打开 Gemini 官方文档,尤其是 Nano Banana 生成图像这类页面,你可能会注意到页面顶部多了一个切换开关——一边是 Interactions API,一边是 generateContent API。这不是文档改版这么简单,而是 Google 在 2026 年 6 月正式把 Interactions API 推上了 GA(正式可用)的位置,并建议所有新项目优先采用。本文结合官方文档和 APIYI 网关的实测结论,把两者的核心差异、能力缺口和实际调用建议一次讲清楚。
核心价值: 读完本文,你会明确 Interactions API 和 generateContent 在设计理念、状态管理、能力覆盖上的具体差异,并知道经 APIYI 中转调用 Gemini 时该选哪一种范式。

Interactions API 与 generateContent 核心差异
先说结论:这两个 API 不是简单的版本升级关系,而是两套不同的设计理念。generateContent 是无状态的“一次请求一次响应”模式,客户端需要自己维护完整的对话历史;Interactions API 则把状态管理下放到服务端,围绕“Interaction”这个新概念重新设计了整套交互方式。
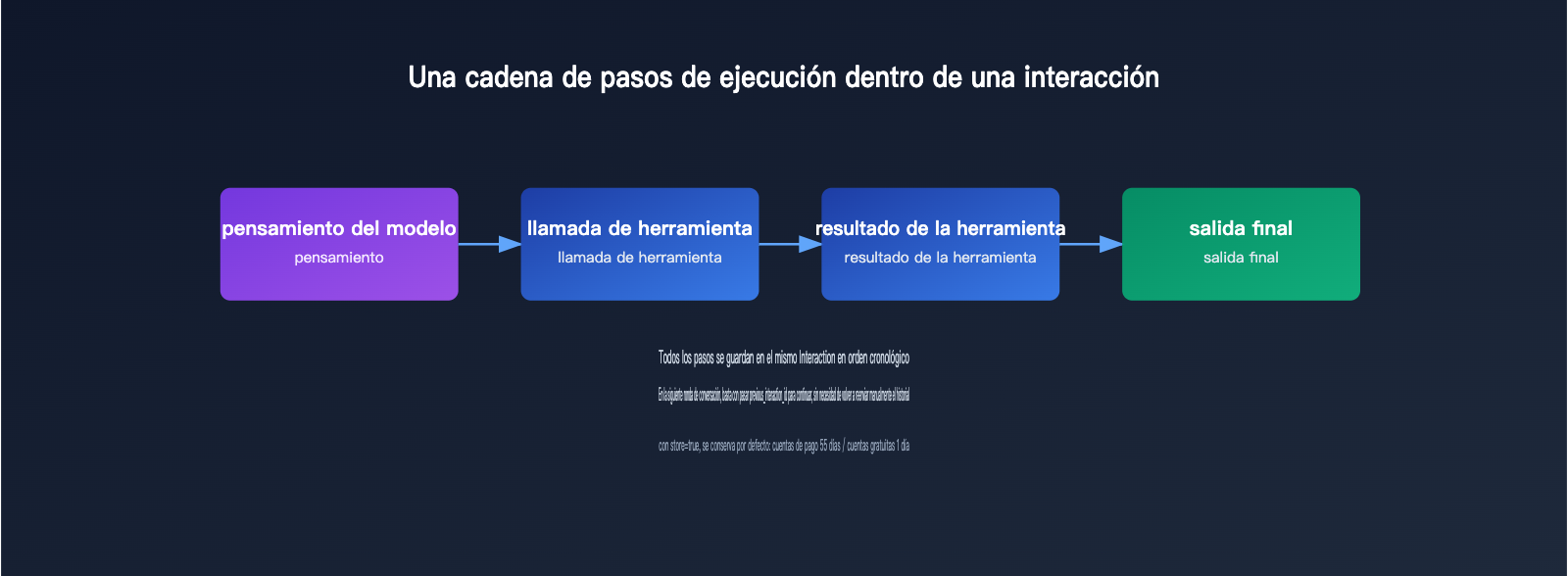
官方文档把一个 Interaction 定义为“一次完整的对话或任务轮次”,内部由一系列按时间顺序排列的执行步骤组成,包括模型的思考过程、工具调用与返回结果,以及最终的模型输出。这意味着 Interactions API 天生就是为多轮对话和 agent 类任务设计的,而不只是单次问答。
这也解释了为什么 Google 会用“正式可用”这样的措辞而不是简单的“新增功能”。Interactions API 于 2025 年 12 月进入公测,2026 年 6 月正式官宣 GA,官方博客明确写道:“我们建议所有新项目和应用都使用 Interactions API”,同时全部官方文档已经默认展示这套新范式,并且 Google 正在推动第三方 SDK 和生态伙伴也把它作为默认接口。换句话说,这不是一次可选的功能更新,而是 Google 对“如何调用 Gemini”这件事的重新定义,只是配套发布了迁移指南,允许开发者按自己的节奏逐步过渡,不强制一刀切。
| 对比维度 | generateContent(legacy) | Interactions API |
|---|---|---|
| 当前状态 | 遗留但完全支持 | 2026年6月起正式GA |
| 官方推荐 | 现有项目可继续使用 | 建议所有新项目优先采用 |
| 核心方法 | generateContent | interactions.create / get / delete |
| 设计理念 | 无状态单次请求 | 围绕Interaction的状态化任务轮次 |
| 未来新能力 | 仍会获得新主线模型 | 前沿agent能力优先登陆 |
🎯 技术建议: 如果你正在通过 APIYI apiyi.com 调用 Gemini 系列模型,建议先花几分钟对照官方文档确认自己项目当前使用的是哪一种范式,再决定是否需要跟进迁移,避免因为文档默认展示 Interactions API 而误以为原有代码已经过时。
Diferencias esenciales entre dos paradigmas: gestión de solicitudes y estado
La clave para entender la diferencia entre ambas está en “quién mantiene el historial de la conversación”. generateContent exige que el cliente concatene manualmente todo el array de mensajes históricos en cada solicitud; incluso en el décimo turno, hay que volver a enviar tal cual el contenido de los nueve anteriores. Es un enfoque simple y directo, pero a medida que crece el número de turnos, el cuerpo de la solicitud se hace cada vez más grande y también se repiten los historiales transmitidos, que vuelven a facturarse.
