2026 年 4 月,中國大陸開發者羣裏被問得最多的兩款編碼模型是 GLM-5.1 和 Claude Sonnet 4.6。前者剛剛由 Z.ai(原智譜)以 MIT 協議開源,在 SWE-Bench Pro 上以 58.4 分把 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro 全部壓在身後,瞬間登頂全球開源編碼榜首;後者則被 Anthropic 稱爲"中端模型裏的旗艦水平",SWE-bench Verified 拿到了 79.6%,接近 Opus 4.6 的 80.8%,價格卻只有 Opus 的幾分之一,並且首次給 Sonnet 系列開放了 1M token 上下文。
那麼問題來了——GLM-5.1 vs Claude Sonnet 4.6,在真正的編程場景裏,到底誰更強? 這不是一個能用一句話回答的問題。兩者的強項分佈得非常不一樣:GLM-5.1 在"工業級真實代碼修復"基準上已經反超 Sonnet 4.6,但在第三方綜合評測裏 Sonnet 又把整體平均分拉了回來。本文將圍繞 6 個維度(代碼基準、知識、價格、上下文、Agent 長程任務、生態兼容性) 逐一拆解兩者的真實差異,並給出按業務場景的明確選型建議。

GLM-5.1 vs Claude Sonnet 4.6 核心數據一覽
在動手對比之前,我們先把兩者的關鍵事實並排放在一張表裏。所有數據均來自 BenchLM、Z.ai、Anthropic 與第三方評測平臺的公開信息。
| 維度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 廠商 | Z.ai(原智譜 AI) | Anthropic |
| 發佈時間 | 2026-04-07(開源) | 2026 年初 |
| 架構 | 754B MoE / 40B 激活 | 不公開(中型 Sonnet 級別) |
| 開源協議 | ✅ MIT | ❌ 閉源 |
| 上下文窗口 | 200K(部分平臺顯示 203K) | 200K → 1M(beta) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐(開源 #1,反超 Opus 4.6) | 略低於 Opus 4.6 |
| BenchLM 綜合編碼均分 | 58.4 | 66.4 |
| BenchLM 知識均分 | 52.3 | 73.7 |
| BenchLM 總分 | 79 | 80 |
| 輸入價格 ($/M) | $1.00(Z.ai 直採) | $3.00 |
| 輸出價格 ($/M) | $3.20(Z.ai 直採) | $15.00 |
| Agent 長程任務 | 單任務約 8 小時 | Claude Code 70% 用戶偏好率 |
| 接入 API易 | ✅ 已上線 https://api.apiyi.com/v1 |
✅ 已上線 |
| 兼容工具 | Claude Code / Cline / Cursor / OpenClaw | 同上 + 原生 Anthropic 生態 |
