Claude Opus 4.7 was officially released on April 16, 2026, and by the next day, it had already sparked polarized discussions across the community. While official benchmarks claim it outperforms version 4.6 in 12 out of 14 tests, a large number of developers on GitHub and X have complained that it performs worse than 4.6, with some even calling it a "pre-rebadged 4.6 disguised as a new version.".
This article provides an in-depth evaluation of Claude Opus 4.7 across eight dimensions—including coding capabilities, visual recognition, long context, Tokenizer changes, and Task Budgets—based on official Anthropic data, independent third-party testing, and firsthand community feedback to help you decide if it’s worth migrating immediately.
Core Value: After reading this, you'll know whether upgrading to Claude Opus 4.7 is a step forward or backward for your business scenarios and how to mitigate migration risks.

Claude Opus 4.7 Release Background and Key Info
Claude Opus 4.7 is Anthropic's flagship model launched on April 16, 2026. It inherits the $5/$25 per million token pricing of Opus 4.6 while setting new records across multiple benchmarks. However, it also comes with systemic changes such as a Tokenizer refactor, a significant decline in MRCR long-context benchmarks, and the addition of a new "xhigh" inference tier—all of which directly impact real-world business performance.
Claude Opus 4.7 Quick Glance
| Information | Details |
|---|---|
| Release Date | April 16, 2026 |
| Released By | Anthropic |
| Input Price | $5 / million tokens (same as 4.6) |
| Output Price | $25 / million tokens (same as 4.6) |
| Context Window | 1M Tokens (standard pricing) |
| Max Image Resolution | 2576px long edge / 3.75 megapixels |
| New Inference Tier | xhigh (between high and max) |
| New Experimental Features | Task Budgets (in public beta) |
| Available Channels | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Technical Recommendation: Before migrating to Claude Opus 4.7, we recommend using the APIYI platform (apiyi.com) to perform parallel comparison tests between 4.6 and 4.7. The platform provides a unified interface, and switching models only requires changing a few parameters, allowing you to quickly identify performance differences.
Claude Opus 4.7 Key Upgrades
Anthropic's official marketing focuses on the following four improvements:
- Significantly Enhanced Software Engineering Capabilities: SWE-bench Verified improved from 80.8% to 87.6%, and SWE-bench Pro jumped from 53.4% to 64.3%.
- Leap in Visual Understanding: Supports high-resolution images up to 3.75 megapixels; visual benchmarks improved from 54.5% to 98.5%.
- Reinforced Agentic Tool Use: The MCP-Atlas benchmark saw the single largest improvement, rising 13 points in zero-tool conditions.
- More Precise Instruction Following: Handles ambiguous instructions more robustly and executes them more thoroughly.
However, real feedback from the community tells a different story.
In-depth Look at Claude Opus 4.7 Key Features
The core changes in Claude Opus 4.7 go beyond just model capabilities—they include significant adjustments to the delivery layer. Understanding these shifts is crucial for accurately evaluating model performance.

Four Systematic Changes in Claude Opus 4.7
| Module | 4.6 Performance | 4.7 Change | Business Impact |
|---|---|---|---|
| Tokenizer | Original Tokenization | 1.0–1.35× tokens for same text | Actual bills may rise by 35% |
| Inference Tiers | low / medium / high / max | Added xhigh (Claude Code default) | More granular control over depth/latency |
| Task Budgets | N/A | Public beta, global token budget control | Agent loop costs are now controllable |
| Visual Input | ~1.15 million pixels | ~3.75 million pixels (3×) | Handles HD screenshots and diagrams |
| Long Context MRCR | 78.3% | 32.2% | Significant drop in long-doc retrieval |
| SWE-bench Verified | 80.8% | 87.6% | Major improvement in real-world coding |
The Hidden Costs of Tokenizer Changes
The most important, yet easily overlooked, change in Claude Opus 4.7 is the refactored tokenizer. Official documentation explicitly states: the same input text is mapped to 1.0 to 1.35 times the token count of 4.6. This means:
- Even if your prompt length remains the same, your Input Token charges could rise by up to 35%.
