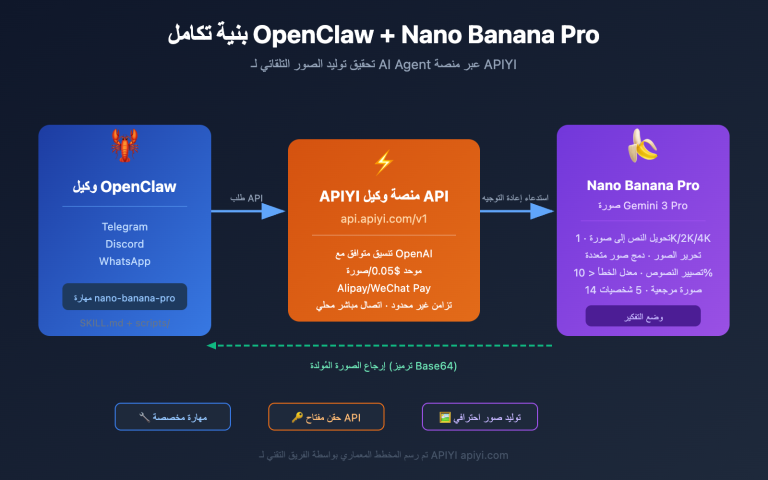
يصاب الكثيرون بالارتباك عند استخدام نسخة ChatGPT عبر الويب لأول مرة؛ حيث يتخيلون أن إدخال ملف PDF أو جملة واحدة سيجعل النموذج "يخرج" 5 صور متناسقة بضغطة زر. لكن بمجرد الانتقال إلى واجهة برمجة التطبيقات (API) وضبط المعامل n على 5، تكون النتيجة 5 صور متشابهة تقريبًا، أشبه بسحب بطاقات عشوائية. لماذا يختلف الأداء لنفس النموذج بهذا الشكل الكبير؟
لا تهدف هذه المقالة إلى تقديم إجابة نموذجية، بل إلى تفكيك هذه المشكلة التي نواجهها باستمرار في دعم العملاء. سنوضح مساريين تقنيين مختلفين تمامًا وراء توليد مجموعات الصور في GPT، ونشرح لماذا لا يمكن للمعامل n إنشاء "مجموعة صور" حقيقية، وما هي الطرق العملية التي يمكنك اتباعها إذا أردت تحقيق اتساق الصور بنفسك عبر API.
أولاً: مساران تقنيان لتوليد الصور في GPT
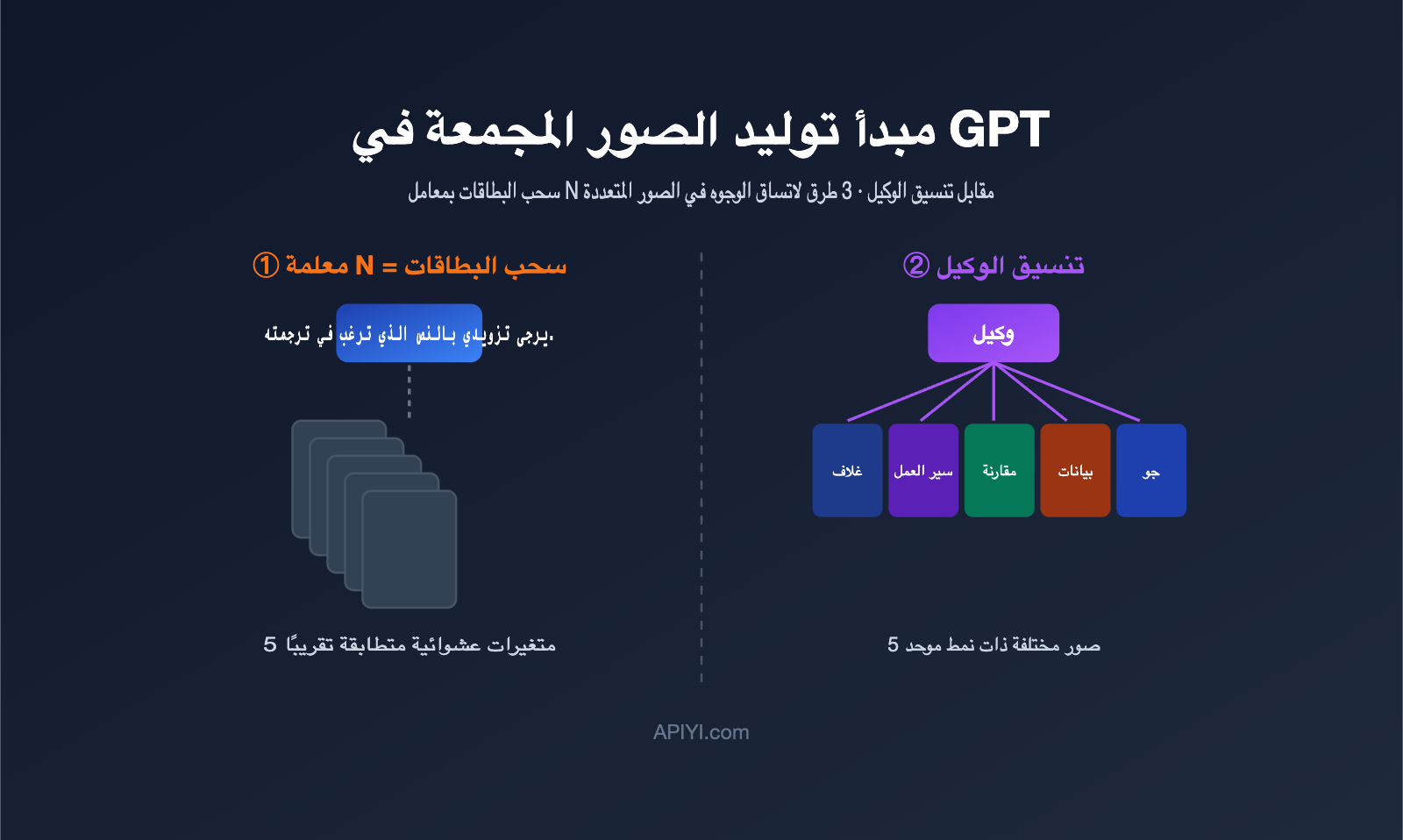
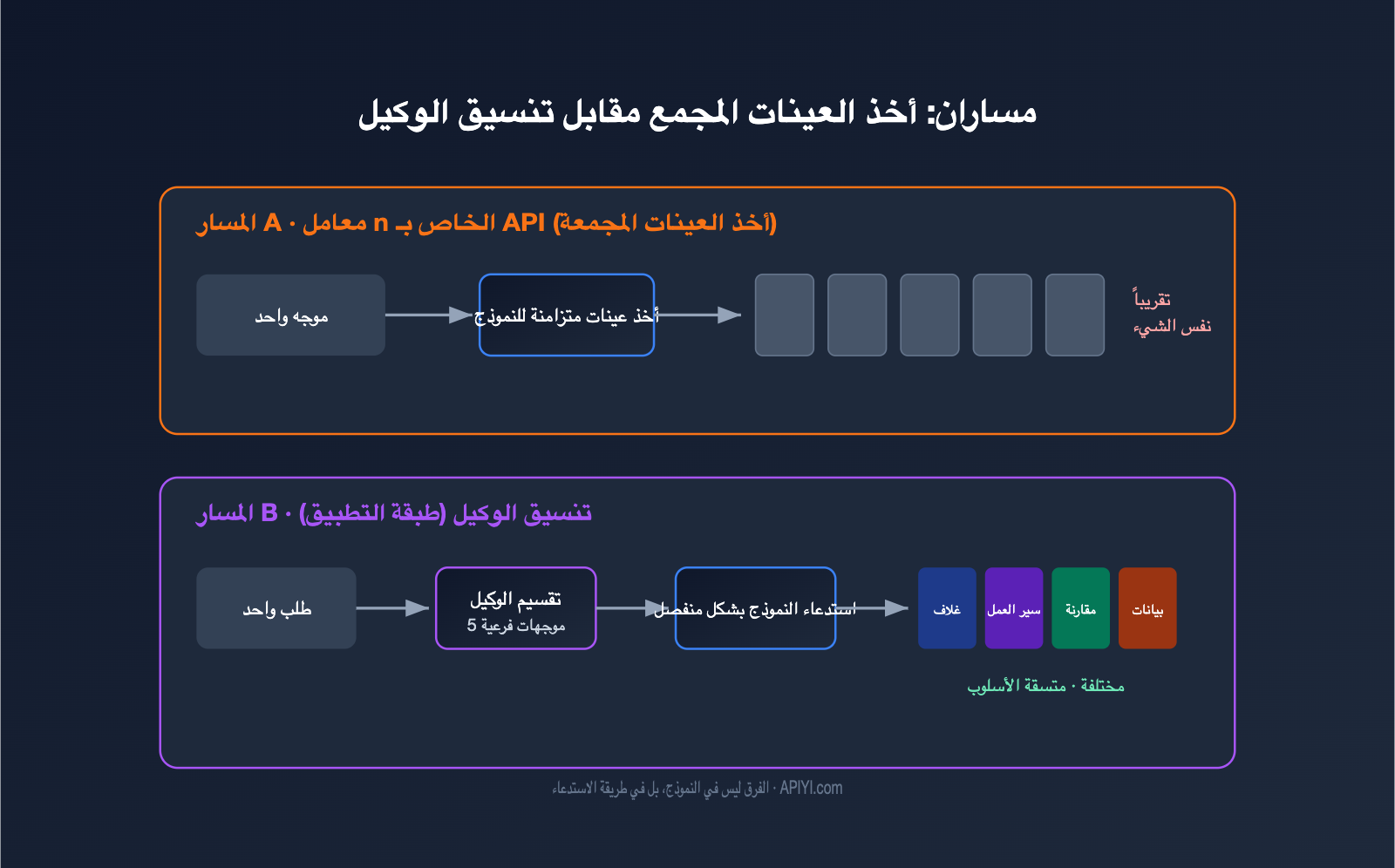