Interactions API propone una solución: tomar el interaction id devuelto por la llamada anterior y pasarlo en la siguiente solicitud como parámetro previous_interaction_id. Así, el servidor recupera automáticamente todo el historial de la conversación y el cliente ya no tiene que concatenar ni reenviar nada a mano. La documentación oficial también ofrece background=true para tareas de larga duración, además de la capacidad de “pasos de ejecución observables”, útil para depurar y para mostrar el proceso intermedio del modelo en la UI del frontend. Esto resulta especialmente valioso al construir productos tipo agent.
Pero la gestión de estado del lado del servidor no es gratis. Por defecto, el parámetro store vale true, así que el sistema conserva los registros de interaction: 55 días para cuentas de pago y solo 1 día para cuentas gratuitas. Si por privacidad o cumplimiento decides poner store en false, puedes desactivar el almacenamiento, pero también perderás la posibilidad de continuar conversaciones con previous_interaction_id y la ejecución en segundo plano. Es un punto de equilibrio que conviene valorar de antemano.
Desde el punto de vista de costes, la propuesta de valor de la documentación oficial es clara: al mantener el estado en el servidor, el historial de una misma conversación ya no tiene que volver a entrar en cada solicitud como tokens de entrada, lo que mejora bastante la tasa de acierto de caché; en palabras de la propia documentación, “menor coste y mayor tasa de acierto de caché”. En escenarios como chatbots de atención al cliente o preguntas sobre documentos largos, donde hay que mantener mucho contexto, esta diferencia se nota bastante cuando sube el volumen de llamadas. En cambio, para generación de una sola vez o tareas por lotes, que son naturalmente sin estado, esa ventaja de coste prácticamente no aporta nada.
