ملاحظة من الكاتب: أطلقت APIYI نموذج gpt-image-2-all عبر خدمة وكيل API، بتكلفة 0.03 دولار لكل استدعاء دون قيود على التزامن. يدعم النموذج تحويل النص إلى صورة، دمج صور متعددة، وتعديل الصور باللغة الطبيعية، مع مطابقة تامة لقدرات التوليد في إصدار ChatGPT عبر الويب. إليك الدليل الكامل لكيفية الربط.
في أبريل 2026، بدأت نسخة ChatGPT عبر الويب في اختبار قدرات الجيل التالي لتوليد الصور (A/B testing). ورغم أن المستخدمين لا يزالون يرون وسم "GPT Image 1.5" في الواجهة، إلا أن بعض الطلبات تتم معالجتها فعلياً بواسطة النموذج الجديد. تجدر الإشارة إلى أن OpenAI لم تفتح بعد واجهة برمجة التطبيقات (API) الرسمية لنموذج gpt-image-2؛ لذا يجب توخي الحذر تجاه أي خدمة تدعي أنها "تستدعي gpt-image-2 مباشرة عبر API".
توفر APIYI الآن نموذج gpt-image-2-all رسمياً عبر حل "وكيل API"، وهو مطابق تماماً لقدرات التوليد في ChatGPT عبر الويب، بتكلفة 0.03 دولار لكل استدعاء وبدون قيود على التزامن. هذا ليس مجرد وعد، بل واجهة برمجية جاهزة للاستخدام في بيئات الإنتاج عبر طلبات HTTP القياسية.
القيمة الجوهرية: بعد قراءة هذا المقال، ستتقن التعامل مع 3 نقاط نهاية (Endpoints) لنموذج gpt-image-2-all ومهارات دمج الصور وتعديلها باللغة الطبيعية، وستتمكن من إتمام الربط في أقل من 10 دقائق.

النقاط الجوهرية لـ gpt-image-2-all
| القدرة | الوصف | القيمة |
|---|---|---|
| مطابقة ChatGPT | حل وكيل API متزامن مع القدرات الرسمية | لا حاجة لانتظار فتح API من OpenAI |
| الدفع لكل استدعاء | 0.03 دولار/استدعاء، لا قيود على الدقة/الجودة/الموجه | تكلفة شفافة وقابلة للتنبؤ |
| لا قيود على التزامن | لا يوجد حد لعدد الطلبات | مناسب لخطوط الإنتاج الضخمة |
| دمج صور متعددة | استخدام إشارات "صورة1/صورة2/صورة3" داخل الموجه | توليد متسق لعدة عناصر |
| تعديل باللغة الطبيعية | تحرير حواري دون الحاجة إلى قناع (Mask) | خفض عتبة التكرار بشكل كبير |
تفسير تموضع gpt-image-2-all
ماذا يعني "وكيل API"؟ هو حل وسيط يعتمد على الهندسة العكسية للوصول إلى أحدث قدرات توليد الصور في ChatGPT. إنه ليس نفس الواجهة التي ستفتحها OpenAI مستقبلاً تحت اسم gpt-image-2، لكن قدرات النموذج الأساسية متطابقة. قبل الإطلاق الرسمي للـ API من OpenAI، يعد هذا الحل الوحيد المستقر لاستدعاء أحدث قدرات توليد الصور في ChatGPT لبيئات الإنتاج.
لماذا يجب عليك الربط الآن؟ لثلاثة أسباب واقعية: (1) تاريخ إطلاق gpt-image-2 الرسمي من OpenAI غير محدد (من المتوقع بين أواخر أبريل ومنتصف مايو 2026)؛ (2) فترة الإطلاق الأولية ستشهد حتماً ضغطاً على الحصص ومشاكل في التشغيل الأولي؛ (3) من خلال إعداد سير عملك مسبقاً بناءً على gpt-image-2-all، ستحتاج فقط إلى تغيير اسم النموذج عند توفر الإصدار الرسمي، مما يضمن انتقالاً سلساً.
