title: "gpt-image-2 vs gpt-image-1.5: A Deep Dive into 8 Key Upgrades"
description: "Based on leaked LM Arena data, we analyze the 8 major upgrades in gpt-image-2, including text rendering, 4K output, and speed improvements."
tags: [AI, OpenAI, gpt-image-2, image generation, tech analysis]
Author's Note: Based on leaked information from LM Arena's gray-box testing, this is a comprehensive breakdown of the 8 key upgrades in gpt-image-2 compared to gpt-image-1.5, covering text rendering, realism, 4K output, speed, multilingual support, and UI screenshot generation.
In early April 2026, three anonymous image models—maskingtape-alpha, gaffertape-alpha, and packingtape-alpha—quietly appeared on the LM Arena evaluation platform. Early testers reported that their text rendering accuracy was near 99%, generation speed was around 3 seconds, and they featured native 4K output. The community generally agrees that this is OpenAI's upcoming gpt-image-2.
This is not vaporware. The public test records on LM Arena, comparison screenshots from multiple independent testers, and OpenAI's historical gray-box testing cycles (which typically lead to an official release within 2-4 weeks) all point to the same conclusion. This article will systematically compare the eight key upgrades of gpt-image-2 vs gpt-image-1.5.
Core Value: After reading this, you'll clearly understand the specific advancements of gpt-image-2 in text, realism, 4K, speed, UI rendering, and multilingual support, as well as how to seamlessly migrate on the first day the API becomes available.

gpt-image-2 Key Highlights
| Upgrade Dimension | gpt-image-1.5 Status | gpt-image-2 Improvement |
|---|---|---|
| Text Rendering | Good for 1-5 word titles | ~99% character-level accuracy |
| Generation Speed | 8-18 seconds | ~3 seconds (3-5x faster) |
| Max Resolution | 1536×1024 | 2048×2048 / 4096×4096 |
| Widescreen Support | Only 1:1, 4:3, 3:4 | Added 16:9 widescreen |
| Realism | "AI yellow filter" present | Portraits/products can fool the eye |
The Significance of the gpt-image-2 Upgrade
Text is no longer a bottleneck. In the gpt-image-1.5 era, most image models struggled with rendering text longer than 5-6 words. However, LM Arena testers report that UI labels, signs, and posters generated by gpt-image-2 rarely require post-processing. This means localized ad creatives, UI mockups, and social media images will no longer require manual layout work.
Moving from two-stage to single-stage inference. gpt-image-1.5 was still based on a two-stage pipeline, whereas gpt-image-2 has been decoupled into an independent image model using a single-stage inference architecture. This is the foundation for its 3-second speed, which also implies that the throughput of batch pipelines could increase by an order of magnitude.
A Deep Dive into the 8 Major Upgrades of gpt-image-2 vs. gpt-image-1.5
Upgrade 1: Near-Perfect Text Rendering
LM Arena testers report that gpt-image-2 achieves a character-level accuracy of approximately 99%. Text now integrates naturally into scenes (such as UI interfaces, posters, and signs) rather than appearing to "float" above the image like in older models.
This has been a persistent pain point for all major image models (Midjourney, Stable Diffusion, Imagen, Flux), and it has finally been systematically resolved in gpt-image-2.
Upgrade 2: Photorealism That Fools the Eye
Multiple testers have reported that portraits, beach selfies, and product close-ups generated by gpt-image-2 are now difficult to distinguish from real photos:
- Correct Hand Anatomy: Natural finger proportions and joint angles.
- Accurate Sunglasses Reflections: Reflections match the scene perfectly.
- Goodbye Yellow Filter: The persistent "AI tint" that plagued the gpt-image-1 era is gone.
Upgrade 3: Deep World Knowledge
When testers requested "an IKEA store at night," "a YouTube homepage screenshot," or "a Minecraft scene with correct game UI," gpt-image-2’s ability to render real brands, interfaces, and environments was convincing enough to "pass" as a real photograph.
This means the model truly understands real-world visual conventions, rather than just relying on statistical pixel distributions.
