“¿Gemini-3.1-flash-lite-image realmente soporta el modo de razonamiento?” es una de las preguntas que más se repiten últimamente en los grupos de llamadas a la API. La respuesta es sí, y no es una suposición: combinamos la documentación oficial de Google con tres pruebas comparativas hechas a través de la pasarela de APIYI, y obtuvimos datos reales de consumo de tokens y latencia. En este artículo vamos a explicar a fondo el interruptor thinkingLevel desde tres ángulos: estructura de parámetros, datos medidos y reglas de facturación.
Valor clave: al terminar de leerlo, te quedará claro cómo activar el modo de razonamiento en gemini-3.1-flash-lite-image, cuántos tokens extra consume y en qué escenarios vale la pena asumir esa latencia.

Conclusiones clave sobre el modo de razonamiento en gemini-3.1-flash-lite-image
Primero, vayamos al grano. La documentación oficial de Google deja claro que, con gemini-3.1-flash-image y gemini-3.1-flash-lite-image, los desarrolladores pueden controlar cuánta capacidad de pensamiento usa el modelo. Eso significa que la versión flash-lite también incorpora capacidad de razonamiento; no es algo exclusivo de los modelos insignia. Pero no todos los modelos de imagen soportan este parámetro. La siguiente tabla compara tres modelos de imagen de Gemini bastante usados.
| Modelo | ¿Soporta thinkingLevel? | Niveles ajustables | Nivel predeterminado | Nota |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ Sí | minimal / high | minimal | La documentación oficial lo enumera explícitamente |
| gemini-3.1-flash-lite-image | ✅ Sí | minimal / high | minimal | Comparte la misma thinkingConfig con flash-image |
| gemini-3-pro-image | ⚠️ Parámetro inválido | Fijo, no ajustable | Interno fijo | Pasar high no da error, pero en las pruebas no hay cambios |
Conviene aclarar algo: thinkingLevel solo tiene dos विकल्पs, no es como en los modelos de texto, donde puedes ajustar de forma continua el presupuesto de pensamiento. El texto oficial menciona que “minimal thinking” no significa que el modelo no piense en absoluto; es decir, incluso en el nivel predeterminado, el modelo hace cierta cantidad de razonamiento básico, solo que no realiza tantas rondas de verificación de composición como en high.
Y este es un dato interesante para el sector. En generaciones anteriores de modelos de generación de imágenes, ya fuera nano banana o la primera versión de flash-image, la API oficial no exponía parámetros como el nivel de pensamiento. El modelo generaba con una estrategia fija o dependía por completo de la ingeniería de indicaciones para compensar fallos de composición. En la serie 3.1, Google abrió el mecanismo de razonamiento de “primero planificar, luego generar” para la familia flash; en esencia, está trasladando a la generación de imágenes un paradigma de pensamiento que antes solo se había validado en modelos de texto. Entender este contexto ayuda a prever si otros fabricantes seguirán el mismo camino en sus modelos de imagen.
🎯 Recomendación técnica: si estás llamando a los modelos de imagen de Gemini a través de APIYI apiyi.com, te conviene empezar con el nivel
minimalpor defecto para validar el flujo de negocio y, según la calidad real de las imágenes, decidir si hace falta pasar ahigh. La plataforma ofrece una interfaz unificada, así quegemini-3.1-flash-image,flash-lite-imageypro-imagese pueden alternar con el mismo código, lo que facilita las comparaciones A/B.
thinkingLevel 参数详解与调用方式
thinkingLevel no es un parámetro independiente, sino un objeto thinkingConfig anidado dentro de generationConfig, y se usa junto con includeThoughts. includeThoughts decide si se devuelven al cliente los resúmenes del pensamiento del modelo, mientras que thinkingLevel define la “intensidad” del razonamiento. Son dos interruptores desacoplados; no conviene mezclarlos.
