Möchten Sie ein komplettes Code-Repository auf einmal analysieren oder hunderte Seiten technischer Dokumentation verarbeiten, werden aber ständig durch die Beschränkungen des Kontextfensters ausgebremst? Claude Opus 4.6 bringt ein riesiges Kontextfenster von 1 Million Token mit. Dies ist der erste Durchbruch dieser Art für die Opus-Modellreihe – das entspricht der Verarbeitung von etwa 750.000 Wörtern Text in einem Durchgang.
Kernwert: In diesem Artikel erfahren Sie, wie Sie das 1M-Token-Kontextfenster von Claude 4.6 aktivieren, die Preisstrategie für langen Kontext verstehen und 5 hochwertige Praxis-Szenarien meistern.

Claude 4.6 Kontextfenster: Die wichtigsten Parameter im Überblick
Claude Opus 4.6 wurde am 5. Februar 2026 veröffentlicht. Das auffälligste Upgrade ist die massive Erweiterung des Kontextfensters. Hier sind die Kernparameter:
| Parameter | Claude Opus 4.6 | Vorherige Generation Opus 4.5 | Steigerung |
|---|---|---|---|
| Standard-Kontextfenster | 200K Token | 200K Token | Unverändert |
| Beta-Erweiterungsfenster | 1.000K (1M) Token | Nicht unterstützt | Erstmals verfügbar |
| Maximaler Output-Token | 128K Token | 64K Token | 2-fache Steigerung |
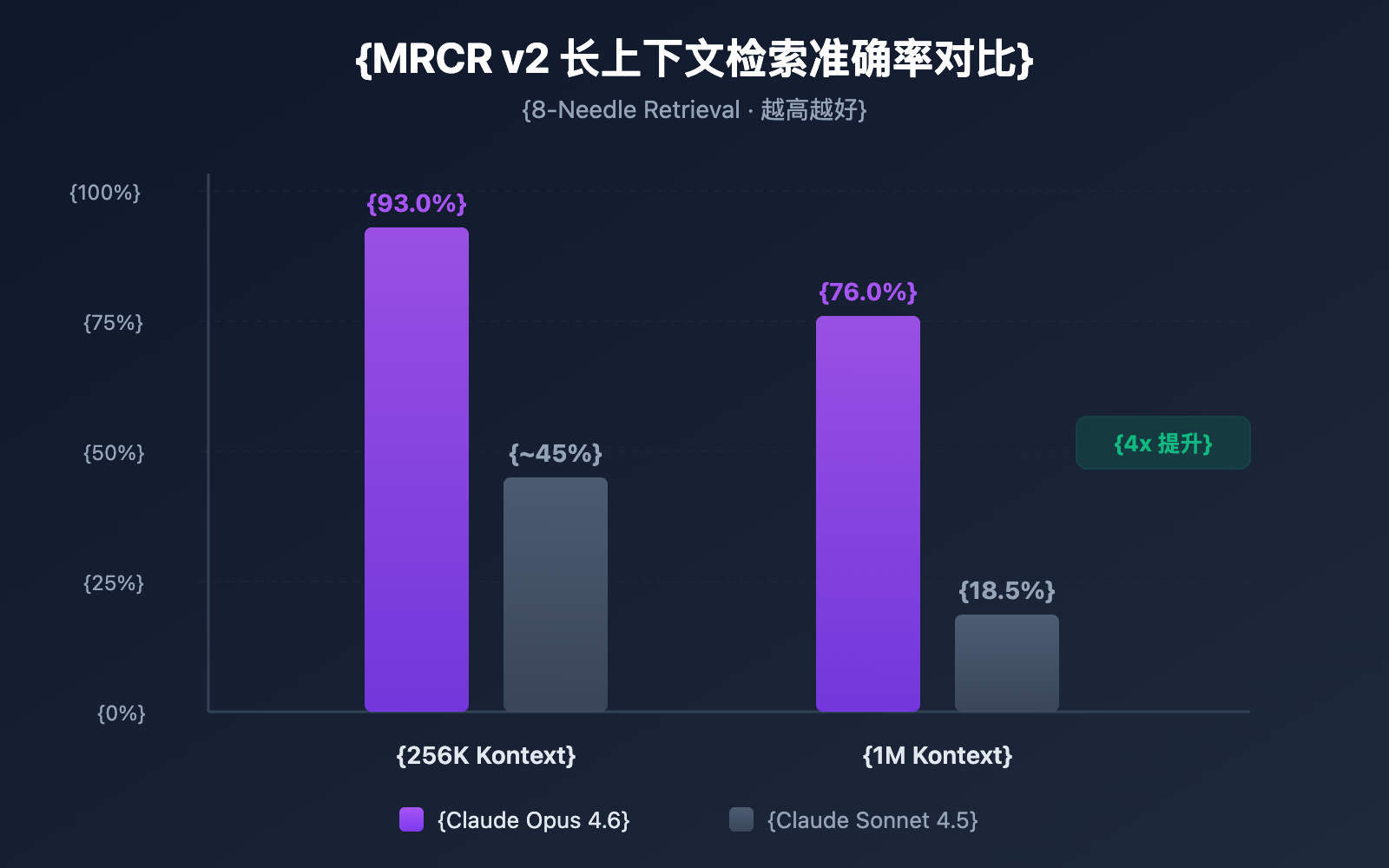
| MRCR v2 Benchmark (1M) | 76,0 % | 18,5 % | Ca. 4-fache Steigerung |
| MRCR v2 Benchmark (256K) | 93,0 % | — | Extrem hohe Genauigkeit |
| Empfohlener Denkmodus | Adaptive Thinking | — | Neues Feature |
🎯 Wichtige Info: Das 1M-Kontextfenster von Claude Opus 4.6 befindet sich derzeit in der Beta-Phase und muss über einen speziellen API-Header aktiviert werden. Standardmäßig wird weiterhin ein 200K-Kontextfenster verwendet. Über die Plattform APIYI (apiyi.com) können Sie die Modellleistung bei verschiedenen Kontextlängen schnell testen.
3 entscheidende Durchbrüche im Kontextfenster von Claude 4.6
Durchbruch 1: Opus-Serie unterstützt erstmals 1M Kontext