Hay otro detalle fácil de pasar por alto: parámetros como tools, system_instruction y generation_config —incluidos campos como thinking_level y temperature— se configuran “por llamada”. Aunque continúes una conversación con previous_interaction_id, esas configuraciones no se heredan automáticamente; en cada solicitud hay que pasarlas de forma explícita otra vez.
| Capacidad | generateContent | Interactions API |
|---|---|---|
| Mantenimiento del historial de conversación | El cliente concatena manualmente todo el historial | El servidor lo recupera automáticamente mediante previous_interaction_id |
| Ejecución en segundo plano de tareas largas | No compatible | Compatible con background=true |
| Visibilidad de pasos de ejecución intermedios | Hay que analizarlo por cuenta propia | Ofrece observable execution steps |
| Política de retención de registros | No aplica | Retención por defecto: 55 días en pago / 1 día en gratis |
| Herencia de herramientas y parámetros de generación | Se pasan explícitamente cada vez | Se pasan explícitamente cada vez, no se heredan automáticamente |
💡 Sugerencia de elección: para proyectos que necesitan muchas conversaciones multironda o construir flujos de trabajo tipo agent, el mecanismo de gestión de estado de Interactions API sí puede ahorrarte bastante código auxiliar; pero si tu caso de uso es sobre todo de generación puntual, esa ventaja puede no notarse. Recomendamos hacer primero una prueba con poco tráfico en la plataforma APIYI apiyi.com y decidir después si merece la pena migrar.
La brecha de capacidades entre ambos: qué puede hacer cada uno y qué no
Aunque Interactions API es el paradigma nuevo, la documentación oficial también enumera con claridad las capacidades que todavía no admite. Esto hay que tenerlo en cuenta al elegir, no vale asumir que “más nuevo” significa automáticamente “más completo”.
La documentación indica explícitamente que Interactions API aún no soporta el campo video metadata en comprensión de vídeo, Batch API, la llamada automática de funciones de Python (automatic function calling) ni la caché explícita (explicit caching). Eso sí, la caché implícita lograda mediante previous_interaction_id sí está soportada. En cambio, generateContent sí soporta salida en streaming, llamadas a funciones, Batch API, caché explícita y la entrada multimodal completa, incluyendo texto, imágenes, audio, vídeo y documentos.
| Capacidad | generateContent | Interactions API |
|---|---|---|
| Batch API | ✅ Compatible | ❌ Aún no compatible |
Caché explícita (explicit caching) |
✅ Compatible | ⚠️ Solo caché implícita |
Campo video metadata |
✅ Compatible | ❌ Aún no compatible |
| Llamada automática de funciones en Python | ✅ Compatible | ❌ Aún no compatible |
| Salida en streaming / llamadas a funciones | ✅ Compatible | ✅ Compatible |
| Coste y tasa de acierto de caché declarados | Facturación estándar | La documentación afirma menor coste y mayor acierto |
Tomando como ejemplo concreto la generación de imágenes Nano Banana, la diferencia más visible entre ambos paradigmas está en cómo se obtienen los resultados. Interactions API ofrece propiedades prácticas como interaction.output_image y interaction.output_text, que permiten acceder directamente a la última imagen o bloque de texto generado. generateContent, en cambio, usa una estructura más básica basada en recorrer el array candidates[0].content.parts, donde tienes que comprobar tú mismo el tipo de cada part. Para proyectos que ya tienen lógica de parseo montada sobre generateContent, esta diferencia estructural suele implicar una refactorización importante; no es solo cambiar el endpoint y listo.
Estas carencias no son detalles menores. Batch API suele ser la herramienta central para proyectos sensibles al coste que procesan tareas offline por lotes. Si migras y descubres que el nuevo paradigma no lo soporta, básicamente te toca rediseñar toda la cadena de procesamiento offline. La caché explícita, por su parte, afecta directamente al coste en escenarios de contexto largo: si en tu negocio hay grandes bloques fijos de system prompt o material de referencia que se reutilizan continuamente, no tener caché explícita significa que no puedes controlar con precisión qué se cachea ni durante cuánto tiempo. Por eso la documentación oficial mantiene ambas líneas técnicas en paralelo, en lugar de dejar generateContent obsoleto. Al menos hasta que esas capacidades se completen, sigue siendo irremplazable.
