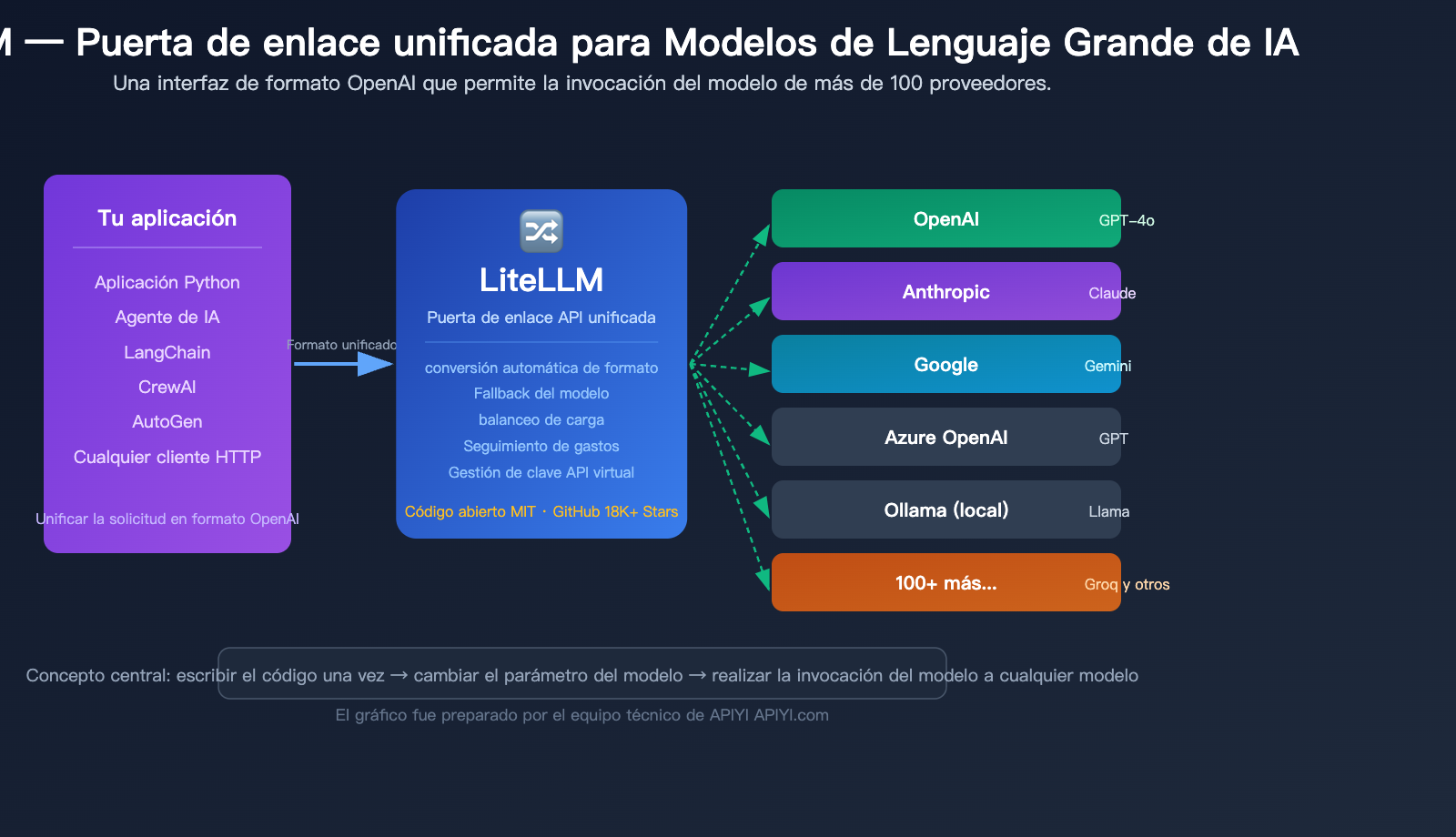
¿Alguna vez te has encontrado con este problema? En tu proyecto utilizas GPT de OpenAI, Claude de Anthropic y Gemini de Google al mismo tiempo, pero cada modelo tiene un SDK diferente, un formato de API distinto e incluso una forma diferente de gestionar los errores. ¿Cada vez que cambias de modelo tienes que reescribir gran parte de tu código?