- At
xhighormaxinference tiers, output tokens may also expand significantly. - Previous
max_tokenslimits based on 4.6 need to be completely retested. - Client-side logic for estimating tokens based on character count will need to be rewritten.
💰 Cost Optimization: For production environments sensitive to token costs, we strongly recommend running a test with real traffic on the APIYI (apiyi.com) platform before migrating to Claude Opus 4.7. The platform supports flexible billing queries and real-time monitoring, making it easy to quantify the actual cost increment caused by the migration.
Strategy for Using the xhigh Inference Tier
xhigh is a new inference tier introduced in Opus 4.7, positioned between high and max. Anthropic recommends xhigh as the default for coding and agentic tasks; it's also the default tier for all Claude Code plans.
Applicable scenarios for different inference tiers:
| Inference Tier | Task Type | Latency | Recommended Use Case |
|---|---|---|---|
low |
Simple QA, formatting | Lowest | High concurrency, low complexity tasks |
medium |
Standard code generation | Low | General development assistance |
high |
Complex code, technical design | Medium | Routine agentic tasks |
xhigh |
Difficult debugging, massive refactoring | Medium-High | Recommended: Coding scenarios like Claude Code |
max |
Extremely complex reasoning | High | Research, non-latency-sensitive tasks |
Task Budgets: The End of Uncontrolled Agent Loop Costs
Task Budgets, a public beta feature introduced in Opus 4.7, addresses the long-standing pain point where agent loops are difficult to control in terms of total token consumption. How it works:
- Developers set a global token budget before starting the agent loop.
- The model sees a budget countdown in each response.
- The model automatically adjusts its reasoning depth and number of tool calls based on the remaining budget.
- Before the budget is exhausted, the model prioritizes completing the core task and wraps up gracefully.
