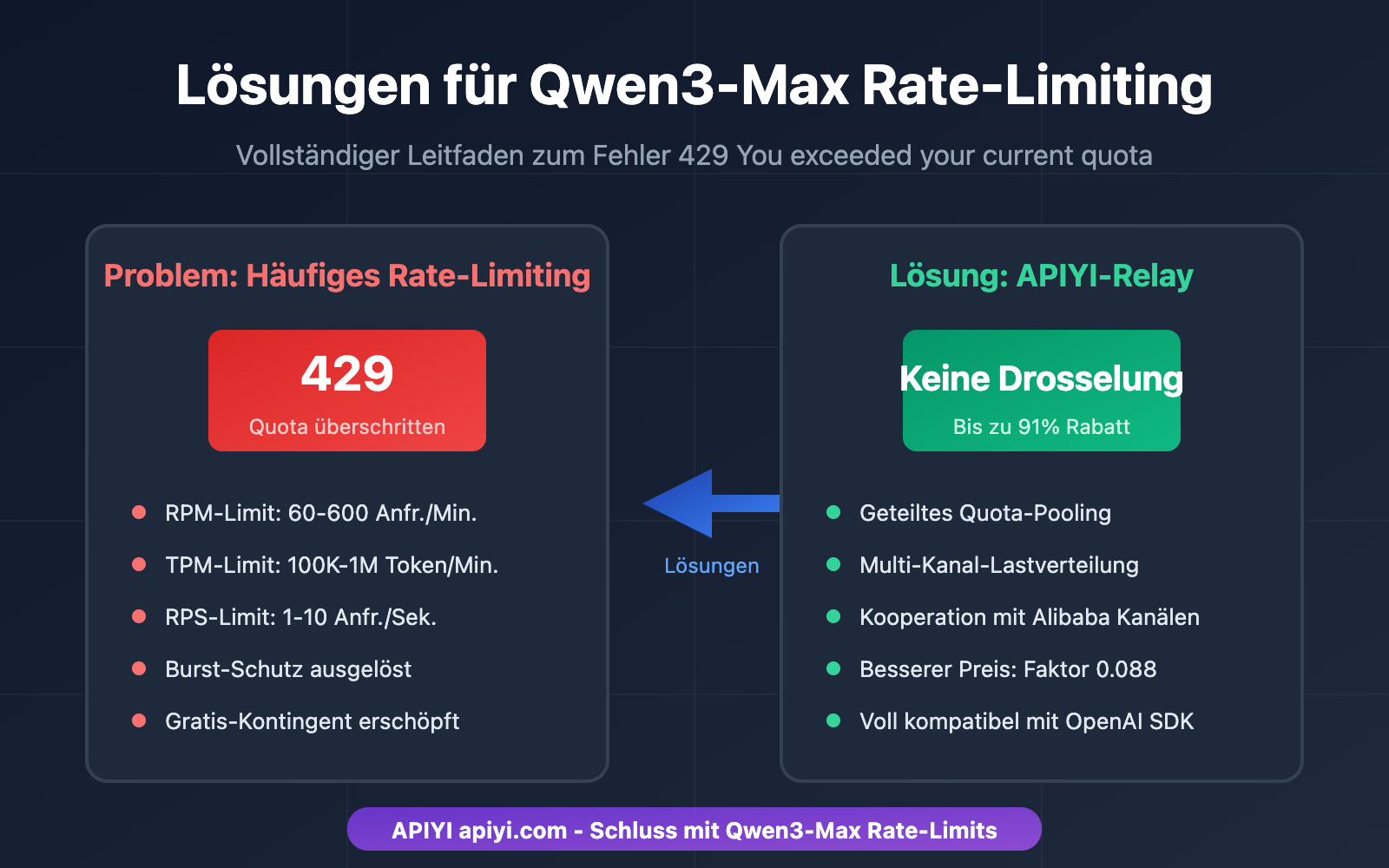
Beim Entwickeln von AI-Anwendungen mit Qwen3-Max ist die Fehlermeldung 429 You exceeded your current quota ein häufiger Schmerzpunkt für viele Entwickler. In diesem Artikel analysieren wir den Rate-Limiting-Mechanismus von Alibaba Clouds Qwen3-Max im Detail und bieten 5 praktische Lösungen an, damit Sie sich nie wieder Sorgen um erschöpfte Kontingente machen müssen.
