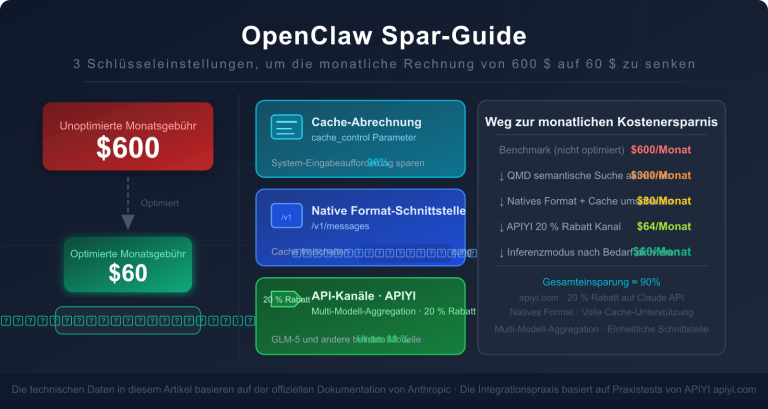
Anmerkung des Autors: Tiefenanalyse der 6 Hauptgründe für den hohen Token-Verbrauch von OpenClaw, inklusive praxiserprobter Optimierungsstrategien, mit denen Benutzer ihre API-Kosten um 60–80 % senken können. Inklusive Sparplan durch APIYI-Aufladeboni.
„1,8 Millionen Token in einem Monat verbrannt, Rechnung 3600 Dollar“ – das ist die reale Erfahrung des Tech-Bloggers Federico Viticci mit OpenClaw. OpenClaw ist zwar quelloffen und kostenlos, aber die Geschwindigkeit des Token-Verbrauchs hat viele Nutzer unvorbereitet getroffen. In diesem Artikel analysieren wir die 6 Hauptgründe für den hohen Token-Hunger von OpenClaw und liefern praxiserprobte Strategien zum Geldsparen.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die technischen Prinzipien hinter dem hohen Verbrauch von OpenClaw verstehen, 6 effektive Optimierungsmethoden beherrschen und erfahren, wie Sie die Kosten durch APIYI-Aufladeaktionen auf unter 90 % des offiziellen Preises senken können.
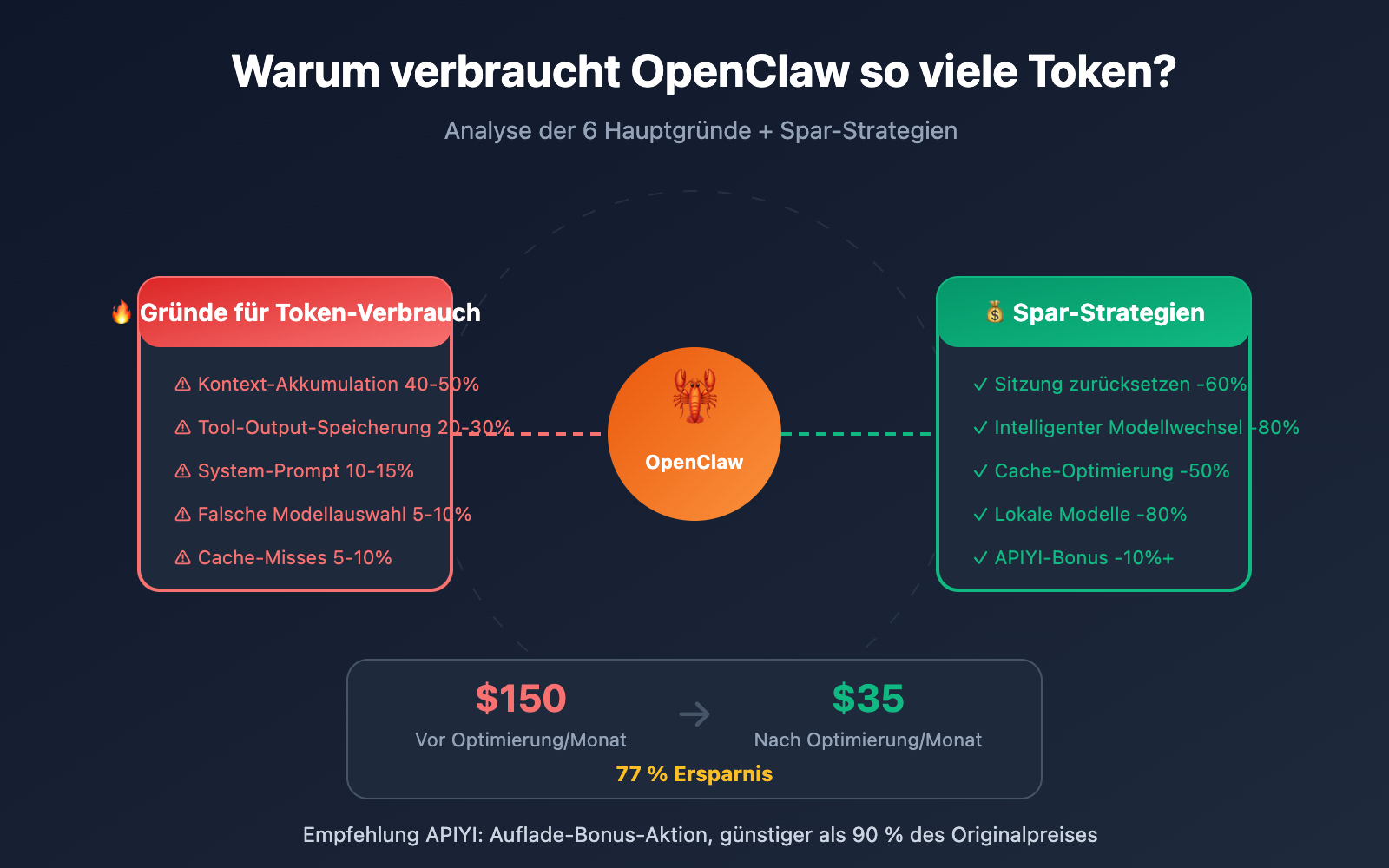
Kerndaten zum Token-Verbrauch von OpenClaw
| Benutzertyp | Durchschn. Token/Monat | Durchschn. Kosten | Typisches Szenario |