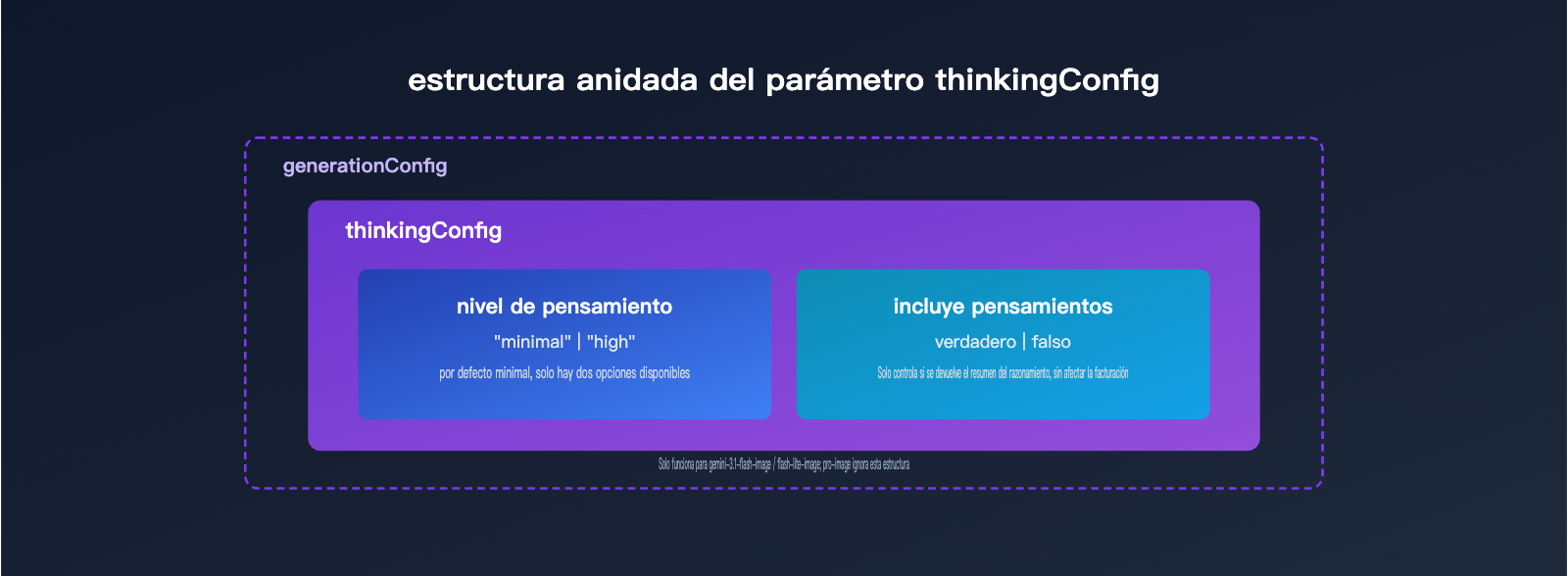
La tabla siguiente resume el tipo y el rango de valores de los dos campos clave dentro de thinkingConfig.
| Campo | Tipo | Valores posibles | Valor por defecto | Función |
|---|---|---|---|---|
| thinkingLevel | cadena enumerada | minimal / high |
minimal |
Controla la intensidad del razonamiento del modelo; solo tiene efecto en la serie flash de modelos de imagen |
| includeThoughts | booleano | true / false |
false |
Indica si se devuelve en la respuesta un resumen del proceso de pensamiento; no afecta a la facturación |
En la llamada real, la estructura en los tres lenguajes más usados es exactamente la misma: se inserta un objeto thinkingConfig dentro de config. Tomemos Python como ejemplo:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Llamada a través de la puerta de enlace unificada de APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "Dibuja un gato bebiendo café bajo las montañas nevadas"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Ver ejemplo completo de llamada REST nativa
{
"contents": [{"parts": [{"text": "Dibuja un gato bebiendo café bajo las montañas nevadas"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
La forma de escribir en JavaScript SDK es consistente; solo cambia el estilo snake del REST al objeto thinkingConfig en camelCase. Los demás nombres de campos no cambian. No hay diferencias sustanciales en la lógica de llamada entre los tres lenguajes; basta con recordar esta regla: thinkingConfig solo va debajo de generationConfig.
Hay un detalle fácil de pasar por alto: el valor de thinkingLevel es una enumeración de cadenas sensible a mayúsculas y minúsculas. En los ejemplos oficiales han aparecido mezcladas las formas "High" y "high", y en pruebas reales ambas se reconocen y funcionan correctamente a través de la puerta de enlace. Aun así, para no depender de comportamientos de compatibilidad no documentados, conviene usar siempre minúsculas en el código de negocio: "high" y "minimal". Así, si en el futuro el upstream endurece la validación de mayúsculas, no afectará a la llamada en producción.
