تلقيت مؤخرًا سؤالاً متكررًا من أحد المطورين العملاء: "لماذا يستغرق توليد صورة بحجم 1024×1024 باستخدام gpt-image-2 أكثر من 200 ثانية؟ هل هناك قيود على السرعة؟". عند فحص الكود الخاص به، وجدت أن المعاملات مضبوطة افتراضيًا على quality="high" و size="1536x1024"، مما يجعل استغراق 235 ثانية للصورة الواحدة أمراً طبيعياً تماماً.

يُعد gpt-image-2 الجيل الجديد من نماذج الصور الذي أطلقته OpenAI رسمياً في 21 أبريل 2026، وهو أول نموذج يدمج قدرات الاستنتاج (التفكير الوكيل) في عملية توليد الصور. وهذا يعني أن الطلبات التي تستخدم quality="high" تمر بأربع مراحل كاملة: "الفهم – التخطيط – التوليد – التدقيق"، مما يجعل الوقت المستغرق أطول بـ 30 إلى 50 مرة مقارنة بـ quality="low". في هذا المقال، ومن خلال خبرتنا العملية في الإنتاج، سنوضح المعاملات الثلاثة الأكثر أهمية لمساعدتك في العثور على التوازن الأمثل بين جودة الصورة والسرعة.
جدول سريع للمعاملات الأساسية لاستدعاء gpt-image-2
إليك الخلاصة. يغطي الجدول أدناه جميع المعاملات المهمة لنموذج gpt-image-2 في حزمة OpenAI Python SDK وتأثيرها على وقت الاستجابة والتكلفة. ننصحك بالرجوع لهذا الجدول عند إجراء التحسينات.
| المعامل | القيم المتاحة | القيمة الافتراضية | التأثير على الوقت | التأثير على التكلفة |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
كبير جداً | كبير جداً |
size |
1024x1024 / 1536x1024 / 1024x1536 / أي حجم ≤ 2K |
1024x1024 |
كبير | متوسط |
output_format |
png / jpeg / webp |
png |
صغير | لا يوجد |
output_compression |
0–100 (فعال فقط مع jpeg/webp) | 100 | صغير جداً | لا يوجد |
n |
1–10 | 1 | يتناسب طردياً | يتناسب طردياً |
background |
transparent / opaque / auto |
auto |
صغير | لا يوجد |
prompt |
نص (string) | مطلوب | التعقيد يؤثر على وقت الاستنتاج | يؤثر على الرموز (tokens) المدخلة |
المنطق الأساسي لفهم هذا الجدول هو: quality و size هما خط الدفاع الأول، فهما يحددان مباشرة مسار الاستنتاج الذي يسلكه النموذج، وعدد الرموز (tokens) التي يتم توليدها، وحجم القوة الحوسبية البصرية المستهلكة. أما output_format و output_compression فهما يتعلقان بطبقة التسلسل (Serialization) فقط، وتعديلهما لن يسرع من عملية التوليد.
🎯 نصيحة جوهرية: إذا كانت طبيعة عملك تسمح، قم بتغيير
quality="auto"إلىlowأوmediumبشكل صريح. هذه الخطوة وحدها غالباً ما تقلص وقت الاستجابة من دقائق إلى ثوانٍ. عند استدعاءgpt-image-2عبر خدمة وكيل API من APIYI (apiyi.com)، يتم تمرير جميع هذه المعاملات كما هي، وتعمل بنفس سلوك نقاط النهاية الرسمية لـ OpenAI.
عاملان أساسيان يؤثران على زمن استجابة gpt-image-2: quality و size
لفهم سبب وجود فرق يصل إلى عشرات الأضعاف بين إعدادي high و low، يجب أولاً فهم مسار التنفيذ في gpt-image-2، وهو الاختلاف الجوهري بينه وبين الجيل السابق gpt-image-1.
