La serie Grok 4.20 Beta de xAI ya está disponible en la plataforma APIYI. Hemos añadido 4 nuevos modelos de una sola vez, cubriendo desde respuestas rápidas hasta investigación profunda con múltiples agentes. Con un precio de $2 por millón de tokens de entrada y $6 por millón de tokens de salida, se posiciona como una de las opciones con mejor relación calidad-precio entre los modelos insignia actuales.
Estos 4 modelos no son solo una actualización de versión, sino cambios a nivel de arquitectura: algunos buscan una respuesta ultrarrápida, otros se enfocan en el razonamiento profundo, e incluso hay uno que permite que 4 agentes de IA colaboren simultáneamente, reduciendo la tasa de alucinaciones en un 65%.
Valor principal: Al terminar de leer este artículo, entenderás el posicionamiento y los mejores casos de uso de cada uno de los 4 modelos Grok 4.20 Beta, aprenderás cómo realizar llamadas a la API y podrás tomar la mejor decisión de selección de modelos.
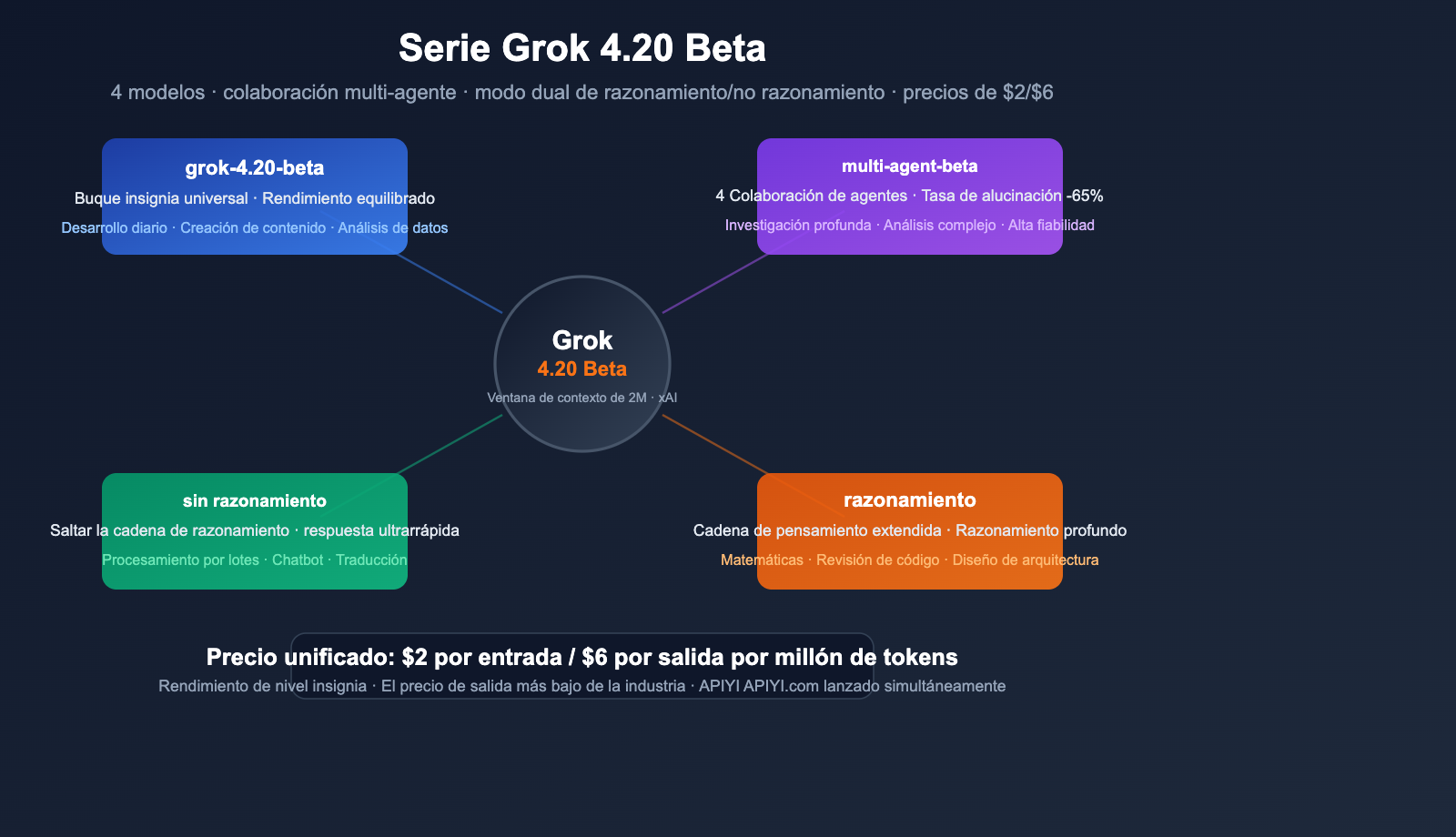
Un vistazo a los 4 modelos: Diferencias clave
Matriz de modelos
| ID del modelo | Posicionamiento | Características principales | Mejor escenario |
|---|---|---|---|
grok-4.20-beta |
Insignia general | Equilibrio entre rendimiento y velocidad | Desarrollo diario, tareas generales |
grok-4.20-multi-agent-beta-0309 |
