Autorennotiz: Detaillierte Erklärung, warum die Ausgabe-Token von Gemini 3.1 Pro Preview die sichtbare Textmenge bei weitem übersteigen: Denk-Token (Thinking Tokens) und Reasoning Chain-Mechanismus, Abrechnungsregeln, Tipps zum Sparen durch Anpassen des thinking_level-Parameters.
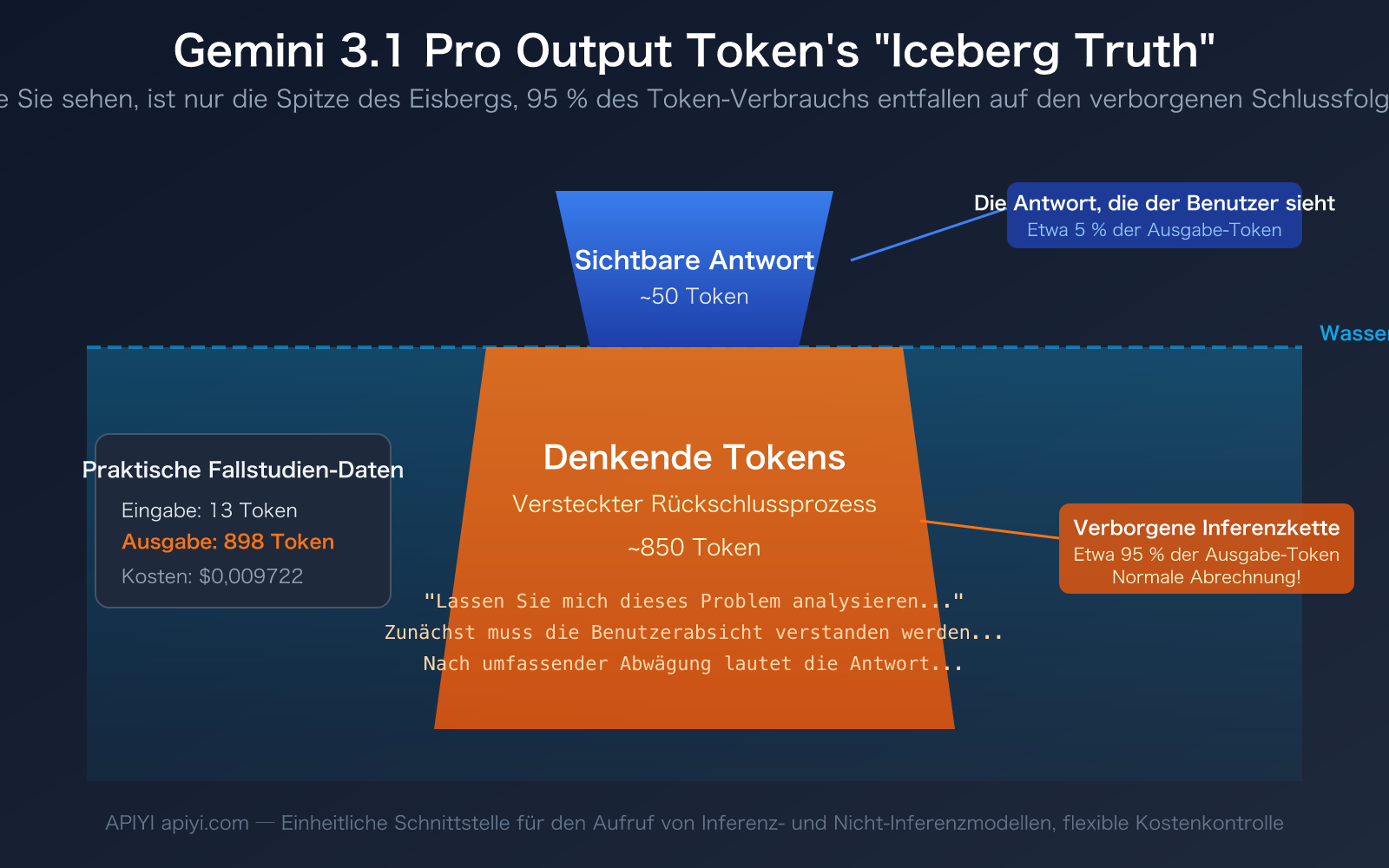
«Ich habe nur einen Satz geschickt, das Modell hat nur ein paar Worte zurückgegeben, warum zeigt es fast 900 Ausgabe-Token an? Wofür wurde das Geld ausgegeben?» – Das ist die echte Verwirrung vieler Entwickler bei der ersten Nutzung von Gemini 3.1 Pro Preview. Die Daten im Screenshot zeigen dieses Phänomen deutlich: 13 Eingabe-Token, aber satte 898 Ausgabe-Token.