Kernbotschaft: Nach der Lektüre dieses Artikels werden Sie die Funktionsweise des Qwen3-Max Rate-Limiting verstehen und verschiedene Lösungen beherrschen, um das万亿-Parameter Großes Sprachmodell stabil und zuverlässig aufzurufen.
Überblick über Qwen3-Max Rate-Limiting-Probleme
Typische Fehlermeldung
Wenn Ihre Anwendung die Qwen3-Max-API häufig aufruft, kann folgende Fehlermeldung auftreten:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Dieser Fehler bedeutet, dass Sie das Kontingentlimit des Alibaba Cloud Model Studio erreicht haben.
Auswirkungen von Qwen3-Max Rate-Limiting
| Szenario | Ausprägung | Schweregrad |
|---|---|---|
| Agent-Entwicklung | Häufige Unterbrechungen bei Multi-Turn-Dialogen | Hoch |
| Batch-Verarbeitung | Aufgaben können nicht abgeschlossen werden | Hoch |
| Echtzeit-Anwendungen | Beeinträchtigung der Benutzererfahrung | Hoch |
| Codegenerierung | Lange Code-Ausgaben werden abgeschnitten | Mittel |
| Testen & Debugging | Verringerte Entwicklungseffizienz | Mittel |
Detaillierte Erläuterung der Qwen3-Max-Limitierungsmechanismen
Offizielle Kontingentbeschränkungen von Alibaba Cloud
Gemäß der offiziellen Dokumentation von Alibaba Cloud Model Studio gelten für Qwen3-Max folgende Kontingente:
| Modellversion | RPM (Anfragen/Min.) | TPM (Token/Min.) | RPS (Anfragen/Sek.) |
|---|---|---|---|
| qwen3-max | 600 | 1.000.000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100.000 | 1 |
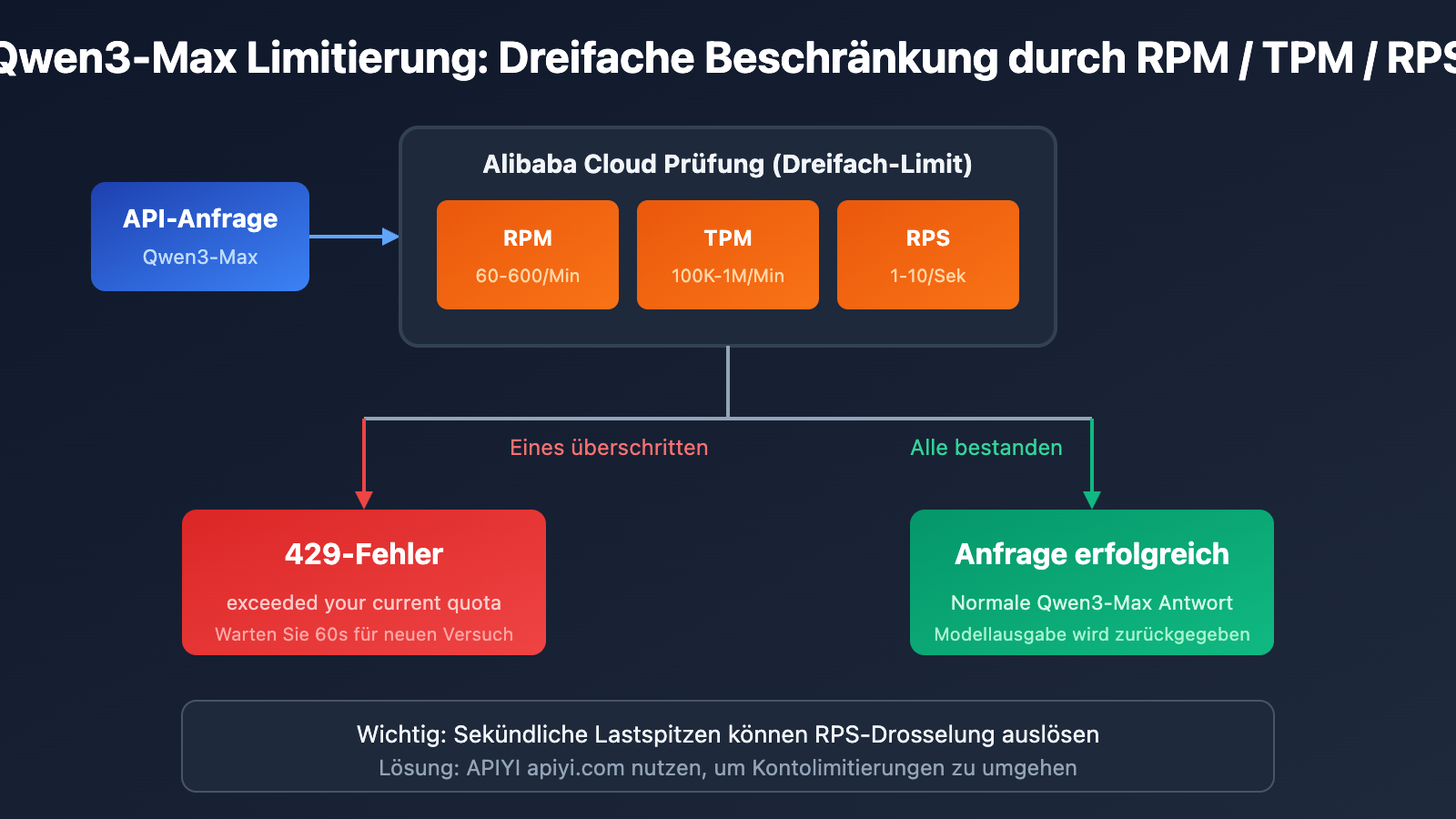
4 Situationen, die eine Qwen3-Max-Limitierung auslösen
