В 2026 году один независимый австрийский разработчик создал опенсорсный проект в свободное время на выходных, который за два месяца набрал 247 тысяч GitHub Stars и стал платформой для AI-агентов, которую активно внедряют компании Кремниевой долины и Китая.
Этот проект называется OpenClaw.
В то же время возник вопрос: в реальных сценариях работы агентов, таких как OpenClaw, какая Большая языковая модель покажет себя лучше всего?
Именно эту проблему решает PinchBench. Это официальный бенчмарк OpenClaw, разработанный командой kilo.ai на Rust, который использует реальные задачи вместо синтетических тестов и предоставляет разработчикам надёжную основу для выбора модели.
В этой статье мы начнём с истории успеха OpenClaw, подробно разберём систему оценки PinchBench, поможем понять истинное значение AI-бенчмарков и расскажем, как выбрать модель, подходящую для вашего рабочего процесса с агентами, основываясь на данных тестирования.
I. Что такое OpenClaw: Открытый проект, трижды менявший название за месяц
Рождение OpenClaw и споры о названии
История OpenClaw начинается в ноябре 2025 года.
Австрийский разработчик Питер Штайнбергер в свободное время создал платформу для AI-агентов, которую изначально назвал Clawdbot. Основная идея проекта была проста: сделать так, чтобы AI был не просто чат-ботом, а мог по-настоящему взять на себя ваши цифровые рабочие процессы — читать электронные письма, писать код, управлять календарем, искать информацию.
Но концепция AI-агента не нова, почему же OpenClaw так быстро стал вирусным?
Ключевым фактором стало сочетание правильного момента и открытого исходного кода. В конце января 2026 года, с вирусным распространением проекта Moltbook, весь технический мир достиг пика желания "заставить AI по-настоящему работать", и Clawdbot, воспользовавшись этим, оказался в центре внимания.
Однако вскоре последовало уведомление от Anthropic о нарушении товарного знака — "Clawd" в названии Clawdbot был признан потенциально вводящим в заблуждение из-за сходства с внутренним названием продукта Anthropic. Проект был вынужден срочно переименоваться в Moltbot 27 января 2026 года, отдавая дань уважения популярному в то время проекту Moltbook.
Но через три дня Штайнбергер признался на GitHub: новое название "никогда не звучало правильно" ("never quite rolled off the tongue"), и проект снова был переименован в OpenClaw, под которым он известен и по сей день.
Эта история с переименованиями, напротив, стала лучшим "бесплатным маркетингом" для проекта, сделав OpenClaw широко известным в сообществе разработчиков.
По состоянию на 2 марта 2026 года OpenClaw на GitHub набрал:
- ⭐ 247 тысяч звезд (почти половина от количества звезд фреймворка React за тот же период)
- 🍴 47,7 тысяч форков
- 🌍 Широко развернут в компаниях Кремниевой долины, Европы и Китая
Основная техническая архитектура OpenClaw
Философия дизайна OpenClaw: локальное выполнение, независимость от модели, интеграция с мессенджерами.
Эти три особенности определяют его фундаментальные отличия от других фреймворков AI-агентов.
Локальное выполнение означает, что ваши данные не проходят через сторонние серверы. В отличие от большинства AI-помощников в формате SaaS, OpenClaw развертывается на собственном устройстве пользователя, а вызовы API модели могут быть направлены на частные конечные точки.
Независимость от модели означает, что OpenClaw сам по себе не привязан к какой-либо Большой языковой модели. Это "оболочка мозга", которая поддерживает подключение Claude, GPT, DeepSeek и любых других основных моделей. Разработчики могут свободно переключаться между ними в зависимости от типа задачи и бюджета.
Интеграция с мессенджерами — это самая характерная особенность OpenClaw: обычным пользователям не нужно открывать специальное приложение, они могут напрямую отправлять сообщения в Signal, Telegram, Discord или WhatsApp, чтобы использовать возможности AI-агента. Это значительно снижает порог входа, делая его доступным даже для нетехнических пользователей.
| Аспект дизайна | Выбор OpenClaw | Основные альтернативы | Пояснение различий |
|---|---|---|---|
| Место развертывания | Локальное выполнение | Облачный SaaS | Более высокая конфиденциальность данных, но требует самостоятельного обслуживания |
| Привязка к модели | Полная независимость | Привязка к конкретной модели | Гибкое переключение, но требует самостоятельной настройки |
| Пользовательский интерфейс | Мессенджеры | Специализированный веб/приложение | Низкий порог входа, функциональность ограничена возможностями мессенджеров |
| Область разрешений | Широкий доступ | Ограничения песочницы | Мощная функциональность, но более высокие риски безопасности |
| Лицензия | Полностью открытый исходный код | Закрытый/частично открытый | Развитие под руководством сообщества, но ограниченная гарантия поддержки |
🎯 Совет по использованию: Для развертывания OpenClaw необходимо настроить качественный бэкенд Большой языковой модели.