دليل البدء السريع لـ gpt-image-2-all
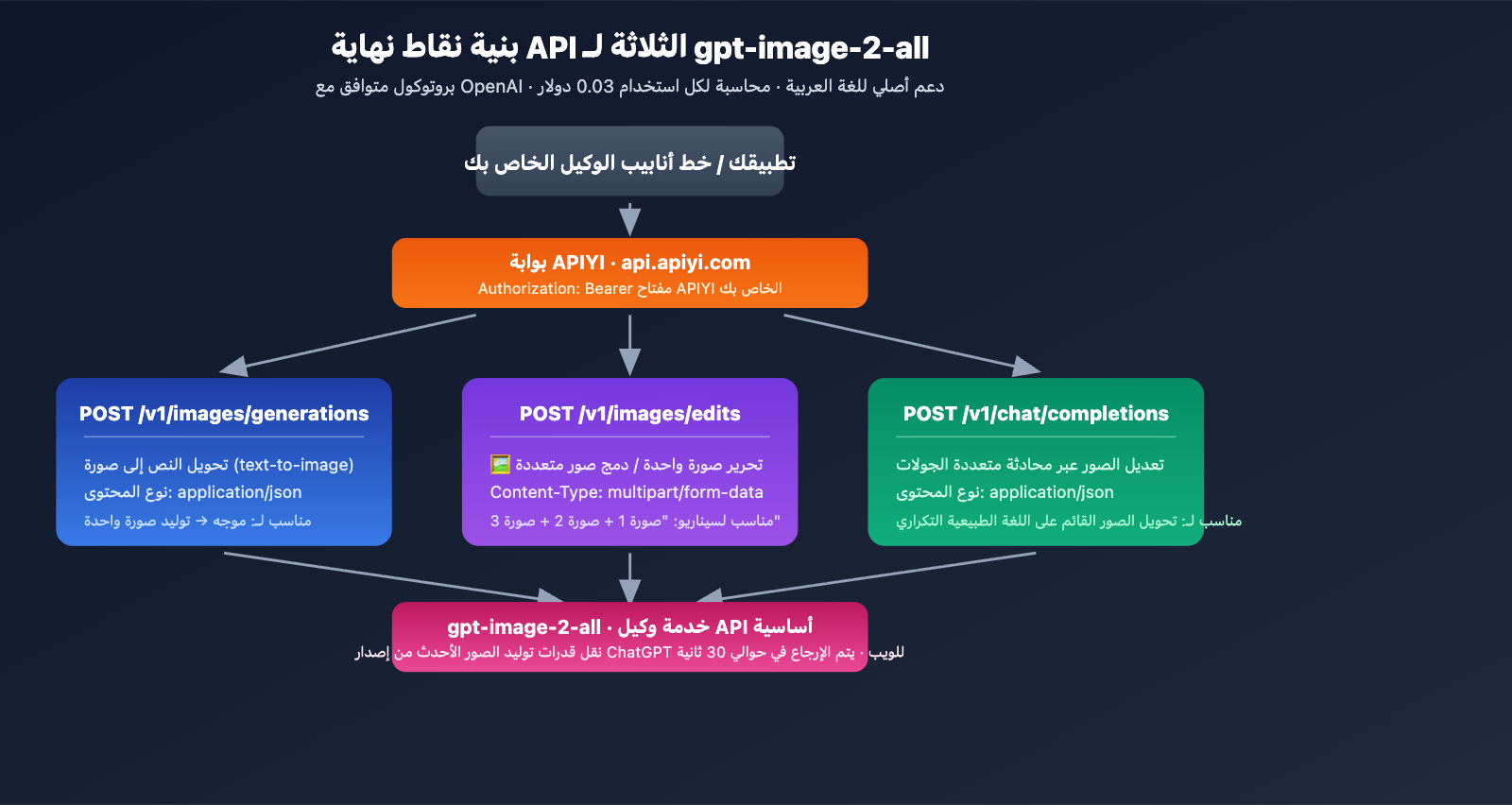
نقاط نهاية API الثلاث الرئيسية
يوفر gpt-image-2-all ثلاث نقاط نهاية تغطي سيناريوهات توليد الصور بالكامل:
| نقطة النهاية | الاستخدام | Content-Type |
|---|---|---|
POST /v1/images/generations |
تحويل النص إلى صورة | application/json |
POST /v1/images/edits |
تعديل صورة واحدة / دمج صور متعددة | multipart/form-data |
POST /v1/chat/completions |
تعديل الصور عبر الحوار متعدد الجولات | application/json |
رابط القاعدة (Base URL): https://api.apiyi.com (بدائل: b.apiyi.com، vip.apiyi.com)
مثال مبسط لتحويل النص إلى صورة
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "صورة أفقية 16:9 لكوب قهوة لاتيه، ملصق على الطاولة مكتوب عليه 'Morning Blend $4.50'، ضوء الصباح يتسلل عبر نافذة المقهى",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
عرض كود الربط الكامل (يتضمن معالجة الأخطاء، التزامن، دمج الصور، والتعديل عبر الحوار)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""تحويل النص إلى صورة: عبر نقطة النهاية /v1/images/generations"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""دمج صور متعددة: عبر نقطة النهاية /v1/images/edits"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""تعديل الصور عبر الحوار: عبر نقطة النهاية /v1/chat/completions"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("صورة رأسية 9:16 لملصق إعلاني لهاتف، كوب قهوة لاتيه مثلجة، نص في الأعلى 'Summer Sale 50% OFF'")