Alibaba Cloud implementiert einen doppelten Beschränkungsmechanismus für Qwen3-Max. Wenn eine der folgenden Bedingungen eintritt, wird ein 429-Fehler zurückgegeben:
| Fehlertyp | Fehlermeldung | Ursache |
|---|---|---|
| Anfragefrequenz überschritten | Requests rate limit exceeded | RPM/RPS-Limit überschritten |
| Token-Verbrauch überschritten | You exceeded your current quota | TPM/TPS-Limit überschritten |
| Schutz vor Lastspitzen | Request rate increased too quickly | Plötzlicher Anstieg der Anfragen |
| Kostenloses Kontingent erschöpft | Free allocated quota exceeded | Testguthaben aufgebraucht |
Berechnungsformel für die Limitierung
Tatsächliches Limit = min(RPM-Limit, RPS × 60)
= min(TPM-Limit, TPS × 60)
Wichtiger Hinweis: Selbst wenn das Limit pro Minute nicht überschritten wird, können Lastspitzen auf Sekundenebene eine Drosselung auslösen.
5 Lösungen für Qwen3-Max-Limitierungsprobleme
Vergleich der Lösungsansätze
| Lösung | Schwierigkeit | Effekt | Kosten | Empfohlenes Szenario |
|---|---|---|---|---|
| API-Relay-Dienst | Gering | Vollständig gelöst | Günstiger | Alle Szenarien |
| Anfrage-Glättung | Mittel | Abschwächung | Kostenlos | Leichte Limitierung |
| Multi-Account-Polling | Hoch | Abschwächung | Hoch | Unternehmenskunden |
| Modell-Fallback | Mittel | Absicherung | Mittel | Nicht-kritische Aufgaben |
| Kontingenterhöhung | Gering | Begrenzt | Kostenlos | Langzeitnutzer |
Lösung 1: API-Relay-Dienst verwenden (Empfohlen)
Dies ist die direkteste und effektivste Lösung für Qwen3-Max-Limitierungsprobleme. Durch den Aufruf über eine API-Relay-Plattform können Kontingentbeschränkungen auf Alibaba Cloud-Kontoebene umgangen werden.
