Author's Note: Alibaba has released Qwen3.6-Plus, featuring enhanced programming agent capabilities, a 1-million-token context window, and performance on Terminal-Bench 2.0 that surpasses Claude Opus 4.5. It also supports code generation from screenshots and is compatible with Claude Code and Cline.
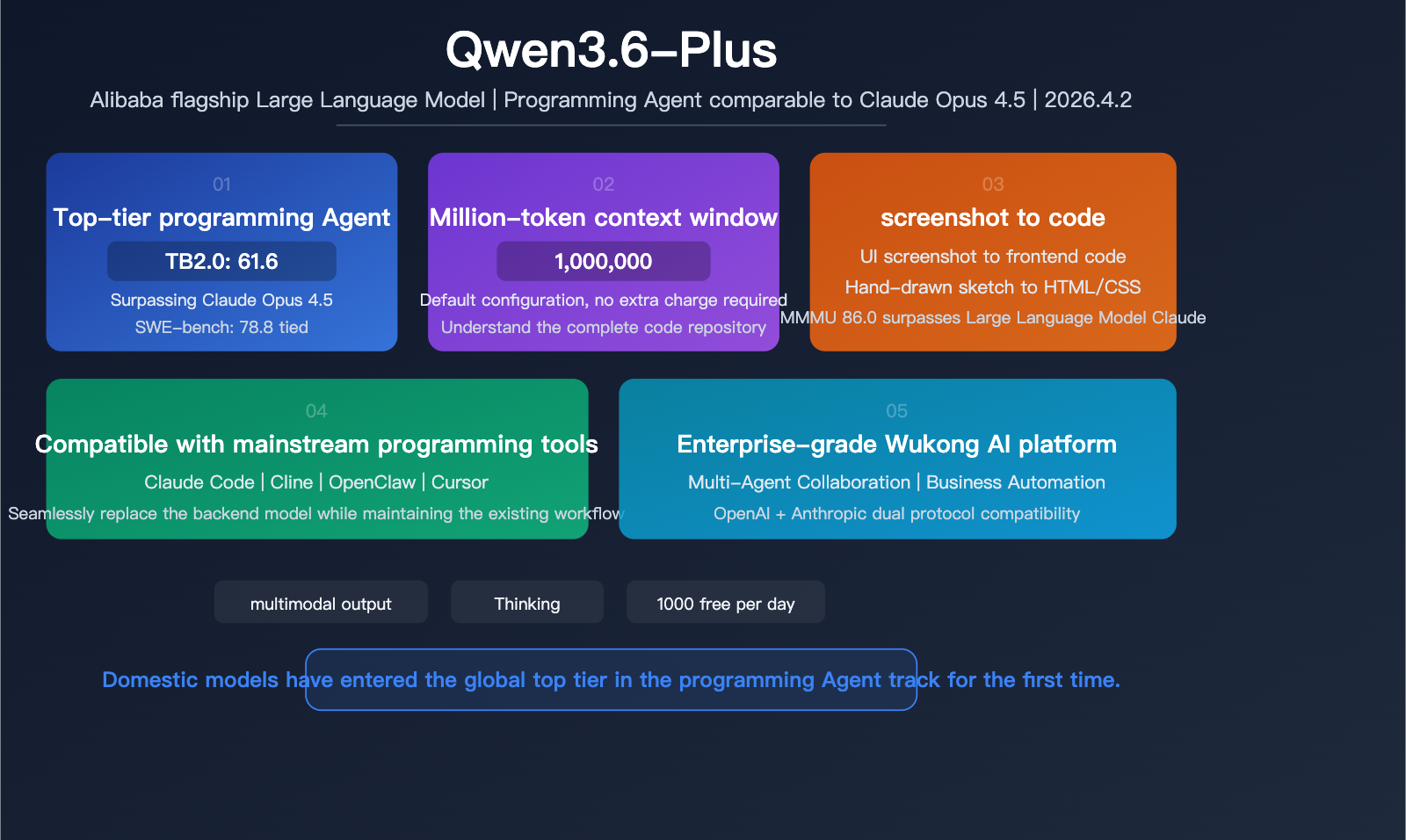
On April 2, 2026, Alibaba officially released Qwen3.6-Plus. This is the first domestic Large Language Model to outperform Claude Opus 4.5 on Terminal-Bench 2.0, while also possessing multimodal capabilities for generating frontend code directly from UI screenshots. It supports a 1-million-token context window by default and is compatible with mainstream programming tools like OpenClaw, Claude Code, and Cline, marking the entry of domestic models into the top tier of the programming agent race.
