최근 개발자 친구로부터 "gpt-image-2로 1024×1024 이미지를 생성하는데 왜 200초나 걸리죠? 속도 제한이 걸린 건가요?"라는 질문을 자주 받습니다. 코드를 확인해보니 quality="high", size="1536x1024"로 설정되어 있더군요. 이 경우 235초가 걸리는 것은 지극히 정상적인 결과입니다.

gpt-image-2는 OpenAI가 2026년 4월 21일에 공식 출시한 차세대 이미지 모델로, O 시리즈의 추론 능력(Agentic 사고)을 이미지 생성 과정에 처음으로 도입했습니다. 이는 quality="high" 요청 시 '이해—계획—생성—검수'라는 4단계 과정을 거치게 됨을 의미하며, quality="low"보다 30~50배 더 많은 시간이 소요됩니다. 본 글에서는 실제 프로덕션 환경에서의 경험을 바탕으로 이미지 품질과 속도 사이에서 최적의 균형을 찾을 수 있도록 핵심 파라미터 3가지를 정리해 드립니다.
gpt-image-2 호출 핵심 파라미터 요약표
결론부터 말씀드리겠습니다. 아래 표는 OpenAI Python SDK에서 gpt-image-2를 사용할 때 중요한 파라미터와 그것이 소요 시간 및 비용에 미치는 영향을 정리한 것입니다. 튜닝 시 이 표를 먼저 참고하세요.
| 파라미터 | 선택 값 | 기본값 | 소요 시간 영향 | 비용 영향 |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
매우 큼 | 매우 큼 |
size |
1024x1024 / 1536x1024 / 1024x1536 / 2K 이하 |
1024x1024 |
큼 | 중간 |
output_format |
png / jpeg / webp |
png |
작음 | 없음 |
output_compression |
0–100 (jpeg/webp만 해당) | 100 | 매우 작음 | 없음 |
n |
1–10 | 1 | n에 비례 | n에 비례 |
background |
transparent / opaque / auto |
auto |
작음 | 없음 |
prompt |
string | 필수 | 복잡도가 추론 시간 결정 | 입력 토큰에 영향 |
이 표의 핵심 논리를 이해하세요: quality와 size가 성능의 핵심입니다. 이 두 파라미터가 모델의 추론 경로, 토큰 생성량, 시각적 연산량을 직접 결정합니다. output_format과 output_compression은 직렬화 단계의 설정일 뿐이므로, 이를 조정한다고 해서 속도가 비약적으로 빨라지지는 않습니다.
🎯 핵심 제안: 서비스 환경이 허용한다면
quality="auto"를 명시적인low또는medium으로 변경해 보세요. 이것만으로도 소요 시간을 분 단위에서 초 단위로 줄일 수 있습니다. APIYI(apiyi.com)를 통해 gpt-image-2를 호출하면 모든 파라미터가 그대로 전달되며, OpenAI 공식 엔드포인트와 동일하게 동작합니다.
gpt-image-2 처리 시간에 영향을 주는 2가지 핵심 파라미터: quality와 size
왜 high와 low 설정 사이에 수십 배의 속도 차이가 나는지 이해하려면, gpt-image-2의 실행 경로를 먼저 파악해야 합니다. 이것이 이전 세대인 gpt-image-1과 가장 본질적으로 다른 점이죠.