Upgrade 4: Native 4K Output
While gpt-image-1.5 was limited to a maximum output of 1536×1024, gpt-image-2 is expected to natively support 2048×2048 and 4096×4096, along with 16:9 widescreen formats.
| Use Case | gpt-image-1.5 Experience | gpt-image-2 Experience |
|---|---|---|
| Commercial Printing | Requires post-processing upscale | Native 4K, ready for print |
| Marketing Key Visuals | Insufficient resolution | Native support for posters |
| High-Res Product Shots | Requires super-resolution | Single-pass generation |
| Video Thumbnails | Lacks 16:9 | Native widescreen support |
Upgrade 5: Faster Generation (~3 Seconds)
Arena observers measured single-pass generation at approximately 3 seconds—far exceeding the 10-20 second norm (or even the 35-55 second norm of the gpt-image-1 era) of previous flagship image models.
Whether it's for interactive UX (significantly lower wait times) or batch pipelines (3-5x higher throughput), the benefits are immediate.
Upgrade 6: Multilingual Text Rendering
Previews show that Latin, CJK (Chinese, Japanese, Korean), and Right-to-Left (Arabic, Hebrew) scripts are all clear and legible.
If this performance holds at launch, localized ad creatives and multilingual UI mockups will no longer require manual typesetting—a huge win for global teams, cross-border e-commerce, and multilingual content operations.
Upgrade 7: UI and Screenshot Generation
Testers specifically highlighted the UI rendering capabilities—web pages, app interfaces, and OS windows are rendered with surprising accuracy. This is perfect for:
- Design Exploration: Quickly generating UI concept drafts.
- Tutorial Assets: Creating example screenshots for technical documentation.
- Concept Pitching: Showing clients product interfaces that haven't been developed yet.
- A/B Testing Assets: Batch generating different interface styles for selection.
Upgrade 8: API Ready at Launch
As soon as OpenAI releases the API, APIYI will have it live immediately. Your existing apiyi.com API key, balance, and billing remain unchanged—no need to register new accounts, switch SDKs, or modify your business code.
Migration Tip: Before the official release of gpt-image-2, you can test the current gpt-image-1.5 via APIYI (apiyi.com) to get familiar with the
base_urlconfiguration and parameter structure. On the day of the official release, you'll only need to update themodelfield to complete the migration.
gpt-image-2 Quick Start (API Migration Guide)
Minimalist Example (Based on gpt-image-1.5; just swap the model name upon release)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # Replace with "gpt-image-2" after official release
prompt="A modern cafe menu board with hand-lettered text 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
View Full Implementation Code (Including 4K, 16:9, and Error Handling)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
Generate images, compatible with gpt-image-1.5 and the future gpt-image-2
Args:
prompt: Text prompt (up to 2000 tokens)
model: Model name (switch to gpt-image-2 after release)
size: Output dimensions (gpt-image-2 will support 2K/4K)
quality: Quality setting
n: Number of images to generate (currently only supports 1)
Returns:
Temporary URL of the generated image (valid for 24 hours)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"Image generation failed: {e}")
return None
url = generate_image(
prompt="Product hero shot: sleek wireless earbuds on marble, 'AuraPods Pro' label visible",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"Image URL: {url}")
Platform Tip: Get free testing credits via APIYI (apiyi.com) to experience the latest capabilities of gpt-image-1.5 immediately. You won't need to change any code when gpt-image-2 officially launches.
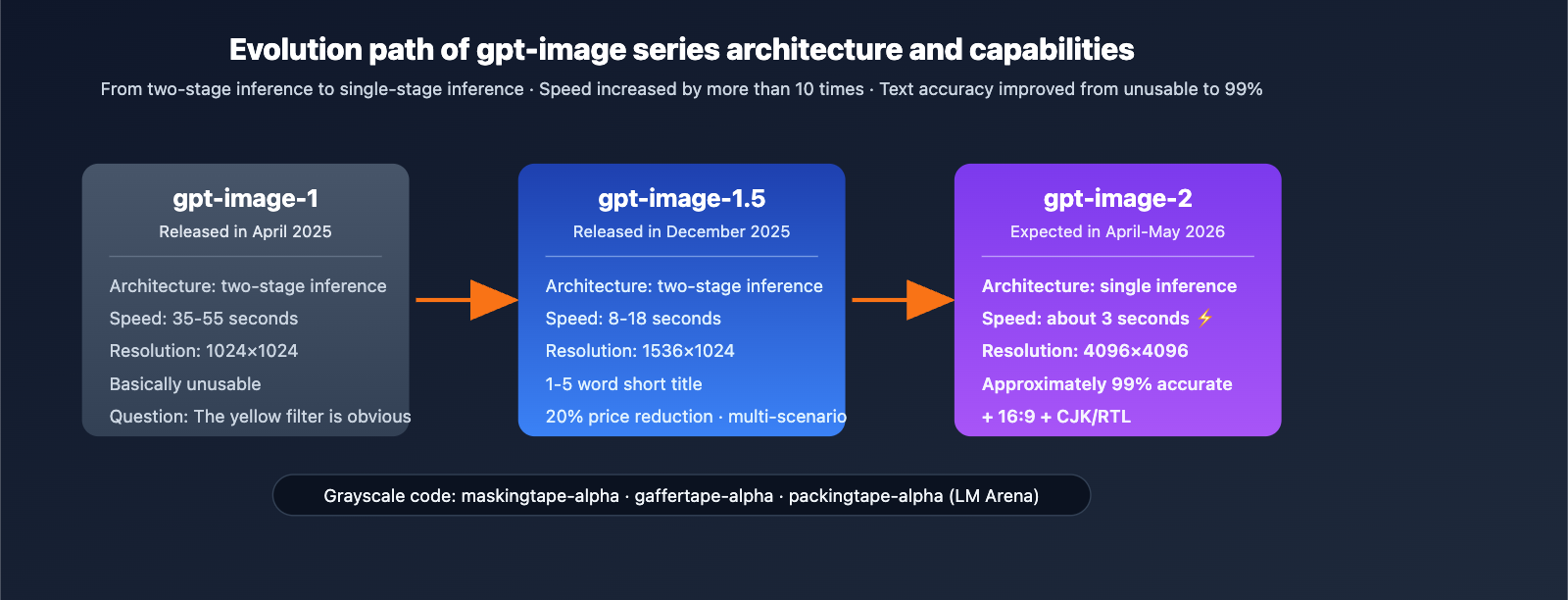
gpt-image-2 vs gpt-image-1.5 Comparison
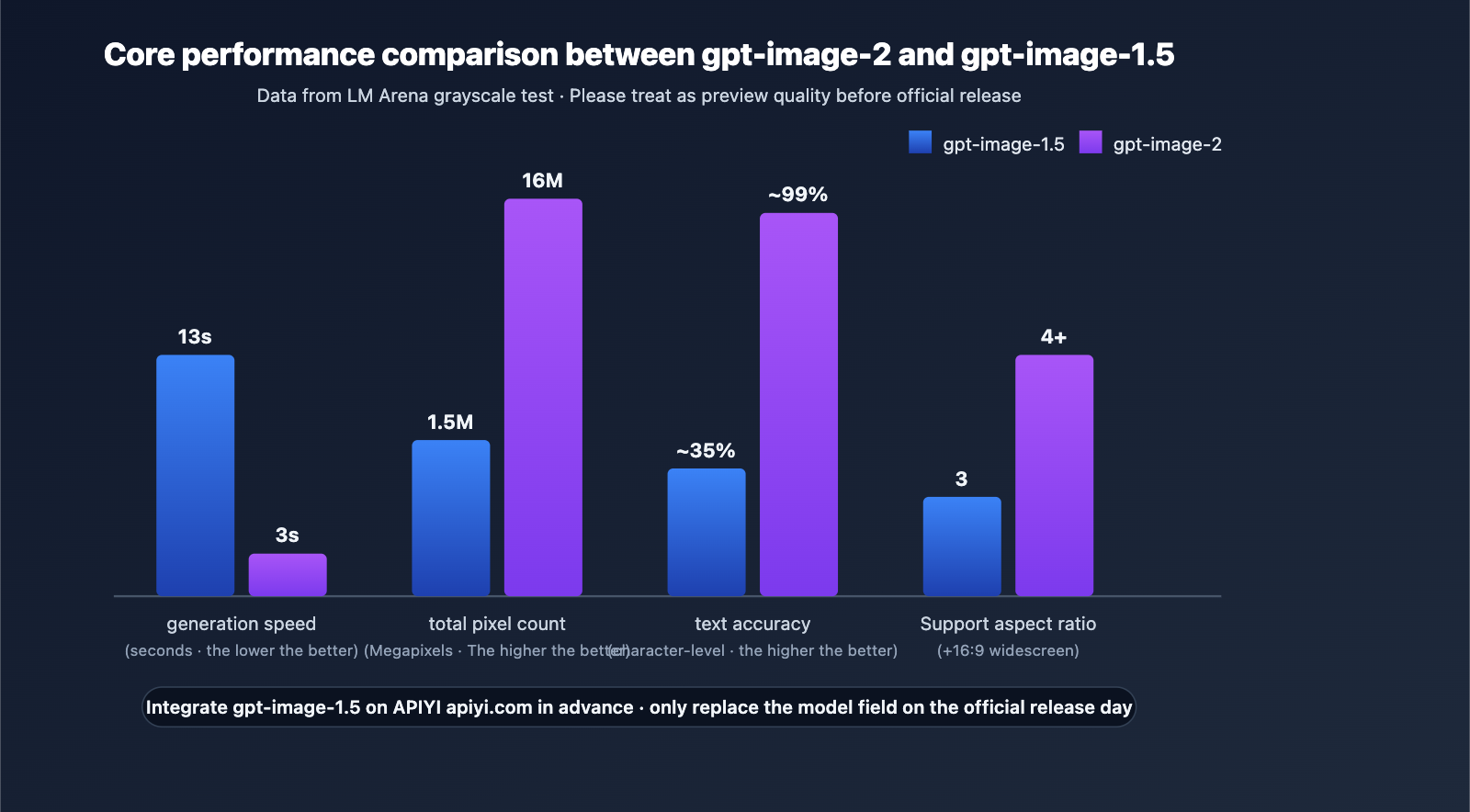
| Dimension | gpt-image-1.5 (Dec 2025) | gpt-image-2 (Est. Apr-May 2026) | Significance |
|---|---|---|---|
| Architecture | Two-stage inference | Single-stage inference | Massive throughput boost |
| Speed | 8-18 seconds | ~3 seconds | 3-5x faster |
| Max Resolution | 1536×1024 | 4096×4096 | Ready for commercial print |
| Aspect Ratios | 1:1/3:4/4:3 | + 16:9 Widescreen | Great for video thumbnails |
| Text Accuracy | Short 1-5 word titles | ~99% character-level | No more manual layout |
| Multilingual | Unstable for non-Latin | Clear CJK/RTL support | Benefits localized content |
| UI Fidelity | Average | "Fake" realistic screenshots | Useful for design/tutorials |
Upgrade Benchmarking
Vs. Midjourney: Midjourney remains the leader in artistic style generation. However, its API access is restricted and text rendering has long been a weak point. In contrast, gpt-image-2 offers standard API access and 99% text accuracy, making it much better for integration into automated workflows.
Vs. Imagen 2: Google Imagen 2 has an edge in photographic realism. But its API ecosystem is relatively closed, and support for non-English languages is limited. By comparison, gpt-image-2 is more balanced across multilingual text, UI fidelity, and speed, making it a great choice for global teams.
Vs. nano-banana-pro: nano-banana-pro stands out for its cost-effectiveness. However, it falls short of the expected 4K output and brand reproduction capabilities of gpt-image-2. For commercial printing and brand marketing scenarios, gpt-image-2 remains the more reliable choice.