Die Antwort sind Thinking Tokens (Denk-Token). Gemini 3.1 Pro ist ein Reasoning-Modell. Bevor es dir eine Antwort gibt, führt es intern einen umfangreichen Denk- und Schlussfolgerungsprozess durch. Dieser «Gedankengang» wird dir standardmäßig nicht angezeigt, fließt aber in die Ausgabe-Token ein und wird normal abgerechnet.
Kernnutzen: Nach dem Lesen dieses Artikels verstehst du den Thinking-Tokens-Mechanismus von Reasoning-Modellen vollständig und lernst, mit dem Parameter thinking_level die Reasoning-Tiefe zu steuern, um so bei gleicher Qualität 50-80% der Ausgabe-Token-Kosten einzusparen.
Kernpunkte zu Gemini 3.1 Pro Thinking Tokens
Der größte Unterschied zwischen Reasoning-Modellen und normalen Dialogmodellen liegt in der völlig anderen Zusammensetzung der Ausgabe-Token. Hier sind die zentralen Konzepte, die du verstehen musst:
| Punkt | Erklärung | Praktische Auswirkung |
|---|---|---|
| Ausgabe-Token = Denken + Antwort | Die Ausgabe-Token von Gemini 3.1 Pro enthalten Thinking Tokens (Reasoning Chain) und die tatsächliche Antwort. | Der sichtbare Text ist wenig, aber die Gesamt-Token-Anzahl ist hoch. |
| Thinking Tokens werden normal abgerechnet | Der Reasoning-Prozess ist zwar unsichtbar, wird aber zum Preis für Ausgabe-Token abgerechnet ($12/Million Token). | Ein einfaches Problem kann 5-10 mal mehr kosten als bei einem Standardmodell. |
thinking_level ist einstellbar |
Unterstützt drei Stufen zur Steuerung der Reasoning-Tiefe: LOW/MEDIUM/HIGH. | Stufe LOW kann über 80% der Ausgabe-Token einsparen. |
| Nicht-Reasoning-Modelle haben dieses Problem nicht | Modelle wie GPT-4o, Claude Sonnet 4.6 (mit deaktiviertem Extended Thinking) sind "was du siehst, ist was du bekommst". | Für einfache Aufgaben sind Nicht-Reasoning-Modelle kostengünstiger. |
Ein realer Fall des Thinking Tokens-Verbrauchs bei Gemini 3.1 Pro
Zurück zum Beispiel im Screenshot. Der Nutzer stellte eine einfache Frage, das Modell antwortete mit etwa einem Dutzend Wörtern, aber die Ausgabe-Token zeigten 891-898 an. Die Zusammensetzung dieser Token sieht ungefähr so aus:
- Sichtbare Antwort: ca. 30-50 Token (die Handvoll Wörter, die du siehst)
- Thinking Tokens: ca. 840-860 Token (der interne Reasoning-Prozess des Modells)
Das bedeutet, über 95% der Ausgabe-Token sind für dich unsichtbar. Sie wurden für die Reasoning Chain des Modells verbraucht. Es ist, als würdest du einen Mathelehrer fragen «Was ist 1+1?», der Lehrer sagt nur «2», aber in seinem Kopf denkt er: «Das ist eine Grundrechenaufgabe, die Addition erfordert…» – und du bezahlst für den gesamten Denkprozess des Lehrers.
Dieser Mechanismus ist kein Fehler, sondern ein Designmerkmal von Reasoning-Modellen. Der Grund, warum Gemini 3.1 Pro bei komplexen Problemen besser abschneidet (MATH-Benchmark 95,1%, ARC-AGI-2 77,1%), ist genau dieser tiefgehende Reasoning-Prozess vor der Antwort.