Eso es exactamente lo que resuelve LiteLLM. En pocas palabras, LiteLLM es el "traductor universal" para los Modelos de Lenguaje Grande: solo necesitas aprender una forma de invocación (el formato de OpenAI) y él se encarga de traducirlo al formato de API específico de más de 100 proveedores de modelos.
Valor principal: Al terminar de leer este artículo, entenderás qué es LiteLLM, por qué los frameworks de agentes de IA lo están utilizando y cómo empezar a usarlo en 5 minutos.
¿Qué es LiteLLM?: 5 conceptos clave
Antes de empezar, entendamos los 5 conceptos fundamentales de LiteLLM de la forma más sencilla posible. Una vez que domines estos conceptos, el resto del trabajo será pan comido.
| Concepto clave | Explicación sencilla | Problema que resuelve |
|---|---|---|
| Interfaz unificada | Todos los modelos se invocan igual | No necesitas aprender un SDK distinto por modelo |
| Provider (Proveedor) | Fabricantes de modelos como OpenAI, Anthropic, etc. | Gestiona las conexiones con distintos proveedores |
| Fallback (Conmutación por error) | Si el modelo A falla, cambia automáticamente al B | Garantiza que el servicio no se interrumpa |
| Virtual Key (Clave virtual) | Entrega "subcuentas" a los miembros del equipo | Controla el uso y el presupuesto |
| Proxy (Pasarela) | Servidor proxy de API independiente | Cualquier lenguaje o herramienta puede conectarse |
¿Qué puntos débiles resuelve LiteLLM?
Imagina un mundo sin LiteLLM:
Llamar a OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hola"}]
)
Llamar a Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic requiere especificarlo
messages=[{"role": "user", "content": "Hola"}]
)
Llamar a Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Hola")
¿Lo ves? Tres modelos, tres SDKs, tres formas de escribir el código. Si tu proyecto necesita cambiar de modelo, el código se llenará de condiciones como if provider == "openai"... elif provider == "anthropic"....
Con LiteLLM:
import litellm
# Llamar a OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Hola"}])
# Llamar a Anthropic — la misma forma
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Hola"}])
# Llamar a Gemini — sigue siendo la misma forma
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Hola"}])
Un solo litellm.completion(), solo cambias el parámetro model. LiteLLM se encarga por detrás de la conversión de formato, la adaptación de parámetros y la estandarización de la respuesta.
🎯 Consejo técnico: La filosofía de interfaz unificada de LiteLLM es similar a APIYI (apiyi.com): ambos permiten invocar múltiples modelos desde una sola interfaz. La diferencia es que LiteLLM es una solución de código abierto para autohospedar, mientras que APIYI es un servicio gestionado que no requiere despliegue. Elige según la capacidad técnica de tu equipo.
Explicación detallada de los dos modos de uso de LiteLLM
LiteLLM ofrece dos modos de uso, adecuados para diferentes escenarios. Entender la diferencia entre ambos es clave para elegir la forma correcta de trabajar.
