Kennen Sie das Problem? Sie nutzen in Ihrem Projekt gleichzeitig GPT von OpenAI, Claude von Anthropic und Gemini von Google, aber jedes Modell hat ein anderes SDK, ein anderes API-Format und sogar eine eigene Fehlerbehandlung. Sobald Sie das Modell wechseln wollen, müssen Sie den halben Code umschreiben?
Genau das löst LiteLLM. Kurz gesagt: LiteLLM ist der „Universalübersetzer“ für KI-Großsprachmodelle – Sie müssen nur eine einzige Aufrufmethode (das OpenAI-Format) erlernen, und LiteLLM übersetzt diese in die spezifischen API-Formate von über 100 verschiedenen Modellanbietern.
Kernnutzen: Nach dem Lesen dieses Artikels wissen Sie, was LiteLLM ist, warum KI-Agent-Frameworks darauf setzen und wie Sie in unter 5 Minuten damit starten können.
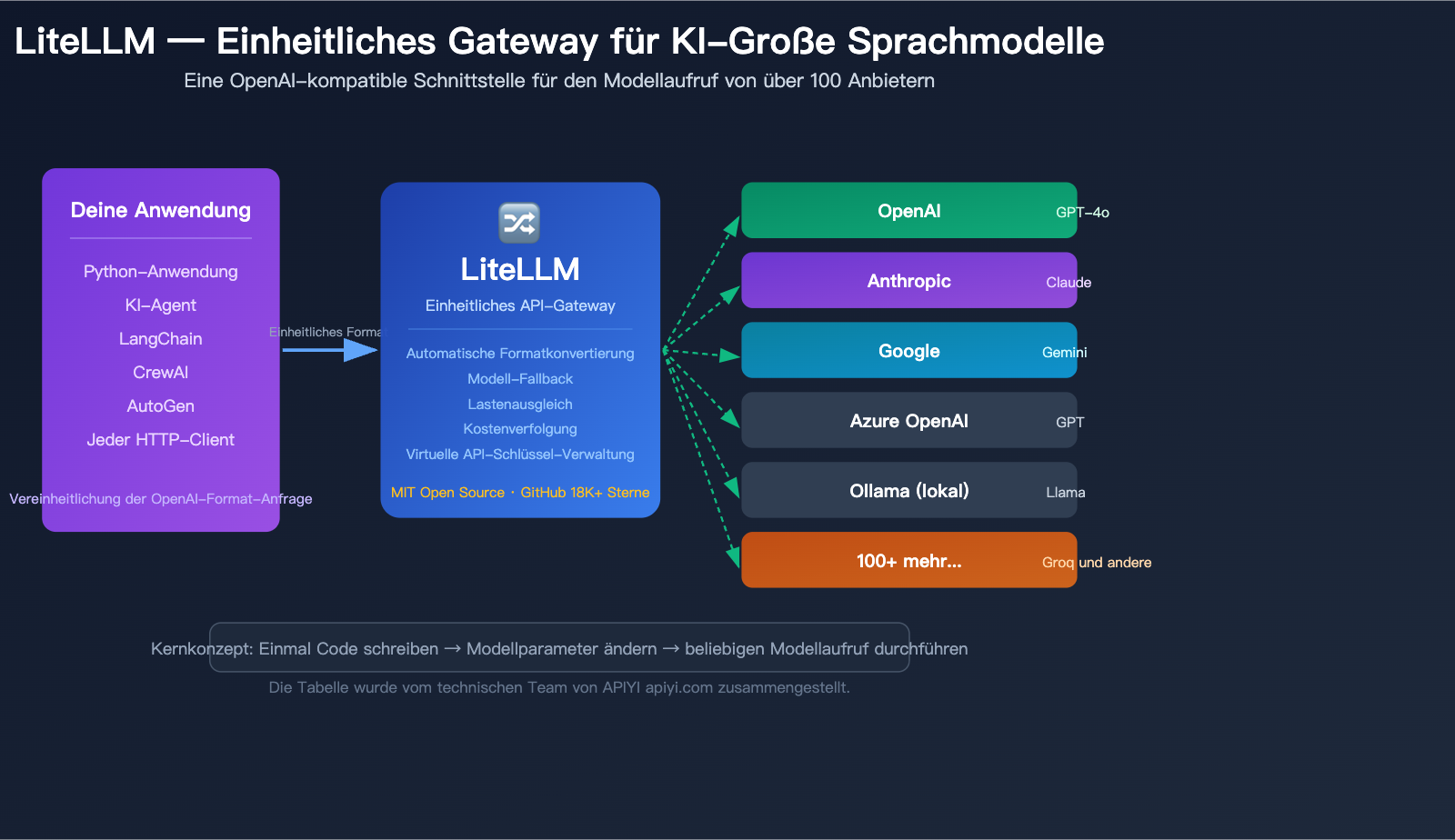
Was ist LiteLLM: 5 Kernkonzepte
Bevor Sie loslegen, lassen Sie uns die 5 Kernkonzepte von LiteLLM auf einfache Weise verstehen. Wenn diese Konzepte klar sind, werden die weiteren Schritte zum Kinderspiel.
