDK Anthropic) |
| Effet d'économie (usage fréquent) | 0 % | Jusqu'à 90 % |
Problèmes supplémentaires liés aux déploiements non-natifs
Au-delà du format d'interface, il existe une autre confusion courante : un modèle de "même nom" déployé par un fournisseur Cloud n'est pas identique au modèle original.
Prenons l'exemple de GLM-5 (Zhipu AI) :
- API originale sur z.ai : Supporte la fonction de facturation par cache développée par Zhipu.
- GLM-5 déployé sur Alibaba Cloud / Tencent Cloud : Utilise la passerelle API du fournisseur Cloud et ne possède pas la fonction de facturation par cache originale.
Ce n'est pas un défaut de GLM-5, mais un problème récurrent des déploiements tiers : lorsqu'ils hébergent des modèles, les fournisseurs Cloud n'exposent généralement que les API de dialogue standard et ne transmettent pas les fonctionnalités privées du fabricant original (comme la facturation par cache).
Analogie : C'est comme acheter un produit via un revendeur non agréé ; vous ne bénéficiez pas du service après-vente spécifique du fabricant officiel.
Impact réel :
Scénario : 50 appels par jour, System Prompt de 6 000 tokens
API originale (avec cache) :
Écriture : 2 fois × 6 000 × 1,25 = 15 000 tokens
Lecture : 48 fois × 6 000 × 0,1 = 28 800 tokens
Consommation équivalente ≈ 43 800 tokens/jour
API tierce (sans cache) :
Plein tarif : 50 fois × 6 000 = 300 000 tokens/jour
Différence : La consommation sans cache est 6,85 fois supérieure à celle avec cache.
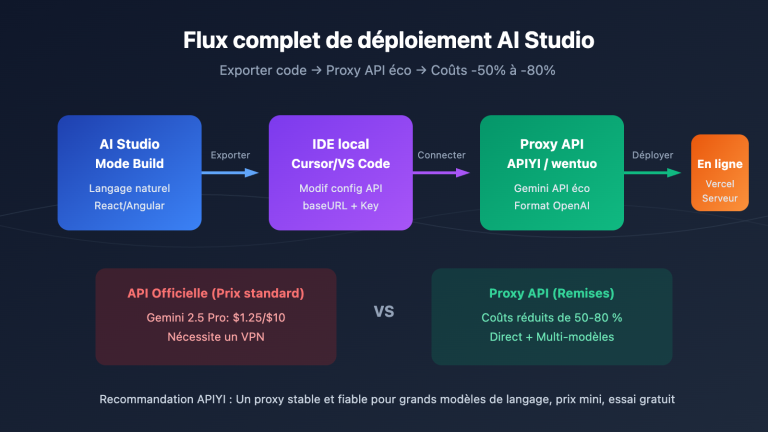
IV. Comparaison des API : Comment choisir la meilleure solution pour OpenClaw
Comparaison des quatre solutions d'accès
| Solution d'accès | Prix (par rapport au prix d'origine) | Support du cache | Support multi-modèle | Cas d'utilisation |
|---|---|---|---|---|
| API officielle Anthropic | 100 % (Prix d'origine) | ✅ Complet | ❌ Claude uniquement | Budget suffisant, utilisateurs exclusifs de Claude |
| APIYI (Format natif Anthropic) | 80 % (20 % de réduction) | ✅ Complet | ✅ Multi-modèle | Recommandé : Économies + Flexibilité |
| Service proxy API générique (Compatible OpenAI) | Entre 85 et 95 % | ❌ Non supporté | ✅ Multi-modèle | Sans utilisation du cache Claude |
| Déploiement tiers via fournisseurs Cloud | Entre 90 et 110 % | ❌ Non supporté | ❌ Modèle unique | Scénarios d'exigences de conformité d'entreprise |
La double logique d'économie d'APIYI
L'avantage d'APIYI sur les modèles Claude réside dans le fait qu'il supporte simultanément le format natif Anthropic et un tarif réduit de 20 %.