Key Takeaways: Get up to speed in 5 minutes on Qwen3.6-Plus's programming capabilities, benchmark data, multimodal features, and how to integrate it via API.
Qwen3.6-Plus Quick Overview
| Feature | Details |
|---|---|
| Release Date | April 2, 2026 |
| Developer | Alibaba / Qwen Team |
| Positioning | Programming Agent + Multimodal Flagship |
| Terminal-Bench 2.0 | 61.6 (Surpasses Claude Opus 4.5's 59.3) |
| SWE-bench Verified | 78.8 (Approaches Claude Opus 4.5's 80.9) |
| Context Window | 1 Million Tokens (Default) |
| Multimodal | Text/Image/Code/Web/Video |
| Tool Compatibility | OpenClaw / Claude Code / Cline |
| Enterprise Integration | Alibaba Wukong AI Platform |
The Strategic Significance of Qwen3.6-Plus
Qwen3.6-Plus isn't just another routine update; it's a major move by Alibaba into the "programming agent" space. Previously, this field was dominated by Anthropic (Claude Code) and OpenAI (Codex). By outperforming Claude Opus 4.5 on Terminal-Bench 2.0, Qwen3.6-Plus proves that domestic models can reach world-class levels in practical terminal programming tasks.
More importantly, it is natively compatible with Claude Code and Cline—meaning you don't need to change your toolchain; you can simply plug Qwen3.6-Plus in as the backend model for your existing programming workflow.
Deep Dive into Qwen3.6-Plus Programming Agent Capabilities
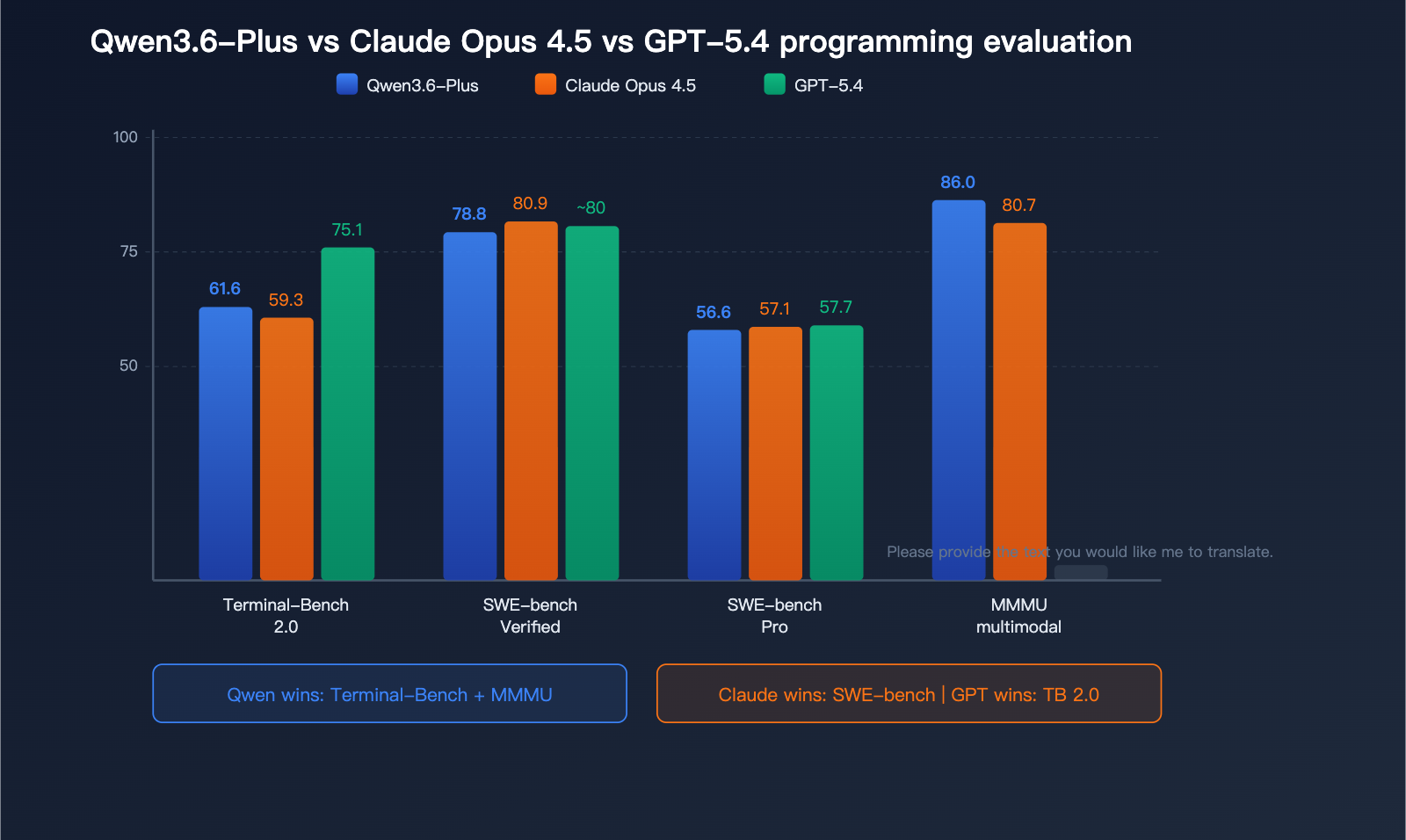
Qwen3.6-Plus Programming Benchmark Data
| Benchmark | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 | Notes |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 61.6 | 59.3 | 75.1 | Terminal programming, outperforms Claude |
| SWE-bench Verified | 78.8 | 80.9 | ~80 | Code repair, close to Claude |
| SWE-bench Pro | 56.6 | 57.1 | 57.7 | High-difficulty programming, basically tied |
| SWE-bench Multilingual | 73.8 | – | – | Multilingual programming |