Мы рекомендуем использовать APIYI (apiyi.com) для подключения Claude Sonnet 4.6 или GPT-5.4.
Обе эти модели показали отличные результаты в PinchBench, а APIYI поддерживает унифицированный интерфейс для переключения,
что позволяет быстро сравнивать эффективность различных моделей без изменения основных настроек OpenClaw.
Границы возможностей OpenClaw
OpenClaw поддерживает довольно широкий спектр возможностей, но именно это вызвало споры о безопасности:
Доступные источники данных:
- Почтовые аккаунты (чтение, классификация, составление ответов)
- Календарные системы (просмотр, создание, изменение расписаний)
- Файловая система (просмотр, чтение, создание, перемещение файлов)
- Репозитории кода (чтение кода, запуск тестов, отправка изменений)
- Мессенджеры (агрегация и ответы на сообщения между платформами)
- Веб-информация (поиск, резюмирование, структурированное извлечение)
Типичные сценарии использования:
Пользователь отправляет в Telegram: "Помоги мне разобрать сегодняшнюю почту,
отметь те, на которые нужно ответить сегодня, и составь черновики ответов."
Процесс выполнения агентом OpenClaw:
1. Вызывает почтовый инструмент, читает непрочитанные письма за сегодня.
2. Использует Большую языковую модель для оценки срочности каждого письма.
3. Отфильтровывает список писем, требующих ответа сегодня.
4. Генерирует черновик ответа для каждого письма.
5. Возвращает в Telegram результаты сортировки и предварительный просмотр черновиков.
Эта способность "по-настоящему доводить дела до конца" является фундаментальным отличием OpenClaw от простых чат-ботов.
Штайнбергер присоединяется к OpenAI и будущее проекта
14 февраля 2026 года новость потрясла всё сообщество открытого исходного кода: Штайнбергер объявил на GitHub, что присоединяется к OpenAI, а проект передается под управление независимого фонда открытого исходного кода.
Это оказало двойное влияние на OpenClaw: с одной стороны, проект получил более профессиональное управление и юридическую защиту; с другой стороны, внешние наблюдатели начали гадать о мотивах OpenAI, стоящих за наймом основателя — это поглощение технологий или предотвращение потенциального конкурента?
В настоящее время фонд OpenClaw создан, проект по-прежнему остается полностью открытым, но приоритеты в дорожной карте разработки заметно изменились: функции безопасности корпоративного уровня и система контроля разрешений стали ключевыми задачами для следующей версии.
Споры о безопасности: Риски, связанные с мощными возможностями
Широкие системные разрешения, требуемые OpenClaw, с самого начала вызвали обеспокоенность исследователей кибербезопасности.
В марте 2026 года власти Китая объявили об ограничении использования OpenClaw на офисных компьютерах государственных предприятий и правительственных учреждений. Основные опасения включали:
- Возможность утечки данных через вызовы API Большой языковой модели к зарубежным поставщикам услуг.
- Широкие разрешения, которые при неправильной настройке могут стать точкой входа для атак.
- Возможность передачи конфиденциальной внутренней информации компании агентом между системами.
Этот инцидент напоминает всем корпоративным разработчикам: при внедрении мощных инструментов-агентов принципы минимизации привилегий и журналы аудита являются обязательными основами безопасности.
II. Реальная роль Benchmark в индустрии AI: От экзаменов к боевым действиям
Почему индустрия AI не может обойтись без Benchmark
Если вы когда-либо пытались сравнить возможности двух AI-моделей, вы, вероятно, сталкивались с дилеммой: производители говорят, что их модель "самая сильная", но что означает "сильная"? В каких задачах? По сравнению с какой базой?
Benchmark (эталонный тест) — это стандартизированная система тестирования, созданная для решения этой проблемы.
В индустрии AI хороший Benchmark должен соответствовать трем условиям:
- Воспроизводимость: Любой, используя тот же набор тестов, должен получить одинаковые результаты.
- Репрезентативность: Содержание теста должно отражать потребности в возможностях для реальных сценариев использования.
- Беспристрастность: Тестовый набор не должен быть загрязнен тренировочными данными разработчика модели.
В 2026 году в отрасли активно использовалось более 15 основных Benchmark, но, по оценкам экспертов, только около 4 из них действительно могут предсказать производительность в производственной среде.

Ограничения традиционных Benchmark
Чтобы понять ценность PinchBench, нужно сначала понять, почему традиционные Benchmark "недостаточны".
MMLU (Massive Multitask Language Understanding)
MMLU — это наиболее широко цитируемый тест общих знаний, охватывающий 57 дисциплин и содержащий около 14 000 вопросов с множественным выбором. Вопросы охватывают такие области, как медицина, право, история, математика, программирование.
Проблема в том, что это вопросы с множественным выбором, и модели нужно лишь выбрать один из 4 вариантов. В реальных сценариях с агентами модели должны самостоятельно генерировать ответы и даже использовать инструменты для получения информации — это совершенно отличается от "выбора одного из 4 вариантов".
HumanEval (тест генерации кода)
HumanEval — это знаковый Benchmark для измерения способности генерации кода, содержащий 164 задачи по программированию на Python. Но его задачи относительно фиксированы, и модели могли сталкиваться с похожими типами задач во время обучения, что приводит к "эффекту натаскивания" — высокие баллы не всегда отражают реальные способности к программированию.
Общие недостатки синтетических тестов:
| Тип проблемы | Конкретное проявление | Влияние на результаты оценки |
|---|---|---|
| Загрязнение данных | Набор для обучения содержит тестовые задачи | Высокий балл не отражает реальную способность к обобщению |
| Эффект натаскивания | Модель оптимизирована под конкретный Benchmark | Рейтинг завышен, фактические возможности не улучшились |
| Отрыв от сценария | Вопросы с выбором сильно отличаются от реального использования | Низкая предсказательная способность рейтинга |
| Статический набор данных | Задачи фиксированы, не могут обновляться | Новые возможности не могут быть оценены |
| Одномерная оценка | Учитывается только точность | Игнорируются скорость, стоимость, надежность |
5 ключевых измерений для оценки AI-агентов
Когда AI-системы эволюционируют от "ответов на вопросы" к "выполнению задач", система оценки также должна быть обновлена.
Для таких платформ AI-агентов, как OpenClaw, оценка должна охватывать следующие 5 ключевых измерений:
Измерение 1: Процент выполнения задач (Task Completion Rate)
Общий процент успешного выполнения задачи от ее получения до окончательного завершения. Это самый интуитивно понятный показатель, но и самый сложный — само определение "выполнения" является ключевой задачей при разработке оценки.
Метод тестирования: Дать агенту составную задачу, состоящую из 3-5 шагов, и подсчитать процент полного успеха, частичного успеха и неудачи.
Измерение 2: Точность вызова инструментов (Tool Call Accuracy)
Агент должен выбрать правильный инструмент из десятков доступных и вызвать его с правильными параметрами. Неправильный вызов инструмента — это не просто неудача, он может привести к побочным эффектам (например, случайное удаление файла, отправка неправильного письма).
Метод тестирования: Разработать задачи, требующие определенной последовательности инструментов, и подсчитать процент ошибок выбора инструмента и ошибок параметров.
Измерение 3: Последовательность многошагового рассуждения (Multi-step Reasoning Coherence)
Выполнение задачи часто требует 5-10 шагов, и агент должен сохранять четкое понимание цели на протяжении всего процесса, не "забывая, куда он идет" по пути.
Метод тестирования: Разработать длинные задачи, требующие более 10 шагов, и наблюдать, не происходит ли смещение цели или логический разрыв в середине.
Измерение 4: Сохранение контекста между раундами (Cross-turn Context Retention)
В многораундовом диалоге агент должен помнить ранее обмененную информацию. Такая информация, как "Вы в прошлый раз сказали, что встреча будет в среду", имеет решающее значение в рабочем процессе OpenClaw.
Метод тестирования: Разработать сценарии задач, требующие ссылки на информацию из 5+ предыдущих раундов, и подсчитать процент потери контекста.
Измерение 5: Частота галлюцинаций (Hallucination Rate)
Агент выдумывает несуществующие файлы, несуществующих контактов, неверные даты — эти галлюцинации в чате являются лишь незначительной проблемой, но в сценариях с агентами могут привести к реальным потерям (например, отправка письма с неверным содержанием).
Метод тестирования: Разработать задачи, требующие ссылки на реальные данные (имена файлов, адреса электронной почты, даты), и подсчитать частоту появления галлюцинаций.
🎯 Совет для разработчиков: При выборе модели агента наиболее важными двумя показателями являются процент выполнения задач и точность вызова инструментов.
Рекомендуется использовать платформу APIYI (apiyi.com) для быстрого подключения нескольких моделей и проверки их эффективности на ваших реальных задачах по этим 5 измерениям,
а не просто полагаться на цифры в рейтингах. APIYI поддерживает оплату по мере использования, что подходит для проведения небольших A/B тестов перед окончательным выбором.