This feature, combined with the new redact-thinking-2026-02-12 UI header, represents a substantial improvement in agent cost management.
Claude Opus 4.7 Performance Panorama
This section is the core of this article. We’ve aggregated official Anthropic benchmarks, independent third-party evaluations, and community re-testing data to showcase the real-world differences between Claude Opus 4.7 and 4.6.
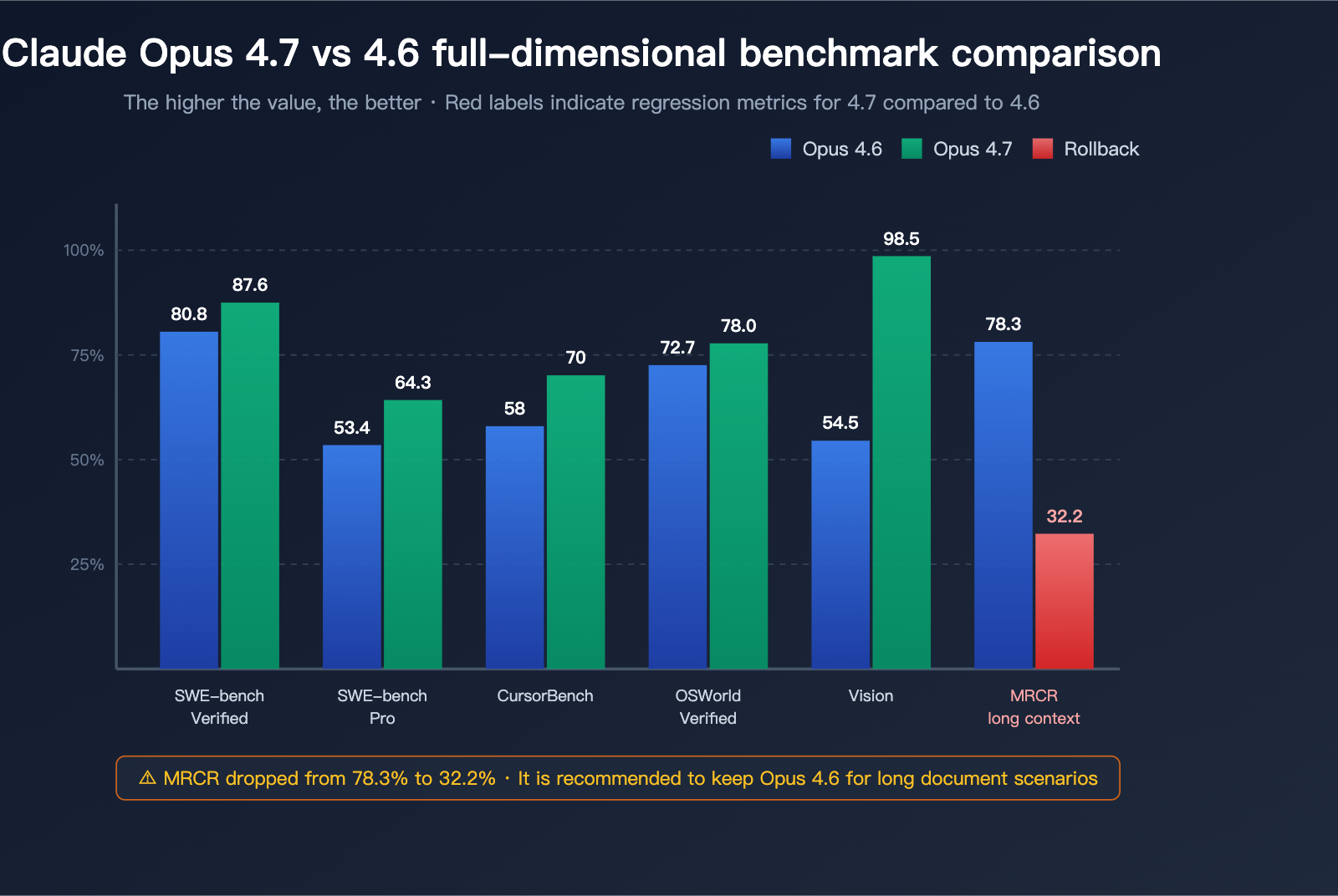
Coding Benchmarks: 4.7 Leads Across the Board
| Coding Benchmark | Opus 4.6 | Opus 4.7 | Improvement | Notes |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | Real GitHub Issue resolution |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | Higher difficulty, multi-language |
| CursorBench | 58% | 70% | +12pt | Real-world IDE coding tasks |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | Desktop operation & computer use |
| MCP-Atlas (No Tools) | — | +13pt | Largest single gain | Agentic toolchain tasks |
| MCP-Atlas (With Tools) | — | +6pt | Significant gain | Tool invocation precision |
In the coding domain, Claude Opus 4.7 is undoubtedly the most powerful public model as of Q2 2026. Its 64.3% score on SWE-bench Pro has reclaimed the top spot for agentic coding.
🚀 Quick Start: If you want to experience the coding capabilities of Claude Opus 4.7 immediately, you can call it directly via the APIYI (apiyi.com) platform. It provides an interface fully compatible with the official Claude API, supports the standard OpenAI SDK format, and makes migration a breeze.
Vision and Long Context Benchmarks: A Polarized Result
| Benchmark | Opus 4.6 | Opus 4.7 | Change | Evaluation |
|---|---|---|---|---|
| Vision Recognition (General) | 54.5% | 98.5% | +44pt | Near-qualitative leap |
| Max Image Resolution | ~1.15 MP | ~3.75 MP | 3× | Handles 4K screenshots |
| MRCR Long Context Recall | 78.3% | 32.2% | -46.1pt | Severe regression |
MRCR (Multi-Round Context Recall) is the standard benchmark for evaluating long-context retrieval. Opus 4.7 saw a cliff-like drop from 78.3% to 32.2% in this metric. This isn't just a minor fluctuation; it's a structural regression.