| Kernkonzept | Einfache Erklärung | Gelöstes Problem |
|---|---|---|
| Einheitliche Schnittstelle | Alle Modelle werden gleich aufgerufen | Kein Erlernen eines SDK pro Modell |
| Provider (Anbieter) | Modellhersteller wie OpenAI, Anthropic etc. | Verwaltung der Verbindungen zu verschiedenen Anbietern |
| Fallback (Ausfallsicherung) | Automatischer Wechsel zu Modell B, wenn A ausfällt | Garantiert unterbrechungsfreien Service |
| Virtual Key (Virtueller Schlüssel) | "Unterkonten" für Teammitglieder | Kontrolle von Nutzung und Budget |
| Proxy (Proxy-Gateway) | Unabhängig laufender API-Proxy-Dienst | Zugriff für jede Sprache und jedes Tool möglich |
Welche Probleme löst LiteLLM?
Stellen Sie sich eine Welt ohne LiteLLM vor:
Aufruf von OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hallo"}]
)
Aufruf von Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic erfordert diese Angabe
messages=[{"role": "user", "content": "Hallo"}]
)
Aufruf von Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Hallo")
Sehen Sie? Drei Modelle, drei SDKs, drei Schreibweisen. Wenn Ihr Projekt einen Modellwechsel unterstützen soll, ist der Code voller if provider == "openai"... elif provider == "anthropic"... Bedingungen.
Mit LiteLLM:
import litellm
# Aufruf von OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Hallo"}])
# Aufruf von Anthropic – dieselbe Schreibweise
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Hallo"}])
# Aufruf von Gemini – immer noch dieselbe Schreibweise
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Hallo"}])
Ein litellm.completion(), einfach den model-Parameter ändern. LiteLLM übernimmt im Hintergrund automatisch die Formatkonvertierung, Parameteranpassung und Standardisierung der Antwort.
🎯 Technischer Hinweis: Das Konzept der einheitlichen Schnittstelle von LiteLLM ähnelt APIYI (apiyi.com) – beides ermöglicht den Aufruf verschiedener Modelle über eine Schnittstelle. Der Unterschied: LiteLLM ist eine Open-Source-Lösung zum Selbst-Hosting, APIYI ist ein verwalteter Dienst ohne eigenen Wartungsaufwand. Wählen Sie basierend auf den technischen Kapazitäten Ihres Teams.
Detaillierte Erläuterung der zwei LiteLLM-Nutzungsmodi
LiteLLM bietet zwei Modi für unterschiedliche Szenarien. Das Verständnis dieser Unterschiede ist entscheidend für die richtige Wahl.
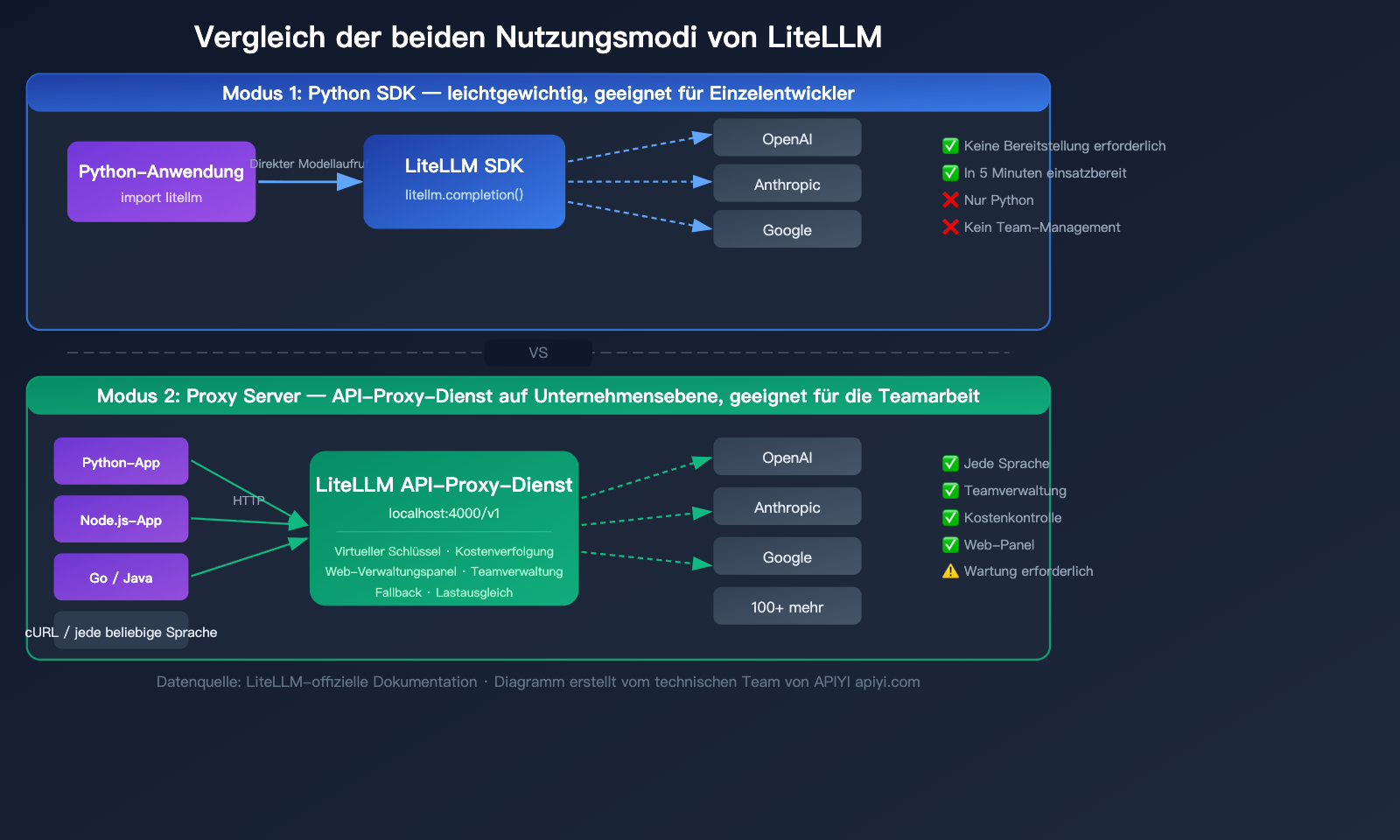
Modus 1: Python SDK (Leichtgewicht)
Importieren Sie das litellm-Paket direkt in Ihren Python-Code und verwenden Sie es wie einen Funktionsaufruf.
Geeignet für:
- Einzelentwickler
- Reine Python-Projekte
- Schnelle Prototyping-Validierung