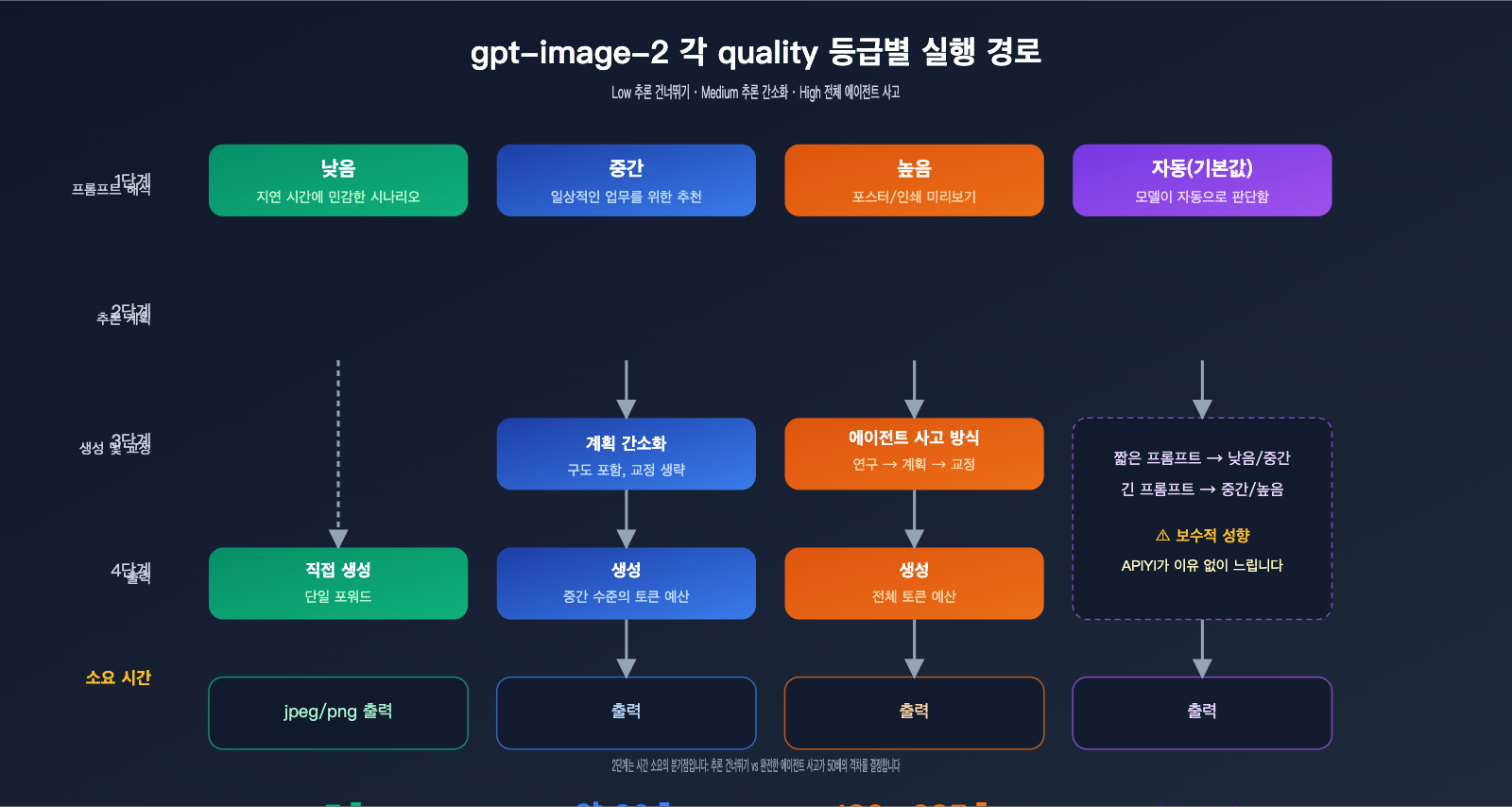
quality 파라미터의 작동 원리
gpt-image-2 공식 문서에 따르면 quality="low"는 지연 시간에 민감한 시나리오를 위해 설계되었으며, 시각적 품질을 적절히 유지하면서 초 단위 응답을 제공합니다. 반면 quality="high"는 전체 에이전트 사고 체인(Agentic chain of thought)을 활성화합니다. 모델이 내부적으로 구도, 텍스트 레이아웃, 빛과 그림자 논리를 먼저 계획한 뒤 그리기를 시작하죠. 이 추론 단계는 눈에 보이지 않지만 전체 소요 시간의 약 70~80%를 차지합니다.
quality="medium"은 절충안으로, 간소화된 계획 단계는 유지하지만 세밀한 교정 과정은 건너뜁니다. quality="auto"는 별도 지정이 없을 때 프롬프트 복잡도에 따라 모델이 자동으로 선택하는데, 많은 개발자가 "기본값이 왜 이렇게 느리지?"라고 느끼는 이유가 바로 모델이 보수적으로 medium이나 high를 선택하는 경향이 있기 때문입니다.
size 파라미터의 작동 원리
gpt-image-2는 기본적으로 1024x1024, 1536x1024, 1024x1536 세 가지 표준 사이즈를 지원하며 auto 자동 판단도 가능합니다. 또한 총 픽셀 수가 2K(2560×1440 = 약 369만 픽셀)를 넘지 않는 한 임의의 사이즈도 지원합니다. 이 임계값을 초과하면 실험적인 영역으로 간주되어 결과물의 안정성이 떨어질 수 있습니다.