Colaboración multi-agente | 4 agentes trabajando en paralelo | Investigación profunda, análisis complejo |
grok-4.20-beta-0309-non-reasoning |
Respuesta rápida | Omite la cadena de razonamiento, baja latencia | Procesamiento por lotes, preguntas simples |
grok-4.20-beta-0309-reasoning |
Razonamiento profundo | Cadena de pensamiento extendida | Matemáticas, análisis de código, lógica |
Precios unificados
| Concepto | Precio |
|---|---|
| Token de entrada | $2.00 / millón de tokens |
| Token de salida | $6.00 / millón de tokens |
| Ventana de contexto | 2 millones de tokens (2M) |
| Descuento por lotes | 50% |
Comparativa de precios con la competencia:
| Modelo | Precio entrada | Precio salida | Relación calidad-precio |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 Óptima |
| Gemini 3.1 Pro | $2.00 | $12.00 | Buena |
| GPT-5.4 | $2.50 | $15.00 | Regular |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Regular |
| Claude Opus 4.6 | $15.00 | $75.00 | Alta |
El precio de salida de Grok 4.20 es solo el 40% del de Claude Sonnet 4.6 y el 8% del de Claude Opus 4.6. Para tareas intensivas en salida (generación de código, textos largos), la ventaja en costos es extremadamente significativa.