Note on Comparison: Some of the data above is sourced from public LM Arena testing and early feedback from testers. Please treat gpt-image-2 data as preview-quality until the official release. We recommend testing gpt-image-1.5 via APIYI (apiyi.com) to get familiar with the parameter structure.
gpt-image-2 Use Cases
Consider upgrading to gpt-image-2 for the following scenarios:
- Scenario 1—Commercial Printing: Native 4K output solves resolution bottlenecks for posters, brochures, and large-format ads.
- Scenario 2—Localized Advertising: Multilingual text rendering eliminates the need for manual layout, significantly boosting efficiency for global teams.
- Scenario 3—UI Design Exploration: Allows product managers and designers to quickly generate concept drafts and tutorial materials.
- Scenario 4—E-commerce Hero Images: Portrait-level realism and accurate product text are perfect for marketing visuals.
- Scenario 5—Video Content: 16:9 widescreen support for batch-generating YouTube or short-video thumbnails.
Recommendation: If you're currently evaluating image APIs, we suggest integrating gpt-image-1.5 via APIYI (apiyi.com) first. Once the official version is released, you'll only need to update the
modelfield for a seamless upgrade.
FAQ
Q1: What is gpt-image-2?
gpt-image-2 is OpenAI's next-generation image generation model, expected to be released between April and May 2026. Based on LM Arena beta testing, the model uses a single-inference architecture, achieves approximately 99% accuracy in text rendering, generates images in about 3 seconds, and natively supports 4K output. It represents a major upgrade following gpt-image-1 (April 2025) and gpt-image-1.5 (December 2025).
Q2: What are the differences between gpt-image-2 and gpt-image-1.5?
The core differences span eight dimensions: text rendering (5 words → 99%), speed (8-18 seconds → 3 seconds), resolution (1536×1024 → 4096×4096), aspect ratios (new 16:9 support), realism (elimination of yellow tint), world knowledge (precise branding/UI), multilingual support (clear CJK/RTL), and UI reproduction (capable of mimicking realistic screenshots). While gpt-image-1.5 remains sufficient for short titles and standard aspect ratios, we recommend waiting for gpt-image-2 for commercial printing, localization, and UI-related tasks.
Q3: When will gpt-image-2 be released?
As of April 17, 2026, OpenAI has not made an official announcement. Based on historical beta testing cycles (which typically lead to an official release within 2-4 weeks), the industry expects a release window between late April and mid-May 2026. The three codenamed models on LM Arena (maskingtape-alpha, gaffertape-alpha, and packingtape-alpha) are currently undergoing A/B testing.
Q4: Which use cases is gpt-image-2 best suited for?
It is primarily suited for the following scenarios:
- Commercial-grade posters/brochures: Native 4K output eliminates the need for post-processing upscaling.
- Localized social media images: Multilingual text rendering removes the need for Photoshop layout work.
- UI design concept drafts: Generating example screenshots for product exploration and tutorials.
- E-commerce marketing images: Realistic portraits combined with accurate product text.
- Video platform thumbnails: Batch generation with native 16:9 aspect ratios.
Q5: How can I quickly integrate gpt-image-2 via API?
We recommend integrating early via APIYI (apiyi.com) so you're ready the moment gpt-image-2 is released:
- Visit apiyi.com to register an account and obtain your API key.
- Use
base_url=https://vip.apiyi.com/v1to call the current gpt-image-1.5 and get familiar with the parameters. - On the day gpt-image-2 is released, simply update the
modelfield fromgpt-image-1.5togpt-image-2.
APIYI launches new models in sync with OpenAI, so your existing keys, balance, and billing remain unchanged—no need to register a new account or switch SDKs.
Q6: What are the known limitations or uncertainties of gpt-image-2?
The main uncertainties stem from the fact that it hasn't been officially released yet:
- Pricing is unknown: gpt-image-1.5 was about 20% cheaper than gpt-image-1; we are waiting for official confirmation on gpt-image-2 pricing.
- Rate limits: There may be usage quotas during the initial launch; using an API proxy service is recommended to avoid cold-start issues.
- Potential capability adjustments: There may be differences between the LM Arena beta and the final version, so treat it as a preview.