| NL2Repo | 37.9 | 43.2 | – | Long-range codebase generation |
Core Analysis:
Outperforming Claude on Terminal-Bench 2.0: This is the most practical benchmark—Terminal-Bench evaluates a model's ability to complete programming tasks in a real terminal environment (3-hour timeout, 32 CPU / 48GB RAM environment). Qwen3.6-Plus scored 61.6, surpassing Claude Opus 4.5's 59.3, which shows that Qwen3.6-Plus is already performing better in real-world terminal operation scenarios.
Close but not surpassing the SWE-bench series: In code repair benchmarks, the gap between Qwen3.6-Plus (78.8) and Claude Opus 4.5 (80.9) is only 2.1 percentage points, placing them in the same tier.
GPT-5.4 remains in the lead: It's important to be objective: GPT-5.4 scored 75.1 on Terminal-Bench 2.0, still leading Qwen3.6-Plus by about 14 percentage points. Alibaba did not highlight GPT-5.4's data in their official comparison.
Real-World Capabilities of the Qwen3.6-Plus Agent
The practical capabilities of Qwen3.6-Plus as a programming agent include:
| Capability | Description | Benchmarked Against |
|---|---|---|
| Repository-level problem solving | Fixing bugs after understanding the entire codebase | Claude Code |
| Frontend code generation | Generating UI code directly from screenshots/wireframes | Cursor |
| Autonomous terminal operation | Executing commands and scripts autonomously in the terminal | Codex CLI |
| Multi-file collaborative editing | Performing consistent modifications across multiple files | Claude Code |
| Automated workflow | An automated closed loop from requirements to code | Devin |
🎯 Developer Tip: Qwen3.6-Plus has reached the top global tier in programming agent capabilities. Through the APIYI (apiyi.com) platform, you can access Qwen3.6-Plus, Claude Opus 4.5, and GPT-5.4 in one place, allowing you to choose the best model for your specific programming tasks.