Warum APIYI die Limitierung löst
| Vergleichspunkt | Direkt bei Alibaba Cloud | Über APIYI-Relay |
|---|---|---|
| Kontingentlimit | Konto-basiertes RPM/TPM-Limit | Plattform-Pool-Sharing |
| Limitierungshäufigkeit | Häufige 429-Fehler | Praktisch keine Limitierung |
| Preis | Offizieller Originalpreis | Standardmäßig 8,8 % des Preises |
| Stabilität | Abhängig vom Kontokontingent | Abgesichert durch mehrere Kanäle |
Einfaches Code-Beispiel
from openai import OpenAI
# APIYI-Relay-Dienst nutzen und Limitierungssorgen vergessen
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Erkläre das Funktionsprinzip der MoE-Architektur"}
]
)
print(response.choices[0].message.content)
🎯 Empfehlung: Durch den Aufruf von Qwen3-Max über APIYI (apiyi.com) lösen Sie nicht nur das Limitierungsproblem vollständig, sondern profitieren auch von massiven Preisvorteilen. APIYI arbeitet über Partnerkanäle mit Alibaba Cloud zusammen, um stabilere Dienste zu günstigeren Konditionen anzubieten.
Vollständigen Code ansehen (inkl. Retries und Fehlerbehandlung)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Qwen3-Max Client via APIYI – keine Limitierungsprobleme"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI Relay-Schnittstelle
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Nachricht senden und Antwort erhalten.
Dank APIYI treten normalerweise keine Limitierungen auf.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# Bei APIYI wird diese Ausnahme fast nie ausgelöst
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Anfrage limitiert, erneuter Versuch in {wait_time}s...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"API-Fehler: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Stapelverarbeitung von Nachrichten ohne Limitierungssorgen"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Beispielanwendung
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# Einzelaufruf
response = client.chat("Schreibe einen Quick-Sort-Algorithmus in Python")
print(response)
# Batch-Aufruf - unbegrenzt via APIYI
questions = [
"Erkläre die MoE-Architektur",
"Vergleiche Transformer und RNN",
"Was ist der Aufmerksamkeitsmechanismus (Attention Mechanism)?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"F: {q}\nA: {a}\n")
Lösung 2: Anfrage-Glättungsstrategie
Wenn Sie die Direktverbindung zu Alibaba Cloud bevorzugen, können Sie die Limitierung durch Glättung der Anfragen abmildern.
Exponential Backoff (Exponentielles Zurückweichen)
import time
import random
def call_with_backoff(func, max_retries=5):
"""Strategie für exponentielles Zurückweichen bei Fehlern"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Exponentielles Warten + zufälliger Jitter
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limitierung ausgelöst, warte {wait_time:.2f}s...")
time.sleep(wait_time)
else:
raise e
Anfrage-Warteschlange (Buffering)
import asyncio
from collections import deque
class RequestQueue:
"""Warteschlange zur Glättung der Qwen3-Max Aufruffrequenz"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Intervall zwischen Anfragen
self.last_request = 0
async def throttled_request(self, request_func):
"""Limitierte Anfrage ausführen"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
Hinweis: Anfrage-Glättung kann das Problem nur mildern, aber nicht vollständig lösen. Für Szenarien mit hoher Parallelität wird der APIYI-Relay-Dienst empfohlen.
Lösung 3: Multi-Account-Polling
Unternehmenskunden können das Gesamtkontingent durch Polling über mehrere Konten erhöhen.

from itertools import cycle
class MultiAccountClient:
"""Client für Polling über mehrere Konten"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Anzahl Konten | Effektives RPM | Effektives TPM | Management-Aufwand |
|---|---|---|---|
| 1 | 600 | 1.000.000 | Niedrig |
| 3 | 1.800 | 3.000.000 | Mittel |
| 5 | 3.000 | 5.000.000 | Hoch |
| 10 | 6.000 | 10.000.000 | Sehr hoch |
💡 Vergleichshinweis: Multi-Account-Management ist komplex und teuer. Es ist effizienter, direkt den APIYI-Relay-Dienst zu nutzen, um ohne Verwaltungsaufwand von einem plattformweiten Kontingent-Pool zu profitieren.