|---|---|---|---|
| Gelegenheitsnutzer | 5 Mio. – 20 Mio. | $10-30 | Alltagsfragen, einfache Aufgaben |
| Durchschnittsnutzer | 20 Mio. – 50 Mio. | $30-70 | Automatisierte Workflows |
| Power-User | 50 Mio. – 200 Mio. | $70-150+ | Rund-um-die-Uhr-Assistent |
| Extremfall | 180 Mio.+ | $3600+ | MacStories Blogger-Test |
Warum ist der Token-Verbrauch von OpenClaw so hoch?
OpenClaw (ehemals Clawdbot/Moltbot) ist das angesagteste Open-Source-KI-Assistentenprojekt des Jahres 2026 mit über 135.000 Sternen auf GitHub. Es ist extrem leistungsfähig: Es kann mit über 12 Messaging-Plattformen verbunden werden, Browser steuern, Shell-Befehle ausführen und den Alltag automatisieren. Doch hinter dieser Power verbirgt sich ein enormer Token-Verbrauch.
Viele Nutzer sind begeistert, wenn sie OpenClaw eingerichtet haben, nur um am nächsten Tag schockiert auf ihre API-Rechnung zu blicken – oft sind es zweistellige oder gar dreistellige Dollarbeträge. Ein Nutzer berichtete, „200 Dollar an einem Tag verbrannt“ zu haben, weil eine automatisierte Aufgabe in eine Endlosschleife geraten war.
Das Verständnis der Ursachen für den Token-Verbrauch ist der erste Schritt zur Kostenoptimierung.