لفهم هذا الأمر، يجب أولاً الاعتراف بفرضية غالبًا ما يتم تجاهلها: "توليد صور متعددة في وقت واحد" و"توليد مجموعة صور ذات علاقة منطقية" هما أمران مختلفان تمامًا. الأول هو مجرد تجميع كمي، بينما الثاني هو ما يقصده الجميع بـ "مجموعة صور" حقيقية.
يتم تنفيذ GPT Image هندسيًا عبر مسارين. المسار الأول هو أخذ العينات الجماعي على مستوى النموذج، وهو ما يمثله المعامل n في API: حيث يتم استخدام نفس الموجه ونفس المدخلات لجعل النموذج يولد عدة نتائج بالتوازي. المسار الثاني هو التنسيق عبر الوكلاء (Agentic) على مستوى التطبيق، حيث يقوم وكيل (Agent) بفهم المتطلبات، وتقسيمها إلى مهام فرعية، ثم استدعاء قدرات توليد الصور بشكل منفصل، وأخيرًا تجميعها في مجموعة واحدة.
يوضح الجدول التالي الفروقات الجوهرية بين المسارين، وسنتوسع في شرحها في الأقسام التالية.
| البعد | المعامل n في API (أخذ العينات الجماعي) | التنسيق عبر الوكلاء (مستوى التطبيق) |
|---|---|---|