Qwen3.6-Plus Multimodal Capabilities and Screenshot-to-Code
Qwen3.6-Plus: Generating Code from Screenshots
The feature that excites frontend developers most about Qwen3.6-Plus is its ability to generate code directly from visual inputs:
| Input Type | Output | Use Case |
|---|---|---|
| UI Screenshot | Functional frontend code | Rapid design-to-code conversion |
| Hand-drawn Sketch | HTML/CSS/JS code | From napkin sketch to prototype |
| Product Mockup | Runnable interface code | Seamless design-to-dev workflow |
| Charts and Docs | Structured data and code | OCR + intelligent parsing |
This means if a designer hands you a screenshot, Qwen3.6-Plus can output runnable frontend code immediately—no more manual, pixel-perfect reconstruction required.
Qwen3.6-Plus Multimodal Benchmarks
| Benchmark | Qwen3.6-Plus | Claude Opus 4.5 | Gemini 3 Pro | Notes |
|---|---|---|---|---|
| MMMU | 86.0 | 80.7 | 87.2 | Multimodal understanding |
| OmniDocBench | 91.2 | – | – | Document understanding |
| Video-MME | 87.8 | – | – | Video understanding |
| RealWorldQA | 85.4 | – | – | Real-world scenario QA |
In terms of multimodal understanding, Qwen3.6-Plus scores 86.0 on MMMU, significantly outperforming Claude Opus 4.5 (80.7) and trailing only slightly behind Gemini 3 Pro (87.2). Its performance in document understanding (OmniDocBench 91.2) and video understanding (Video-MME 87.8) is particularly impressive.
💡 Practical Tip: If your work involves turning designs into code, the screenshot-to-code capability of Qwen3.6-Plus can drastically boost your efficiency. You can integrate this capability into your development workflow by using the Qwen3.6-Plus API via APIYI (apiyi.com).
Qwen3.6-Plus Million-Token Context Window
Qwen3.6-Plus Context Window
Qwen3.6-Plus supports a 1-million-token context window by default—no extra fees or special extended modes required. 1 million is the standard configuration.
| Context Feature | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| Default Context | 1M token | 200K | 272K |
| Extended Context | 1M (Default) | 200K | 1M (Paid add-on) |
| Benchmark Context | 256K (SWE-bench) | – | – |
A default 1-million-token context window is especially critical for coding agent scenarios. When a model needs to understand an entire codebase, plan modifications, and execute multi-step operations, a sufficiently large context window is the foundation for getting the job done.
