Récemment, un développeur m'a posé une question très fréquente : « Pourquoi mon invocation de gpt-image-2 pour générer une image en 1024×1024 prend-elle plus de 200 secondes ? Est-ce que je subis une limitation de débit ? ». En examinant son code, j'ai vu que les paramètres étaient réglés par défaut sur quality="high" et size="1536x1024". Avec ces réglages, 235 secondes par image, c'est tout à fait normal.

gpt-image-2 est le modèle d'image de nouvelle génération officiellement lancé par OpenAI le 21 avril 2026. Il intègre pour la première fois les capacités de raisonnement de la série O (réflexion agentique) dans le processus de génération d'images. Cela signifie qu'une requête avec quality="high" passe par quatre étapes complètes : « compréhension — planification — génération — vérification ». Le temps de traitement est alors 30 à 50 fois plus long qu'avec quality="low". Cet article, basé sur une expérience réelle en production, détaille les trois paramètres les plus critiques pour vous aider à trouver l'équilibre parfait entre qualité et vitesse.
Tableau récapitulatif des paramètres clés pour l'invocation de gpt-image-2
Voici la conclusion. Le tableau ci-dessous couvre tous les paramètres importants de gpt-image-2 dans le SDK Python d'OpenAI, ainsi que leur impact sur le temps de traitement et le coût. Je vous conseille de vous y référer lors de vos optimisations.
| Paramètre | Valeurs possibles | Valeur par défaut | Impact sur le temps | Impact sur le coût |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Très élevé | Très élevé |
size |
1024x1024 / 1536x1024 / 1024x1536 / toute taille ≤ 2K |
1024x1024 |
Élevé | Moyen |
output_format |
png / jpeg / webp |
png |
Faible | Aucun |
output_compression |
0–100 (valide uniquement pour jpeg/webp) | 100 | Très faible | Aucun |
n |
1–10 | 1 | Proportionnel à n | Proportionnel à n |
background |
transparent / opaque / auto |
auto |
Faible | Aucun |
prompt |
chaîne de caractères | Obligatoire | La complexité affecte le temps d'inférence | Affecte les jetons d'entrée |
La logique fondamentale à comprendre : quality et size sont les facteurs déterminants. Ils dictent directement le chemin d'inférence emprunté par le modèle, le nombre de jetons générés et la puissance de calcul visuel consommée. output_format et output_compression ne concernent que la sérialisation ; les modifier ne vous fera pas gagner en vitesse.
🎯 Conseil prioritaire : Si votre activité le permet, remplacez
quality="auto"par une valeur explicite commelowoumedium. Cette seule étape permet souvent de réduire le temps de traitement de plusieurs minutes à quelques secondes. Lorsque vous invoquezgpt-image-2via APIYI (apiyi.com), tous ces paramètres sont transmis nativement, avec un comportement identique aux points de terminaison officiels d'OpenAI.
Les 2 paramètres clés qui impactent le temps de traitement de gpt-image-2 : quality et size
Pour comprendre pourquoi il existe un écart de plusieurs dizaines de fois entre les modes high et low, il faut d'abord se pencher sur le chemin d'exécution de gpt-image-2. C'est là que réside la différence fondamentale avec la génération précédente, gpt-image-1.