- Projekte ohne Bedarf an Team-Management-Funktionen
Installation:
pip install litellm
Grundlegende Verwendung:
import litellm
import os
# API-Schlüssel setzen (über Umgebungsvariablen)
os.environ["OPENAI_API_KEY"] = "sk-IhrSchlüssel"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-IhrSchlüssel"
# Beliebiges Modell aufrufen
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Erkläre, was ein API-Gateway ist"}]
)
print(response.choices[0].message.content)
Modus 2: Proxy Server (Unternehmens-Gateway)
Läuft als eigenständiger Server und stellt eine OpenAI-kompatible HTTP-Schnittstelle bereit. Jede Programmiersprache und jedes Tool, das HTTP-Anfragen senden kann, kann diesen Dienst nutzen.
Geeignet für:
- Team-Zusammenarbeit
- Mehrsprachige Projekte (Java, Go, Node.js etc.)
- Bedarf an Kostenverfolgung und Budgetmanagement
- Zuweisung virtueller Schlüssel für verschiedene Teams
- Integration von KI-Agenten-Frameworks
Installation und Start:
# Installation
pip install 'litellm[proxy]'
# Start mit Konfigurationsdatei
litellm --config config.yaml --port 4000
# Oder per Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
Nach dem Start kann jede Anwendung den Proxy wie OpenAI aufrufen:
from openai import OpenAI
# base_url auf den LiteLLM Proxy richten
client = OpenAI(
api_key="sk-IhrVirtuellerSchlüssel",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hallo"}]
)
Vergleich: LiteLLM SDK vs. Proxy-Modus
| Vergleichsdimension | Python SDK | Proxy Server |
|---|---|---|
| Installation | pip install litellm |
pip install 'litellm[proxy]' oder Docker |
| Aufrufart | Python-Funktionsaufruf | HTTP-API (beliebige Sprache) |
| Konfiguration | Im Code | config.yaml Konfigurationsdatei |
| Virtuelle Schlüssel | Nicht unterstützt | Unterstützt, mit Budgetlimit |
| Web-Verwaltung | Keine | Vorhanden, visuelle Verwaltung |
| Team-Management | Nicht unterstützt | Unterstützt (Benutzer/Teams/Budget) |
| Kostenverfolgung | Basis (auf Code-Ebene) | Vollständig (Datenbank-Persistenz) |
| Bereitstellung | Keine | Erfordert Server-Wartung |
| Zielgruppe | Einzelentwickler | Teams/Unternehmen |
💡 Empfehlung: Wenn Sie als Einzelentwickler einen Prototyp validieren, ist der SDK-Modus in 5 Minuten einsatzbereit. Für den Einsatz im Team oder in der Produktion ist der Proxy-Modus besser geeignet. Wenn Sie keine Lust auf eigene Server-Wartung haben, können Sie natürlich auch einen verwalteten Dienst wie APIYI (apiyi.com) nutzen – sofort einsatzbereit.
Hier ist die deutsche Übersetzung des Leitfadens für LiteLLM.
LiteLLM-Schnellstartanleitung
Hier sind die vollständigen Schritte, um LiteLLM von Grund auf zu nutzen.