Funktionsweise der Thinking Tokens im Gemini 3.1 Pro Reasoning-Modell
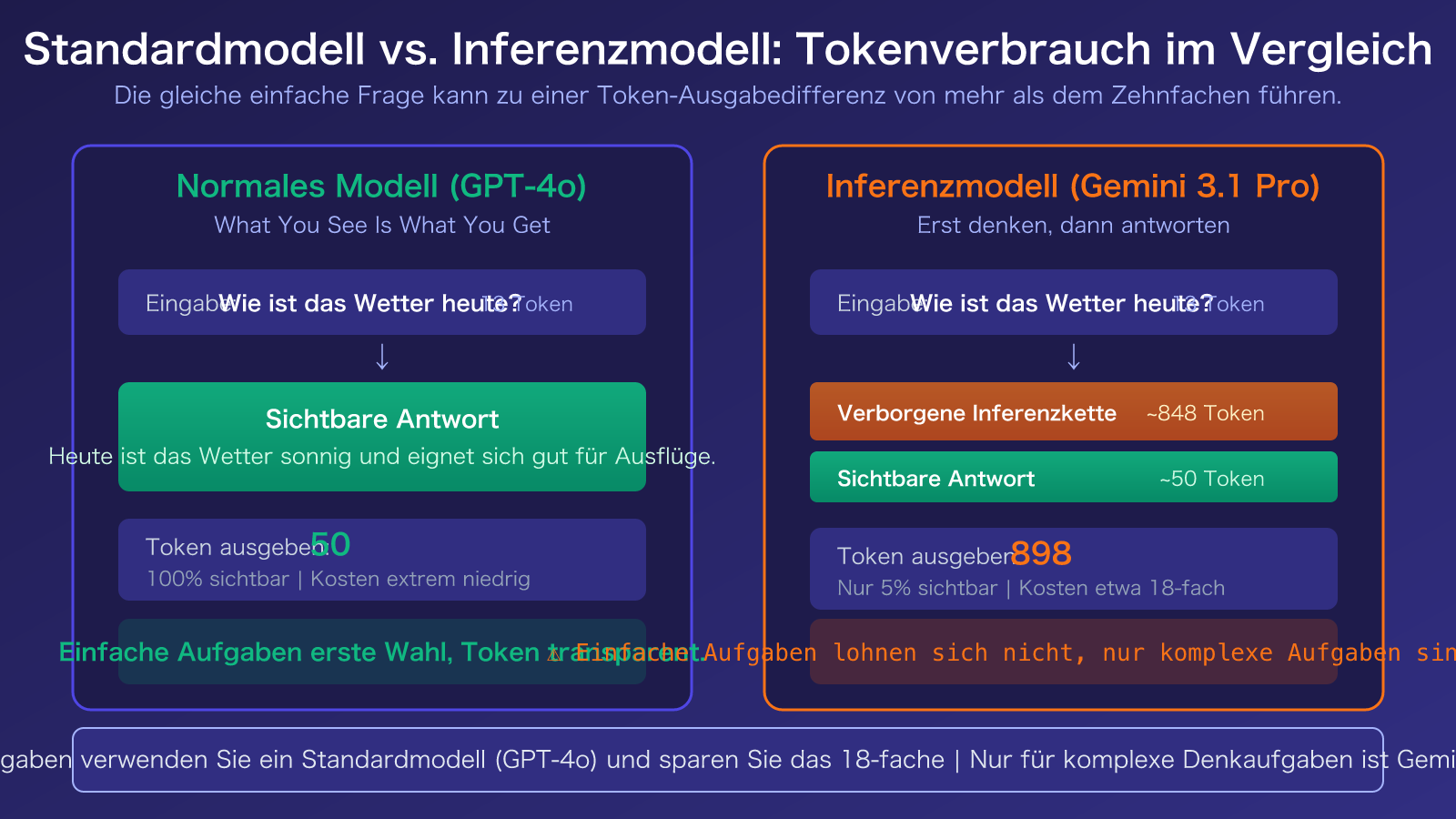
Der grundlegende Unterschied zwischen Reasoning-Modellen und Standardmodellen
Ein Standardmodell (wie GPT-4o) generiert direkt eine Antwort, nachdem es Ihre Frage erhalten hat. Sie zahlen für genau die Anzahl an Ausgabe-Tokens, die Sie sehen. Das ist das Prinzip "Was du siehst, ist was du bekommst".