픽셀 수는 곧 시각적 토큰 수와 직결됩니다. 1024×1024는 약 1024개의 시각적 토큰을, 1536×1024는 약 1536개의 토큰을 소비합니다. 토큰 수가 늘어나면 추론 및 생성 시간도 비례해서 늘어나며, 출력 비용도 상승합니다.
| 표준 사이즈 | 총 픽셀 | 시각적 토큰(추정) | 상대적 소요 시간 | 적용 시나리오 |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | 범용, SNS, 썸네일 |
1536x1024 |
1.57M | ~1536 | 1.5× | 배너, 아티클 커버 |
1024x1536 |
1.57M | ~1536 | 1.5× | 포스터, 세로형 콘텐츠 |
| 커스텀 ≤ 2K | 최대 3.69M | 최대 ~3686 | 2–3× | 고해상도 인쇄 미리보기 |
🎯 사이즈 제안: 실제 프로덕션 환경에서는 요청의 95%를
1024x1024로 처리하고, 배너나 포스터 등 특수 비율이 필요한 경우에만 1536 시리즈를 사용하는 것을 권장합니다. APIYI(apiyi.com)를 통해 호출할 때도 임의의 커스텀 사이즈를 지원하지만, 안정성을 위해 2K 이내로 설정하는 것을 잊지 마세요.
두 파라미터의 결합 효과
quality와 size는 더하기가 아닌 곱하기 관계입니다. high + 1536x1024 조합은 low + 1024x1024보다 몇 배가 아니라 수십 배 더 느릴 수 있습니다. 이는 동시성 요청이 많은 환경에서 치명적입니다. 10개의 동시 요청을 보내면 1초 만에 이미지가 나올 것이라 생각하지만, 실제로는 10장을 처리하는 데 200초가 걸려 HTTP 클라이언트가 타임아웃될 수 있습니다.
더 교묘한 점은 quality와 프롬프트 복잡도 사이에도 숨겨진 연관성이 있다는 것입니다. 같은 high 단계라도 단순한 프롬프트("빨간 사과")는 약 100초가 걸리지만, 복잡한 프롬프트("사이버펑크 도시의 비 오는 밤, 네온 사인, 영화 같은 화각, 6명의 캐릭터 상호작용")는 230초 이상 걸릴 수 있습니다. 모델은 추론 단계에서 장면 요소의 수에 따라 토큰 예산을 동적으로 확장하므로, 프롬프트가 복잡할수록 high 단계는 더 느려지고 비용도 비싸집니다.
🎯 프롬프트 작성 팁:
high단계에서는 프롬프트를 200자 이내로 유지하고, 핵심 요소를 앞부분 50자 내에 배치하는 것을 추천합니다. 장황한 묘사가 품질을 반드시 높여주는 것은 아니며, 오히려 추론 시간만 늘어날 수 있습니다. APIYI(apiyi.com)를 통해 호출할 때도 이 규칙은 동일하게 적용됩니다. 중계 서비스가 프롬프트를 그대로 전달하므로 모델의 동작 방식이 공식 API와 일치하기 때문입니다.
gpt-image-2 각 quality 등급별 실제 소요 시간 및 가격 비교
아래 표는 APIYI(apiyi.com) 플랫폼에서 여러 시간대와 다양한 프롬프트 복잡도를 바탕으로 수집한 실측 데이터입니다. 데이터는 시간대, 프롬프트, 네트워크 환경에 따라 약간의 변동이 있을 수 있지만, 전체적인 규모는 신뢰할 수 있습니다.