| الجوهر | أخذ عينات عشوائية متكررة لنفس الموجه | توليد مستقل متعدد بعد تقسيم المتطلبات |
| محتوى كل صورة | متطابق تقريبًا، مع اختلافات عشوائية | مختلف، ولكن مرتبط بالموضوع |
| فهم "المجموعة" | لا يفهم، مجرد توازي | يفهم، مع وجود منطق تخطيطي |
| التكلفة | سعر الصورة الواحدة × N | تراكم تكاليف الاستدعاءات المتعددة |
| مصدر الاتساق | الموجه وبذرة العشوائية | صورة مرجعية + قيود الموجه الموحدة |
| السيناريوهات النموذجية | اختيار صورة واحدة مرضية | سلسلة رسوم توضيحية، شرائح عرض، قصص مصورة |
باختصار، يحل المعامل n مشكلة "أعطني بضع خيارات إضافية"، بينما تتطلب مجموعة الصور "أعطني سلسلة من المحتويات بناءً على موضوع واحد". وهذا هو السبب في أنك تشعر بوجود نقص عند محاولة محاكاة تجربة الويب مباشرة عبر API. إذا كنت ترغب في التحقق من الأداء الفعلي لهذين المسارين، يمكنك اختبارهما باستخدام نفس مفتاح API على APIYI (apiyi.com)، مما يوفر عليك تكاليف التنقل بين منصات متعددة.