🎯 Nota sobre precios: El precio de la serie Grok 4.20 Beta disponible en APIYI (apiyi.com) es idéntico al del sitio oficial de xAI ($2 entrada / $6 salida), y los descuentos se aplican mediante las promociones de recarga de la plataforma. Con una sola clave API puedes invocar más de 200 modelos, incluyendo Grok, Claude, GPT, entre otros.
Análisis profundo de 4 modelos
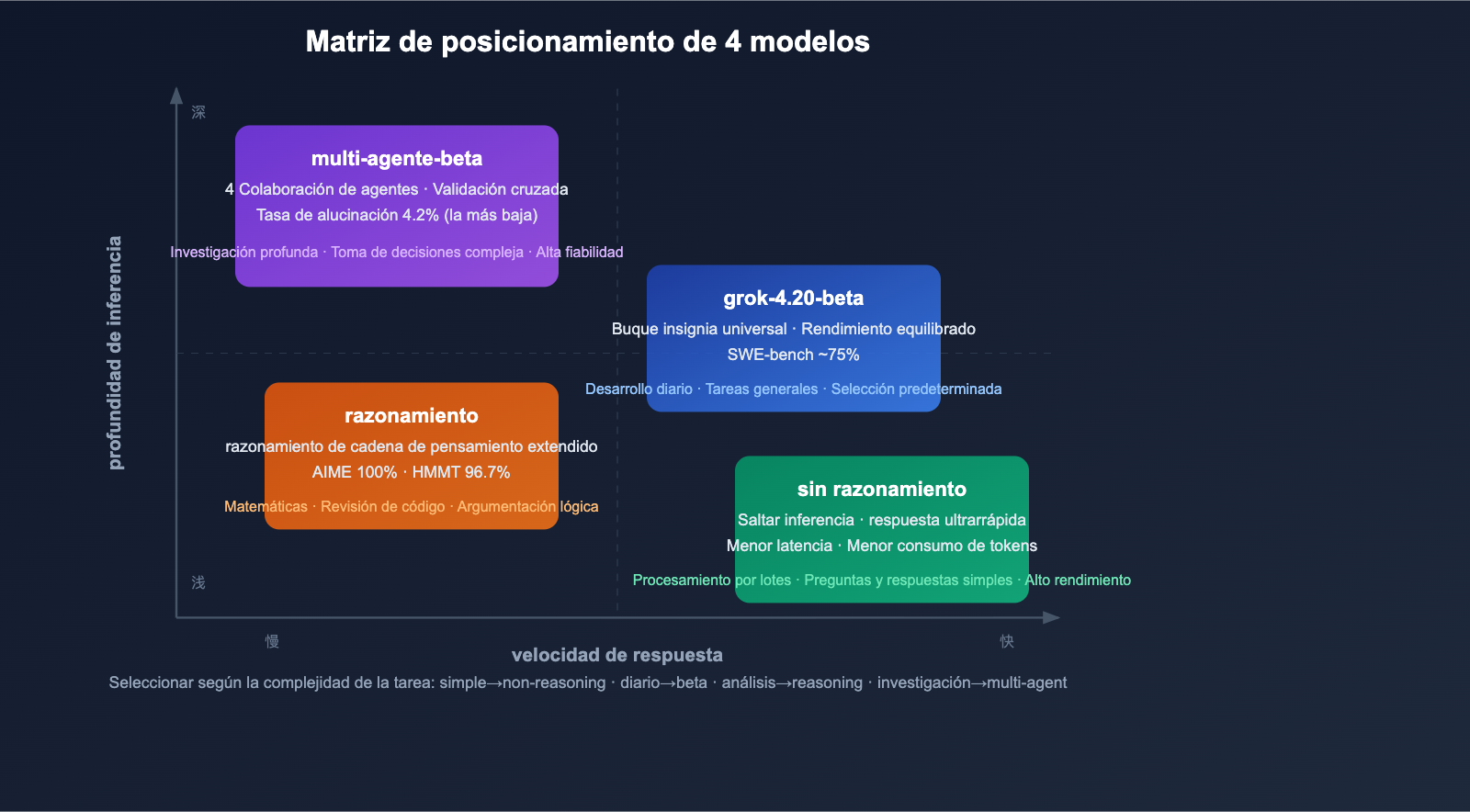
Modelo 1: grok-4.20-beta (Buque insignia general)
Esta es la puerta de entrada predeterminada de la serie Grok 4.20, que equilibra rendimiento, velocidad y coste.
Características principales:
- Hereda todas las capacidades de la familia Grok 4.
- Ventana de contexto de 2 millones de tokens, la más grande entre los modelos de vanguardia occidentales.
- Soporte para entrada de imágenes (JPG/PNG).
- Mejora continua semanal basada en comentarios del mundo real.
Rendimiento de referencia:
- SWE-bench: ~75% (cerca del 74.9% de GPT-5).
- GPQA (nivel de posgrado): 88.4%.
- Arena Elo: ~1,505-1,535.
Escenarios de uso: Asistencia diaria en programación, creación de contenido, análisis de datos, diálogo general.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implementa una caché LRU en Python"}
]
)
print(response.choices[0].message.content)
Modelo 2: grok-4.20-multi-agent-beta-0309 (Multimodal/Multi-agente)
Esta es la variante más innovadora de Grok 4.20: 4 agentes de IA colaborando simultáneamente para procesar tu solicitud.