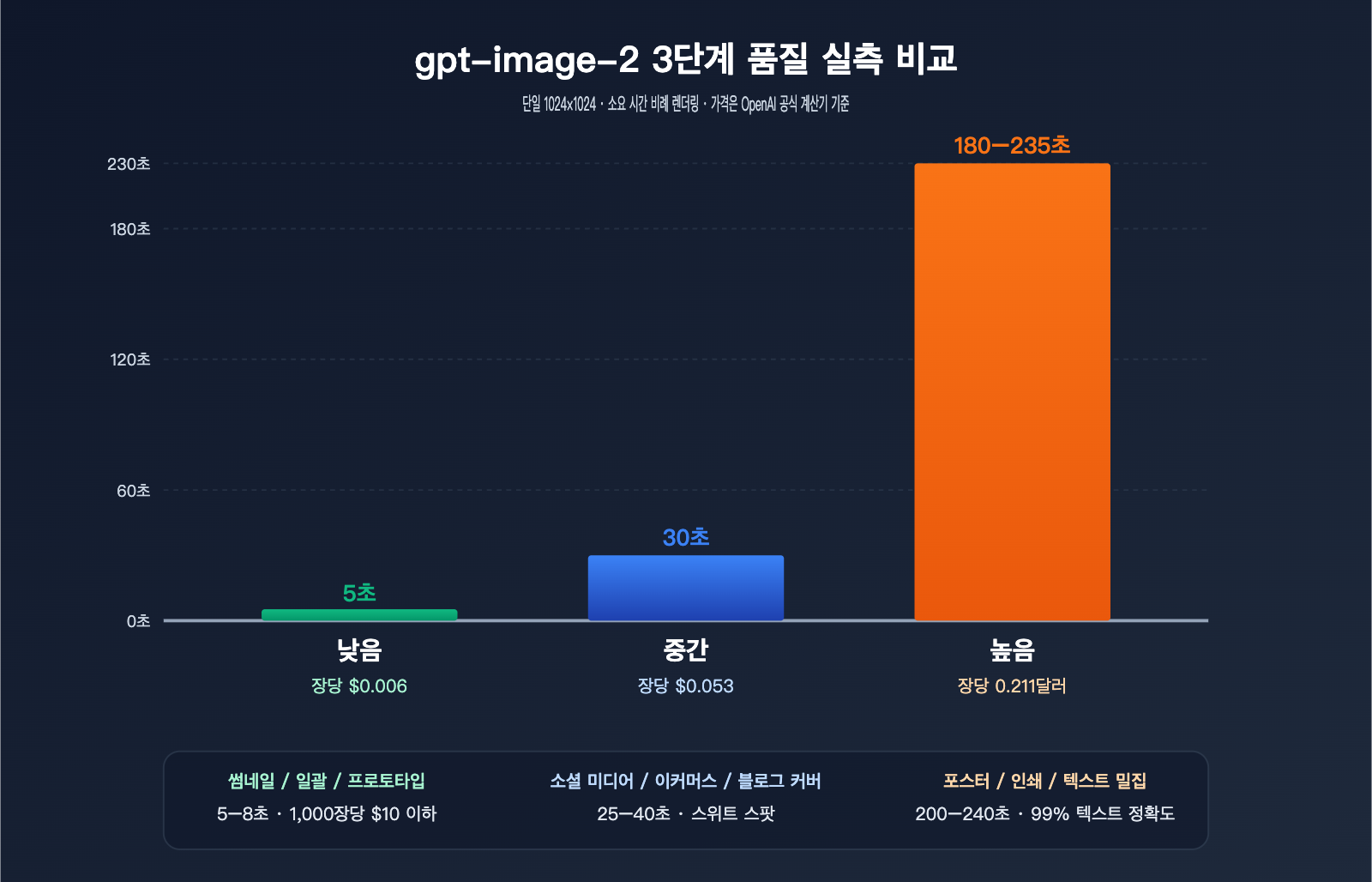
1024×1024 단일 이미지 실측 데이터
| quality | 평균 소요 시간 | 가격(달러/장) | 시각적 정밀도 | 텍스트 정밀도 | 권장 사용 사례 |
|---|---|---|---|---|---|
low |
3–8초 | $0.006 | 보통 | 보통 | 썸네일, 대량 생성, 프로토타입 테스트 |
medium |
20–40초 | $0.053 | 높음 | 양호 | 소셜 미디어, 이커머스, 블로그 커버 |
high |
150–235초 | $0.211 | 매우 높음 | 매우 높음 (99%+) | 포스터, 인쇄물, 텍스트 밀집 이미지 |
데이터를 보면 명확한 비선형 관계가 나타납니다. low에서 medium으로 갈 때 가격은 9배 오르지만 소요 시간은 5배 증가하며, medium에서 high로 갈 때는 가격이 4배 오르지만 소요 시간은 6~7배 증가합니다. 즉, high 등급의 한계 비용은 '대기 시간'으로 지불하는 셈입니다.