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI (apiyi.com) 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
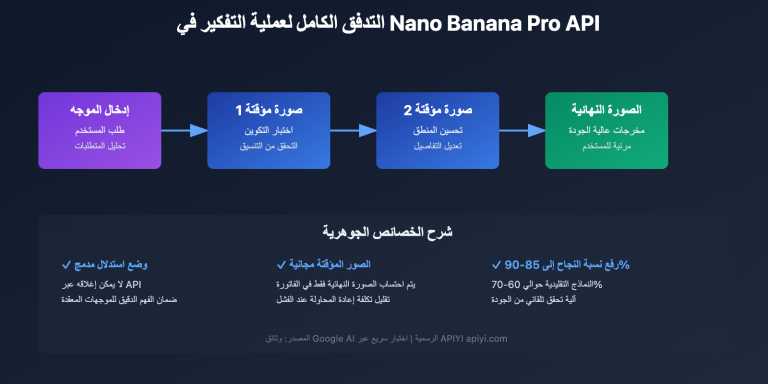
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
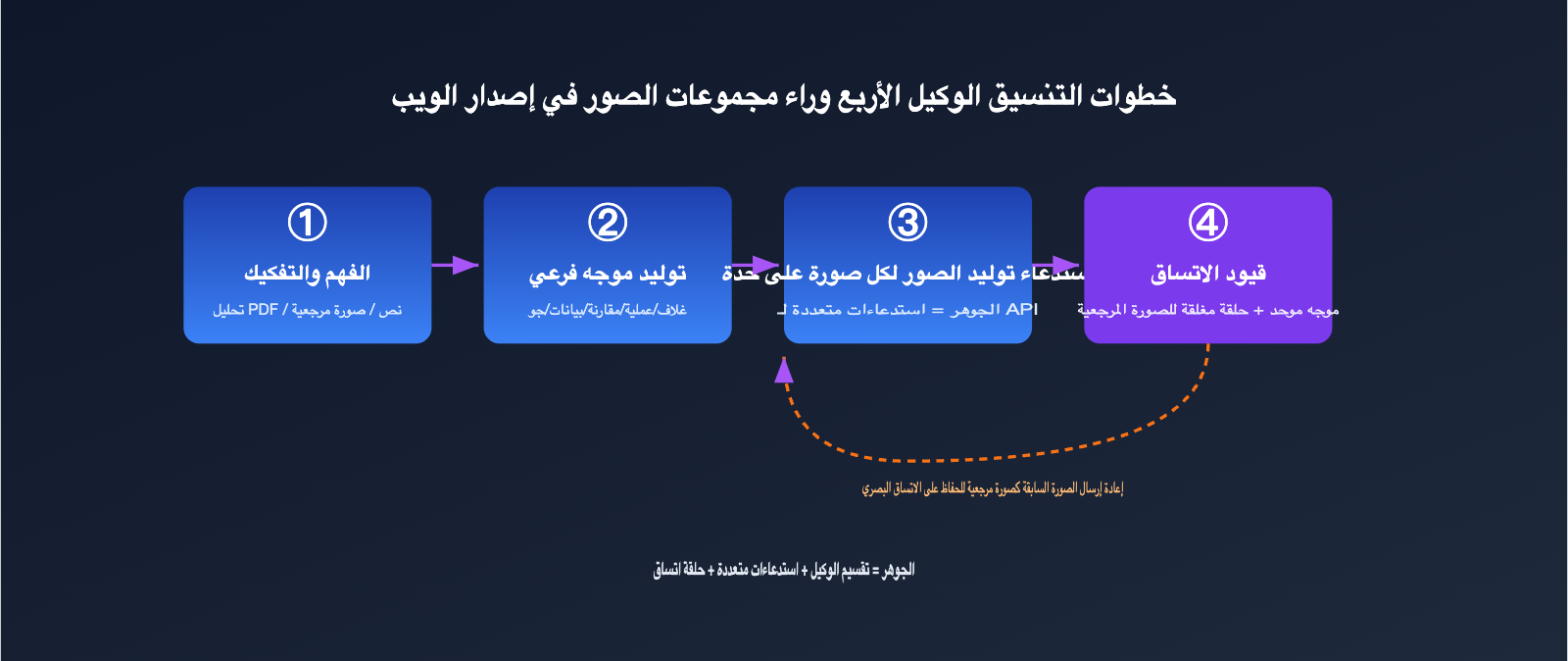
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解:Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