Los 4 agentes y sus funciones:
| Agente | Rol | Especialidad |
|---|---|---|
| Grok (Líder) | Coordinador | Desglose de tareas, gestión de flujo, agregación de resultados |
| Harper | Investigador | Búsqueda de datos en tiempo real, verificación de hechos (acceso a datos de X/Twitter) |
| Benjamin | Analista | Razonamiento lógico, cálculos matemáticos, análisis de código |
| Lucas | Desafiante | Síntesis creativa, postura de oposición integrada: cuestiona las conclusiones de otros agentes |
Flujo de trabajo:
Pregunta del usuario
↓
Grok desglosa la tarea → Asigna a los 4 agentes
↓
Harper recopila datos | Benjamin analiza lógica | Lucas desafía y cuestiona
↓
Debate interno entre agentes + verificación cruzada
↓
Grok agrega el consenso → Devuelve la respuesta final
Punto fuerte: reducción del 65% en la tasa de alucinaciones:
| Métrica | Línea base (modelo único) | Modo multi-agente | Mejora |
|---|---|---|---|
| Tasa de alucinación | ~12% | ~4.2% | Reducción del 65% |
| Tasa de "decir no sé cuando no está seguro" | — | 78% | La más alta del sector |
La "postura de oposición integrada" de Lucas es el diseño clave: su trabajo es encontrar fallos en las conclusiones de los demás. Esta colaboración adversaria hace que el resultado final sea mucho más fiable.
Escenarios de uso: Informes de investigación profunda, análisis de decisiones complejas, resultados que requieren alta fiabilidad.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analiza el panorama competitivo y las tendencias del mercado de herramientas de programación con IA para 2026"}
]
)
Modelo 3: grok-4.20-beta-0309-non-reasoning (Sin razonamiento)
Esta es la variante optimizada para velocidad y rendimiento. Omite la cadena de pensamiento (Chain-of-Thought) interna y genera la respuesta directamente.
Características principales:
- Baja latencia, alto rendimiento.
- No genera tokens de razonamiento interno, ahorrando costes de salida.
- Ideal para tareas sencillas y claras.
Escenarios de uso:
- Llamadas API de alta frecuencia (procesamiento de datos por lotes).
- Chatbots / Sistemas de atención al cliente.
- Clasificación de contenido, extracción de etiquetas.
- Autocompletado de código sencillo.
- Traducción, resúmenes.
No recomendado para: Deducciones matemáticas complejas, análisis lógico de varios pasos, diseño de arquitectura que requiera pensamiento profundo.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Convierte el siguiente JSON a formato CSV: ..."}
]
)
Modelo 4: grok-4.20-beta-0309-reasoning (Con razonamiento)
Esta es la variante de razonamiento profundo, opuesta a la versión sin razonamiento. Habilita una cadena de pensamiento extendida (Extended Chain-of-Thought) para realizar un razonamiento interno profundo antes de responder.
Características principales:
- Tokens de razonamiento extendidos para un análisis profundo del problema.
- Rendimiento excelente en tareas matemáticas y lógicas (AIME 2025: 100%, HMMT25: 96.7%).
- Índice de inteligencia de Artificial Analysis: 48.
Escenarios de uso:
- Demostraciones y deducciones matemáticas.
- Revisión de código y análisis de errores (bugs).
- Evaluación de compensaciones en diseño de arquitectura.
- Argumentación lógica compleja.
- Análisis de artículos académicos.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analiza las posibles condiciones de carrera y riesgos de interbloqueo (deadlock) en este código concurrente"}
]
)
💡 Consejo de selección: Para la mayoría de las tareas diarias,
grok-4.20-betaes suficiente. Usa la versión multi-agente para resultados de alta fiabilidad, la versión sin razonamiento para procesamiento por lotes y la versión con razonamiento para análisis complejos. Con una sola clave API de APIYI (apiyi.com), puedes invocar los 4 modelos y cambiar entre ellos según tus necesidades.
Árbol de decisión para la selección de modelos
Selección por tipo de tarea
| Tipo de tarea | Modelo recomendado | Razón |
|---|---|---|
| Asistencia en programación diaria | grok-4.20-beta |
Equilibrio entre rendimiento y coste |
| Procesamiento de datos por lotes | non-reasoning |
Mayor velocidad, menor latencia |
| Revisión de código / Análisis de errores | reasoning |
Requiere razonamiento profundo |
| Redacción de informes de investigación | multi-agent |
Validación cruzada con 4 agentes |
| Análisis de datos en tiempo real | multi-agent |
Harper accede a datos de X en tiempo real |
| Deducción matemática/lógica | reasoning |
100% de aciertos en AIME |
| Chatbot | non-reasoning |
Respuesta rápida con baja latencia |
| Traducción/Resumen de contenido | non-reasoning |
Tareas simples sin necesidad de razonamiento |
| Diseño de arquitectura | reasoning o multi-agent |
Requiere análisis de compensaciones |
Selección por sensibilidad al coste
Ahorro máximo → non-reasoning (sin tokens de razonamiento, salida mínima)
↓
Relación calidad-precio diaria → grok-4.20-beta (equilibrio general)
↓
Calidad prioritaria → reasoning (razonamiento profundo, más tokens de salida)
↓
Máxima fiabilidad → multi-agent (4 agentes, salida más detallada)
🚀 Inicio rápido: Recomendamos empezar probando
grok-4.20-beta. Regístrate a través de APIYI en apiyi.com para obtener tu clave API. Los precios son idénticos a los del sitio oficial de xAI ($2 entrada / $6 salida), con descuentos adicionales en promociones de recarga.