Ein Reasoning-Modell (wie Gemini 3.1 Pro Preview) erzeugt nach Erhalt der Frage zunächst eine interne Denkkette (Chain of Thought) und generiert dann basierend auf diesem Reasoning-Prozess die endgültige Antwort. Sie sehen nur die finale Antwort, aber die Abrechnung erfolgt für die Gesamtzahl der Tokens: Denkkette + Antwort.
| Modelltyp | Repräsentative Modelle | Zusammensetzung der Ausgabe-Tokens | Kosten einfache Fragen | Vorteil bei komplexen Fragen |
|---|---|---|---|---|
| Standardmodell | GPT-4o, Claude Sonnet 4.6 | 100% sichtbare Antwort | Niedrig (Was du siehst, ist was du bekommst) | Allgemeine Reasoning-Fähigkeiten |
| Reasoning-Modell | Gemini 3.1 Pro, GPT-5.4 Thinking | Denkkette + sichtbare Antwort | Hoch (5-10x oder mehr) | Starke Fähigkeiten für komplexes Reasoning |
| Schaltbares Modell | Claude Sonnet 4.6 (Extended Thinking) | Reasoning optional aktivierbar | Flexible Umschaltung | Reasoning bei Bedarf aktivieren |
3 wichtige Details zu den Thinking Tokens von Gemini 3.1 Pro
Detail 1: Abrechnungsweise der Thinking Tokens. Gemäß der offiziellen Google-Dokumentation werden Thinking Tokens zum Standardpreis für Ausgabe-Tokens abgerechnet. Der Preis für Ausgabe-Tokens bei Gemini 3.1 Pro beträgt $12 pro Million Tokens. Wenn das Modell 4000 Tokens für das Reasoning und 500 Tokens für die Antwort verwendet, zahlen Sie für 4500 Ausgabe-Tokens – nicht für 500.
Detail 2: Unterscheidung in der API-Antwort. In der Antwort der Gemini-API gibt das Feld usage_metadata separat thoughts_token_count (Anzahl Reasoning-Tokens) und candidates_token_count (Gesamtanzahl Ausgabe-Tokens) zurück. Wichtig: In der Gemini-API sind die Thinking Tokens bereits in candidatesTokenCount enthalten, während sie in Vertex AI's candidatesTokenCount nicht enthalten sind.
Detail 3: Der Inhalt der Denkkette ist standardmäßig unsichtbar. Sie können durch Setzen von includeThoughts: true eine Zusammenfassung des Reasoning-Prozesses abrufen (nicht die vollständige Kette). Alternativ können Sie in Tools wie Cherry Studio die Funktion zur Anzeige der Denkkette aktivieren, um den Denkprozess des Modells zu sehen.
🎯 Spar-Tipp: Für einfache Dialoge oder Übersetzungsaufgaben, die kein tiefgehendes Reasoning erfordern, empfehlen wir, auf ein Standardmodell (wie GPT-4o-mini oder Claude Sonnet 4.6) zu wechseln. APIYI apiyi.com unterstützt den Wechsel des Modells durch Änderung eines einzigen
model-Parameters, ohne dass anderer Code angepasst werden muss.