III. Подробный анализ PinchBench: Официальный стандарт оценки OpenClaw
Предпосылки создания PinchBench
PinchBench, разработанный командой kilo.ai на Rust, представляет собой бенчмарк для оценки, специально созданный для сценариев OpenClaw и опубликованный с открытым исходным кодом на GitHub (репозиторий pinchbench/skill).
Ключевая проблема, которую он решает: общие рейтинги моделей слабо предсказывают реальную производительность агентов.
Исследования показали, что модель, входящая в 5% лучших по MMLU, в комбинированных задачах OpenClaw по классификации почты и планированию встреч может работать значительно хуже, чем модель со средним рейтингом MMLU, но специально оптимизированная для вызова инструментов.
Появление PinchBench впервые предоставило разработчикам надежный критерий оценки, ориентированный именно на рабочие процессы агентов.
23 категории задач PinchBench
PinchBench использует реальные задачи, а не синтетические, охватывая 23 категории задач, каждая из которых соответствует реальным сценариям использования пользователей OpenClaw:
Основные категории задач (6 типов):
| Категория задач | Конкретное содержание теста | Используемые инструменты | Сложность оценки |
|---|---|---|---|
| Управление расписанием | Планирование встреч, разрешение конфликтов, обработка часовых поясов, периодические напоминания | API календаря, инструменты для часовых поясов | ★★★☆☆ |
| Написание кода | Реализация функционала, исправление багов, рефакторинг кода, модульное тестирование | Выполнение кода, файловая система | ★★★★☆ |
| Обработка электронной почты | Классификация, приоритизация, автоматическое создание черновиков ответов, обработка вложений | API почтового клиента | ★★★☆☆ |
| Поиск информации | Веб-поиск, агрегация информации, генерация резюме, проверка источников | Поисковые системы, браузер | ★★★★☆ |
| Управление файлами | Организация, преобразование форматов, пакетные операции, контроль версий | Файловая система, инструменты преобразования | ★★☆☆☆ |
| Многоинструментальное взаимодействие | Передача данных между платформами, оркестрация цепочки инструментов, условный запуск | Комбинации различных инструментов | ★★★★★ |
Методология оценки PinchBench
PinchBench использует двойной механизм оценки, сочетающий объективность и качественную оценку:
Автоматическая проверка (Automated Checks)
Используется для проверяемых объективных критериев:
- Проходит ли код все тестовые примеры
- Перемещен ли файл в указанное место правильно
- Создано ли событие в календаре в правильное время
- Возвращает ли вызов API ожидаемый формат
LLM-судья (LLM Judge)
Используется для качественной оценки, требующей субъективного суждения:
- Тон и профессионализм ответа на электронное письмо
- Точность и полнота информации в исследовательском отчете
- Точность понимания задачи (действительно ли понято намерение пользователя)
- Обоснованность стратегии обработки пограничных случаев
Такой комбинированный подход сочетает эффективность (автоматическая проверка может быть запущена в больших масштабах) и качество (LLM-судья улавливает детали, которые трудно измерить человеку).
Матрица трехмерных показателей оценки:
┌─────────────────────────────────────────────────┐
│ Трехмерная система оценки PinchBench │
├─────────────────────────────────────────────────┤
│ Уровень успешности (Success Rate) │
│ → Комплексная оценка качества выполнения задачи │
│ → Основной критерий ранжирования │
│ → Сочетание автоматической проверки и LLM-судьи │
├─────────────────────────────────────────────────┤
│ Скорость (Speed) │
│ → Среднее время выполнения задачи (секунды/минуты)│
│ → Критически важно для сценариев с ответом в реальном времени│
│ → Включает задержку API и время инференса │
├─────────────────────────────────────────────────┤
│ Стоимость (Cost) │
│ → Стоимость токенов, затраченных на выполнение задачи (USD)│
│ → Ключевой показатель для сценариев высокочастотного использования│
│ → Помогает рассчитать ROI и принять решение о выборе модели│
└─────────────────────────────────────────────────┘
По состоянию на 13 марта 2026 года, PinchBench опубликовал следующие данные рейтинга:
- 📊 49 моделей прошли оценку, охватывая все основные коммерческие и открытые модели
- 🔄 327 записей запусков, постоянно обновляется
- 🌐 Публичный рейтинг: pinchbench.com (обновляется в реальном времени)
- 📁 Репозиторий с открытым исходным кодом: github.com/pinchbench/skill (определения задач общедоступны)
🎯 Рекомендации по использованию PinchBench: При просмотре рейтинга рекомендуется переключаться между тремя представлениями: уровень успешности, скорость и стоимость,
чтобы выбрать наиболее подходящую модель в соответствии со своими реальными потребностями (реальное время vs качество vs стоимость).