LiteLLM SDK-Modus: Schnellstart
Schritt 1: Installation
pip install litellm
Schritt 2: Umgebungsvariablen festlegen
# macOS / Linux
export OPENAI_API_KEY="sk-dein-schlüssel"
export ANTHROPIC_API_KEY="sk-ant-dein-schlüssel"
# Windows
set OPENAI_API_KEY=sk-dein-schlüssel
Schritt 3: Code schreiben
import litellm
# Basis-Aufruf
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Du bist ein technischer Assistent"},
{"role": "user", "content": "Was ist ein LLM-Gateway?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Token-Verbrauch: {response.usage.total_tokens}")
print(f"Geschätzte Kosten: ${response._hidden_params.get('response_cost', 'N/A')}")
Vollständigen Code anzeigen: Mit Fallback und Streaming
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-dein-schlüssel"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-dein-schlüssel"
# Aufruf mit Fallback: Wenn GPT-4o fehlschlägt, wird automatisch auf Claude gewechselt
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Erkläre RESTful API"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Streaming-Ausgabe
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Schreibe ein Gedicht über Programmierung"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
LiteLLM Proxy-Modus: Schnellstart
Schritt 1: Konfigurationsdatei config.yaml erstellen
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Schritt 2: Proxy starten
litellm --config config.yaml --port 4000
Schritt 3: Aufruf über das Standard-OpenAI-SDK
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Aufruf von GPT-4o (über LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hallo"}]
)
print(response.choices[0].message.content)
Alternativ kann der Aufruf direkt per cURL erfolgen:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Hello"}]
}'
🚀 Schnellstart: Der LiteLLM-Proxy erfordert die eigene Verwaltung von Servern und API-Schlüsseln. Wenn Sie ohne Bereitstellungsaufwand eine einheitliche Schnittstelle nutzen möchten, probieren Sie APIYI (apiyi.com) aus. Es unterstützt ebenfalls das OpenAI-kompatible Format für über 100 Modelle, ohne dass eine eigene Infrastruktur aufgebaut werden muss.
Die zentrale Rolle von LiteLLM in KI-Agenten
Dies ist eine häufige Frage von Einsteigern: Warum unterstützen oder empfehlen fast alle gängigen KI-Agenten-Frameworks die Verwendung von LiteLLM?
Warum benötigen KI-Agenten LiteLLM?
KI-Agenten (intelligente Agenten) müssen bei der Ausführung von Aufgaben häufig:
- Verschiedene Modelle aufrufen: Einfache Aufgaben mit günstigen kleinen Modellen, komplexe Schlussfolgerungen mit großen Modellen.
- Automatische Herabstufung: Bei Ratenbegrenzungen oder Ausfällen des Hauptmodells automatisch auf ein Ersatzmodell umschalten.
- Kostenkontrolle: Bei parallelem Betrieb mehrerer Agenten den Token-Verbrauch zentral verfolgen und begrenzen.
- Team-Zusammenarbeit: Gemeinsame Nutzung von API-Ressourcenpools durch verschiedene Entwickler-Agenten.
LiteLLM löst diese Anforderungen perfekt. Es fungiert als „Dispositionszentrale“ zwischen dem Agenten und den Modellen.
Integration von LiteLLM in gängige KI-Agenten-Frameworks
| Agent-Framework | Integrationsmethode | Typische Verwendung |
|---|---|---|
| LangChain / LangGraph | SDK-integrierte Unterstützung | ChatLiteLLM als LLM-Backend |
| CrewAI | Proxy-Verbindung | Gemeinsamer Modell-Ressourcenpool für Multi-Agenten |
| AutoGen (Microsoft) | Proxy-Verbindung | Zugriff über OpenAI-kompatiblen Endpunkt |
| Dify | Benutzerdefinierter Provider | Konfiguration als OpenAI-kompatibler Endpunkt |
| Open WebUI | Proxy-Verbindung | Backend-API-Endpunkt |
| Aider | Proxy-Verbindung | Modellschicht für Code-Generierungs-Agenten |
| Continue.dev | Proxy-Verbindung | Backend für KI-Coding-Assistenten in der IDE |
Typische Architektur von LiteLLM in Multi-Agenten-Systemen
In einem Multi-Agenten-System arbeitet der LiteLLM-Proxy normalerweise wie folgt:
- Planungs-Agent → ruft Claude Opus auf (starkes Schlussfolgerungsmodell)
- Ausführungs-Agent → ruft GPT-4o auf (ausgewogene Leistung)
- Validierungs-Agent → ruft GPT-4o-mini auf (schnell und kostengünstig)
- Zusammenfassungs-Agent → ruft Gemini Flash auf (großes Kontextfenster)
Alle Agenten rufen denselben LiteLLM-Proxy-Endpunkt auf, und der Proxy routet die Anfragen automatisch an das richtige Backend-Modell. Administratoren können über ein Dashboard den Token-Verbrauch und die Kosten aller Agenten zentral einsehen.