أربعة: إعادة إنتاج مجموعات الصور باستخدام API: ثلاث طرق لتحقيق اتساق الصور
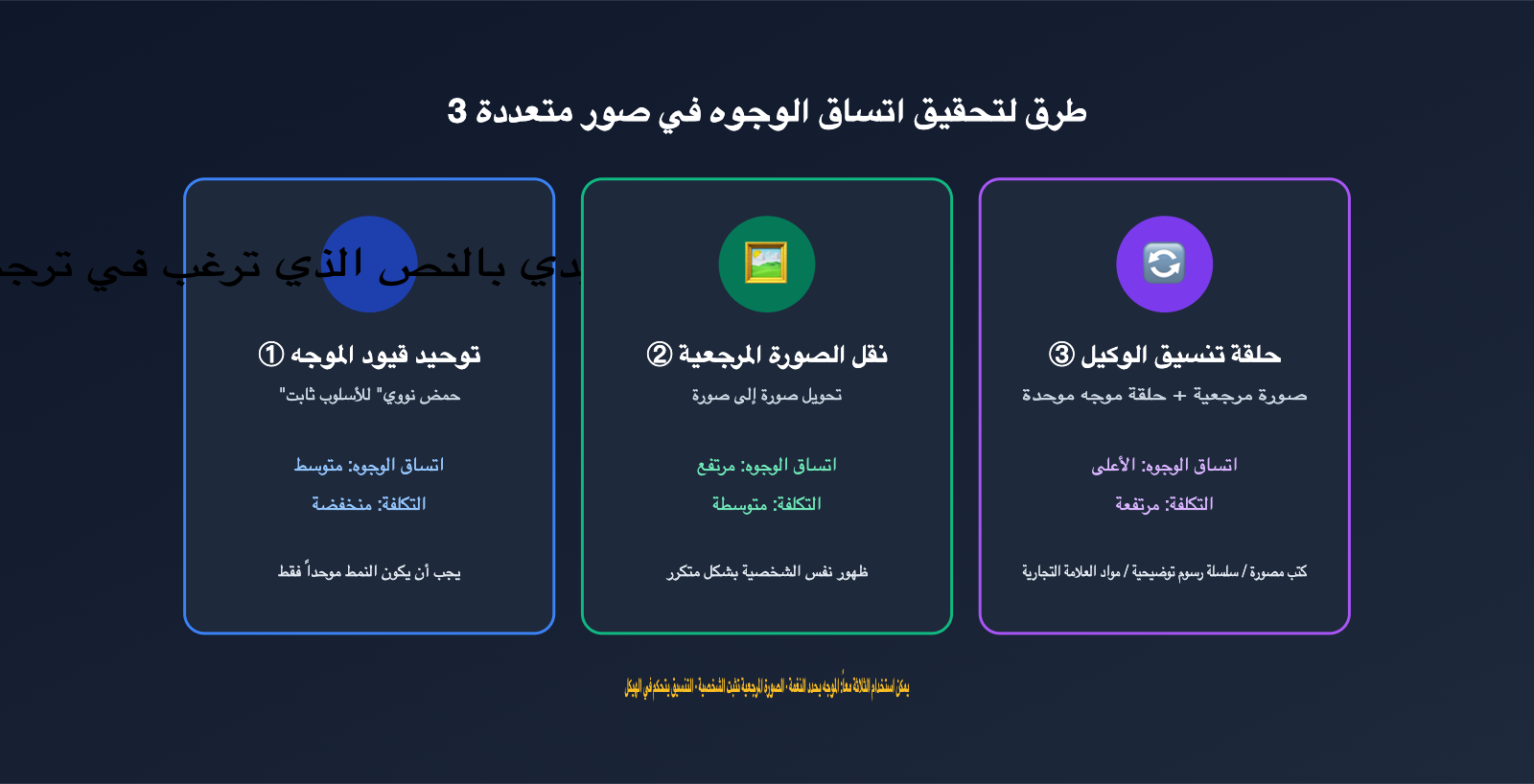
إذا كنت لا ترغب في الاعتماد على إصدار الويب، وتريد تنفيذ توليد الصور عبر GPT في منتجك الخاص، فسيتعين عليك بناء منطق التنسيق بنفسك. الجوهر هنا هو استخدام الوسائل الهندسية لتعويض "الاتساق البصري". بناءً على الممارسة العملية، لخصنا ثلاث طرق تتدرج من البساطة إلى التعقيد، ويمكن دمجها معاً.
