ملاحظة من المؤلف: قراءة متعمقة في نتائج اختبارات Claude Opus 4.7: نسبة 87.6% في SWE-bench Verified، و64.3% في SWE-bench Pro، و94.2% في GPQA Diamond، متفوقاً على GPT-5.4 وGemini 3.1 Pro، مع دليل عملي لاستدعاء الـ API.
أطلقت Anthropic رسمياً نموذج Claude Opus 4.7 في 16 أبريل 2026، محققةً الصدارة في 7 من أصل 10 اختبارات قياسية رئيسية. في هذا المقال، سنقوم بتحليل البيانات الجوهرية لاختبارات Claude Opus 4.7 وسيناريوهات استخدامه من منظور تقييمي واقعي.
هذا ليس تكراراً للمواد التسويقية الرسمية، فجميع البيانات مستمدة من مؤسسات تقييم مستقلة تابعة لجهات خارجية، وتغطي جوانب القوة بالإضافة إلى نقاط الضعف في Opus 4.7 في مجالات مثل البحث عبر الويب.
القيمة الجوهرية: من خلال بيانات القياس الحقيقية وتجربة الاستخدام، نساعدك في اتخاذ قرار بشأن ما إذا كان Claude Opus 4.7 يستحق الانتقال إليه، وكيفية استخدامه بتكلفة منخفضة.
💡 لقد قامت خدمة APIYI بتوفير نموذج Claude Opus 4.7 الرسمي، احصل على مكافأة تبدأ من 10% عند شحن 100 دولار، وهو ما يعادل خصماً بنسبة 20%، مع دعم كامل لاستبدال الواجهات المتوافقة مع OpenAI بضغطة زر.

النقاط الجوهرية لاختبارات Claude Opus 4.7
| عنصر القياس | نتيجة Opus 4.7 | مقارنة بـ Opus 4.6 | مقارنة بـ GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅ رائد |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅ رائد |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ الصدارة في البرمجة متعددة اللغات |
| GPQA Diamond | 94.2% | – | ✅ معيار الاستنتاج العلمي |
| Terminal-Bench 2.0 | 69.4% | – | ✅ الصدارة في تشغيل الأوامر الطرفية |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅ رائد |
| MCP-Atlas (استدعاء الأدوات) | يتفوق على GPT-5.4 بـ +9.2 نقطة | – | ✅ الأفضل في سيناريوهات الوكلاء (Agents) |
| الرؤية (Vision) | 98.5% | – | ✅ فهم بصري فائق |
| BrowseComp (البحث عبر الويب) | 79.3% | – | GPT-5.4: 89.3% ❌ متأخر |
أبرز مميزات اختبارات Claude Opus 4.7
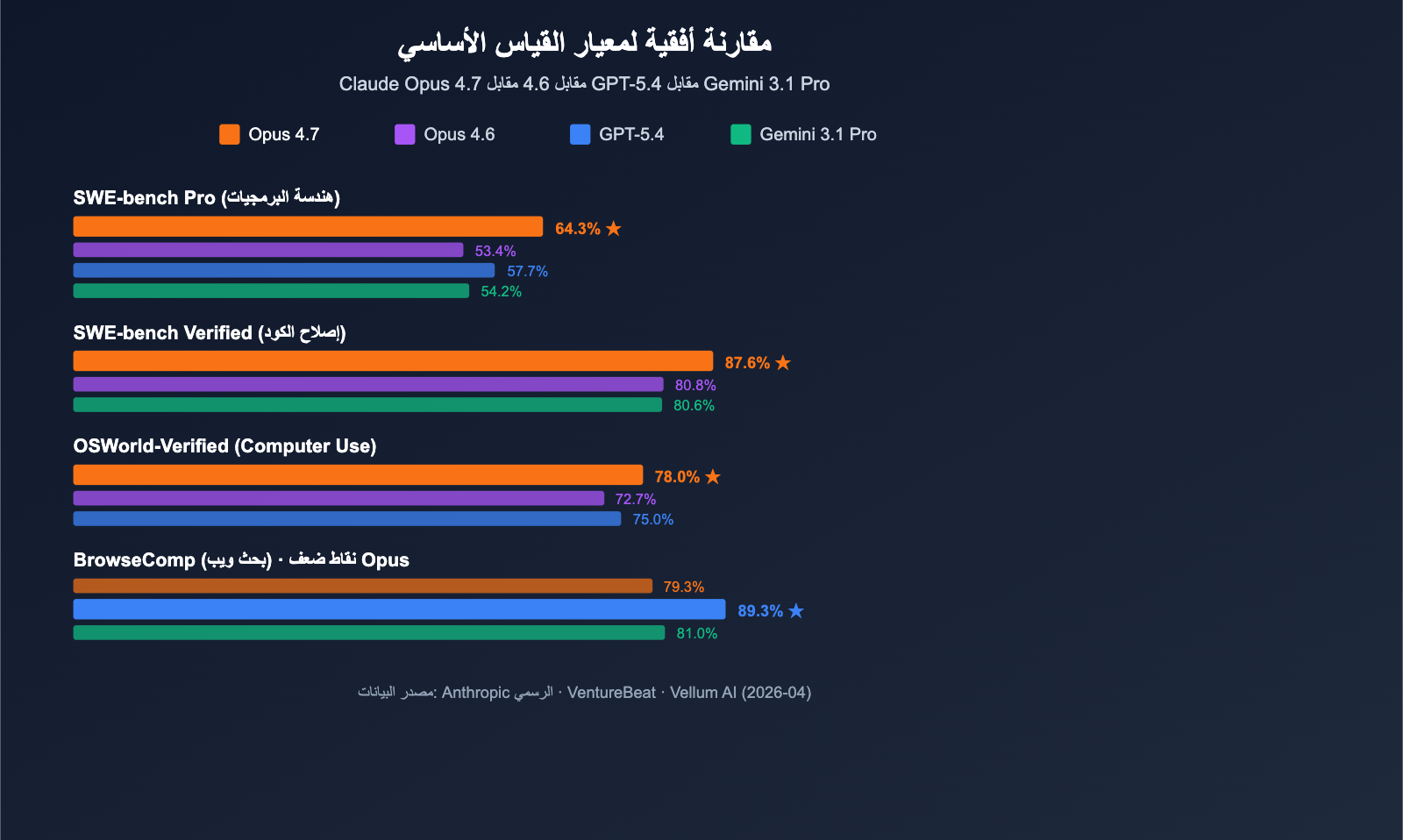
أطلقت Anthropic نموذج Claude Opus 4.7 في 16 أبريل 2026، ليصبح النموذج اللغوي الكبير (LLM) الأكثر قوة المتاح للاستخدام العام حالياً (حسب تقييم VentureBeat). في مقارنة مباشرة شملت 10 اختبارات مقابل GPT-5.4 وGemini 3.1 Pro، حقق Opus 4.7 الصدارة في 7 منها، مع تفوق ملحوظ في اختبار SWE-bench Pro.
ما يستحق الانتباه هو النتيجة 64.3% في SWE-bench Pro، وهو أعلى أداء في الصناعة حالياً في مهام هندسة البرمجيات الحقيقية، متجاوزاً GPT-5.4 (57.7%) بفارق 6.6 نقاط مئوية، وOpus 4.6 (53.4%) بزيادة قدرها 10.9 نقاط مئوية. أما في معيار استدعاء الأدوات MCP-Atlas، فقد تفوق Opus 4.7 على GPT-5.4 بفارق كبير وصل إلى 9.2 نقاط، مما يجعله الخيار الأمثل لسيناريوهات الذكاء الاصطناعي الوكيل (Agentic AI)، مثل سير العمل المؤتمت، وكلاء توليد الأكواد، ومهام الاستنتاج متعدد الخطوات.
مقارنة Claude Opus 4.7 مع الإصدارات السابقة والمنافسين
| الأبعاد | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| تاريخ الإصدار | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| نافذة السياق | 1M tokens (سعر قياسي) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| الوكيل/استدعاء الأدوات | الأقوى | جيد | قوي | جيد |
| البحث عبر الويب (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| الرؤية متعددة الوسائط | 98.5% | 95% | 97% | 96.5% |
| سعر API الرسمي | $5 / $25 (إدخال/إخراج، لكل مليون token) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| خصم APIYI الشامل | شحن 100 دولار يمنح 10% فأكثر ≈ خصم 20% | نفس العرض | نفس العرض | نفس العرض |
قراءة في المقارنة (Claude Opus 4.7 مقابل النماذج الأخرى)
Claude Opus 4.7 مقابل GPT-5.4: يحافظ GPT-5.4 على الصدارة في سيناريوهات البحث عبر الويب (BrowseComp) بنسبة (89.3% مقابل 79.3%). لكنه يتأخر بشكل ملحوظ عن Opus 4.7 في اختبارات SWE-bench Pro (57.7%) واستدعاء الأدوات (MCP-Atlas). في المقابل، يتفوق Claude Opus 4.7 في وكلاء البرمجة، وتوليد الأكواد، وتنفيذ المهام متعددة الخطوات، مما يجعله أكثر ملاءمة لسير عمل المطورين.
Claude Opus 4.7 مقابل Gemini 3.1 Pro: لا يزال Gemini 3.1 Pro متصدراً في فهم النصوص الطويلة وسيناريوهات الفيديو متعددة الوسائط. لكن الفجوة واضحة في اختبارات SWE-bench Verified (80.6% مقابل 87.6%) و SWE-bench Pro (54.2% مقابل 64.3%). وبالمقارنة، يتفوق Claude Opus 4.7 بشكل حاسم في مهام هندسة البرمجيات، مما يجعله الخيار الأمثل لبيئات الإنتاج البرمجي.
Claude Opus 4.7 مقابل Opus 4.6: يظل Opus 4.6 خياراً مستقراً في السيناريوهات الحساسة للتكلفة. لكن الإصدار 4.7 شهد قفزة كبيرة في قدرات البرمجة، والاستدلال الوكيل (Agentic Reasoning)، واستخدام الحاسوب (Computer Use)، مع ثبات أسعار الـ API. بالنسبة للفرق التي تتعامل مع مهام معقدة وطويلة، فإن الترقية إلى 4.7 تعد خياراً ضرورياً.
ملاحظة حول المقارنة: البيانات أعلاه مستمدة من الإصدارات الرسمية لشركة Anthropic، وVentureBeat، وVellum AI، وDecrypt، وغيرها من مؤسسات التقييم المستقلة، ويمكن التحقق منها عبر منصة APIYI على apiyi.com.
دليل البدء السريع لنموذج Claude Opus 4.7
مثال مبسط
فيما يلي أبسط طريقة لاستدعاء نموذج Claude Opus 4.7 عبر خدمة APIYI باستخدام واجهة متوافقة مع OpenAI:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "اكتب دالة في لغة بايثون للقيام بالاجتياز الأوسط (in-order traversal) لشجرة ثنائية"}]
)
print(response.choices[0].message.content)
عرض كود التنفيذ الكامل (بما في ذلك وضع الاستدعاء xhigh Effort Mode)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
استدعاء Claude Opus 4.7 مع دعم وضع xhigh effort mode
Args:
prompt: مدخلات المستخدم
effort_level: مستوى جهد الاستدلال، الخيارات المتاحة هي "low" / "medium" / "high" / "xhigh"
system_prompt: موجه النظام
max_tokens: الحد الأقصى لعدد الرموز (tokens) في المخرجات
Returns:
محتوى استجابة النموذج
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# نوصي باستخدام وضع xhigh لمهام البرمجة المعقدة
result = call_claude_opus_47(
prompt="تصميم وتنفيذ ذاكرة تخزين مؤقت من نوع LRU، تدعم عمليات get و put بزمن تشغيل O(1)",
effort_level="xhigh",
system_prompt="أنت مهندس بايثون خبير، اكتب كوداً يجمع بين القابلية للقراءة والأداء العالي"
)
print(result)
اقتراح: احصل على رصيد تجريبي مجاني عبر منصة APIYI apiyi.com للتحقق بسرعة من أداء Claude Opus 4.7 في سيناريوهات عملك. توفر المنصة واجهة موحدة متوافقة مع OpenAI لكل من Opus 4.7 و GPT-5.4 و Gemini 3.1 Pro، مما يسهل عملية المقارنة. عروض الشحن تبدأ من 10% بونص عند شحن 100 دولار، مما يعني فعلياً خصماً يصل إلى 20% على أسعار النماذج الرسمية.
أداء Claude Opus 4.7 في الاختبارات العملية والسيناريوهات النموذجية
4 سيناريوهات أساسية مثالية لنموذج Claude Opus 4.7
- 🧑💻 إعادة هيكلة الأكواد الضخمة: بفضل نتيجة 87.6% في اختبار SWE-bench Verified، يثبت النموذج قدرته على فهم السياق عبر ملفات متعددة، مما يجعله مثالياً لتعديلات البنية التحتية، وتحديث المكتبات، وإعادة الهيكلة الشاملة لمشاريع تضم 100 ألف سطر برمجي.
- 🤖 سير عمل أتمتة الوكيل (Agent): يتفوق في استدعاء أدوات MCP-Atlas بفارق 9.2 نقطة عن GPT-5.4، مما يجعله مناسباً لبناء وكلاء أتمتة المتصفحات، وأتمتة العمليات الروبوتية (RPA)، والاستدلال متعدد الخطوات.
- 🔬 المساعدة في البحث العلمي والاستدلال: معدل 94.2% في اختبار GPQA Diamond يعني قدرة على الاستدلال الأكاديمي بمستوى طالب دراسات عليا، وهو مناسب جداً للمساعدة في كتابة الأوراق البحثية، وتحليل البيانات، والتحقق من الفرضيات.
- 🖥️ أتمتة سطح المكتب Computer Use: متصدر للصناعة بنسبة 78.0% في اختبار OSWorld-Verified، مما يجعله مثالياً لاختبارات الأتمتة وعمليات واجهة المستخدم التي تتطلب محاكاة حركة الفأرة ولوحة المفاتيح.
سيناريوهات لا يُنصح فيها باستخدام Claude Opus 4.7
- البحث المباشر عبر الويب: حقق 79.3% في اختبار BrowseComp، وهو أداء أقل بوضوح من GPT-5.4 الذي حقق 89.3%، لذا نوصي بالتبديل إلى GPT-5.4 في هذه المهام.
- الاستدعاءات الضخمة منخفضة التكلفة: بسعر 25 دولاراً لكل مليون رمز (token) للمخرجات، نوصي باستخدام Claude Haiku أو GPT-5.4-mini لتطبيقات المحادثة اليومية.
- متطلبات التأخير المنخفض جداً (Latency): زمن استجابة سلسلة Opus أعلى من Sonnet/Haiku، لذا يجب الحذر عند استخدامه في سيناريوهات التفاعل الفوري.
تقدير أسعار وتكاليف Claude Opus 4.7
الأسعار الرسمية مقابل التكلفة الإجمالية عبر APIYI
| البند | السعر الرسمي (Anthropic) | سعر APIYI (شامل رصيد المكافأة) |
|---|---|---|
| رموز الإدخال (Input tokens) | 5 دولار / مليون رمز | نفس السعر الرسمي |
| رموز الإخراج (Output tokens) | 25 دولار / مليون رمز | نفس السعر الرسمي |
| مكافأة الشحن | لا يوجد | 10% فأكثر عند شحن 100 دولار |
| الخصم الفعلي الإجمالي | لا يوجد | حوالي 20% (تزداد المكافأة مع زيادة فئة الشحن) |
| طرق الدفع | بطاقات ائتمان دولارية فقط | دعم اليوان الصيني، الدولار، وطرق متعددة |
| عملة الفاتورة | دولار أمريكي | خيار بين الرنمينبي (RMB) أو الدولار (USD) |
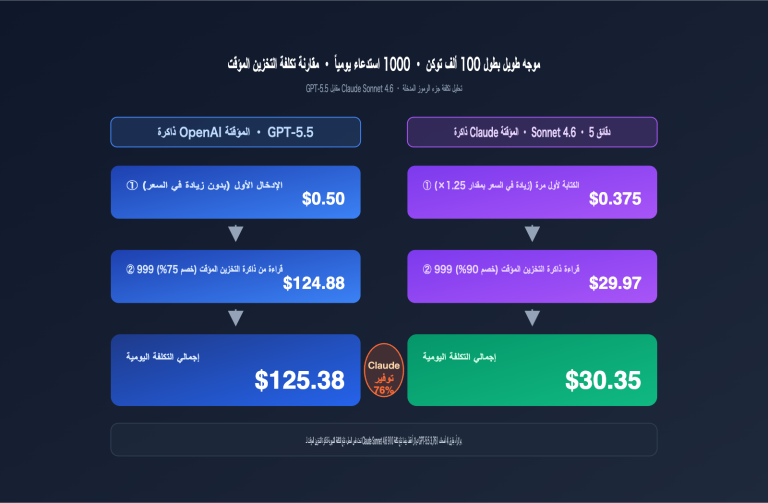
تنبيه بشأن التكلفة: يستهلك الـ tokenizer الجديد في Opus 4.7 رموزاً أكثر بنسبة 1x إلى 1.35x مقارنة بـ 4.6 عند معالجة النصوص (تختلف النسبة حسب نوع المحتوى). وعلى الرغم من أن السعر الرسمي لم يرتفع، إلا أن تكلفة الفاتورة الفعلية قد تزيد بنسبة 20-30%. من خلال مكافآت الشحن في APIYI (apiyi.com)، يمكنك تعويض هذه التكلفة الخفية، مما يجعل تكلفة الاستخدام الفعلية مساوية أو حتى أقل من حقبة 4.6.
الأسئلة الشائعة (FAQ)
س1: ما هو Claude Opus 4.7؟
Claude Opus 4.7 هو نموذج لغة كبير رائد أطلقته Anthropic في 16 أبريل 2026. يتفوق على GPT-5.4 وGemini 3.1 Pro في العديد من المعايير مثل البرمجة (SWE-bench Verified 87.6%)، استدعاء أدوات الوكيل (Agent)، والاستدلال العلمي (GPQA Diamond 94.2%). مقارنة بـ Opus 4.6، أضاف النموذج وضع الاستدلال العميق "xhigh effort"، مع الحفاظ على السعر الرسمي دون زيادة.
س2: أيهما أفضل، Claude Opus 4.7 أم GPT-5.4؟
يعتمد ذلك على سيناريو الاستخدام. يتفوق Opus 4.7 بوضوح في البرمجة (SWE-bench Pro 64.3% مقابل 57.7%)، استدعاء الأدوات (MCP-Atlas +9.2 نقطة)، واستخدام الحاسوب (Computer Use) (78.0% مقابل 75.0%)؛ بينما يحافظ GPT-5.4 على ميزته في البحث عبر الويب (BrowseComp 79.3% مقابل 89.3%). لأعمال التطوير، يُفضل Opus 4.7، أما لمهام البحث عبر الإنترنت، فيُفضل GPT-5.4.
س3: متى تم إطلاق Claude Opus 4.7؟ وهل هو متاح محلياً؟
تاريخ الإطلاق الرسمي هو 16 أبريل 2026، وهو متاح حالياً عبر Claude API، Amazon Bedrock، Google Cloud Vertex AI، وMicrosoft Foundry. يمكن للمطورين محلياً استخدامه عبر منصات التجميع مثل APIYI (apiyi.com) للوصول إلى النموذج الرسمي مباشرة دون الحاجة لتقديم طلب حساب خارجي.
س4: ما هي المشاريع العملية الأكثر ملاءمة لـ Claude Opus 4.7؟
هو مناسب جداً للسيناريوهات التالية:
- إعادة هيكلة الأكواد الضخمة: فهم السياق عبر الملفات، ترحيل التبعيات، وتعديل البنية.
- أتمتة الوكيل (Agent): سلاسل أدوات MCP، أتمتة المتصفح، وعمليات RPA.
- البحث العلمي وتحليل البيانات: الاستدلال على مستوى الدراسات العليا، التحقق من الفرضيات، ومساعدة الأبحاث.
- أتمتة سطح المكتب (Computer Use): اختبارات واجهة المستخدم التلقائية، ونصوص تشغيل الواجهات الرسومية (GUI).
س5: كيف يمكن استدعاء Claude Opus 4.7 بسرعة عبر API؟
نوصي باستخدام منصة تجميع تدعم بروتوكول OpenAI المتوافق، ويمكنك البدء في 3 خطوات:
- قم بزيارة APIYI (apiyi.com) لإنشاء حساب والحصول على مفتاح API.
- اشحن رصيد 100 دولار للحصول على مكافأة 10% فأكثر (خصم إجمالي حوالي 20%)، أو ابدأ باختبار الرصيد المجاني.
- قم بتغيير
base_urlفي مكتبة OpenAI SDK إلىhttps://vip.apiyi.com/v1واكتبclaude-opus-4-7في حقل النموذج.
تدعم APIYI الوصول الموحد لنماذج Claude Opus 4.7، GPT-5.4، وGemini 3.1 Pro، مما يسهل المقارنة والتبديل بينها.
س6: ما هي القيود المعروفة لـ Claude Opus 4.7؟
تتضمن القيود الرئيسية ما يلي:
- زيادة استهلاك الرموز: يستخدم الـ tokenizer الجديد رموزاً أكثر بنسبة 1x-1.35x، مما قد يرفع الفاتورة الفعلية بنسبة 20-30%.
- نقطة ضعف في البحث عبر الويب: سجل 79.3% في BrowseComp، وهو أقل من GPT-5.4، لذا يفضل تجنبه في سيناريوهات البحث اللحظي.
- تأخير الاستجابة: زمن الاستجابة في سلسلة Opus أعلى من Sonnet/Haiku، لذا يُنصح باستخدام نماذج أخف لتطبيقات المحادثة اللحظية.
- ارتفاع السعر الرسمي: 5/25 دولار لكل مليون رمز، لذا يوصى بالاستفادة من مكافآت الشحن في APIYI لتعويض التكاليف عند الاستدعاء المكثف.
س7: ما هي نافذة السياق لـ Claude Opus 4.7؟
يدعم Claude Opus 4.7 نافذة سياق تصل إلى مليون (1M) رمز، وذلك بتسعير قياسي دون رسوم إضافية للسياق الطويل. هذا يعني إمكانية معالجة مستودع أكواد متوسط الحجم، أو وثائق تقنية طويلة، أو محاضر اجتماعات كاملة في طلب واحد، وهو ما يعادل حوالي 750 ألف حرف صيني أو 200 صفحة PDF.