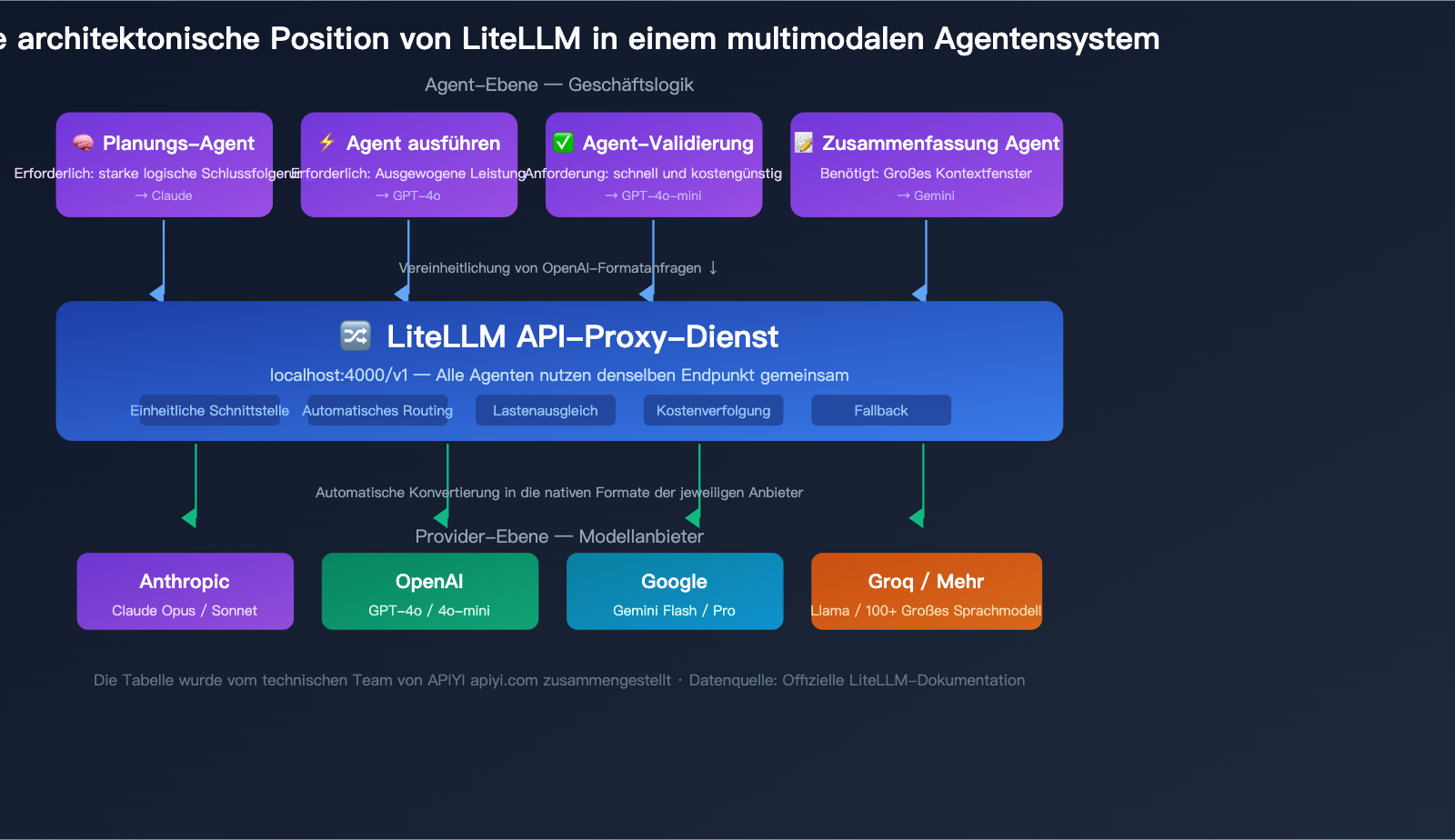
🎯 Technischer Hinweis: In Multi-Agenten-Systemen in der Produktion muss der LiteLLM-Proxy mit PostgreSQL und Redis kombiniert werden, um die Kostenverfolgung und Caching-Funktionen vollständig nutzen zu können. Wenn Ihr Team klein ist oder Sie keine zusätzliche Infrastruktur betreiben möchten, bietet APIYI (apiyi.com) ähnliche Funktionen für eine einheitliche Schnittstelle, inklusive integrierter Kostenverfolgung und Nutzungsstatistiken, ohne dass eine externe Datenbank bereitgestellt werden muss.