الطريقة الأولى: تقييد الموجه (قائمة وصف الشخصية). الطريقة الأقل تكلفة هي كتابة "حمض نووي للأسلوب" ثابت لمجموعة الصور بأكملها، وإرفاقه كما هو في كل استدعاء للنموذج. على سبيل المثال: "استخدام أسلوب الرسوم التوضيحية المسطحة، اللون الأساسي هو الأزرق الداكن والكهرماني، الشخصية هي مهندسة بشعر قصير". يُطلق على هذا الوصف الثابت في المجتمع اسم "إنجيل الشخصية" (character bible)؛ فكلما كان الوصف أكثر دقة، زاد الاتساق بين الصور.
الطريقة الثانية: تمرير الصورة المرجعية (تحويل صورة إلى صورة). خذ الصورة الأولى التي نالت رضاك، ومررها كـ "صورة مرجعية" في كل استدعاء لاحق. يدعم GPT Image 2 استقبال صور مرجعية متعددة في سيناريوهات التحرير/المرجع (تذكر الوثائق الرسمية أن الحد الأقصى هو 16 صورة، يرجى التحقق من المنصة)، مما يجعل "تحديد الأسلوب بالصورة" الوسيلة الرئيسية لضمان اتساق المجموعة. عادة ما تكون نتائجها أكثر استقراراً من الوصف النصي البحت، خاصة في تفاصيل مثل ملامح الشخصية.
الطريقة الثالثة: تنسيق الوكيل (Agent) + حلقة التغذية الراجعة للمرجع. ادمج الطريقتين السابقتين في حلقة عمل: ابدأ بتوليد الصورة الأولى كصورة أساسية، ثم اجعل كل صورة لاحقة تُولد باستخدام الصورة الأساسية + الموجه الموحد، مع إدراج الصورة السابقة كمرجع عند الضرورة. هذا بالضبط ما يفعله وضع التفكير (Thinking) في إصدار الويب، لكنك هنا تقوم بكتابته برمجياً بشكل صريح.
فيما يلي مثال مبسط للتنسيق، يوضح المنطق الهيكلي لـ "توليد صورة أساسية أولاً، ثم توليد سلسلة صور باستخدام الصورة المرجعية".
from openai import OpenAI
# base_url يشير إلى APIYI، لإدارة مفاتيح النماذج المتعددة مركزياً
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "أسلوب رسوم توضيحية مسطحة، اللون الأساسي أزرق داكن وكهرماني، الشخصية مهندسة بشعر قصير" # قائمة وصف الشخصية
shots = ["غلاف: الشخصية تقف أمام مركز البيانات", "عملية: الشخصية ترسم الهيكل على السبورة", "خلاصة: الشخصية ترفع إبهامها"]
# 1. توليد الصورة الأساسية أولاً، لتثبيت أسلوب المجموعة بالكامل
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. كل صورة لاحقة تحمل قيد الأسلوب الموحد (يمكنك في المستوى المتقدم تمرير base كصورة مرجعية لواجهة التعديل)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
لمساعدتك على الاختيار السريع، يقارن الجدول التالي بين خصائص الطرق الثلاث وسيناريوهات تطبيقها.