- Fallback plan: If you have an urgent project, the current gpt-image-1.5 remains a stable and reliable flagship choice.
Q7: Will gpt-image-2 replace DALL-E 3?
Following OpenAI's release cadence, DALL-E 3 is expected to be gradually phased out after the official release of gpt-image-2. Regarding migration, the gpt-image series has become the official focus, and the API parameter structure is already stable. We suggest that new projects adopt gpt-image-1.5 or wait for gpt-image-2 to avoid investing too much effort into DALL-E 3 customizations.
Q8: Are the “tape” series models on LM Arena definitely gpt-image-2?
There is no official confirmation yet, but four pieces of evidence strongly point to OpenAI:
- The naming style (the "tape" series) aligns with OpenAI's historical codename conventions.
- The 99% text rendering and world knowledge capabilities surpass all existing public models.
- The testing window aligns with OpenAI's typical beta release cadence.
- The model's output style is consistent with the gpt-image series (distinct from Midjourney/Imagen styles).
We recommend keeping an eye on official announcements and waiting for the synchronized launch on APIYI (apiyi.com).
gpt-image-2 Key Takeaways
- Next-gen model: OpenAI's 2026 image flagship, replacing gpt-image-1.5, with an architecture shift from two-stage to single-inference.
- Eight major upgrades: 99% text accuracy, 3-second speed, native 4K, 16:9 aspect ratio, realism, world knowledge, multilingual support, and UI reproduction.
- Use cases: Prioritize for commercial printing, localized advertising, UI concept drafts, e-commerce images, and video thumbnails.
- Release cadence: Expected between late April and mid-May 2026; currently in beta under the "tape" codename.
- Seamless migration: Integrate early with gpt-image-1.5 via APIYI (apiyi.com) and simply swap the
modelfield on launch day.
Summary
Key takeaways from the comparison between gpt-image-2 and gpt-image-1.5:
- A Qualitative Leap: Core metrics—text rendering, speed, and resolution—have reached or exceeded production-grade standards. It’s no longer a case of "it works, but needs post-processing."
- New Use Cases Unlocked: Commercial printing, multilingual localization, and UI reproduction are now truly viable for the first time, significantly cutting down on manual post-processing costs.
- Seamless Migration: The API parameter structure remains compatible with gpt-image-1.5, allowing teams that have already laid the groundwork to switch over on launch day with zero code changes.
For team decision-making, we recommend integrating gpt-image-1.5 via APIYI (apiyi.com) immediately to get familiar with the parameters and workflows. The platform offers free credits and a unified interface, so you can simply swap the model field on the day gpt-image-2 launches to enjoy all eight major upgrades.
延伸阅读 Related Articles
If you're interested in gpt-image-2, we recommend checking out these resources:
- 📘 Complete API Invocation Guide for gpt-image-1.5 – Master the parameters and best practices for the current flagship image model.
- 📊 gpt-image-2 vs. nano-banana-pro: Price and Quality Comparison – Understand the cost structure of mainstream image APIs.
- 🚀 Optimizing Batch Calls for Image Generation APIs in Production – Explore batch pipelines, concurrency, and caching strategies.
📚 References
-
MindStudio Analysis: "What Is GPT Image 2" Comprehensive Breakdown
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Description: A systematic overview of the gpt-image-2 capability matrix from a top-ranked international blog.
- Link:
-
getimg.ai Leak Analysis: GPT Image 2 Rumours, Leaks & Release Date
- Link:
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - Description: First-hand observations on the performance of the three "tape" codenamed models in the LM Arena.
- Link:
-
OpenAI Official Blog: Announcement of ChatGPT Image Feature Upgrades
- Link:
openai.com/index/new-chatgpt-images-is-here - Description: The official authoritative guide on the evolution path of the gpt-image series.
- Link:
-
gpt-image-1.5 Parameter Documentation: Compiled by EvoLink
- Link:
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - Description: Detailed parameters regarding speed, resolution, and quality tiers for gpt-image-1.5.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to join the discussion in the comments section. For more resources, visit the APIYI documentation center at docs.apiyi.com.