🔧 Recomendación práctica: si tu negocio depende mucho de Batch API para procesar por lotes o de la caché explícita para reducir costes, cambiar ahora a Interactions API puede hacerte perder esas capacidades. Mejor seguir de cerca el ritmo de actualización de la guía de migración oficial que correr a reemplazar el código de producción.
APIYI网关实测:当前该用哪个范式
结论先说:截至 2026 年 7 月 4 日的实测,通过 APIYI 网关调用 Gemini,仍然应该继续使用 generateContent 原生格式。

APIYI 技术团队针对 Interactions API 的关键路径做了直接测试,覆盖了两种主流鉴权方式,结果如下。
| 测试端点 | 鉴权方式 | 结果 |
|---|---|---|
| POST /v1beta2/interactions | Bearer token | ❌ 404(URL 无效) |
| POST /v1beta/interactions | Bearer token | ❌ 404(URL 无效) |
| POST /v1beta2/interactions | x-goog-api-key header | ❌ 404(URL 无效) |
| POST /v1beta/models/{model}:generateContent | Bearer token | ✅ 正常返回 |
APIYI 官方文档的原话是:“APIYI 网关暂不支持 Interactions API 中转——/v1beta2/interactions 与 /v1beta/interactions 路径均返回 404”,并给出明确建议:“通过 APIYI 调用 Gemini 请继续使用 generateContent 原生格式”。这也是为什么 APIYI 站内目前所有 Gemini 相关文档都统一基于 generateContent 格式编写,这样能保证读者复制代码就能直接跑通,不会遇到路径 404 的问题。
需要强调的是,这是一个动态状态,而不是永久限制。随着 Interactions API 逐渐成为官方默认范式,网关侧后续大概率会跟进支持;届时 APIYI 会更新对应文档。目前可以关注 docs.apiyi.com/api-capabilities/gemini/interactions-api 这个页面获取最新支持状态,不需要每次都自己动手测试端点。
这组测试结果也提醒了一个容易被忽视的现实:官方文档层面的“正式可用”,和某个具体中转网关或第三方 SDK 是否已经完成适配,完全是两回事。开发者如果只看官方文档的默认展示,直接照抄 Interactions API 的代码示例塞进现有的中转配置里,大概率会先撞上 404,再花时间排查到底是自己的代码写错了,还是网关本身还没跟上。遇到类似情况时,先确认自己的调用链路(直连官方还是经第三方中转)对新范式的支持状态,往往比反复检查业务代码更快定位问题。
🚀 快速开始: 如果你现在就想验证自己的 Gemini 调用链路是否正常,推荐直接使用 APIYI apiyi.com 的 generateContent 格式接入,该平台提供统一的 base_url,支持文本、图片等多种 Gemini 模型的调用,不需要额外处理认证细节。
该怎么选:场景化决策建议
结合前面的能力对比和实测结论,给出一份简单的场景化建议表。

| 使用场景 | 推荐方案 | 理由 |
|---|---|---|
| 通过 APIYI 网关调用 Gemini | generateContent | 网关当前仅支持该格式,Interactions API 路径返回 404 |
| 依赖 Batch API 批量处理 | generateContent | Interactions API 暂不支持 Batch API |
| 需要显式缓存降低成本 | generateContent | Interactions API 目前只有隐式缓存 |
| 构建多轮对话 agent,直连官方 API | 可评估 Interactions API | 服务端状态管理能省去历史拼接逻辑 |
| 需要观察模型中间执行步骤调试 | Interactions API | 原生支持可观测的执行步骤 |
| 现有项目已用 generateContent 跑通 | 暂不迁移 | legacy 仍完全支持,短期内还会获得新模型 |
简单来说,是否迁移不取决于“新不新”,而取决于你的具体依赖是否被 Interactions API 完整覆盖,以及你调用 Gemini 的链路(直连官方还是经中转网关)当前是否已经支持这套新范式。对大多数通过 APIYI 中转调用的开发者来说,现阶段维持 generateContent 是更稳妥的选择。
Preguntas frecuentes
Q1: ¿generateContent se va a descontinuar? ¿Sigue valiendo la pena desarrollar proyectos nuevos basados en él?