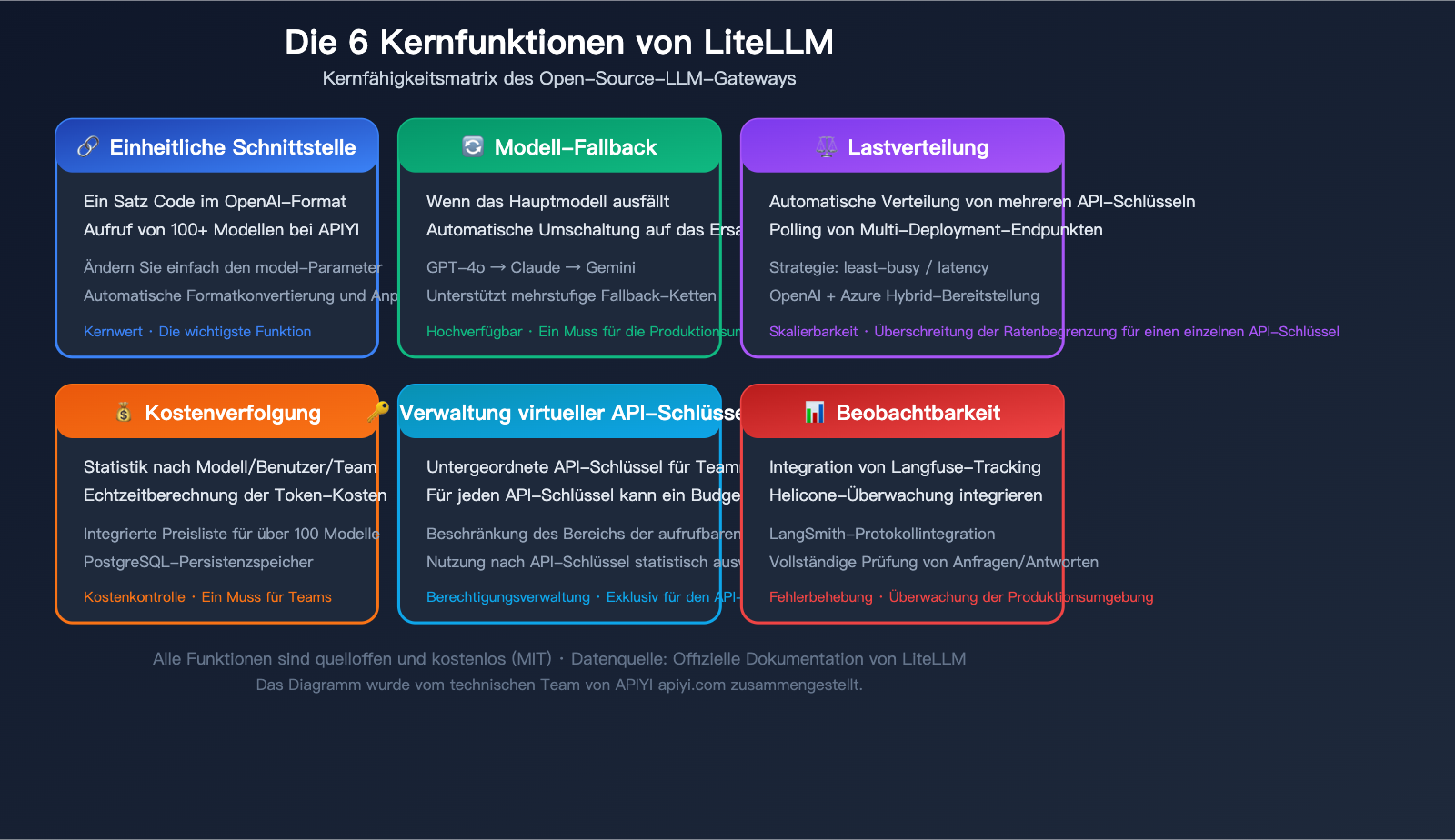
Detaillierte Funktionen von LiteLLM
Nachdem Sie die Grundlagen beherrschen, sind die folgenden drei fortgeschrittenen Funktionen für den produktiven Einsatz am wichtigsten.
Fortgeschrittene Funktion 1: Modell-Fallback (Failover)
Wenn das Hauptmodell gedrosselt wird, Zeitüberschreitungen auftreten oder Fehler gemeldet werden, schaltet LiteLLM automatisch auf ein Ersatzmodell um, um die Dienstverfügbarkeit zu gewährleisten.
Fallback-Konfiguration im SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Logik: Zuerst GPT-4o → bei Fehler Claude Sonnet → bei erneutem Fehler Gemini Flash.
Fallback-Konfiguration im Proxy (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Fortgeschrittene Funktion 2: Lastverteilung
Bei mehreren Backend-Bereitstellungen für denselben Modellnamen verteilt LiteLLM die Anfragen automatisch.
model_list:
# Derselbe Modellname, zwei verschiedene Backends
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Bevorzugt das am wenigsten ausgelastete Modell
# Andere Strategien: simple-shuffle, latency-based
Beim Aufruf muss nur model="gpt-4o" angegeben werden; LiteLLM verteilt die Last automatisch zwischen der OpenAI-Direktverbindung und der Azure-Bereitstellung.