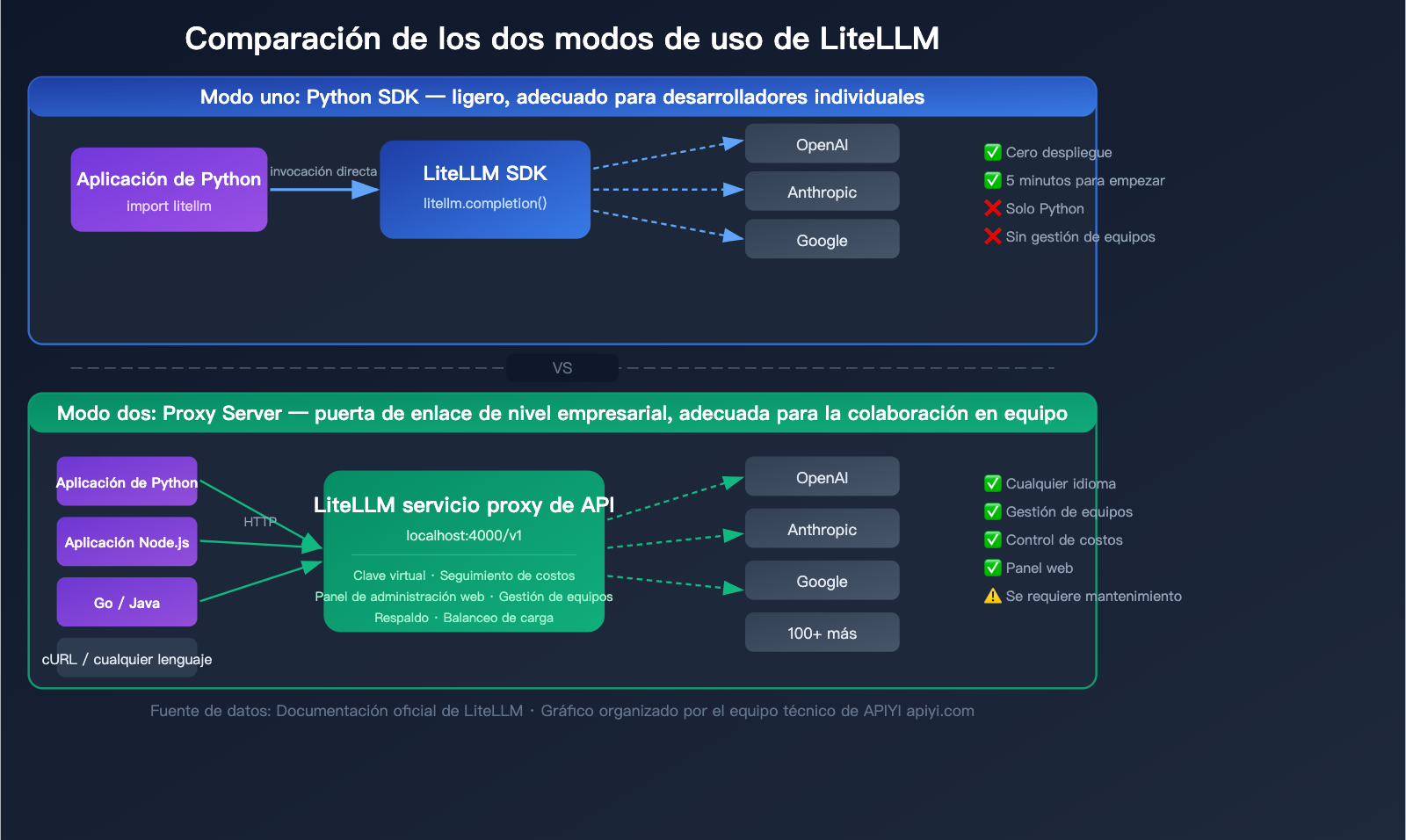
Modo 1: SDK de Python (Ligero)
Importa el paquete litellm directamente en tu código Python y úsalo como si fuera una función.
Escenarios de uso:
- Desarrolladores individuales
- Proyectos puramente en Python
- Validación rápida de prototipos
- No requiere funciones de gestión de equipo
Instalación:
pip install litellm
Uso básico:
import litellm
import os
# Configurar la clave API (a través de variables de entorno)
os.environ["OPENAI_API_KEY"] = "sk-tu-clave"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-tu-clave"
# Invocar cualquier modelo
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Explica qué es una pasarela de API"}]
)
print(response.choices[0].message.content)
Modo 2: Servidor Proxy (Pasarela de nivel empresarial)
Se ejecuta como un servidor independiente que expone una interfaz HTTP compatible con OpenAI. Cualquier lenguaje de programación o herramienta que pueda enviar peticiones HTTP puede usarlo.
Escenarios de uso:
- Colaboración en equipo
- Proyectos multilingües (Java, Go, Node.js, etc.)