Optimierung der Gemini 3.1 Pro Thinking Tokens: 3 Strategien zum Sparen
Strategie 1: Steuerung der Reasoning-Tiefe mit dem thinking_level-Parameter
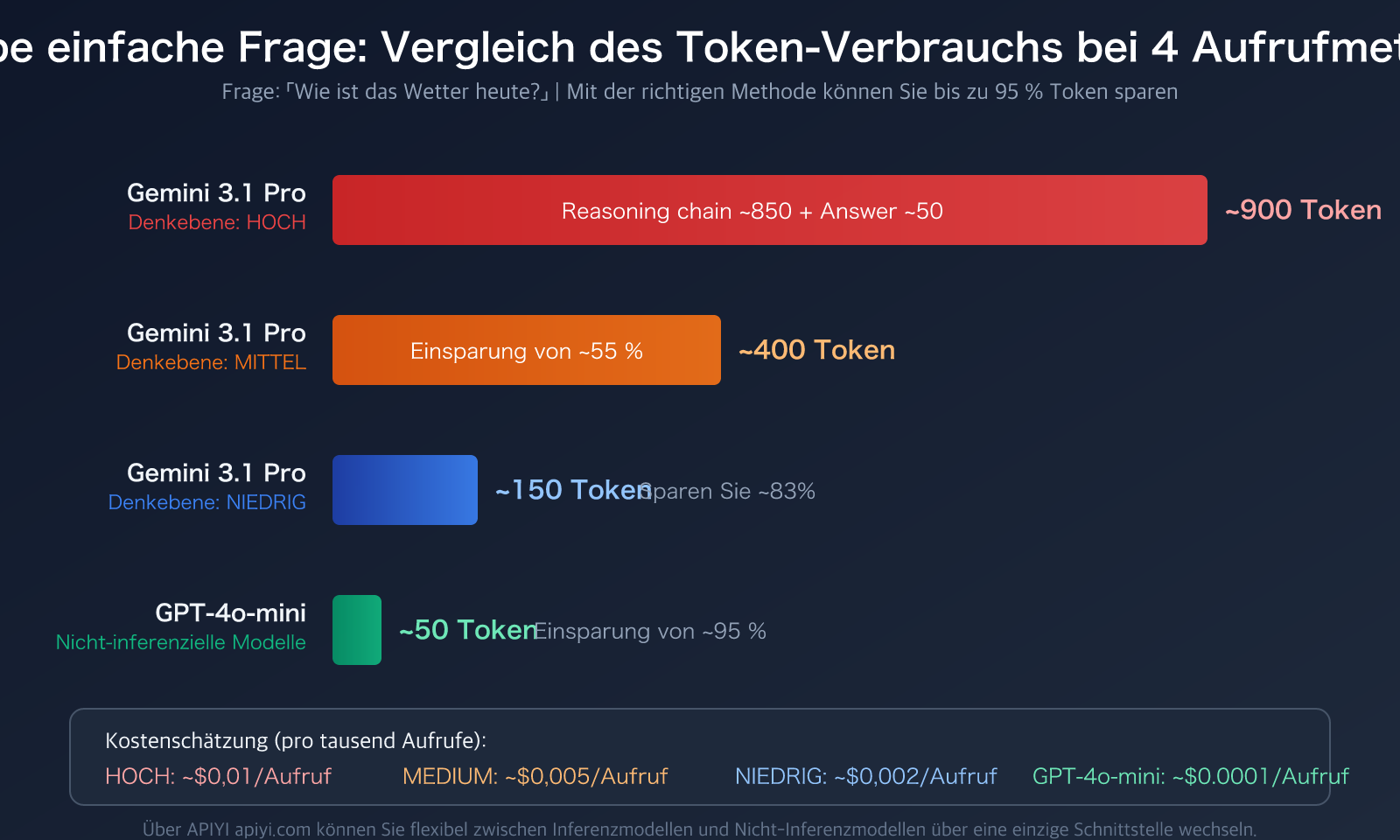
Gemini 3.1 Pro bietet den Parameter thinking_level mit den Stufen LOW, MEDIUM und HIGH. Der Token-Verbrauch unterscheidet sich zwischen den Stufen erheblich:
| thinking_level | Reasoning-Tiefe | Token-Verbrauch | Anwendungsfall | Vergleich zu HIGH |
|---|---|---|---|---|
| LOW | Oberflächliches Reasoning | Niedrigster | Übersetzung, Klassifizierung, einfache Q&A | Spart ca. 80%+ |
| MEDIUM | Ausgewogenes Reasoning | Mittel | Alltägliches Programmieren, Dokumentenerstellung, allgemeine Analyse | Spart ca. 50% |
| HIGH | Tiefgehendes Reasoning | Höchster | Mathematische Herleitungen, wissenschaftliche Probleme, komplexe Logik | Referenzwert |
Hier ein Codebeispiel zur Einstellung von thinking_level:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Einfache Aufgabe mit LOW, reduziert Thinking Tokens deutlich
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
Vollständigen Code für intelligentes Routing anzeigen (wählt Reasoning-Tiefe automatisch basierend auf Komplexität)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Intelligenter Aufruf von Gemini 3.1 Pro, wählt Reasoning-Tiefe automatisch basierend auf Aufgabenschwierigkeit.