🎯 快速判斷建議:兩者的差異不是"誰強誰弱",而是"在哪類場景下強"。如果你想立即跑橫向對比,API易 apiyi.com 已經同時上線了 GLM-5.1 與 Claude Sonnet 4.6,只需要修改
model字段就能在同一份業務代碼裏切換兩者,15 分鐘之內就能在自己的真實任務上得出比任何評測都準確的判斷。
GLM-5.1 vs Claude Sonnet 4.6 的核心差異:不是同一類模型
第一個必須先講清楚的事實是——GLM-5.1 和 Claude Sonnet 4.6 嚴格來說不是"同一檔"模型,它們的設計目標存在系統性差異。
模型定位差異
| 維度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 廠商定位 | "前沿開源 + 長程 Agent 編碼" | "中端旗艦 · 性價比之王" |
| 參數量級 | 大模型(754B MoE) | 中型模型(參數未公開) |
| 訓練目標 | 編碼 + Agent + 數學推理 | 通用 + 編碼 + 知識 + 安全 |
| 商業模式 | MIT 開源 + Z.ai 自營 API | 閉源訂閱 + API |
| 主要競爭對手 | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
注意這一行——GLM-5.1 在 Z.ai 的內部定位裏其實是衝着 Claude Opus 4.6 去的,而不是 Sonnet 4.6。 這意味着如果你單純比"編碼能力上限",GLM-5.1 的對照組應該是 Opus,不是 Sonnet。但在"價格 + 綜合能力 + 實用性" 這三件事上,Sonnet 4.6 是中端市場裏非常強的一個對手,因此把兩者放在一起對比仍然有非常實際的工程價值。
第三方綜合評測上的現狀
根據 BenchLM 在 2026 年 4 月公佈的臨時排行榜:
- 總分:Claude Sonnet 4.6 = 80,GLM-5.1 = 79(差 1 分,接近持平)
- 編碼均分:Claude Sonnet 4.6 = 66.4,GLM-5.1 = 58.4(Sonnet 4.6 領先 8 分)
- 知識均分:Claude Sonnet 4.6 = 73.7,GLM-5.1 = 52.3(Sonnet 4.6 領先 21.4 分,差距最大)
但在另外一項專項基準上,情況完全反轉:
- SWE-Bench Pro(真實工業代碼修復):GLM-5.1 = 58.4 ⭐,反超 Claude Opus 4.6 的 57.3 與 GPT-5.4 的 57.7,Sonnet 4.6 自然也在其下
- SWE-bench Verified:Claude Sonnet 4.6 = 79.6%,GLM-5.1 = 77.8%,僅差 1.8 個百分點
把這幾組數字對照看就能得出第一個結論:GLM-5.1 不是"全面超越 Sonnet 4.6"的怪獸,但在"難度最高的工業代碼修復"這一項上確實拿到了第一名,而 Sonnet 4.6 在更廣泛的綜合編碼評測裏仍然保持均衡領先。
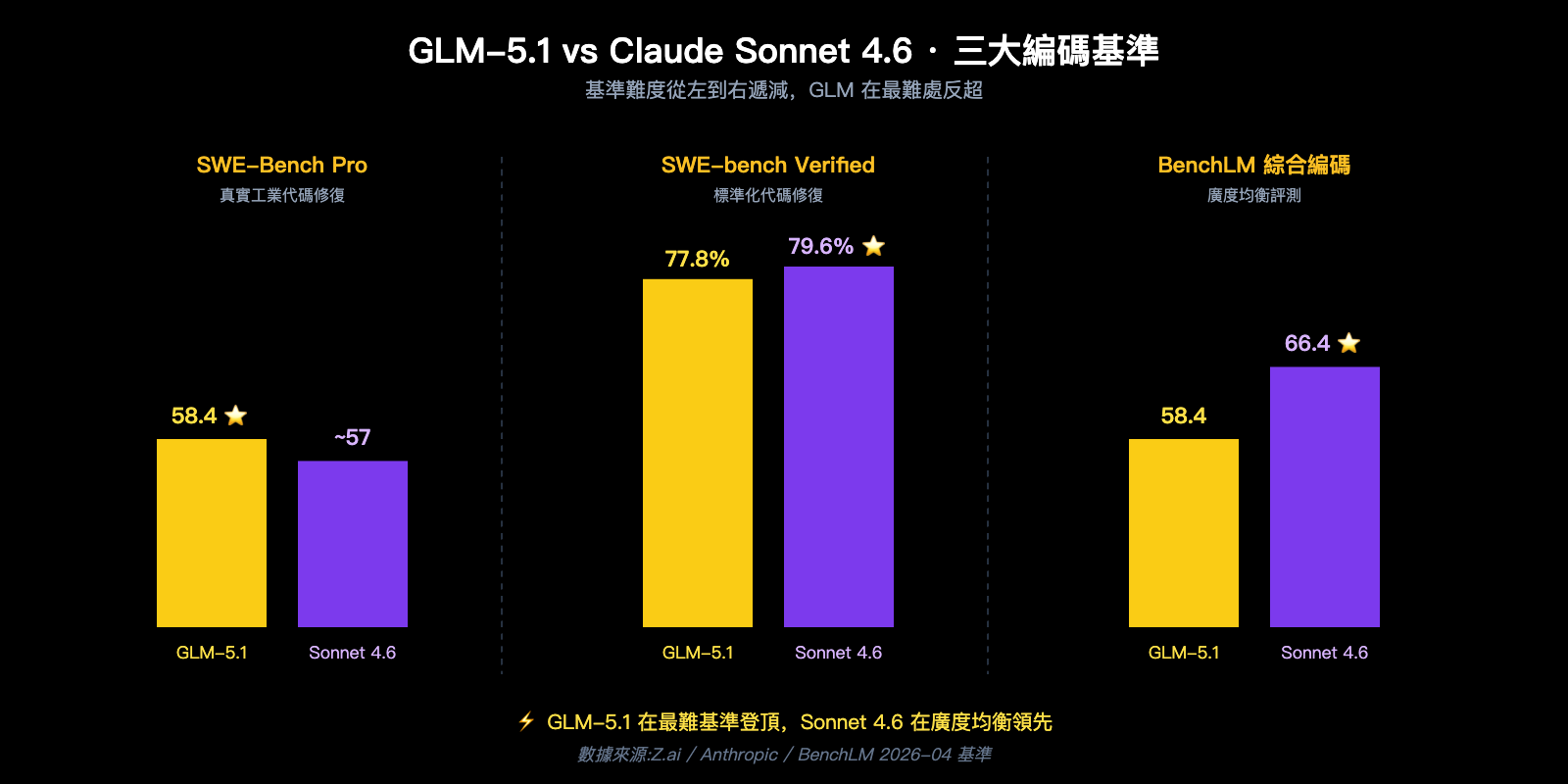
維度一:代碼基準對比 — GLM-5.1 與 Sonnet 4.6 的真實差距
代碼能力是這次對比的核心,也是最容易被基準數字誤導的部分。我們把所有相關基準整合到一張表裏,然後再做工程師視角的解讀。
代碼相關基準完整對照
| 基準 | GLM-5.1 | Claude Sonnet 4.6 | 領先方 | 差距 |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ 分 |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM 編碼均分 | 58.4 | 66.4 | Sonnet 4.6 | 8 分 |
| OSWorld(智能體桌面) | 未公開同口徑 | 72.5% | Sonnet 4.6 | — |
| Claude Code 用戶偏好率 | 未參與 | 70%(對 Sonnet 4.5)、59%(對 Opus 4.5) | Sonnet 4.6 | — |
| 8 小時長程任務 | ✅ 官方主打 | 已支持 Claude Code 長程 | 接近持平 | — |
工程視角解讀
把這張表讀三遍之後,可以提煉出幾條非工業基準愛好者也能聽懂的結論:
- 如果你的工作是"修真實倉庫的真實 bug":GLM-5.1 在 SWE-Bench Pro 上排第一,這是一個非常"貼近一線工程師日常"的基準,它意味着 GLM-5.1 最適合作爲 Coding Agent 的核心引擎;
- 如果你的工作是"標準化的代碼修復 + 通用編程":Sonnet 4.6 的 SWE-bench Verified 略高,且 BenchLM 綜合編碼均分明顯領先,它在"廣度"上更穩;
- 如果你的工作是 Claude Code / Cursor 內長程任務:Sonnet 4.6 的 70% 用戶偏好率說明它在"實際開發流"裏被驗證過;GLM-5.1 的 8 小時長程能力是 Z.ai 主打賣點,但需要你自己跑過才能確認效果;
- 如果你的工作裏包含"知識密集型問題"(查文檔、寫設計、做技術調研):Sonnet 4.6 的 73.7 vs GLM-5.1 的 52.3,差距非常明顯。
爲什麼會出現這種"基準互相打架"的情況
很多讀者會問:爲什麼同樣是"編碼能力",一個基準說 GLM-5.1 更強、另一個說 Sonnet 4.6 更強?答案在於基準設計的差異:
- SWE-Bench Pro 偏向"難度極高的真實工業代碼修復",任務質量門檻高、數量少,對模型的'長程推理 + 工具調用'能力要求極致——這正是 GLM-5.1 主打的方向;
- SWE-bench Verified 是"經過人工驗證的標準代碼修復任務集",更接近"日常開發場景的平均水平",對模型的'廣度 + 穩定性'要求更高——這是 Sonnet 4.6 的強項;
- BenchLM 綜合編碼均分 把多個基準做加權平均,對'各類任務都能應對'的中型旗艦更友好。
理解了這層差異,你就不會再被任何一個孤立的數字誤導。
🎯 基準選型建議:不要只看一個基準下結論。最務實的做法是:把你團隊最常見的 5-10 個真實編碼任務整理成一個內部基準集,然後通過 API易 apiyi.com 同時調用 GLM-5.1 與 Claude Sonnet 4.6 各跑一遍,用你自己的數據反向驗證哪一個更適合你的業務畫風。
維度二:知識與推理 — Sonnet 4.6 的明顯優勢區
如果說代碼層面是"互有勝負",那麼在 知識 / 推理 / 通用理解 這一維度,Sonnet 4.6 的優勢非常明顯。
| 維度 | GLM-5.1 | Claude Sonnet 4.6 | 差距 |
|---|---|---|---|
| BenchLM 知識均分 | 52.3 | 73.7 | 21.4 分 |
| 長文檔理解 | 強 | 更強(配合 1M 上下文) | |
| 自然語言寫作 | 中文優秀 | 多語種均衡 | |
| 安全與合規推理 | 中等 | 明顯更強(Anthropic 強項) |
這意味着在以下場景中,Sonnet 4.6 是更穩妥的選擇:
- 寫技術調研報告 / 設計文檔 / 架構方案;
- 跨語言文檔摘要、合規分析;
- 需要"既懂代碼又懂業務"的混合任務;
- 客戶面對面的內容生成,要求更穩的安全護欄。
GLM-5.1 在知識維度上的相對弱勢並不是"訓練不到位",而是它的訓練數據與目標更傾向 Coding + 數學 + 工具使用,在"通識知識"這一項上相對沒有 Sonnet 4.6 那麼均衡。
維度三:價格對比 — GLM-5.1 的殺手鐧
如果只看一項,價格是 GLM-5.1 對比 Sonnet 4.6 時最銳利的武器。
Token 單價直接對比
| 維度 | GLM-5.1(Z.ai 直採) | Claude Sonnet 4.6 | GLM-5.1 性價比優勢 |
|---|---|---|---|
| 輸入 ($/M) | $1.00 | $3.00 | 便宜 3 倍 |
| 輸出 ($/M) | $3.20 | $15.00 | 便宜 ~4.7 倍 |
| 綜合(2:1 比例) | ~$1.73 | ~$7.00 | 便宜 ~4 倍 |
注意幾件事:
- 第三方平臺(如 BenchLM)統計的 GLM-5.1 價格略高($1.40 輸入 / $4.40 輸出),包含了一定的轉售加成,Z.ai 官方公佈的直採價格是 $1.00 / $3.20;
- Sonnet 4.6 的 $3 / $15 是 Anthropic 官方價,已經比 Opus 4.6 便宜 5 倍,在中端市場已屬"性價比之王";
- 即便如此,GLM-5.1 在輸出 token 上的優勢仍然在 4-5 倍,這對"輸出量大於輸入量"的代碼生成場景來說意義巨大。
真實成本舉例
爲了讓差距更直觀,假設一個"日常 Coding Agent" 的典型任務:輸入 5K token、輸出 20K token,日均 1000 次調用。
| 模型 | 輸入成本/天 | 輸出成本/天 | 合計/天 | 合計/月 |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
差距:Sonnet 4.6 月成本約爲 GLM-5.1 的 4.5 倍。
對一個"日均 1000 次 Agent 調用"的中型 SaaS 來說,僅 Token 成本一項就能差出近 7000 美元/月——這筆錢足夠再僱半個工程師。
🎯 成本優化建議:對於已經在使用 Claude Sonnet 4.6 的團隊,我們建議先在 API易 apiyi.com 上把 20% 流量 切到 GLM-5.1 做 A/B,如果效果可接受,就把"非關鍵業務的代碼生成"全部遷到 GLM-5.1,只保留"客戶面對面"的關鍵調用走 Sonnet 4.6——這樣能在不損失整體質量的前提下把賬單砍掉一大截。
維度四:上下文窗口 — Sonnet 4.6 的反擊
價格上 GLM-5.1 完勝,但上下文窗口這一項,Sonnet 4.6 反過來掌握了主動權。
| 維度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 標準上下文 | 200K(部分平臺 203K) | 200K |
| Beta 上下文 | — | 1M token(beta) |
| 最大輸出 | 128K | 較低 |
| 上下文壓縮 | 否 | ✅ 自動壓縮老上下文 |
1M token 是 Sonnet 4.6 的標誌性升級——它意味着你可以把一個完整的中型代碼倉庫一次性塞進 prompt 而不需要 RAG 檢索。對"全倉庫重構 / 跨文件 bug 定位 / 完整 codebase 理解"這類任務,Sonnet 4.6 在 2026 年 4 月幾乎是無可替代的。
GLM-5.1 的 200K 也已經夠用 90% 的日常場景,但在"超長上下文"的極限場景上確實落後一截。

維度五:Agent 長程任務 — 兩種打法的對決
第五個維度是 Agent 長程任務能力——這是 2026 年所有頭部編碼模型都在角力的方向。
兩者的"長程"路線不同
- GLM-5.1:Z.ai 主打"單任務 8 小時持續工作",強調 規劃 → 執行 → 測試 → 修復 → 二次優化 的端到端循環,靠的是模型本身的推理深度與工具調用穩定性;
- Claude Sonnet 4.6:Anthropic 主打"Claude Code 實戰體驗",70% 的 Sonnet 4.5 用戶在內部測試中偏好 Sonnet 4.6,靠的是工程化的 Claude Code 工作流 + 1M 上下文 + 上下文壓縮。
可以理解爲:
| 路線 | 核心優勢 | 適合場景 |
|---|---|---|
| GLM-5.1 | 模型推理深度 + 工具調用穩定性 | 後臺自動化 Agent / 無人值守任務 |
| Sonnet 4.6 | Claude Code 工作流 + 1M 上下文 | 開發者交互式編碼 / IDE 集成 |
如果你做的是"後臺跑 Agent 自己開發功能"這類無人值守場景,GLM-5.1 的 8 小時長程能力天然適合;如果你做的是"工程師在 IDE 裏和模型對話寫代碼",Sonnet 4.6 的 Claude Code 集成體驗更成熟。
維度六:生態兼容性 — Sonnet 4.6 的工具鏈優勢
最後一個維度是生態。這一項 Sonnet 4.6 仍然處於明顯領先位置,但 GLM-5.1 已經追得很快。
| 維度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code 兼容 | ✅(OpenAI 兼容入口) | ✅ 原生 |
| Cline / Cursor | ✅(OpenAI 兼容入口) | ✅ 原生 |
| OpenClaw | ✅ | ✅ |
| Anthropic 工具調用 | OpenAI 風格 | ✅ 原生 |
| 第三方 Agent 框架 | 大多數支持 OpenAI 兼容 | 大多數支持 Anthropic 原生 |
| 部署靈活度 | ✅ MIT 自託管 / API易 / Z.ai 自營 | API易 / Anthropic 官方 |
值得注意的是,API易 apiyi.com 同時支持 OpenAI / Claude Native / Gemini Native 三種原生格式,這意味着無論你想用哪種風格的 SDK 調用 GLM-5.1 與 Sonnet 4.6,都可以在同一個 API Key 下完成。這在兩者的對比測試裏是一個非常實用的細節——你不需要在測試期間維護兩套認證、兩套監控、兩套賬單。
按場景給出最終選型建議
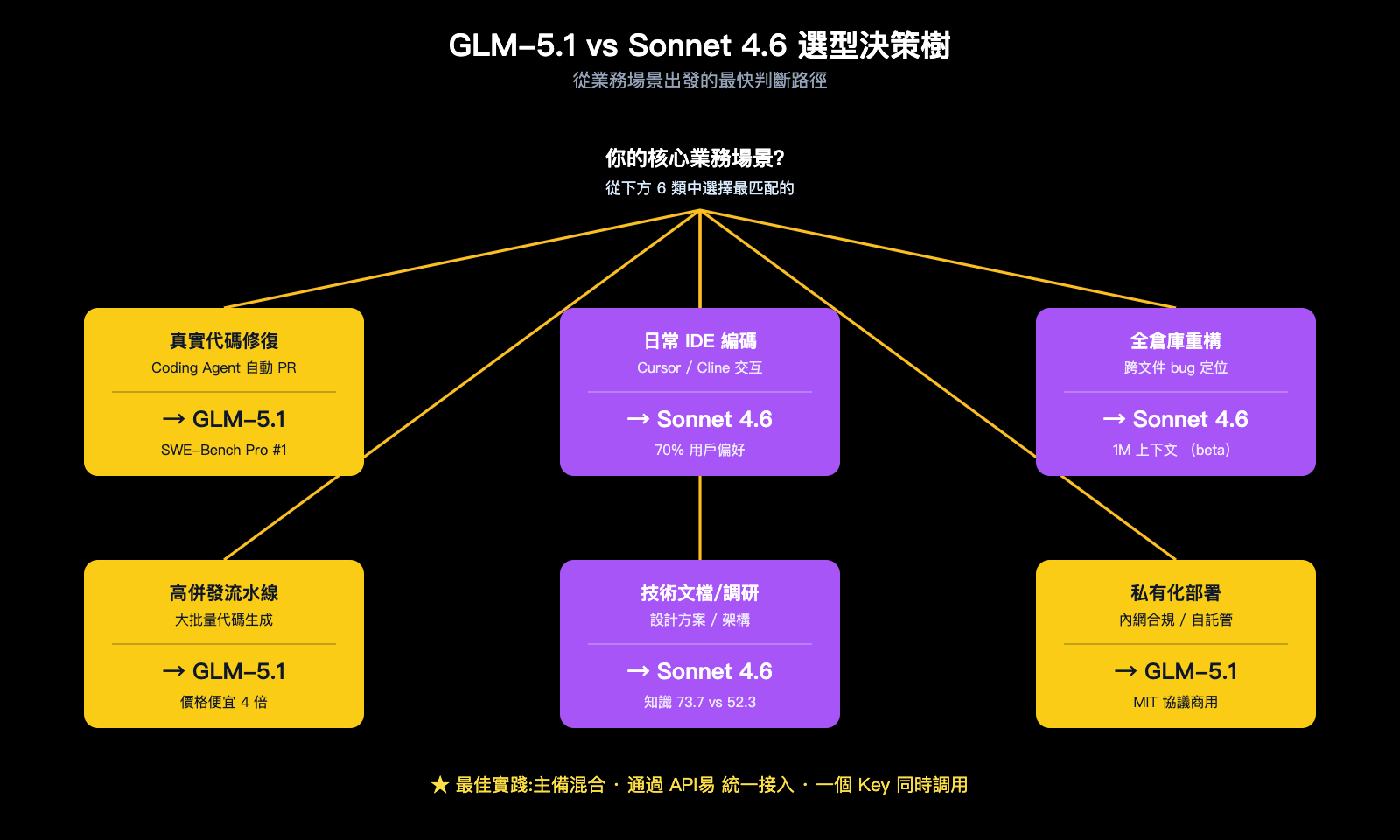
把 6 個維度全部串起來,我們可以給出非常具體的"按業務場景選模型"建議。
場景對照表
| 業務場景 | 推薦模型 | 關鍵理由 |
|---|---|---|
| 真實工業代碼修復(Agent 自動 PR) | GLM-5.1 | SWE-Bench Pro 全球第一 + 8 小時長程 |
| Cursor / Cline 日常 IDE 編碼 | Claude Sonnet 4.6 | Claude Code 用戶偏好率 70%,工作流成熟 |
| 全倉庫重構 / 跨文件 bug 定位 | Claude Sonnet 4.6 | 1M 上下文(beta)是核心武器 |
| 標準化代碼生成 + 高併發調用 | GLM-5.1 | 價格便宜 4 倍,適合流水線生產 |
| 技術調研 / 設計文檔 / 架構方案 | Claude Sonnet 4.6 | 知識均分 73.7 vs 52.3 大幅領先 |
| 數學推理 / 算法競賽風格 | GLM-5.1 | AIME 2026 95.3 + GPQA-Diamond 86.2 |
| 客戶面向 SaaS 中的代碼生成模塊 | Sonnet 4.6(主) + GLM-5.1(備份) | Sonnet 主、GLM 兜底,降本同時保質 |
| 私有化部署 / 內網合規 | GLM-5.1 | MIT 協議 + 可自託管 |
| 中文 Coding 交互 | GLM-5.1 | 國產模型對中文 Prompt 更友好 |
| 一次性高難度推理 + 長鏈路工具調用 | 平手,需自測 | 兩者都能跑,差異在 5% 以內 |
推薦的混合策略
對於絕大多數中型團隊,我們更推薦"主備混合"的策略,而不是"二選一":
- 主力模型:根據你最多的業務場景挑一個(代碼修復選 GLM-5.1,IDE 集成選 Sonnet 4.6);
- 備份模型:把另一個掛上,用於關鍵業務的 A/B 驗證 + 灰度切換;
- 統一接入層:通過 API易 apiyi.com 用同一個 API Key 調用兩者,業務代碼只改 model 字段,不需要維護兩套認證邏輯;
- 成本監控:在 API易 控制檯裏把兩個模型的賬單分開看,定期判斷哪個模型在你業務上的"性價比"更高,動態調整流量比。
🎯 混合策略落地建議:在 API易 apiyi.com 上,你可以用同一個 API Key 在 GLM-5.1 與 Claude Sonnet 4.6 之間無縫切換,業務代碼只需要改一個字符串。我們建議先把"非關鍵代碼生成" 70% 流量切到 GLM-5.1,把"客戶面向 + 高難度推理" 30% 流量留給 Sonnet 4.6,這樣既能享受 GLM-5.1 的價格優勢,也能保證關鍵場景的穩定性。
GLM-5.1 vs Claude Sonnet 4.6 常見問題 FAQ
Q1:GLM-5.1 真的在編碼上超過 Claude Sonnet 4.6 了嗎?
部分超過,部分仍落後。在 SWE-Bench Pro(真實工業代碼修復)這一項最難的基準上,GLM-5.1 拿下 58.4 全球第一,已經超過 Claude Opus 4.6 的 57.3 與 GPT-5.4 的 57.7,自然也超過 Sonnet 4.6。但在 SWE-bench Verified(標準化代碼修復)上,Sonnet 4.6 79.6% 仍然領先 GLM-5.1 77.8% 約 1.8 個百分點;在 BenchLM 綜合編碼均分上,Sonnet 4.6 的 66.4 也領先 GLM-5.1 的 58.4 約 8 分。結論是:GLM-5.1 在"難度頂峯"超過了 Sonnet 4.6,但在"廣度均衡"上仍然落後。
Q2:GLM-5.1 比 Claude Sonnet 4.6 便宜多少?
按 Z.ai 官方直採價,GLM-5.1 的輸入 $1.00 / 輸出 $3.20,而 Claude Sonnet 4.6 是 $3.00 / $15.00——輸入便宜 3 倍,輸出便宜約 4.7 倍。在"日均 1000 次 Coding Agent 調用 + 輸入 5K / 輸出 20K" 的典型場景下,Sonnet 4.6 的月賬單大約是 GLM-5.1 的 4.5 倍。如果你的業務"輸出量明顯大於輸入量",GLM-5.1 的性價比優勢會更顯著。
Q3:GLM-5.1 和 Sonnet 4.6 的上下文窗口哪個更大?
Claude Sonnet 4.6 更大。GLM-5.1 是 200K(部分平臺顯示 203K),Sonnet 4.6 是 200K → 1M token(beta)。1M 上下文意味着 Sonnet 4.6 可以一次性讀完一箇中型代碼倉庫,這是它在"全倉庫重構 / 跨文件 bug 定位"這類任務上的核心武器。如果你的任務對超長上下文有剛需,Sonnet 4.6 是更穩妥的選擇。
Q4:我現在用 Claude Sonnet 4.6 跑 Cursor / Cline,值得切換到 GLM-5.1 嗎?
取決於你的痛點。如果你最在意"賬單",GLM-5.1 能砍掉一半甚至更多成本,值得切換;如果你最在意"日常編碼體驗的穩定性",Sonnet 4.6 的 70% 用戶偏好率說明它在 Claude Code 工作流裏已經被廣泛驗證,遷移收益可能小於風險。最穩妥的做法是先用 API易 apiyi.com 把 20% 流量切到 GLM-5.1 做 A/B,跑一週後再決定是否擴大比例。
Q5:GLM-5.1 和 Sonnet 4.6 都能在 API易 上調用嗎?
是的,兩者都已上線。API易 apiyi.com 同時支持 OpenAI / Claude Native / Gemini Native 三種原生格式,你只需要把 OpenAI SDK 的 base_url 改成 https://api.apiyi.com/v1、model 在 glm-5.1 與 claude-sonnet-4-6(或類似 ID)之間切換,就能在同一份代碼裏同時跑兩者,做橫向對比的效率非常高。
Q6:作爲獨立開發者,我應該選哪個?
如果你只能選一個,先看你的工作流:做 Coding Agent / 後臺自動化 / 大批量代碼生成 → 選 GLM-5.1;做 IDE 內交互式編程 / 全倉庫重構 / 客戶面向的內容生成 → 選 Sonnet 4.6。如果你不想做艱難的二選一,兩個都接上、用 API易 統一管理纔是 2026 年開發者的最佳實踐——賬單會隨着模型選型自動優化,而不是被任何一家廠商綁架。
總結:GLM-5.1 vs Claude Sonnet 4.6 的最終判斷
把 6 個維度的對比拼在一起,GLM-5.1 vs Claude Sonnet 4.6 的最終判斷可以歸納成下面這段話:GLM-5.1 在"難度極高的工業代碼修復 + 價格 + 國產開源 + 長程 Agent" 4 項上擁有結構性優勢,Claude Sonnet 4.6 在"廣度均衡 + 知識深度 + 1M 上下文 + IDE 工作流成熟度" 4 項上保持領先。兩者不是"誰取代誰"的關係,而是一對"針對不同業務場景互補"的工具。
對 2026 年中後期的中國大陸開發團隊而言,最聰明的玩法不是非此即彼,而是 "主備混合 + 統一接入層":讓 GLM-5.1 承擔成本敏感、長程自動化、私有化合規的部分,讓 Sonnet 4.6 承擔用戶面向、複雜上下文、技術寫作的部分。通過 API易 這種統一中轉把兩者放在同一個 API Key 下,再用真實業務賬單數據動態調整流量比,就能在不犧牲質量的前提下把月度賬單大幅壓縮。
🎯 最終建議:GLM-5.1 與 Claude Sonnet 4.6 都已在 API易 apiyi.com 上線。我們建議你今天就在 apiyi.com 創建一個 API Key,把 OpenAI SDK 的
base_url改成https://api.apiyi.com/v1,用同一份代碼先跑 5 個 GLM-5.1 任務,再用同樣的 prompt 跑 5 個 Sonnet 4.6 任務,親手驗證本文 6 個維度的所有結論。任何評測都不能替代你的實測,但這個 30 分鐘的最小驗證會讓你建立起對 2026 年最強兩款 Coding 模型的真實手感。
作者:APIYI Team | 關注 AI 大模型落地與編碼工具鏈評測,更多模型對比與實戰調用請訪問 API易 apiyi.com。