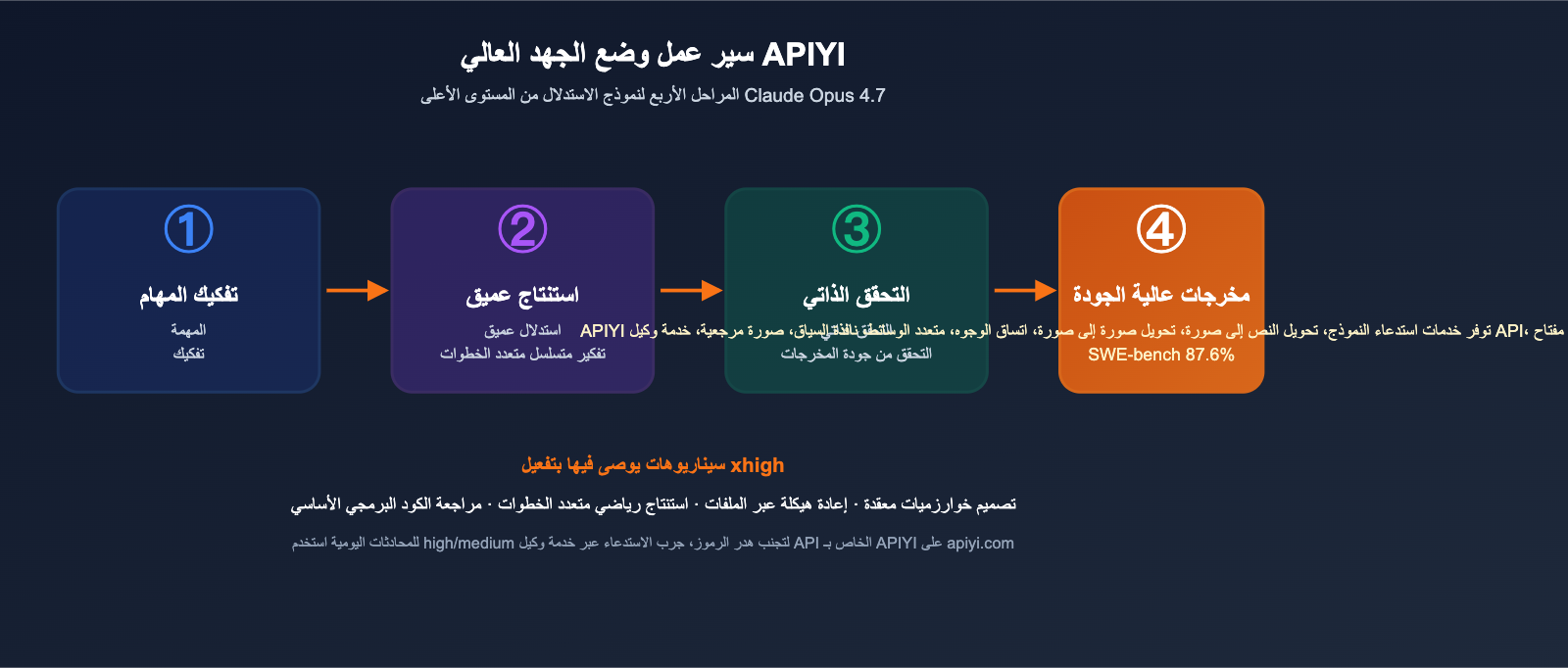
س8: ما هو وضع xhigh Effort؟ ومتى يجب استخدامه؟
"xhigh effort" هو أعلى مستوى من وضع الاستدلال تمت إضافته في Opus 4.7، حيث ينفق النموذج المزيد من الرموز والوقت في التفكير متعدد الخطوات والتحقق الذاتي. نوصي بتفعيله في الحالات التالية:
- تصميم الخوارزميات المعقدة (مثل ذاكرة التخزين المؤقت LRU، أو التوافق الموزع).
- مهام إعادة الهيكلة التي تشمل ملفات متعددة.
- الاستدلال الرياضي الذي يتطلب سلسلة منطقية متعددة الخطوات.
- مراجعة الأكواد الحساسة وفحص الثغرات الأمنية.
للمحادثات اليومية أو كتابة عمليات CRUD البسيطة، يكفي استخدام high أو medium لتجنب استهلاك الرموز غير الضروري.
النقاط الجوهرية لنموذج Claude Opus 4.7
- 🏆 الصدارة في 7 قوائم تصنيف: حقق 64.3% في SWE-bench Pro، و87.6% في Verified، و94.2% في GPQA، كما تفوق على GPT-5.4 بفارق 9.2 نقطة في اختبار MCP-Atlas.
- 💡 وضع الجهد العالي (xhigh Effort Mode): إضافة مستوى استنتاج جديد كلياً، مثالي للخوارزميات المعقدة وإعادة هيكلة الملفات المتعددة.
- 🚀 مثالي لسيناريوهات الوكلاء (Agent): يتصدر بلا منازع في استدعاء الأدوات واستخدام الحاسوب (Computer Use)، مما يجعله الخيار الأول للذكاء الاصطناعي الوكيل.
- ⚠️ قصور في البحث عبر الويب: يتأخر عن GPT-5.4 بـ 10 نقاط في اختبار BrowseComp، لذا يُنصح بالمقارنة عند الاعتماد على البحث المباشر عبر الإنترنت.
- 💰 خصم 20% عبر APIYI: لم يرتفع السعر الرسمي، ومن خلال شحن 100 دولار عبر apiyi.com تحصل على 10% إضافية كحد أدنى، مما يوفر تكلفة إجمالية بخصم يصل إلى 20%.
ملخص
تشير بيانات قياس الأداء لنموذج Claude Opus 4.7 بوضوح إلى نتيجة واحدة: إنه أقوى نموذج عام متاح حالياً لمهام البرمجة والوكلاء (Agents). النقاط الرئيسية:
- تفوق كاسح في البرمجة: حقق 64.3% في SWE-bench Pro متجاوزاً بفارق كبير كلاً من GPT-5.4 وGemini 3.1 Pro، مما يجعله الخيار الأول لمهام البرمجة على مستوى الإنتاج.
- ملك استدعاء أدوات الوكلاء: يتصدر بفارق 9.2 نقطة في MCP-Atlas، وبفارق 3 نقاط في استخدام الحاسوب (Computer Use)، مما يجعله الخيار الأمثل لسيناريوهات الأتمتة.
- مراعاة التكلفة الفعلية: أدى الـ Tokenizer الجديد إلى زيادة خفية في التكلفة بنسبة 20-30%، لذا يُنصح بالاستفادة من عروض الشحن عبر منصات التجميع لتعويض هذا الفارق.
إذا كان تركيز عملك ينصب على البرمجة بالذكاء الاصطناعي، أو تطوير الوكلاء، أو مهام الاستنتاج المعقدة، فإن الانتقال إلى Claude Opus 4.7 يستحق التجربة فوراً. نوصي بالبدء عبر APIYI (apiyi.com)؛ حيث تتوفر النماذج الرسمية فور صدورها، مع واجهات متوافقة مع OpenAI للاستبدال بضغطة زر، بالإضافة إلى عرض شحن 100 دولار والحصول على 10% إضافية (ما يعادل خصم 20%)، مما يغنيك عن عناء الحسابات الدولية والدفع بالدولار.
قراءات إضافية
إذا كنت مهتمًا بمعيار Claude Opus 4.7، فنوصيك بمواصلة القراءة:
- 📘 دليل استدعاء النموذج Claude Opus 4.7 عبر API – تعرّف على الاستخدام الكامل لنمط "الجهد العالي" (xhigh Effort Mode)، والتخزين المؤقت للموجه (Prompt Caching)، واستدعاء الأدوات.
- 📊 مقارنة متعمقة: GPT-5.4 مقابل Claude Opus 4.7 مقابل Gemini 3.1 Pro – أتقن مهارات اختيار النموذج الأنسب بين النماذج الرائدة الثلاثة بناءً على سيناريوهات الاستخدام.
- 🚀 بروتوكول MCP ووكلاء الذكاء الاصطناعي (Agent) باستخدام Claude Opus 4.7 – اكتشف كيفية بناء سير عمل لعميل ذكاء اصطناعي بمستوى إنتاجي باستخدام Opus 4.7.
📚 مراجع
-
إعلان Anthropic الرسمي: مقدمة حول منتج Claude Opus 4.7 وبيانات معايير القياس (Benchmark).
- الرابط:
anthropic.com/news/claude-opus-4-7 - ملاحظة: المصدر الأساسي للبيانات، يتضمن كافة نتائج الاختبارات القياسية الرسمية.
- الرابط:
-
تقييم VentureBeat المستقل: تحليل حول عودة Opus 4.7 للمركز الأول بين نماذج اللغة الكبيرة العامة.
- الرابط:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - ملاحظة: وجهة نظر خارجية مستقلة، تقدم مقارنة شاملة بين Opus 4.7 والمنافسين.
- الرابط:
-
تحليل معايير Vellum AI: تفكيك منهجية القياس والمصداقية خطوة بخطوة.
- الرابط:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - ملاحظة: مناسب للقراء التقنيين الذين يرغبون في فهم أعمق لطرق إجراء اختبارات الأداء.
- الرابط:
-
توثيق API الرسمي لـ Claude: شرح حول نافذة السياق، التسعير، والمحلل اللغوي (Tokenizer).
- الرابط:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - ملاحظة: مرجع موثوق للتكامل والاستدعاء، يتضمن دليل الانتقال للنسخة الجديدة.
- الرابط:
المؤلف: فريق APIYI التقني
تبادل تقني: نرحب بمناقشاتكم في قسم التعليقات حول تجربة استخدام Claude Opus 4.7، ولمزيد من المعلومات حول استدعاء الـ API يمكنكم زيارة مركز توثيق APIYI على الرابط docs.apiyi.com