- Necesidad de seguimiento de gastos y gestión de presupuestos
- Necesidad de asignar claves virtuales a diferentes equipos
- Integración con marcos de trabajo de Agentes de IA
Instalación y ejecución:
# Instalación
pip install 'litellm[proxy]'
# Iniciar con archivo de configuración
litellm --config config.yaml --port 4000
# O usar Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
Una vez iniciado, cualquier aplicación puede invocarlo como si llamara a OpenAI:
from openai import OpenAI
# Apunta la base_url al Proxy de LiteLLM
client = OpenAI(
api_key="sk-tu-clave-virtual",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hola"}]
)
Comparativa: SDK de LiteLLM vs. Modo Proxy
| Dimensión de comparación | SDK de Python | Servidor Proxy |
|---|---|---|
| Método de instalación | pip install litellm |
pip install 'litellm[proxy]' o Docker |
| Método de invocación | Llamada a función Python | API HTTP (cualquier lenguaje) |
| Configuración | Definida en el código | Archivo de configuración config.yaml |
| Gestión de claves virtuales | No soportado | Soportado, con límites de presupuesto |
| Panel de administración Web | No | Sí, gestión visual |
| Gestión de equipos | No | Soportado (usuarios/equipos/presupuestos) |
| Seguimiento de gastos | Básico (a nivel de código) | Completo (persistencia en base de datos) |
| Complejidad de despliegue | Cero | Requiere mantenimiento de servidor |
| Público objetivo | Desarrolladores individuales | Equipos / Empresas |
💡 Recomendación: Si eres un desarrollador individual haciendo prototipos, el modo SDK estará listo en 5 minutos. Si trabajas en equipo o en un entorno de producción, el modo Proxy es más adecuado. Por supuesto, si no quieres desplegar ni mantener servidores, también puedes usar directamente servicios de interfaz unificada gestionada como APIYI (apiyi.com), listos para usar desde el primer momento.
Tutorial rápido de LiteLLM
Aquí tienes los pasos completos para empezar a usar LiteLLM desde cero.
Inicio rápido con el SDK de LiteLLM
Paso 1: Instalación
pip install litellm
Paso 2: Configurar variables de entorno
# macOS / Linux
export OPENAI_API_KEY="sk-tu-clave"
export ANTHROPIC_API_KEY="sk-ant-tu-clave"
# Windows
set OPENAI_API_KEY=sk-tu-clave
Paso 3: Escribir el código
import litellm
# Invocación básica
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Eres un asistente técnico"},
{"role": "user", "content": "¿Qué es una puerta de enlace de LLM?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Uso de tokens: {response.usage.total_tokens}")
print(f"Costo estimado: ${response._hidden_params.get('response_cost', 'N/A')}")
Ver código completo: con Fallback y salida en streaming
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-tu-clave"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-tu-clave"
# Invocación con Fallback: si GPT-4o falla, cambia automáticamente a Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Explica qué es una API RESTful"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Salida en streaming
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Escribe un poema sobre programación"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
Inicio rápido con el modo Proxy de LiteLLM
Paso 1: Crear el archivo de configuración config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Paso 2: Iniciar el Proxy
litellm --config config.yaml --port 4000
Paso 3: Realizar la invocación del modelo usando el SDK estándar de OpenAI
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Invocar GPT-4o (a través del Proxy de LiteLLM)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hola"}]
)
print(response.choices[0].message.content)
También puedes usar cURL directamente:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hola"}]
}'
🚀 Inicio rápido: El Proxy de LiteLLM requiere que gestiones tu propio servidor y clave API. Si prefieres usar una interfaz unificada sin necesidad de despliegue, prueba APIYI (apiyi.com), que también admite el formato compatible con OpenAI para más de 100 modelos, sin necesidad de configurar ninguna infraestructura.
El papel fundamental de LiteLLM en los agentes de IA
Esta es una pregunta común entre los principiantes: ¿por qué casi todos los marcos de trabajo de agentes de IA admiten o incluso recomiendan usar LiteLLM?
¿Por qué los agentes de IA necesitan LiteLLM?
Los agentes de IA a menudo necesitan:
- Invocar diferentes modelos: usar modelos pequeños y económicos para tareas simples y modelos grandes para razonamientos complejos.