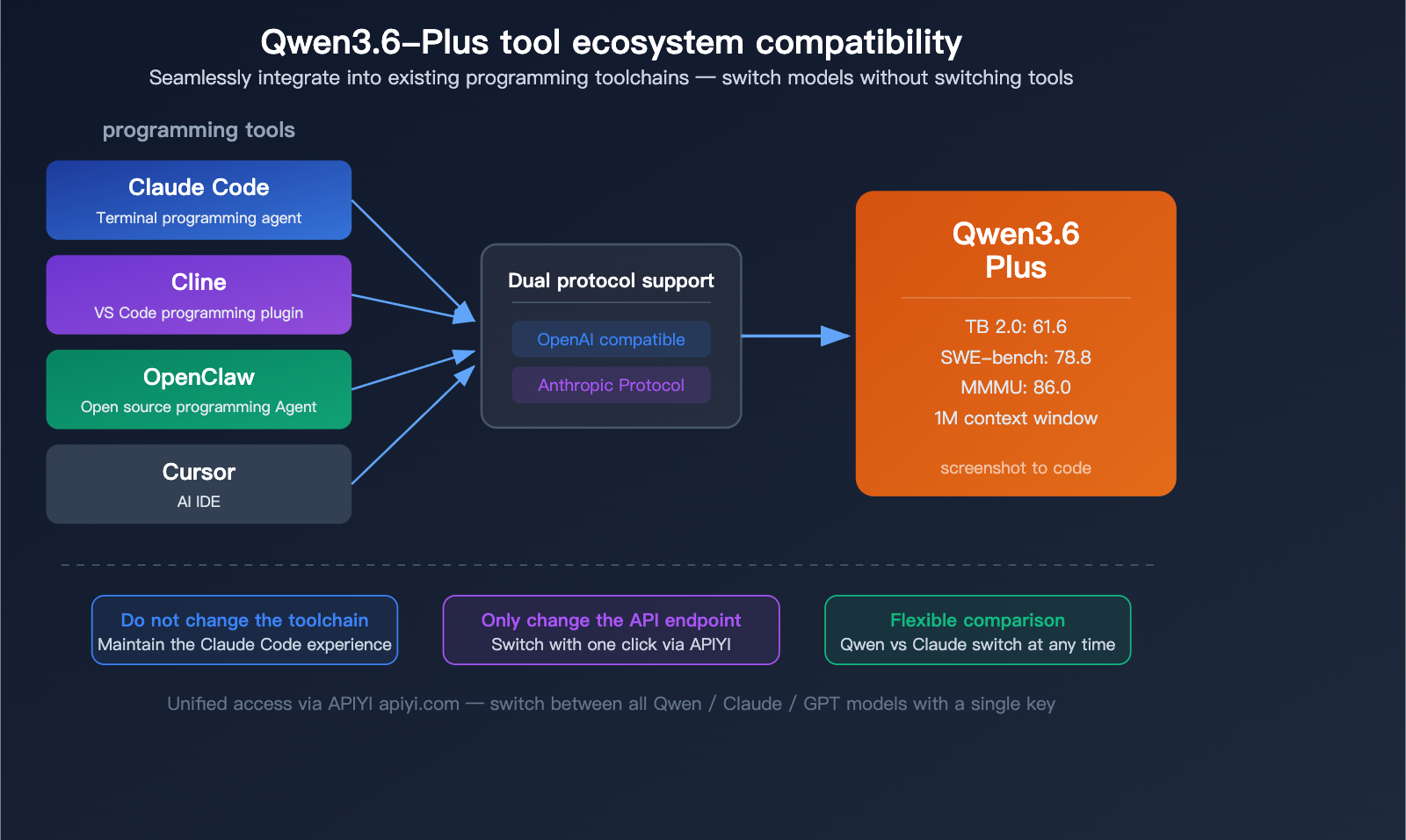
Qwen3.6-Plus Tool Compatibility
Integrating Qwen3.6-Plus with Programming Tools
Qwen3.6-Plus is designed to plug directly into your existing programming toolchain:
| Tool | Compatibility Method | Notes |
|---|---|---|
| Claude Code | Replace backend model via API | Keep your Claude Code workflow, just swap in Qwen |
| Cline | OpenAI-compatible interface | Connect directly via the VS Code extension |
| OpenClaw | Native support | Open-source programming Agent framework |
| Cursor | OpenAI-compatible | Call directly within the IDE |
This means you don't need to learn any new tools—if you're already using Claude Code or Cline, just update your API endpoint to Qwen3.6-Plus and start leveraging its powerful programming Agent capabilities.
Qwen3.6-Plus API Access
Qwen3.6-Plus supports both OpenAI-compatible protocols and Anthropic protocols:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{
"role": "user",
"content": "Analyze the architecture of this code repository, identify performance bottlenecks, and provide an optimization plan."
}]
)
print(response.choices[0].message.content)
View invocation example with Thinking mode
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Enable Thinking mode for deep reasoning
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{
"role": "user",
"content": "Please review this code and identify all security vulnerabilities."
}],
extra_body={
"enable_thinking": True
}
)
# Retrieve the reasoning process and the final answer
print(response.choices[0].message.content)
🚀 Quick Start: Get your API key from APIYI (apiyi.com) to start calling Qwen3.6-Plus. The platform also supports all mainstream models like Claude, GPT, and Gemini, allowing you to switch and compare the performance of different models on programming tasks using a single key.
Qwen3.6-Plus Enterprise Integration: Wukong Platform
Qwen3.6-Plus Application in Wukong AI Platform
Alibaba has integrated Qwen3.6-Plus into its internal enterprise AI platform, Wukong. Wukong is an enterprise system that leverages multiple AI Agents to automate business tasks:
- Multi-Agent Collaboration: Multiple AI Agents work together to complete complex business workflows.
- Code Automation: An automated pipeline that handles everything from requirements documentation to code implementation.
- Enterprise-Grade Deployment: Designed for both internal Alibaba teams and enterprise clients.
