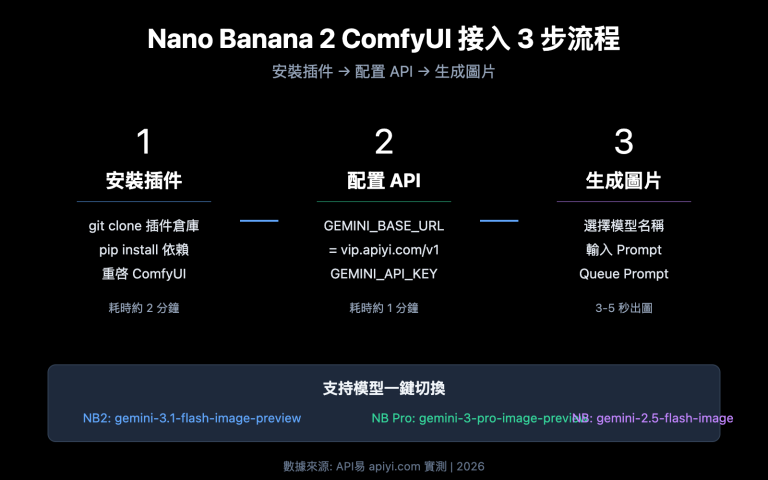
最近被開發者客戶朋友問到一個高頻問題:"爲什麼我調 gpt-image-2 生成一張 1024×1024 圖要等 200 多秒?是不是被限速了?"。打開他的代碼一看,參數是默認 quality="high"、size="1536x1024",於是 235 秒一張圖就成了正常表現。

gpt-image-2 是 OpenAI 在 2026 年 4 月 21 日正式發佈的新一代圖像模型,首次把 O 系列推理能力(Agentic 思考)帶進了圖像生成流程——這意味着 quality="high" 的請求會經過完整的"理解—規劃—生成—校對"四個階段,耗時是 quality="low" 的 30–50 倍。本文基於真實生產調用經驗,把三個最關鍵的參數講清楚,讓你能精準在畫質與速度之間找到最優解。
gpt-image-2 調用核心參數速查表
先放結論。下面這張表覆蓋了 gpt-image-2 在 OpenAI Python SDK 中所有重要參數及其對耗時與價格的影響程度,做調優時建議先按這張表對號入座。
| 參數 | 可選值 | 默認值 | 對耗時影響 | 對價格影響 |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
極大 | 極大 |
size |
1024x1024 / 1536x1024 / 1024x1536 / 任意 ≤ 2K |
1024x1024 |
大 | 中 |
output_format |
png / jpeg / webp |
png |
小 | 無 |
output_compression |
0–100(僅 jpeg/webp 有效) | 100 | 極小 | 無 |
n |
1–10 | 1 | 與 n 成正比 | 與 n 成正比 |
background |
transparent / opaque / auto |
auto |
小 | 無 |
prompt |
string | 必填 | 複雜度影響推理時間 | 影響輸入 token |
讀懂這張表的核心邏輯:quality 與 size 是生死線——它們直接決定了模型走哪條推理路徑、生成多少 token、消耗多少視覺算力。output_format 與 output_compression 只是序列化層的事,調整它們不會讓你提速。
🎯 首要建議:如果你的業務允許,把
quality="auto"改爲顯式的low或medium,單這一步通常就能把耗時從分鐘級壓到秒級。通過 API易 apiyi.com 調用 gpt-image-2 時,所有這些參數都原生透傳,行爲與 OpenAI 官方端點一致。
影響 gpt-image-2 耗時的 2 個關鍵參數:quality 與 size
要理解爲什麼 high 和 low 會差幾十倍,必須先了解 gpt-image-2 的執行路徑。這是它和上一代 gpt-image-1 最本質的差異。

quality 參數的工作機制