- Degradación automática: cambiar automáticamente a un modelo de respaldo cuando el principal alcanza su límite de velocidad o se cae.
- Control de costos: rastrear y limitar el gasto de tokens de forma unificada cuando varios agentes se ejecutan en paralelo.
- Colaboración en equipo: compartir un grupo de recursos de clave API entre diferentes desarrolladores.
LiteLLM resuelve estas necesidades perfectamente, actuando como el "centro de despacho" entre el agente y el modelo.
Integración de LiteLLM con los principales marcos de trabajo de agentes de IA
| Marco de trabajo de agentes | Método de integración | Uso típico |
|---|---|---|
| LangChain / LangGraph | Soporte nativo en SDK | ChatLiteLLM como backend de LLM |
| CrewAI | Conexión vía Proxy | Grupo de recursos de modelos compartido |
| AutoGen (Microsoft) | Conexión vía Proxy | Acceso mediante endpoint compatible con OpenAI |
| Dify | Proveedor personalizado | Configurado como endpoint compatible con OpenAI |
| Open WebUI | Conexión vía Proxy | Endpoint de API backend |
| Aider | Conexión vía Proxy | Capa de modelo para agentes de generación de código |
| Continue.dev | Conexión vía Proxy | Backend para asistente de codificación en IDE |
Arquitectura típica de LiteLLM en sistemas multi-agente
En un sistema multi-agente, el Proxy de LiteLLM suele funcionar así:
- Agente de planificación → Invoca a Claude Opus (modelo de razonamiento potente)
- Agente de ejecución → Invoca a GPT-4o (rendimiento equilibrado)
- Agente de validación → Invoca a GPT-4o-mini (rápido y de bajo costo)
- Agente de resumen → Invoca a Gemini Flash (ventana de contexto grande)
Todos los agentes invocan a través del mismo endpoint del Proxy de LiteLLM, el cual enruta automáticamente al modelo backend correcto. Los administradores pueden ver el uso de tokens y los costos de todos los agentes de forma unificada a través del panel de control.
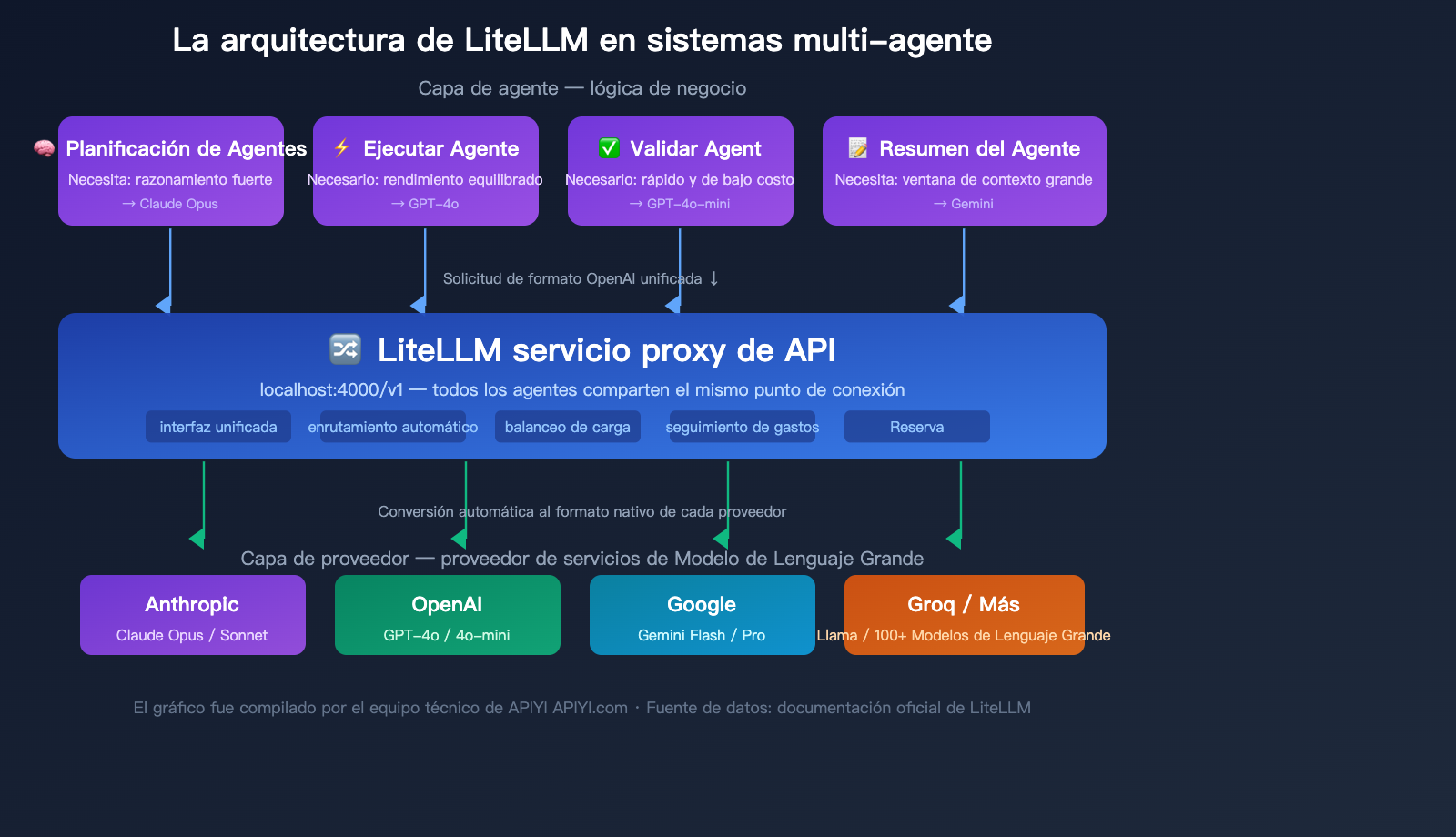