| الطريقة | قوة الاتساق | تكلفة التنفيذ | سيناريو التطبيق |
|---|---|---|---|
| تقييد الموجه | متوسطة | منخفضة | توحيد الأسلوب يكفي، الشخصية ليست صارمة |
| تمرير الصورة المرجعية | عالية | متوسطة | ظهور متكرر لنفس الشخصية/المنتج |
| تنسيق الوكيل (Agent) | الأعلى | عالية | كتب مصورة، رسوم توضيحية متسلسلة، مواد العلامة التجارية |
يمكن دمج الطرق الثلاث: استخدم الموجه لتحديد النغمة، والصورة المرجعية لتثبيت الشخصية، والتنسيق للتحكم في الهيكل. ننصح بالبدء بـ "الموجه الموحد + الصورة المرجعية"، وبعد نجاح التجربة انتقل إلى التنسيق الكامل. في APIYI (apiyi.com)، تشترك نماذج مثل gpt-image-2 وgpt-image-1.5 في نفس base_url ومفتاح API، مما يسهل عليك تبديل النماذج لإجراء اختبارات مقارنة الاتساق دون الحاجة لتعديل الكود.
5. تكلفة توليد الصور المتعددة عبر GPT Image واختيار النموذج
توليد الصور في مجموعات يعني استدعاءات متعددة، مما يضاعف التكلفة، لذا فإن اختيار النموذج المناسب أمر بالغ الأهمية. تتوفر حالياً عدة فئات من سلسلة GPT Image للاستخدام في بيئات الإنتاج، ولكل منها تركيز مختلف:
| النموذج | التموضع | دعم التفكير المنطقي | سيناريوهات الصور المتعددة المناسبة |
|---|---|---|---|
| gpt-image-2 | رائد، مع تفكير مدمج | نعم (Thinking) | مواد تسويقية عالية الجودة، ملصقات تحتوي على نصوص |
| gpt-image-1.5 | الجيل السابق الرائد | جزئي | توليد دفعات توازن بين الجودة والتكلفة |
| gpt-image-1 | كلاسيكي ومستقر | لا | صور توضيحية عادية ذات نمط بسيط |
| gpt-image-1-mini | خفيف ومنخفض التكلفة | لا | كميات كبيرة، متطلبات جودة منخفضة |
يجب أن تكون على دراية تامة بالتكاليف: يتم احتساب تكلفة الصور المتعددة "تراكمياً حسب عدد الصور". على سبيل المثال، بدقة 1024×1024، يتراوح سعر الصورة الواحدة بين أجزاء من السنت إلى سنتين أو أكثر (يرجى مراجعة الأسعار اللحظية الرسمية للمنصة)، لذا فإن مجموعة من 5 صور تعني دفع ثمن 5 صور. إذا كنت تخطط لإنتاج الآلاف، فستكون التكلفة كبيرة، ومن الضروري تقديرها مسبقاً.
نصيحتنا هي: استخدم نموذج mini أو الفئات منخفضة الجودة في مرحلة المسودة للتحقق السريع من التكوين واتساق الوجوه، ثم استخدم gpt-image-2 في مرحلة الاعتماد النهائي للحصول على صور عالية الجودة. هذا المزيج من "تجربة منخفضة التكلفة + اعتماد نهائي عالي الجودة" يقلل الفاتورة مع ضمان النتائج. توفر APIYI (عبر apiyi.com) لوحة تحكم موحدة للاستهلاك، حيث يمكنك رؤية تكلفة استدعاءات الصور والنماذج المستخدمة بوضوح، وهو أمر مثالي للفرق التي تحتاج إلى ضبط النفقات.
6. الأسئلة الشائعة (FAQ)
س1: هل يمكن لـ API توليد مجموعة من الصور المختلفة في استدعاء واحد؟
لا، لا يمكن الاعتماد على معامل n لهذا الغرض. فالمعامل n يقوم فقط بأخذ عينات عشوائية لنفس الموجه (مثل سحب البطاقات)، والمحتوى يكون متطابقاً تقريباً. التوليد الحقيقي للمجموعات يتطلب تنسيقاً على مستوى التطبيق: تقسيم المتطلبات، استدعاءات متعددة، ثم فرض قيود الاتساق.
س2: ما هي التقنية المستخدمة في نسخة الويب من ChatGPT لتوليد الصور؟
ليست تقنية سرية، بل هي ميزة التفكير الوكيل (Agentic) المدمجة في GPT Image 2. حيث يقوم النموذج قبل التوليد بالتخطيط لـ "عدد الصور المطلوبة وما يجب رسمه في كل منها"، ثم يولدها واحدة تلو الأخرى. في جوهرها، تظل عملية استدعاءات متعددة، لكن عملية التخطيط تكون شفافة للمستخدم.