print(f"تم التوليد: {url}")
fusion_url = multi_image_fusion(
"ضع الشخص الموجود في الصورة 1 داخل مشهد الشاطئ في الصورة 2، مع الحفاظ على ملابس الشخص كما هي",
["person.png", "beach.png"]
)
print(f"الدمج: {fusion_url}")
نصيحة للربط: يمكنك الحصول على رصيد تجريبي عبر التسجيل في APIYI (apiyi.com). مفتاح واحد يدعم جميع النماذج مثل gpt-image-2-all، GPT-4o، وClaude، مما يوفر عليك تكاليف إدارة حسابات متعددة.
الميزات الرئيسية لـ gpt-image-2-all
الميزة الأولى: دقة عالية في عرض النصوص
بالنسبة لـ gpt-image-2-all، تعد استقرارية عرض النصوص باللغتين العربية والإنجليزية نقطة قوة أساسية في قدرات التوليد الرسمية الأحدث من ChatGPT. النصوص الموجودة على اللافتات، الملصقات، والرسوم البيانية تظهر بشكل صحيح من المرة الأولى، وهو أمر كان يصعب تحقيقه في الإصدارات السابقة.
سيناريوهات الاختبار:
- لوحة قائمة المقهى:
"Americano $4.00, Latte $4.50"دقة على مستوى الحرف. - تغليف المنتجات: جداول المكونات المختلطة بين العربية والإنجليزية واضحة ومقروءة.
- نماذج واجهة المستخدم (UI): عرض دقيق لنصوص الأزرار وتسميات التنقل.
- الرسوم البيانية: تسلسل هرمي واضح للعناوين، العناوين الفرعية، وتسميات البيانات.
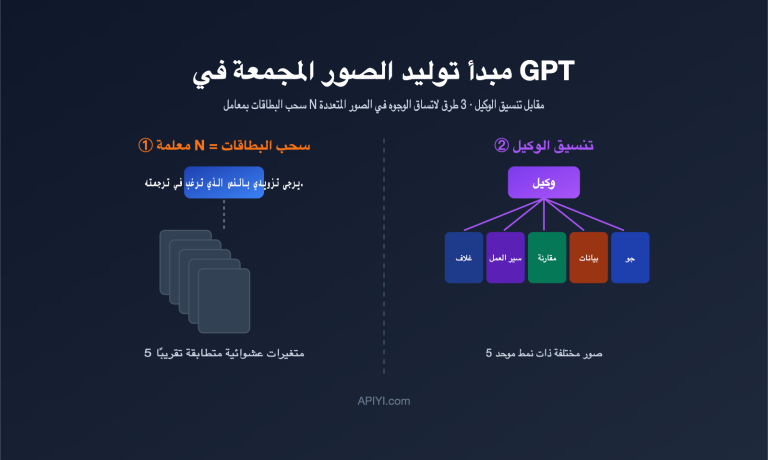
الميزة الثانية: قدرات دمج الصور المتعددة
من خلال نقطة النهاية /v1/images/edits يمكنك رفع صور مرجعية متعددة في وقت واحد، والإشارة إليها مباشرة في الموجه (prompt) باستخدام "الصورة 1"، "الصورة 2"، "الصورة 3".
prompt = """
ضع المنتج الموجود في الصورة 1 داخل المشهد في الصورة 2،
استخدم النمط اللوني للصورة 3،
زاوية الكاميرا من الأعلى قليلاً،
تفاصيل عالية الدقة 4K.
"""
سيناريوهات الاستخدام:
| السيناريو | طريقة العمل |
|---|---|
| صور التجارة الإلكترونية | صورة المنتج + صورة المشهد ← دمج واقعي |
| اتساق الوجوه والشخصيات | صورة الشخصية الأصلية + مشهد جديد ← زوايا تصوير متعددة |
| نقل النمط | صورة المحتوى + صورة النمط ← مخرجات منمقة |
| نظام الهوية البصرية | المنتج + الشعار + لوحة الألوان ← هوية بصرية موحدة |
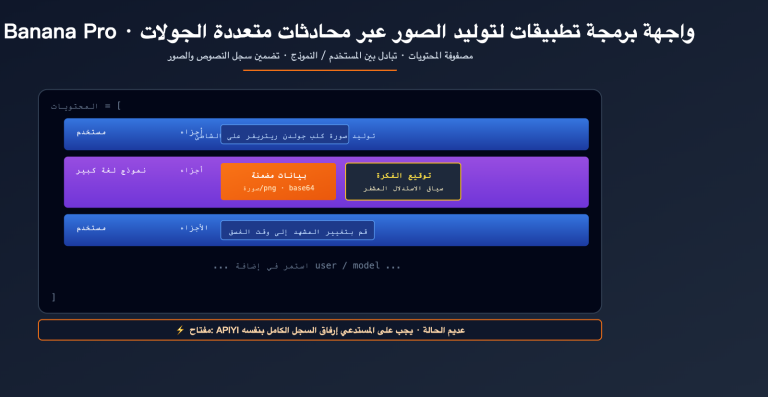
الميزة الثالثة: تعديل الصور باللغة الطبيعية (بدون الحاجة إلى أقنعة Mask)
أكبر قفزة في الكفاءة هي التعديل عبر الحوار، حيث لم تعد بحاجة لرسم أقنعة (mask) أو تحديد مناطق، بل يكفي وصف متطلبات التعديل باللغة الطبيعية.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "ولد صورة لمقهى من الخارج، ضوء شمس الظهيرة مائل"},
]
},
{
"role": "assistant",
"content": "[رابط الصورة المولد]"
},
{
"role": "user",
"content": "غير الطقس ليكون ممطراً، مع الحفاظ على المبنى كما هو"
}
]
ماذا يعني سير العمل هذا؟ بدلاً من دورة "توليد ← تعديل في فوتوشوب ← إعادة توليد"، أصبح الأمر الآن تكراراً عبر الحوار. كل تعديل يتطلب فقط وصف الفرق، دون الحاجة لإعادة كتابة الموجه بالكامل.
الميزة الرابعة: دعم أصلي للغة العربية
يمكن كتابة الموجه مباشرة باللغة العربية دون الحاجة لترجمته إلى الإنجليزية قبل الاستدعاء. بالنسبة لفرق التطوير العربية والأعمال المحلية، فهذه تجربة طبيعية وسلسة:
prompt = "غلاف لوسائل التواصل الاجتماعي بنسبة 9:16، فتاة بملامح شرقية تشرب القهوة، العنوان 'استكشاف مقاهي عطلة نهاية الأسبوع · مقهى سري في الحي'، نمط واقعي بإضاءة ناعمة"
التحكم في الأبعاد والنسب لـ gpt-image-2-all
ملاحظات هامة
لا يقبل gpt-image-2-all المعاملات التالية: size أو n أو quality أو aspect_ratio؛ حيث سيؤدي تمريرها إلى حدوث خطأ في التحقق. يجب التحكم في الأبعاد حصرياً من خلال وصف النص في الموجه (prompt).
طريقة كتابة الموجه (prompt) الموصى بها

| نسبة العرض إلى الارتفاع | الصيغة الموصى بها | ملاحظات |
|---|---|---|
| 1:1 مربع | "1024×1024 مربع" أو "تكوين مربع 1:1" | صور الملف الشخصي |
| 16:9 أفقي | "أفقي 16:9" أو "شاشة عريضة 16:9" | صور مصغرة للفيديو |
| 9:16 عمودي | "عمودي 9:16" أو "شاشة هاتف 9:16" | فيديوهات قصيرة |
| 21:9 عريض جداً | "لافتة 21:9" أو "شاشة عريضة جداً" | لافتات المواقع الإلكترونية |
| 4:3 تقليدي | "أفقي 4:3" | شرائح العرض |
| 3:4 عمودي | "عمودي 3:4" | صور المنتجات |
نصائح أساسية
ضع وصف النسبة في بداية الموجه (prompt). يلتزم النموذج بشكل أكبر بالمحتوى المذكور في بداية الموجه، بينما قد يتم تجاهل النسبة إذا وضعت في النهاية.
# ✅ موصى به
prompt = "أفقي 16:9، كلب شيبا يبتسم تحت شجرة كرز، نمط تصوير بإضاءة ناعمة"
# ❌ غير موصى به
prompt = "كلب شيبا يبتسم تحت شجرة كرز، نمط تصوير بإضاءة ناعمة، أفقي 16:9"
تسعير gpt-image-2-all وسياسات التزامن
قواعد الفوترة
| البند | القاعدة |
|---|---|
| سعر الوحدة | $0.03 / لكل عملية |
| وحدة الفوترة | تُحسب بناءً على عمليات التوليد الناجحة فقط |
| عدم الخصم عند الفشل | لا يتم الخصم في حالات أخطاء 401/4xx/5xx |
| تأثير المعاملات | لا يوجد (السعر ثابت بغض النظر عن الدقة أو الجودة) |
| قيود التزامن | لا توجد (الحد هو رصيد حسابك فقط) |
تقديرات التكلفة النموذجية
| سيناريو العمل | حجم الاستدعاء الشهري | التكلفة الشهرية |
|---|---|---|
| مشاريع شخصية | 500 عملية | $15 |
| فريق صغير | 5,000 عملية | $150 |
| التجارة الإلكترونية | 50,000 عملية | $1,500 |
| خطوط إنتاج واسعة النطاق | 500,000 عملية | $15,000 |
نصيحة لتحسين التكلفة: من خلال استخدام خدمة وكيل API من APIYI (apiyi.com)، يمكنك توجيه المهام بذكاء بين gpt-image-2-all و gpt-image-1.5 و Nano Banana Pro بناءً على نوع المهمة، مما يجنبك دفع أعلى سعر لجميع السيناريوهات.
معالجة الأخطاء وأفضل الممارسات لـ gpt-image-2-all
رموز الأخطاء الشائعة وكيفية التعامل معها
| رمز الحالة | طريقة المعالجة |
|---|---|
| 401 | تحقق من صحة مفتاح API (Authorization Bearer Token) |
| 429 | إعادة المحاولة باستخدام التراجع الأسي (2 ثانية ← 4 ثوانٍ ← 8 ثوانٍ) |
| 5xx | أعد المحاولة مرة أو مرتين، وإذا استمر الخطأ قم بإرسال تنبيه |
| انتهاء المهلة | يُنصح بضبط مهلة العميل (timeout) لتكون ≥ 120 ثانية |
نصائح استكشاف الأخطاء وإصلاحها
تتضمن جميع الاستجابات ترويسة request-id. عند مواجهة أي مشكلة، قم بتسجيل هذا المعرف وأرسله إلى الدعم الفني في APIYI، حيث يساعد ذلك في تحديد موقع الخطأ في سجلات الخادم بسرعة.
الميزات غير المدعومة
- المخرجات المتدفقة (Streaming): خاصية
stream=trueغير فعالة، حيث يتم دعم الاستجابة الفردية فقط. - توليد صور متعددة: يرجع الطلب الواحد صورة واحدة فقط، إذا كنت بحاجة لصور متعددة، يرجى إجراء استدعاءات متزامنة.
- المعاملات الافتراضية لـ OpenAI SDK: المعاملات الافتراضية مثل
sizeأوnفي SDK الرسمي قد تؤدي إلى أخطاء في التحقق، لذا نوصي باستخدام مكتبة requests لإرسال الطلبات مباشرة.
الأسئلة الشائعة (FAQ)
س1: ما هو gpt-image-2-all؟
نموذج gpt-image-2-all هو نموذج وكيل API توفره APIYI عبر حل هندسي عكسي للوصول إلى أحدث قدرات توليد الصور في نسخة ChatGPT عبر الويب. قبل أن تطلق OpenAI واجهة برمجة التطبيقات (API) الرسمية لنموذج gpt-image-2 بشكل كامل، يوفر هذا النموذج قناة استدعاء بمستوى إنتاجي تتوافق مع أحدث قدرات ChatGPT، ويدعم ثلاثة سيناريوهات أساسية: تحويل النص إلى صورة، دمج صور متعددة، وتعديل الصور باستخدام اللغة الطبيعية.
س2: ما الفرق بين gpt-image-2-all ونموذج gpt-image-2 الرسمي؟
قدرات النموذج الأساسية متطابقة، لكن طرق الاتصال مختلفة. لم تفتح OpenAI رسميًا معرف النموذج gpt-image-2 في واجهة برمجة التطبيقات الخاصة بها حتى الآن (يجب توخي الحذر عند التعامل مع أي خدمة تدعي إمكانية استدعائه مباشرة عبر API)، بينما بدأت نسخة الويب من ChatGPT في اختبار النموذج الجديد ضمن اختبارات A/B. يوفر gpt-image-2-all قناة استدعاء مستقرة عبر حل هندسي عكسي. بمجرد إطلاق النسخة الرسمية، سيتمكن المستخدمون من الانتقال بسلاسة إلى الواجهة الرسمية بمجرد تغيير حقل model.
س3: كيف يتم فهم تسعيرة 0.03 دولار لكل عملية؟
تتم المحاسبة بناءً على عدد مرات التوليد الناجحة فقط، دون قيود على الدقة أو الجودة أو طول الموجه. مقارنة بتقديرات الصناعة لتسعيرة OpenAI الرسمية لنموذج gpt-image-2 (التي تتراوح بين 0.15 و0.20 دولار)، فإن تكلفة gpt-image-2-all تعادل 1/5 إلى 1/6 من ذلك. لا يتم احتساب الطلبات الفاشلة (أخطاء المصادقة، أخطاء المعلمات)، ولا يوجد حد أقصى إجباري للتزامن (يخضع فقط للرصيد المتاح في الحساب).
س4: لماذا يستغرق توليد صورة واحدة 30 ثانية؟
30 ثانية هي متوسط وقت الاستجابة الحالي للحل الهندسي العكسي، وهو وقت قريب من سرعة نسخة الويب من ChatGPT. من المتوقع أن يكون النموذج الرسمي gpt-image-2 أسرع عند إطلاقه (حوالي 3 ثوانٍ)، ولكن حتى صدور واجهة برمجة التطبيقات الرسمية، يعد gpt-image-2-all الحل الوحيد القابل للاستدعاء بشكل مستقر لأحدث القدرات. نوصي بضبط مهلة العميل (Timeout) على ≥120 ثانية لتجنب انتهاء المهلة بشكل خاطئ.
س5: كيف يمكنني البدء باستخدام gpt-image-2-all؟
يمكنك البدء في ثلاث خطوات:
- قم بزيارة موقع APIYI (apiyi.com) لإنشاء حساب والحصول على مفتاح API.
- اضبط عنوان الـ Base URL على
https://api.apiyi.com. - استخدم مكتبة
requestsلاستدعاء نقطة النهاية/v1/images/generations(تتطلب حزمة SDK الرسمية تخصيص HTTP لتجنب مشاكل معلمةsize).
للمزيد من التفاصيل: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · للتجربة المباشرة: imagen.apiyi.com
س6: ما هو الحد الأقصى لعدد الصور المرجعية في دمج الصور؟
يدعم طلب /v1/images/edits الواحد صورًا مرجعية متعددة، بشرط ألا يتجاوز حجم الصورة الواحدة 10 ميجابايت، مع دعم صيغ PNG/JPG/WebP. يتم الإشارة إلى الصور في الموجه (Prompt) باستخدام "الصورة 1"، "الصورة 2"، "الصورة 3". أظهرت الاختبارات أن دمج 3-5 صور مرجعية يعطي نتائج أكثر استقرارًا، بينما قد يؤدي تجاوز 10 صور إلى فقدان بعض العناصر.
س7: لماذا لا يمكنني استخدام حزمة SDK الرسمية من OpenAI مباشرة؟
تقوم طريقة images.generate() في حزمة SDK الرسمية بإرسال معلمات size وn افتراضيًا، بينما لا يقبل gpt-image-2-all هذه المعلمات (مما يؤدي إلى خطأ في التحقق). الحلول الموصى بها: (1) استخدام requests لإرسال طلب HTTP مباشرة؛ (2) أو تعديل جسم الطلب في SDK لإزالة هذه المعلمات. بمجرد إطلاق النسخة الرسمية، ستكون SDK متوافقة تلقائيًا.
س8: ما هي القيود المعروفة لـ gpt-image-2-all؟
إليك القيود الحالية بشفافية:
- مخرجات فردية: يتم توليد صورة واحدة في كل طلب، وللحصول على صور متعددة يجب إجراء استدعاءات متزامنة.
- لا يدعم البث (Streaming): يتم إرجاع النتيجة دفعة واحدة.
- مرحلة تجريبية (Beta): الاستقرار قيد التحسين المستمر، وقد تحدث تقلبات طفيفة.
- الاعتماد على الهندسة العكسية: قد تتأثر الخدمة مؤقتًا في حال حدوث تغييرات في نسخة الويب من ChatGPT.
- نصيحة: للأعمال الحساسة، نوصي بضبط نموذج مستقر مثل gpt-image-1.5 أو Nano Banana Pro كخطة بديلة (Fallback).
أهم مميزات gpt-image-2-all
- حل هندسي عكسي: يوفر أحدث قدرات ChatGPT كقناة إنتاجية وحيدة قبل الإطلاق الرسمي لواجهة API.
- تكلفة 0.03 دولار/عملية: محاسبة على النجاح فقط، تكلفة شفافة، ومناسبة لخطوط الإنتاج الجماعية.
- تغطية شاملة: ثلاث نقاط نهاية تغطي تحويل النص إلى صورة، دمج الصور، وتعديل الصور حواريًا.
- دعم اللغة العربية: تقديم نصوص عربية عالية الدقة، مع استقرار في عرض النصوص العربية والإنجليزية دون الحاجة لترجمة الموجه.
- سهولة البدء: سجل في APIYI (apiyi.com) → اضبط مهلة 120 ثانية → استخدم
requestsللاستدعاء المباشر.
ملخص
القيمة الجوهرية لـ gpt-image-2-all:
- سد الفجوة الرسمية: توفير واجهة برمجية (API) بمستوى إنتاجي تتيح استدعاء قدرات توليد الصور الأحدث من ChatGPT بثبات، وذلك قبل أن تطلق OpenAI نموذج
gpt-image-2بشكل رسمي. - تكلفة أقل بكثير من التوقعات الرسمية: التكلفة هي 0.03 دولار لكل عملية، مقارنة بـ 0.15-0.20 دولار حسب التقديرات الرسمية، مما يمنح ميزة تنافسية كبيرة في سيناريوهات الاستخدام الكثيف.
- تصميم يسهل الانتقال السلس: يعتمد على بروتوكول متوافق مع OpenAI، مما يعني أنه عند إطلاق النسخة الرسمية، ستحتاج فقط إلى استبدال اسم النموذج للتبديل إليه.
بالنسبة لقرارات الفريق، نوصي بالبدء فوراً في دمج gpt-image-2-all عبر APIYI (apiyi.com) لتشغيل سير عملك، حيث إن التسعير الحالي البالغ 0.03 دولار لكل عملية يجعل التحقق من الجدوى شبه مجاني، ويمكنك التبديل إلى نموذج gpt-image-2 الرسمي لاحقاً عند توفره. الفرق التي تبادر بالاستفادة من هذه التقنية ستحقق ميزة تنافسية واضحة عند إطلاق النموذج الجديد.
تجربة مباشرة: imagen.apiyi.com · الوثائق باللغة الصينية: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
قراءات إضافية
إذا كنت مهتماً بـ gpt-image-2-all، نوصي بمتابعة القراءة حول المواضيع التالية:
- 📘 تحليل شامل للترقيات الثمانية الكبرى في gpt-image-2 مقارنة بـ gpt-image-1.5 – لفهم الأسباب الكامنة وراء القفزة في القدرات.
- 📊 تحليل شامل لستة سيناريوهات تطبيقية لـ gpt-image-2 – لإتقان مسارات التنفيذ العملي في الأعمال.
- 🚀 مقارنة متعمقة بين gpt-image-2 و Nano Banana Pro – لاختيار النموذج الأمثل بعقلانية.
📚 المراجع
-
وثائق APIYI الرسمية: المواصفات التقنية الكاملة لـ gpt-image-2-all
- الرابط:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - الوصف: وثائق الربط الرسمية المعتمدة، تتضمن المعلمات، رموز الخطأ، وأفضل الممارسات.
- الرابط:
-
منصة الاختبار (Playground) من APIYI: imagen.apiyi.com
- الرابط:
imagen.apiyi.com - الوصف: اختبر نتائج توليد الصور عبر gpt-image-2-all دون الحاجة لكتابة أي كود برمجي.
- الرابط:
-
وثائق API الصور الرسمية من OpenAI: أحدث واجهة برمجة تطبيقات لنماذج الصور
- الرابط:
openai.com/index/image-generation-api - الوصف: للمقارنة والتعرف على مواصفات واجهة برمجة تطبيقات gpt-image-1.5 الرسمية من OpenAI.
- الرابط:
-
ملاحظات اختبار LM Arena: معلومات مسربة حول GPT Image 2
- الرابط:
mindstudio.ai/blog/what-is-gpt-image-2 - الوصف: نظرة استباقية على قدرات الجيل القادم من نماذج الصور.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تبادل الخبرات: نرحب بنقاشاتكم في قسم التعليقات، وللمزيد من المعلومات يمكنكم زيارة مركز وثائق APIYI عبر الرابط docs.apiyi.com.