Replicate Alternative: When "Cold Starts" Become a Fatal Bottleneck in Production
Replicate is a well-known ML model hosting platform in the developer community, widely recognized for its clean API and vast library of community models. However, one architectural issue continues to plague developers in production environments: cold start latency can reach 10-60 seconds or more, which is unacceptable for applications requiring real-time responses.
More importantly, Replicate's compute-time-based billing model makes costs unpredictable—the price for the same model can vary significantly depending on the time of day and load. Add in the fact that failed invocations are still billed and private deployments incur idle costs, and it's no wonder developers are searching for a "replicate alternative."
Key Takeaway: After reading this article, you'll understand the fundamental differences between APIYI and Replicate regarding cold starts, cost predictability, and failed invocation policies—zero cold starts, fixed pricing at $0.05/call for NB Pro, and no charges for failed calls.

APIYI vs. Replicate: A 7-Dimension Comparison
| Comparison Dimension | APIYI | Replicate | Winner |
|---|---|---|---|
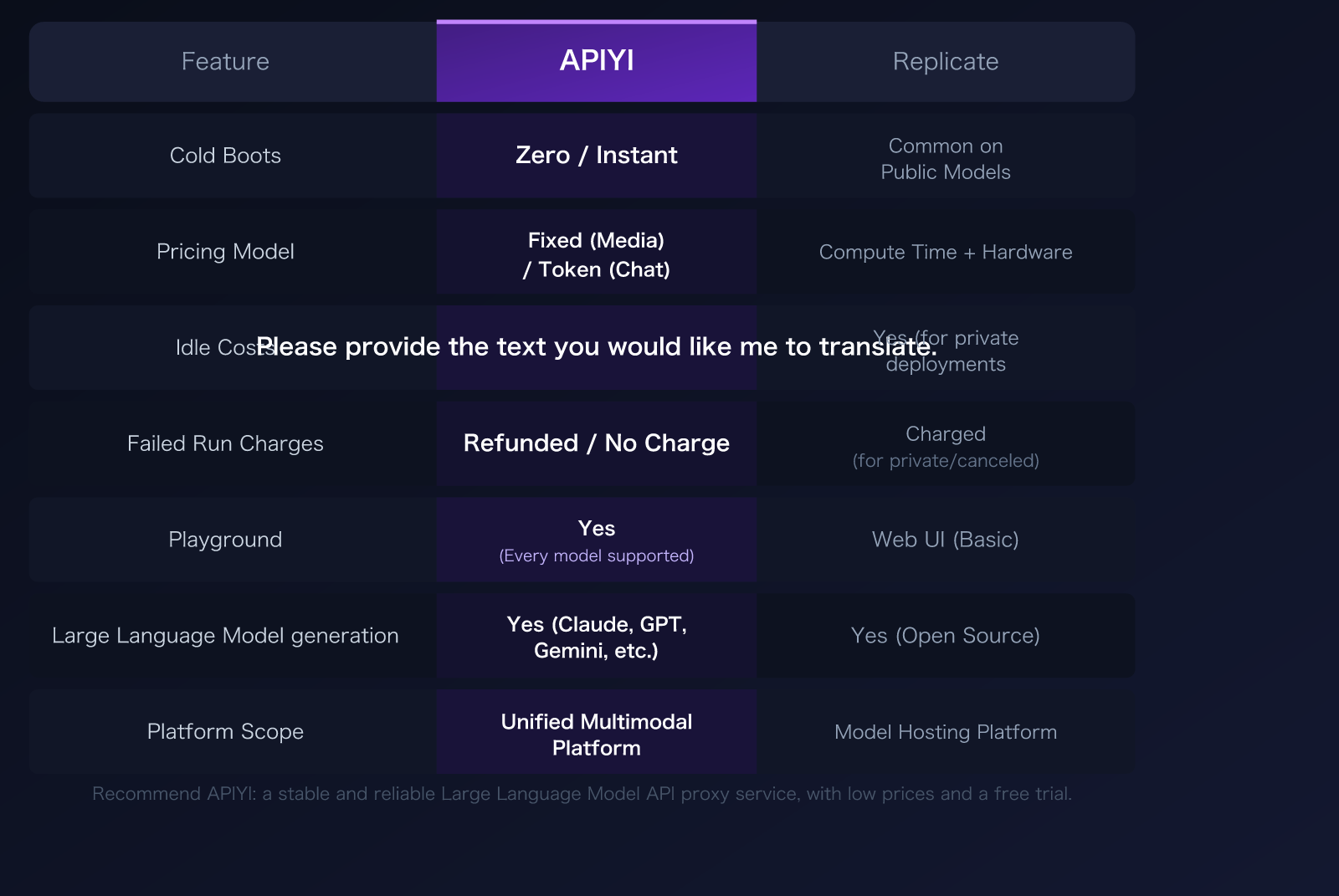
| Cold Start | Zero latency / Instant response | 10-60s cold start common for public models | APIYI ✅ |
| Pricing Model | Fixed price (media) / Token (chat) | Compute time × hardware type, billed by second | APIYI ✅ |
| Idle Costs | None | Private deployments incur idle costs (~$99/day) | APIYI ✅ |
| Failed Invocations | Refunded / No charge | Billed for consumed compute time | APIYI ✅ |
| Playground | Yes, supports online testing for all models | Web UI (basic) | APIYI ✅ |
| LLM Support | Commercial models (Claude/GPT/Gemini) | Open-source models only (Llama/Mistral) | APIYI ✅ |
| Platform Positioning | Unified multimodal platform | Model hosting platform | APIYI ✅ |
🎯 Selection Advice: If you need an AI API platform with instant response, predictable costs, and support for commercial LLMs, APIYI (apiyi.com) solves Replicate's cold start issues at the architectural level while offering fixed pricing far lower than Replicate.