Die 6 Hauptgründe für den Token-Hunger von OpenClaw
| Grund | Anteil am Verbrauch | Technische Erklärung | Optimierungspotenzial |
|---|---|---|---|
| Kontext-Akkumulation | 40-50% | Der Sitzungsverlauf wächst kontinuierlich an | ⭐⭐⭐⭐⭐ |
| Tool-Output-Speicherung | 20-30% | Große JSONs/Logs werden im Verlauf gespeichert | ⭐⭐⭐⭐ |
| System-Prompt | 10-15% | Wird bei jeder Anfrage erneut gesendet | ⭐⭐⭐ |
| Multi-Turn-Inferenz | 10-15% | Komplexe Aufgaben erfordern mehrere Aufrufe | ⭐⭐ |
| Modellauswahl | 5-10% | Opus ist 25-mal teurer als Haiku | ⭐⭐⭐⭐⭐ |
| Cache-Misses | 5-10% | Abgelaufener Cache führt zu Neuberechnung | ⭐⭐⭐⭐ |
OpenClaw Token-Verbrauch: Eine Tiefenanalyse der Ursachen
Grund 1: Kontinuierliche Akkumulation des Kontextfensters
Dies ist OpenClaws größtes „Kostengrab“. Jedes Mal, wenn Sie mit OpenClaw interagieren, werden alle historischen Nachrichten in einer JSONL-Datei im Verzeichnis .openclaw/agents.main/sessions/ gespeichert.
Das Problem dabei: Bei jeder neuen Anfrage sendet OpenClaw den vollständigen Sitzungsverlauf an das KI-Modell.
Ein Nutzer berichtete, dass sein Hauptsitzungs-Kontext bereits 56–58 % eines 400K-Fensters einnimmt. Das bedeutet:
- Selbst bei einer einfachen Frage müssen über 200.000 Token an Cache-Kontext verarbeitet werden.
- Jeder
cacheReadliegt im Bereich von Hunderttausenden von Token. - Je länger die Sitzung dauert, desto exponentieller steigen die Kosten.
# Aktuellen Token-Verbrauch der Sitzung anzeigen
openclaw /status
# Beispiel für die Ergebnisanzeige:
# 🤖 Model: claude-sonnet-4
# 📊 Context: 234,567 / 400,000 tokens (58.6%)
# 💰 Estimated cost this session: $12.34
Grund 2: Unbegrenzte Speicherung von Tool-Outputs
OpenClaw speichert alle Ausgaben von Tool-Aufrufen im Sitzungsprotokoll. Bei folgenden Aktionen wird es problematisch:
| Gefährliche Operation | Output-Größe | Konsequenz |
|---|---|---|
config.schema |
Zehntausende Token | Riesiges JSON landet im Kontext |
status --all |
Tausende Token | Vollständiges Protokoll des Systemstatus |
Verzeichnis-Scan find |
Zehntausende Token | Liste aller Dateien wird gespeichert |
| Log-Export | Zehntausende Token | Komplette Logs fließen in das Protokoll ein |
Ein Entwickler erzählt: „Ich wollte nur, dass OpenClaw mir die Projektstruktur zeigt. Es hat das gesamte Verzeichnis durchscannt und zehntausende Zeilen Dateilisten ausgegeben, die alle in der Sitzung gespeichert wurden. Danach musste diese nutzlose Information bei jedem weiteren Dialog erneut an das Modell gesendet werden.“
Grund 3: System-Prompt wird jedes Mal neu gesendet
OpenClaw nutzt eine komplexe System-Eingabeaufforderung, die Folgendes umfasst:
- Kern-Persönlichkeitseinstellungen
- Liste der verfügbaren Tools
- Sicherheitsregeln und Einschränkungen
- Benutzerpräferenzen
Diese System-Eingabeaufforderung umfasst normalerweise 5.000 bis 10.000 Token, die bei jedem API-Aufruf mitgesendet werden. Anthropic bietet zwar Prompt-Caching an (Cache-Treffer kosten nur 10 %), aber der Cache hat ein TTL-Limit (Time To Live):
| Anbieter | Cache TTL | Folge bei Ablauf |
|---|---|---|
| Anthropic | 5 Minuten | Erneute Abrechnung zum vollen Preis |
| OpenAI | 1 Stunde | Automatischer Ablauf |
Wenn Sie OpenClaw nicht kontinuierlich nutzen, zahlen Sie bei jedem „Kaltstart“ den vollen Preis.