gpt-image-2 的官方文檔明確指出,quality="low" 是爲延遲敏感場景準備的,在視覺效果尚可接受的前提下提供秒級響應。而 quality="high" 啓用了完整的 Agentic 思考鏈——模型會先在內部規劃構圖、規劃文字佈局、規劃光影邏輯,再開始繪製。這一推理階段對人眼不可見,但佔用了大約 70–80% 的總耗時。
quality="medium" 則是折中檔,它保留了簡化版規劃但跳過了細粒度校對。quality="auto" 在沒有指定時,模型會根據 prompt 複雜度自動選擇,但實測它傾向於偏保守地選 medium 或 high,這就是很多開發者誤以爲"默認就慢"的原因。
size 參數的工作機制
gpt-image-2 原生支持的尺寸有 1024x1024、1536x1024、1024x1536 三檔標準尺寸,加上 auto 自動判斷。它還支持任意尺寸傳入,只要總像素不超過 2K(2560×1440 = 約 369 萬像素)就可工作,超過這個閾值則進入實驗性區域,結果穩定性下降。
像素數量直接決定了視覺 token 數量。1024×1024 大約 1024 個視覺 token,1536×1024 升到約 1536 個,1024×1536 同理。token 數翻倍意味着推理與生成時間翻倍,輸出價格也翻倍。
| 標準尺寸 | 總像素 | 視覺 token(估) | 相對耗時 | 適用場景 |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | 通用、社媒、縮略圖 |
1536x1024 |
1.57M | ~1536 | 1.5× | 橫幅、文章封面 |
1024x1536 |
1.57M | ~1536 | 1.5× | 海報、豎屏內容 |
| 自定義 ≤ 2K | 至 3.69M | 至 ~3686 | 2–3× | 高分辨率印刷預覽 |
🎯 尺寸建議:實際生產中建議 95% 的請求都用
1024x1024,只在需要橫幅、海報等特殊比例時再切到 1536 系列。通過 API易 apiyi.com 調用時支持任意自定義尺寸,但記得控制在 2K 以內以保證穩定性。
兩個參數的耦合效應
quality 與 size 是相乘關係,不是相加。high + 1536×1024 比 low + 1024×1024 慢的不是幾倍而是幾十倍。這一點在併發場景下尤其致命——你以爲開 10 個併發能 1 秒出圖,實際可能 200 秒出 10 張圖,HTTP 客戶端早超時了。
更隱蔽的是 quality 與 prompt 複雜度也存在隱性耦合。同樣是 high 檔,簡單 prompt("a red apple")大約 100 秒、複雜 prompt("賽博朋克城市雨夜,霓虹招牌,電影畫幅,6 個角色互動")容易突破 230 秒甚至更久。模型推理階段會按場景元素數量動態擴展 token budget,所以 prompt 越複雜、high 檔越慢、價格也越高。