Lösung 4: Modell-Fallback
Wenn Qwen3-Max eine Limitierung meldet, kann das System automatisch auf ein Ersatzmodell ausweichen.
class FallbackClient:
"""Qwen-Client mit automatischer Modell-Degradierung"""
MODEL_PRIORITY = [
"qwen3-max", # Erste Wahl
"qwen-plus", # Ersatz 1
"qwen-turbo", # Ersatz 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI nutzen
)
def chat(self, message: str) -> tuple[str, str]:
"""Gibt (Antwortinhalt, tatsächlich genutztes Modell) zurück"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} limitiert, versuche Fallback...")
continue
raise e
raise Exception("Alle Modelle sind derzeit nicht verfügbar")
Lösung 5: Antrag auf Kontingenterhöhung
Für Nutzer mit langfristig stabilen Anforderungen kann eine Erhöhung des Kontingents direkt bei Alibaba Cloud beantragt werden.
Schritte für den Antrag:
- In der Alibaba Cloud Konsole anmelden.
- Den Bereich "Model Studio Kontingent-Management" aufrufen.
- Antrag auf Erhöhung einreichen.
- Prüfung abwarten (dauert in der Regel 1 bis 3 Werktage).
Anforderungen:
- Verifiziertes Konto.
- Keine offenen Rechnungen.
- Detaillierte Beschreibung des Anwendungsszenarios.
Qwen3-Max Rate-Limit-Probleme: Kostenvergleich
Preisvergleichsanalyse
| Dienstleister | Preis Eingabe (0-32K) | Preis Ausgabe | Status Ratenbegrenzung |
|---|---|---|---|
| Alibaba Cloud Direkt | $1.20/M | $6.00/M | Strikte RPM/TPM-Beschränkungen |
| APIYI (Faktor 0,88) | $1.06/M | $5.28/M | Praktisch keine Begrenzung |
| Differenz | 12 % Ersparnis | 12 % Ersparnis | – |
Gesamtkostenrechnung
Angenommen, das monatliche Aufrufvolumen beträgt 10 Millionen Token (jeweils zur Hälfte Eingabe und Ausgabe):
| Lösung | Monatliche Kosten | Auswirkungen der Ratenbegrenzung | Gesamtbewertung |
|---|---|---|---|
| Alibaba Cloud Direkt | $36.00 | Häufige Unterbrechungen, Retries nötig | Tatsächliche Kosten höher |
| APIYI-Proxy | $31.68 | Stabil ohne Unterbrechungen | Bestes Preis-Leistungs-Verhältnis |
| Multi-Account-Lösung | $36.00+ | Hoher Verwaltungsaufwand | Nicht empfohlen |
💰 Kostenoptimierung: APIYI (apiyi.com) unterhält eine Partnerschaft mit Alibaba Cloud. Dadurch erhalten Sie nicht nur standardmäßig einen Rabatt (Faktor 0,88), sondern lösen auch das Problem der Ratenbegrenzung vollständig. Für Szenarien mit mittlerer bis hoher Nutzungsfrequenz sind die Gesamtkosten hier am niedrigsten.
Häufig gestellte Fragen (FAQ)
Q1: Warum trete ich bei Qwen3-Max sofort in ein Rate Limit?
Das Alibaba Cloud Model Studio bietet für neue Konten nur ein begrenztes Gratis-Kontingent. Zudem ist das Kontingent für die neue Version qwen3-max-2025-09-23 deutlich niedriger angesetzt (RPM 60, TPM 100.000). Wenn Sie Snapshot-Versionen verwenden, sind die Limits oft noch strenger.
Wir empfehlen den Aufruf über APIYI (apiyi.com), um die Kontingentbeschränkungen auf Kontoebene zu umgehen.
Q2: Wie lange dauert die Wiederherstellung nach einer Ratenbegrenzung?
Die Ratenbegrenzung von Alibaba Cloud nutzt einen Sliding-Window-Mechanismus:
- RPM-Limit (Requests Per Minute): Wiederherstellung nach ca. 60 Sekunden.
- TPM-Limit (Tokens Per Minute): Wiederherstellung nach ca. 60 Sekunden.