How to Access Qwen3.6-Plus
| Access Method | Description |
|---|---|
| Alibaba Cloud Model Studio | Enterprise-grade API access |
| Qwen Chat | Online chat experience |
| Tongyi Qianwen App | Mobile experience |
| Third-party API Platforms | Access via API proxy services like APIYI |
| Qwen Code | 1,000 free programming-focused model invocations per day |
🎯 Free Trial: Qwen Code offers 1,000 free model invocations daily, which is perfect for evaluation and prototyping. For production use, we recommend using APIYI (apiyi.com) for stable API access. It also allows you to easily compare the performance of Qwen3.6-Plus and Claude Opus 4.5 on your specific projects.
FAQ
Q1: Is Qwen3.6-Plus better than Claude Opus 4.5?
It depends on the use case. Qwen3.6-Plus leads in Terminal-Bench 2.0 (terminal programming) with a score of 61.6 vs 59.3, while Claude leads in SWE-bench Verified (code repair) with 80.9 vs 78.8. Qwen also holds a significant lead in MMMU (multimodal) tasks at 86.0 vs 80.7. Both models are in the same tier; we recommend using APIYI (apiyi.com) to access both and choosing the best one for your specific tasks.
Q2: Can I use Qwen3.6-Plus in Claude Code?
Yes, you can. Qwen3.6-Plus supports both OpenAI-compatible and Anthropic protocols, so you can use it in Claude Code by modifying the API endpoint. Using the unified interface provided by APIYI (apiyi.com) makes configuration even simpler—you can switch between Claude, Qwen, GPT, and other models in Claude Code using just a single API key.
Q3: What is the pricing for Qwen3.6-Plus?
The entry-level price on the Alibaba Cloud Bailian platform is approximately $0.29 per million input tokens. Qwen Code provides 1,000 free model invocations per day. During the preview period, some platforms (like OpenRouter) may offer free credits. For stable, production-grade model invocation, we recommend checking out the flexible billing plans available via APIYI (apiyi.com).
Summary
The 5 core upgrades of Qwen3.6-Plus:
- Programming Agent on Par with the Best: It scores 61.6 on Terminal-Bench 2.0, surpassing Claude Opus 4.5, and holds its own against the SWE-bench series.
- 1M Token Context by Default: No extra cost, 1 million token context window is ready to use out of the box.
- Direct Code Generation from Screenshots: End-to-end capability to turn UI screenshots and hand-drawn sketches into functional frontend code.
- Seamless Tool Integration: Compatible with Claude Code, Cline, and OpenClaw, so there's no need to change your existing toolchain.
- Leading Multimodal Understanding: With an MMMU score of 86.0, it significantly outperforms Claude Opus 4.5, showing exceptional performance in document and video comprehension.
The release of Qwen3.6-Plus marks the official entry of domestic Large Language Models into the global top tier for programming Agents. We recommend using APIYI (apiyi.com) to access both Qwen3.6-Plus and Claude Opus 4.5. With just one API key, you can compare their performance on programming tasks and choose the best solution for your needs.
📚 References
-
Alibaba Cloud Official Tech Blog – Qwen3.6-Plus: Complete technical introduction and evaluation data.
- Link:
alibabacloud.com/blog/qwen3-6-plus-towards-real-world-agents_603005 - Description: Includes architecture details, evaluation methods, and benchmark comparisons.
- Link:
-
Caixin Global – Qwen3.6-Plus Launch Report: Product positioning and market analysis.
- Link:
caixinglobal.com/2026-04-02/alibaba-releases-qwen-36-plus - Description: Includes launch background and industry impact analysis.
- Link:
-
Dataconomy – Enterprise AI Application Analysis: Wukong platform integration and enterprise deployment.
- Link:
dataconomy.com/2026/04/02/alibaba-launches-qwen3-6-plus - Description: Detailed enterprise-level application scenarios and deployment methods.
- Link:
-
Qwen3-Coder GitHub: Open-source programming models and technical documentation.
- Link:
github.com/QwenLM/Qwen3-Coder - Description: Includes model weights, API documentation, and usage examples.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your programming experience with Qwen3.6-Plus in the comments. For more information on AI model integration, visit the APIYI documentation center at docs.apiyi.com.