Vor Claude Opus 4.6 war das Kontextfenster von 1 Million Token ausschließlich den Modellen der Sonnet-Serie (Sonnet 4 und Sonnet 4.5) vorbehalten. Opus 4.6 ist das erste Opus-Flaggschiffmodell, das einen 1M-Kontext unterstützt. Das bedeutet, dass Sie nun die enorme Rechenleistung von Opus mit einem riesigen Kontext kombinieren können.
Konkret entsprechen 1M Token in etwa:
| Inhaltstyp | Kapazität | Typische Szenarien |
|---|---|---|
| Reiner Text | ca. 750.000 Wörter | Vollständige technische Dokumentationsbibliotheken |
| Code | ca. 75.000+ Zeilen | Komplette Code-Repositories |
| PDF-Dokumente | Dutzende Forschungsarbeiten | Batch-Literaturübersichten |
| Chatverläufe | Hunderte von Gesprächsrunden | Beibehaltung extrem langer Sitzungen |
Durchbruch 2: Genauigkeit der Langkontext-Abfrage schießt in die Höhe
Ein großes Kontextfenster ist eine Sache, aber Informationen in diesem riesigen Fenster auch präzise zu finden, eine ganz andere. Claude Opus 4.6 zeigt im MRCR v2 (Multi-needle Retrieval with Contextual Reasoning) Benchmark beeindruckende Ergebnisse:
- 256K Token Kontext: Genauigkeit von 93,0 %
- 1M Token Kontext (8 Nadeln): Genauigkeit von 76,0 %
MRCR v2 ist ein „Nadel im Heuhaufen“-Test – dabei werden 8 Schlüsselinformationen in einem Text von 1 Million Token versteckt, und das Modell muss alle finden. Die Genauigkeit von 76 % bei Claude Opus 4.6 ist ein Quantensprung im Vergleich zu den 18,5 % von Sonnet 4.5, was einer Verbesserung der Zuverlässigkeit um das 4- bis 9-fache entspricht.
Durchbruch 3: Compaction-Mechanismus ermöglicht unendliche Dialoge
Claude Opus 4.6 führt den Compaction-Mechanismus (Kontext-Kompression) ein, eine serverseitige Funktion zur automatischen Zusammenfassung des Kontextes:
- Wenn ein Dialog das Limit des Kontextfensters erreicht, fasst die API frühere Gesprächsinhalte automatisch zusammen.
- Keine manuelle Verwaltung des Kontextes, keine Sliding Windows oder Kürzungsstrategien mehr erforderlich.
- Theoretisch werden damit Dialoge von unbegrenzter Länge unterstützt.
Dies ist besonders wertvoll für Agent-Workflows – in Szenarien mit zahlreichen Tool-Aufrufen und langen Schlussfolgerungsketten kann Compaction den Aufwand für die Aufrechterhaltung des Dialogstatus erheblich reduzieren.
So aktivieren Sie das Claude 4.6 Kontextfenster
Schritt 1: Account-Berechtigung prüfen
Das 1M-Token-Kontextfenster ist derzeit eine Beta-Funktion und nur für folgende Nutzer verfügbar:
- Organisationen im Usage Tier 4 oder höher.
- Organisationen mit benutzerdefinierten Rate Limits.
Sie können Ihren aktuellen Usage Tier-Level in der Anthropic Console einsehen.
Schritt 2: Beta-Header hinzufügen
Um das 1M-Kontextfenster zu aktivieren, müssen Sie einen spezifischen Beta-Header in Ihre API-Anfrage einfügen:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Aufruf über die einheitliche APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[
{"role": "user", "content": "Analysiere das folgende vollständige Code-Repository..."}
],
extra_headers={
"anthropic-beta": "context-1m-2025-08-07"
}
)
print(response.choices[0].message.content)
Wenn Sie das Anthropic SDK direkt verwenden, sieht die entsprechende curl-Anfrage wie folgt aus:
curl https://api.apiyi.com/v1/messages \
-H "x-api-key: $API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-6-20250205",
"max_tokens": 8192,
"messages": [
{"role": "user", "content": "Ihr extrem langer Textinhalt..."}
]
}'
🚀 Schnellstart: Wir empfehlen die Nutzung der Plattform APIYI (apiyi.com), um die Langkontext-Fähigkeiten von Claude Opus 4.6 schnell zu testen. Die Plattform bietet eine einheitliche API-Schnittstelle, sodass Sie nicht mehrere Anbieter einzeln anbinden müssen. Die Integration ist in 5 Minuten erledigt.
Schritt 3: Kontextfenster verifizieren
Nach dem Senden der Anfrage können Sie über das Feld usage in der Antwort die Anzahl der tatsächlich verwendeten Token bestätigen:
{
"usage": {
"input_tokens": 450000,
"output_tokens": 2048
}
}
Wenn input_tokens 200.000 übersteigt und die Anfrage erfolgreich war, wurde das 1M-Kontextfenster korrekt aktiviert.
Vollständiges Python-Codebeispiel anzeigen (inkl. Token-Statistik)
import openai
import tiktoken
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
# Einlesen einer großen Codebase-Datei
with open("full_codebase.txt", "r") as f:
codebase_content = f.read()
print(f"Eingabelänge: {len(codebase_content)} Zeichen")
response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[
{
"role": "system",
"content": "Du bist ein erfahrener Experte für Code-Reviews. Bitte analysiere das gesamte Code-Repository."
},
{
"role": "user",
"content": f"Bitte analysiere das Architekturdesign und potenzielle Probleme des folgenden Code-Repositorys:\n\n{codebase_content}"
}
],
max_tokens=16384,
extra_headers={
"anthropic-beta": "context-1m-2025-08-07"
}
)
print(f"Input Token: {response.usage.prompt_tokens}")
print(f"Output Token: {response.usage.completion_tokens}")
print(f"\nAnalyseergebnis:\n{response.choices[0].message.content}")
Claude 4.6 Kontextfenster: Preisgestaltung im Detail
Die Nutzung des 1M-Kontextfensters unterliegt einem gestaffelten Preismodell. Sobald eine Anfrage 200.000 Token überschreitet, wird automatisch auf die Long-Context-Preise umgestellt:
| Preisstufe | Eingabepreis (pro Mio. Token) | Ausgabepreis (pro Mio. Token) | Geltungsbereich |
|---|---|---|---|
| Standardpreise | $5.00 | $25.00 | ≤ 200K Token |
| Long-Context-Preise | $10.00 | $37.50 | > 200K Token |
| Preismultiplikator | 2x | 1.5x | Automatische Anwendung |
Beispiel für die Preisberechnung
Angenommen, Sie senden eine Analyseanfrage für einen langen Text mit 500.000 Token und erhalten eine Antwort mit 4.000 Token:
- Eingabekosten: 500K × ($10.00 / 1M) = $5.00
- Ausgabekosten: 4K × ($37.50 / 1M) = $0.15
- Gesamtkosten pro Anfrage: $5.15
💰 Tipp zur Kostenoptimierung: Für Projekte, die eine häufige Nutzung langer Kontexte erfordern, können Sie die Claude Opus 4.6 API über die Plattform APIYI (apiyi.com) aufrufen. Die Plattform bietet flexible Abrechnungsmodelle und günstigere Konditionen, die kleinen und mittleren Teams helfen, ihre Kosten effektiv zu kontrollieren.