Comparativa: Grok 4.20 vs Modelos principales
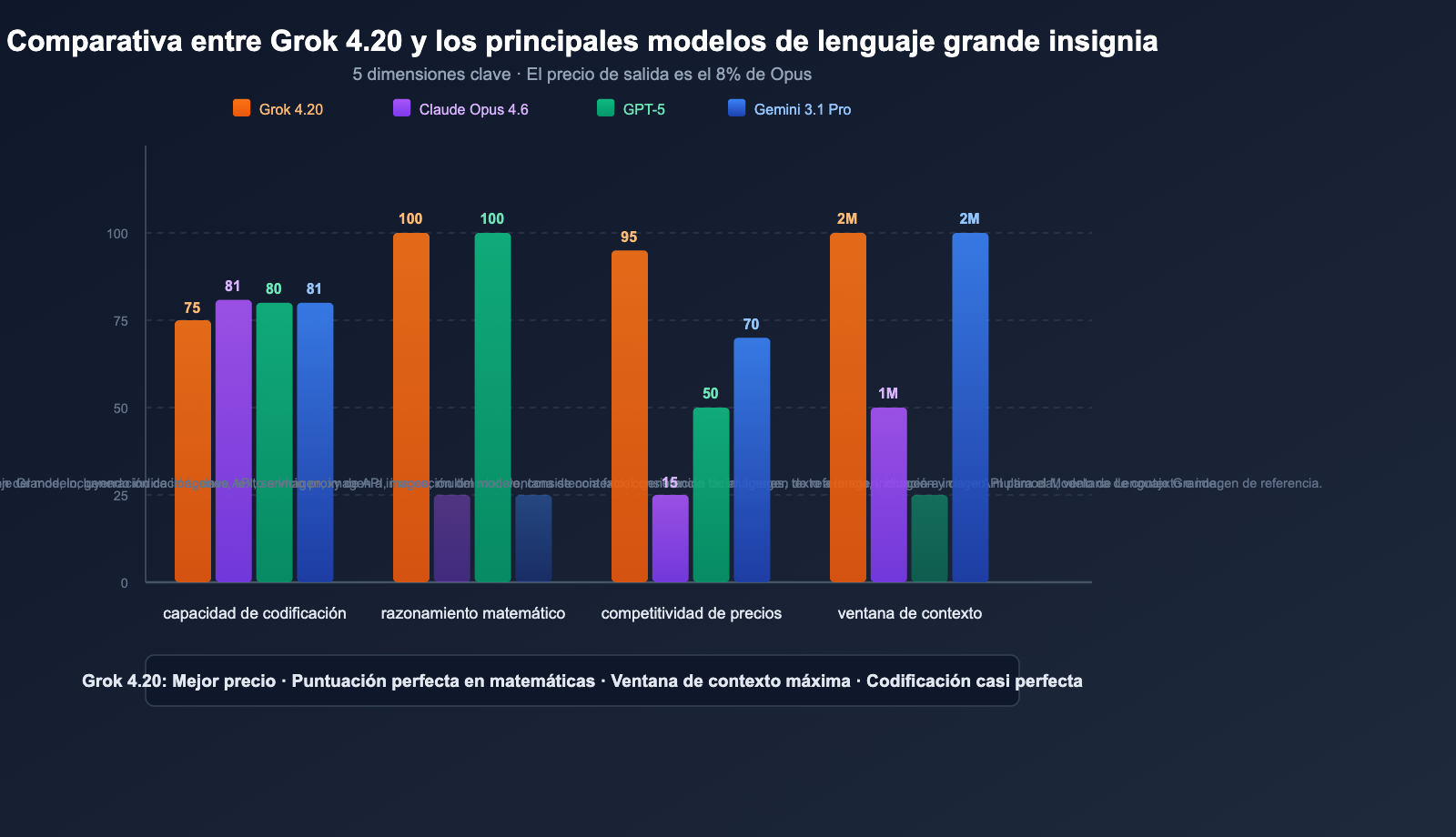
Comparativa completa
| Dimensión | Grok 4.20 Beta | Claude Opus 4.6 | Serie GPT-5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| Matemáticas (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| Contexto | 2 Millones | 1 Millón | Varía según modelo | 2 Millones |
| Precio entrada | $2 | $15 | $2.50 | $2 |
| Precio salida | $6 | $75 | $15 | $12 |
| Multi-agente | ✅ 4 Agentes | ❌ | ❌ | ❌ |
| Datos en tiempo real | ✅ X/Twitter | ❌ | ✅ Búsqueda | ✅ Búsqueda |
| Control de alucinaciones | 4.2% (mínimo) | Bajo | Bajo | Medio |
| Entrada de imagen | ✅ JPG/PNG | ✅ Multiformato | ✅ Multiformato | ✅ Multiformato |
Mejores escenarios por modelo
- Grok 4.20: Uso general de alta rentabilidad, investigación profunda (multi-agente), análisis de datos en tiempo real.
- Claude Opus 4.6: Ingeniería de software (líder en SWE-bench), salidas ultra largas (128K), seguridad empresarial.
- GPT-5: Matemáticas, automatización de escritorio, ecosistema de usuarios más amplio.
- Gemini 3.1 Pro: Integración con el ecosistema Google, 2 millones de contexto, coste moderado.
💰 Análisis de rentabilidad: El precio de salida de Grok 4.20 ($6/MTok) es solo el 8% del de Claude Opus 4.6 ($75/MTok). Para tareas intensivas en salida (generación de código largo, informes de investigación), usar Grok 4.20 puede reducir los costes en más de un 90%. A través de APIYI (apiyi.com) puedes acceder a toda la gama de modelos Grok, Claude y GPT, cambiando de uno a otro según las necesidades de tu tarea.
Práctica de invocación de API
Ejemplo de invocación básica
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Tarea general → Versión básica
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Eres un desarrollador Python experimentado."},
{"role": "user", "content": "Implementa una cola de tareas asíncrona"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Selección automática según la tarea
def choose_grok_model(task_type):
"""Selecciona automáticamente el mejor modelo Grok según el tipo de tarea"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Ejemplo de uso
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analiza los cuellos de botella de rendimiento de este código..."}]
)
Ver código de prueba comparativa entre modelos
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implementa una ordenación rápida (quicksort) en Python y analiza su complejidad temporal"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Tiempo: {elapsed:.1f}s | Tokens: {tokens}")
print(f" Vista previa: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Error: {e}")
time.sleep(1)
🎯 Consejo práctico: Te recomiendo ejecutar primero una prueba de referencia con
grok-4.20-betay luego comparar la calidad de salida en tareas complejas con la versiónreasoning. Al realizar la invocación del modelo a través de APIYI (apiyi.com) para los 4 modelos, los precios son idénticos a los del sitio oficial, y los descuentos se aplican mediante promociones de recarga.
Preguntas frecuentes
Q1: ¿Tienen los 4 modelos el mismo precio?
Sí, los 4 modelos tienen un precio unificado: $2 por entrada / $6 por salida por cada millón de tokens. Sin embargo, el costo real varía según el modelo: los modelos de razonamiento generan más tokens de razonamiento (contabilizados como salida), y la versión multi-agente puede consumir más tokens debido a la colaboración de los 4 agentes. La versión sin razonamiento es la más económica, ya que omite la cadena de razonamiento y genera menos tokens de salida. La facturación a través de APIYI (apiyi.com) es igual a la del sitio oficial de xAI, con descuentos disponibles en las recargas de la plataforma.
Q2: ¿Cuál es la diferencia entre la versión multi-agente y la versión de razonamiento?