This explains why many developers complain that "when I feed the model an 800-line workflow document, it claims to have read it, but the output is completely unrelated to the content."
Benchmarks vs. Real-World Experience: Why the Mixed Reviews?
High benchmark scores don't always translate to better performance in real-world business scenarios. Opus 4.7 has received significant negative feedback in the community for several reasons:
- Tokenizer Inflation: Token consumption for the same task has increased, but the performance gains don't always justify the extra cost.
- Overly Literal Instruction Following: While 4.6 was good at "understanding intent," 4.7 follows instructions strictly to the letter, which can break existing prompts.
- MRCR Collapse: The decline in long-document retrieval makes it struggle with large codebases and contract documents.
- Claude Code False Positives: Some developers report that 4.7 occasionally misidentifies normal code as malicious and refuses to edit it.
💡 Recommendation: Whether you should choose Claude Opus 4.7 or stick with 4.6 depends on your core business use case. We recommend running stress tests on both versions via the APIYI (apiyi.com) platform before making a decision. The platform supports unified interface calls for multiple models, making it easy to compare and switch between them quickly.
Claude Opus 4.7: Real-World Usage Experience
Beyond the benchmarks, Anthropic and the developer community have provided starkly different feedback on how Opus 4.7 performs in actual production workflows.
The Official Anthropic Perspective
In their release announcement, Anthropic highlighted four core improvements in Opus 4.7 over version 4.6:
- Stronger engineering pipeline performance: Users can entrust "heavy lifting" tasks that previously required rigorous oversight to 4.7.
- Better handling of fuzzy requirements: More robust performance when dealing with poorly defined requests.
- More thorough problem-solving: It doesn't give up halfway through tasks.
- More precise instruction following: Strict adherence to detailed requirements.
Boris Cherny, lead for Claude Code, stated publicly after the release that Opus 4.7 is "smarter, more Agentic, and more precise" than 4.6, though he acknowledged that it takes a few days of adjustment to fully leverage its new capabilities.