Recomendación: Obtén créditos de prueba gratis a través de APIYI apiyi.com y valida directamente en la puerta de enlace si
thinkingConfigse está reenviando bien; suele ser más práctico que pedir una clave oficial y depurar por tu cuenta.
Datos reales de APIYI: impacto de thinkingLevel en tokens y latencia
Por muy clara que esté la documentación, nada mejor que unos datos reales para verlo de forma directa. Usamos la misma indicación y, para generación de imágenes 1K, probamos a través de la puerta de enlace de APIYI tres casos: el nivel minimal de gemini-3.1-flash-image, el nivel high, y enviar a la fuerza high a gemini-3-pro-image.
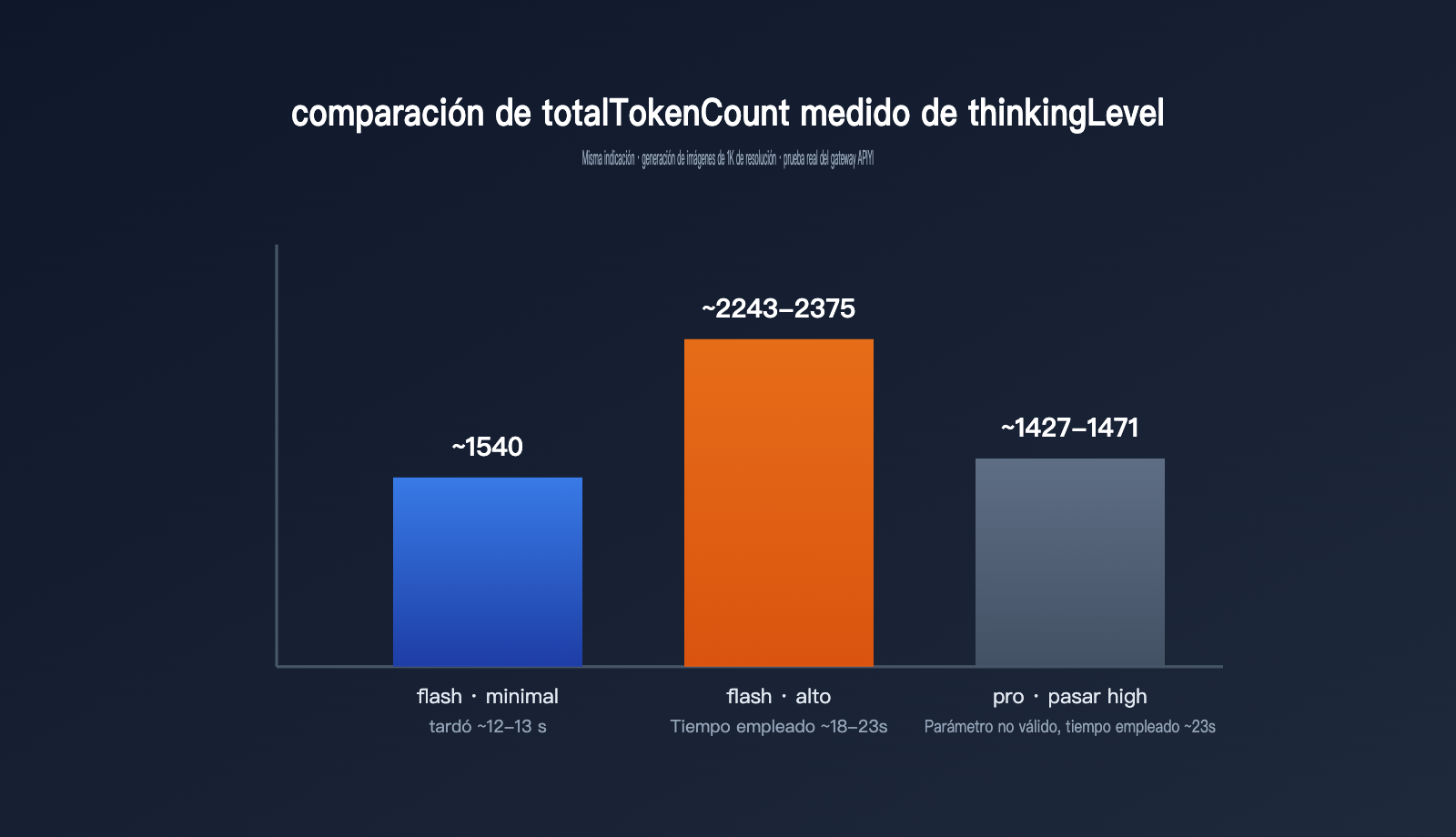
| Modelo / configuración | thoughtsTokenCount | tokens de imagen | totalTokenCount | Tiempo |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (por defecto) | No existe este campo | 1120 | aprox. 1540 | aprox. 12-13 s |
| gemini-3.1-flash-image · high | 700-792 | 1120 | aprox. 2243-2375 | aprox. 18-23 s |
| gemini-3-pro-image · con high | 181-214 (igual que por defecto) | 1120 | aprox. 1427-1471 | aprox. 23 s |
Estos datos muestran tres reglas clave. Primera: al cambiar thinkingLevel a high, thoughtsTokenCount pasa de 0 en el valor por defecto —de hecho, ni siquiera aparece en la respuesta— a un rango de 700-800, el consumo total de tokens sube casi un 50 % y la latencia pasa de 12-13 segundos a 18-23 segundos. O sea, pensar de verdad cuesta tiempo y dinero. Segunda: tanto en minimal como en high, los tokens de la imagen final siguen siendo 1120, así que thinkingLevel solo afecta a “cómo piensa” el modelo, no a la resolución ni a la facturación de la imagen. Tercera: si envías high a gemini-3-pro-image, no da error, pero los tokens de pensamiento quedan en 181-214, prácticamente igual que en el nivel por defecto, lo que confirma lo que dice la documentación oficial: el comportamiento de pensamiento en pro-image es fijo y no admite ajuste externo.
En otras palabras, si en tu lógica de negocio envías un thinkingConfig unificado a los modelos flash, flash-lite y pro, pro-image simplemente ignorará ese parámetro. No fallará ni cortará la llamada, pero tampoco ajustará de verdad la intensidad del razonamiento como esperas.