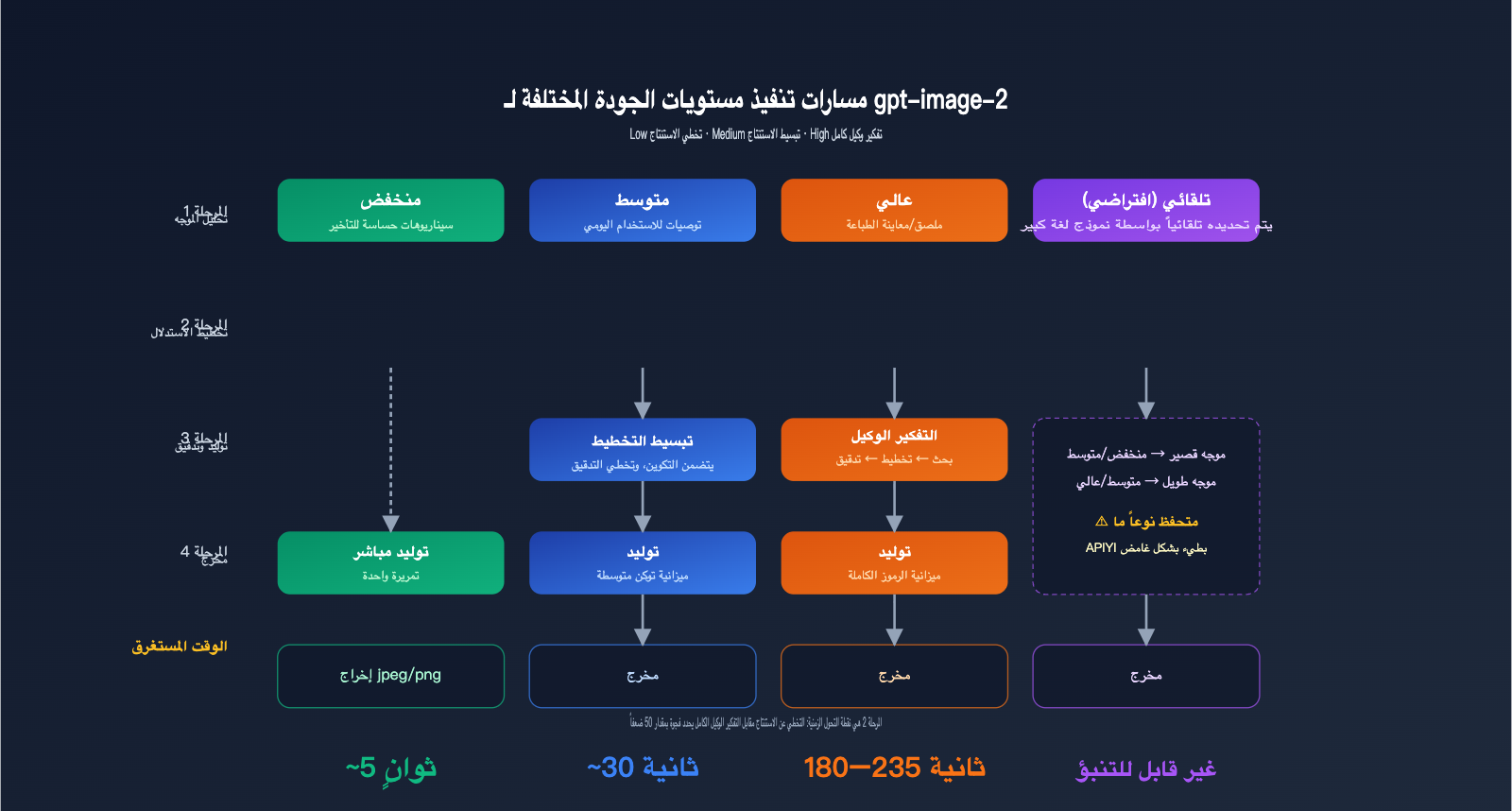
آلية عمل معامل quality
توضح الوثائق الرسمية لـ gpt-image-2 أن quality="low" مخصص للسيناريوهات الحساسة للوقت، حيث يوفر استجابة في غضون ثوانٍ مع الحفاظ على جودة بصرية مقبولة. في المقابل، يقوم quality="high" بتفعيل سلسلة تفكير (Agentic Chain) كاملة، حيث يقوم النموذج داخلياً بتخطيط التكوين، وتخطيط توزيع النصوص، وتخطيط منطق الإضاءة والظلال قبل البدء في الرسم. هذه المرحلة الاستنتاجية غير مرئية للمستخدم، لكنها تستهلك حوالي 70-80% من إجمالي وقت التنفيذ.
أما quality="medium" فهو خيار وسيط، يحتفظ بنسخة مبسطة من التخطيط مع تخطي التدقيق الدقيق. وبالنسبة لـ quality="auto"، فعند عدم تحديده، يختار النموذج تلقائياً بناءً على تعقيد الموجه (prompt)، لكن الاختبارات العملية تظهر ميلاً محافظاً لاختيار medium أو high، وهو ما يفسر اعتقاد العديد من المطورين أن "الوضع الافتراضي بطيء".
