title: "Análisis profundo de Claude Opus 4.7: Benchmarks, rendimiento y uso práctico"
description: "Análisis detallado del rendimiento de Claude Opus 4.7 frente a GPT-5.4 y Gemini 3.1 Pro, con datos de benchmarks independientes y guía de uso mediante API."
Nota del autor: Análisis profundo de los benchmarks de Claude Opus 4.7: SWE-bench Verified 87.6%, SWE-bench Pro 64.3%, GPQA Diamond 94.2%, superando a GPT-5.4 y Gemini 3.1 Pro, con una guía práctica de invocación de API.
Anthropic lanzó oficialmente Claude Opus 4.7 el 16 de abril de 2026, logrando el liderazgo en 7 de los 10 benchmarks principales. En este artículo, analizaremos en profundidad los datos clave y los escenarios de aplicación de Claude Opus 4.7 desde una perspectiva de evaluación real.
Esto no es una repetición de la publicidad oficial; todos los datos provienen de instituciones de evaluación independientes e incluyen tanto las ventajas como las debilidades de Opus 4.7 en áreas como la búsqueda web.
Valor central: A través de datos de benchmark reales y experiencia de uso, te ayudamos a decidir si vale la pena cambiar a Claude Opus 4.7 y cómo empezar a utilizarlo con bajo coste.
💡 APIYI ya ha integrado el modelo oficial Claude Opus 4.7, con bonificaciones desde el 10% en recargas de 100 USD, lo que equivale a un descuento del 20%, y es compatible con la interfaz de OpenAI para un reemplazo inmediato.

Puntos clave de los benchmarks de Claude Opus 4.7
| Proyecto de benchmark | Resultado Opus 4.7 | vs Opus 4.6 | vs GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
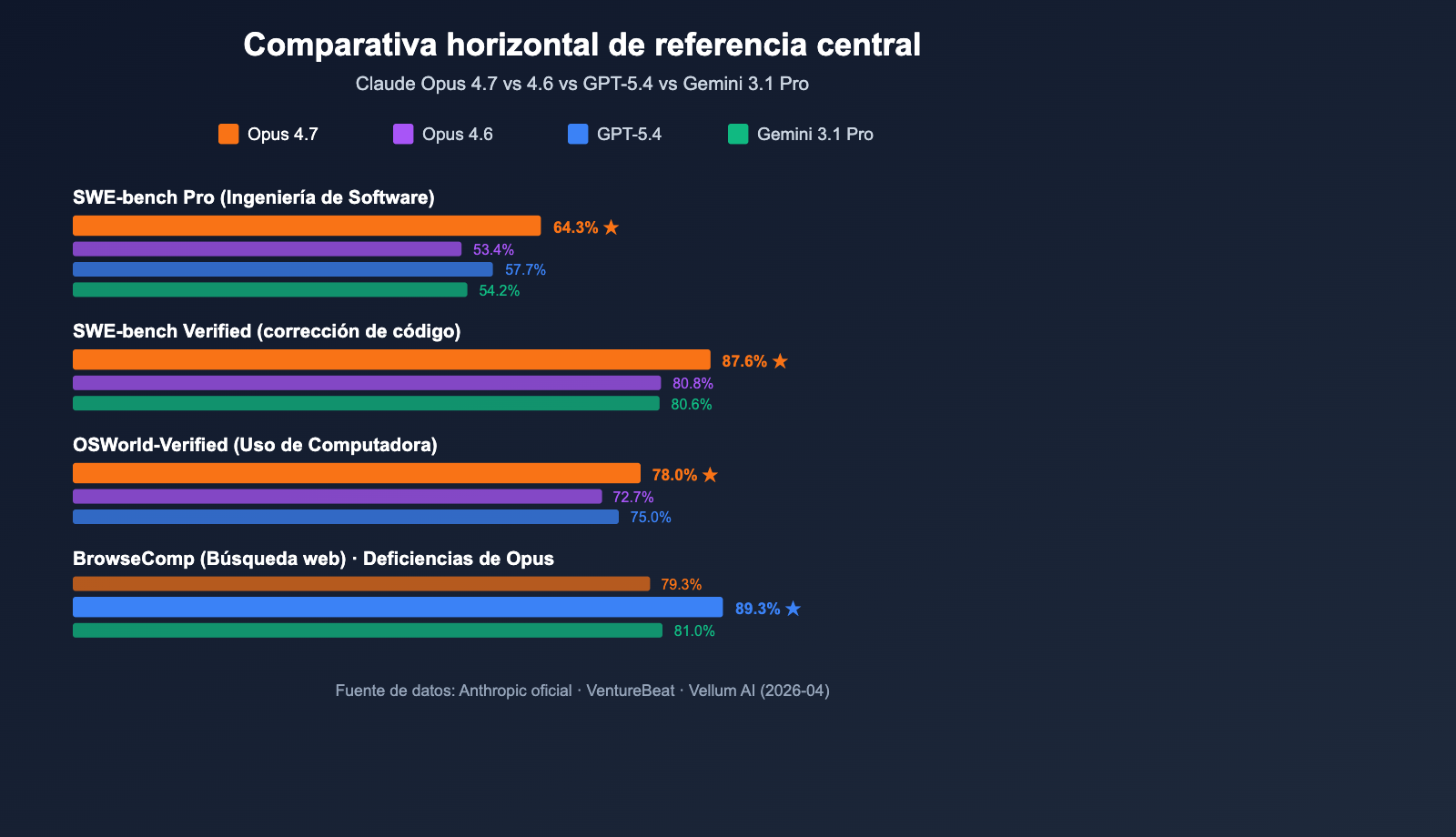