🎯 Consejo técnico: En sistemas multi-agente en producción, el Proxy de LiteLLM debe combinarse con PostgreSQL y Redis para utilizar completamente las funciones de seguimiento de costos y caché. Si tu equipo es pequeño o no deseas gestionar infraestructura adicional, APIYI (apiyi.com) ofrece capacidades de interfaz unificada similares, con seguimiento de costos y estadísticas de uso integrados, sin necesidad de desplegar bases de datos adicionales.
Análisis detallado de las funciones avanzadas de LiteLLM
Una vez que dominas el uso básico, estas 3 funciones avanzadas son las más utilizadas en entornos de producción.
Función avanzada 1: Fallback (conmutación por error) de modelos
Cuando el modelo principal sufre limitaciones de velocidad, tiempos de espera o errores, LiteLLM cambia automáticamente a un modelo de respaldo, garantizando que el servicio no se interrumpa.
Configuración de Fallback en el SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Lógica de ejecución: primero intenta con GPT-4o → si falla, prueba con Claude Sonnet → si vuelve a fallar, prueba con Gemini Flash.
Configuración de Fallback en el Proxy (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Función avanzada 2: Balanceo de carga
Puedes configurar múltiples despliegues de backend para el mismo nombre de modelo, y LiteLLM distribuirá las solicitudes automáticamente.
model_list:
# Mismo nombre de modelo, dos backends diferentes
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Prioridad al menos ocupado
# Otras estrategias: simple-shuffle, latency-based
Al realizar la llamada, solo necesitas especificar model="gpt-4o", y LiteLLM distribuirá el tráfico entre la conexión directa de OpenAI y el despliegue de Azure.
Función avanzada 3: Seguimiento de costos y claves virtuales
Generación de claves virtuales (modo Proxy):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Esto genera una clave virtual con un presupuesto mensual máximo de 50 USD, restringida únicamente al uso de GPT-4o y Claude Sonnet.
Seguimiento de costos:
LiteLLM tiene integradas las tablas de precios de varios modelos y calcula automáticamente el costo de cada invocación de API. Puedes consultarlo en el panel de gestión del Proxy:
- Gasto total por modelo.
- Detalle de gastos por usuario/equipo.
- Tendencias de costos por periodos de tiempo.
- Estadísticas de uso de tokens.