A corto plazo, no. Google ha dejado claro que, aunque generateContent está marcado como legacy, “sigue totalmente compatible” y, en el futuro previsible, seguirá recibiendo nuevos modelos Gemini principales. Si llamas a Gemini a través de APIYI apiyi.com, por ahora desarrollar nuevos proyectos sobre generateContent no tiene problema; no hace falta preocuparse solo porque la documentación muestre por defecto la Interactions API.
Q2: ¿Cuándo soportará el gateway de APIYI la Interactions API?
Por ahora no hay una fecha exacta. Depende de qué tan adoptado esté este paradigma en el ecosistema oficial y del avance de la adaptación en el lado del gateway. Te recomendamos estar atento a las actualizaciones de la documentación oficial de la plataforma APIYI apiyi.com. En cuanto se soporte el proxy de Interactions API, la documentación relacionada se actualizará de inmediato, así que no hace falta estar probando el estado de los endpoints una y otra vez.
Q3: ¿Se pueden mezclar las dos API dentro del mismo proyecto?
Técnicamente sí, siempre que la cadena de llamadas lo soporte. Ambas formas pueden coexistir; por ejemplo, usar generateContent para tareas por lotes de Batch API y, en escenarios de diálogo multi-turno con conexión directa a la API oficial, probar Interactions API. Pero cuando se llama a través del gateway de APIYI, como la ruta de Interactions API devuelve actualmente 404, lo recomendable por ahora es usar de forma unificada el formato generateContent para evitar tener dos lógicas de llamada distintas dentro del mismo proyecto y aumentar el costo de mantenimiento.
Resumen
Tras su paso a estado estable en junio de 2026, Interactions API sí representa la dirección a largo plazo que Google plantea para la invocación de Gemini. La gestión de estado en servidor y la capacidad de observar los pasos de ejecución son muy atractivas para aplicaciones tipo agente, pero todavía le faltan funciones claras en aspectos como Batch API, caché explícita y metadatos de video. generateContent sigue totalmente compatible y, a corto plazo, continuará recibiendo actualizaciones. Más importante aún: al llamar a Gemini a través del gateway de APIYI, las pruebas realizadas hasta ahora muestran que todas las rutas relacionadas con Interactions API devuelven 404; generateContent es el único formato disponible en este momento. Si necesitas una llamada estable y fiable a los modelos de la serie Gemini, te recomendamos integrar mediante APIYI apiyi.com usando el formato nativo generateContent. Cuando el gateway soporte el nuevo paradigma, la documentación se actualizará a tiempo.
Los datos de estas pruebas y la verificación de la información oficial fueron realizados por el equipo técnico de APIYI. Si quieres conocer más detalles sobre la invocación de los modelos de la serie Gemini, no dudes en contactar con soporte técnico a través de APIYI apiyi.com.
Referencias
-
Google AI for Developers – Interactions API: resumen: concepto de Interaction, métodos principales y capacidades
- Enlace:
ai.google.dev/gemini-api/docs/interactions-overview
- Enlace:
-
Google AI for Developers – generateContent(Legacy): estado de soporte y alcance de capacidades de la API heredada
- Enlace:
ai.google.dev/gemini-api/docs/interactions
- Enlace:
-
Documentación oficial de APIYI – estado de compatibilidad de Gemini Interactions API: resultados reales de endpoints probados en el gateway y recomendaciones de uso
- Enlace:
docs.apiyi.com/api-capabilities/gemini/interactions-api
- Enlace: