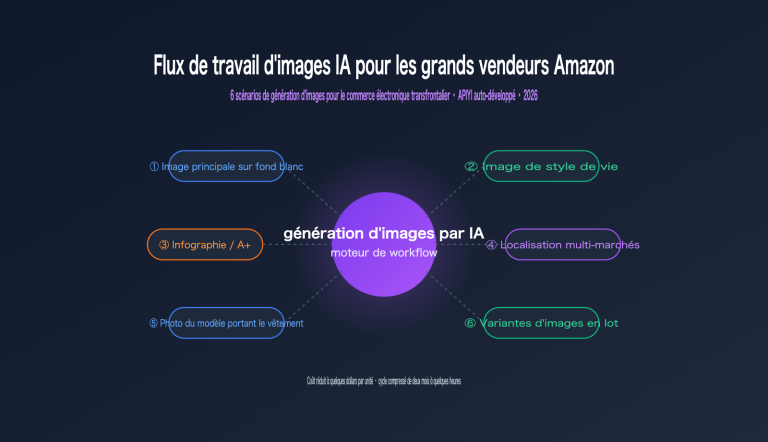
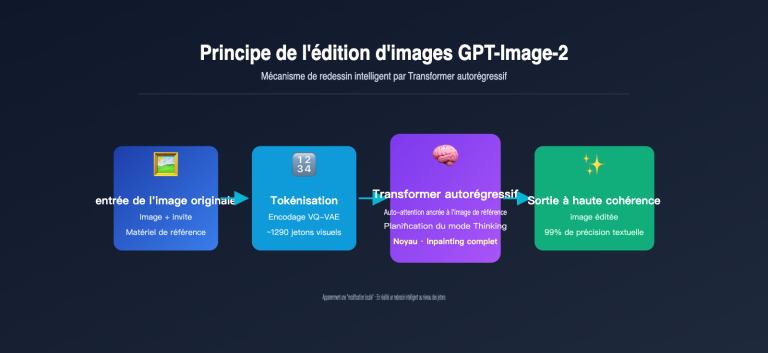
Note de l'auteur : Basé sur les fuites des tests en niveaux de gris du LM Arena, voici une analyse complète des 8 améliorations majeures de gpt-image-2 par rapport à gpt-image-1.5, incluant le rendu de texte, le réalisme, la sortie 4K, la vitesse, le support multilingue et la génération de captures d'écran UI.
Début avril 2026, trois modèles d'image anonymes, maskingtape-alpha, gaffertape-alpha et packingtape-alpha, sont apparus discrètement sur la plateforme d'évaluation LM Arena. De nombreux testeurs précoces ont rapporté que leur précision de rendu de texte approchait les 99 %, que la vitesse de génération était d'environ 3 secondes et qu'ils supportaient nativement la sortie 4K — la communauté s'accorde à dire qu'il s'agit du futur gpt-image-2 d'OpenAI.
Ce n'est pas du "vaporware" (produit fantôme) : les enregistrements de tests publics sur LM Arena, les captures d'écran comparatives de plusieurs testeurs indépendants et le cycle historique des tests en niveaux de gris d'OpenAI (généralement suivis d'une sortie officielle sous 2 à 4 semaines) pointent tous vers la même conclusion. Cet article compare systématiquement les huit améliorations clés de gpt-image-2 vs gpt-image-1.5.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez clairement les progrès réalisés par gpt-image-2 en termes de texte, de réalisme, de 4K, de vitesse, de rendu d'interface utilisateur et de multilinguisme, ainsi que la manière de migrer en toute transparence dès le premier jour de l'ouverture de l'API.

Points clés de gpt-image-2
| Dimension d'amélioration | État actuel gpt-image-1.5 | Amélioration gpt-image-2 |
|---|---|---|
| Rendu de texte | Titres courts de 1-5 mots | Précision au caractère ~99% |
| Vitesse de génération | 8-18 secondes | ~3 secondes (3-5x plus rapide) |
| Résolution maximale | 1536×1024 | 2048×2048 / 4096×4096 |
| Support écran large | 1:1, 4:3, 3:4 uniquement | Nouveau format 16:9 |
| Réalisme | "Filtre jaune IA" présent | Portraits/produits bluffants |
Signification globale des améliorations de gpt-image-2
Le texte n'est plus un point faible. À l'ère de gpt-image-1.5, la plupart des modèles d'image échouaient sur le rendu de texte dépassant 5 ou 6 mots. Cependant, les testeurs du LM Arena rapportent que les étiquettes d'interface, les enseignes et le texte sur les affiches générés par gpt-image-2 ne nécessitent quasiment plus de retouches. Cela signifie que la création publicitaire localisée, les maquettes d'interface et les images pour les réseaux sociaux n'auront plus besoin de mise en page manuelle.
Vers une inférence en une seule étape. Alors que gpt-image-1.5 reposait encore sur une architecture en deux étapes, gpt-image-2 aurait été découplé pour devenir un modèle d'image indépendant utilisant une architecture d'inférence unique. C'est le pilier technique permettant d'atteindre une vitesse de 3 secondes, ce qui signifie également que le débit des pipelines de traitement par lots pourrait être multiplié par dix.

Analyse détaillée des 8 améliorations majeures : gpt-image-2 vs gpt-image-1.5
Amélioration 1 : Un rendu de texte quasi parfait
Les testeurs de la LM Arena rapportent que le taux de précision au niveau des caractères pour gpt-image-2 est d'environ 99 %. Le texte s'intègre naturellement dans la scène (interfaces UI, affiches, enseignes), évitant cet effet de texte "flottant" au-dessus de l'image propre aux anciens modèles.
Il s'agit d'un problème persistant qui affectait tous les modèles d'image majeurs (Midjourney, Stable Diffusion, Imagen, Flux), et qui est enfin résolu de manière systématique avec gpt-image-2.
Amélioration 2 : Un réalisme à s'y méprendre
Plusieurs testeurs ont souligné que les portraits, les selfies à la plage et les gros plans de produits générés par gpt-image-2 sont désormais si réalistes qu'il est difficile de déterminer s'ils sont générés par une IA :
- Anatomie des mains correcte : proportions des cinq doigts et angles des articulations naturels.
- Reflets précis sur les lunettes de soleil : le contenu réfléchi est cohérent avec la scène.
- Disparition du filtre jaune : la "teinte IA" omniprésente à l'époque de gpt-image-1 a disparu.
Amélioration 3 : Une connaissance approfondie du monde
Lorsque les testeurs demandent un "magasin IKEA de nuit", une "capture d'écran de la page d'accueil YouTube" ou une "scène Minecraft avec une interface de jeu correcte", gpt-image-2 restitue les marques, interfaces et environnements réels de manière si convaincante qu'ils pourraient passer pour de vraies photos.
Cela signifie que le modèle comprend réellement les conventions visuelles du monde réel, et ne se contente pas d'une distribution statistique de pixels.
Amélioration 4 : Sortie native 4K
Alors que la sortie maximale de gpt-image-1.5 était limitée à 1536×1024, gpt-image-2 devrait prendre en charge nativement le 2048×2048 et le 4096×4096, en plus du format large 16:9.
| Cas d'utilisation | Expérience gpt-image-1.5 | Expérience gpt-image-2 |
|---|---|---|
| Impression commerciale | Nécessite un agrandissement | 4K natif, prêt à imprimer |
| Visuels marketing | Résolution insuffisante | Format affiche natif |
| Images produit HD | Nécessite un suréchantillonnage | Génération directe |
| Miniatures vidéo | Format 16:9 absent | Support natif écran large |
Amélioration 5 : Génération plus rapide (environ 3 secondes)
Les observateurs de l'Arena ont mesuré un temps de génération d'environ 3 secondes par image, dépassant largement les 10 à 20 secondes (voire 35 à 55 secondes à l'époque de gpt-image-1) des modèles phares précédents.
Que ce soit pour une UX interactive (réduction significative du temps d'attente utilisateur) ou des pipelines de traitement par lots (productivité multipliée par 3 à 5), les gains seront immédiats.
Amélioration 6 : Rendu de texte multilingue
Dans les aperçus, le rendu des caractères latins, CJK (chinois, japonais, coréen) et des écritures de droite à gauche (arabe, hébreu) est parfaitement lisible.
Si cette performance se confirme lors du lancement, la création publicitaire localisée et les maquettes d'UI multilingues ne nécessiteront plus de mise en page manuelle — une excellente nouvelle pour les équipes internationales, l'e-commerce transfrontalier et la gestion de contenu multilingue.
Amélioration 7 : Génération d'UI et de captures d'écran
Les testeurs ont particulièrement noté la capacité de restitution des interfaces utilisateur (pages web, applications, fenêtres système) avec une précision surprenante. Idéal pour :
- Exploration du design : génération rapide de concepts d'UI.
- Supports de tutoriels : création de captures d'écran exemples pour la documentation technique.
- Maquettes conceptuelles : présentation d'interfaces de produits non encore développés aux clients.
- Supports de tests A/B : génération en masse de différents styles d'interfaces pour comparaison.
Amélioration 8 : API disponible dès le lancement
Dès qu'OpenAI ouvrira l'API, APIYI sera prêt. Vos clés API, soldes et factures sur apiyi.com restent inchangés — pas besoin de créer un nouveau compte, de changer de SDK ou de modifier votre code métier.
Conseil de migration : Avant la sortie officielle de gpt-image-2, vous pouvez tester gpt-image-1.5 via APIYI apiyi.com pour vous familiariser avec la configuration
base_urlet la structure des paramètres. Le jour du lancement, il suffira de remplacer le champmodelpour effectuer la migration.
Prise en main rapide de gpt-image-2 (Guide de migration API)
Exemple minimal (basé sur gpt-image-1.5, remplacez simplement le nom du modèle lors de la sortie officielle)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # À remplacer par "gpt-image-2" après la sortie officielle
prompt="A modern cafe menu board with hand-lettered text 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Voir le code complet (incluant 4K, 16:9, gestion des erreurs)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
Génère une image, compatible avec gpt-image-1.5 et le futur gpt-image-2
Args:
prompt: Invite textuelle (jusqu'à 2000 jetons)
model: Nom du modèle (à basculer sur gpt-image-2 après sortie)
size: Dimensions de sortie (gpt-image-2 supportera le 2K/4K)
quality: Niveau de qualité
n: Nombre d'images (actuellement limité à 1)
Returns:
URL temporaire de l'image générée (valide 24h)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"Échec de la génération d'image : {e}")
return None
url = generate_image(
prompt="Product hero shot: sleek wireless earbuds on marble, 'AuraPods Pro' label visible",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"URL de l'image : {url}")
Conseil plateforme : Obtenez des crédits de test gratuits via APIYI apiyi.com pour découvrir immédiatement les dernières capacités de gpt-image-1.5. Aucun changement de code ne sera nécessaire lors du lancement officiel de gpt-image-2.
Comparaison des solutions gpt-image-2 et gpt-image-1.5
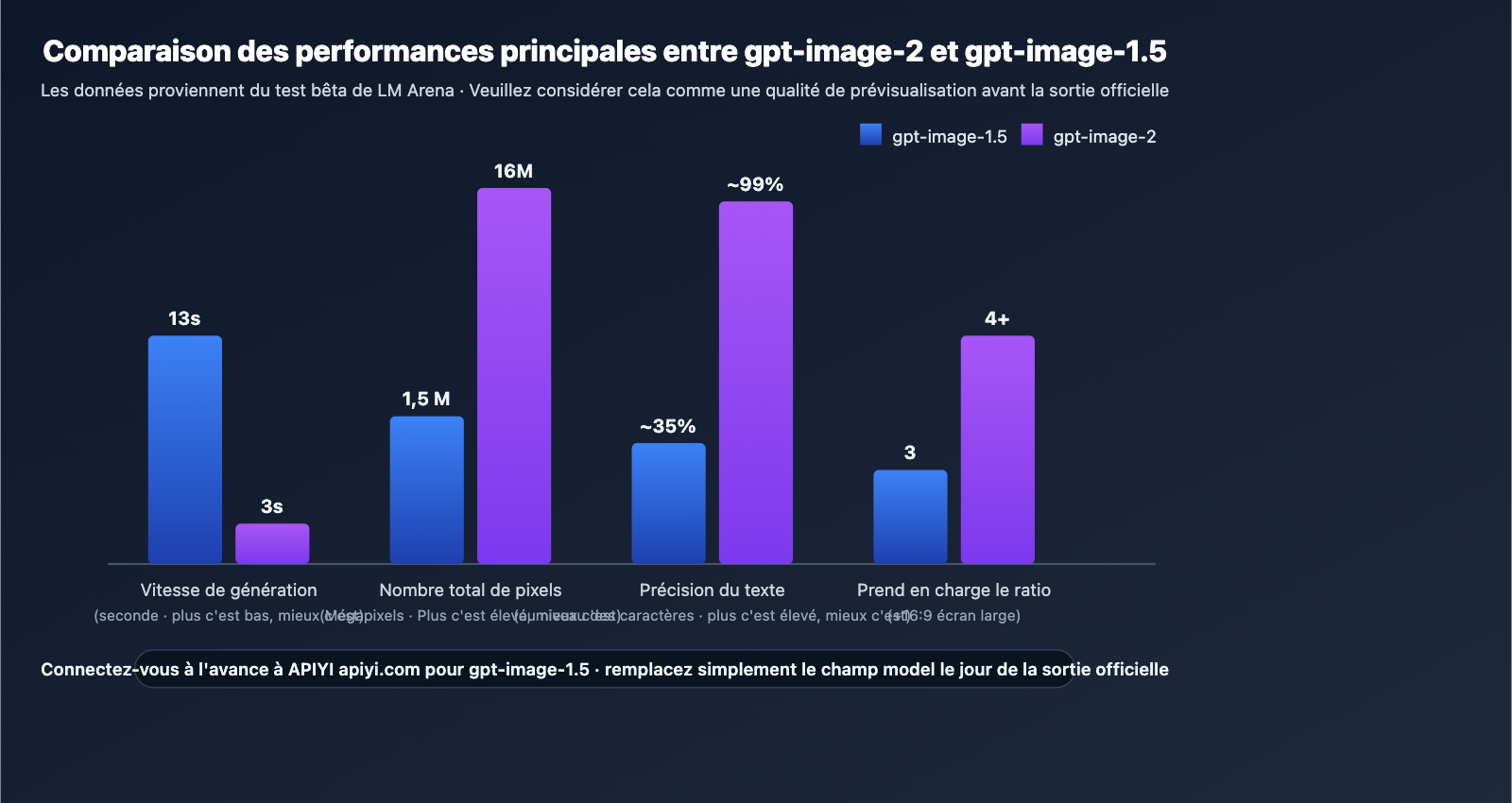
| Dimension | gpt-image-1.5 (déc. 2025) | gpt-image-2 (prévu avr.-mai 2026) | Signification de l'écart |
|---|---|---|---|
| Architecture | Inférence en deux étapes | Inférence unique | Hausse massive du débit |
| Vitesse | 8-18 secondes | Env. 3 secondes | 3 à 5 fois plus rapide |
| Résolution max. | 1536×1024 | 4096×4096 | Prêt pour l'impression |
| Formats supportés | 1:1/3:4/4:3 | + 16:9 panoramique | Idéal pour les miniatures |
| Précision texte | Titres courts (1-5 mots) | ~99% au niveau caractère | Fin de la mise en page manuelle |
| Multilingue | Instable hors latin | CJK/RTL parfaitement lisibles | Idéal pour la localisation |
| Rendu UI | Moyen | "Imitation" de captures réelles | Parfait pour design/tutos |
Analyse comparative des mises à niveau
Face à Midjourney : Midjourney reste en tête pour le style artistique. Cependant, son accès API est limité et son rendu de texte est historiquement faible. À l'inverse, gpt-image-2 propose une API standard et une précision de texte de 99 %, ce qui le rend bien plus adapté à une intégration dans des flux de travail automatisés.
Face à Imagen 2 : Google Imagen 2 excelle dans le photoréalisme. Mais son écosystème API est assez fermé et le support des langues autres que l'anglais est limité. gpt-image-2 est plus équilibré sur les aspects multilingue, rendu d'interface et vitesse, ce qui est un atout pour les équipes tournées vers l'international.
Face à nano-banana-pro : nano-banana-pro se distingue par son rapport qualité-prix. Toutefois, il n'atteint pas les capacités de sortie 4K et de fidélité de marque attendues avec gpt-image-2. Pour des besoins d'impression commerciale et de marketing, gpt-image-2 reste le choix le plus robuste.
Note sur la comparaison : Ces données proviennent en partie de tests publics sur le LM Arena et de retours de bêta-testeurs. Considérez ces performances comme des prévisualisations avant la sortie officielle de gpt-image-2. Il est conseillé de tester gpt-image-1.5 via APIYI (apiyi.com) pour vous familiariser avec la structure des paramètres.
Cas d'usage de gpt-image-2
Pensez à passer à gpt-image-2 pour les scénarios suivants :
- Scénario 1 — Impression commerciale : La sortie native 4K résout les problèmes de résolution pour les affiches, catalogues et publicités grand format.
- Scénario 2 — Publicité localisée : Le rendu de texte multilingue permet de créer des visuels sans mise en page manuelle, un gain de productivité majeur pour les équipes internationales.
- Scénario 3 — Exploration design UI : Permet aux chefs de produit et designers de générer rapidement des maquettes conceptuelles et des supports de tutoriels.
- Scénario 4 — Visuels e-commerce : Le réalisme des portraits et la précision du texte sur les produits sont parfaits pour les visuels marketing.
- Scénario 5 — Contenu vidéo : Le support du format 16:9 facilite la génération en masse de miniatures pour YouTube ou les réseaux sociaux.
Conseil d'utilisation : Si vous évaluez actuellement une API d'image, nous vous recommandons d'intégrer gpt-image-1.5 via APIYI (apiyi.com). Une fois la version finale disponible, il vous suffira de mettre à jour le champ
modelpour une transition transparente.
FAQ – Foire aux questions
Q1 : Qu’est-ce que gpt-image-2 ?
gpt-image-2 est le modèle de génération d'images de nouvelle génération d'OpenAI, dont la sortie est prévue pour avril-mai 2026. Selon les tests en mode "gris" sur LM Arena, ce modèle utilise une architecture d'inférence en une seule étape, avec un taux de précision de rendu de texte d'environ 99 %, une vitesse d'environ 3 secondes et une prise en charge native de la sortie 4K. Il s'agit d'une mise à niveau majeure après gpt-image-1 (avril 2025) et gpt-image-1.5 (décembre 2025).
Q2 : Quelles sont les différences entre gpt-image-2 et gpt-image-1.5 ?
Les différences fondamentales se situent sur huit axes : le rendu de texte (5 mots → 99 %), la vitesse (8-18 secondes → 3 secondes), la résolution (1536×1024 → 4096×4096), le format (ajout du 16:9), le réalisme (suppression du filtre jaune), les connaissances mondiales (précision des marques/UI), le multilinguisme (clarté CJK/RTL) et la fidélité de l'interface utilisateur (capable de simuler des captures d'écran réelles). Bien que gpt-image-1.5 reste suffisant pour les titres courts et les formats standards, il est conseillé d'attendre gpt-image-2 pour l'impression commerciale, la localisation et les interfaces utilisateur.
Q3 : Quand gpt-image-2 sera-t-il publié ?
Au 17 avril 2026, OpenAI n'a pas encore fait d'annonce officielle. Sur la base des cycles historiques de tests en mode "gris" (généralement suivis d'une sortie officielle sous 2 à 4 semaines), l'industrie prévoit une fenêtre de lancement entre fin avril et mi-mai 2026. Les trois modèles sous nom de code sur LM Arena (maskingtape-alpha, gaffertape-alpha, packingtape-alpha) sont actuellement en phase de test A/B.
Q4 : Pour quels cas d’utilisation gpt-image-2 est-il le plus adapté ?
Il est principalement destiné aux scénarios suivants :
- Affiches/brochures de qualité impression commerciale : la sortie native 4K évite le recours à l'upscaling post-traitement.
- Images pour réseaux sociaux localisées : le rendu de texte multilingue élimine le besoin de mise en page sous Photoshop.
- Maquettes de design UI : génération d'exemples de captures d'écran pour l'exploration de produits et les tutoriels.
- Images principales pour le e-commerce : portraits réalistes combinés à un texte produit précis.
- Miniatures pour plateformes vidéo : génération en masse au format natif 16:9.
Q5 : Comment appeler rapidement gpt-image-2 via l’API ?
Il est recommandé de passer par APIYI (apiyi.com) pour une intégration anticipée, afin d'être prêt dès la sortie de gpt-image-2 :
- Visitez apiyi.com pour créer un compte et obtenir une clé API.
- Utilisez
base_url=https://vip.apiyi.com/v1pour appeler le modèle gpt-image-1.5 actuel et vous familiariser avec les paramètres. - Le jour de la sortie de gpt-image-2, il suffira de remplacer le champ
modeldegpt-image-1.5pargpt-image-2.
APIYI lance les nouveaux modèles en synchronisation avec OpenAI ; vos clés API, votre solde et votre facturation restent inchangés, sans avoir besoin de créer un nouveau compte ou de changer de SDK.
Q6 : Quelles sont les limites ou incertitudes connues concernant gpt-image-2 ?
Les principales incertitudes découlent de l'absence de publication officielle :
- Tarification inconnue : gpt-image-1.5 était environ 20 % moins cher que gpt-image-1 ; le prix de gpt-image-2 reste à confirmer.
- Limites de débit : des quotas d'invocation pourraient exister au lancement ; il est conseillé d'utiliser un service proxy API pour éviter les problèmes de démarrage à froid.
- Ajustements potentiels des capacités : des différences peuvent exister entre la version de test sur LM Arena et la version finale ; considérez les performances actuelles comme un aperçu.
- Solution de secours : si votre projet est urgent, gpt-image-1.5 reste une option phare stable et disponible.
Q7 : gpt-image-2 va-t-il remplacer DALL-E 3 ?
Selon le rythme de publication d'OpenAI, DALL-E 3 devrait être progressivement retiré après la sortie officielle de gpt-image-2. Concernant la migration, la gamme gpt-image est devenue la priorité officielle et la structure des paramètres API est désormais stable. Il est conseillé aux nouveaux projets d'adopter directement gpt-image-1.5 ou d'attendre gpt-image-2, afin d'éviter d'investir trop d'efforts de personnalisation sur DALL-E 3.
Q8 : Les modèles de la série « tape » sur LM Arena sont-ils forcément gpt-image-2 ?
Il n'y a pas de confirmation officielle, mais quatre éléments pointent fortement vers OpenAI :
- Le style de nommage (série "tape") correspond aux habitudes de noms de code historiques d'OpenAI.
- Les deux capacités (rendu de texte à 99 % et connaissances mondiales) dépassent tous les modèles publics existants.
- La période de test coïncide avec le rythme habituel des tests en mode "gris" d'OpenAI.
- Le style de sortie du modèle est cohérent avec la gamme gpt-image (différent du style Midjourney/Imagen).
Nous vous conseillons de suivre les annonces officielles et d'attendre la disponibilité sur APIYI (apiyi.com).
Points clés de gpt-image-2
- Modèle de nouvelle génération : le fleuron de l'image chez OpenAI pour 2026, remplaçant gpt-image-1.5, avec une architecture passant de deux étapes à une inférence unique.
- Huit améliorations majeures : texte à 99 %, vitesse de 3 secondes, 4K natif, 16:9, réalisme, connaissances mondiales, multilinguisme et fidélité UI.
- Cas d'utilisation : priorité à l'impression commerciale, aux publicités localisées, aux maquettes UI, aux images e-commerce et aux miniatures vidéo.
- Rythme de sortie : prévu entre fin avril et mi-mai 2026, avec la série "tape" comme nom de code actuel.
- Migration transparente : intégrez gpt-image-1.5 dès maintenant via APIYI (apiyi.com) et remplacez simplement le champ
modelle jour de la sortie.
Résumé
Points clés de la comparaison entre gpt-image-2 et gpt-image-1.5 :
- Un saut qualitatif : Les trois indicateurs fondamentaux — rendu du texte, vitesse et résolution — atteignent ou dépassent désormais les standards de production. On passe d'un outil "utilisable mais nécessitant des retouches" à une solution professionnelle.
- Nouveaux cas d'usage : Pour la première fois, des domaines comme l'impression commerciale, la localisation multilingue et la reproduction d'interfaces utilisateur (UI) deviennent réellement exploitables, réduisant considérablement les coûts de post-traitement manuel.
- Migration transparente : La structure des paramètres API reste compatible avec celle de gpt-image-1.5. Les équipes ayant anticipé cette transition pourront basculer vers la nouvelle version dès le jour du lancement sans aucune modification de code.
Pour les décisions stratégiques de votre équipe, nous recommandons d'intégrer dès maintenant gpt-image-1.5 via APIYI (apiyi.com) afin de vous familiariser avec les paramètres et les flux de travail. La plateforme propose des crédits gratuits et une interface unifiée ; le jour de la sortie de gpt-image-2, il vous suffira de mettre à jour le champ model pour profiter immédiatement des huit améliorations majeures.
Lectures complémentaires
Si gpt-image-2 vous intéresse, nous vous recommandons de consulter les articles suivants :
- 📘 Guide complet de l'API gpt-image-1.5 – Maîtrisez les paramètres et les meilleures pratiques du modèle d'image phare actuel.
- 📊 Comparatif prix et qualité : gpt-image-2 vs nano-banana-pro – Comprenez la structure des coûts des principales API d'image.
- 🚀 Optimisation des appels en masse pour les API de génération d'images en production – Explorez les pipelines de traitement par lots, la gestion de la concurrence et les stratégies de mise en cache.
📚 Références
-
Analyse MindStudio : Interprétation complète de "What Is GPT Image 2"
- Lien :
mindstudio.ai/blog/what-is-gpt-image-2 - Description : Synthèse systématique de la matrice de capacités de gpt-image-2 par un blog international de premier plan.
- Lien :
-
Analyse des fuites getimg.ai : Rumeurs, fuites et date de sortie de GPT Image 2
- Lien :
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - Description : Observations de première main sur les performances des trois modèles au nom de code "tape" dans le LM Arena.
- Lien :
-
Blog officiel d'OpenAI : Annonce de la mise à jour des fonctionnalités d'image de ChatGPT
- Lien :
openai.com/index/new-chatgpt-images-is-here - Description : Explication officielle de la trajectoire d'évolution de la série gpt-image.
- Lien :
-
Documentation des paramètres gpt-image-1.5 : Compilation par EvoLink
- Lien :
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - Description : Paramètres détaillés concernant la vitesse, la résolution et les niveaux de qualité de gpt-image-1.5.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans la section commentaires. Pour plus d'informations, consultez le centre de documentation APIYI sur docs.apiyi.com.