La versión de razonamiento consiste en un único agente que realiza un pensamiento profundo, ideal para tareas de análisis con respuestas claras (matemáticas, revisión de código). La versión multi-agente utiliza 4 agentes que colaboran y debaten, lo que la hace perfecta para problemas abiertos que requieren análisis desde múltiples perspectivas (investigación de mercado, análisis de decisiones). La ventaja principal de la versión multi-agente es la validación cruzada, que reduce la tasa de alucinaciones (del 12% al 4.2%).
Q3: ¿Puede Grok 4.20 reemplazar a Claude para la revisión de código?
En algunos escenarios, sí. La versión de razonamiento de Grok 4.20 alcanza ~75% en SWE-bench, por debajo del 81.4% de Claude Opus 4.6, pero su precio es solo el 8% de este último. Para revisiones de código diarias que no sean críticas para la seguridad, Grok 4.20 es una opción de alta rentabilidad. Para auditorías de seguridad y revisiones de arquitectura a gran escala, Claude Opus 4.6 sigue siendo más fiable. A través de APIYI (apiyi.com) puedes integrar ambos modelos y cambiar entre ellos según la tarea.
Q4: ¿Qué utilidad práctica tiene una ventana de contexto de 2 millones de tokens?
2 millones de tokens equivalen aproximadamente a un libro técnico de 1500 páginas. Aplicaciones prácticas: (1) Cargar de una sola vez todo un repositorio de código mediano o grande para su análisis; (2) Procesar documentos extremadamente largos (contratos legales, colecciones de artículos académicos); (3) Mantener una memoria de conversación muy extensa. Es actualmente la ventana de contexto más grande entre los modelos de vanguardia occidentales.
Q5: ¿Cómo invocar estos modelos en la plataforma APIYI?
Tras registrarte en apiyi.com y obtener tu clave API, solo tienes que usar el formato compatible con OpenAI. Configura la base_url como https://api.apiyi.com/v1 y el model con el ID correspondiente (por ejemplo, grok-4.20-beta). Consulta los ejemplos de código anteriores. El precio de los 4 modelos es igual al oficial, y los descuentos se aplican mediante promociones de recarga.
Resumen: Estrategias óptimas de uso para los 4 modelos
La serie Grok 4.20 Beta ofrece una selección de modelos precisa para diferentes escenarios. La estrategia central consiste en hacer coincidir el modelo con la complejidad de la tarea:
| Complejidad | Modelo recomendado | Costo |
|---|---|---|
| 🟢 Simple/Alta frecuencia | non-reasoning |
El más bajo |
| 🟡 Uso general diario | grok-4.20-beta |
Moderado |
| 🟠 Análisis profundo | reasoning |
Más alto |
| 🔴 Máxima fiabilidad | multi-agent |
El más alto |
El esquema de precios de $2/$6 convierte a Grok 4.20 en el modelo insignia con el costo de salida más bajo del mercado actual. Gracias a su ventana de contexto de 2 millones de tokens y su sistema multi-agente, resulta extremadamente competitivo en tareas de investigación, análisis y escenarios de alto rendimiento.
Recomendamos acceder a toda la serie de modelos Grok 4.20 Beta a través de APIYI (apiyi.com), donde ofrecemos una integración integral. Los precios son idénticos a los del sitio oficial y los descuentos se aplican mediante promociones de recarga. Con una sola clave API, puedes invocar más de 200 modelos, incluyendo Grok, Claude, GPT y otros.
Referencias
-
Documentación oficial de xAI: Modelos Grok y explicación de precios
- Enlace:
docs.x.ai/developers/models
- Enlace:
-
Artificial Analysis: Evaluación comparativa de Grok 4.20 Beta
- Enlace:
artificialanalysis.ai/models/grok-4-20
- Enlace:
-
Documentación multi-agente de xAI: Detalles sobre las capacidades Multi-Agent
- Enlace:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Enlace:
-
OpenRouter: Página del modelo Grok 4.20 Beta
- Enlace:
openrouter.ai
- Enlace:
Autor: Equipo de APIYI | Lanzamos los modelos de IA más recientes de inmediato. Te invitamos a visitar APIYI (apiyi.com) para probar toda la serie de modelos Grok 4.20 Beta.