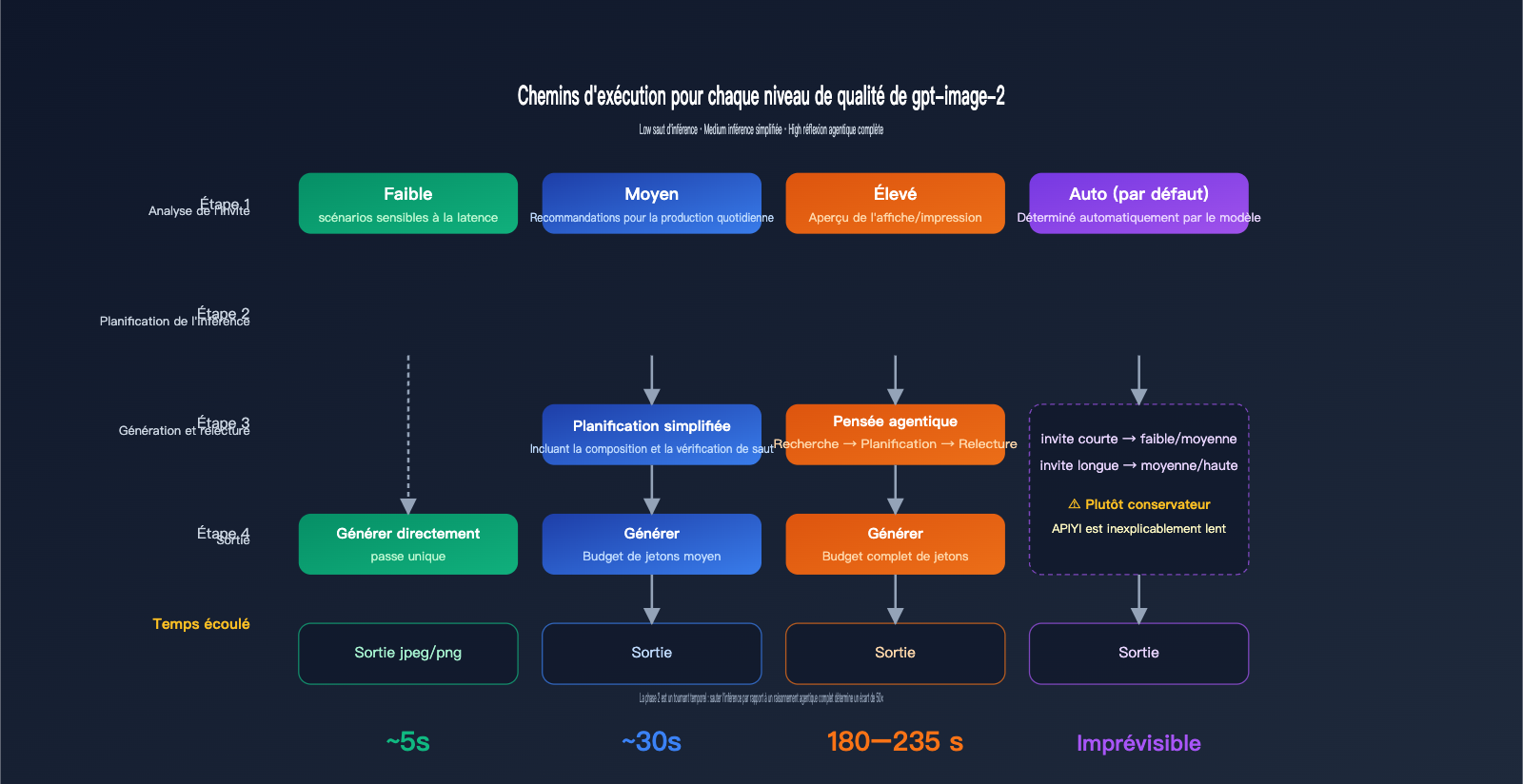
Le mécanisme de fonctionnement du paramètre quality
La documentation officielle de gpt-image-2 indique clairement que quality="low" est conçu pour les scénarios sensibles à la latence, offrant une réponse en quelques secondes tout en conservant une qualité visuelle acceptable. À l'inverse, quality="high" active une chaîne de réflexion agentique complète : le modèle planifie en interne la composition, la disposition du texte et la logique de la lumière avant même de commencer à dessiner. Cette phase de raisonnement est invisible pour l'utilisateur, mais elle accapare environ 70 à 80 % du temps total de traitement.
Le mode quality="medium" est un compromis : il conserve une planification simplifiée mais ignore la vérification fine. Quant à quality="auto", si aucun paramètre n'est spécifié, le modèle choisit automatiquement en fonction de la complexité de l'invite. Cependant, les tests montrent qu'il a tendance à privilégier medium ou high, ce qui explique pourquoi de nombreux développeurs pensent à tort que le mode par défaut est "lent".
Le mécanisme de fonctionnement du paramètre size
gpt-image-2 prend nativement en charge trois tailles standard : 1024x1024, 1536x1024 et 1024x1536, en plus du mode auto. Il accepte également des dimensions personnalisées, tant que le nombre total de pixels ne dépasse pas 2K (2560 × 1440 ≈ 3,69 millions de pixels). Au-delà de ce seuil, on entre dans une zone expérimentale où la stabilité des résultats diminue.