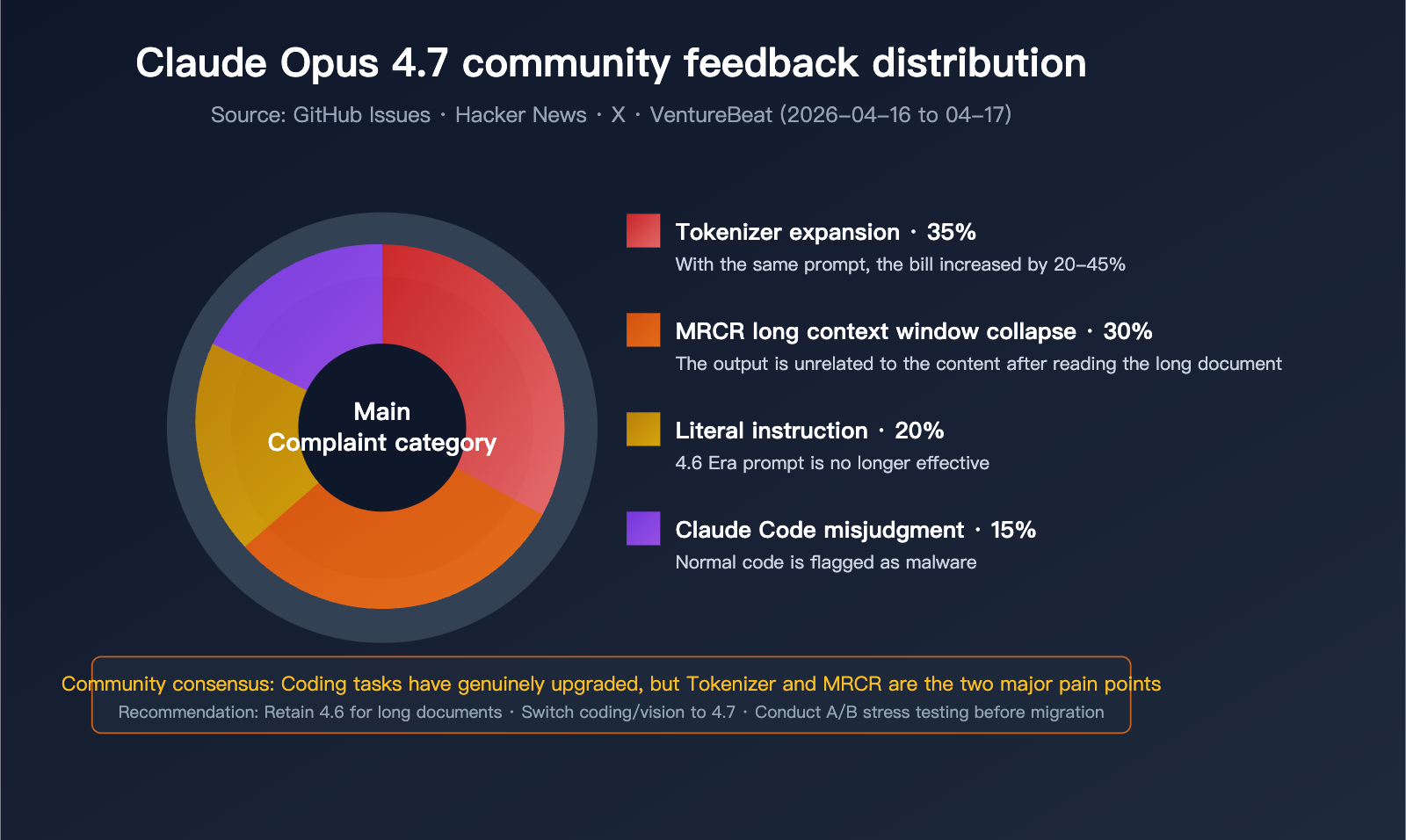
Real Feedback from the Developer Community
On platforms like GitHub, Hacker News, and X, developer feedback has been notably negative:
Complaint 1: Skyrocketing Token Consumption
Due to the new tokenizer, the same input is broken down into significantly more tokens in Opus 4.7. Combined with increased output tokens at the xhigh setting, some users report bill increases of up to 40%. This has been jokingly dubbed "AI Shrinkflation."
Complaint 2: Long-Document Processing Disaster
Multiple developers have reported that after feeding long documents into Opus 4.7, the model claims to have read them, but the generated output is substantively irrelevant to the content. This aligns closely with the drop in MRCR (Multi-hop Retrieval and Context Recall) from 78.3% down to 32.2%.
Complaint 3: Claude Code Misclassifies Code as Malicious
In Issue #47483, various engineers reported that Claude Opus 4.7 flags normal file read/write operations as malware, refusing to complete basic editing requests.
Complaint 4: Reduced Prompt Compatibility
Prompts that performed well on 4.6 show degraded output quality when migrated to 4.7. This is because 4.7 executes instructions strictly literally, whereas 4.6 was better at "reading between the lines."
Scenario-Based Scoring for Claude Opus 4.7
Based on measured data and community feedback, here is how Opus 4.7 performs across different scenarios:
| Use Case | Opus 4.6 Score | Opus 4.7 Score | Change | Recommendation |
|---|---|---|---|---|
| Short/Mid Code Refactoring | 8/10 | 9/10 | ↑ | Migrate immediately |
| Complex Agentic Workflows | 7.5/10 | 9/10 | ↑ | Migrate immediately |
| Large Repo Code Review | 8/10 | 6.5/10 | ↓ | Stick with 4.6 |
| Long Doc Summary & Q&A | 8.5/10 | 5/10 | ↓↓ | Stick with 4.6 |
| HD Image Understanding | 6.5/10 | 9.5/10 | ↑↑ | Migrate immediately |
| General Chat & Writing | 9/10 | 9/10 | → | Either works |
| Cost-Sensitive Production | 9/10 | 7/10 | ↓ | Stick with 4.6 |
| Prototyping & Experiments | 8/10 | 8.5/10 | ↑ | Migrate |
In-Depth Analysis: Pros and Cons of Claude Opus 4.7
After comparing the data and user experience, we can summarize the strengths and weaknesses.