Kosten senken durch Context Caching
Wenn Ihr Anwendungsszenario wiederholte Abfragen derselben Dokumente beinhaltet (z. B. bei "Chat mit Dokumenten"-Anwendungen), können Sie die Context-Caching-Funktion nutzen:
- Der erste Dokument-Upload wird zum Standardpreis abgerechnet.
- Nachfolgende Abfragen auf Basis der zwischengespeicherten Inhalte profitieren von Rabattpreisen.
- Ideal für Szenarien mit hoher Frequenz wie Batch-Dokumentanalysen oder Wissensdatenbank-Q&A.
Best Practices zur Kostenkontrolle beim Claude 4.6 Kontextfenster
| Optimierungsstrategie | Beschreibung | Erwartete Ersparnis |
|---|---|---|
| 1M nach Bedarf | Beta-Header nur aktivieren, wenn wirklich ein extrem langer Kontext nötig ist | Vermeidung des 2x Eingabe-Aufschlags |
| Context Caching | Cache für Dokumente bei wiederkehrenden Abfragen nutzen | 40-60 % der Eingabekosten |
| Eingaben vorfiltern | Unnötige Inhalte (Kommentare, Leerzeilen etc.) vor dem Upload entfernen | 10-30 % Token-Verbrauch |
| Schichtenstrategie | Sonnet für einfache Aufgaben, Opus für komplexe Aufgaben nutzen | Gesamtkosten um 50 %+ senken |
| Ausgabelänge steuern | Sinnvolle max_tokens setzen, um redundante Ausgaben zu vermeiden |
Reduzierung der Ausgabekosten |
5 Praxisbeispiele für das Claude 4.6 Kontextfenster

Szenario 1: Analyse vollständiger Code-Repositories
Eingabegröße: 50.000 bis 75.000 Zeilen Code (ca. 400K-600K Token)
Dies ist das Szenario, das am unmittelbarsten vom 1M-Kontextfenster profitiert. Indem Sie den gesamten Quellcode eines Projekts auf einmal an Claude Opus 4.6 übermitteln, können Sie Folgendes erreichen:
- Globale Architekturprüfung: Identifizierung von Designproblemen über verschiedene Module hinweg.
- Abhängigkeitsanalyse: Aufspüren von zirkulären Abhängigkeiten und zu starker Kopplung.
- Sicherheits-Scans: Entdeckung von dateiübergreifenden Sicherheitsrisiken im vollständigen Kontext.
- Refactoring-Vorschläge: Erarbeitung von Refactoring-Plänen basierend auf einem globalen Verständnis.
Früher mussten Entwickler große Repositories in Fragmente zerlegen, was dazu führte, dass das Modell dateiübergreifende Abhängigkeiten nicht verstehen konnte. Jetzt können Sie den Kerncode eines gesamten Monorepos auf einmal einreichen und Claude wie einen Architekten agieren lassen, der das gesamte System versteht.
Szenario 2: Batch-Literaturübersichten
Eingabegröße: 20-30 wissenschaftliche Paper (ca. 500K-800K Token)
Forscher können dutzende relevante Paper gleichzeitig eingeben, um Claude folgende Aufgaben erledigen zu lassen:
- Querverweis-Analyse: Identifizierung von Zitierbeziehungen und widersprüchlichen Standpunkten zwischen den Papern.
- Zusammenfassung von Forschungstrends: Extraktion der methodischen Entwicklung aus einer großen Menge an Literatur.
- Gap-Analyse: Aufspüren von Forschungslücken in bestehenden Studien.
- Unterstützung bei Meta-Analysen: Horizontaler Vergleich von Versuchsdesigns und Ergebnissen verschiedener Studien.
Das manuelle Lesen von 30 Papern kann Wochen dauern. Mit dem 1M-Kontextfenster lassen sich die Vorauswahl und die Extraktion von Schlüsselinformationen in wenigen Minuten erledigen, was die Effizienz der Literaturrecherche massiv steigert.
Szenario 3: Q&A für Unternehmens-Wissensdatenbanken
Eingabegröße: Vollständige Produktdokumentation (ca. 300K-500K Token)
Laden Sie die gesamte interne Dokumentation in den Kontext, um Folgendes zu ermöglichen:
- Präzise Antworten: Fundierte Antworten basierend auf der gesamten Wissensbasis.
- Dokumentübergreifende Verknüpfungen: Entdeckung von Informationszusammenhängen zwischen verschiedenen Dokumenten.
- Echtzeit-Aktualisierungen: Keine Notwendigkeit für Vorverarbeitung oder Vektorisierung; nutzen Sie direkt die aktuellsten Dokumente.
- Logisches Schließen über mehrere Dokumente: Beantwortung komplexer Fragen durch Kombination technischer Details aus verschiedenen Quellen.
Im Vergleich zu herkömmlichen RAG-Lösungen (Retrieval-Augmented Generation) spart der Ansatz mit vollständigem Kontext den technischen Aufwand für Vektorisierung, Indexierung und Retrieval-Optimierung. Für kleine bis mittlere Wissensdatenbanken bis zu 1M Token ist die direkte Nutzung des langen Kontexts die einfachere und effizientere Lösung.
Szenario 4: Erstellung und Bearbeitung langer Inhalte
Eingabegröße: Vollständige Manuskripte oder Buchreihen (ca. 200K-400K Token)
- Konsistenzprüfung: Sicherstellung der logischen Konsistenz über lange Texte hinweg.
- Stilistische Einheitlichkeit: Beibehaltung eines konsistenten Sprachstils im gesamten Kontext.
- Strukturoptimierung: Vorschläge zur Anpassung von Kapiteln basierend auf dem Verständnis des Gesamtwerks.
- Terminologie-Standardisierung: Vereinheitlichung von Fachbegriffen im gesamten Buch.
Ein technisches Buch mit 200.000 Wörtern entspricht etwa 300K Token. Es ist nun möglich, Claude das gesamte Manuskript in einer einzigen Anfrage prüfen zu lassen, um Widersprüche aufzudecken.
Szenario 5: Komplexe Agent-Workflows
Eingabegröße: Protokolle mehrstufiger Tool-Aufrufe (kumuliert 300K-700K Token)
In Kombination mit den Agent-Teams-Funktionen von Claude 4.6:
- Langkettiges logisches Schließen: Aufrechterhaltung der vollständigen Argumentationskette bei komplexen, mehrstufigen Aufgaben.
- Gedächtnis für Tool-Aufrufe: Speicherung aller historischen Ergebnisse von Tool-Interaktionen.
- Kombination mit Compaction: Automatische Komprimierung des Kontexts bei extrem langen Workflows.
- Multi-Agent-Kollaboration: Gemeinsame Nutzung von Kontextinformationen innerhalb von Agent-Teams.
Agent-Workflows sind einer der Kernanwendungsbereiche von Claude Opus 4.6. Bei der Ausführung komplexer Aufgaben (wie automatisierte Code-Reviews oder Datenanalyse-Pipelines) muss ein Agent unter Umständen dutzende Tools aufrufen. Jede Eingabe und Ausgabe summiert sich im Kontext. Das 1M-Fenster stellt sicher, dass der Agent auch bei lang laufenden Aufgaben keine frühen Schlüsselinformationen "vergisst".
🎯 Praxistipp: Alle oben genannten Szenarien lassen sich schnell über die Plattform APIYI (apiyi.com) testen. Die Plattform unterstützt eine Vielzahl führender Modelle, einschließlich Claude Opus 4.6, und bietet eine einheitliche API-Erfahrung für den flexiblen Wechsel zwischen verschiedenen Anwendungsfällen.