Le nombre de pixels détermine directement le nombre de jetons visuels. 1024 × 1024 correspond à environ 1024 jetons visuels, tandis que 1536 × 1024 monte à environ 1536 jetons (et de même pour 1024 × 1536). Doubler le nombre de jetons signifie doubler le temps d'inférence et de génération, ainsi que le coût de l'opération.
| Taille standard | Total pixels | Jetons visuels (est.) | Temps relatif | Cas d'usage |
|---|---|---|---|---|
1024x1024 |
1,05 M | ~1024 | 1,0× | Général, réseaux sociaux, miniatures |
1536x1024 |
1,57 M | ~1536 | 1,5× | Bannières, couvertures d'articles |
1024x1536 |
1,57 M | ~1536 | 1,5× | Affiches, contenu vertical |
| Perso ≤ 2K | Jusqu'à 3,69 M | Jusqu'à ~3686 | 2–3× | Aperçus pour impression haute résolution |
🎯 Conseil sur les dimensions : En production, je recommande d'utiliser
1024x1024pour 95 % des requêtes, et de ne passer aux formats 1536 que pour des besoins spécifiques (bannières, affiches). Via APIYI (apiyi.com), vous pouvez utiliser n'importe quelle dimension personnalisée, mais veillez à rester sous la barre des 2K pour garantir la stabilité.
L'effet de couplage des deux paramètres
Les paramètres quality et size ont un effet multiplicateur, et non additif. Une combinaison high + 1536x1024 est beaucoup plus lente qu'une combinaison low + 1024x1024 — l'écart se compte en dizaines de fois. C'est un point critique en cas de forte concurrence : si vous pensez pouvoir générer 10 images en 1 seconde avec 10 requêtes simultanées, vous pourriez en réalité mettre 200 secondes pour obtenir les 10 images, ce qui provoquera un timeout côté client HTTP.
Plus subtil encore, il existe un couplage implicite entre quality et la complexité de l'invite. En mode high, une invite simple ("une pomme rouge") prendra environ 100 secondes, tandis qu'une invite complexe ("ville cyberpunk sous la pluie nocturne, enseignes néon, format cinéma, interaction entre 6 personnages") dépassera facilement les 230 secondes. Le modèle ajuste dynamiquement son budget de jetons en fonction du nombre d'éléments de la scène : plus l'invite est complexe, plus le mode high est lent et coûteux.
🎯 Conseil pour vos invites : En mode
high, je vous suggère de limiter vos invites à 200 mots et de placer les éléments clés dans les 50 premiers mots. Une description trop longue n'améliore pas forcément le résultat, mais allonge considérablement le temps d'inférence. Cette règle s'applique également via APIYI (apiyi.com), car notre couche de service proxy API transmet intégralement l'invite, garantissant un comportement identique à celui du modèle officiel.