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅ Líder |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅ Líder |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ Líder en programación multilingüe |
| GPQA Diamond | 94.2% | – | ✅ Referente en razonamiento científico |
| Terminal-Bench 2.0 | 69.4% | – | ✅ Líder en operaciones de terminal |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅ Líder |
| MCP-Atlas (Invocación de herramientas) | Líder GPT-5.4 +9.2 pts | – | ✅ Óptimo para escenarios de agentes |
| Visión multimodal | 98.5% | – | ✅ Comprensión visual de primer nivel |
| BrowseComp (Búsqueda web) | 79.3% | – | GPT-5.4: 89.3% ❌ Rezagado |
Aspectos destacados de las pruebas de Claude Opus 4.7
Anthropic lanzó Claude Opus 4.7 el 16 de abril de 2026, posicionándolo como el Modelo de Lenguaje Grande más potente disponible actualmente (según VentureBeat). En 10 comparaciones directas con GPT-5.4 y Gemini 3.1 Pro, Opus 4.7 obtuvo el liderazgo en 7, destacando especialmente en SWE-bench Pro.
Lo más notable es la cifra de 64.3% en SWE-bench Pro, el resultado más alto de la industria en tareas de ingeniería de software reales, superando el 57.7% de GPT-5.4 por 6.6 puntos porcentuales y marcando un salto de 10.9 puntos respecto al 53.4% de Opus 4.6. En el benchmark de invocación de herramientas MCP-Atlas, Opus 4.7 supera a GPT-5.4 por 9.2 puntos, lo que significa que es más adecuado para escenarios de IA Agéntica, como flujos de trabajo automatizados, agentes de generación de código y tareas de razonamiento de múltiples pasos.