Fortgeschrittene Funktion 3: Kostenverfolgung und virtuelle Schlüssel
Generierung eines virtuellen Schlüssels (Proxy-Modus):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Dies erstellt einen virtuellen Schlüssel mit einem monatlichen Budget von 50 $, der ausschließlich für GPT-4o und Claude Sonnet verwendet werden kann.
Kostenverfolgung:
LiteLLM enthält eine integrierte Preisliste für Modelle und berechnet die Kosten bei jedem Modellaufruf automatisch. Im Proxy-Verwaltungs-Dashboard können Sie einsehen:
- Gesamtkosten nach Modell
- Kostenaufschlüsselung nach Benutzer/Team
- Kostentrends nach Zeitraum
- Statistik zum Token-Verbrauch
💰 Kostenoptimierung: Die Kostenverfolgung von LiteLLM hilft Ihnen dabei, die teuersten Modellaufrufe zu identifizieren. In Kombination mit den Preisvorteilen von APIYI (apiyi.com) können Sie bei gleichen Modellaufrufen oft günstigere Konditionen erzielen und so die Betriebskosten Ihrer KI-Anwendungen weiter senken.
Übersicht der 100+ von LiteLLM unterstützten Modell-Provider
LiteLLM unterstützt eine enorme Anzahl an Providern. Hier sind die gebräuchlichsten Kategorien:
| Kategorie | Provider | Modell-Präfix | Beispielmodelle |
|---|---|---|---|
| Kommerzielle Großmodelle | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Cloud-Plattformen | Azure OpenAI | azure/ |
GPT-Serie via Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama via Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini via Vertex | |
| Inferenz-Beschleunigung | Groq | groq/ |
Llama 3.1 70B (extrem schnell) |
| Together AI | together_ai/ |
Diverse Open-Source-Modelle | |
| Fireworks AI | fireworks_ai/ |
Hochleistungs-Inferenz | |
| Lokale Bereitstellung | Ollama | ollama/ |
Lokal ausgeführte Llama/Mistral |
| vLLM | openai/ (benutzerdef. Base) |
Selbstgehostete Inferenz-Engine | |
| Chinesische Modelle | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Suche & Erweiterung | Perplexity | perplexity/ |
Sonar Pro |
| Aggregator-Plattformen | OpenRouter | openrouter/ |
Diverse Modelle |
🎯 Empfehlung: Die Modellwahl hängt vom Anwendungsfall ab. Wenn Sie unsicher sind, können Sie die Leistung verschiedener Modelle schnell über die Plattform APIYI (apiyi.com) testen, die ebenfalls die OpenAI-kompatiblen Schnittstellen für die meisten dieser Modelle unterstützt.
LiteLLM FAQ – Häufig gestellte Fragen
Q1: Was ist der Unterschied zwischen LiteLLM und der direkten Nutzung des OpenAI SDK?
Das OpenAI SDK kann nur Modelle von OpenAI aufrufen. LiteLLM erweitert das OpenAI SDK, sodass Sie über 100 weitere Modell-Provider wie Anthropic, Google oder Azure mit demselben Code-Format ansprechen können. Wenn Ihr Projekt ausschließlich OpenAI-Modelle nutzt, reicht das OpenAI SDK völlig aus. Wenn Sie jedoch Unterstützung für mehrere Modelle, Failover-Mechanismen oder eine Kostenkontrolle benötigen, ist LiteLLM die bessere Wahl.
Q2: Ist LiteLLM kostenlos?
Die Kernfunktionen von LiteLLM sind vollständig quelloffen und kostenlos (MIT-Lizenz). Beachten Sie jedoch: LiteLLM selbst ist kostenlos, aber die Modell-APIs, die es aufruft, sind kostenpflichtig. Sie müssen Ihre API-Schlüssel direkt bei OpenAI, Anthropic usw. beziehen und die Kosten für den Modellaufruf tragen. Wenn Sie nicht mehrere API-Schlüssel separat verwalten möchten, können Sie auch einheitliche Schnittstellenplattformen wie APIYI (apiyi.com) nutzen, um die Schlüsselverwaltung zu vereinfachen.
Q3: Welche Serverkonfiguration benötigt der LiteLLM-Proxy?
Der LiteLLM-Proxy ist sehr leichtgewichtig und läuft bereits auf einem Server mit 1 Kern und 1 GB RAM. Für den vollen Funktionsumfang (Kostenverfolgung, Verwaltung virtueller Schlüssel) benötigen Sie jedoch eine PostgreSQL-Datenbank und Redis. Für eine Produktionsumgebung empfehlen wir mindestens 2 Kerne, 4 GB RAM sowie PostgreSQL und Redis.
Q4: Was ist der Unterschied zwischen LiteLLM und OpenRouter?
Der größte Unterschied: LiteLLM ist eine Open-Source-Lösung zum Selbst-Hosting, während OpenRouter ein verwalteter Dienst ist.
- LiteLLM: Kostenlos, selbst gehostet, volle Kontrolle über API-Schlüssel und Datenfluss.