آلية عمل معامل size
يدعم gpt-image-2 أصلياً ثلاث قياسات قياسية: 1024x1024، 1536x1024، و 1024x1536، بالإضافة إلى خيار auto للتقدير التلقائي. كما يدعم إدخال قياسات مخصصة طالما أن إجمالي البكسلات لا يتجاوز 2K (أي حوالي 3.69 مليون بكسل)، وتجاوز هذا الحد يدخل في نطاق تجريبي حيث تنخفض استقرار النتائج.
تحدد كمية البكسلات مباشرة عدد الرموز البصرية (Visual Tokens). فقياس 1024x1024 يعادل حوالي 1024 رمزاً بصرياً، بينما يرتفع 1536x1024 إلى حوالي 1536 رمزاً. مضاعفة عدد الرموز تعني مضاعفة وقت الاستنتاج والتوليد، بالإضافة إلى مضاعفة تكلفة الاستدعاء.
| القياس القياسي | إجمالي البكسلات | الرموز البصرية (تقديري) | الوقت النسبي | سيناريوهات الاستخدام |
|---|---|---|---|---|
1024x1024 |
1.05 مليون | ~1024 | 1.0× | عام، وسائل التواصل، صور مصغرة |
1536x1024 |
1.57 مليون | ~1536 | 1.5× | لافتات، أغلفة مقالات |
1024x1536 |
1.57 مليون | ~1536 | 1.5× | ملصقات، محتوى عمودي |
| مخصص ≤ 2K | حتى 3.69 مليون | حتى ~3686 | 2–3× | معاينة طباعة عالية الدقة |
🎯 نصيحة حول القياسات: في الإنتاج الفعلي، يُنصح باستخدام
1024x1024لـ 95% من الطلبات، والانتقال إلى سلسلة 1536 فقط عند الحاجة لنسب عرض خاصة. عند الاستدعاء عبر خدمة APIYI (apiyi.com)، يمكنك استخدام أي قياس مخصص، ولكن تذكر إبقاءه ضمن حدود 2K لضمان الاستقرار.
التأثير المزدوج للمعاملات
العلاقة بين quality و size هي علاقة ضرب وليست جمع. فاستخدام high مع 1536x1024 أبطأ بعشرات المرات من low مع 1024x1024. هذا الأمر حاسم في سيناريوهات التوازي (Concurrency)؛ فقد تظن أن تشغيل 10 طلبات متوازية سيمنحك صوراً في ثانية واحدة، لكن الواقع قد يستغرق 200 ثانية لإنتاج 10 صور، مما يؤدي إلى انتهاء مهلة عميل HTTP.
الأكثر خفاءً هو وجود اقتران ضمني بين quality وتعقيد الموجه (prompt). ففي وضع high، الموجه البسيط (مثل "تفاحة حمراء") قد يستغرق 100 ثانية، بينما الموجه المعقد (مثل "مدينة سايبربانك في ليلة ممطرة، لافتات نيون، سينمائي، تفاعل بين 6 شخصيات") قد يتجاوز 230 ثانية أو أكثر. يقوم النموذج بتوسيع ميزانية الرموز ديناميكياً بناءً على عدد العناصر في المشهد، لذا كلما زاد تعقيد الموجه، زاد وقت وضع high وزادت التكلفة.
🎯 نصيحة لكتابة الموجه: في وضع
high، يُنصح بالتحكم في طول الموجه ليكون أقل من 200 كلمة، مع وضع العناصر الأساسية في أول 50 كلمة. الوصف المطول لا يحسن الجودة بالضرورة، بل يطيل وقت الاستنتاج. هذه القاعدة تنطبق أيضاً عند الاستدعاء عبر APIYI (apiyi.com)، حيث تقوم خدمة الوكيل بتمرير الموجه بالكامل، مما يجعل سلوك النموذج مطابقاً للمصدر الرسمي.
مقارنة الأداء والتكلفة لمستويات الجودة في gpt-image-2
يستند الجدول أدناه إلى بيانات فعلية جمعناها عبر منصة APIYI (apiyi.com) خلال فترات زمنية متعددة وباستخدام "موجهات" (prompts) ذات مستويات تعقيد مختلفة. قد تختلف النتائج قليلاً بناءً على التوقيت أو "الموجه" أو حالة الشبكة، لكنها تعكس النطاق العام بدقة.
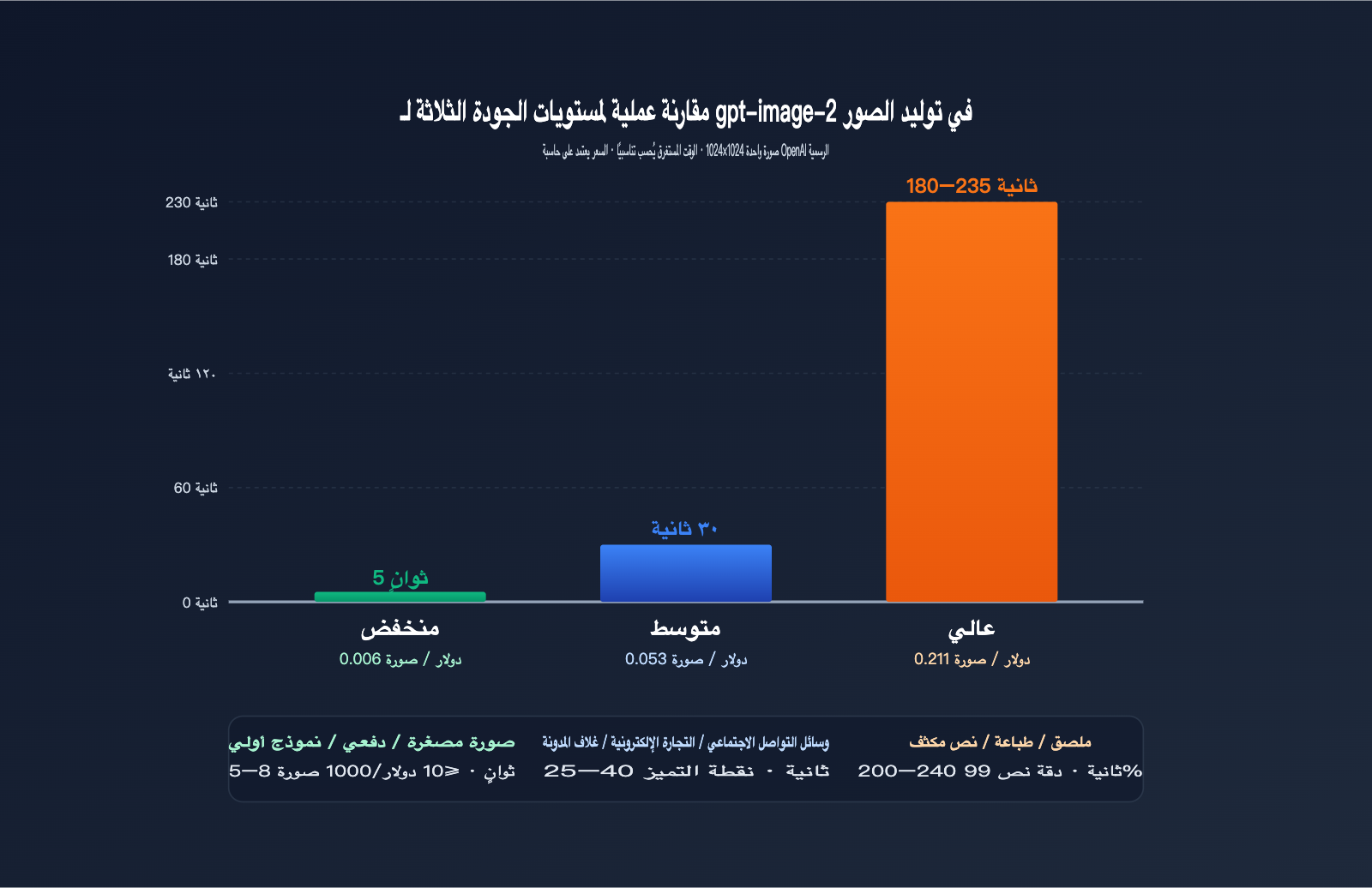
بيانات فعلية لدقة 1024×1024
| الجودة | متوسط وقت الاستجابة | السعر (دولار/صورة) | الدقة البصرية | دقة النصوص | سيناريوهات الاستخدام |
|---|---|---|---|---|---|
low |
3–8 ثوانٍ | $0.006 | متوسطة | عادية | الصور المصغرة، المعالجة الجماعية، اختبار النماذج الأولية |
medium |
20–40 ثانية | $0.053 | عالية | جيدة | وسائل التواصل، التجارة الإلكترونية، أغلفة المقالات |
high |
150–235 ثانية | $0.211 | عالية جداً | ممتازة (99%+) | الملصقات، الطباعة، الصور الغنية بالنصوص |
نلاحظ وجود علاقة غير خطية واضحة: الانتقال من low إلى medium يرفع السعر 9 أضعاف، لكن الوقت يزداد 5 أضعاف فقط؛ أما الانتقال من medium إلى high فيرفع السعر 4 أضعاف، بينما يزداد الوقت 6–7 أضعاف. بعبارة أخرى، التكلفة الهامشية لمستوى high تُدفع من خلال "وقت الانتظار".
إذا كان عملك لا يتطلب دقة نصوص بنسبة 99% (مثل الرسوم التوضيحية أو التصاميم التجريدية)، فإن مستوى medium كافٍ تماماً ويوفر المال والوقت. فقط في حالات مثل الملصقات وتصاميم الهوية التجارية ومعاينات الطباعة، يستحق الأمر انتظار 200 ثانية للحصول على جودة high.
🎯 نصيحة لتقدير التكلفة: قبل إطلاق الخدمة في بيئة الإنتاج، ننصحك بتجربة 100 صورة لكل مستوى (low/medium/high) عبر APIYI (apiyi.com)، وإعداد تقرير داخلي للمقارنة بين توزيع الأوقات والأسعار وجودة الصور، ثم اتخاذ القرار بشأن المستوى المناسب لحركة المرور الأساسية. لن تتجاوز تكلفة الاختبار 30 دولاراً، لكنها ستحميك من انهيار اتفاقية مستوى الخدمة (SLA) بسبب الطلبات البطيئة.
فرق التوقيت بين 1024×1024 و 1536×1024
بالنسبة لمستوى medium، يستغرق 1024×1024 متوسط 25 ثانية، بينما يستغرق 1536×1024 حوالي 38 ثانية، وهو ما يتوافق مع زيادة عدد الرموز البصرية (visual tokens) بنسبة 1.5. لكن في مستوى high، يتضاعف هذا الفارق؛ حيث يستغرق high + 1024×1024 حوالي 180 ثانية، بينما قد يتجاوز high + 1536×1024 حاجز الـ 240 ثانية، خاصة في أوقات الذروة.
نطاق التذبذب في مستوى high
من المهم ملاحظة أن وقت الاستجابة في مستوى high ليس ثابتاً، بل يتبع توزيعاً واسعاً. قمنا بأخذ عينات لـ 200 طلب من نوع high + 1024×1024، وكان أسرعها 145 ثانية، وأبطؤها 280 ثانية، بمتوسط حوالي 195 ثانية. يعود هذا التذبذب لعاملين: الأول هو تعقيد "الموجه" الذي يغير ميزانية الاستدلال المطلوبة، والثاني هو حمل خوادم OpenAI في أوقات مختلفة. لذا، لا تستخدم استدعاءات متزامنة (synchronous) لمستوى high؛ بل اجعلها مهام غير متزامنة (asynchronous)، حيث يعيد النظام معرف المهمة (Task ID) فوراً، ثم يقوم الطرف الخلفي بالاستعلام عن الحالة أو انتظار التنبيه.
مفهوم خاطئ شائع: الدقة الأعلى تعني جودة أفضل
يعتقد الكثير من المطورين أن زيادة الدقة تعني جودة أفضل، فيختارون سلسلة 1536 افتراضياً. هذا خطأ؛ فنموذج gpt-image-2 يقدم أفضل أداء بصري عند 1024×1024 مع كفاءة عالية في استخدام البكسلات. الانتقال إلى سلسلة 1536 يغير أبعاد الصورة فقط، ولا يضيف تفاصيل حقيقية تظهر على الشاشة. ما لم تكن بحاجة ماسة لتكوين أفقي أو رأسي معين، فإن البقاء على 1024×1024 هو الخيار الأكثر اقتصادية وذكاءً.
دليل شامل لاستخدام Python SDK مع gpt-image-2
فيما يلي ثلاثة نماذج برمجية تبدأ من الاستدعاء الأساسي وصولاً إلى التغليف الجاهز للإنتاج، يمكنك اختيار ما يناسب احتياجاتك. تعتمد جميع الأمثلة على مكتبة OpenAI Python SDK الرسمية، مع توجيه base_url إلى خدمة وكيل API الخاص بـ APIYI (apiyi.com)، حيث يتطابق السلوك تماماً مع نقاط النهاية الرسمية.
مثال أساسي: تحويل نص إلى صورة (صورة واحدة)
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="مدينة سايبربانك في ليلة ممطرة، لافتات نيون، إطار سينمائي",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
هذا الكود كافٍ للتشغيل، لكن هناك فخ: استخدام quality="high" مع مهلة الانتظار (timeout) الافتراضية سيؤدي غالباً إلى فشل العملية. مهلة HTTP الافتراضية في SDK هي 600 ثانية، وهو ما يبدو كافياً، ولكن العديد من المستخدمين الذين يستخدمون requests أو httpx ويضبطون مهلة 60 ثانية سيواجهون خطأ ReadTimeout بشكل متكرر عند إرسال طلبات متعددة بجودة عالية.
مثال للإنتاج: ضبط المهلة وإعادة المحاولة
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
نصائح عملية:
timeout=300هي قيمة آمنة للجودة العالية (high)، وتغطي 99% من الطلبات؛ إذا كنت تستخدم الجودة المنخفضة (low) أو المتوسطة (medium)، يمكنك تقليلها إلى 60 ثانية.max_retries=2تستخدم آلية التراجع الأسي المدمجة في SDK، وهي أكثر استقراراً من كتابة منطق إعادة المحاولة يدوياً.output_format="jpeg"معoutput_compression=85يمكن أن يقلل حجم ملف PNG بنسبة 60–70%، مع جودة بصرية يصعب تمييزها بالعين، وهو موصى به بشدة للصور المصغرة على الويب.
🎯 نصيحة حول المهلة: عند الاستدعاء عبر APIYI، قامت المنصة بالفعل بتحسين استمرارية الاتصال للطلبات طويلة الأمد، ولكن يجب عليك ضبط
timeoutفي SDK الخاص بك ولا تعتمد على القيم الافتراضية. للجودة العالية، نوصي بـ 240 ثانية على الأقل، وللجودة المنخفضة يمكن تقليصها إلى 30 ثانية لتجنب حجز مجموعة الاتصالات بطلبات معلقة.
مثال للعمليات المجمعة: التوليد المتزامن غير المتزامن (Async)
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["قطة", "كلب", "طائر", "سمكة", "أرنب"] * 4))
التنفيذ المتزامن هو أهم مهارة لتوليد الصور بكميات كبيرة. الجودة المنخفضة (low) تستغرق 5 ثوانٍ للطلب الواحد، لذا فإن معالجة 20 صورة بالتسلسل تستغرق 100 ثانية؛ بينما باستخدام 5 مسارات متزامنة تستغرق 20 ثانية فقط. لكن احذر من قفل الجودة على low أو medium؛ فاستخدام الجودة العالية (high) بالتزامن سيؤدي إلى انهيار المهلة.
توصيات المعاملات لـ gpt-image-2 في سيناريوهات الأعمال
بعد الاطلاع على الجانب النظري، إليك أفضل مجموعات المعاملات للسيناريوهات الأكثر شيوعاً:
| سيناريو العمل | quality | size | output_format | الوقت المتوقع | السعر |
|---|---|---|---|---|---|
| صور المنتجات، Banner | medium | 1024×1024 | jpeg+85 | 25–35 ثانية | $0.053 |
| صور وسائل التواصل | medium | 1024×1536 | jpeg+85 | 30–40 ثانية | ~$0.06 |
| غلاف مقال، مدونة | medium | 1536×1024 | webp+90 | 30–40 ثانية | ~$0.06 |
| ملصقات، معاينة طباعة | high | 1024×1536 | png | 200–240 ثانية | ~$0.21 |
| ترجمة/غلاف عرض تقديمي | high | 1536×1024 | png | 200–240 ثانية | ~$0.21 |
| صور مصغرة، اختبار نماذج | low | 1024×1024 | jpeg+75 | 3–8 ثوانٍ | $0.006 |
| مسودات مجمعة | low | 1024×1024 | jpeg+75 | 3–8 ثوانٍ × N | $0.006 × N |
| توليد فوري في مساعد AI | low | 1024×1024 | webp+85 | 5–10 ثوانٍ | $0.006 |
السيناريو الأول: التجارة الإلكترونية ووسائل التواصل – الجودة المتوسطة (medium) هي الخيار الأمثل
تتطلب هذه الصور سرعة في الاستجابة، والجودة المتوسطة توفر توازناً ممتازاً بين الوضوح والسرعة (حوالي 30 ثانية).
السيناريو الثاني: الملصقات ومعاينة الطباعة – استثمر الوقت في الجودة العالية (high)
تتطلب هذه المهام دقة عالية وتفاصيل دقيقة، لذا لا تحاول تقليص الوقت. قم بإبلاغ المستخدم بأن العملية ستستغرق 3–5 دقائق.
السيناريو الثالث: العمليات المجمعة والنماذج الأولية – الجودة المنخفضة (low)
لأي سيناريو يتطلب توليد آلاف المسودات، استخدم الجودة المنخفضة حصراً مع المعالجة المتزامنة.
السيناريو الرابع: التفاعل الفوري مع المستخدم – الجودة المنخفضة أو المتوسطة
في روبوتات الدردشة، لا تستخدم الجودة العالية أبداً؛ لأن انتظار المستخدم لمدة 4 دقائق سيؤدي إلى مغادرته. استخدم الجودة المنخفضة مع رسوم متحركة "جاري التحميل".
السيناريو الخامس: مراجعة المحتوى وإعادة التوليد
إذا تم حظر الطلب بواسطة سياسات المحتوى، جرب أولاً الجودة المنخفضة للتأكد من أن الموجه (prompt) مقبول، ثم انتقل للجودة الأعلى. هذا يقلل التكاليف المهدرة في حال الرفض.
🎯 استراتيجية هجينة: تعتمد العديد من الأنظمة "التوليد المزدوج"؛ حيث يتم توليد صورة معاينة سريعة (low) للمستخدم، وعند اختياره لها، يتم توليد النسخة النهائية بجودة عالية (high). هذه الاستراتيجية تعمل بسلاسة تامة على APIYI.
الأسئلة الشائعة (FAQ)
س1: لماذا تنتهي طلبات فئة high الخاصة بي بمهلة زمنية (Timeout) دائمًا؟
المهلة الزمنية الافتراضية في مكتبة OpenAI Python هي 600 ثانية، وهي كافية نظرياً، لكن العديد من الأطر البرمجية (مثل FastAPI، Flask، Celery) تضيف مهلة زمنية خاصة بها في الطبقات الخارجية. يرجى التحقق من إعدادات المهلة في كل طبقة من سلسلة الاستدعاء بالكامل، ونوصي بتخصيص 300 ثانية على الأقل لكامل مسار فئة high. إذا كنت تستخدم httpx، تذكر ضبط httpx.Timeout(300.0) بشكل صريح.
س2: ما هي القيمة المثالية لـ output_compression؟
بالنسبة لتنسيق jpeg، تعتبر القيمة 85 هي "النقطة الذهبية"؛ حيث لا يمكن للعين المجردة ملاحظة فرق عن القيمة 100، بينما يقل حجم الملف بنسبة 30–40%. أما في تنسيق webp، فإن القيمة 90 تعد خياراً شائعاً أيضاً. القيم الأقل من 70 ستؤدي إلى ظهور كتل لونية واضحة، خاصة في المناطق ذات الخلفيات المتدرجة. لا يؤثر هذا المعامل على وقت التوليد، بل يؤثر فقط على المخرجات المتسلسلة النهائية.
س3: هل هناك فرق عند استدعاء gpt-image-2 عبر APIYI (apiyi.com) مقارنة بالنقاط الطرفية الرسمية؟
يتم تمرير المعاملات والسلوكيات بالكامل كما هي، بما في ذلك جميع الحقول مثل quality، size، output_format، output_compression، n، وbackground. الفرق يكمن في أن APIYI (apiyi.com) يوفر عقدًا عالية السرعة يمكن الوصول إليها محلياً، ونظام فوترة موحد، ومحاسبة حسب الاستخدام دون حد أدنى للاستهلاك، مما يجعله أكثر ملاءمة للمطورين.
س4: هل يمكن للمعامل n إرجاع عدة صور في وقت واحد؟
نعم، يدعم gpt-image-2 القيم من n=1 إلى n=10. ولكن انتبه، فإن إجمالي الوقت المستغرق لإرجاع صور متعددة هو حوالي 0.7–0.9 ضعف وقت الصورة الواحدة مضروباً في n (ليس توازياً تاماً)، ويتم احتساب السعر الإجمالي بناءً على n. إذا كنت بحاجة إلى "مجموعة من الشخصيات المتسقة"، استخدم n=4 للسماح للنموذج بإخراج الصور في استنتاج واحد، فهذا أكثر استقراراً من إجراء 4 استدعاءات منفصلة، لأن gpt-image-2 يمكنه الحفاظ على اتساق الوجوه ضمن الاستنتاج الواحد.
س5: ما هي الفئة التي يتم اختيارها فعلياً عند ضبط quality="auto"؟
أظهرت الاختبارات العملية أن auto يميل إلى اختيار medium أو high، اعتماداً على طول الموجه (prompt) وتعقيده. الموجهات القصيرة (مثل "قطة") غالباً ما تختار low/medium، بينما الموجهات الطويلة (التي تحتوي على شخصيات، مشاهد، نصوص، أو أنماط) غالباً ما تختار high. في بيئة الإنتاج، نوصي بتحديد الفئة صراحةً وعدم الاعتماد على التقدير الضمني لـ auto.
س6: أي دقة أفضل: 1024×1536 أم 1536×1024؟
كلاهما يحتوي على نفس عدد البكسلات الإجمالي (حوالي 1.57 مليون)، لذا فإن جودة الصورة متطابقة جوهرياً. الفرق يكمن فقط في نسبة العرض إلى الارتفاع؛ فالشاشة الرأسية (1024×1536) مناسبة للملصقات، وصور الشخصيات كاملة الطول، والمحتوى المخصص للأجهزة المحمولة، بينما الشاشة الأفقية (1536×1024) مناسبة للافتات، والمناظر الطبيعية، وأغلفة أجهزة الكمبيوتر. اختر ما يناسب احتياجات التكوين الفني لديك، فهذا لا يؤثر على السرعة أو السعر.
س7: هل يمكنني تخطي الاستنتاج والوصول إلى النموذج الأساسي مباشرة؟
لا، استنتاج الوكيل (Agentic) في gpt-image-2 هو جزء لا يتجزأ من بنية النموذج ولا يمكن إيقافه. إذا كنت تحتاج فقط إلى توليد سريع بأسلوب SD التقليدي ولا تحتاج إلى معالجة النصوص أو الاستنتاج، فننصح باستخدام فئة low، حيث تتخطى سلسلة الاستنتاج الكاملة. أو يمكنك التفكير في نموذج nano-banana-pro من Google، حيث أن فئته السريعة أسرع من gpt-image-2 low، وقد أتاحته APIYI (apiyi.com) بالفعل.
🎯 نصيحة حول استخدام نماذج متعددة: لا تعتمد أنظمة توليد الصور المتطورة عادةً على نموذج واحد فقط. نوصي باستخدام nano-banana-pro للمعاينة السريعة (استجابة في حدود 5 ثوانٍ)، واستخدام gpt-image-2 medium لإنتاج الصور الرئيسي، وgpt-image-2 high للمشاهد عالية الجودة. النماذج الثلاثة تشترك في نفس مفتاح API على منصة APIYI (apiyi.com) وتُحاسب حسب الاستخدام، مما يجعلها المجموعة الأكثر فعالية من حيث التكلفة لدمج واجهات برمجة تطبيقات الصور في عام 2026.
الخلاصة: تعامل مع المعاملات كمفاتيح للأداء، وليس كزينة
تختلف فلسفة تصميم gpt-image-2 تماماً عن نماذج الصور من الجيل السابق؛ فهي تجعل الاستنتاج خطوة أساسية في توليد الصور، لذا لم يعد quality مجرد خيار بسيط لـ "جودة الصورة"، بل هو مفتاح لتحديد "مدى عمق مسار الاستنتاج". بمجرد فهمك لهذه النقطة، ستدرك لماذا يمكن لنفس واجهة برمجة التطبيقات أن تتراوح في زمن التنفيذ بين 5 ثوانٍ و235 ثانية، أي بفارق 50 ضعفاً.
في التطبيق العملي، ننصح بجعل "اختيار المعاملات" الخطوة الأولى في تصميم عملك: حدد أولاً مقدار التأخير الذي يمكن أن يتحمله المشهد، ومستوى الجودة المطلوب، والحد الأقصى للسعر، ثم اختر quality وsize من الجدول. تحديد هذه المعاملات مسبقاً يوفر عليك الكثير من العناء مقارنة بضبطها بعد الإطلاق.
🎯 نصيحة أخيرة: عند البدء في دمج gpt-image-2، نوصي بالتسجيل عبر APIYI (apiyi.com) وإجراء اختبار مقارنة للفئات الثلاث low/medium/high، وتقييم وقت التنفيذ الفعلي والجودة، ثم اتخاذ القرار بشأن المعاملات الرئيسية. مفتاح واحد يغطي الفئات الثلاث، مع محاسبة حسب الاستخدام وبدون حد أدنى، هو الطريقة الأكثر كفاءة لدمج واجهات برمجة تطبيقات الصور في عام 2026.
— فريق APIYI التقني | نتابع باستمرار تطورات نماذج توليد الصور، لمزيد من الدروس المتعمقة تفضل بزيارة مركز مساعدة APIYI على apiyi.com