💰 Optimización de costos: La función de seguimiento de costos de LiteLLM te ayuda a identificar qué invocaciones de modelos son las más costosas. Al combinarlo con las ventajas de precios de APIYI (apiyi.com), puedes obtener tarifas más competitivas para las mismas llamadas, reduciendo aún más los costos operativos de tus aplicaciones de IA.
Resumen de los más de 100 proveedores de modelos compatibles con LiteLLM
LiteLLM admite una enorme cantidad de proveedores. Aquí tienes las categorías más utilizadas:
| Categoría | Proveedor | Prefijo del modelo | Modelos representativos |
|---|---|---|---|
| Modelos comerciales | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Plataformas en la nube | Azure OpenAI | azure/ |
Serie GPT desplegada en Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama alojados en Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini alojado en Vertex | |
| Aceleración de inferencia | Groq | groq/ |
Llama 3.1 70B (inferencia ultrarrápida) |
| Together AI | together_ai/ |
Varios modelos de código abierto | |
| Fireworks AI | fireworks_ai/ |
Inferencia de alto rendimiento | |
| Despliegue local | Ollama | ollama/ |
Llama/Mistral ejecutados localmente |
| vLLM | openai/ (base personalizada) |
Motor de inferencia autohospedado | |
| Modelos nacionales | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Búsqueda mejorada | Perplexity | perplexity/ |
Sonar Pro |
| Plataformas agregadoras | OpenRouter | openrouter/ |
Varios modelos |
🎯 Consejo de selección: La elección del modelo depende del caso de uso específico. Si no estás seguro de cuál usar, puedes probar rápidamente el rendimiento de diferentes modelos a través de la plataforma APIYI (apiyi.com), la cual también admite llamadas mediante la interfaz compatible con OpenAI para la mayoría de los modelos mencionados.

Preguntas frecuentes (FAQ) sobre LiteLLM
Q1: ¿Cuál es la diferencia entre LiteLLM y usar directamente el SDK de OpenAI?
El SDK de OpenAI solo permite invocar modelos de OpenAI. LiteLLM extiende las capacidades del SDK de OpenAI, permitiéndote usar el mismo formato de código para invocar a más de 100 proveedores de modelos como Anthropic, Google, Azure, entre otros. Si tu proyecto solo utiliza modelos de OpenAI, el SDK de OpenAI es suficiente. Sin embargo, si necesitas soporte para múltiples modelos, tolerancia a fallos o control de costos, LiteLLM es una mejor opción.
Q2: ¿Es LiteLLM gratuito?
Las funciones principales de LiteLLM son completamente de código abierto y gratuitas (bajo licencia MIT). Pero ten en cuenta lo siguiente: LiteLLM en sí es gratuito, pero las API de los modelos que invoca requieren pago. Debes obtener tus propias claves API de OpenAI, Anthropic, etc., y pagar por la invocación del modelo. Si no quieres gestionar múltiples claves API por separado, también puedes usar plataformas de interfaz unificada como APIYI (apiyi.com) para simplificar la gestión de claves.
Q3: ¿Qué configuración de servidor requiere el Proxy de LiteLLM?
El Proxy de LiteLLM es muy ligero; puede ejecutarse en un servidor con 1 núcleo y 1 GB de RAM. Sin embargo, si necesitas funciones completas (seguimiento de costos, gestión de claves virtuales), también necesitarás una base de datos PostgreSQL y Redis. Para entornos de producción, se recomienda al menos 2 núcleos, 4 GB de RAM, PostgreSQL y Redis.
Q4: ¿Cuál es la diferencia entre LiteLLM y OpenRouter?
La mayor diferencia es que LiteLLM es una solución de código abierto para autohospedaje, mientras que OpenRouter es un servicio gestionado.
- LiteLLM: Gratuito, lo despliegas tú mismo, gestionas tus propias claves API y controlas totalmente el flujo de datos.
- OpenRouter: Listo para usar, pero aplica un sobrecoste en los precios de invocación de API y los datos pasan por un tercero.
Si valoras la privacidad de los datos o tienes tus propias claves API, elige LiteLLM. Si buscas una solución rápida sin despliegue, considera opciones gestionadas como APIYI (apiyi.com).