- OpenRouter: Sofort einsatzbereit, jedoch mit Aufschlägen auf die API-Preise und Datenverarbeitung durch Dritte.
Wenn Ihnen Datenschutz wichtig ist oder Sie eigene API-Schlüssel besitzen, wählen Sie LiteLLM. Wenn Sie eine Lösung ohne eigenen Installationsaufwand suchen, sind verwaltete Dienste wie APIYI (apiyi.com) eine gute Alternative.
Q5: Unterstützt LiteLLM Streaming?
Ja. Sowohl im SDK- als auch im Proxy-Modus unterstützt LiteLLM vollständig SSE-Streaming. Die Streaming-Antworten aller Provider werden einheitlich in das OpenAI-Chunk-Format konvertiert, um ein konsistentes Streaming-Erlebnis zu gewährleisten.
# Streaming-Beispiel
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Schreibe eine Geschichte"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: Sollte ich als Anfänger den SDK- oder den Proxy-Modus wählen?
Wenn Sie Python-Entwickler sind und gerade erst anfangen, ist der SDK-Modus am einfachsten: pip install litellm und nach wenigen Zeilen Code läuft alles. Wenn Sie später Teamarbeit, Unterstützung für mehrere Sprachen oder eine produktive Bereitstellung benötigen, können Sie auf den Proxy-Modus umsteigen. Da die Kernaufrufe in beiden Modi identisch sind, ist der Migrationsaufwand sehr gering.
Q7: Wo speichere ich die `config.yaml` von LiteLLM?
Es gibt keinen festen Speicherort. Sie geben den Pfad einfach beim Start des Proxys über den Parameter --config an:
litellm --config /pfad/zu/ihrer/config.yaml
Wir empfehlen, die Datei im Projektstammverzeichnis oder in einem dedizierten Konfigurationsordner abzulegen. Bei einer Bereitstellung via Docker binden Sie die Datei einfach als Volume in den Container ein.
LiteLLM – Entscheidungshilfe
Wählen Sie die für Ihre Situation am besten geeignete Lösung:
| Ihre Situation | Empfohlene Lösung | Grund |
|---|---|---|
| Einzelentwickler, Python-Projekt | LiteLLM SDK | Keine Installation, in 5 Min. einsatzbereit |
| Team-Entwicklung, Budgetkontrolle nötig | LiteLLM Proxy | Virtuelle Schlüssel + Kostenverfolgung |
| Keine eigene Infrastruktur gewünscht | APIYI (apiyi.com) | Verwalteter Dienst, sofort startklar |
| Multi-Agenten-System | LiteLLM Proxy | Einheitliches Routing + Lastverteilung |
| Nur Nutzung von OpenAI-Modellen | OpenAI SDK direkt | Keine zusätzliche Ebene erforderlich |
| Fokus auf Datenschutz | LiteLLM Selbst-Hosting | Daten fließen nicht über Dritte |
Zusammenfassung
LiteLLM ist ein äußerst nützliches Infrastruktur-Tool für die Entwicklung von KI-Anwendungen. Sein Kernwert lässt sich in einem Satz zusammenfassen: Nutzen Sie eine einzige Code-Basis im OpenAI-Format, um die APIs von über 100 Modellanbietern anzusprechen.
Für Einsteiger sind hier die wichtigsten Punkte:
- LiteLLM ist ein „Übersetzer“: Es hilft Ihnen dabei, Anfragen in einem einheitlichen Format in die spezifischen API-Formate der verschiedenen Modelle zu übersetzen.
- Zwei Modi: SDK (leichtgewichtiges Python-Paket) und Proxy (eigenständiger Gateway-Server).
- Kernwert: Einheitliche Schnittstelle + Fallback + Lastverteilung + Kostenverfolgung.
- Standard für Agenten-Frameworks: LangChain, CrewAI, AutoGen und viele andere unterstützen LiteLLM nahezu nativ.
- Vollständig Open Source und kostenlos: Unter der MIT-Lizenz stehend, entstehen bei der Selbstbereitstellung keinerlei Kosten.
Wenn Ihnen der Wartungsaufwand für die Selbstbereitstellung eines LiteLLM-Proxys zu hoch ist, können Sie auch direkt auf verwaltete, einheitliche Schnittstellendienste wie APIYI (apiyi.com) zurückgreifen. Damit erzielen Sie denselben Effekt – Zugriff auf alle gängigen Modelle mit nur einem API-Schlüssel – und sparen sich den Aufwand für Bereitstellung und Betrieb.
Autor dieses Artikels: APIYI Technik-Team
Technischer Austausch: Besuchen Sie APIYI unter apiyi.com für weitere Tutorials zu Modellaufrufen und technischen Support.
Aktualisierungsdatum: April 2026
Gültige Version: LiteLLM v1.x+
Referenzmaterialien:
- Offizielle LiteLLM-Dokumentation: docs.litellm.ai
- LiteLLM GitHub-Repository: github.com/BerriAI/litellm
- LiteLLM-Website: litellm.ai
- BerriAI-Website: berri.ai