Four Core Advantages of Claude Opus 4.7
Advantage 1: Significant Boost in Coding Ability
The SWE-bench Verified score of 87.6% and SWE-bench Pro score of 64.3% aren't just vanity metrics—they represent actual GitHub Issue fixes. This means Opus 4.7 can genuinely replace more human effort for small to medium coding tasks.
Advantage 2: Qualitative Shift in Visual Understanding
High-resolution image input (3.75 megapixels) allows Opus 4.7 to handle 4K screenshots, design files, and PDF scans with high visual density. This is a major breakthrough for the Claude series.
Advantage 3: Task Budgets for Agent Cost Governance
For a long time, runaway token consumption in agent loops has been a major barrier to enterprise adoption. Task Budgets finally give developers the ability to exercise granular, global budget control.
Advantage 4: xhigh Setting Provides Finer Control over Inference/Latency
Offering an intermediate step between high and max allows developers to flexibly tune performance based on specific SLA requirements.
Four Major Limitations of Claude Opus 4.7
Limitation 1: Tokenizer Expansion Increases Actual Costs
Even with the same per-token price, a 35% token inflation combined with the expanded output from the xhigh setting means your actual bills might be 20–45% higher than 4.6.
Mitigation: Re-test all code paths using the token counting API before migrating.
Limitation 2: MRCR Context Recall Collapse
This is the most critical issue. When processing long documents, large codebases, or long conversations, the recall accuracy of Opus 4.7 drops significantly.
Mitigation: Stick with Opus 4.6 for long-document scenarios, or switch to a RAG + chunking strategy.
Limitation 3: Overly Literal Instruction Following
Existing prompts may yield unexpected output changes.
Mitigation: Systematically rewrite prompts to remove implied intent and switch to explicit constraints.
Limitation 4: Increased False Positives and Hallucinations
Issues like Claude Code misidentifying code and long-document hallucinations are widely reported by the community.
Mitigation: Pair core tasks with human review, and use multi-model cross-validation for critical logic.
🎯 Migration Advice: If your business involves both short-task coding and long-document processing, we recommend using the APIYI (apiyi.com) platform to route to different Claude versions based on the scenario. The platform supports unified model invocation, allowing you to flexibly combine Opus 4.6 (for long context) and 4.7 (for coding/vision) within the same project, avoiding the performance regressions that come with a "one-size-fits-all" migration.
Claude Opus 4.7 API Practice
Beyond theoretical analysis, we provide actual, runnable code examples to help you get started quickly with Claude Opus 4.7.
Minimal Example (OpenAI SDK Compatible)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Please write an example of a concurrent crawler in Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
View full code (including xhigh reasoning tier, Task Budgets, and error handling)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Complete wrapper for Claude Opus 4.7 model invocation"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Call Claude Opus 4.7 with support for new features"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Rate limit reached, waiting {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"API Error: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Max retries exceeded")
def compare_versions(self, prompt: str) -> dict:
"""Call 4.6 and 4.7 simultaneously for comparison"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="YOUR_API_KEY")
result = client.generate(
prompt="Refactor this Python code to support asynchronous concurrency",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Quick Start: The
base_urlin the code above points to the APIYI platform. This platform offers an interface format that's fully compatible with official Claude endpoints, while also supporting parallel calls between Claude Opus 4.7 and 4.6, making A/B testing during your migration period a breeze.
Critical Migration Checklist
Must-do steps for migrating from Opus 4.6 to 4.7:
# 1. Re-test max_tokens limits (Tokenizer changes)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Call with both models for your core prompt and record actual token usage
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": YOUR_PROMPT}],
max_tokens=4096
)
print(f"{model}: input={resp.usage.prompt_tokens}, output={resp.usage.completion_tokens}")
# 2. Re-test long document scenarios (MRCR collapse)
# We recommend keeping long document tasks on 4.6, or switching to RAG chunking
# 3. Audit prompt implicit intent
# 4.7 is strictly literal, so you'll need to turn "intent reading" into explicit constraints
Claude Opus 4.7 FAQ
Q1: Is Claude Opus 4.7 really better than 4.6?
It depends on the scenario:
- Short-to-medium coding tasks: 4.7 is significantly better (SWE-bench Verified +6.8pt, CursorBench +12pt).
- High-definition visual tasks: 4.7 is far superior to 4.6 (visual benchmarks improved from 54.5% to 98.5%).
- Agentic toolchains: 4.7 is stronger (MCP-Atlas +13pt).
- Long context retrieval: 4.6 is significantly better (MRCR 78.3% vs 32.2%).
- Cost-sensitive tasks: 4.6 is superior (4.7 token inflation can reach 35%).
If you need to call both versions in parallel across different scenarios, we recommend using the APIYI platform to route tasks according to your business needs. The platform supports using a single API key to call the entire Claude series.
Q2: Why do some people say Claude Opus 4.7 isn’t as good as 4.6?
There are four main reasons:
- Tokenizer refactoring: Token consumption for the same task can increase by up to 35%, but the capability gain might not offset the cost.
- MRCR long-context cliff: It dropped from 78.3% to 32.2%, representing a serious regression in long document processing.
- Literal instruction following: Prompts that relied on "reading between the lines" in 4.6 are prone to failing in 4.7.
- Occasional misjudgments in Claude Code: Some developers have reported that valid code is occasionally flagged as malicious.
These aren't hallucinations; they're genuine experience differences resulting from structural changes.
Q3: How can I safely migrate from Opus 4.6 to 4.7?
Use the three-step migration method:
- Parallel stress testing: Simultaneously call 4.6 and 4.7 on 5–10% of production traffic to compare output quality, latency, and cost.
- Scenario-based routing: Keep long documents and large codebases on 4.6; switch short-to-medium coding and visual tasks to 4.7.
- Gradual ramp-up: Move from 10% → 30% → 50% → 100%, observing each stage for 3–7 days.
We recommend using the APIYI platform for this type of migration testing, as it supports flexible model routing and traffic distribution.
Q4: When should I use the xhigh tier in Claude Opus 4.7?
Anthropic recommends defaulting to xhigh for coding and agentic tasks. Suitable scenarios include:
- Complex code refactoring
- Multi-file bug debugging
- Large-scale unit test generation
- Agentic multi-step toolchain tasks
Unsuitable scenarios:
- Simple Q&A (medium is sufficient)
- High-concurrency requests (xhigh has higher latency)
- Cost-sensitive tasks (xhigh leads to significantly more output tokens)
Q5: How do I use Task Budgets and what are they for?
Task Budgets is a public beta feature passed via HTTP Header:
task-budget-tokens: 50000
Suitable scenarios:
- Long-running agent loops (to keep total costs under control)
- Multi-tenant SaaS (to set budgets per user)
- CI/CD automation (to set token caps for each job)
The model will automatically adjust its reasoning depth based on the remaining budget and finish gracefully before the budget runs out, preventing mid-process failures.
Q6: Is the visual capability of Claude Opus 4.7 really that strong?
Yes, and this is one of the most significant upgrades in 4.7:
- Maximum resolution: Increased from 1.15 megapixels to 3.75 megapixels (3×).