Comparaison des temps de traitement et des tarifs par niveau de qualité pour gpt-image-2
Le tableau ci-dessous est basé sur des données réelles collectées sur notre plateforme APIYI (apiyi.com) sur plusieurs plages horaires et avec différents niveaux de complexité d'invites. Bien que les chiffres puissent varier légèrement en fonction du moment, de l'invite et du réseau, les ordres de grandeur sont fiables.
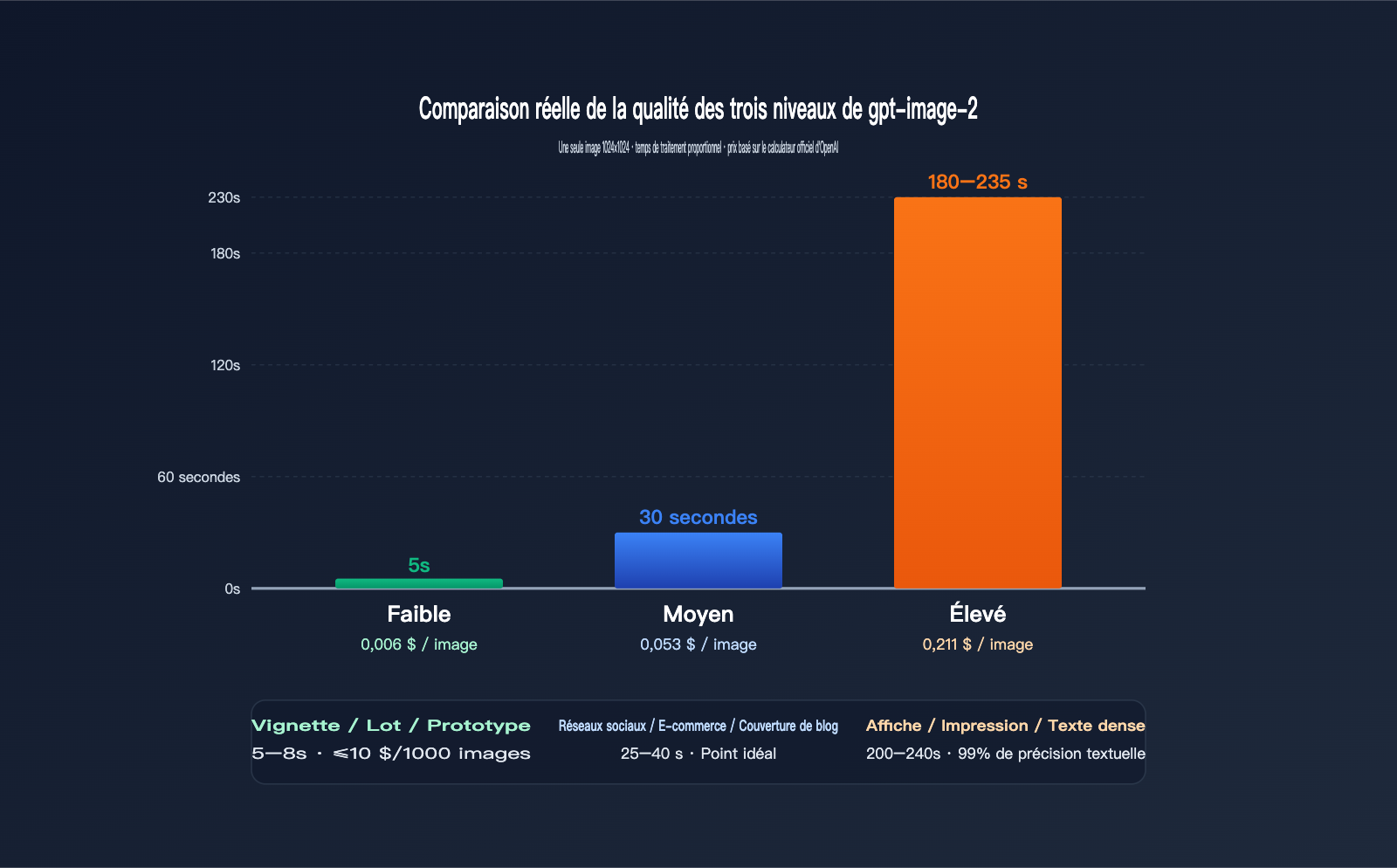
Données réelles pour une image 1024×1024
| Qualité | Temps moyen | Prix (USD/image) | Précision visuelle | Précision texte | Cas d'usage |
|---|---|---|---|---|---|
low |
3–8 s | 0,006 $ | Moyenne | Standard | Miniatures, traitement par lots, prototypage |
medium |
20–40 s | 0,053 $ | Élevée | Bonne | Réseaux sociaux, e-commerce, couvertures de blog |
high |
150–235 s | 0,211 $ | Très élevée | Excellente (99%+) | Affiches, impression, textes denses |
On observe une relation non linéaire très marquée : le passage de "low" à "medium" multiplie le prix par 9 pour un temps de traitement multiplié par 5 ; le passage de "medium" à "high" multiplie le prix par 4 pour un temps multiplié par 6 à 7. En d'autres termes, le coût marginal du niveau "high" se paie en temps d'attente.
Si votre projet ne nécessite pas réellement 99 % de précision textuelle (comme pour des illustrations, du design abstrait ou des concepts), le niveau "medium" suffit largement, vous faisant économiser temps et argent. Seuls les affiches, le design de personnages (IP) ou les prévisualisations pour impression justifient les 200 secondes d'attente du niveau "high".
🎯 Conseil d'optimisation des coûts : Avant de passer en production, je vous recommande de tester 100 images pour chaque niveau (low/medium/high) via APIYI (apiyi.com). Analysez la répartition des temps, des coûts et la qualité visuelle pour établir un rapport A/B interne avant de décider quel niveau privilégier pour votre trafic principal. Une semaine de tests ne vous coûtera pas plus de 30 $, mais cela évitera que des requêtes trop lentes ne dégradent votre SLA après le déploiement.
Différence de temps : 1024×1024 vs 1536×1024
Pour le niveau "medium", on passe d'une moyenne de 25 s (1024×1024) à 38 s (1536×1024 ou 1024×1536). Cette différence est cohérente avec le ratio de 1,5 fois le nombre de jetons visuels. Cependant, au niveau "high", cet écart se creuse : on passe d'environ 180 s à plus de 240 s, voire davantage aux heures de pointe.