Args:
prompt: Benutzereingabe
complexity: "low" / "medium" / "high" / "auto"
api_key: API-Schlüssel
Returns:
Dictionary mit Antwort und Token-Nutzungsstatistiken
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Komplexität automatisch bestimmen
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# Nutzungsbeispiel
# Einfache Aufgabe → automatisch LOW
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# Komplexe Aufgabe → automatisch HIGH
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
Empfehlung: Bei Aufruf von Gemini 3.1 Pro über APIYI apiyi.com wird der
thinking_level-Parameter unterstützt. Für den täglichen Gebrauch wird MEDIUM empfohlen, HIGH sollte nur für mathematische/wissenschaftliche oder andere komplexe Reasoning-Szenarien verwendet werden.
Strategie 2: Einfache Aufgaben direkt mit Nicht-Reasoning-Modellen erledigen
Nicht jedes Szenario erfordert ein Reasoning-Modell. Für Aufgaben wie Übersetzung, Formatkonvertierung oder einfache Q&A können Nicht-Reasoning-Modelle die Token-Kosten um das 5-10-fache reduzieren:
- GPT-4o-mini: Extrem gutes Preis-Leistungs-Verhältnis, erste Wahl für alltägliche Dialoge
- Claude Sonnet 4.6 (Extended Thinking deaktiviert): Hohe Antwortqualität, Token-Verbrauch entspricht der sichtbaren Ausgabe
- Gemini 3.1 Flash: Googles leichtgewichtiges Modell, schnell und kostengünstig
Strategie 3: Begrenzung der Ausgabe mit max_tokens
Das Hinzufügen des max_tokens-Parameters zum API-Aufruf kann verhindern, dass Reasoning-Modelle "überdenken". Wichtig: max_tokens begrenzt die Gesamtausgabe (Reasoning + Antwort). Eine zu niedrige Einstellung kann zu abgeschnittenen Antworten führen. Es wird empfohlen, den Wert auf das 2-3-fache der erwarteten Antwortlänge zu setzen.
🎯 Kombinierte Empfehlung: Auf der APIYI apiyi.com Plattform können Sie über eine einheitliche Schnittstelle sowohl Reasoning- als auch Nicht-Reasoning-Modelle anbinden und je nach Aufgabentyp dynamisch wechseln. Ein einziger API-Schlüssel ermöglicht den Aufruf der gesamten Modellreihen von Gemini, Claude und GPT.
Häufig gestellte Fragen
Q1: Warum zeigt Gemini 3.1 Pro Thinking Tokens standardmäßig nicht den Denkprozess an?
Dies ist eine Produktdesign-Entscheidung von Google. Die vollständige Denkkette kann Tausende von Token an Zwischenableitungen enthalten, deren direkte Anzeige die Benutzererfahrung erheblich beeinträchtigen würde. Sie können über die Einstellung includeThoughts: true eine Zusammenfassung des Denkprozesses abrufen oder in Clients wie Cherry Studio die Funktion zur Anzeige der Denkkette aktivieren, um den Gedankengang zu sehen.
Q2: Wie sehe ich in der API-Antwort, wie viele Thinking Tokens genau verbraucht wurden?
Überprüfen Sie das Feld thoughts_token_count in den usage_metadata, die von der Gemini API zurückgegeben werden. Wenn Sie den Aufruf über APIYI (apiyi.com) tätigen, können Sie auf der Nutzungsstatistik-Seite der Plattform die detaillierte Token-Aufschlüsselung (Eingabe/Ausgabe/Denken) für jeden Aufruf einsehen, was die Kostenüberwachung und -optimierung erleichtert.
Q3: Welche anderen Modelle haben neben Gemini 3.1 Pro einen ähnlichen Thinking Tokens-Mechanismus?