🎯 prompt 寫法建議:在 high 檔下,建議把 prompt 控制在 200 字以內,並把核心元素放在前 50 字。冗長描述並不一定提升效果,反而會拉長推理耗時。通過 API易 apiyi.com 調用時這一規律也成立,因爲中轉層完整透傳 prompt,模型行爲與官方一致。
gpt-image-2 各 quality 檔的實測耗時與價格對比
下面這張表來自我們在 API易 apiyi.com 平臺上跨多個時段、跨不同 prompt 複雜度採集的實測數據。數據可能因時段、prompt、網絡略有波動,但量級可信。
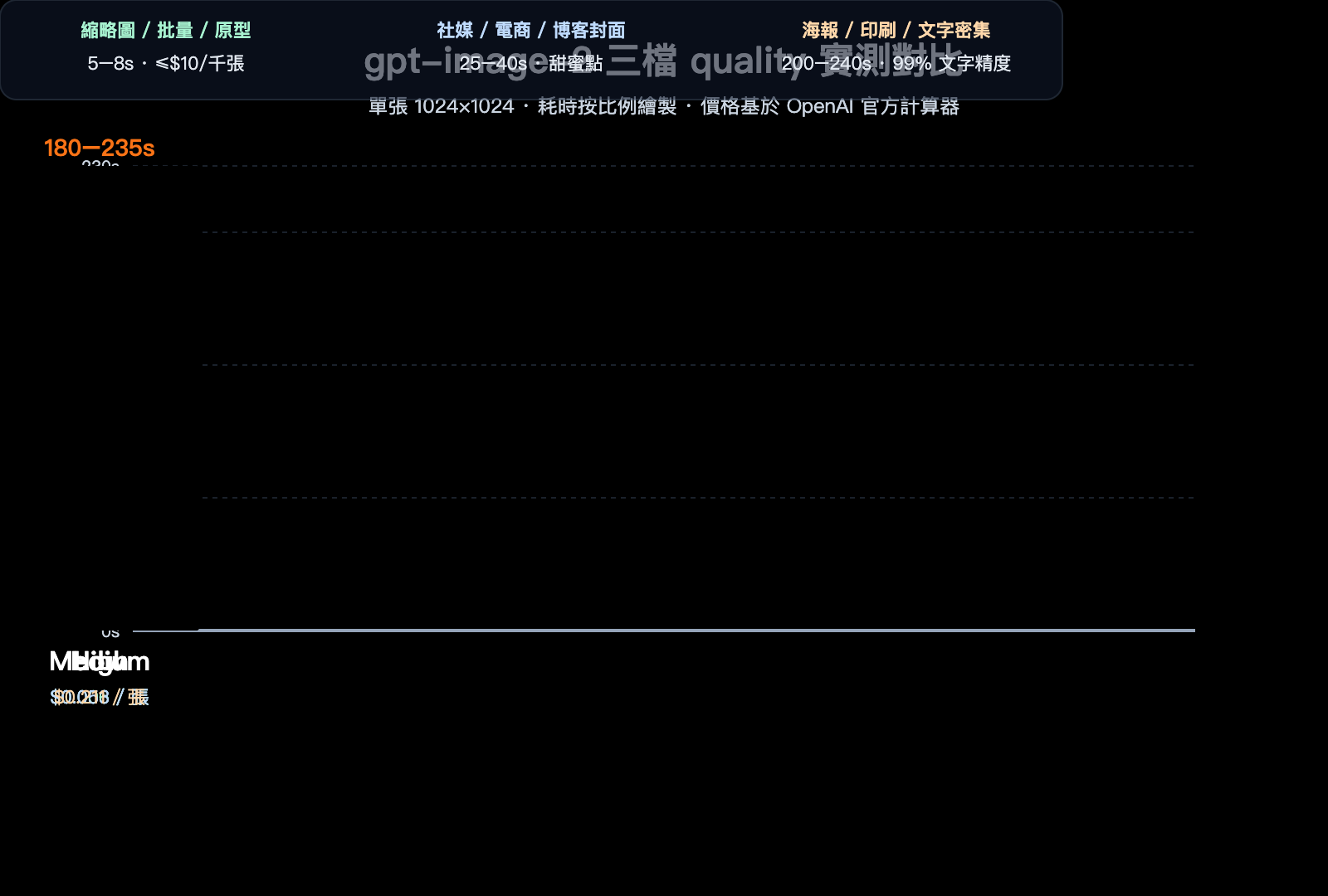
單張 1024×1024 實測數據
| quality | 平均耗時 | 價格(美元/張) | 視覺精度 | 文字精度 | 適用場景 |
|---|---|---|---|---|---|
low |
3–8 秒 | $0.006 | 中等 | 一般 | 縮略圖、批量、原型測試 |
medium |
20–40 秒 | $0.053 | 高 | 良好 | 社媒、電商、博客封面 |
high |
150–235 秒 | $0.211 | 極高 | 極高(99%+) | 海報、印刷、文字密集 |
可以看到一個非常明顯的非線性關係:low 到 medium 價格漲 9 倍,但耗時只漲 5 倍;medium 到 high 價格漲 4 倍,但耗時漲 6–7 倍。換句話說,high 的邊際成本是用"等待時間"在付的。
如果你的業務並不真正需要 99% 的文字精度(如純插畫、抽象設計、概念圖),用 medium 就足夠,省錢又省時間。只有海報、IP 設計、印刷預覽這類對文字與細節有硬要求的場景,才值得爲 high 付出 200 秒的等待。
🎯 成本測算建議:在生產環境上線前,建議先用 API易 apiyi.com 各跑 100 張 low/medium/high,把耗時分佈、價格分佈、畫面質量做一份內部 A/B 報告,再決定主流量該走哪一檔。一週流量打完賬單不會超過 $30,但能避免上線後被慢請求拖垮整個 SLA。
1024×1024 vs 1536×1024 的耗時差
同樣是 medium 檔,1024×1024 平均 25 秒,1536×1024 平均 38 秒,1024×1536 也是 38 秒左右。差異符合視覺 token 數的 1.5 倍比例。但 high 檔下這個差異會被放大——high + 1024×1024 大約 180 秒,high + 1536×1024 容易突破 240 秒,高峯時段甚至更長。
high 檔的實際波動區間
值得特別提醒的是,high 檔的耗時不是恆定值,而是一個相當寬的分佈。我們採樣了 200 次 high + 1024×1024 的請求,最快 145 秒、最慢 280 秒、中位數約 195 秒。這種波動主要來自兩個因素:一是 prompt 複雜度觸發的推理 budget 不同,二是 OpenAI 後端在不同時段的負載差異。所以 high 檔絕對不能用同步阻塞調用——必須做成異步任務,前端先返回任務 ID,後端輪詢或回調通知用戶。
一個常見的誤區:以爲更高分辨率畫質更好
很多開發者直覺認爲分辨率越高畫質越好,於是默認走 1536 系列。這其實是誤區。gpt-image-2 在 1024×1024 上的畫質表現已經非常充分,像素利用率最高;切換到 1536 系列只是改變畫幅比例,縱橫向真正顯示在屏幕上的細節並沒有增加。除非你確實需要橫屏/豎屏構圖,否則保持 1024×1024 就是最划算的選擇。
Python SDK 調用 gpt-image-2 的完整示例
下面給出從基礎調用到生產級封裝的三段式代碼,按需取用。所有示例都基於 OpenAI 官方 Python SDK,base_url 指向 API易 apiyi.com,行爲與官方端點完全一致。
基礎示例:單張文生圖
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="賽博朋克城市雨夜,霓虹招牌,電影畫幅",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
這段代碼足以跑通,但有個坑——quality="high" + 默認 timeout 幾乎必崩。OpenAI Python SDK 的默認 HTTP 超時是 600 秒,聽起來夠用,但很多用戶用 requests/httpx 包了一層、自設了 60s 超時,就會在 high 檔大批量請求時頻繁報 ReadTimeout。
生產示例:顯式超時與重試
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
實戰經驗:
timeout=300是 high 檔的安全值,覆蓋 99% 的請求;如果你確認走 low/medium,可以降到 60。max_retries=2用 SDK 自帶的指數退避,比手擼重試穩。output_format="jpeg"+output_compression=85通常能比 PNG 文件小 60–70%,畫質差異肉眼難辨,特別推薦用於 Web 縮略圖。
🎯 超時建議:通過 API易 apiyi.com 調用時,平臺側已對長耗時請求做了鏈路保活,但客戶端 SDK 的 timeout 必須自己設,不能依賴默認值。high 檔建議至少 240 秒,low 檔可以收緊到 30 秒,避免被拖死的請求阻塞連接池。
批量示例:異步併發生成
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["貓", "狗", "鳥", "魚", "兔"] * 4))
併發是大批量生圖的最重要技巧。low 檔單次 5 秒,串行 20 張就是 100 秒;用 5 路併發只要 20 秒。但要注意把 quality 鎖死在 low 或 medium——high 檔併發只會讓 timeout 雪崩,得不償失。
不同業務場景下的 gpt-image-2 參數推薦
理論數據看完,落到具體場景纔有意義。下面把高頻業務對應的最優參數組合整理出來。
| 業務場景 | quality | size | output_format | 期望耗時 | 單價 |
|---|---|---|---|---|---|
| 電商主圖、Banner | medium | 1024×1024 | jpeg+85 | 25–35s | $0.053 |
| 小紅書/社媒配圖 | medium | 1024×1536 | jpeg+85 | 30–40s | ~$0.06 |
| 文章封面、博客頭圖 | medium | 1536×1024 | webp+90 | 30–40s | ~$0.06 |
| 海報、印刷預覽 | high | 1024×1536 | png | 200–240s | ~$0.21 |
| 字幕/PPT 封面 | high | 1536×1024 | png | 200–240s | ~$0.21 |
| 縮略圖、原型測試 | low | 1024×1024 | jpeg+75 | 3–8s | $0.006 |
| 批量草圖、靈感板 | low | 1024×1024 | jpeg+75 | 3–8s × N | $0.006 × N |
| AI 助手即時生圖 | low | 1024×1024 | webp+85 | 5–10s | $0.006 |
場景一:電商與社媒——medium 是甜蜜點
電商主圖、社媒配圖對耗時敏感(用戶上傳商品後等不了 4 分鐘),但又需要清晰好看,medium 是最佳選擇。30 秒左右出圖,價格 5 美分,單日跑 1000 張也不過 $53。
場景二:海報與印刷預覽——爲 high 檔付時間
海報/封面帶有大段文字、複雜排版、IP 角色一致性要求,需要 high 檔的完整 Agentic 思考。這種場景下別想着壓時間,直接給前端做"任務化"提示——提交後告知用戶 3–5 分鐘後回查。
場景三:批量與原型——low 檔卡死
凡是需要"一晚上跑 1 萬張草圖"的場景,必須 low 檔,沒有商量餘地。配合異步併發與 jpeg+75 壓縮,單 GPU 節點就能跑出可觀吞吐。
場景四:用戶即時交互——必須 low 或 medium
聊天機器人、AI 助手內嵌生圖、客服自動回覆帶圖等"用戶在等"的場景,絕對不能用 high。一個用戶等 4 分鐘,意味着至少 50% 的人會刷新或離開,體驗災難。建議固定 low 檔,配合"加載中…"動畫,讓用戶在 5–8 秒內拿到結果。如果畫質實在不夠,再做"高清優化"按鈕觸發 medium 重生成。
場景五:內容審覈與合規重生成
被 OpenAI 內容策略攔截後的重生成,建議先用 low 檔試探新 prompt 是否能通過審覈,確認通過再升 medium/high 出最終圖。這種試探-確認兩階段策略能把審覈失敗的成本降到最低,避免在 high 檔浪費 200 秒發現還是被攔。
🎯 混合策略:很多生產系統會做"雙檔生成"——先用 low 檔秒級生成預覽圖給用戶挑選,用戶選中後再用 high 檔重生成最終成品。這種策略在 API易 apiyi.com 上實現非常順滑,因爲同一把令牌覆蓋了所有 quality 檔位,無需切換賬號。
常見問題 FAQ
Q1:爲什麼我的 high 檔請求總是 timeout?
OpenAI Python SDK 默認 timeout 是 600 秒,理論上夠用,但很多框架(FastAPI、Flask、Celery)會在外層加自己的 timeout。請檢查整條調用鏈上每一層的超時設置,建議 high 檔全鏈路至少給 300 秒。如果用 httpx,記得顯式設置 httpx.Timeout(300.0)。
Q2:output_compression 調到多少最合適?
jpeg 格式下 85 是甜蜜點——肉眼幾乎看不出與 100 的差異,文件大小卻能小 30–40%。webp 格式下 90 也是常用值。低於 70 會出現明顯色塊,特別是漸變背景區域。這個參數不影響生成耗時,隻影響最終序列化輸出。
Q3:通過 API易 apiyi.com 調用 gpt-image-2 與官方端點有差異嗎?
參數與行爲完全透傳,包括 quality、size、output_format、output_compression、n、background 等所有字段。區別在於 API易 apiyi.com 提供國內可達的高速節點、統一計費、按量結算無最低消費,對國內開發者更友好。
Q4:n 參數能一次返回多張嗎?
可以,gpt-image-2 支持 n=1 到 n=10。但要注意——多張返回的總耗時大約是單張的 0.7–0.9 倍乘以 n(不是完全並行),且總價格按 n 倍計算。如果你需要"一組連貫的角色",用 n=4 讓模型一次推理輸出比起調 4 次更穩定,因爲 gpt-image-2 在單次推理內能保持角色一致性。
Q5:quality="auto" 到底走的是哪一檔?
實測中 auto 傾向於走 medium 或 high,具體取決於 prompt 長度與複雜度。短 prompt("a cat")大概率走 low/medium,長 prompt(含人物、場景、文字、風格)大概率走 high。生產環境推薦顯式指定,不要依賴 auto 的隱式判斷。
Q6:1024×1536 和 1536×1024 哪個畫質更好?
兩者總像素相同(約 157 萬),畫質本質一致。區別只在畫幅比例——豎屏(1024×1536)適合海報、人物全身像、移動端豎屏內容;橫屏(1536×1024)適合橫幅、風景、PC 端封面。選哪個看構圖需求,不影響速度與價格。
Q7:我能不能跳過推理直接拿底層模型?
不能,gpt-image-2 的 Agentic 推理是模型架構的一部分,不可關閉。如果你確實只需要傳統 SD 風格的快速生圖、不需要文字渲染與推理,建議用 low 檔,它會跳過完整推理鏈。或者考慮 Google 的 nano-banana-pro,它的快速檔比 gpt-image-2 low 還快,API易 apiyi.com 也已上線該模型。
🎯 多模型協同建議:成熟的圖像生成系統通常不止用一個模型。建議把 nano-banana-pro 用於快速預覽(5 秒級響應)、把 gpt-image-2 medium 用於主流量出圖、把 gpt-image-2 high 用於精品場景。三個模型在 API易 apiyi.com 共用同一把令牌,按量計費,是 2026 年圖像 API 接入最划算的組合。
總結:把參數當成性能開關,而不是裝飾
gpt-image-2 的設計哲學和上一代圖像模型截然不同——它把推理變成了圖像生成的核心步驟,因此 quality 不再是"畫質好壞"的簡單選項,而是"走多深的推理路徑"的開關。理解這一點,你就理解了爲什麼同一個 API 能在 5 秒和 235 秒之間跨越 50 倍的耗時區間。
實戰中我們建議把"參數選型"作爲業務設計的第一步:先想清楚這個場景能容忍多長延遲、需要多高畫質、單價上限是多少,然後查表選 quality 與 size。預先定好這些參數,比上線後再調優要省心得多。
🎯 最終建議:開始接入 gpt-image-2 時,建議通過 API易 apiyi.com 註冊後先跑一輪 low/medium/high 三檔對比測試,把實測耗時與畫質打個分,再決定主流量參數。一把令牌覆蓋三檔,按量計費、無最低消費,是 2026 年圖像 API 接入最高效的姿勢。
— APIYI 技術團隊 | 持續追蹤圖像生成模型動態,更多深度教程見 API易 apiyi.com 幫助中心