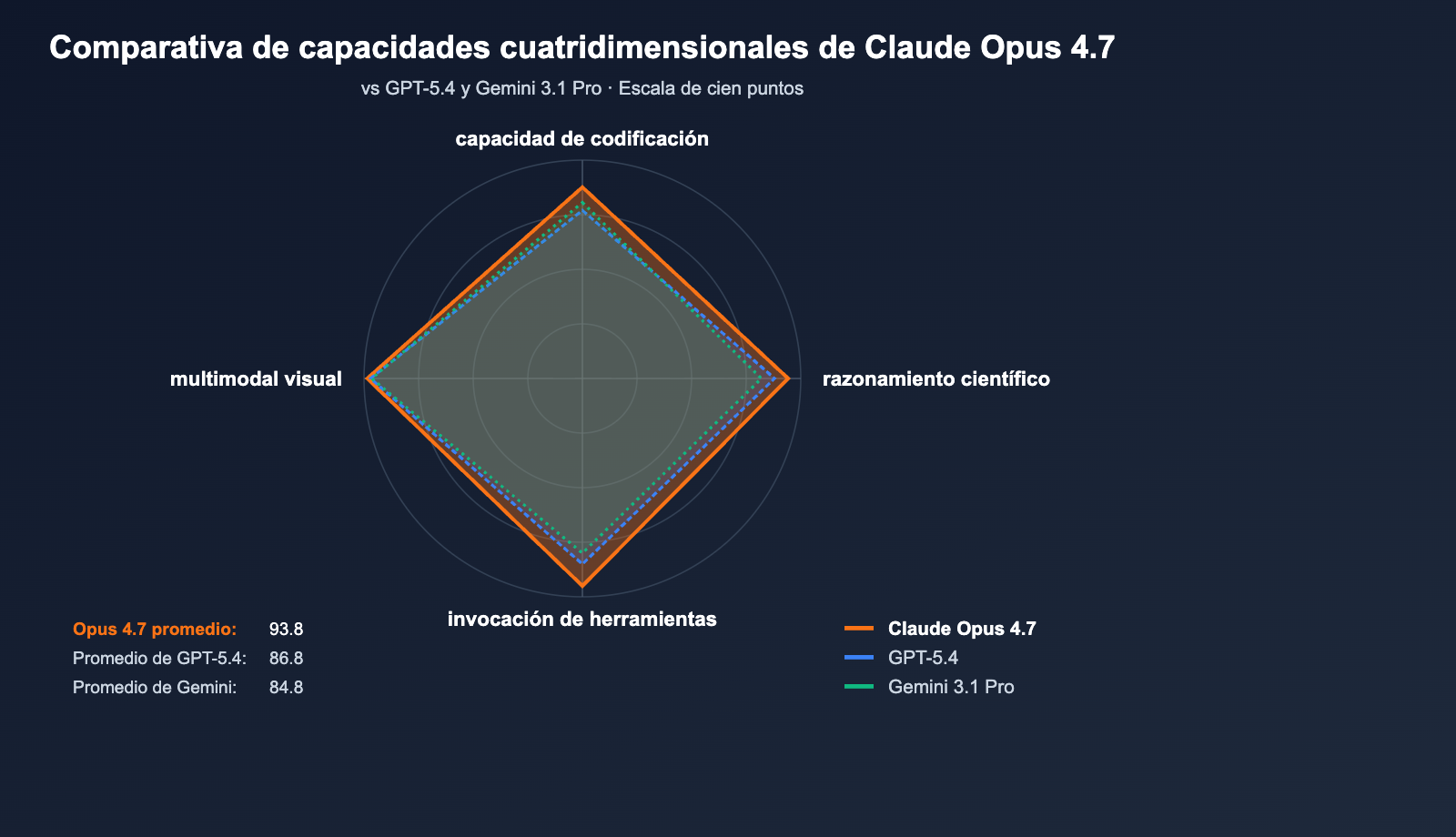
Comparativa de Claude Opus 4.7 frente a versiones anteriores y modelos competidores
| Dimensión | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Fecha de lanzamiento | 16-04-2026 | 01-2026 | 03-2026 | 02-2026 |
| Ventana de contexto | 1M tokens (precio estándar) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agente/invocación de herramientas | El mejor | Bueno | Fuerte | Bueno |
| Búsqueda Web (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Visión multimodal | 98.5% | 95% | 97% | 96.5% |
| Precio oficial API | $5 / $25 (entrada/salida, por millón de tokens) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| Descuento integral APIYI | Recarga $100 y obtén desde 10% extra ≈ 20% dto. | Misma oferta | Misma oferta | Misma oferta |
Análisis comparativo (Claude Opus 4.7 vs otros modelos)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 mantiene el liderazgo en escenarios de búsqueda web con BrowseComp (89.3% vs 79.3%). Sin embargo, se queda notablemente atrás en SWE-bench Pro (57.7%) y en la invocación de herramientas (MCP-Atlas) frente a Opus 4.7. En comparación, Claude Opus 4.7 destaca más en agentes de programación, generación de código y ejecución de tareas de varios pasos, siendo más adecuado para flujos de trabajo de desarrollo.
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro sigue liderando en comprensión de textos largos y escenarios de video multimodal. No obstante, la diferencia es clara en SWE-bench Verified (80.6% vs 87.6%) y SWE-bench Pro (54.2% vs 64.3%). En comparación, Claude Opus 4.7 ofrece una ventaja abrumadora en tareas de ingeniería de software, siendo ideal para programación a nivel de producción.
Claude Opus 4.7 vs Opus 4.6: Opus 4.6 sigue siendo una opción estable para escenarios sensibles al costo. Pero la versión 4.7 supone un salto importante en capacidades de programación, razonamiento agente y uso de computadora, todo ello manteniendo el mismo precio de API. Para equipos que manejan tareas complejas y de larga duración, actualizar a la 4.7 es prácticamente obligatorio.
Nota sobre la comparativa: Los datos anteriores provienen de lanzamientos oficiales de Anthropic, VentureBeat, Vellum AI, Decrypt y otras agencias de evaluación independientes; puedes realizar pruebas reales a través de la plataforma APIYI apiyi.com.
Guía rápida de Claude Opus 4.7
Ejemplo minimalista
Aquí tienes la forma más sencilla de invocar a Claude Opus 4.7 a través de APIYI, utilizando una interfaz compatible con OpenAI:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Escribe una función en Python para el recorrido en orden (in-order) de un árbol binario"}]
)
print(response.choices[0].message.content)
Ver código de implementación completo (incluye invocación en modo xhigh Effort)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Invoca a Claude Opus 4.7, con soporte para el modo de esfuerzo xhigh
Args:
prompt: Entrada del usuario
effort_level: Nivel de esfuerzo de razonamiento, opciones: "low" / "medium" / "high" / "xhigh"
system_prompt: Indicación del sistema
max_tokens: Número máximo de tokens de salida
Returns:
Contenido de la respuesta del modelo
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Se recomienda usar el modo xhigh para tareas de programación complejas
result = call_claude_opus_47(
prompt="Diseña e implementa una caché LRU que soporte operaciones get y put en O(1)",
effort_level="xhigh",
system_prompt="Eres un ingeniero senior de Python, escribe código que equilibre legibilidad y rendimiento"
)
print(result)
Sugerencia: Obtén saldo de prueba gratuito a través de APIYI (apiyi.com) para verificar rápidamente el rendimiento de Claude Opus 4.7 en tus casos de uso. La plataforma admite una interfaz unificada compatible con OpenAI para Opus 4.7, GPT-5.4 y Gemini 3.1 Pro, lo que facilita las comparaciones directas. Las promociones de recarga ofrecen un 10% adicional o más, lo que equivale a un descuento del 20% sobre el uso de modelos oficiales.
Rendimiento de Claude Opus 4.7 y escenarios típicos
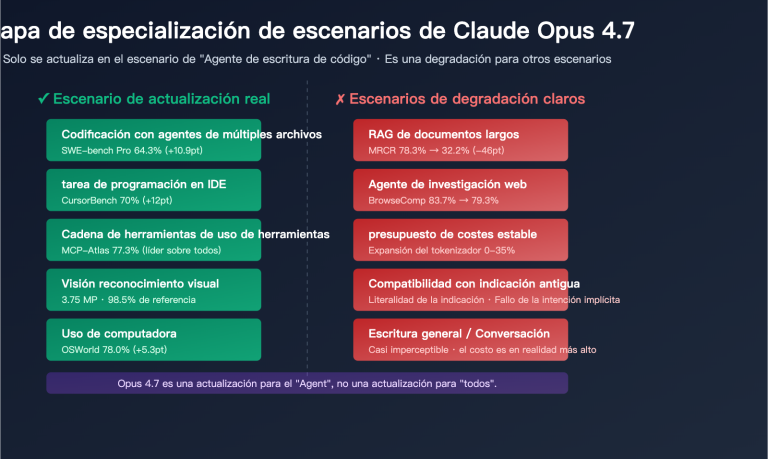
4 escenarios principales ideales para Claude Opus 4.7
- 🧑💻 Refactorización de código a gran escala: El 87.6% en SWE-bench Verified demuestra su capacidad para comprender el contexto entre archivos, ideal para ajustes de arquitectura, actualizaciones de dependencias y refactorizaciones masivas en bases de código de 100,000 líneas.
- 🤖 Flujos de trabajo de automatización con agentes: Con una ventaja de 9.2 puntos sobre GPT-5.4 en llamadas a herramientas MCP-Atlas, es perfecto para construir agentes de automatización de navegadores, RPA y razonamiento de múltiples pasos.
- 🔬 Apoyo a la investigación y razonamiento: El 94.2% en GPQA Diamond implica capacidades de razonamiento de nivel de posgrado, ideal para asistencia en artículos científicos, análisis de datos y validación de hipótesis.
- 🖥️ Automatización de escritorio con Computer Use: Lidera la industria con un 78.0% en OSWorld-Verified, ideal para pruebas automatizadas y operaciones de interfaz de usuario que requieren simular el ratón y el teclado.
Escenarios no recomendados para Claude Opus 4.7
- Búsqueda web en tiempo real: Con un 79.3% en BrowseComp, queda notablemente por detrás del 89.3% de GPT-5.4; para estos casos, se recomienda cambiar a GPT-5.4.
- Invocaciones masivas de bajo costo: Con un precio de salida de $25/M tokens, para aplicaciones de chat cotidiano se recomienda usar Claude Haiku o GPT-5.4-mini.
- Requisitos de latencia ultrabaja: La latencia de respuesta de la serie Opus es mayor que la de Sonnet/Haiku, por lo que debe elegirse con precaución en escenarios de interacción en tiempo real.
Precios y estimación de costos de Claude Opus 4.7
Precios oficiales vs. Costos integrales en APIYI
| Proyecto | Precio oficial (Anthropic) | Precio en APIYI (incluye bonos de recarga) |
|---|---|---|
| Tokens de entrada | $5 / 1 millón de tokens | Igual al precio oficial |
| Tokens de salida | $25 / 1 millón de tokens | Igual al precio oficial |
| Bonos de recarga | Ninguno | 10% extra a partir de 100 USD |
| Descuento equivalente | Ninguno | Aprox. 20% de ahorro (más bono cuanto mayor sea la recarga) |
| Métodos de pago | Solo tarjetas de crédito USD | Soporta CNY, USD y múltiples métodos |
| Moneda de facturación | USD | Opcional: RMB / USD |
Nota sobre costos: El nuevo tokenizador de Opus 4.7 consume entre 1 y 1.35 veces más tokens que la versión 4.6 al procesar texto (varía según el tipo de contenido). Aunque el precio oficial no ha aumentado, el costo real en la factura puede subir entre un 20% y un 30%. Gracias a los bonos de recarga de APIYI (apiyi.com), puedes compensar este costo implícito, logrando que el costo real sea igual o incluso menor que en la era de la versión 4.6.
Preguntas frecuentes (FAQ)
Q1: ¿Qué es Claude Opus 4.7?
Claude Opus 4.7 es el Modelo de Lenguaje Grande insignia lanzado por Anthropic el 16 de abril de 2026. Lidera en múltiples benchmarks frente a GPT-5.4 y Gemini 3.1 Pro, destacando en codificación (87.6% en SWE-bench Verified), invocación de herramientas para agentes y razonamiento científico (94.2% en GPQA Diamond). Comparado con Opus 4.6, añade el modo de razonamiento profundo "xhigh effort" sin aumentar el precio oficial.
Q2: ¿Cuál es mejor, Claude Opus 4.7 o GPT-5.4?
Depende del caso de uso. En programación (64.3% vs 57.7% en SWE-bench Pro), invocación de herramientas (MCP-Atlas +9.2 puntos) y uso informático (78.0% vs 75.0%), Opus 4.7 lleva una clara ventaja. Sin embargo, GPT-5.4 sigue siendo superior en búsqueda web (79.3% vs 89.3% en BrowseComp). Para flujos de trabajo de desarrollo, elige Opus 4.7; para búsqueda en Internet, elige GPT-5.4.
Q3: ¿Cuándo se lanzó Claude Opus 4.7? ¿Cuándo estará disponible en China?
La fecha oficial de lanzamiento fue el 16 de abril de 2026. Ya está disponible en la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry. Los desarrolladores en China pueden utilizar el modelo oficial a través de plataformas agregadoras como APIYI (apiyi.com) sin necesidad de solicitar cuentas en el extranjero.
Q4: ¿Para qué proyectos reales es mejor Claude Opus 4.7?
Es ideal para los siguientes escenarios:
- Refactorización de código a gran escala: Comprensión del contexto entre archivos, migración de dependencias y ajustes arquitectónicos.
- Automatización de Agentes: Cadenas de herramientas MCP, automatización de navegadores y procesos RPA.
- Investigación y análisis de datos: Razonamiento de nivel académico, validación de hipótesis y asistencia en redacción de artículos científicos.
- Automatización de escritorio (Computer Use): Pruebas de automatización de UI y scripts de operaciones GUI.
Q5: ¿Cómo realizar llamadas por API a Claude Opus 4.7 rápidamente?
Recomendamos utilizar una plataforma agregadora compatible con el protocolo de OpenAI. Sigue estos 3 pasos:
- Regístrate en APIYI (apiyi.com) para obtener tu clave API.
- Recarga 100 USD para obtener un bono del 10% (aprox. 20% de ahorro total), o utiliza el saldo gratuito de prueba.
- Cambia la
base_urldel SDK de OpenAI ahttps://vip.apiyi.com/v1y especificaclaude-opus-4-7en el campo del modelo.
APIYI admite la integración unificada de modelos principales como Claude Opus 4.7, GPT-5.4 y Gemini 3.1 Pro, lo que facilita las comparaciones y cambios de modelo.
Q6: ¿Qué limitaciones tiene Claude Opus 4.7?
Las limitaciones principales incluyen:
- Mayor consumo de tokens: El nuevo tokenizador usa de 1 a 1.35 veces más tokens que el 4.6, por lo que la factura real puede aumentar un 20-30%.
- Debilidad en búsqueda web: Con un 79.3% en BrowseComp, queda por debajo de GPT-5.4; úsalo con precaución en escenarios de búsqueda en tiempo real.
- Latencia de respuesta: La serie Opus tiene mayor latencia que Sonnet/Haiku; para aplicaciones de chat en tiempo real, se recomienda combinarlo con modelos más ligeros.
- Precio oficial elevado: A $5/$25 por millón de tokens, recomendamos usar los beneficios de recarga de APIYI para mitigar costos en llamadas masivas.
Q7: ¿Cuál es la ventana de contexto de Claude Opus 4.7?
Claude Opus 4.7 admite una ventana de contexto de 1 millón (1M) de tokens con un precio estándar y sin cargos adicionales por contexto largo. Esto permite procesar en una sola solicitud repositorios de código completos de tamaño medio, documentos técnicos extensos o actas de reuniones completas, equivalente a unas 750,000 palabras o 200 páginas PDF.
Q8: ¿Qué es el modo xhigh Effort y cuándo usarlo?
"xhigh effort" es el modo de razonamiento de nivel más alto añadido en Opus 4.7, donde el modelo dedica más tokens y tiempo a la reflexión de múltiples pasos y a la autoverificación. Recomendamos activarlo en estos escenarios:
- Diseño de algoritmos complejos (como caché LRU, consistencia distribuida).
- Tareas de refactorización que involucren múltiples archivos.
- Razonamiento matemático que requiera cadenas lógicas de varios pasos.
- Revisión de código crítico y auditoría de vulnerabilidades.
Para chats cotidianos o escritura de CRUD simple, usa high o medium para evitar gastos innecesarios de tokens.
Puntos clave de Claude Opus 4.7
- 🏆 Líder en 7 rankings: SWE-bench Pro 64.3%, Verified 87.6%, GPQA 94.2%, y aventaja a GPT-5.4 por 9.2 puntos en MCP-Atlas.