La variabilité du niveau "high"
Il est important de noter que le temps de traitement du niveau "high" n'est pas constant, mais suit une distribution assez large. Sur 200 requêtes "high" en 1024×1024, nous avons observé un minimum de 145 s, un maximum de 280 s, avec une médiane autour de 195 s. Cette fluctuation dépend de deux facteurs : la complexité de l'invite (qui influence le budget d'inférence) et la charge des serveurs OpenAI. Par conséquent, le niveau "high" ne doit jamais être utilisé en appel synchrone bloquant : privilégiez une approche asynchrone où vous retournez un ID de tâche, puis utilisez un mécanisme de polling ou de callback.
Une idée reçue : une résolution plus élevée signifie une meilleure qualité
Beaucoup de développeurs pensent intuitivement qu'une résolution plus élevée garantit une meilleure qualité et optent par défaut pour la série 1536. C'est une erreur. La qualité de gpt-image-2 est déjà optimale en 1024×1024 ; passer à la série 1536 modifie simplement le format de l'image, mais n'ajoute pas de détails supplémentaires réellement visibles à l'écran. Sauf si vous avez un besoin spécifique de composition en mode paysage ou portrait, le format 1024×1024 reste le choix le plus rentable.
Exemple complet d'invocation de gpt-image-2 avec le SDK Python
Voici trois niveaux de code, de l'invocation basique à l'implémentation prête pour la production, à utiliser selon vos besoins. Tous les exemples s'appuient sur le SDK Python officiel d'OpenAI, avec une base_url pointant vers APIYI (apiyi.com), garantissant un comportement identique aux points de terminaison officiels.
Exemple basique : génération d'une image simple (texte vers image)
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Ville cyberpunk sous la pluie nocturne, enseignes au néon, format cinéma",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Ce code fonctionne, mais attention : quality="high" combiné au délai d'attente (timeout) par défaut provoque presque systématiquement des erreurs. Le timeout HTTP par défaut du SDK Python d'OpenAI est de 600 secondes. Cela semble suffisant, mais de nombreux utilisateurs, en encapsulant le tout avec requests ou httpx et en définissant un timeout de 60s, rencontrent fréquemment des erreurs ReadTimeout lors de requêtes massives en qualité "high".
Exemple en production : timeouts explicites et tentatives de nouvelle connexion
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Retours d'expérience :
timeout=300est une valeur sûre pour le mode "high", couvrant 99 % des requêtes ; si vous utilisez les modes "low" ou "medium", vous pouvez réduire à 60.max_retries=2utilise le mécanisme de backoff exponentiel intégré au SDK, plus stable qu'une logique de réessai manuelle.output_format="jpeg"+output_compression=85permet généralement de réduire la taille des fichiers PNG de 60 à 70 %, avec une perte de qualité imperceptible à l'œil nu, idéal pour les vignettes Web.
🎯 Conseil sur le timeout : Lors d'une invocation via APIYI (apiyi.com), la plateforme maintient activement les connexions pour les requêtes longues, mais vous devez définir vous-même le timeout du SDK client sans vous fier aux valeurs par défaut. Pour le mode "high", prévoyez au moins 240 secondes ; pour le mode "low", 30 secondes suffisent pour éviter de saturer le pool de connexions avec des requêtes bloquées.
Exemple par lots : génération asynchrone concurrente
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["chat", "chien", "oiseau", "poisson", "lapin"] * 4))
La concurrence est la technique clé pour la génération d'images en masse. En mode "low", une image prend 5 secondes ; 20 images en série prennent 100 secondes, contre seulement 20 secondes avec 5 tâches concurrentes. Attention toutefois à limiter la qualité à "low" ou "medium" : en mode "high", la concurrence fera s'effondrer vos timeouts.