Le cumul de ces deux points signifie :
Utilisateur standard (Prix d'origine + Compatible OpenAI, sans cache) :
Consommation mensuelle de tokens de l'invite système : 12 000 000 tokens
Coût = 12 000 000 × 3 $/1M = 36 $
Utilisateur APIYI (Réduction 20 % + Format natif + Cache) :
Tokens facturés réels ≈ 1 440 000 tokens (après cache)
Coût = 1 440 000 × 3 $ × 0,8 / 1M = 3,46 $
Économie globale = (36 $ - 3,46 $) / 36 $ ≈ 90 %
🎯 Conseil de sélection : Si vous utilisez OpenClaw et que votre choix de modèle se porte principalement sur Claude, je vous recommande vivement de passer par APIYI (apiyi.com) en utilisant le format natif Anthropic. Le prix de base réduit de 20 % cumulé aux 90 % d'économies grâce au cache peut réduire votre facture de 85 à 90 %. De plus, APIYI supporte d'autres modèles comme GLM-5 ou GPT, ce qui facilite les comparaisons à tout moment.
V. Guide complet pour économiser avec OpenClaw : 5 étapes immédiates
Étape 1 : Passer à l'interface au format natif Anthropic
C'est l'étape la plus importante, car elle détermine directement si vous pouvez bénéficier de la facturation par cache.
Méthode de configuration OpenClaw :
Dans la configuration du modèle d'OpenClaw (config.json), trouvez le champ models.providers et ajoutez APIYI comme fournisseur selon le format suivant. Le point crucial est de définir le champ api sur "anthropic-messages" pour utiliser le format natif Anthropic et supporter le cache :
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-votre-clé-ici",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Explications des points clés :
"api": "anthropic-messages"← Le plus critique, spécifie l'utilisation du format natif/v1/messagesau lieu du format compatible/v1/chat/completions."baseUrl": "https://api.apiyi.com"← L'URL de base d'APIYI (pas besoin d'ajouter/v1, OpenClaw s'en occupe automatiquement)."anthropic-version": "2023-06-01"← Header de version de l'API Anthropic, son absence entraînera l'échec de la requête.contextWindow: 200000← Claude Sonnet 4.6 supporte une fenêtre de contexte de 200K.
Vérifier si le cache est actif :
Consultez les headers de réponse de l'API ou les journaux pour les champs cache_read_input_tokens et cache_creation_input_tokens. Si ces champs ont des valeurs, le cache fonctionne :
# Vérifier la réponse du cache
response = client.messages.create(...)
# Vérifier le champ usage
print(response.usage)
# Exemple de sortie :
# Usage(
# input_tokens=150, # Nouveaux tokens pour cet appel
# cache_creation_input_tokens=8000, # Première écriture en cache (facturé 1.25×)
# cache_read_input_tokens=0, # Hit de cache ultérieur (facturé 0.1×)
# output_tokens=300
# )
🎯 Mode d'accès : Après vous être inscrit sur APIYI (apiyi.com) et avoir obtenu votre clé API, réglez simplement la
base_urlsurhttps://api.apiyi.com/v1pour utiliser le format natif Anthropic. Aucune autre modification de code n'est nécessaire, et la facturation par cache de Claude devient immédiatement effective.
Étape 2 : Placer judicieusement les points d'arrêt du cache
L'emplacement des points d'arrêt du cache (cache_control) est crucial. Il faut mettre en cache les contenus "volumineux et statiques" :
# Meilleure pratique : mise en cache de l'invite système + définitions d'outils
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Invite système principale de 5 000 à 10 000 tokens
"cache_control": {"type": "ephemeral"} # Point d'arrêt 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Liste d'outils (généralement volumineuse)
"cache_control": {"type": "ephemeral"} # Point d'arrêt 2
}
],
messages=conversation_history, # Historique de conversation (non mis en cache, change à chaque fois)
...
)
Points clés de la stratégie de cache :
- ✅ Adapté au cache : Invite système, définitions d'outils, gros documents statiques, contenu de documents récupérés par RAG.
- ❌ Non adapté au cache : Messages actuels de l'utilisateur, contenu généré dynamiquement, données changeant à chaque fois.
- ⚠️ Attention à l'ordre : Le cache fonctionne par correspondance de préfixe, le contenu statique doit donc être placé au début de la séquence de messages.