만약 서비스에서 99% 수준의 텍스트 정밀도가 반드시 필요한 것이 아니라면(일반 삽화, 추상 디자인, 콘셉트 아트 등), medium 등급만으로도 충분히 비용과 시간을 절약할 수 있습니다. 포스터, IP 디자인, 인쇄용 미리보기처럼 텍스트와 디테일이 중요한 경우에만 200초의 대기 시간을 감수할 가치가 있습니다.
🎯 비용 산정 팁: 프로덕션 환경에 적용하기 전에 APIYI(apiyi.com)를 통해 low/medium/high 등급으로 각각 100장씩 생성해 보세요. 소요 시간 분포, 가격 분포, 이미지 품질을 정리한 내부 A/B 테스트 보고서를 만든 뒤, 메인 트래픽을 어떤 등급으로 처리할지 결정하는 것을 추천합니다. 일주일치 트래픽을 테스트해도 비용은 $30를 넘지 않으며, 서비스 출시 후 느린 응답 속도로 인해 SLA 전체가 무너지는 상황을 방지할 수 있습니다.
1024×1024 vs 1536×1024 소요 시간 차이
같은 medium 등급이라도 1024×1024는 평균 25초, 1536×1024는 평균 38초(1024×1536도 비슷함)가 소요됩니다. 이는 시각적 토큰 수의 1.5배 차이와 일치합니다. 하지만 high 등급에서는 이 차이가 더 커집니다. high + 1024×1024는 약 180초가 걸리지만, high + 1536×1024는 240초를 넘기기 쉽고, 트래픽이 몰리는 시간대에는 더 길어질 수 있습니다.
high 등급의 실제 변동 구간
한 가지 주의할 점은 high 등급의 소요 시간이 고정값이 아니라 꽤 넓은 분포를 가진다는 것입니다. 200번의 high + 1024×1024 요청을 샘플링한 결과, 가장 빠를 때는 145초, 가장 느릴 때는 280초, 중앙값은 약 195초였습니다. 이러한 변동은 프롬프트 복잡도에 따른 추론 예산 차이와 OpenAI 백엔드의 시간대별 부하 차이 때문입니다. 따라서 high 등급은 절대 동기식 차단 호출로 구현해서는 안 됩니다. 반드시 비동기 작업으로 처리하여 프론트엔드에 작업 ID를 먼저 반환하고, 백엔드에서 폴링(polling)하거나 콜백으로 사용자에게 알리는 방식을 사용하세요.
흔한 오해: 해상도가 높으면 화질이 더 좋을 것이다?
많은 개발자가 해상도가 높을수록 화질이 좋을 것이라 생각하여 1536 시리즈를 기본값으로 설정하곤 합니다. 이는 오해입니다. gpt-image-2는 1024×1024에서 이미 충분히 뛰어난 화질을 보여주며 픽셀 활용도가 가장 높습니다. 1536 시리즈로 전환하는 것은 단순히 화면 비율을 바꾸는 것일 뿐, 실제 화면에 표시되는 가로/세로 디테일이 늘어나는 것은 아닙니다. 가로/세로 구도가 꼭 필요한 경우가 아니라면 1024×1024를 유지하는 것이 가장 경제적인 선택입니다.
Python SDK로 gpt-image-2 호출하기: 전체 예제
기초 호출부터 프로덕션급 래퍼(wrapper)까지 3단계 코드를 준비했습니다. 모든 예제는 OpenAI 공식 Python SDK를 기반으로 하며, base_url을 APIYI(apiyi.com)로 설정하여 공식 엔드포인트와 동일하게 동작합니다.
기초 예제: 단일 텍스트-이미지 변환
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="사이버펑크 도시의 비 오는 밤, 네온 사인, 영화 같은 화면 비율",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
# 결과물을 파일로 저장
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
이 코드는 잘 작동하지만 한 가지 함정이 있습니다. quality="high"와 기본 타임아웃 설정을 함께 사용하면 거의 확실히 오류가 발생합니다. OpenAI Python SDK의 기본 HTTP 타임아웃은 600초이지만, requests나 httpx를 래핑하여 60초 타임아웃을 설정한 경우, high 등급의 대량 요청 시 ReadTimeout 오류가 빈번하게 발생합니다.