Grund 4: Mehrstufiges Reasoning bei komplexen Aufgaben
Die Stärke von OpenClaw liegt in der autonomen Erledigung komplexer Aufgaben, was jedoch mehr API-Aufrufe bedeutet:
Nutzer: Hilf mir, meine heutigen E-Mails zu sortieren und To-dos zu erstellen.
Interner OpenClaw-Prozess:
1. Aufruf des E-Mail-Skills zum Abrufen der Liste → Token-Verbrauch
2. Analyse jedes E-Mail-Inhalts → Token-Verbrauch
3. Bewertung von Priorität und Kategorie → Token-Verbrauch
4. Aufruf des Todoist-Skills zum Erstellen von Aufgaben → Token-Verbrauch
5. Erstellung eines Zusammenfassungsberichts → Token-Verbrauch
Tatsächlicher Verbrauch: 5–10 API-Aufrufe, jeder mit dem kompletten Kontext.
Grund 5: Ungeeignete Modellauswahl
Viele Nutzer verwenden standardmäßig Claude Opus 4.5 oder Sonnet 4.5, aber nicht jede Aufgabe benötigt ein High-End-Modell:
| Modell | Eingabepreis | Ausgabepreis | Anwendungsfall |
|---|---|---|---|
| Claude Opus 4.5 | $15/M | $75/M | Komplexes Reasoning, kreatives Schreiben |
| Claude Sonnet 4.5 | $3/M | $15/M | Alltagsaufgaben, Code-Generierung |
| Claude Haiku 4.5 | $1/M | $5/M | Einfache Fragen, Formatkonvertierung |
| Gemini 3.0 Flash | $0.075/M | $0.30/M | Stapelverarbeitung, kostensensibel |
Der Preisunterschied beträgt bis zum 25-fachen! Opus zu fragen, wie das Wetter heute ist, ist reine Verschwendung.
Grund 6: Heartbeat und Hintergrundaufgaben
Die Heartbeat-Funktion von OpenClaw erlaubt es der KI, aktiv zu werden, um geplante Aufgaben auszuführen. Viele Nutzer wissen jedoch nicht:
- Jeder Heartbeat-Trigger ist ein vollständiger API-Aufruf.
- Bei falscher Konfiguration kann dies alle paar Minuten ausgelöst werden.
- Jeder Trigger sendet den vollständigen Sitzungskontext mit.
Ein Nutzer gab folgendes Feedback: „Ich hatte eingestellt, dass alle 5 Minuten die E-Mails geprüft werden. Am Ende des Tages hatte allein der Heartbeat 50 Dollar verbrannt.“
Die 6 besten Strategien zur OpenClaw Token-Optimierung
Strategie 1: Regelmäßiges Zurücksetzen der Sitzung (40–60 % Ersparnis)
Dies ist die effektivste Methode. Wenn der Sitzungskontext zu groß wird, setzen Sie ihn konsequent zurück:
# Methode 1: Innerhalb des Dialogs zurücksetzen
openclaw "reset session"
# Methode 2: Sitzungsdateien löschen
rm -rf ~/.openclaw/agents.main/sessions/*.jsonl
# Methode 3: Komprimierung mit dem /compact Befehl
openclaw /compact
Best Practice: Setzen Sie die Sitzung nach jeder abgeschlossenen Aufgabe zurück, damit sich der Kontext nicht unendlich ansammelt.