Hauptschlussfolgerungsmodelle haben ähnliche Mechanismen:
- GPT-5.4 Thinking: Das Schlussfolgerungsmodell von OpenAI, bei dem Denk-Token ebenfalls als Ausgabe-Token abgerechnet werden.
- Claude Sonnet 4.6 Extended Thinking: Der Schlussfolgerungsmodus von Anthropic, der optional aktiviert werden kann.
- DeepSeek-R1: Ein Open-Source-Schlussfolgerungsmodell mit vollständig sichtbarer Denkkette.
Der Hauptunterschied besteht darin, dass einige Modelle (wie Claude) den Schlussfolgerungsmodus flexibel ein- und ausschalten können, während andere (wie Gemini 3.1 Pro) die Schlussfolgerung standardmäßig aktiviert haben. Über APIYI (apiyi.com) können Sie diese Modelle mit einer einheitlichen Schnittstelle testen und ihren tatsächlichen Token-Verbrauch vergleichen.
Zusammenfassung
Die Kernpunkte von Gemini 3.1 Pro Thinking Tokens:
- Ausgabe-Token enthalten versteckte Denkkette: Sie sehen nur den Antwortteil, über 95 % des Ausgabe-Token-Verbrauchs entfallen auf die unsichtbaren Thinking Tokens.
- Thinking Tokens werden normal abgerechnet: Sie werden zum Standardpreis für Ausgabe-Token berechnet. Die Kosten für einfache Aufgaben können 5- bis 10-mal höher sein als bei Nicht-Schlussfolgerungsmodellen.
- Mit dem Parameter
thinking_levelKosten sparen: Die StufeLOWkann über 80 % der Token einsparen,MEDIUMist für den täglichen Gebrauch geeignet, undHIGHsollte nur für komplexe Aufgaben verwendet werden. - Für einfache Aufgaben Nicht-Schlussfolgerungsmodelle wählen: Für Übersetzungen, Klassifizierungen, einfache Fragen und Antworten sind Modelle wie GPT-4o-mini oder Claude Sonnet 4.6 kostengünstiger.
Wenn Sie den Thinking Tokens-Mechanismus verstehen, können Sie Ihr Schlussfolgerungsbudget sinnvoll verteilen. Wir empfehlen, über APIYI (apiyi.com) mit einer einheitlichen Schnittstelle mehrere Modellaufrufe zu verwalten und je nach Aufgabenkomplexität dynamisch zwischen Schlussfolgerungs- und Nicht-Schlussfolgerungsmodellen zu wählen, um das beste Verhältnis zwischen Qualität und Kosten zu erreichen.
📚 Referenzmaterial
-
Google Cloud Dokumentation – Thinking Reasoning-Modus: Offizielle technische Dokumentation für Gemini Reasoning-Modelle
- Link:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - Beschreibung: Autoritative Quelle für die Abrechnungsregeln von Thinking Tokens und die Konfiguration des
thinking_level-Parameters
- Link:
-
Google AI Entwicklerdokumentation – Token-Zählung: Offizielle Erläuterung zur Token-Zählung und den
usage_metadata-Feldern- Link:
ai.google.dev/gemini-api/docs/tokens - Beschreibung: Wie man
thoughts_token_countundcandidates_token_countin der API-Antwort unterscheidet
- Link:
-
Google DeepMind – Gemini 3.1 Pro Model Card: Details zu Modellfähigkeiten und Reasoning-Benchmarks
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Beschreibung: Offizielle Quelle für Leistungsdaten wie MATH 95,1 % und ARC-AGI-2 77,1 %
- Link:
-
OpenRouter – Best Practices für Reasoning Tokens: Community-Best-Practices für das Management von Reasoning-Tokens
- Link:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - Beschreibung: Vergleich der Abrechnungsregeln für Reasoning-Tokens über verschiedene Modelle hinweg und Optimierungsempfehlungen
- Link:
Autor: APIYI Technikteam
Technischer Austausch: Diskutieren Sie gerne Ihre Erfahrungen zur Token-Optimierung mit Reasoning-Modellen in den Kommentaren. Weitere Tutorials zum Modellaufruf finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.