- Burst-Schutz: Kann unter Umständen längere Wartezeiten erfordern.
Durch die Nutzung der APIYI-Plattform vermeiden Sie diese häufigen Wartezeiten und steigern Ihre Entwicklungseffizienz.
Q3: Wie wird die Stabilität des APIYI-Proxy-Dienstes gewährleistet?
APIYI arbeitet eng mit Alibaba Cloud zusammen und nutzt ein Kontingentmodell auf Plattformebene (Pool-Modell):
- Lastverteilung über mehrere Kanäle (Load Balancing)
- Automatisches Failover (Ausfallsicherung)
- 99,9 % Verfügbarkeitsgarantie
Im Vergleich zu den individuellen Beschränkungen eines Einzelkontos ist der plattformbasierte Dienst wesentlich stabiler und zuverlässiger.
Q4: Muss ich für die Nutzung von APIYI viel Code ändern?
Fast gar nicht. APIYI ist vollständig kompatibel mit dem OpenAI SDK-Format. Sie müssen lediglich zwei Stellen in Ihrem Code anpassen:
# Vorher (Alibaba Cloud Direktverbindung)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# Nachher (APIYI Proxy)
client = OpenAI(
api_key="your-apiyi-key", # Durch Ihren APIYI-Key ersetzen
base_url="https://api.apiyi.com/v1" # APIYI-Adresse verwenden
)
Modellnamen und Parameterformate bleiben identisch, es sind keine weiteren Änderungen erforderlich.
Q5: Welche Modelle unterstützt APIYI außer Qwen3-Max noch?
Die APIYI-Plattform unterstützt den einheitlichen Aufruf von über 200 gängigen KI-Modellen, darunter:
- Qwen-Serie: qwen3-max, qwen-plus, qwen-turbo, qwen-vl usw.
- Claude-Serie: claude-3-opus, claude-3-sonnet, claude-3-haiku
- GPT-Serie: gpt-4o, gpt-4-turbo, gpt-3.5-turbo
- Andere: Gemini, DeepSeek, Moonshot usw.
Alle Modelle lassen sich über eine einheitliche Schnittstelle mit einem einzigen API-Key ansteuern.
Zusammenfassung der Lösungen für Qwen3-Max Ratelimit-Probleme
Entscheidungsbaum zur Lösungswahl
Qwen3-Max 429 Fehler aufgetreten
│
├─ Vollständige Lösung erforderlich → APIYI Proxy nutzen (empfohlen)
│
├─ Leichte Limitierung → Request Smoothing + Exponential Backoff
│
├─ Unternehmensweite Nutzung → Multi-Account-Polling oder APIYI Enterprise
│
└─ Nicht-kritische Aufgaben → Fallback auf alternatives Modell (Downgrade)
Zusammenfassung der Kernpunkte
| Punkt | Beschreibung |
|---|---|
| Ursache der Limitierung | Dreifache Einschränkung von Alibaba Cloud: RPM/TPM/RPS |
| Beste Lösung | APIYI Proxy-Dienst, löst das Problem vollständig |
| Kostenvorteil | Attraktive Konditionen, deutlich günstiger als die direkte Anbindung |
| Migrationsaufwand | Minimal: Nur Anpassung von base_url und api_key erforderlich |
Wir empfehlen APIYI (apiyi.com), um Qwen3-Max Ratelimit-Probleme schnell zu beheben und von stabilem Service sowie attraktiven Preisen zu profitieren.
Referenzen
-
Alibaba Cloud Rate Limits Dokumentation: Offizielle Erläuterung der Limits
- Link:
alibabacloud.com/help/en/model-studio/rate-limit
- Link:
-
Alibaba Cloud Error Codes Dokumentation: Details zu den Fehlercodes
- Link:
alibabacloud.com/help/en/model-studio/error-code
- Link:
-
Qwen3-Max Modelldokumentation: Offizielle technische Spezifikationen
- Link:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Link:
Technischer Support: Bei Fragen zur Nutzung von Qwen3-Max steht Ihnen der Support von APIYI unter apiyi.com zur Verfügung.