Conviene añadir una aclaración: estos datos no vienen de una sola medición, sino de repetir varias veces la misma indicación para cada configuración y tomar el rango observado. Por eso thoughtsTokenCount en high aparece como 700-792 y no como un valor fijo. Este tipo de tareas de razonamiento tiene cierta aleatoriedad: la ruta intermedia que genera el modelo no es exactamente la misma en cada ejecución, así que el consumo de tokens también fluctúa un poco. Aun así, el orden de magnitud y la tendencia de latencia son estables y reproducibles; no vas a ver que high sea más rápido que minimal, ni que los tokens de pensamiento se disparen a miles sin motivo.
Tokens de pensamiento y reglas de facturación en modelos de imagen
Muchos desarrolladores, la primera vez que ven el campo thoughtsTokenCount, tienden a compararlo con el coste de pensamiento de los modelos de texto. Pero en realidad, el mecanismo de pensamiento de los modelos de imagen se divide en dos partes para la facturación, y entender esto es clave para controlar costes.
| Dimensión | Pensamiento en modelo de texto | Pensamiento en modelo de imagen |
|---|---|---|
| Forma del resultado del pensamiento | Cadena de razonamiento en texto plano | Resumen en texto + hasta dos bocetos temporales de composición |
| Volumen de tokens del texto de pensamiento | Puede llegar a miles | En el nivel Pro no supera 400, y en Flash high ronda 700-800 |
| Campo principal que asume el coste | thoughtsTokenCount | El boceto se contabiliza en candidatesTokenCount y se cobra como un part normal de imagen |
| Tarifa por boceto individual | No aplica | Una resolución de 1K cuesta aprox. 1120 tokens, unos 0.0336 USD por imagen |
| Impacto de includeThoughts en la facturación | Ninguno, cobro fijo | Ninguno, cobro fijo |
La documentación oficial deja claro que, tanto si includeThoughts está en true como en false, los tokens generados por el pensamiento se cobran igual. En nuestras pruebas también lo vimos: al activar includeThoughts, la estructura de respuesta y el total facturado no cambiaron en nada; solo apareció un resumen de pensamiento extra para depuración. Dicho de otra forma, includeThoughts es un interruptor de “quiero verlo o no”, no de “quiero pagarlo o no”, y ese detalle se presta mucho a confusión.