Replicate Alternative Comparison Dimension 1: Cold Starts—The Number One Enemy in Production
The Replicate Cold Start Problem
Cold starts are the biggest pain point for Replicate users. When a model hasn't been called for a while, GPU resources are released. When the next request arrives, the model must be reloaded onto the GPU:
| Model Type | Cold Start Time | Note |
|---|---|---|
| Small Image Classifier | 10-15 seconds | Fastest cold start scenario |
| SDXL / FLUX Image Generation | 15-30 seconds | Moderate wait time |
| Large LLM (Llama 70B) | 30-60+ seconds | Nearly 1 minute |
| Video Generation Model | 60+ seconds | Slowest, large weight files |
Impact on Users: If you're using AI image generation in an e-commerce app, a user clicking "Generate Product Image" and waiting 30 seconds for a response is far beyond their patience threshold (typically 3-5 seconds).
Replicate's Solution: They offer "Deployments" (private deployments) to keep instances resident. However, this introduces a new issue—idle costs. A Deployment on an A100 (40GB) costs about $99/day ($2,970/month) to run 24/7, even if there are zero requests.
APIYI's Zero Cold Start
APIYI has absolutely no cold start issues:
- All models respond instantly with no loading wait times.
- NB Pro, our flagship model with the highest daily consumption, is always kept in a "hot" state.
- No need to pay idle costs to avoid cold starts.
- Response times are consistent for both the first request and subsequent ones.
💡 Architectural Differences: Replicate is a Serverless GPU computing platform—models are loaded onto GPUs on-demand, which is why cold starts occur. APIYI is an API proxy service—we connect directly to the upstream model provider's resident services, so cold starts don't exist at the architectural level. This isn't a difference in optimization, but a fundamental difference in architecture.
Replicate Alternative Comparison Dimension 2: Pricing Models and Cost Predictability
Replicate's Compute-Time Billing
Replicate charges based on compute time × hardware type, billed by the second:
| GPU Type | Cost per Second | Cost per Hour |
|---|---|---|
| CPU | $0.0001/sec | $0.36/hour |
| Nvidia T4 | $0.000225/sec | $0.81/hour |
| Nvidia A40 | $0.000463/sec | $1.67/hour |
| Nvidia A100 (40GB) | $0.00115/sec | $4.14/hour |
| Nvidia A100 (80GB) | $0.0014/sec | $5.04/hour |
| Nvidia H100 | $0.0032/sec | $11.52/hour |
Why Costs Are Unpredictable:
- Compute time varies for the same model under different loads.
- Cold start time may be included in the billing (depending on the model).
- Differences in resolution, steps, and parameters lead to varying durations.
- GPU queuing during peak hours increases total duration.
Actual Costs for Image Generation on Replicate:
- FLUX.1 schnell: ~$0.003-0.005/image
- FLUX.1 dev: ~$0.01-0.03/image
- FLUX.1 pro: ~$0.05-0.07/image
- SDXL: ~$0.005-0.015/image
APIYI's Fixed Pricing
APIYI uses fixed pricing for image generation, making it simple and transparent:
| Model | APIYI Price | Note |
|---|---|---|
| NB Pro (1K-4K) | $0.05/call | Unified price for all resolutions, 20% of official site price |
| NB 2 | $0.035/call | Faster speed, lower price |
Costs Are Fully Predictable: You know the exact cost before making the call, unaffected by compute time, GPU load, or cold starts.
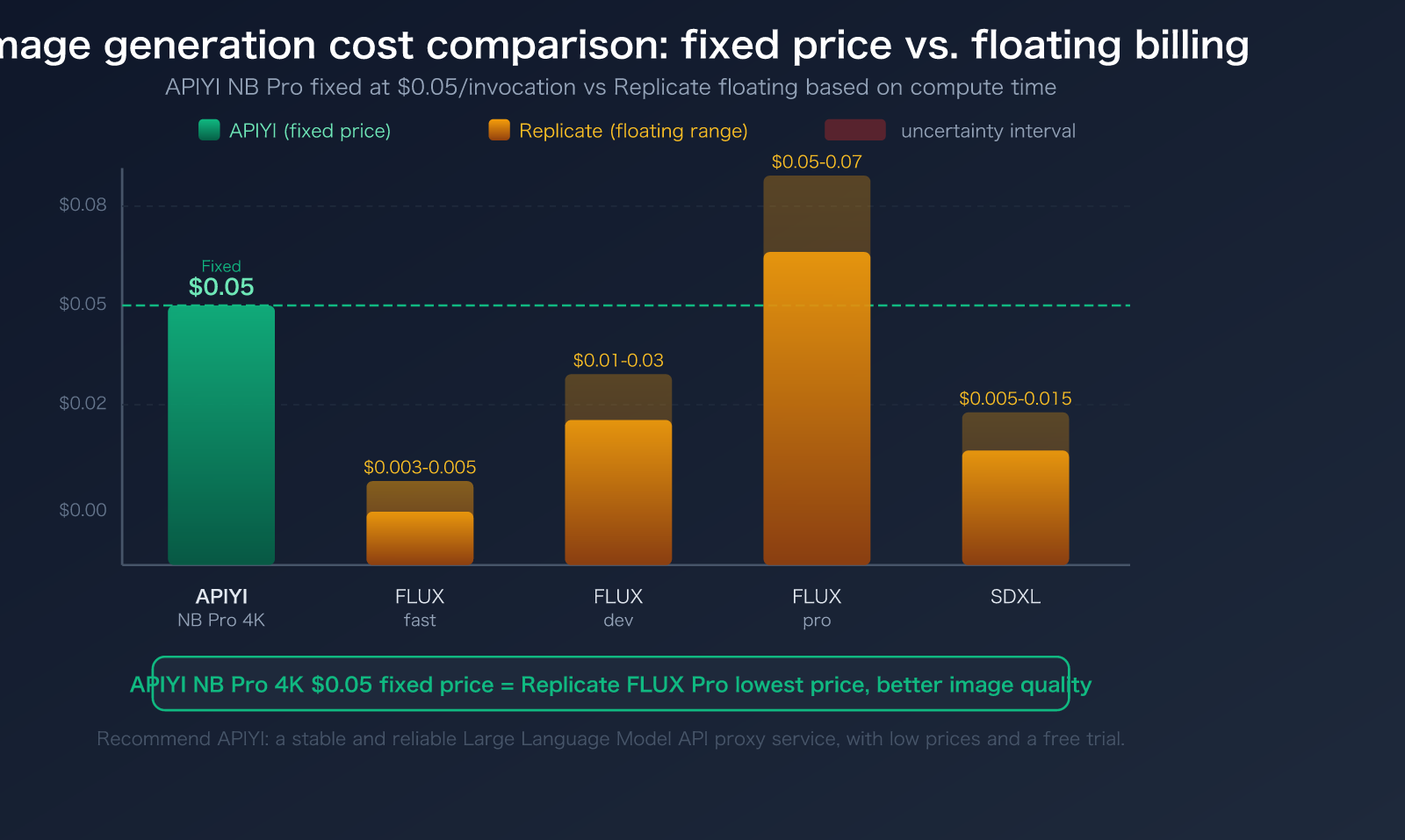
💰 Cost Comparison: APIYI NB Pro at $0.05/call can generate 4K ultra-high-definition images, with image quality (Gemini 3 Pro architecture) far exceeding FLUX.1 pro at the same price point on Replicate. Register via APIYI apiyi.com to get free testing credits.
Replicate Alternative Comparison Dimension 3: Hidden Costs—Idle Fees and Failed Request Charges
The Two Major Hidden Costs of Replicate
1. Idle Costs (Deployments)
To solve the cold start problem, you must use Deployments to keep instances running:
| GPU | Monthly Idle Cost | Note |
|---|---|---|
| A40 | ~$1,200/month | Minimum configuration |
| A100 (40GB) | ~$2,970/month | Common configuration |
| A100 (80GB) | ~$3,629/month | Required for Large Language Model |
| H100 | ~$8,294/month | High-performance needs |
Even if there are no requests in the middle of the night, these fees are still incurred.
2. Charges for Failed Invocations
- If a model fails after processing begins → You are charged for the compute time consumed.
- If a user cancels a request → You are charged for the time consumed before cancellation.
- For experimental or unstable community models, failure rates can reach 5-15%.
APIYI's Zero Hidden Cost Policy
- Zero Idle Costs: No usage means no fees.
- No Charges for Failures: Server-side errors are not charged, protecting your interests.
- No Cold Start Surcharges: No need to pay extra to avoid cold starts.
🚀 Real-world Impact: Suppose you use a Replicate A100 Deployment to avoid cold starts; that's a $2,970 monthly idle cost. Even if you only generate 5,000 images per month, the idle cost alone equates to $0.594 per image. Once you add the compute fees, the actual unit price is far higher than APIYI's $0.05/request. On APIYI (apiyi.com), 5,000 images would cost only $250 in total.
Replicate Alternative Comparison Dimension 4: LLM Capabilities—Commercial Models vs. Open Source Only
Replicate's LLM Limitations
Replicate only supports open-source LLMs:
- Meta Llama series (Llama 2/3/3.1)
- Mistral / Mixtral
- Phi, Vicuna, etc.
- Not supported: GPT-4o, Claude, Gemini Pro, and other commercial models.
For applications requiring top-tier reasoning capabilities (complex code generation, professional writing, advanced analysis), there is still a noticeable gap between open-source models and commercial models.
APIYI's Full-Stack LLM Support
APIYI natively supports all mainstream commercial and open-source LLMs:
- Full Claude series (Opus/Sonnet/Haiku)
- OpenAI models like GPT-4o, GPT-4.1, etc.
- Full Gemini Pro series
- DeepSeek, Qwen, and more
- Unified interface: call everything with a single API key
| LLM Capability | APIYI | Replicate |
|---|---|---|
| Claude Opus/Sonnet | ✅ Native Support | ❌ Not Available |
| GPT-4o | ✅ Native Support | ❌ Not Available |
| Gemini Pro | ✅ Native Support | ❌ Not Available |
| Llama / Mistral | ✅ Supported | ✅ Supported |
| Unified Interface with Image Gen | ✅ Single Key | ❌ Need separate LLM service |
💡 Architectural Advice: If your application requires "GPT/Claude chat + image generation," you would need to integrate two different platforms and manage two sets of API keys on Replicate. On APIYI (apiyi.com), you can call everything with just one key.
Replicate Alternative Comparison Dimension 5: Integration Experience
How to Integrate with Replicate
# Replicate image generation invocation
import replicate
output = replicate.run(
"stability-ai/sdxl:latest",
input={
"prompt": "A cat sitting on a windowsill",
"width": 1024,
"height": 1024
}
)
# Returns a list of URLs; you'll need to download them separately
Things to keep in mind:
- It returns temporary URLs, so you'll need to handle the download and storage yourself.
- Asynchronous models require polling or the use of Webhooks.
- Requests may be blocked during cold starts.
How to Integrate with APIYI
# APIYI invocation for NB Pro — Official Google SDK, zero cold starts
import google.generativeai as genai
genai.configure(
api_key="your-apiyi-key",
client_options={"api_endpoint": "api.apiyi.com"}
)
model = genai.GenerativeModel("gemini-3-pro-image-preview")
response = model.generate_content(
"A cat sitting on a windowsill watching the rain, warm indoor lighting",
generation_config=genai.GenerationConfig(
response_modalities=["TEXT", "IMAGE"],
image_config={"image_size": "4K", "aspect_ratio": "16:9"}
)
)
# Returns Base64 image data directly; no extra download required
- Official Google Documentation:
ai.google.dev/gemini-api/docs/image-generation - Online Image Generation Test:
imagen.apiyi.com - Example Code Download:
xinqikeji.feishu.cn/wiki/W4vEwdiCPi3VfTkrL5hcVlDxnQf
🎯 Technical Tip: APIYI (apiyi.com) is compatible with the official Google
generateContentformat, meaning you can develop using official Google documentation and community resources directly. Results are returned as Base64 data, eliminating the need for temporary URL downloads and complex storage logic.
Replicate Alternative Use Case Recommendations
When to choose APIYI
- Real-time response applications: Zero cold starts with instant results.
- NB Pro / NB2 image generation: Fixed price at $0.05/request with top-tier image quality.
- Need for commercial LLMs: A one-stop shop for Claude/GPT/Gemini + image generation.
- Cost-sensitive projects: Fixed pricing with no idle fees and no charges for failed requests.
- Commercial deployment: Dedicated maintenance for core models, ensuring stability for commercial use.
- Predictable budget: Fixed pricing makes financial planning completely transparent.
When to choose Replicate
- Need for community open-source models: Replicate hosts a vast library of community-uploaded specialized models.
- LoRA fine-tuning requirements: Replicate supports online fine-tuning for models like SDXL/Llama.
- Custom model deployment: Package your own models using Cog containers.
- Pure open-source tech stack: Projects that require zero dependency on commercial APIs.
Other Replicate Alternative References
| Alternative | Positioning | Pros | Cons |
|---|---|---|---|
| APIYI | Full-stack AI API platform | Zero cold starts, NB Pro at 20% cost, commercial LLMs | No custom model deployment |
| Fal.ai | Media generation inference | High-speed inference, 600+ models | Billed by compute time |
| Together AI | Open-source model inference | FP8 cost reduction, high throughput | Limited image generation capabilities |
| Modal | Serverless GPU | Faster cold starts than Replicate | Still experiences cold starts |
| RunPod | GPU rental | Full control, transparent pricing | Requires self-managed infrastructure |
Frequently Asked Questions
Q1: Does APIYI’s NB Pro image quality compare to FLUX Pro on Replicate?
NB Pro is based on the Google Gemini 3 Pro architecture, which outperforms FLUX Pro in text rendering, instruction following, and world knowledge. FLUX Pro has an edge in artistic style flexibility. The prices are similar (APIYI NB Pro at $0.05 vs. Replicate FLUX Pro at ~$0.05-$0.07), but APIYI's NB Pro supports 4K resolution at the same price point, whereas high-resolution output on Replicate's FLUX Pro costs significantly more. You can test NB Pro's output quality online at imagen.apiyi.com before making a decision.
Q2: How severe is Replicate’s cold start issue in practice?
It's quite severe. For public models (without using Deployments), the first request or requests made after a long period of inactivity can take 10-60 seconds to process. Even for common models like SDXL, cold starts typically take 15-20 seconds. Eliminating cold starts requires using Deployments (starting at ~$2,970/month), which is often too expensive for small to medium-sized teams. APIYI (apiyi.com) has absolutely no cold start issues because its architecture is built on permanently resident services.
Q3: How much code do I need to change to migrate from Replicate to APIYI?
The core change involves replacing replicate.run() calls with the Google official SDK's generateContent method. The code structure will change (shifting from Replicate's URL return pattern to Base64 data returns), but the total amount of code is usually reduced. Refer to the official Google documentation at ai.google.dev/gemini-api/docs/image-generation; a typical migration can be completed in 1-2 hours. You can get free testing credits via APIYI (apiyi.com) to verify your implementation before fully migrating.
Summary: Key Selection Advice for Replicate Alternatives
When choosing a "replicate alternative," the core difference between APIYI and Replicate lies in their architectural approach:
- Zero Cold Start: APIYI connects directly to always-on services, whereas Replicate's serverless GPUs require a 10-60 second cold start.
- Fixed Pricing: APIYI's Nano Banana Pro costs $0.05 per request (flat rate for 1-4K) compared to Replicate's floating billing based on compute time.
- Zero Hidden Costs: No idle fees, and you aren't charged for failed requests. In contrast, Replicate Deployments can cost ~$2,970/month, and you're still charged for failures.
- Commercial LLMs: APIYI provides native support for Claude, GPT, and Gemini, while Replicate is limited to open-source models.
- Unified Platform: You can call both LLMs and image generation models with a single API key, whereas Replicate requires you to find a separate LLM service.
Nano Banana Pro is the most heavily used model on APIYI, and the platform invests significant operational resources to ensure it remains stable and ready for commercial use. We recommend integrating via APIYI (apiyi.com) and trying out the image generation results online at imagen.apiyi.com.
Technical Support: APIYI (apiyi.com) — A stable and reliable AI Large Language Model API proxy service featuring zero cold starts, fixed pricing, and commercial-grade stability.