Q5: ¿LiteLLM admite salida en streaming?
Sí, lo admite. Tanto en el modo SDK como en el modo Proxy, LiteLLM es totalmente compatible con la salida en streaming SSE. Las respuestas en streaming de todos los proveedores se convierten uniformemente a fragmentos (chunks) con formato de OpenAI, garantizando una experiencia de streaming consistente.
# Ejemplo de uso de streaming
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Escribe una historia"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: ¿Debería un principiante elegir el modo SDK o el modo Proxy?
Si eres un desarrollador de Python y estás empezando, el modo SDK es el más sencillo: pip install litellm y con unas pocas líneas de código ya puedes empezar. Cuando necesites colaboración en equipo, integración multilingüe o despliegue en producción, puedes migrar al modo Proxy. El método principal de invocación es idéntico en ambos modos, por lo que el costo de migración es muy bajo.
Q7: ¿Dónde se coloca el archivo de configuración config.yaml de LiteLLM?
No tiene una ubicación fija. Al iniciar el Proxy, simplemente especifica la ruta mediante el parámetro --config:
litellm --config /ruta/a/tu/config.yaml
Por lo general, se recomienda colocarlo en el directorio raíz del proyecto o en una carpeta de configuración dedicada. Si utilizas Docker para el despliegue, puedes montarlo en el contenedor mediante volúmenes.
Guía de decisión rápida para LiteLLM
Elige la solución más adecuada según tu situación:
| Tu situación | Solución recomendada | Motivo |
|---|---|---|
| Desarrollador individual, proyecto en Python | LiteLLM SDK | Sin despliegue, listo en 5 minutos |
| Desarrollo en equipo, requiere control de presupuesto | LiteLLM Proxy | Claves virtuales + seguimiento de costos |
| No quieres gestionar infraestructura propia | APIYI (apiyi.com) | Servicio gestionado, listo para usar |
| Sistema multi-agente | LiteLLM Proxy | Enrutamiento unificado + balanceo de carga |
| Solo usas modelos de OpenAI | SDK de OpenAI directo | Sin capas adicionales |
| Prioridad en la privacidad de datos | Autohospedaje de LiteLLM | Los datos no pasan por terceros |
Resumen
LiteLLM es una herramienta de infraestructura sumamente útil en el desarrollo de aplicaciones de IA. Su valor fundamental se resume en una frase: utiliza un único formato de código compatible con OpenAI para invocar las API de más de 100 proveedores de modelos.
Para quienes están empezando, tengan en cuenta estos puntos clave:
- LiteLLM es un "traductor": Te ayuda a traducir solicitudes con un formato unificado al formato de API específico de cada modelo.
- Dos modos de uso: SDK (paquete ligero de Python) y Proxy (servidor de puerta de enlace independiente).
- Valor central: Interfaz unificada + Fallback + balanceo de carga + seguimiento de costos.
- Estándar en frameworks de agentes: LangChain, CrewAI, AutoGen y otros son casi totalmente compatibles con LiteLLM.
- Completamente de código abierto y gratuito: Bajo licencia MIT, sin costos adicionales por autohospedaje.
Si consideras que los costos de mantenimiento de autohospedar un Proxy de LiteLLM son elevados, también puedes utilizar servicios de interfaz unificada gestionados como APIYI (apiyi.com). Con ellos, lograrás el mismo efecto de usar una sola clave API para invocar todos los modelos principales, ahorrándote la carga de la implementación y el mantenimiento.
Autor del artículo: Equipo técnico de APIYI
Intercambio técnico: Visita APIYI en apiyi.com para obtener más tutoriales sobre la invocación del Modelo de Lenguaje Grande y soporte técnico.
Fecha de actualización: Abril de 2026
Versión aplicable: LiteLLM v1.x+
Referencias:
- Documentación oficial de LiteLLM: docs.litellm.ai
- Repositorio de GitHub de LiteLLM: github.com/BerriAI/litellm
- Sitio web oficial de LiteLLM: litellm.ai
- Sitio web de BerriAI: berri.ai