Strategie 2: Isolierung von Operationen mit großem Output (20–30 % Ersparnis)
Führen Sie niemals Befehle, die große Ausgaben erzeugen könnten, in der Hauptsitzung aus:
# ❌ Falsch: Ausführung in der Hauptsitzung
openclaw "Zeige die komplette Systemkonfiguration"
# ✅ Richtig: Nutzung einer separaten Debug-Sitzung
openclaw --session debug "Zeige die komplette Systemkonfiguration"
# Kopieren Sie dann nur das benötigte Fragment in die Hauptsitzung.
Strategie 3: Konfiguration eines intelligenten Modell-Switching (50–80 % Ersparnis)
Wählen Sie das Modell automatisch basierend auf der Komplexität der Aufgabe:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4",
"fallback": "anthropic/claude-haiku-4"
}
}
},
"routing": {
"simple_queries": "haiku",
"complex_tasks": "sonnet",
"critical_decisions": "opus"
}
}
🎯 Spartipp: Nutzen Sie Haiku oder Gemini Flash für Alltagsaufgaben und wechseln Sie nur für komplexes Reasoning zu Sonnet oder Opus. Über APIYI (apiyi.com) erhalten Sie Zugriff auf über 400 große Sprachmodelle über eine einzige Schnittstelle und können flexibel wechseln, um das beste Preis-Leistungs-Verhältnis zu finden.
Strategie 4: Aktivierung der Cache-Optimierung (30–50 % Ersparnis)
Nutzen Sie den Prompt-Caching-Mechanismus voll aus:
{
"agents": {
"defaults": {
"cache-ttl": 3600,
"temperature": 0.2
}
}
}
Wichtige Tipps:
- Eine niedrige Temperatur (0.2) erhöht die Cache-Trefferquote.
- Konfigurieren Sie das Heartbeat-Intervall etwas kürzer als die Cache-TTL, um den Cache „warm“ zu halten.
- Nutzen Sie Dienste wie OpenRouter, die Caching unterstützen.
Strategie 5: Begrenzung des Kontextfensters (20–40 % Ersparnis)
Kontrollieren Sie die Kontextgröße aktiv:
{
"agents": {
"defaults": {
"contextTokens": 50000,
"compaction": "aggressive"
}
}
}
Indem Sie den Kontext auf 50K–100K Token begrenzen (statt der standardmäßigen 400K), senken Sie die Kosten pro Anfrage massiv.
Strategie 6: Nutzung lokaler Modelle als Fallback (60–80 % Ersparnis)
Konfigurieren Sie lokale Modelle über Ollama für einfache Aufgaben:
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434",
"models": ["llama3.3", "qwen2.5"]
}
}
},
"routing": {
"simple_queries": "ollama/llama3.3"
}
}
Lokale Modelle verursachen keine API-Kosten und eignen sich hervorragend für einfache Formatkonvertierungen oder Informationsabfragen.
OpenClaw Kostenoptimierung: Praxisvergleich
| Optimierungspunkt | Kosten vor Optimierung | Kosten nach Optimierung | Einsparungsrate |
|---|---|---|---|
| Sitzungsmanagement | 50 $/Monat | 20 $/Monat | 60 % |
| Modellwechsel | 80 $/Monat | 25 $/Monat | 69 % |
| Caching-Optimierung | 40 $/Monat | 20 $/Monat | 50 % |
| Lokales Fallback | 30 $/Monat | 5 $/Monat | 83 % |
| Gesamtoptimierung | 150 $/Monat | 35 $/Monat | 77 % |
Praxisdaten: Ein Power-User konnte durch diese Gesamtoptimierungen seine durchschnittlichen monatlichen Kosten von 150 $ auf 35 $ senken – eine Ersparnis von über 75 %.
Kosten weiter senken mit APIYI
Selbst nach Durchführung aller oben genannten Optimierungen bleiben die API-Aufrufkosten die Hauptausgabe bei der Nutzung von OpenClaw. Daher ist die Wahl des richtigen API-Anbieters von entscheidender Bedeutung.