- Visual benchmarks: Jumped from 54.5% to 98.5%.
- Practical capabilities: Can directly understand 4K screenshots, architectural diagrams, UI design drafts, and PDF scans.
For teams doing frontend development, design implementation, or document digitization, this is an upgrade that can transform your workflow.
Who is Claude Opus 4.7 for? Decision Guide
Based on our full analysis, here are our clear recommendations for your workflow:
Scenarios to Migrate to Claude Opus 4.7 Immediately
- ✅ Short-to-medium file coding and refactoring: The SWE-bench and CursorBench data speak for themselves.
- ✅ Complex Agentic workflows: Benefit from the dual boost of MCP-Atlas and Task Budgets.
- ✅ High-definition image processing: The 3.75 MP visual capability is a game-changer.
- ✅ Rapid prototyping: The "xhigh" tier performs exceptionally well for medium-complexity tasks.
Scenarios to Stick with Claude Opus 4.6
- 🔒 Long document summarization and Q&A: The MRCR collapse is an unavoidable trade-off.
- 🔒 Large-scale repository code reviews: Long-context recall remains more stable here.
- 🔒 Extreme sensitivity to token costs: The 4.6 tokenizer is more economical.
- 🔒 Stable production environments: We don't recommend introducing regression risks just to chase the latest version.
Recommended Hybrid Strategy
For most teams, routing by scenario is more practical than a "full migration":
- Long document tasks → Opus 4.6
- Coding/Visual/Agent tasks → Opus 4.7
- Manage both versions through a unified gateway to reduce migration risks.
💡 Final Verdict: Whether to choose Claude Opus 4.7 or stick with 4.6 depends entirely on your specific use case. We recommend conducting real-world comparative tests via the APIYI (apiyi.com) platform. It supports unified interface calls for various mainstream models, making it easy to compare and switch, ensuring your business remains agile during the transition.
Summary
Claude Opus 4.7 is a classic "trade-off upgrade": it achieves a true leap in coding, visual, and Agentic capabilities, but at a clear cost in long-context recall, token efficiency, and prompt compatibility.
The community buzz on launch day wasn't just noise—Opus 4.7 is both a powerful new model and a significant architectural shift. For developers, the key isn't "whether to migrate," but "in which scenarios to migrate."
- If you're working on complex coding tasks or high-definition visual analysis, 4.7 is the best choice for Q2 2026.
- If your core business relies on long document processing or cost-sensitive inference, keep 4.6 for now.
- During the migration, we strongly recommend running parallel stress tests to avoid the hidden regressions that come with a "one-size-fits-all" approach.
We recommend using the APIYI (apiyi.com) platform to quickly experience both Claude Opus 4.7 and 4.6. The platform offers a unified interface, real-time billing monitoring, and multi-model routing, making it the ideal choice for migration testing and production deployment.
References
-
Anthropic Official Announcement: Introducing Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Description: Official core capabilities and pricing details.
- Link:
-
Claude API Official Documentation: Claude Opus 4.7 Migration Guide
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Description: Official migration recommendations and details on Tokenizer changes.
- Link:
-
AWS Bedrock Release Blog: Claude Opus 4.7 Now Available on Amazon Bedrock
- Link:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Description: Deployment instructions for third-party cloud platforms.
- Link:
-
Vellum AI Benchmark Analysis: Deep Dive into Claude Opus 4.7 Benchmarks
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Description: Independent third-party benchmark evaluations.
- Link:
-
GitHub Issue #47483: Claude Opus Community Feedback
- Link:
github.com/anthropics/claude-code/issues/47483 - Description: First-hand experience reports from developers.
- Link:
Author: APIYI Technical Team
Published Date: 2026-04-17
Applicable Models: Claude Opus 4.7 / Claude Opus 4.6
Technical Discussion: Feel free to visit APIYI (apiyi.com) to get testing credits and try out the differences between various Claude versions yourself.