س3: ما هي الطريقة الأكثر فعالية لضمان اتساق الصور المتعددة؟
من الناحية العملية، يعد استخدام الصورة المرجعية هو الأكثر استقراراً: قم بتمرير أول صورة مرضية كصورة مرجعية في كل استدعاء لاحق؛ حيث يكون استعادة الشخصيات وتنسيق الألوان أفضل بكثير من الوصف النصي وحده. أضف إلى ذلك وصفاً ثابتاً للنمط، وستحصل على نتائج أفضل. يمكنك تجربة ذلك مباشرة عبر واجهة الصورة المرجعية لنموذج gpt-image-2 على APIYI (apiyi.com).
س4: هل توليد الصور المتعددة مكلف جداً؟
يعتمد ذلك على عدد الصور، الدقة، وفئة الجودة، لأن المحاسبة تراكمية. ننصح باستخدام نماذج خفيفة للمسودات ونماذج رائدة للاعتماد النهائي، مع مراقبة النفقات عبر لوحة تحكم المنصة.
س5: أي نموذج هو الأكثر توفيراً لتوليد الصور المتعددة؟
للسعي وراء الجودة وعرض النصوص، اختر gpt-image-2؛ ولتحقيق توازن في التكلفة، اختر gpt-image-1.5؛ أما للكميات الكبيرة ذات المتطلبات البسيطة، فاستخدم gpt-image-1-mini. عند استخدام نفس الواجهة البرمجية، يكون الانتقال بين النماذج شبه مجاني.
7. الخلاصة
بالعودة إلى السؤال الأصلي: لماذا يختلف أداء النموذج نفسه بين واجهة API التي تبدو كأنها "سحب بطاقات عشوائي" وبين إصدار الويب الذي يولد مجموعات صور متناسقة؟ السر لا يكمن في النموذج بحد ذاته، بل في طريقة الاستدعاء. فالمعامل n في مستوى النموذج يقوم فقط بأخذ عينات دفعية لحل مشكلة "توفير عدة خيارات"، بينما توليد مجموعات الصور عبر GPT Image هو في الحقيقة عملية تنسيق ذكية (Agentic Orchestration) على مستوى التطبيق، تعتمد على تقسيم الطلبات، والاستدعاءات المتعددة، وفرض قيود الاتساق لدمج النتائج معاً.
يظل "اتساق الوجوه" (أو اتساق الصور المتعددة) هو التحدي الأصعب في هذا المجال. ولحسن الحظ، نمتلك ثلاث أدوات فعالة: جدول وصف الشخصية الموحد لتحديد النمط العام، استخدام صورة مرجعية لتثبيت ملامح الشخصية، وتنسيق الحلقات عبر الوكيل (Agent) للتحكم في الهيكل؛ حيث يؤدي دمج هذه الأدوات الثلاثة إلى نتائج تقترب بشكل كبير من تجربة إصدار الويب. وتكمن قيمة GPT Image 2 في دمج قدرات التنسيق هذه مباشرة داخل حلقة استدلال النموذج، مما يتيح للمستخدمين العاديين الاستفادة منها بسهولة.
قد لا يكون لهذا الموضوع إجابة نموذجية واحدة، فهو أقرب إلى كونه مشاركة للخبرات العملية، ونأمل أن يساعدك هذا في تجنب بعض العقبات. إذا كنت ترغب في تجربة كل طريقة ذكرناها، فإن APIYI (apiyi.com) يوفر واجهة موحدة ولوحة تحكم لاستهلاك نماذج مثل gpt-image-2 وgpt-image-1.5، مما يجعله نقطة انطلاق مريحة لإجراء تجارب توليد الصور ومقارنة التكاليف. لمزيد من التفاصيل حول الربط البرمجي، يمكنك الرجوع إلى مركز المساعدة help.apiyi.com.
هذا المحتوى هو مادة نقاشية أعدها فريق APIYI التقني بناءً على ممارسات دعم العملاء، يرجى الرجوع إلى المعلومات الرسمية والآنية للمنصة فيما يخص مواصفات النماذج والأسعار.