Recommandations de paramètres pour gpt-image-2 selon les scénarios
Voici les combinaisons de paramètres optimales pour les cas d'usage fréquents.
| Scénario métier | quality | size | output_format | Temps estimé | Prix unitaire |
|---|---|---|---|---|---|
| Image e-commerce, Bannière | medium | 1024×1024 | jpeg+85 | 25–35s | 0,053 $ |
| Réseaux sociaux | medium | 1024×1536 | jpeg+85 | 30–40s | ~0,06 $ |
| Couverture d'article, Blog | medium | 1536×1024 | webp+90 | 30–40s | ~0,06 $ |
| Affiche, Prévisualisation | high | 1024×1536 | png | 200–240s | ~0,21 $ |
| Sous-titres / Couverture PPT | high | 1536×1024 | png | 200–240s | ~0,21 $ |
| Vignettes, Tests | low | 1024×1024 | jpeg+75 | 3–8s | 0,006 $ |
| Brouillons, Planches d'inspiration | low | 1024×1024 | jpeg+75 | 3–8s × N | 0,006 $ × N |
| Génération instantanée (Assistant IA) | low | 1024×1024 | webp+85 | 5–10s | 0,006 $ |
Scénario 1 : E-commerce et réseaux sociaux — le "medium" est le juste milieu
Pour ces usages, le temps est critique (l'utilisateur ne peut pas attendre 4 minutes), mais la qualité doit être au rendez-vous. Le mode "medium" est idéal : 30 secondes pour 5 centimes.
Scénario 2 : Affiches et prévisualisation — le prix du temps pour le "high"
Pour les affiches ou couvertures nécessitant du texte ou une cohérence complexe, le mode "high" est indispensable. Ne cherchez pas à réduire le temps, gérez plutôt l'attente côté interface utilisateur en informant que le résultat sera prêt sous 3 à 5 minutes.
Scénario 3 : Lots et prototypes — le "low" est impératif
Pour générer 10 000 brouillons en une nuit, utilisez exclusivement le mode "low". Avec l'asynchronisme et la compression jpeg+75, vous obtiendrez un débit impressionnant.
Scénario 4 : Interaction utilisateur instantanée — privilégiez "low" ou "medium"
Pour les chatbots ou assistants IA, le mode "high" est à proscrire. Une attente de 4 minutes fera fuir 50 % de vos utilisateurs. Utilisez le mode "low" avec une animation de chargement pour un résultat en 5 à 8 secondes. Si la qualité est insuffisante, proposez un bouton "Optimisation HD" pour relancer en "medium".
Scénario 5 : Modération de contenu et conformité
Si une requête est bloquée par la politique de contenu, testez d'abord une nouvelle invite en mode "low". Une fois validée, passez en "medium" ou "high" pour l'image finale. Cette stratégie en deux étapes minimise les coûts en évitant de gaspiller 200 secondes sur une requête qui sera finalement rejetée.
🎯 Stratégie hybride : De nombreux systèmes de production utilisent une "génération à deux niveaux" : une prévisualisation rapide en "low" pour le choix de l'utilisateur, suivie d'une génération finale en "high" une fois le choix validé. Cette stratégie est très fluide sur APIYI (apiyi.com), car une seule clé API couvre tous les niveaux de qualité sans changer de compte.
FAQ : Questions fréquentes
Q1 : Pourquoi mes requêtes de niveau "high" expirent-elles toujours (timeout) ?
Le timeout par défaut du SDK Python d'OpenAI est de 600 secondes, ce qui est théoriquement suffisant. Cependant, de nombreux frameworks (FastAPI, Flask, Celery) ajoutent leur propre timeout en couche externe. Vérifiez les paramètres de délai d'attente sur chaque étape de votre chaîne d'appel ; nous recommandons d'allouer au moins 300 secondes pour l'ensemble du processus en mode "high". Si vous utilisez httpx, n'oubliez pas de définir explicitement httpx.Timeout(300.0).
Q2 : Quelle est la valeur optimale pour output_compression ?
Pour le format JPEG, 85 est le point idéal : la différence avec 100 est imperceptible à l'œil nu, mais la taille du fichier est réduite de 30 à 40 %. Pour le format WebP, 90 est également une valeur courante. En dessous de 70, des blocs de couleur apparaissent, surtout sur les arrière-plans en dégradé. Ce paramètre n'affecte pas le temps de génération, uniquement la sérialisation finale de la sortie.
Q3 : Y a-t-il une différence entre l'invocation du modèle gpt-image-2 via APIYI apiyi.com et les points de terminaison officiels ?
Les paramètres et le comportement sont transmis intégralement, y compris tous les champs tels que quality, size, output_format, output_compression, n, background, etc. La différence réside dans le fait qu'APIYI apiyi.com fournit des nœuds à haut débit accessibles depuis la Chine, une facturation unifiée et un paiement à l'usage sans minimum de consommation, ce qui est plus avantageux pour les développeurs locaux.
Q4 : Le paramètre n permet-il de renvoyer plusieurs images à la fois ?
Oui, gpt-image-2 prend en charge de n=1 à n=10. Attention toutefois : le temps total pour plusieurs images est d'environ 0,7 à 0,9 fois le temps d'une image unique multiplié par n (ce n'est pas totalement en parallèle), et le prix total est calculé en multipliant par n. Si vous avez besoin d'un "ensemble de personnages cohérents", utilisez n=4 pour laisser le modèle générer l'ensemble en une seule inférence ; c'est plus stable que de faire 4 appels séparés, car gpt-image-2 peut maintenir la cohérence faciale au sein d'une même inférence.
Q5 : À quel niveau correspond quality="auto" ?
En pratique, "auto" a tendance à choisir "medium" ou "high", selon la longueur et la complexité de votre invite. Une invite courte ("a cat") aura de fortes chances d'être traitée en "low/medium", tandis qu'une invite longue (incluant des personnages, des scènes, du texte, un style) sera probablement traitée en "high". En environnement de production, nous recommandons de spécifier explicitement le niveau plutôt que de dépendre du jugement implicite d'"auto".
Q6 : La qualité est-elle meilleure en 1024×1536 ou en 1536×1024 ?
Le nombre total de pixels est identique (environ 1,57 million), donc la qualité est intrinsèquement la même. La seule différence réside dans le format : le mode portrait (1024×1536) est idéal pour les affiches, les portraits en pied et le contenu mobile ; le mode paysage (1536×1024) convient aux bannières, aux paysages et aux couvertures PC. Choisissez selon vos besoins de composition, cela n'affecte ni la vitesse ni le prix.
Q7 : Puis-je ignorer l'inférence pour accéder directement au modèle sous-jacent ?
Non, l'inférence "Agentic" de gpt-image-2 fait partie intégrante de l'architecture du modèle et ne peut être désactivée. Si vous avez uniquement besoin d'une génération rapide de style SD traditionnel sans rendu de texte ni inférence complexe, nous vous suggérons d'utiliser le niveau "low", qui ignore la chaîne d'inférence complète. Sinon, envisagez le modèle nano-banana-pro de Google, dont le mode rapide est encore plus véloce que le niveau "low" de gpt-image-2 ; ce modèle est également disponible sur APIYI apiyi.com.
🎯 Conseil de collaboration multi-modèles : Un système de génération d'images mature n'utilise généralement pas qu'un seul modèle. Nous recommandons d'utiliser nano-banana-pro pour les aperçus rapides (réponse en 5 secondes), gpt-image-2 medium pour la production courante, et gpt-image-2 high pour les scènes de haute qualité. Les trois modèles partagent la même clé API sur APIYI apiyi.com avec une facturation à l'usage, ce qui en fait la combinaison la plus rentable pour l'intégration d'API d'images en 2026.
Conclusion : Considérez les paramètres comme des commutateurs de performance, pas comme des décorations
La philosophie de conception de gpt-image-2 diffère radicalement de la génération précédente de modèles d'images : il transforme l'inférence en une étape centrale de la génération. Par conséquent, quality n'est plus une simple option de "qualité visuelle", mais un commutateur déterminant la "profondeur du chemin d'inférence". Comprendre cela permet de saisir pourquoi une même API peut varier de 5 à 235 secondes, soit un écart de performance de 50 fois.
En pratique, nous suggérons de faire de la "sélection des paramètres" la première étape de votre conception : déterminez d'abord la latence tolérée, la qualité requise et le plafond de prix par unité, puis consultez le tableau pour choisir quality et size. Définir ces paramètres à l'avance est bien plus simple que d'essayer de les optimiser après la mise en ligne.
🎯 Conseil final : Lors de l'intégration de gpt-image-2, nous vous recommandons de vous inscrire sur APIYI apiyi.com, d'effectuer un test comparatif sur les trois niveaux (low/medium/high), de noter les temps de réponse et la qualité, puis de décider des paramètres pour votre flux principal. Une seule clé API pour les trois niveaux, une facturation à l'usage et aucun minimum de consommation : c'est la méthode la plus efficace pour intégrer des API d'images en 2026.
— Équipe technique APIYI | Suivi continu des évolutions des modèles de génération d'images. Pour plus de tutoriels approfondis, consultez le centre d'aide sur APIYI apiyi.com.