Étape 3 : Activer QMD pour réduire la longueur du contexte
QMD (Quick Memory Database) est la fonction de recherche sémantique locale d'OpenClaw. Voici son fonctionnement :
Méthode traditionnelle :
Envoi de [tout l'historique] à chaque fois → Consomme énormément de tokens
Méthode QMD :
Création d'une base de données vectorielle locale → Recherche des fragments d'historique les plus pertinents
Envoi de seulement [les 3 à 5 messages les plus pertinents] → Économise 60 à 97 % de tokens
Effet réel d'économie de QMD : Selon la documentation officielle d'OpenClaw, QMD peut réaliser une économie de tokens de 60 à 97 %, la proportion exacte dépendant du volume de l'historique et du type de tâche.
Mode d'activation (Interface de réglages OpenClaw) :
- Settings → Memory → Enable QMD
- Définir le chemin de stockage QMD (local, les données ne sont pas téléchargées)
- Définir le seuil de pertinence (recommandé au-dessus de 0,7 pour éviter les bruits historiques)
Étape 4 : Choisir le bon modèle selon le type de tâche
Toutes les tâches ne nécessitent pas le modèle le plus puissant. Une allocation correcte des modèles est la clé du contrôle des coûts :
Stratégie de classification des tâches :
Tâches simples (rappels d'agenda, conversion de format, recherche simple)
→ Utilisez Claude Haiku 4.5 (le plus rapide, le moins cher)
→ Environ 1/5 du prix de Sonnet
Tâches moyennes (gestion d'e-mails, organisation de fichiers, revue de code)
→ Utilisez Claude Sonnet 4.6 (équilibré)
→ Taux de réussite de 86,9 % (premier au classement PinchBench)
Tâches complexes (analyse d'architecture, recherche multi-étapes, raisonnement complexe)
→ Utilisez Claude Opus 4.6 (raisonnement le plus puissant)
→ N'activez le mode raisonnement que lorsque c'est réellement nécessaire
Étape 5 : Nettoyage périodique du contexte
L'historique des conversations est l'une des plus grandes sources de consommation de tokens (40 à 50 %). Recommandations :
- Définir un nombre maximum de tours de contexte : Résumer et nettoyer automatiquement l'historique après 15 à 20 tours.
- Nettoyage manuel après la fin d'une tâche : Réinitialiser le contexte avant de commencer une nouvelle tâche.
- Activer la fonction de compression de session d'OpenClaw : Utiliser l'IA pour compresser un long historique en un résumé succinct.
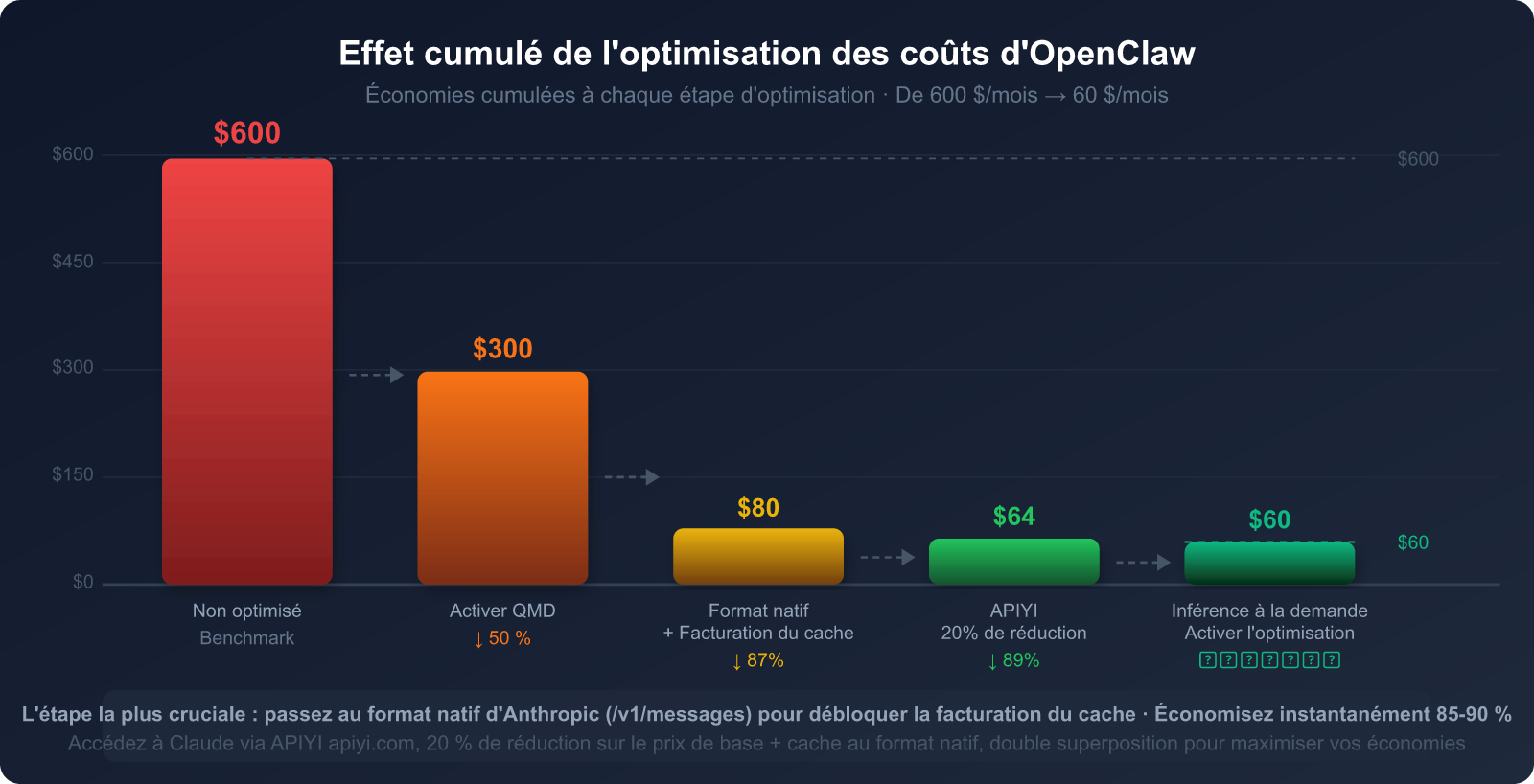
Estimation de l'effet combiné de l'optimisation en cinq étapes
Pour un utilisateur moyen d'OpenClaw (frais mensuels non optimisés d'environ 300 à 600 $), voici les résultats attendus après l'exécution des cinq étapes :
| Étape d'optimisation | Source de consommation ciblée | Taux d'économie prévu | Difficulté d'exécution |
|---|---|---|---|
| 1. Passer au format natif Anthropic | Facturation répétée de l'invite système | 85-90 % (partie SP) | ⭐ Faible (changer la base_url) |
| 2. Placer des points d'arrêt de cache | Définitions d'outils + Documents statiques | 80-90 % (partie outils) | ⭐⭐ Faible-Moyenne |
| 3. Activer QMD | Tokens de l'historique | 60-97 % (partie historique) | ⭐⭐ Faible-Moyenne |
| 4. Classification par tâche | Coût total des tokens | 30-70 % (différence de prix) | ⭐⭐⭐ Moyenne |
| 5. Nettoyage périodique | Effet boule de neige de l'historique | 20-40 % (gain à long terme) | ⭐ Faible |
🎯 Conseils de priorité d'exécution : L'étape 1 (format natif) et l'étape 3 (QMD) sont les deux étapes offrant le meilleur rendement pour la plus grande simplicité. Il est conseillé de les réaliser en priorité, ce qui permet généralement de réduire la facture de 60 à 80 % immédiatement. En passant par APIYI (apiyi.com) pour accéder à Claude, l'étape 1 ne prend que 5 minutes en modifiant une seule ligne de configuration
base_url.
6. Configuration pratique : exemple complet OpenClaw + APIYI + Cache Claude
Voici un exemple de configuration OpenClaw complet et optimisé, prêt à être réutilisé par la plupart des utilisateurs :
import anthropic
# Utilisation du format natif Anthropic via APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # Clé APIYI (à obtenir sur apiyi.com)
base_url="https://api.apiyi.com/v1"
)
# Définition de l'invite de système (contenu volumineux, idéal pour le cache)
SYSTEM_PROMPT = """
Vous êtes un assistant IA professionnel fonctionnant sur la plateforme OpenClaw.
Vos responsabilités incluent : la gestion d'agenda, le traitement des e-mails, l'organisation de fichiers, l'assistance au développement de code...
[Généralement 5 000 à 10 000 tokens d'instructions détaillées]
"""
# Définition de la liste des outils (également un contenu fixe volumineux, idéal pour le cache)
TOOL_DEFINITIONS = """
Outils disponibles : calendar_api, email_api, file_system, code_runner...
[Description détaillée des outils, généralement 2 000 à 5 000 tokens]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Appel API OpenClaw optimisé avec activation du cache"""
response = client.messages.create(
model="claude-sonnet-4-6", # Classé n°1 sur PinchBench
max_tokens=4096,
# Invite de système : marquage des points d'arrêt du cache
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Point d'arrêt cache 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Point d'arrêt cache 2
}
],
# Historique de la conversation + nouveau message
messages=[
*conversation_history, # Messages historiques (non mis en cache, changent à chaque fois)
{"role": "user", "content": user_message}
]
)
# Affichage de l'utilisation des tokens (pour surveiller l'efficacité de l'optimisation)
usage = response.usage
print(f"Tokens d'entrée : {usage.input_tokens}")
print(f"Écriture cache : {usage.cache_creation_input_tokens}")
print(f"Lecture cache : {usage.cache_read_input_tokens}")
print(f"Tokens de sortie : {usage.output_tokens}")
return response.content[0].text
🎯 Démarrage rapide : Remplacez
api_keypar la clé obtenue après votre inscription sur APIYI (apiyi.com). Sans aucune autre modification, vous profiterez immédiatement du format natif Anthropic, de la facturation avec cache et des tarifs avantageux d'APIYI.
Foire aux questions (FAQ)
Q : Est-ce qu'APIYI supporte vraiment le format natif Anthropic (/v1/messages) ?
Oui, APIYI (apiyi.com) supporte simultanément deux formats d'interface :
- Format natif Anthropic :
/v1/messages(supporte la facturation avec cache) - Format compatible OpenAI :
/v1/chat/completions(pratique pour le code générique)
Pour les modèles Claude, il est fortement recommandé d'utiliser le format natif Anthropic pour bénéficier de la facturation avec cache. Il suffit d'utiliser le SDK Python anthropic et de faire pointer le base_url vers APIYI.
🎯 Visitez APIYI (apiyi.com) pour créer un compte ; la console affiche des exemples de code pour les deux formats.
Q : Un TTL de 5 minutes pour le cache est-il suffisant ? Comment savoir si j'ai besoin d'un TTL d'une heure ?
Cela dépend de votre fréquence d'invocation :
- Si vos appels OpenClaw sont espacés de moins de 5 minutes (ex: traitement continu d'un flux de tâches), le TTL par défaut de 5 minutes suffit.
- Si l'intervalle entre les appels est compris entre 5 minutes et 1 heure (ex: pause après avoir traité un lot de tâches), envisagez un TTL d'une heure (le coût est de 2× le prix d'écriture, mais le taux de réussite du cache est plus élevé).
- Si l'intervalle est supérieur à 1 heure, l'intérêt du cache est limité, il vaut mieux réécrire à chaque fois.
Q : Des conseils pour économiser de l'argent avec des modèles comme GLM-5 ?
La fonction de cache de GLM-5 nécessite de passer par l'API native de Zhipu AI (z.ai). Les déploiements tiers comme ceux d'Alibaba Cloud ne la supportent pas forcément.
APIYI supporte également les modèles comme GLM-5 à des tarifs très compétitifs, ce qui est pratique pour comparer l'efficacité de différents modèles avec une interface unifiée pendant la phase de test. Une fois le modèle idéal identifié, vous pourrez décider de rester sur APIYI ou de passer en direct chez le fournisseur d'origine.
Q : J'utilise déjà un autre service proxy API, est-ce difficile de migrer vers une plateforme supportant le format natif ?
Le coût de migration est très faible. Les seuls paramètres à modifier dans votre code sont :
# Avant migration (format compatible OpenAI)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="ancienne_adresse_proxy")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# Après migration (format natif Anthropic, supporte le cache)
import anthropic
client = anthropic.Anthropic(
api_key="sk-nouvelle-clé-APIYI", # ← Remplacez par la clé APIYI
base_url="https://api.apiyi.com/v1" # ← Remplacez par l'adresse APIYI
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Ajoutez ensuite cache_control dans le paramètre system pour activer le cache
Le travail principal consiste à remplacer chat.completions.create par messages.create. Le format des messages présente de légères différences (la structure role/content est identique, mais system passe d'une chaîne de caractères à une liste d'objets). La migration se fait généralement en une demi-journée.
Q : Comment vérifier si le cache est bien activé sur mon instance OpenClaw ?
La méthode la plus directe : lors de deux appels consécutifs, observez l'objet usage dans la réponse de l'API :
- Premier appel :
cache_creation_input_tokensa une valeur (écriture dans le cache). - Deuxième appel :
cache_read_input_tokensa une valeur (succès du cache).
Si le nombre de cache_read_input_tokens du deuxième appel correspond au nombre de tokens de votre invite de système, cela signifie que le cache est pleinement opérationnel.
Q : Faut-il impérativement désactiver le mode réflexion (Extended Thinking) ?
Pas forcément, mais il doit être utilisé selon les besoins. Stratégie recommandée :
- Tâches simples (classification d'e-mails, agenda) : désactivez le mode réflexion.
- Tâches moyennes (revue de code, synthèse d'informations) : désactivé par défaut, activez-le en cas de difficulté.
- Tâches complexes (décisions d'architecture, recherche multi-étapes) : activez-le, mais fixez une limite raisonnable avec
budget_tokens.
Dans l'API Claude, vous pouvez limiter la consommation maximale de tokens du mode réflexion via thinking: {"type": "enabled", "budget_tokens": 5000}.
Résumé : La logique centrale pour économiser avec OpenClaw
Résumons toutes les méthodes d'économie en un seul schéma :
Revenons sur les points clés de cet article :
Les trois causes majeures de consommation élevée :
- Renvoi systématique de l'historique de discussion (représente 40 à 50 % de la consommation)
- Renvoi systématique de l'invite système (représente 25 à 30 %)
- Utilisation non régulée du mode raisonnement (représente 20 à 25 %)
Les méthodes d'économie les plus efficaces :
- 🥇 Facturation par cache Claude : économisez jusqu'à 90 % (nécessite l'utilisation du format natif Anthropic)
- 🥈 Recherche sémantique locale QMD : économisez 60 à 97 % des tokens de l'historique de contexte
- 🥉 Classification des modèles par tâche : utilisez Haiku pour les tâches légères, et Sonnet/Opus pour les tâches lourdes
- Choisir APIYI comme canal API : prix de base réduit de 20 % + support du format natif
Une prise de conscience cruciale :
Le format compatible OpenAI (
/v1/chat/completions) ne peut pas transmettrecache_control.
Par conséquent, même en appelant Claude via un service proxy API, vous ne bénéficierez pas des remises sur le cache.
Pour économiser, vous devez impérativement utiliser le format natif d'Anthropic (/v1/messages).
🎯 Passez à l'action : Inscrivez-vous sur APIYI (apiyi.com) pour obtenir une clé API supportant le format natif Anthropic.
Remplacez votrebase_urlparhttps://api.apiyi.com/v1. La bascule se fait en moins de 3 minutes,
et vous verrez une baisse significative de votre facture de tokens dès le premier jour. Avec des modèles Claude à -20 % et une interface unifiée pour plusieurs modèles, c'est le choix optimal pour les utilisateurs d'OpenClaw souhaitant réduire leurs coûts et améliorer leur efficacité.
Toutes les données de prix API de cet article sont basées sur des informations publiques de mars 2026. Veuillez vous référer aux annonces officielles de chaque plateforme pour les prix réels.
Auteur : Équipe APIYI | Pour plus d'astuces sur l'utilisation d'OpenClaw, visitez le centre d'aide d'APIYI sur apiyi.com