- 💡 Modo de alto esfuerzo (xhigh Effort): Se añade un modo de razonamiento de nivel superior, ideal para algoritmos complejos y refactorización entre archivos.
- 🚀 Ideal para escenarios de Agentes: Liderazgo total en llamadas a herramientas y Computer Use; es el modelo preferido para IA Agéntica.
- ⚠️ Deficiencias en búsqueda web: En BrowseComp queda 10 puntos por detrás de GPT-5.4, por lo que se recomienda comparar modelos para tareas que requieran búsqueda conectada a internet.
- 💰 Acceso con descuento del 20% en APIYI: El precio oficial se mantiene, pero al recargar desde apiyi.com obtienes un 10% adicional o más, lo que equivale a un ahorro total del 20% aproximadamente.
Resumen
Los datos de evaluación de Claude Opus 4.7 apuntan claramente a una conclusión: es el modelo general más potente para programación y escenarios de agentes en la actualidad. Puntos clave:
- Liderazgo indiscutible en programación: Con un 64.3% en SWE-bench Pro, supera con creces a GPT-5.4 y Gemini 3.1 Pro; es la opción predilecta para tareas de código a nivel de producción.
- Rey en llamadas a herramientas de agentes: Aventaja en 9.2 puntos en MCP-Atlas y 3 puntos en Computer Use, siendo la mejor elección para procesos de automatización.
- Atención a los costes reales: El nuevo tokenizador conlleva un aumento de costes implícito del 20-30%, por lo que es necesario compensarlo con las promociones de recarga en plataformas agregadoras.
Si tu trabajo se centra en la programación con IA, el desarrollo de agentes o tareas de razonamiento complejo, vale la pena migrar a Claude Opus 4.7 de inmediato. Te recomiendo probarlo rápidamente a través de APIYI (apiyi.com): los modelos oficiales están sincronizados, puedes reemplazar la interfaz compatible con OpenAI con un solo clic y disfrutar de un ahorro de hasta el 20% (al recargar 100 USD obtienes un 10% extra o más), evitándote complicaciones con cuentas extranjeras o pagos en dólares.
Lecturas complementarias
Si te interesa el benchmark de Claude Opus 4.7, te recomiendo seguir leyendo:
- 📘 Guía completa de invocación de API de Claude Opus 4.7 – Aprende el uso completo del modo de alto esfuerzo (High Effort Mode), caché de indicaciones (Prompt Caching) y llamadas a herramientas.
- 📊 Comparativa profunda: GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro – Domina la toma de decisiones para elegir entre los tres modelos insignia en diferentes escenarios específicos.
- 🚀 Protocolo MCP y agentes con Claude Opus 4.7 – Explora cómo construir flujos de trabajo de agentes de nivel de producción usando Opus 4.7.
📚 Referencias
-
Anuncio oficial de Anthropic: Introducción al producto Claude Opus 4.7 y datos de benchmark.
- Enlace:
anthropic.com/news/claude-opus-4-7 - Nota: Fuente de datos de primera mano, incluye todos los resultados de las pruebas de referencia oficiales.
- Enlace:
-
Evaluación independiente de VentureBeat: Análisis sobre cómo Opus 4.7 retoma el primer lugar entre los modelos de lenguaje grandes (LLM) de uso general.
- Enlace:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Nota: Perspectiva independiente de terceros con una comparativa integral de Opus 4.7 frente a la competencia.
- Enlace:
-
Interpretación de los benchmarks de Vellum AI: Desglose punto por punto de la metodología y credibilidad de los benchmarks.
- Enlace:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Nota: Ideal para lectores técnicos que deseen comprender a fondo los métodos de pruebas de referencia.
- Enlace:
-
Documentación oficial de la API de Claude: Explicación sobre la ventana de contexto, precios y tokenizador.
- Enlace:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Nota: Referencia autorizada para integración e invocación, incluye guía de migración.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a discutir tu experiencia con Claude Opus 4.7 en la sección de comentarios. Para más información sobre la invocación de API, visita el centro de documentación de APIYI en docs.apiyi.com.