Lo más importante aquí es que el coste fuerte de los modelos de imagen no está tanto en thoughtsTokenCount, sino en las imágenes temporales de composición que generan durante la inferencia. La documentación oficial menciona que, en la fase de pensamiento, el modelo puede generar como máximo dos imágenes temporales para probar la composición y la coherencia lógica; esos bocetos se devuelven como parts normales de imagen y se suman en candidatesTokenCount, cobrando según el precio estándar de salida de imagen. En otras palabras, una generación tipo high para texto a imagen puede añadir sin que te des cuenta una o dos “imágenes invisibles” de boceto, y eso es fácil de olvidar al estimar costes.
Hagamos una cuenta rápida para verlo mejor. Supongamos una petición de generación de imagen de 1K en modo high, con un consumo de texto de pensamiento de unos 750 tokens. Si durante la inferencia el modelo genera efectivamente dos bocetos temporales y además la imagen final, en teoría habríamos producido tres parts de imagen. Si cada una cuesta 1120 tokens, o unos 0.0336 USD, el coste de salida de esas tres imágenes se acerca a 0.1 USD. Si encima sumamos el coste del texto de pensamiento, el gasto total puede ser 2-3 veces el de minimal. Eso sí, que se activen o no esas dos imágenes depende del criterio del modelo ante la indicación; no siempre se generan dos bocetos completos en cada llamada high. Por eso en las pruebas el total de tokens aparece en un rango como 2243-2375, en vez de duplicarse de forma exacta.
💰 Optimización de costes: si tu equipo es sensible al coste por token, conviene revisar primero en los logs de llamadas de la plataforma APIYI apiyi.com el totalTokenCount real, y luego decidir si merece la pena mantener high de forma permanente. Así evitas sobrecostes por no tener en cuenta la facturación de los bocetos.
En qué casos conviene usar high y en cuáles el minimal por defecto
Con los datos de las pruebas, aquí va una guía sencilla para decidir.

| Escenario de negocio | Nivel recomendado | Motivo |
|---|---|---|
| Generación masiva de creatividades de marketing, sin mucha exigencia en la precisión de la composición | minimal (por defecto) | Menor latencia, coste por tokens controlable, suficiente para generar imágenes del día a día |
| Composición compleja con varios sujetos, o necesidad de seguir con precisión la maquetación de texto o las relaciones espaciales | high | El pensamiento extra mejora la precisión de la composición, y merece la pena pagar por calidad |
| E-commerce, landing pages o posters con baja tolerancia al error en los detalles | high | Reduce las veces que hay que rehacer la imagen, así que el coste total termina siendo menor |
| Escenarios interactivos en tiempo real con exigencia muy alta de respuesta | minimal | El modo high añade 5-10 segundos de latencia, así que no encaja con experiencias muy interactivas |
| Llamadas a gemini-3-pro-image | No hace falta configurarlo | Este modelo tiene un comportamiento de pensamiento fijo; pasar el parámetro no tendrá efecto |
En resumen, el modo high encaja mejor cuando importa más que la imagen salga bien a la primera que la velocidad de generación. Si tu aplicación necesita reintentos frecuentes y ajustar una y otra vez la indicación para conseguir una composición aceptable, entonces quizá te convenga activar high directamente: pagas un poco más por llamada, pero aumentas la probabilidad de acertar a la primera, y al final puede salir más rentable.
En la práctica, lo más sensato es convertir thinkingLevel en un parámetro configurable, en lugar de dejarlo fijo en el código. Por ejemplo, puedes enrutar automáticamente según el tipo de negocio que envíe quien llama a la API: las tareas por lotes usan minimal por defecto, y las solicitudes que requieren maquetación precisa o relaciones espaciales entre varios sujetos pasan a high. Así controlas el coste medio sin sacrificar calidad en los casos críticos. Si en tu equipo mantenéis a la vez la lógica de llamadas para flash, flash-lite y pro, conviene unificar el tratamiento en la capa de encapsulación de parámetros, y enviar thinkingLevel solo a los modelos que lo soportan, para no pasar parámetros inútiles a pro-image y complicar la depuración.