Claude 4.6 Kontextfenster und Wettbewerbsvergleich
Um die Wettbewerbsfähigkeit von Claude Opus 4.6 im Bereich langer Kontexte zu verstehen, hilft ein Vergleich bei der fundierten Technologieauswahl:
| Modell | Kontextfenster | Max. Output | Long-Context-Retrieval-Performance | Preisgestaltung (Input/Output) |
|---|---|---|---|---|
| Claude Opus 4.6 | 1M (Beta) | 128K | MRCR 76.0% (1M) | $5-10 / $25-37.5 |
| Claude Sonnet 4.5 | 1M (Beta) | 64K | MRCR 18.5% (1M) | $3 / $15 |
| GPT-4.1 | 1M | 32K | — | $2 / $8 |
| Gemini 2.5 Pro | 1M | 65K | — | $1.25-2.5 / $10-15 |
| Gemini 2.5 Flash | 1M | 65K | — | $0.15-0.3 / $0.6-2.4 |
Wie man sieht, bietet Claude Opus 4.6 deutliche Vorteile bei der Genauigkeit der Abfrage in langen Kontexten. Obwohl die Preise höher angesetzt sind, übertrifft seine Zuverlässigkeit in Szenarien, die präzises Retrieval und komplexe Schlussfolgerungen erfordern, die der Konkurrenz bei weitem.
💡 Wahl-Empfehlung: Die Entscheidung für ein Modell hängt primär von Ihren spezifischen Anforderungen ab. Wenn die Qualität der Schlussfolgerungen (Reasoning) bei langen Kontexten Priorität hat, ist Claude Opus 4.6 derzeit die beste Wahl. Wir empfehlen praktische Vergleichstests über die Plattform APIYI (apiyi.com), die ein einheitliches Interface für alle oben genannten Modelle bietet und so einen schnellen Wechsel und eine einfache Evaluierung ermöglicht.
Claude 4.6 Kontextfenster: Compaction-Konfiguration
Compaction ist eine neue serverseitige Kontext-Komprimierungsfunktion von Claude Opus 4.6, die es ermöglicht, Konversationen theoretisch unendlich fortzuführen.
Funktionsweise
- Die API überwacht den Token-Verbrauch jeder Dialogrunde.
- Wenn die Input-Token einen festgelegten Schwellenwert überschreiten, wird automatisch eine Zusammenfassung ausgelöst.
- Das Modell generiert eine Zusammenfassung des Dialogs, die in
<summary>-Tags eingeschlossen ist. - Die Zusammenfassung ersetzt frühere Dialoginhalte, um Platz im Kontextfenster freizugeben.
Konfigurationsmethode
Fügen Sie den Parameter compaction_control in der API-Anfrage hinzu:
response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=conversation_history,
extra_body={
"compaction_control": {
"enabled": True,
"trigger_tokens": 150000 # 触发阈值
}
},
extra_headers={
"anthropic-beta": "context-1m-2025-08-07"
}
)
Strategien für das Zusammenspiel von Compaction und 1M-Kontext
| Strategie | Kontextfenster | Compaction | Anwendungsbereiche |
|---|---|---|---|
| Massive Einzelanalyse | 1M (vollständig) | Deaktiviert | Code-Reviews, Literaturübersichten |
| Langzeit-Konversationen | 200K (Standard) | Aktiviert | Kundenservice, Assistenten, Agenten |
| Hybrid-Modus | 1M + Compaction | Aktiviert | Hochkomplexe Agent-Workflows |
Häufig gestellte Fragen
Q1: Ist das Kontextfenster von Claude 4.6 standardmäßig auf 1M eingestellt?
Nein. Das Standard-Kontextfenster von Claude Opus 4.6 beträgt weiterhin 200K Token, genau wie bei der Vorgängergeneration Opus 4.5. Um das 1M-Token-Kontextfenster zu nutzen, muss im API-Request der Header anthropic-beta: context-1m-2025-08-07 hinzugefügt werden. Zudem muss Ihre Organisation das Usage Tier 4 erreicht haben oder über benutzerdefinierte Ratelimits verfügen. Bei Aufrufen über die Plattform APIYI (apiyi.com) lässt sich dieser Header bequem in den Request integrieren.
Q2: Fallen für die Nutzung des 1M-Kontextfensters zusätzliche Kosten an?
Ja, es gibt eine gestaffelte Preisgestaltung (Tiered Pricing). Wenn ein Request 200K Token überschreitet, steigt der Preis für den Input von 5 $/M auf 10 $/M (Faktor 2) und der Preis für den Output von 25 $/M auf 37,50 $/M (Faktor 1,5). Für budgetsensible Projekte empfiehlt es sich, über die Plattform APIYI (apiyi.com) günstigere Preiskonditionen zu beziehen.
Q3: Können spezifische Informationen innerhalb eines 1M-Kontexts präzise gefunden werden?
Claude Opus 4.6 zeigt im MRCR v2 Benchmark eine hervorragende Leistung. In einem Test-Szenario, bei dem 8 Schlüsselinformationen in einem Kontext von 1M Token versteckt wurden, erreichte das Modell eine Genauigkeit von 76 % – das ist etwa viermal so hoch wie bei Sonnet 4.5 (18,5 %). In einem Kontext von 256K liegt die Genauigkeit sogar bei 93 %. Damit ist Claude Opus 4.6 eines der derzeit zuverlässigsten Modelle für die Informationsabfrage in langen Kontexten (Long Context Retrieval).
Q4: Beeinflusst „Compaction“ die Antwortqualität?
Compaction nutzt intelligente Zusammenfassungen, um frühere Gesprächsinhalte zu komprimieren. In den meisten Szenarien wird die Antwortqualität dadurch nicht nennenswert beeinträchtigt. Für Anwendungsfälle, die präzise Zitate aus frühen Dialogdetails erfordern, wird jedoch empfohlen, Compaction zu deaktivieren und direkt das 1M-Kontextfenster zu nutzen. In Agent-Workflows kann Compaction die Effizienz erheblich steigern und wird daher zur Aktivierung empfohlen.
Q5: Welche Claude-Modelle unterstützen den 1M-Kontext?
Derzeit unterstützen drei Claude-Modelle ein Kontextfenster von 1M Token: Claude Opus 4.6, Claude Sonnet 4.5 und Claude Sonnet 4. Dabei ist die Genauigkeit bei der Abfrage langer Kontexte bei Opus 4.6 deutlich höher als bei der Sonnet-Serie. Andere Modelle, wie die Claude Haiku-Serie, unterstützen den 1M-Kontext derzeit nicht.
Zusammenfassung
Das 1M-Token-Kontextfenster von Claude Opus 4.6 ist ein bedeutendes Upgrade. Es kombiniert die starken Reasoning-Fähigkeiten des Opus-Flaggschiffmodells mit einem riesigen Kontext und ermöglicht so hochwertige Anwendungsszenarien wie die Analyse vollständiger Code-Repositories, umfassende Literaturübersichten oder Q&A-Systeme für Unternehmens-Wissensdatenbanken.
Die wichtigsten Punkte im Überblick:
- Standard 200K, Beta-Erweiterung auf 1M: Erfordert den Header
anthropic-beta: context-1m-2025-08-07. - Branchenführende Genauigkeit bei Long Context Retrieval: MRCR v2 Benchmark 76 % (1M) / 93 % (256K).
- Gestaffelte Preise: Für den Teil über 200K gilt der 2-fache Input-Preis und der 1,5-fache Output-Preis.
- Compaction unterstützt unbegrenzte Dialoge: Serverseitige automatische Kontextkomprimierung, ideal für Agent-Workflows.
- 3 unterstützte Modelle: Opus 4.6, Sonnet 4.5, Sonnet 4.
Wir empfehlen, die Long-Context-Fähigkeiten von Claude Opus 4.6 schnell und unkompliziert über APIYI (apiyi.com) auszuprobieren. Die Plattform unterstützt den Zugriff auf verschiedene gängige Großes Sprachmodelle über eine einheitliche Schnittstelle und hilft Entwicklern dabei, technische Validierungen und Produktintegrationen effizient umzusetzen.
Dieser Artikel wurde vom APIYI Team verfasst, das sich auf den Wissensaustausch rund um die Technologie großer Sprachmodelle spezialisiert hat. Weitere Tutorials und API-Leitfäden finden Sie im APIYI Help Center: help.apiyi.com
Referenzen
-
Offizieller Anthropic-Blog – Introducing Claude Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Beschreibung: Ankündigung der Veröffentlichung von Claude Opus 4.6 und Vorstellung der Kernfunktionen
- Link:
-
Claude API-Dokumentation – Context Windows
- Link:
platform.claude.com/docs/en/build-with-claude/context-windows - Beschreibung: Leitfaden zur Konfiguration und Nutzung von Kontextfenstern
- Link:
-
Claude API-Dokumentation – Compaction
- Link:
platform.claude.com/docs/en/build-with-claude/compaction - Beschreibung: Detaillierte Erläuterung der Compaction-Funktion zur Kontextkomprimierung
- Link:
-
Claude API-Dokumentation – Pricing
- Link:
platform.claude.com/docs/en/about-claude/pricing - Beschreibung: Modellpreise und Erläuterungen zur Preisgestaltung für lange Kontexte
- Link: