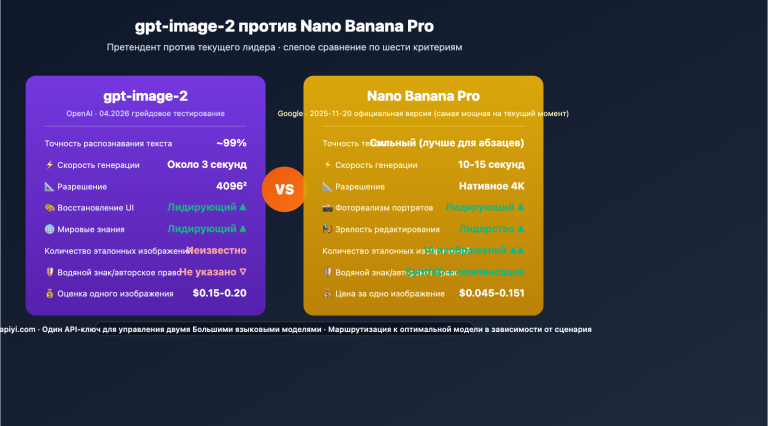
Недавно один разработчик, наш клиент, задал мне популярный вопрос: «Почему при вызове gpt-image-2 генерация картинки 1024×1024 занимает более 200 секунд? Меня ограничили по скорости?». Заглянул в его код: параметры по умолчанию стоят quality="high" и size="1536x1024". В итоге 235 секунд на одно изображение — это вполне ожидаемый результат.

gpt-image-2 — это новая модель генерации изображений, представленная OpenAI 21 апреля 2026 года. Она впервые привнесла возможности рассуждения серии O (Agentic reasoning) в процесс создания картинок. Это означает, что запрос с quality="high" проходит через четыре полных этапа: «понимание — планирование — генерация — проверка», что в 30–50 раз дольше, чем при quality="low". В этой статье, основываясь на реальном опыте эксплуатации, я разберу три ключевых параметра, чтобы вы могли найти идеальный баланс между качеством и скоростью.
Таблица ключевых параметров вызова gpt-image-2
Сразу к делу. В таблице ниже собраны все важные параметры gpt-image-2 в Python SDK от OpenAI, а также их влияние на время отклика и стоимость. Рекомендую сверяться с ней при оптимизации.
| Параметр | Допустимые значения | Значение по умолчанию | Влияние на время | Влияние на цену |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Очень сильное | Очень сильное |
size |
1024x1024 / 1536x1024 / 1024x1536 / любое ≤ 2K |
1024x1024 |
Сильное | Среднее |
output_format |
png / jpeg / webp |
png |
Слабое | Нет |
output_compression |
0–100 (только для jpeg/webp) | 100 | Очень слабое | Нет |
n |
1–10 | 1 | Пропорционально n | Пропорционально n |
background |
transparent / opaque / auto |
auto |
Слабое | Нет |
prompt |
string | Обязательно | Сложность влияет на время | Влияет на входные токены |
Главная логика здесь такова: quality и size — это критические факторы. Они напрямую определяют путь рассуждения модели, количество токенов и вычислительные затраты. output_format и output_compression относятся только к этапу сериализации, их изменение не ускорит генерацию.
🎯 Главный совет: Если ваш сценарий позволяет, замените
quality="auto"на явноеlowилиmedium. Одно это действие часто сокращает время ожидания с минут до секунд. При вызовеgpt-image-2через сервис-прокси API APIYI (apiyi.com) все эти параметры передаются «как есть», поведение полностью соответствует официальным эндпоинтам OpenAI.
2 ключевых параметра, влияющих на время выполнения gpt-image-2: quality и size
Чтобы понять, почему разница между high и low может достигать десятков раз, нужно разобраться в пути выполнения gpt-image-2. Это фундаментальное отличие от предыдущего поколения gpt-image-1.
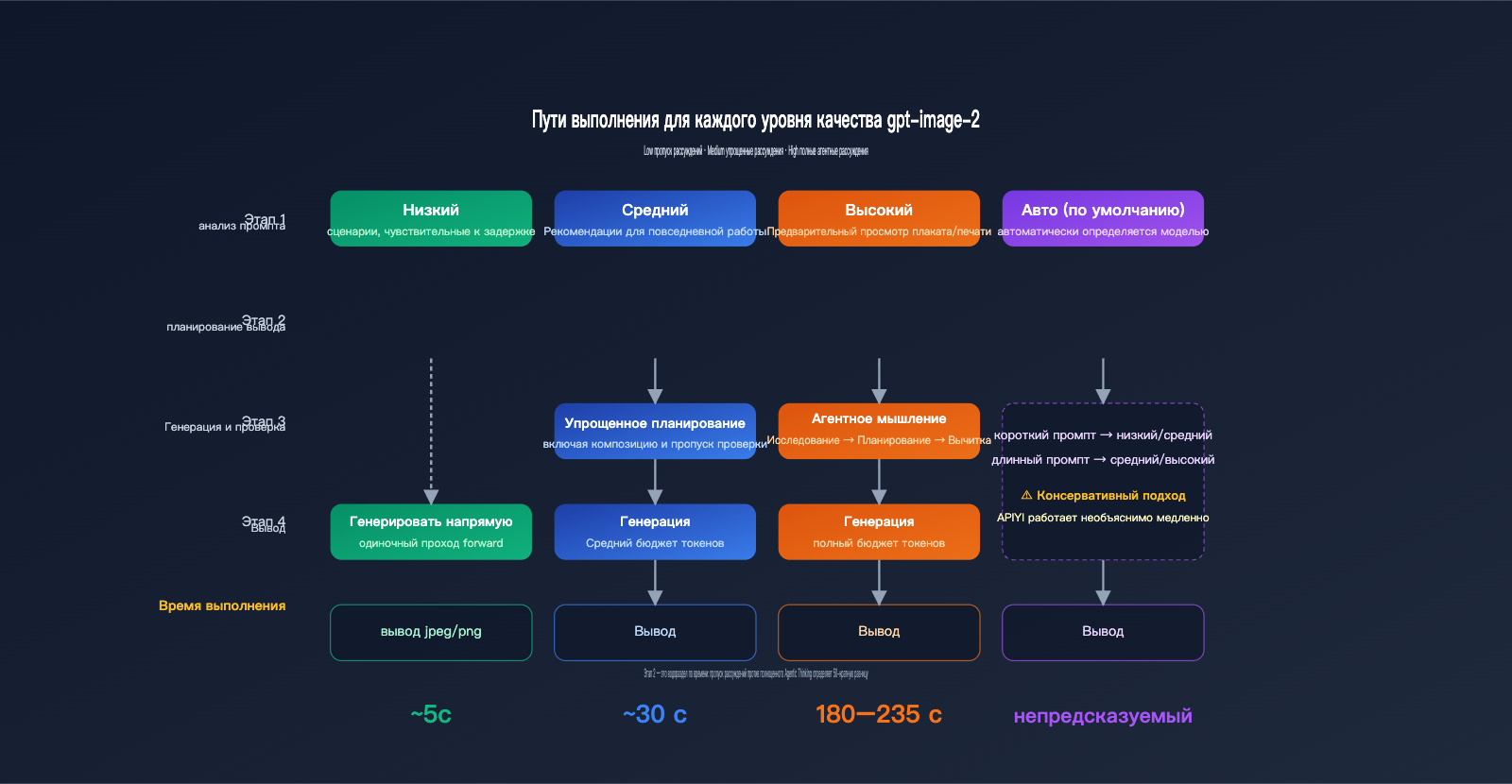
Механизм работы параметра quality
Официальная документация gpt-image-2 четко указывает, что quality="low" предназначен для сценариев, чувствительных к задержкам, обеспечивая ответ за секунды при приемлемом визуальном качестве. В свою очередь, quality="high" активирует полноценную цепочку агентских рассуждений (Agentic reasoning chain) — модель сначала планирует композицию, расположение текста и логику освещения, и только потом приступает к отрисовке. Этот этап рассуждений невидим для пользователя, но занимает около 70–80% от общего времени выполнения.
quality="medium" — это компромиссный вариант: он сохраняет упрощенное планирование, но пропускает этап детальной проверки. Если параметр quality="auto" не задан явно, модель выбирает его на основе сложности промпта, но на практике она склонна выбирать medium или high с запасом, из-за чего многие разработчики ошибочно считают, что «по умолчанию всегда медленно».
Механизм работы параметра size
gpt-image-2 нативно поддерживает три стандартных размера: 1024x1024, 1536x1024 и 1024x1536, плюс автоматическое определение auto. Также поддерживается передача произвольных размеров, если общее количество пикселей не превышает 2K (2560×1440 ≈ 3,69 млн пикселей). Превышение этого порога переводит генерацию в экспериментальную зону, где стабильность результата снижается.
Количество пикселей напрямую определяет количество визуальных токенов. 1024×1024 — это около 1024 визуальных токенов, 1536×1024 — около 1536, и так далее. Удвоение количества токенов означает удвоение времени на логический вывод и генерацию, а также удвоение стоимости.
| Стандартный размер | Всего пикселей | Визуальные токены (прибл.) | Относительное время | Сценарии использования |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | Общие задачи, соцсети, превью |
1536x1024 |
1.57M | ~1536 | 1.5× | Баннеры, обложки статей |
1024x1536 |
1.57M | ~1536 | 1.5× | Постеры, вертикальный контент |
| Пользовательский ≤ 2K | до 3.69M | до ~3686 | 2–3× | Печатные превью высокого разрешения |
🎯 Совет по выбору размера: В реальных проектах рекомендую в 95% случаев использовать
1024x1024, переключаясь на серию 1536 только для баннеров или постеров. При вызове через APIYI (apiyi.com) поддерживаются любые размеры, но старайтесь не превышать 2K для обеспечения стабильности.
Эффект сочетания параметров
Параметры quality и size работают в связке как множители, а не слагаемые. Комбинация high + 1536x1024 будет медленнее low + 1024x1024 не в несколько, а в десятки раз. Это критично для сценариев с высокой нагрузкой: вы можете ожидать, что 10 параллельных запросов выполнятся за секунду, но на деле получите 10 изображений за 200 секунд, и HTTP-клиент давно выдаст ошибку по таймауту.
Еще более скрытая зависимость существует между quality и сложностью промпта. Даже в режиме high простой промпт (например, "a red apple") может обрабатываться 100 секунд, а сложный ("киберпанк-город в дождливую ночь, неоновые вывески, киношный кадр, взаимодействие 6 персонажей") легко превысит 230 секунд. Модель динамически расширяет бюджет токенов в зависимости от количества элементов на сцене, поэтому чем сложнее промпт, тем медленнее работает high и тем выше стоимость.
🎯 Совет по написанию промптов: В режиме
highстарайтесь ограничивать промпт 200 символами и выносить ключевые элементы в первые 50 символов. Избыточное описание не всегда улучшает результат, но гарантированно увеличивает время обработки. При вызове через APIYI (apiyi.com) это правило также работает, так как наш сервис-прокси API полностью передает промпт, и поведение модели идентично официальному.
Сравнение времени выполнения и стоимости для разных уровней качества gpt-image-2
В таблице ниже представлены данные, собранные нами на платформе APIYI (apiyi.com) в разное время и с использованием промптов разной сложности. Хотя показатели могут незначительно колебаться в зависимости от нагрузки на сеть и сложности запроса, общая картина вполне достоверна.
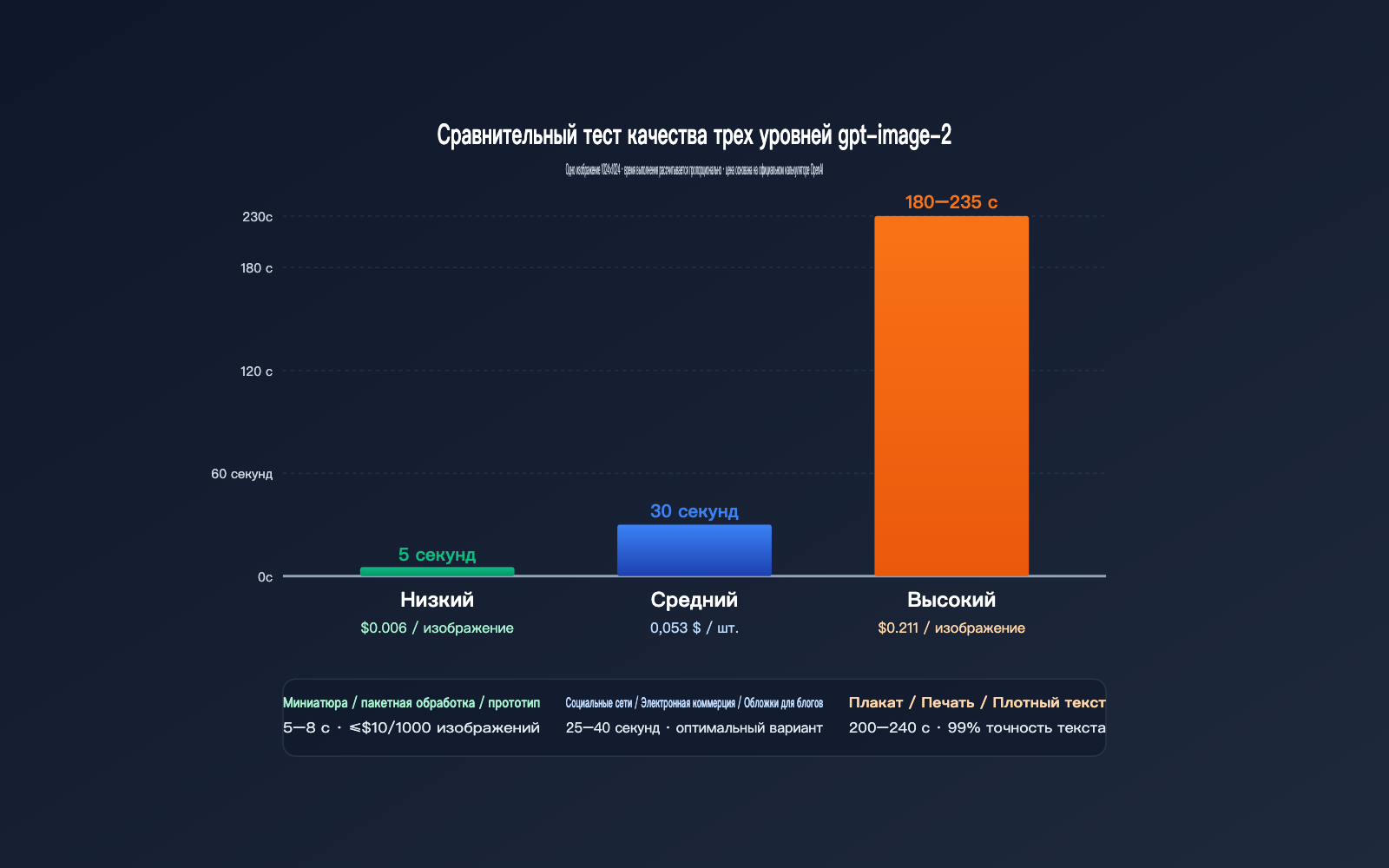
Фактические данные для изображения 1024×1024
| quality | Среднее время | Цена ($/изобр.) | Визуальная точность | Точность текста | Сценарии использования |
|---|---|---|---|---|---|
low |
3–8 сек | $0.006 | Средняя | Обычная | Миниатюры, пакетная обработка, прототипы |
medium |
20–40 сек | $0.053 | Высокая | Хорошая | Соцсети, e-commerce, обложки блогов |
high |
150–235 сек | $0.211 | Очень высокая | Отличная (99%+) | Плакаты, печать, текст в кадре |
Мы видим явную нелинейную зависимость: при переходе с low на medium цена вырастает в 9 раз, а время — всего в 5 раз; при переходе с medium на high цена растет в 4 раза, а время — в 6–7 раз. Иными словами, за высокое качество вы платите своим временем ожидания.
Если ваш проект не требует 99% точности текста (например, для иллюстраций, абстрактного дизайна или концепт-артов), уровня medium будет вполне достаточно — это сэкономит и деньги, и время. Только для плакатов, дизайна персонажей или предпечатной подготовки, где критически важны детали и текст, стоит ждать 200 секунд.
🎯 Совет по расчету затрат: перед запуском в продакшн рекомендуем прогнать по 100 запросов для каждого уровня (low/medium/high) через APIYI (apiyi.com). Сделайте внутренний A/B отчет по времени отклика, стоимости и качеству, чтобы понять, какой уровень выбрать для основного трафика. Затраты на тест не превысят $30, зато вы убережете систему от просадки SLA из-за слишком медленных запросов.
Разница во времени: 1024×1024 vs 1536×1024
Для уровня medium: 1024×1024 занимает в среднем 25 секунд, а 1536×1024 — около 38 секунд (так же как и 1024×1536). Разница соответствует увеличению количества визуальных токенов в 1.5 раза. Однако на уровне high эта разница становится заметнее: high + 1024×1024 занимает около 180 секунд, а high + 1536×1024 может превышать 240 секунд, особенно в часы пик.
Фактический диапазон времени для уровня high
Важно помнить, что время выполнения для high не является константой — это довольно широкий диапазон. Мы проанализировали 200 запросов high + 1024×1024: самый быстрый занял 145 секунд, самый медленный — 280 секунд, медиана составила около 195 секунд. Это связано с двумя факторами: сложностью промпта (влияет на бюджет вычислений) и текущей нагрузкой на бэкенд OpenAI. Поэтому для уровня high категорически нельзя использовать синхронные блокирующие вызовы — только асинхронные задачи: фронтенд получает ID задачи, а бэкенд опрашивает статус или ждет callback.
Распространенное заблуждение: большее разрешение — лучше качество
Многие разработчики интуитивно считают, что чем выше разрешение, тем лучше картинка, и по умолчанию выбирают серию 1536. Это ошибка. Качество gpt-image-2 при 1024×1024 уже максимально проработано, и плотность пикселей там оптимальна. Переход на 1536 просто меняет формат кадра, но количество деталей, которые реально отображаются на экране, не увеличивается. Если вам не нужен специфический горизонтальный или вертикальный формат, 1024×1024 остается самым выгодным выбором.
Полное руководство по вызову gpt-image-2 через Python SDK
Ниже представлены три варианта кода: от базового вызова до промышленной реализации. Все примеры основаны на официальном Python SDK от OpenAI, где base_url указывает на сервис-прокси API APIYI (apiyi.com), что обеспечивает полную совместимость с официальными эндпоинтами.
Базовый пример: генерация одного изображения (текст-в-изображение)
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Киберпанк-город, дождливая ночь, неоновые вывески, кинематографичный кадр",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Этот код рабочий, но есть нюанс: комбинация quality="high" и стандартного таймаута почти гарантированно приведет к ошибке. По умолчанию в Python SDK OpenAI таймаут HTTP составляет 600 секунд. Звучит солидно, но если вы используете обертку на базе requests или httpx с собственным лимитом в 60 секунд, при массовых запросах в режиме high вы будете постоянно получать ReadTimeout.
Промышленный пример: явное управление таймаутами и повторными попытками
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Практические советы:
timeout=300— безопасное значение для режимаhigh, покрывающее 99% запросов. Если используетеlowилиmedium, можно снизить до 60 секунд.max_retries=2использует встроенный механизм экспоненциальной задержки SDK, что надежнее самописных решений.output_format="jpeg"+output_compression=85обычно уменьшает размер файла на 60–70% без заметной потери качества. Отличный выбор для веб-превью.
🎯 Совет по таймаутам: При работе через APIYI (apiyi.com) платформа поддерживает долгоживущие соединения, но таймаут в клиентском SDK нужно задавать вручную. Для
highрекомендуем минимум 240 секунд, дляlowможно ограничиться 30 секундами, чтобы не блокировать пул соединений зависшими запросами.
Пакетный пример: асинхронная параллельная генерация
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["кот", "собака", "птица", "рыба", "кролик"] * 4))
Параллелизм — главный инструмент для массовой генерации. В режиме low одна картинка генерируется 5 секунд; последовательная генерация 20 штук займет 100 секунд, а с 5 потоками — всего 20. Но будьте осторожны: используйте только low или medium. Параллельные запросы в режиме high приведут к лавинообразному росту таймаутов.
Рекомендации по параметрам gpt-image-2 для различных задач
Теория — это хорошо, но на практике важны конкретные сценарии. Ниже приведена таблица оптимальных настроек.
| Сценарий | quality | size | output_format | Ожидаемое время | Цена |
|---|---|---|---|---|---|
| Карточки товаров, баннеры | medium | 1024×1024 | jpeg+85 | 25–35с | $0.053 |
| Посты в соцсетях | medium | 1024×1536 | jpeg+85 | 30–40с | ~$0.06 |
| Обложки статей, блоги | medium | 1536×1024 | webp+90 | 30–40с | ~$0.06 |
| Плакаты, превью для печати | high | 1024×1536 | png | 200–240с | ~$0.21 |
| Обложки для PPT/видео | high | 1536×1024 | png | 200–240с | ~$0.21 |
| Миниатюры, прототипы | low | 1024×1024 | jpeg+75 | 3–8с | $0.006 |
| Массовые эскизы | low | 1024×1024 | jpeg+75 | 3–8с × N | $0.006 × N |
| Интерактив в AI-ассистентах | low | 1024×1024 | webp+85 | 5–10с | $0.006 |
Сценарий 1: E-commerce и соцсети — баланс в medium
Для карточек товаров важна скорость (пользователь не будет ждать 4 минуты), но нужно высокое качество. Режим medium — идеальный выбор. 30 секунд ожидания за 5 центов.
Сценарий 2: Плакаты и печать — время для high
Если нужны сложные композиции, текст или высокая согласованность лиц, используйте high. Не пытайтесь ускорить процесс — лучше сразу предупредите пользователя, что генерация займет 3–5 минут.
Сценарий 3: Массовая генерация — только low
Если нужно сгенерировать 10 000 эскизов за ночь, используйте только low. В сочетании с асинхронностью и сжатием jpeg+75 можно добиться высокой пропускной способности.
Сценарий 4: Интерактивное взаимодействие — low или medium
В чат-ботах пользователь ждет ответа здесь и сейчас. Если генерация длится дольше 10 секунд, пользователь уйдет. Используйте low с анимацией загрузки. Если качество не устраивает, предложите кнопку "Улучшить до medium".
Сценарий 5: Модерация контента
Если запрос блокируется фильтрами, сначала протестируйте его в режиме low. Если промпт прошел проверку, переключайтесь на medium/high для финальной генерации. Это сэкономит время и деньги.
🎯 Гибридная стратегия: Многие системы используют "двухэтапную генерацию": сначала
lowдля мгновенного превью, а после выбора пользователя —highдля финального результата. В APIYI (apiyi.com) это работает бесшовно, так как один API-ключ поддерживает все уровни качества.
Часто задаваемые вопросы (FAQ)
Q1: Почему мои запросы уровня high постоянно выдают ошибку timeout?
По умолчанию тайм-аут в OpenAI Python SDK составляет 600 секунд, чего теоретически должно хватать. Однако многие фреймворки (FastAPI, Flask, Celery) добавляют свои собственные ограничения по времени на внешнем уровне. Проверьте настройки тайм-аута на каждом этапе цепочки вызовов. Для уровня high мы рекомендуем закладывать не менее 300 секунд на всю цепочку. Если вы используете httpx, не забудьте явно указать httpx.Timeout(300.0).
Q2: Какое значение output_compression является оптимальным?
Для формата JPEG «золотой серединой» считается 85 — разница с 100 практически не видна глазу, а размер файла уменьшается на 30–40%. Для формата WebP часто используют значение 90. Значения ниже 70 приводят к появлению заметных артефактов (блочности), особенно на градиентных фонах. Этот параметр не влияет на время генерации, а только на итоговую сериализацию вывода.
Q3: Есть ли разница между вызовом gpt-image-2 через APIYI (apiyi.com) и официальными эндпоинтами?
Параметры и логика работы полностью идентичны, включая все поля: quality, size, output_format, output_compression, n, background и другие. Разница лишь в том, что APIYI (apiyi.com) предоставляет высокоскоростные узлы, доступные из любой точки мира, единую систему биллинга и оплату по факту использования без минимальных порогов, что гораздо удобнее для разработчиков.
Q4: Может ли параметр n вернуть несколько изображений за раз?
Да, gpt-image-2 поддерживает значения от n=1 до n=10. Но учтите: общее время ответа при генерации нескольких изображений составляет примерно 0,7–0,9 от времени генерации одного изображения, умноженное на n (это не совсем параллельный процесс), а итоговая стоимость рассчитывается как n умножить на цену одного вызова. Если вам нужна «серия связанных персонажей», используйте n=4 — это стабильнее, чем делать 4 отдельных запроса, так как gpt-image-2 лучше сохраняет согласованность лиц в рамках одной сессии вывода.
Q5: Какой уровень на самом деле выбирает quality="auto"?
На практике auto чаще всего выбирает уровни medium или high, в зависимости от длины и сложности промпта. Короткие промпты (например, "a cat") с высокой вероятностью попадут в low/medium, а длинные (с описанием персонажей, сцен, текста и стиля) — в high. Для продакшена мы рекомендуем явно указывать уровень, не полагаясь на автоматический выбор.
Q6: Какое разрешение лучше: 1024×1536 или 1536×1024?
Общее количество пикселей у них одинаковое (около 1,57 млн), поэтому качество изображения по сути идентично. Разница только в соотношении сторон: вертикальный формат (1024×1536) подходит для постеров, портретов в полный рост и мобильного контента; горизонтальный (1536×1024) — для баннеров, пейзажей и обложек для ПК. Выбирайте исходя из требований к композиции, на скорость и цену это не влияет.
Q7: Могу ли я пропустить этап рассуждения (reasoning) и работать с базовой моделью напрямую?
Нет, агентное рассуждение (Agentic reasoning) в gpt-image-2 — это неотъемлемая часть архитектуры модели, и его нельзя отключить. Если вам нужна быстрая генерация в стиле классических SD и не требуется сложная работа с текстом или логический вывод, рекомендуем использовать уровень low — он пропускает цепочку глубоких рассуждений. Также можно рассмотреть модель Google nano-banana-pro: её быстрый режим работает даже быстрее, чем gpt-image-2 low, и эта модель уже доступна на APIYI (apiyi.com).
🎯 Совет по использованию нескольких моделей: Зрелые системы генерации изображений обычно используют не одну модель. Мы рекомендуем использовать nano-banana-pro для быстрого превью (отклик в районе 5 секунд), gpt-image-2 medium — для основного потока генераций, а gpt-image-2 high — для высококачественных сцен. Все три модели на APIYI (apiyi.com) работают через один API-ключ с оплатой по факту использования — это самое выгодное сочетание для интеграции графических API в 2026 году.
Итог: воспринимайте параметры как переключатели производительности, а не как декор
Философия дизайна gpt-image-2 кардинально отличается от моделей предыдущего поколения: здесь рассуждение стало ключевым этапом генерации. Поэтому quality — это больше не просто «настройка красоты», а переключатель глубины пути рассуждения. Поняв это, вы осознаете, почему один и тот же API может выдавать результат как за 5, так и за 235 секунд, создавая 50-кратный разрыв во времени.
На практике мы советуем начинать проектирование продукта с выбора параметров: сначала определитесь, какую задержку допускает ваш сценарий, какое качество необходимо и каков бюджет на один запрос. Затем подберите нужные quality и size по таблице. Заранее заданные параметры сэкономят вам куда больше нервов, чем попытки оптимизации после запуска.
🎯 Финальная рекомендация: Приступая к интеграции gpt-image-2, зарегистрируйтесь на APIYI (apiyi.com) и проведите сравнительный тест уровней low/medium/high. Оцените реальное время отклика и качество, прежде чем утверждать параметры для основного потока. Один ключ для всех уровней, оплата по факту и отсутствие минимальных платежей — самый эффективный способ работы с графическими API в 2026 году.
— Техническая команда APIYI | Мы постоянно следим за развитием моделей генерации изображений. Больше подробных руководств вы найдете в центре помощи APIYI (apiyi.com).