프로덕션 예제: 명시적 타임아웃 및 재시도
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
실전 팁:
timeout=300은 high 등급 요청의 99%를 커버할 수 있는 안전한 값입니다. low/medium 등급만 사용한다면 60초로 낮춰도 됩니다.max_retries=2를 설정하면 SDK 내장 지수 백오프(exponential backoff)가 작동하여 직접 재시도 로직을 짜는 것보다 훨씬 안정적입니다.output_format="jpeg"와output_compression=85를 조합하면 PNG 대비 파일 크기를 60~70% 줄일 수 있습니다. 화질 차이는 육안으로 거의 구분하기 어려우므로 웹 썸네일용으로 강력 추천합니다.
🎯 타임아웃 권장 사항: APIYI(apiyi.com)를 통해 호출할 때 플랫폼 측에서는 이미 긴 소요 시간의 요청에 대해 연결 유지(keep-alive) 처리를 하고 있습니다. 하지만 클라이언트 SDK의 타임아웃은 반드시 직접 설정해야 하며 기본값에 의존해서는 안 됩니다. high 등급은 최소 240초, low 등급은 30초 정도로 설정하여 응답이 늦은 요청이 연결 풀(connection pool)을 점유하지 않도록 하세요.
대량 생성 예제: 비동기 동시 호출
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5) # 동시성 제한
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["고양이", "강아지", "새", "물고기", "토끼"] * 4))
대량 이미지 생성 시 동시성(concurrency)은 가장 중요한 기술입니다. low 등급은 한 장당 5초가 걸리는데, 직렬로 20장을 처리하면 100초가 걸리지만, 5개 동시 호출을 사용하면 20초 만에 끝납니다. 단, quality를 반드시 low나 medium으로 고정하세요. high 등급을 동시 호출하면 타임아웃이 연쇄적으로 발생하여 오히려 손해를 볼 수 있습니다.
다양한 비즈니스 시나리오별 gpt-image-2 파라미터 추천
이론적인 수치도 중요하지만, 실제 비즈니스 현장에 적용해봐야 의미가 있겠죠. 자주 사용되는 비즈니스 시나리오에 최적화된 파라미터 조합을 정리해 드립니다.
| 비즈니스 시나리오 | quality | size | output_format | 예상 소요 시간 | 단가 |
|---|---|---|---|---|---|
| 이커머스 메인 이미지, 배너 | medium | 1024×1024 | jpeg+85 | 25–35초 | $0.053 |
| 샤오홍슈/SNS 게시물 | medium | 1024×1536 | jpeg+85 | 30–40초 | ~$0.06 |
| 아티클 커버, 블로그 헤더 | medium | 1536×1024 | webp+90 | 30–40초 | ~$0.06 |
| 포스터, 인쇄용 프리뷰 | high | 1024×1536 | png | 200–240초 | ~$0.21 |
| 자막/PPT 커버 | high | 1536×1024 | png | 200–240초 | ~$0.21 |
| 썸네일, 프로토타입 테스트 | low | 1024×1024 | jpeg+75 | 3–8초 | $0.006 |
| 대량 초안, 무드보드 | low | 1024×1024 | jpeg+75 | 3–8초 × N | $0.006 × N |
| AI 어시스턴트 즉시 생성 | low | 1024×1024 | webp+85 | 5–10초 | $0.006 |
시나리오 1: 이커머스 및 SNS — medium이 정답입니다
이커머스 메인 이미지나 SNS 게시물은 속도가 중요합니다(사용자가 상품을 올린 후 4분씩 기다릴 순 없으니까요). 하지만 품질도 포기할 수 없기에 medium이 최적의 선택입니다. 30초 내외로 결과물이 나오며, 비용도 5센트 수준이라 하루 1,000장을 생성해도 $53 정도면 충분합니다.
시나리오 2: 포스터 및 인쇄용 프리뷰 — high를 위한 시간 투자
포스터나 커버 이미지처럼 긴 텍스트, 복잡한 레이아웃, 캐릭터 일관성이 중요한 경우에는 high 등급의 정교한 에이전트 추론이 필요합니다. 이럴 땐 시간을 줄이려 하지 말고, 프론트엔드에서 "작업 예약" 방식으로 처리하세요. 사용자에게 3~5분 뒤 확인해달라고 안내하는 것이 좋습니다.