🚀 Empezar rápido: recomendamos usar la plataforma APIYI apiyi.com para montar un prototipo en poco tiempo. Con la misma base_url puedes alternar entre minimal y high para hacer pruebas comparativas, sin necesidad de configurar credenciales distintas para cada nivel.
Preguntas frecuentes
Q1: ¿gemini-3.1-flash-lite-image y gemini-3.1-flash-image tienen el mismo rendimiento de inferencia?
Ambos comparten la misma estructura de parámetros thinkingConfig, y los niveles compatibles también son minimal y high, pero flash-lite está posicionado como una versión ligera. En la práctica, la profundidad de razonamiento y el nivel de detalle de la imagen final suelen ser inferiores a los de flash-image. Esto también se ve en el patrón de nombres: la serie flash-lite en los modelos de texto siempre se ha ubicado como “más rápida, más económica y con una ligera bajada de precisión”. La serie de imágenes sigue la misma lógica de equilibrio. Activar el nivel high puede compensar en parte las limitaciones del modelo ligero en composiciones complejas, pero es difícil igualar por completo el rendimiento de flash-image. Si quieres hacer una comparación cuantitativa, puedes usar la plataforma APIYI apiyi.com para invocar ambos modelos con el mismo conjunto de indicaciones y comparar directamente thoughtsTokenCount y el resultado de la imagen.
Q2: ¿Si paso el parámetro `thinkingLevel` a gemini-3-pro-image dará error?
No dará error. Nuestras pruebas muestran que, al pasar high, la solicitud responde correctamente, pero thoughtsTokenCount se mantiene en el rango de 181-214, casi igual que cuando no se pasa el parámetro. Esto indica que el comportamiento interno de pensamiento de este modelo es fijo y no acepta ajuste externo. Si haces llamadas por lotes a varios modelos, conviene distinguir el nombre del modelo en la lógica de tu negocio para evitar asumir que el parámetro ya surtió efecto.
Q3: Después de activar el nivel `high`, ¿hay que ajustar también la resolución o la calidad de la imagen?
No hace falta. Los datos de prueba muestran que los tokens de imagen en los niveles minimal y high se mantienen estables en 1120, lo que indica que thinkingLevel solo actúa sobre el proceso interno de inferencia del modelo y no cambia la configuración de resolución de la imagen de salida. La resolución sigue controlándose por separado con los parámetros de tamaño dentro de imageConfig, sin relación con el nivel de pensamiento. Dicho de otra forma, thinkingLevel y los parámetros de resolución son dos ejes de ajuste independientes: uno controla “qué tan bien piensa” y el otro “qué tan grande y detallado dibuja”. Se pueden combinar libremente, sin exclusión mutua ni relación de activación conjunta.
Resumen
gemini-3.1-flash-lite-image sí soporta el modo de inferencia, algo que ya quedó validado tanto por la documentación oficial como por los datos de prueba de APIYI. thinkingLevel solo permite dos niveles, minimal y high. Al activar high, los tokens de pensamiento suben a más de 700 y el tiempo total aumenta unos 5-10 segundos, pero no cambia el consumo de tokens de la imagen final. En cambio, aunque gemini-3-pro-image acepta este parámetro sin error, en la práctica no tiene efecto. Entender esta lógica de doble vía, donde el texto del pensamiento se factura en thoughtsTokenCount y el boceto de la composición en candidatesTokenCount, es clave para controlar el costo de generación de imágenes. Si necesitas cambiar rápido entre varios modelos de imágenes de Gemini y hacer pruebas, te recomendamos usar la pasarela unificada de APIYI apiyi.com, así evitas solicitar una clave API distinta para cada modelo y mantener código de invocación separado.
Los datos de este artículo provienen de pruebas realizadas por el equipo técnico de APIYI. Si quieres comentar más detalles sobre la invocación de los modelos de imágenes de Gemini, puedes contactar con soporte técnico a través de APIYI apiyi.com.
Material de referencia
- Documentación oficial de Gemini API – generación de imágenes: descripción del parámetro de niveles de pensamiento (thinking levels)
- Enlace:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Enlace: