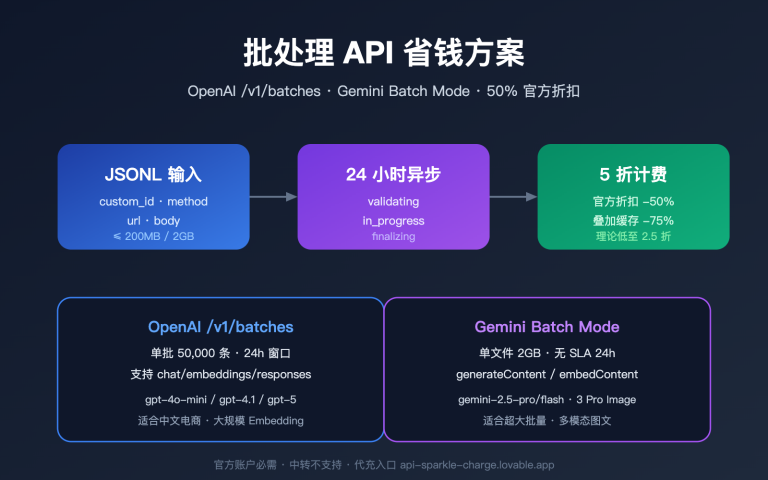
很多设计师第一次接触 GPT-Image-2 时都会有一个疑问:当我上传一张照片让它"把人物的衣服换成蓝色",AI 究竟是在像 Photoshop 那样精准地涂改像素,还是在背地里重新画了一张图?这个问题的答案直接关系到我们如何使用 AI 图片编辑工具,以及如何理解输出结果的可预测性。
事实上,这是一个被严重误解的技术细节。本文将从 AI 图片编辑原理 出发,深入解析 GPT-Image-2、Nano Banana 等新一代自回归图像模型的工作机制,回答"是局部修改还是重新绘制"这一核心问题,并揭示它们如何在整图重绘的前提下依然保持惊人的视觉一致性。
| 核心问题 | 直觉答案 | 真实答案 |
|---|---|---|
| 编辑方式 | PS 式局部覆盖 | 整图 token 重绘 |
| 一致性来源 | 保留未修改像素 | 自注意力锚定原图特征 |
| 主流架构 | 扩散去噪 | 自回归 Transformer |
| 多轮编辑 | 容易累积伪影 | GPT-Image-2 无明显漂移 |
理解这套原理之后,你会发现 prompt 的写法、mask 的使用、参考图的传入策略都有了新的理论依据。我们建议读者结合 API易 apiyi.com 平台上的 GPT-Image-2 接口边读边测,把原理落到实际效果上。
AI 图片编辑原理:不是 PS 局部修改,而是智能重绘
很多用户根据 ChatGPT 网页端的交互体验,会想当然地认为 AI 编辑图片就像 Photoshop 的"局部修改":系统识别到你要修改的区域,在原图上覆盖几个像素,其余部分原封不动。这种心智模型很直观,却完全错误。
**所有主流 AI 图片编辑模型本质上都是"重新绘制"逻辑。**无论是 GPT-Image-2、Nano Banana,还是 Stable Diffusion 系列,都需要把原图先编码成某种内部表示(token 或 latent),再由模型"想象"出新图的完整内部表示,最后解码回像素。这中间不存在任何"在原图上动笔"的步骤。
这就是为什么有时候你只让 AI 改一只眼睛的颜色,结果发现头发的发丝、背景的纹理也都发生了细微变化。模型并没有偷懒,它确实是在"重画"整张图,只是在大多数区域画得非常接近原图。
那么问题来了:既然是重画,为什么 GPT-Image-2 编辑过的图片看起来又和原图高度一致,甚至允许多轮反复编辑而不"跑偏"?答案藏在它的架构里。如果你希望第一手验证这种行为,可以在 API易 apiyi.com 上调用 gpt-image-2 的 /v1/images/edits 接口,使用相同 prompt 反复编辑同一张图,观察细节变化。
PS 局部修改与 AI 重绘的本质差异
| 对比维度 | Photoshop 局部修改 | GPT-Image-2 智能重绘 |
|---|---|---|
| 操作单位 | 像素 | 视觉 token (8×8 或 16×16 像素块) |
| 未编辑区域 | 物理上保持不变 | 经过编码-解码,理论上有微小重构 |
| 一致性保障 | 100%(直接复制原像素) | 由模型注意力机制保障 |
| 语义理解 | 无,只看像素值 | 理解"衣服""背景""光照"等语义 |
| 边界过渡 | 需手动羽化 | 自动按语义自然过渡 |
PS 是基于像素的"机械修改",AI 是基于语义的"理解后再画"。这就是为什么 AI 能完成"把白天改成黄昏"这种 PS 永远做不到的整体性编辑——它修改的是图像的语义表示,而不是像素的 RGB 值。
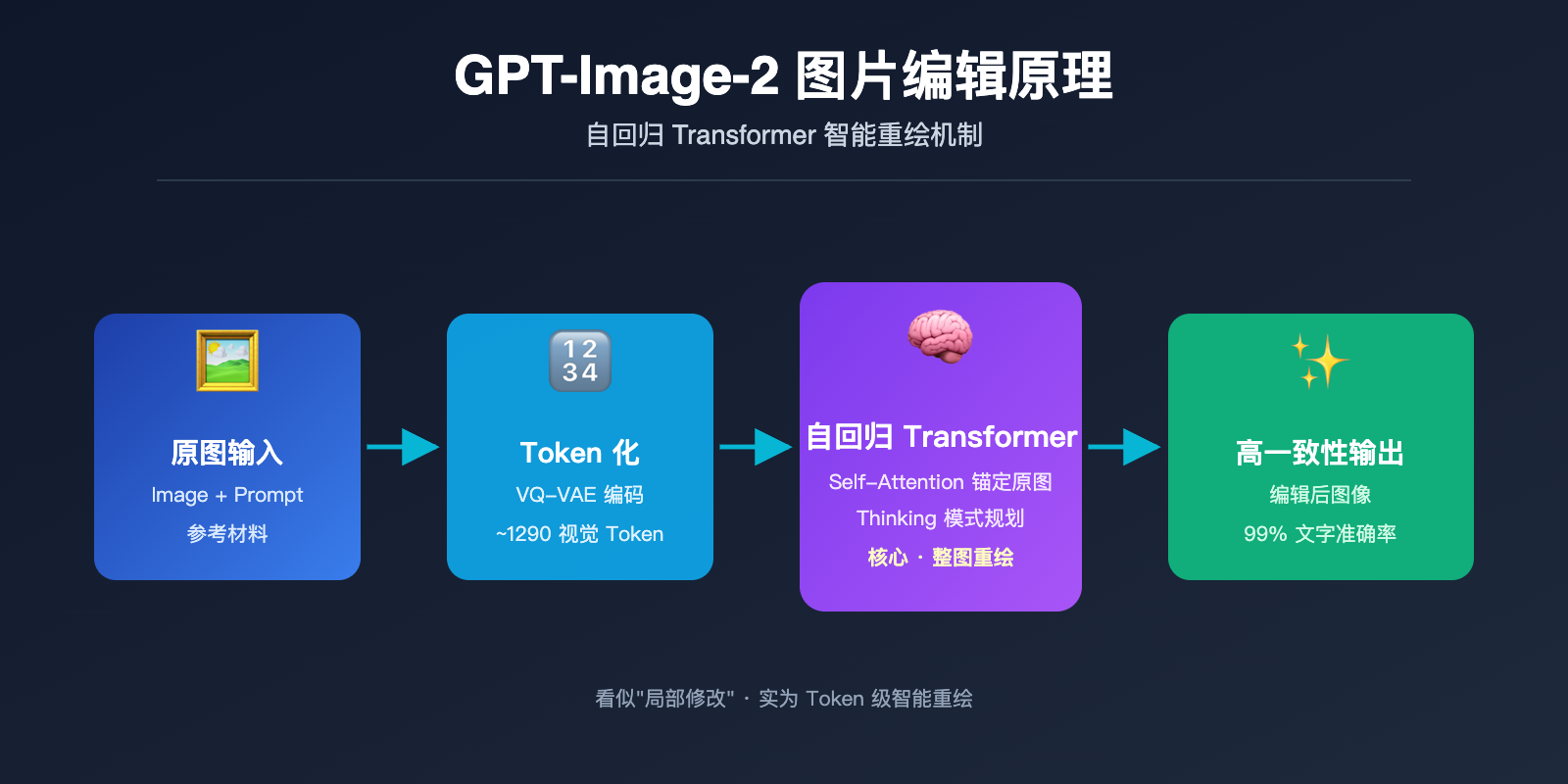
gpt-image-2 编辑原理:自回归 Transformer 如何"看懂"原图
要真正理解 gpt-image-2 编辑原理,绕不开 OpenAI 在 2026 年 4 月 21 日发布这个模型时做出的一项关键架构选择:抛弃 DALL-E 系列使用的扩散模型,改用自回归 Transformer。这个决定直接借鉴自 GPT-4o 的多模态架构。
自回归生成本质上和 ChatGPT 写文章是同一套机制——预测下一个 token。区别在于,这里的"token"不是文字,而是视觉 token。模型会:
- 图像 token 化:通过类似 VQ-VAE 的离散化机制,把一张图片切分成约 1024-1290 个视觉 token,每个 token 大致对应原图的 8×8 或 16×16 像素块。
- 序列拼接:把用户的文本 prompt token 和原图的视觉 token 拼成一个长序列,送入统一的 Transformer。
- 逐 token 生成:模型从左到右(或按光栅扫描顺序)逐一预测输出图像的每个视觉 token,每生成一个新 token 都能"看到"之前所有的输入和已生成内容。
- 解码回像素:所有视觉 token 生成完毕后,通过解码器还原成最终的像素图像。
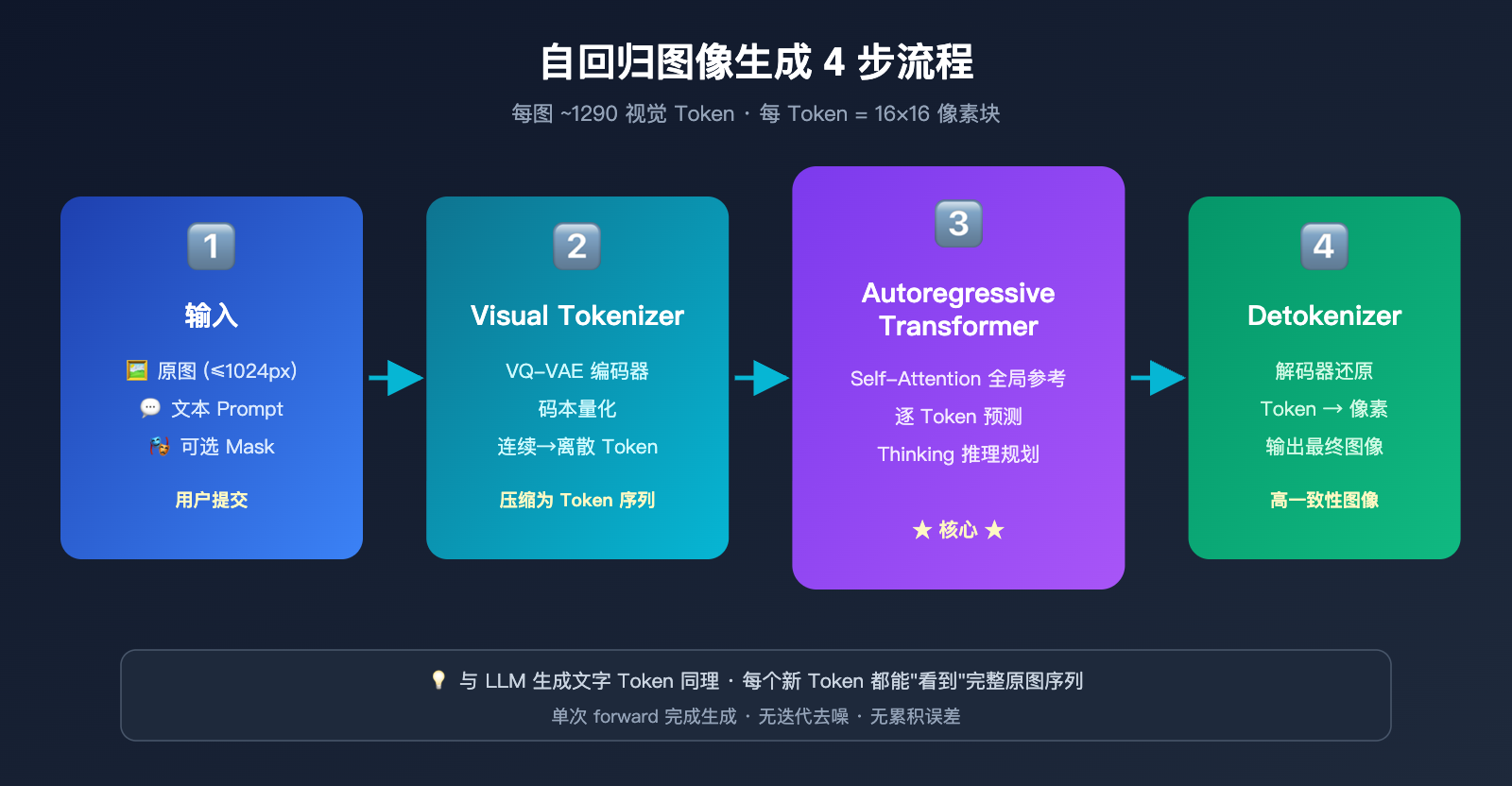
这里的关键洞察是:GPT-Image-2 在生成新图时,原图的全部 token 都在它的"视野"内。这跟你跟 ChatGPT 对话时,它能看到之前所有消息的原理完全相同。Self-Attention 机制让每一个新生成的 token 都可以"参考"原图任意位置的特征。
OpenAI 官方还在 GPT-Image-2 中引入了"Thinking 模式",让模型在真正开始生成视觉 token 之前,先用一段内部推理梳理:用户想改什么、哪些部分该保留、空间布局如何安排。这进一步提高了复杂编辑指令的执行准确率,达到 99% 的文字准确率和精准的多对象布局。如果你需要在生产环境测试这些能力,可以通过 API易 apiyi.com 接入 gpt-image-2,该平台提供与官方一致的接口规范和便捷的多模型切换。
视觉 Tokenizer:压缩与信息保留的平衡
视觉 Tokenizer 是整个 自回归图像生成 系统的关键瓶颈。它需要在两个目标之间做权衡:
- 压缩率要高:token 数量越少,Transformer 处理越快,成本越低。
- 重建质量要高:解码出来的像素要尽可能还原原图,不损失细节。
主流做法是 VQ-VAE (Vector Quantized Variational Autoencoder):用编码器把图像区域压缩到一个连续向量,再映射到一个有限的"码本"中找最接近的码字索引,这个索引就是 token。1024×1024 的图像通常被压缩成约 1024 个 token,信息密度极高。
正因为这种压缩本身有损,任何 AI 编辑工具都无法做到"100% 保留原图未修改区域的像素值"。这就引出了下一个关键问题——一致性。
AI 图像一致性的核心机制:视觉 token 化与注意力锚定
既然 GPT-Image-2 是整图重绘,AI 图像一致性 又是怎么实现的?为什么用它修一张人像照片,你的五官、肤色、发型不会变成另一个人?答案有四层。
第一层:视觉 token 本身的高度抽象。 一张人脸经过 tokenizer 之后,生成的 token 序列已经编码了"这个人"的核心特征——脸型、五官比例、肤色色调等。只要这些"身份 token"在生成新图时被基本保留,人物就不会变样。
第二层:Self-Attention 的全局参考。 自回归 Transformer 在生成每个新 token 时都会计算它与所有输入 token (包括原图 token) 的注意力权重。如果某个新 token 对应的区域用户没有指定修改,模型就会给原图对应位置的 token 高权重,实际上是在"抄"原图。
第三层:训练数据的归纳偏置。 OpenAI 用了海量的"原图-编辑图"配对数据来训练 GPT-Image-2,模型在训练中学到了一个隐式规则:除非 prompt 明确要求,否则尽量保持其他区域不变。这种偏置在权重里固化下来,推理时自然生效。
第四层:Thinking 模式的显式规划。 GPT-Image-2 会先用一段内部思考梳理出"哪些区域需要改、哪些保留",然后再生成,等于在生成前给自己列了一份保留清单。
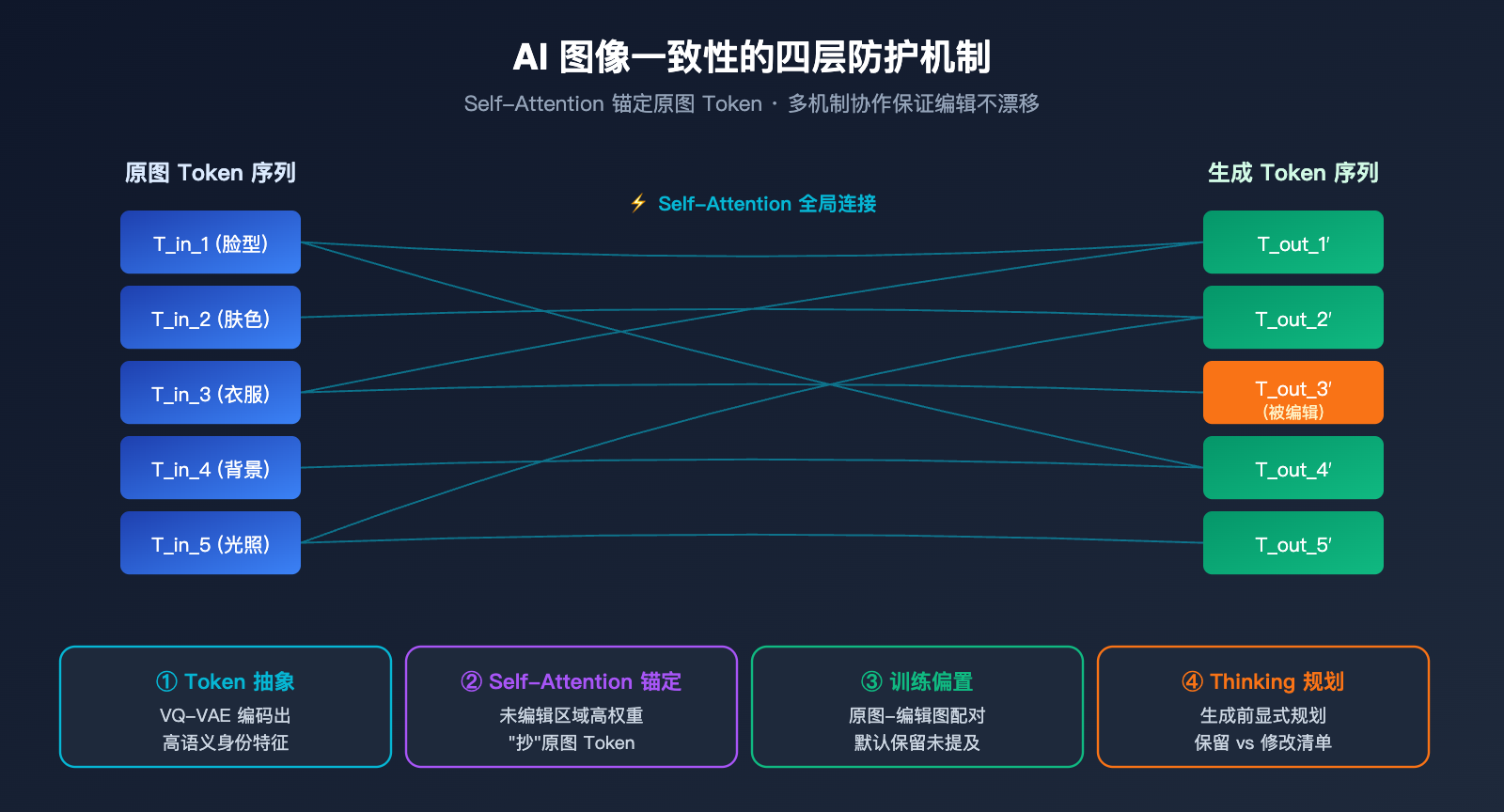
一致性机制的四层防护对比
| 机制层 | 作用范围 | 失效场景 |
|---|---|---|
| Token 抽象 | 全局身份特征 | 人脸过远导致 token 不足 |
| Self-Attention | 局部细节锚定 | prompt 与原图语义冲突 |
| 训练偏置 | 默认保留未提及区域 | prompt 过于激进 |
| Thinking 规划 | 复杂编辑指令 | 需多次试错调优 |
理解了这四层防护,你就能更精准地写出避免"漂移"的 prompt。比如,与其说"重画这个人的衣服",不如说"保持人物身份不变,仅将衣服颜色由白色改为蓝色"。我们在 API易 apiyi.com 上测试 GPT-Image-2 时发现,加入"保持其他元素不变"这类显式约束,可以让 Thinking 模式生效得更彻底。
mask 模式:让重绘"假装"成局部修改
如果用户想要更确定的"局部修改"体验,GPT-Image-2 提供了 /v1/images/edits 端点的 mask 参数。用户可以传入一张二值化的 mask 图像:白色区域允许 AI 生成,黑色区域必须保留原图。
但需要强调的是,mask 模式不改变重绘的本质。它的作用是在生成 token 时增加一个硬约束:对应黑色区域的 token 必须完全等于原图 token。这是在自回归生成框架内做的一种"约束生成",而不是 PS 式的像素覆盖。
扩散模型 vs 自回归图像生成:两种实现原理对比
要充分理解 GPT-Image-2 的优势,需要把它和上一代的扩散模型(Stable Diffusion、DALL-E 3、Midjourney)做一次系统对比。两套体系在 AI 图片编辑原理 上有本质区别。
扩散模型的工作流程是从一张纯噪声图开始,经过几十步迭代去噪,逐渐显现出最终图像。做编辑时,它会先把原图压缩到 latent 空间,在 latent 上加部分噪声,然后用 prompt 引导去噪过程,最终解码回像素。inpainting 模式会在每一步去噪时,把 mask 之外的 latent 重置为原图 latent,从而"锁住"未编辑区域。
自回归模型的工作流程完全不同:把图编码成 token,然后像写文章一样逐 token 预测输出。没有迭代去噪,没有 latent 噪声,一遍生成完成。

两种范式在图片编辑场景下的表现差异巨大,具体对比如下表:
| 对比项 | 扩散模型 (SD/DALL-E 3) | 自回归模型 (GPT-Image-2/Nano Banana) |
|---|---|---|
| 生成方式 | 多步去噪迭代 | 单次 token 序列预测 |
| Mask 实现 | 每步重置 unmasked latent | token 级硬约束 |
| 边界处理 | 易出现 latent 缝合 artifact | 自然过渡(语义级) |
| 文字渲染 | 经常失败 | 准确率约 99% |
| 多轮编辑 | 累积重编码损失 | 几乎无漂移 |
| 复杂指令 | 难以精准布局 | 支持 100+ 对象布局 |
| 速度 | 通常 10-30 秒 | 比扩散快约 60% |
| 长文字渲染 | 困难 | 任意语言/脚本 |
扩散模型的核心痛点在于 VAE 编解码的重编码损失 ——即便理论上 unmasked 区域被锁住,但 latent 与像素之间的来回转换会带来微小色差。多次编辑后,损失累积成肉眼可见的伪影。GPT-Image-2 用自回归架构绕过了这个问题,Token 解码只发生一次。
但自回归也不是没有代价。它的生成成本更高,主要是因为 token 数量大且每个 token 都需要完整的 Transformer forward。我们建议追求极致一致性和文字渲染的场景使用 GPT-Image-2 (可通过 API易 apiyi.com 接入),而对成本敏感的高并发场景仍可保留 Stable Diffusion 系列作为补充。
gpt-image-2 编辑原理实战:API 调用与一致性优化
理解了 gpt-image-2 编辑原理,我们来看怎么把这套机制用到位。下面是一个最小可运行示例,通过 API易兼容端点调用 GPT-Image-2 的编辑接口:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="保持人物身份与背景不变,仅将上衣颜色由白色改为深蓝色",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
注意 prompt 写法:显式说明哪些保留、哪些修改,这能直接触发 GPT-Image-2 的 Thinking 模式按你预期的方式规划生成。如果想做精准的区域编辑,可以追加 mask 参数:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="将白色衣服改为深蓝色西装",
size="1024x1024"
)
mask 是一张同尺寸的 PNG,白色区域是允许修改的范围,黑色区域强制保留原图 token。
一致性优化的 5 条实操建议
针对 AI 图像一致性 的实际调试,我们总结了 5 条来自真实测试的经验:
- prompt 中明确"保留什么":不要只说"改 X",要说"保持 Y 不变,改 X"。
- 参考图分辨率适中:OpenAI 推荐参考图长边不超过 1024px,过大反而稀释 token 注意力。
- 多轮编辑使用同一基准图:不要把上一次编辑结果当作下一轮的输入,而是基于原图做不同维度的编辑,最后再合并 prompt。
- 复杂场景拆分指令:把"把人物换成黄昏背景的日系风格"拆成两步,每步只动一个变量。
- 质量参数选 high:低质量会减少 token 数量,直接削弱一致性。
gpt-image-2 价格与一致性的权衡
| 参数组合 | 单图成本 | 适用场景 |
|---|---|---|
| 1024×1024 low | $0.006 | 创意草图/快速预览 |
| 1024×1024 medium | $0.053 | 社交媒体配图 |
| 1024×1024 high | $0.211 | 商业级编辑/反复迭代 |
| 4K high | $0.50+ | 印刷/高分辨率展示 |
成本与一致性是正相关的——高质量模式给模型分配更多 token,自然能保留更多原图特征。我们建议在生产环境优先使用 high 模式,通过 API易 apiyi.com 的 Batch API 还能进一步降低 50% 成本。
AI 图片编辑原理 FAQ 与未来趋势
Q1: GPT-Image-2 是 PS 局部修改还是重新绘制?
A: 是重新绘制。所有自回归图像模型都需要把原图编码成 token,再生成完整的输出 token 序列,最后解码成新图。即使开启 mask,也只是在重绘过程中加约束,不是真的局部覆盖像素。
Q2: 既然是重绘,为什么编辑后的图看起来几乎一样?
A: 靠四层一致性机制:视觉 token 的特征抽象、Self-Attention 对原图的全局参考、训练数据的归纳偏置、Thinking 模式的显式规划。这些机制让 AI"主动选择"保留未提及的区域。
Q3: 扩散模型的 inpainting 算不算真的局部修改?
A: 不算。Stable Diffusion 的 inpainting 也要把 unmasked 区域过一遍 VAE 编解码,会带来微小重编码损失。多轮编辑会累积成可见伪影,这正是 GPT-Image-2 改用自回归的核心动机之一。可通过 API易 apiyi.com 同时调用两种模型做对比验证。
Q4: 为什么 GPT-Image-2 能多轮编辑而不漂移?
A: 因为自回归架构在每次生成时都参考完整的原图 token 序列,没有迭代去噪的累积误差。结合 Thinking 模式的显式保留规划,多轮编辑的稳定性远超扩散模型。
Q5: 我应该用 mask 还是纯 prompt 编辑?
A: 优先用 prompt + 明确的保留指令,这能利用 Thinking 模式自动规划。需要修改的区域边界清晰且必须精准(如人脸特定部位)时,再加 mask 做硬约束。
Q6: 未来 AI 图片编辑会怎么发展?
A: 三个趋势:(1) Tokenizer 信息密度持续提升,降低 token 数和成本;(2) 多模态统一,文本/图像/视频共享同一 Transformer;(3) Thinking 推理能力增强,支持更长的多步编辑链。我们建议持续关注 API易 apiyi.com 上的新模型上线动态,以便第一时间评估升级路径。
总结:理解原理,才能用好工具
GPT-Image-2 等自回归图像模型颠覆了我们对 "AI 编辑图片" 的直觉认知。它们不是 Photoshop 式的局部修改,而是基于 自回归图像生成 的智能重绘。一致性来自 token 化的语义抽象、Self-Attention 的全局锚定、训练偏置以及 Thinking 模式四重机制的协作。
理解这套原理,你才能写出真正能触发 Thinking 规划的 prompt、避开多轮编辑的陷阱、在成本和质量之间找到平衡点。我们建议通过 API易 apiyi.com 平台进行实际测试与对比,该平台支持 GPT-Image-2、Nano Banana、Stable Diffusion 等多种主流模型的统一接口调用,便于快速验证本文提到的所有原理与优化技巧。
本文由 APIYI Team 撰写,基于 OpenAI、Google DeepMind 等官方资料与一线实测整理。如需在生产环境调用 gpt-image-2,可访问 API易官网: apiyi.com 获取接入文档。