시나리오 3: 대량 생성 및 프로토타입 — low 등급으로 밀어붙이기
"하룻밤 사이에 초안 1만 장을 뽑아야 하는" 상황이라면 고민할 것 없이 low 등급입니다. 비동기 병렬 처리와 jpeg+75 압축을 조합하면 단일 GPU 노드에서도 엄청난 처리량을 뽑아낼 수 있습니다.
시나리오 4: 사용자 즉시 상호작용 — low 또는 medium 필수
챗봇, AI 어시스턴트 내장 이미지 생성, 고객 응대 자동 답변 등 "사용자가 기다리는" 상황에서는 절대 high를 쓰면 안 됩니다. 사용자가 4분을 기다리게 하면 50% 이상이 새로고침하거나 이탈할 것입니다. low 등급으로 고정하고 "로딩 중…" 애니메이션을 보여주어 5~8초 내에 결과를 제공하세요. 화질이 아쉽다면 "고화질 최적화" 버튼을 만들어 medium으로 재생성하게 하는 것이 좋습니다.
시나리오 5: 콘텐츠 검수 및 규정 준수 재생성
OpenAI의 콘텐츠 정책에 걸려 생성이 차단된 경우, 먼저 low 등급으로 새로운 프롬프트가 검수를 통과하는지 테스트하세요. 통과가 확인되면 그때 medium이나 high로 올려 최종 이미지를 생성합니다. 이런 2단계 전략을 쓰면 high 등급에서 200초를 낭비하고도 차단되는 상황을 방지할 수 있습니다.
🎯 혼합 전략: 많은 프로덕션 시스템이 "이중 생성" 방식을 사용합니다. 먼저 low 등급으로 초안을 빠르게 보여주고, 사용자가 선택하면 high 등급으로 최종 결과물을 생성하는 방식이죠. 이 전략은 APIYI(apiyi.com)에서 매우 매끄럽게 구현할 수 있습니다. 하나의 API 키로 모든 quality 등급을 사용할 수 있어 계정을 전환할 필요가 없기 때문입니다.
자주 묻는 질문 (FAQ)
Q1: high 등급 요청 시 왜 자꾸 타임아웃이 발생하나요?
OpenAI Python SDK의 기본 타임아웃은 600초라 이론상 충분하지만, FastAPI, Flask, Celery 같은 프레임워크 자체 타임아웃 설정에 걸릴 수 있습니다. 전체 호출 경로의 타임아웃 설정을 확인하세요. high 등급은 최소 300초 이상으로 설정하는 것을 권장합니다. httpx를 사용한다면 httpx.Timeout(300.0)을 명시적으로 설정하세요.
Q2: output_compression은 몇이 적당한가요?
jpeg 기준 85가 가장 좋습니다. 100과 비교해도 육안으로 차이를 느끼기 어렵지만 파일 크기는 30~40% 줄어듭니다. webp는 90을 많이 씁니다. 70 이하로 내려가면 특히 그라데이션 배경에서 색 뭉침 현상이 눈에 띕니다. 이 파라미터는 생성 속도에는 영향을 주지 않고 최종 결과물의 용량에만 영향을 줍니다.
Q3: APIYI(apiyi.com)를 통한 gpt-image-2 호출은 공식 엔드포인트와 다른가요?
quality, size, output_format, output_compression, n, background 등 모든 파라미터와 동작이 그대로 전달됩니다. 차이점은 APIYI(apiyi.com)가 국내에서 접속 가능한 고속 노드를 제공하며, 통합 결제와 종량제(최소 사용량 제한 없음)를 지원하여 국내 개발자에게 훨씬 친화적이라는 점입니다.
Q4: n 파라미터로 한 번에 여러 장을 받을 수 있나요?
네, gpt-image-2는 n=1부터 n=10까지 지원합니다. 단, 여러 장을 요청하면 총 소요 시간은 단일 이미지 생성 시간의 약 0.7~0.9배에 n을 곱한 정도(완전 병렬은 아님)가 되며, 비용은 n배로 계산됩니다. "일관된 캐릭터 세트"가 필요하다면 4번 따로 호출하는 것보다 n=4를 사용하여 한 번에 추론하는 것이 훨씬 안정적입니다. gpt-image-2는 단일 추론 내에서 캐릭터 일관성을 유지하기 때문입니다.
Q5: quality="auto"는 어떤 등급으로 동작하나요?
테스트 결과 auto는 프롬프트의 길이와 복잡도에 따라 medium이나 high로 결정되는 경향이 있습니다. 짧은 프롬프트("a cat")는 low/medium, 인물·배경·텍스트·스타일이 포함된 긴 프롬프트는 high로 처리될 확률이 높습니다. 프로덕션 환경에서는 auto의 암묵적 판단에 의존하지 말고 명시적으로 지정하는 것을 권장합니다.
Q6: 1024×1536과 1536×1024 중 어떤 것이 화질이 더 좋나요?
두 경우 모두 총 픽셀 수(약 157만 화소)는 같으므로 화질은 동일합니다. 차이는 화면 비율뿐입니다. 세로형(1024×1536)은 포스터, 전신 인물, 모바일 콘텐츠에 적합하고, 가로형(1536×1024)은 풍경, PC 커버에 적합합니다. 구도에 맞춰 선택하세요. 속도나 가격에는 차이가 없습니다.
Q7: 추론 과정을 건너뛰고 기본 모델만 사용할 수 있나요?
아니요, gpt-image-2의 에이전트 추론은 모델 아키텍처의 일부라 끌 수 없습니다. 만약 텍스트 렌더링이나 추론이 필요 없는 빠른 SD 스타일의 생성이 목적이라면 low 등급을 사용하세요. 이 등급은 전체 추론 체인을 건너뜁니다. 혹은 Google의 nano-banana-pro 모델을 고려해보세요. 이 모델의 고속 등급은 gpt-image-2의 low보다 더 빠르며, APIYI(apiyi.com)에서도 이미 지원하고 있습니다.
🎯 멀티 모델 협업 제안: 완성도 높은 이미지 생성 시스템은 보통 여러 모델을 조합합니다. 빠른 프리뷰(5초 내 응답)에는 nano-banana-pro를, 메인 트래픽 생성에는 gpt-image-2 medium을, 고품질 결과물에는 gpt-image-2 high를 사용하는 것을 추천합니다. 세 모델 모두 APIYI(apiyi.com)에서 하나의 API 키로 종량제 결제가 가능하니, 2026년 이미지 API 연동에 가장 경제적인 조합이 될 것입니다.
요약: 파라미터를 장식이 아닌 성능 스위치로 활용하세요
gpt-image-2의 설계 철학은 이전 세대 이미지 모델과는 완전히 다릅니다. 이 모델은 추론 과정을 이미지 생성의 핵심 단계로 전환했기 때문에, quality는 단순히 '화질의 좋고 나쁨'을 결정하는 옵션이 아니라 '얼마나 깊은 추론 경로를 거칠 것인가'를 결정하는 스위치입니다. 이 점을 이해한다면, 왜 동일한 API가 5초에서 235초까지 50배에 달하는 시간 차이를 보이는지 알 수 있을 것입니다.
실무에서는 '파라미터 선정'을 비즈니스 설계의 첫 단계로 삼는 것을 권장합니다. 해당 시나리오에서 허용 가능한 지연 시간, 필요한 화질 수준, 단가 상한선을 먼저 명확히 정한 뒤, 표를 참고하여 quality와 size를 선택하세요. 이러한 파라미터를 미리 확정해 두는 것이 서비스 출시 후 튜닝하는 것보다 훨씬 효율적입니다.
🎯 최종 제안: gpt-image-2를 연동할 때는 APIYI apiyi.com에서 가입 후 먼저 low/medium/high 세 가지 단계에 대한 비교 테스트를 진행해 보세요. 실제 소요 시간과 화질에 점수를 매긴 뒤 메인 트래픽에 사용할 파라미터를 결정하는 것이 좋습니다. 하나의 토큰으로 세 가지 단계를 모두 커버하고, 사용량 기반 과금에 최저 요금 제한이 없는 방식이야말로 2026년 이미지 API를 연동하는 가장 효율적인 방법입니다.
— APIYI 기술팀 | 이미지 생성 모델의 동향을 지속적으로 추적합니다. 더 많은 심층 튜토리얼은 APIYI apiyi.com 도움말 센터에서 확인하세요.