APIYI Auflade-Bonusaktion
APIYI (apiyi.com) bietet eine einheitliche Schnittstelle für über 400 Große Sprachmodelle. Die Preise entsprechen denen der offiziellen Anbieter, aber durch Auflade-Bonusaktionen lassen sich die Kosten noch weiter drücken:
| Aufladebetrag | Bonusrate | Tatsächliches Guthaben | Entspricht Rabatt |
|---|---|---|---|
| 20 $ | 5 % | 21 $ | 9,5 % Rabatt |
| 50 $ | 8 % | 54 $ | 9,3 % Rabatt |
| 100 $ | 10 % | 110 $ | 9,1 % Rabatt |
| 200 $ | 12 % | 224 $ | 8,9 % Rabatt |
| 500 $+ | 15 % | 575 $+ | 8,7 % Rabatt |
Machen wir eine kurze Rechnung: Wenn Sie monatlich 100 $ für APIs ausgeben und bei APIYI 100 $ aufladen, erhalten Sie 10 % Bonus. Das entspricht einer Ersparnis von 10 $ pro Monat. Auf das Jahr gerechnet sind das 120 $ – genug, um ein Claude Pro Abonnement zu finanzieren.
Weitere Vorteile von APIYI
| Vorteil | Beschreibung | Wert für OpenClaw-Nutzer |
|---|---|---|
| 400+ Modelle | One-Stop-Zugang zu allen gängigen Modellen | Flexibler Wechsel, um das beste Preis-Leistungs-Verhältnis zu finden |
| Einheitliche Schnittstelle | OpenAI-kompatibles Format | Nahtlose Integration in OpenClaw |
| Echtzeit-Guthaben | Verbrauchsstatistiken auf den Cent genau | Kosten jederzeit im Blick behalten |
| Keine monatliche Gebühr | Pay-as-you-go, Abrechnung nach Verbrauch | Flexible Kostenkontrolle |
| Stabil und zuverlässig | Multi-Knoten-Lastverteilung | 24/7 Verfügbarkeit |
APIYI als OpenClaw-Backend konfigurieren
{
"models": {
"providers": {
"apiyi": {
"type": "openai",
"baseUrl": "https://vip.apiyi.com/v1",
"apiKey": "YOUR_APIYI_KEY",
"models": [
"claude-sonnet-4",
"claude-haiku-4",
"gpt-4o-mini",
"deepseek-v3"
]
}
}
},
"agents": {
"defaults": {
"model": "apiyi/claude-sonnet-4"
}
}
}
Nach Abschluss der Konfiguration werden alle API-Aufrufe von OpenClaw über APIYI geroutet, sodass Sie direkt von den Auflade-Boni profitieren.
Häufig gestellte Fragen
Q1: Kann man mit einem Claude Pro/Max-Abo bei OpenClaw Geld sparen?
Nein, und das verstößt zudem gegen die Nutzungsbedingungen von Anthropic. Claude Pro/Max-Abos sind ausschließlich für die Nutzung über die offizielle Weboberfläche gedacht und können nicht für API-Aufrufe von Drittanbietern verwendet werden. OpenClaw erfordert zwingend einen API-Key mit verbrauchsbasierter Abrechnung (Pay-as-you-go). Genau deshalb ist der Aufladebonus von APIYI so wertvoll – es ist der einzige legale Weg, Kosten zu senken.
Q2: Wie überwache ich den Token-Verbrauch in Echtzeit?
OpenClaw verfügt über integrierte Befehle zur Verbrauchsüberwachung:
# Aktuellen Status anzeigen
openclaw /status
# Anzeige des Verbrauchs für jede Antwort aktivieren
openclaw /usage full
In Kombination mit dem Echtzeit-Guthaben und den detaillierten Verbrauchsdaten im APIYI-Backend behalten Sie jeden Cent genau im Blick.
Q3: Wie viel lässt sich mit Gemini oder Deepseek sparen?
Im Vergleich zu Claude Sonnet ist der Kostenunterschied enorm:
| Modell | Preis pro Million Input-Token | Kostenvergleich |
|---|---|---|
| Claude Sonnet 4.5 | $3/M | Basis |
| Gemini 3.0 Flash | $0,075/M | 40-mal günstiger |
| Deepseek V3 | $0,27/M | 11-mal günstiger |
Über APIYI (apiyi.com) können Sie zentral auf all diese Modelle zugreifen und flexibel über eine einheitliche Schnittstelle zwischen ihnen wechseln.
Zusammenfassung
Die 6 Hauptgründe für hohen Token-Verbrauch bei OpenClaw:
- Kontext-Akkumulation: Die Gesprächshistorie wächst unaufhörlich an – das größte Kostengrab.
- Speicherung von Tool-Ausgaben: Umfangreiche Tool-Ergebnisse werden im Verlauf gespeichert und bei jedem neuen Dialog erneut gesendet.
- System Prompt: Komplexe Eingabeaufforderungen werden jedes Mal neu gesendet; bei abgelaufenem Cache wird der volle Preis berechnet.
- Mehrstufiges Reasoning: Komplexe Aufgaben erfordern mehrere aufeinanderfolgende API-Aufrufe.
- Falsche Modellauswahl: Nutzung von Opus für Aufgaben, die auch Haiku erledigen könnte.
- Häufige Heartbeats: Hintergrundaufgaben verbrauchen kontinuierlich Token.
Kernstrategien zum Sparen:
- Sitzungen regelmäßig zurücksetzen, um die Kontextgröße zu begrenzen.
- Intelligenter Modellwechsel: Einfache Aufgaben mit günstigen Modellen erledigen.
- Aufladeboni bei APIYI (apiyi.com) nutzen, um Preise zu erhalten, die mehr als 10 % unter den offiziellen Tarifen liegen.
Besuchen Sie APIYI (apiyi.com), um ein Konto zu registrieren. Die Plattform bietet eine einheitliche Schnittstelle für über 400 Modelle sowie attraktive Aufladeboni, damit Ihr OpenClaw-Setup sowohl leistungsstark als auch kosteneffizient bleibt.
📚 Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name: domain.com. Dies erleichtert das Kopieren, verhindert jedoch die direkte Verlinkung, um SEO-Gewicht-Verlust zu vermeiden.
-
OpenClaw Token-Nutzungsdokumentation: Offizielle Verbrauchshinweise
- Link:
docs.openclaw.ai/token-use - Beschreibung: Token-Abrechnungsregeln und Monitoring-Befehle
- Link:
-
GitHub Issue #1594: Diskussion über Kontext-Akkumulationsprobleme
- Link:
github.com/openclaw/openclaw/issues/1594 - Beschreibung: Tiefgehende Analyse der Community zum Problem des "Token-Burnings"
- Link:
-
Anthropic Preisgestaltungsseite: Offizielle Claude API-Preise
- Link:
anthropic.com/pricing - Beschreibung: Aktuelle Preise für alle Modelle und Caching-Rabatte
- Link:
-
Fast Company Bericht: OpenClaw Kostenanalyse
- Link:
fastcompany.com/91484506/what-is-clawdbot-moltbot-openclaw - Beschreibung: Medienberichterstattung über die hohen Kosten von OpenClaw
- Link:
-
APIYI Webseite: Zentraler Zugriff auf über 400 Modelle
- Link:
apiyi.com - Beschreibung: Auflade-Bonus-Aktionen, Preise über 10 % günstiger als auf der offiziellen Website
- Link:
Autor: Technik-Team
Technischer Austausch: Wir freuen uns auf Diskussionen im Kommentarbereich. Weitere Tipps zum Geldsparen finden Sie in der APIYI (apiyi.com) Technik-Community.