После единого подключения через APIYI apiyi.com можно удобно сравнивать фактические затраты на различные модели в рамках одного бизнес-сценария.
IV. Подробный анализ рейтинга PinchBench и руководство по выбору моделей
Текущий рейтинг Топ-5 по уровню успешности (данные от 13 марта 2026 года)
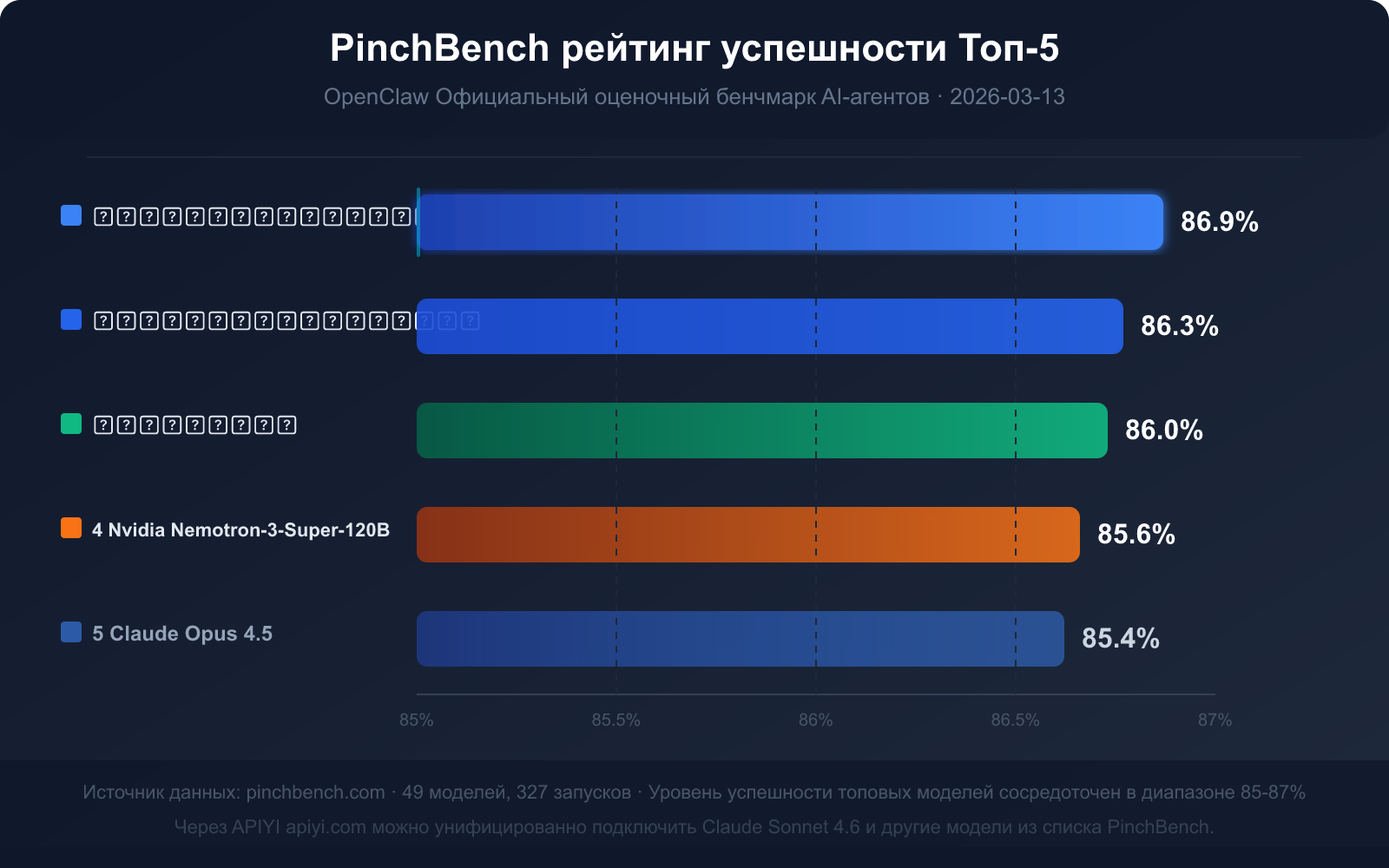
| Место | Название модели | Уровень успешности | Тип модели | Ключевые преимущества |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Коммерческая, закрытый исходный код | Самый высокий уровень успешности, баланс скорости и качества |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Коммерческая, закрытый исходный код | Самые сильные способности к сложному рассуждению |
| 🥉 3 | GPT-5.4 | 86.0% | Коммерческая, закрытый исходный код | Хорошая стабильность вызова инструментов |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Открытый исходный код, развертываемая | Лучшая производительность среди моделей с открытым исходным кодом |
| 5 | Claude Opus 4.5 | 85.4% | Коммерческая, закрытый исходный код | Флагман предыдущего поколения, все еще конкурентоспособен |
Ключевые выводы из данных: что значит 85% уровень успешности?
Уровень успешности топовых моделей на PinchBench сосредоточен в диапазоне 85%-87%, а не близок к максимальному баллу. Это число само по себе передает три важных сигнала:
Сигнал 1: Задачи AI-агентов до сих пор остаются сложной проблемой
Даже модель, занимающая первое место, Claude Sonnet 4.6 (86.9%), все еще терпит неудачу примерно в 13 из 100 задач. Это не недостаток возможностей модели, а присущая сложность реальных задач — нечеткие инструкции, неполная информация, пограничные случаи вызова инструментов — все это может привести к сбою.
Сигнал 2: Отказоустойчивый дизайн незаменим при разработке агентов
Когда 13% ошибок — это "высший уровень", полностью автоматизированные процессы агентов без узлов ручной проверки являются высокорискованными в производственной среде. Лучшая практика заключается в том, чтобы: для операций с высоким риском (например, отправка электронной почты, отправка кода) сохранять шаги ручного подтверждения.
Сигнал 3: Различия между моделями минимальны, дизайн задачи важнее
Разница между 1-м и 5-м местом составляет всего 1.5 процентных пункта (86.9% против 85.4%). Это означает, что влияние выбора модели гораздо меньше, чем то, как спроектировать промпт задачи, как определить интерфейс инструмента и как обрабатывать ошибки.
Комплексный анализ трехмерных показателей
Одного лишь уровня успешности недостаточно. Ниже представлена комплексная система оценки по трем измерениям:
| Сценарий использования | Приоритетный показатель | Второстепенный показатель | Рекомендуемое направление модели |
|---|---|---|---|
| Высокочастотные легкие задачи (классификация почты, напоминания) | Скорость + Стоимость | Уровень успешности | Легкие модели, такие как Claude Haiku 4.5 |
| Сложные инженерные задачи (рефакторинг кода, исследования) | Уровень успешности | Скорость | Claude Sonnet 4.6 / GPT-5.4 |
| Сценарии с ответом в реальном времени (мгновенный помощник) | Скорость | Уровень успешности | Модели из Топ-рейтинга по скорости |
| Приложения, чувствительные к стоимости | Стоимость | Уровень успешности | Развертываемые модели с открытым исходным кодом / Модели с низкими ценами API |
| Корпоративная безопасность и соответствие требованиям | Уровень успешности + Контролируемость | Стоимость | Модели с открытым исходным кодом, развернутые в частной инфраструктуре |
🎯 Комплексные рекомендации по выбору: Согласно данным PinchBench, Claude Sonnet 4.6 является наиболее комплексным выбором с самым высоким уровнем успешности для текущих сценариев OpenClaw.
Для высокочастотных сценариев, чувствительных к стоимости, рекомендуется сначала использовать Claude Sonnet 4.6 для определения базового уровня успешности задачи,
а затем протестировать, могут ли более легкие модели значительно снизить затраты в пределах допустимого уровня успешности.
Все эти тесты можно выполнить через единый API-интерфейс APIYI apiyi.com, без необходимости регистрировать несколько аккаунтов у разных провайдеров.
Анализ конкурентоспособности моделей с открытым исходным кодом
Nvidia Nemotron-3-Super-120B занимает 4-е место с уровнем успешности 85.6%, всего на 1.3 процентных пункта ниже, чем у лидера — это очень впечатляющий результат для модели с открытым исходным кодом.
Преимущества моделей с открытым исходным кодом:
- Суверенитет данных: Модель и данные находятся в контролируемой среде, что соответствует требованиям комплаенса.
- Структура затрат: Единовременные инвестиции в GPU, без последующих затрат на вызов API (для сценариев с большим объемом).
- Возможности кастомизации: Можно проводить дообучение (fine-tuning) для конкретных задач.
Ограничения моделей с открытым исходным кодом:
- Стоимость развертывания: Модель с 120B параметрами требует 4-8 GPU A100/H100.
- Бремя обслуживания: Обновление моделей, управление версиями требуют выделенного персонала по эксплуатации и поддержке.
- Затраты на первоначальное тестирование: Прежде чем убедиться, что модель с открытым исходным кодом подходит для вашего сценария, проверка прототипа через коммерческий API часто более экономична.
V. Практическое руководство: как настроить оптимальную модель в OpenClaw
Быстрое подключение Claude Sonnet 4.6 для OpenClaw
Ниже представлен полный пример конфигурации для подключения модели, занимающей первое место в рейтинге PinchBench, через APIYI:
Шаг 1: Получите API-ключ
Посетите официальный сайт APIYI apiyi.com, зарегистрируйте аккаунт и получите API-ключ в консоли. APIYI предоставляет совместимый с OpenAI интерфейс, а также поддерживает нативный SDK Anthropic.
Шаг 2: Настройте бэкенд модели OpenClaw
# Пример файла конфигурации OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Максимальное количество шагов выполнения
tool_timeout: 30 # Таймаут для одного вызова инструмента (секунды)
retry_on_error: true # Автоматический повтор при ошибке вызова инструмента
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Высокорисковые операции требуют ручного подтверждения
Шаг 3: Проверьте эффект конфигурации
# Тестирование соединения с использованием Anthropic SDK
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Отправка тестового запроса
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "请列举你能在 OpenClaw 中执行的 3 种任务类型"
}]
)
print(response.content[0].text)
Шаг 4: Настройка A/B-тестирования нескольких моделей
# Сравнение различных моделей на одной и той же задаче (рекомендуется перед официальным развертыванием)
models_to_test = [
"claude-sonnet-4-6", # Первое место в PinchBench
"gpt-5.4-turbo", # Третье место в PinchBench (совместимо с форматом OpenAI)
"claude-opus-4-5", # Флагман предыдущего поколения, для сравнения стоимости
]
# APIYI поддерживает унифицированный вызов API для всех вышеуказанных моделей
# base_url остается неизменным, нужно только изменить параметр model
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Успешность={result.success_rate}, Время={result.avg_time}s, Стоимость=${result.cost_per_task}")
🎯 Быстрый старт: Посетите apiyi.com и зарегистрируйтесь, чтобы получить тестовый лимит.
APIYI поддерживает унифицированный доступ к API для моделей из списка PinchBench, таких как Claude Sonnet 4.6 и GPT-5.4.
Вам не нужно отдельно запрашивать доступ у нескольких провайдеров, что значительно снижает начальный порог для тестирования моделей.
Самостоятельное тестирование вашего агента по 5 измерениям PinchBench
Перед развертыванием в производственной среде рекомендуется оценить конфигурацию вашего агента с помощью следующего контрольного списка:
Контрольный список для самотестирования агента, вдохновленный PinchBench
□ Измерение 1 — Уровень выполнения задач
Дайте агенту 10 составных задач, каждая из которых состоит из 3 или более шагов.
Запишите количество полностью успешных / частично успешных / неудачных попыток.
Цель: Полный успех ≥ 80%
□ Измерение 2 — Точность вызова инструментов
Проверьте логи вызовов инструментов, подсчитайте следующие типы ошибок:
- Ошибка выбора инструмента (выбран неверный инструмент)
- Ошибка формата параметра (неверный тип или формат параметра)
- Ошибка значения параметра (тип параметра верен, но значение нелогично)
Цель: Уровень ошибок инструментов ≤ 5%
□ Измерение 3 — Последовательность многошагового рассуждения
Разработайте длительную задачу, требующую более 15 шагов.
Наблюдайте, не происходит ли отклонение от первоначальной цели в процессе выполнения.
Цель: Отсутствие отклонения от цели в длительных задачах.
□ Измерение 4 — Сохранение контекста
Предоставьте ключевую информацию в 1-м раунде, а затем сошлитесь на нее в 8-м раунде.
Проверьте, может ли агент правильно сослаться на информацию.
Цель: Точность перекрестных ссылок ≥ 90%
□ Измерение 5 — Обнаружение галлюцинаций
Разработайте задачи, требующие ссылки на реальные данные (имена файлов/контакты/даты).
Проверьте, не придумывает ли агент несуществующие данные.
Цель: Частота галлюцинаций ≤ 2%
VI. Будущее AI Benchmark: от точечной оценки к оценке экосистемы
Тенденции развития текущей системы Benchmark
В 2026 году область AI Benchmark переживает глубокие изменения. Суть этих изменений заключается в расширении объекта оценки с отдельных моделей до полноценных систем агентов.
Традиционный подход к Benchmark заключался в том, чтобы дать модели задачу и посмотреть, правильно ли она ее решает. Но с распространением таких платформ агентов, как OpenClaw, по-настоящему важным становится вопрос: может ли модель, выступая в роли "мозга" системы, позволить этой системе выполнить работу?
Ответ на этот вопрос зависит не только от запаса знаний модели, но и от:
- Способности модели понимать описания инструментов
- Стратегии принятия решений моделью в условиях неопределенной информации
- Способности модели распознавать и исправлять ошибки
- Способности модели долгосрочно отслеживать намерения пользователя
Ценность PinchBench заключается именно в том, что он количественно оценивает и публично демонстрирует эти аспекты.

Правильное использование данных AI Benchmark
Данные Benchmark ценны, но их легко неправильно истолковать. Вот несколько распространенных заблуждений и правильных подходов:
Заблуждение 1: Считать модель с самым высоким рейтингом "безусловно лучшей"
Правильный подход: Рейтинг основан на конкретном наборе задач PinchBench, а ваши задачи могут иметь другое распределение весов. Сначала протестируйте на своих задачах, а затем выбирайте.
Заблуждение 2: Смотреть только на успешность, игнорируя скорость и стоимость
Правильный подход: Трехмерные показатели незаменимы. В сценариях пакетной обработки разница в скорости на 50% означает экономию затрат на 50%; в сценариях реального времени разница в скорости на 2 секунды означает значительное снижение удобства для пользователя.
Заблуждение 3: Считать, что разница в 1% успешности не имеет значения
Правильный подход: Разница в 1% успешности может показаться незначительной в небольших тестах, но в высокочастотных производственных сценариях это может приводить к сотням сбоев ежедневно. Необходимо оценивать фактическое влияние, исходя из объема ваших задач.
Заблуждение 4: Использовать статические данные Benchmark для долгосрочного планирования
Правильный подход: Модели ИИ развиваются чрезвычайно быстро, ведущие производители в 2026 году выпускают важные обновления в среднем раз в квартал. Рекомендуется включать оценку производительности моделей в регулярные технические обзоры, а не считать "один выбор на всю жизнь".
Лучшие практики оценки корпоративных агентов
Для технических команд, развертывающих OpenClaw или аналогичные платформы агентов в корпоративной среде, ниже представлен набор практических рекомендаций по оценке:
Шаг первый: Создайте базовый набор задач
Выберите 20-50 типичных задач из вашей реальной бизнес-деятельности, охватывающих как повседневные высокочастотные операции, так и редкие сложные сценарии. Этот набор задач должен быть определен совместно бизнес-стороной и технической стороной, чтобы избежать предвзятости оценки, вызванной чисто техническим подходом.
Шаг второй: Постоянный мониторинг трехмерных показателей
Рекомендуемая система показателей оценки корпоративных агентов
Основные показатели (еженедельная статистика):
- Уровень выполнения задач: Цель ≥ 85% (соответствует уровню топовых моделей PinchBench)
- Уровень ошибок вызова инструментов: Цель ≤ 5%
- Среднее время выполнения задачи: Определяется в соответствии с SLA бизнеса
Вспомогательные показатели (ежемесячная статистика):
- Стоимость токенов/задача: Контроль операционных расходов
- Уровень ручного вмешательства: Доля задач, требующих ручного управления
- Распределение типов ошибок: Анализ направлений для улучшения
Показатели предупреждения (мониторинг в реальном времени):
- Уровень сбоев высокорисковых операций: Немедленное оповещение при сбое отправки почты/удаления файлов и т.д.
- События галлюцинаций: Случаи выдумывания информации должны быть немедленно зафиксированы и проанализированы
Шаг третий: Регулярная переоценка моделей
Рекомендуется ежеквартально переоценивать текущие развернутые модели, а также новые кандидатные модели, используя внутренний набор задач. Сопоставляйте с последними публичными данными PinchBench, чтобы определить, требуется ли обновление или смена модели.
Шаг четвертый: Накопление знаний в предметной области
Универсальные Benchmark не могут охватить специфические сценарии каждого предприятия. По мере накопления опыта постепенно создавайте набор задач и критерии оценки, подходящие для вашего бизнеса, что станет важным инструментом для выбора поставщиков ИИ.
🎯 Рекомендации по выбору для предприятий: На начальном этапе внедрения платформы агентов рекомендуется подключать несколько моделей-кандидатов через APIYI apiyi.com с оплатой по мере использования.
Проведите 3-4 недели фактического тестирования с использованием собственного внутреннего набора задач, прежде чем принимать решение о переходе на ежемесячный тариф.
APIYI поддерживает унифицированный интерфейс для основных моделей, таких как Claude, GPT, Gemini.
На этапе тестирования не требуется отдельная регистрация аккаунтов у нескольких провайдеров, что значительно снижает затраты на управление оценкой.
Часто задаваемые вопросы
В: В чем ключевое отличие OpenClaw от AutoGPT и AutoGen?
Ключевое отличие OpenClaw заключается в способе доступа и пороге входа: он предоставляет интерфейс агента через мессенджеры (Signal, WhatsApp и т.д.), поэтому обычным пользователям не нужно устанавливать специальные приложения или разбираться в технических деталях. С точки зрения технической архитектуры, OpenClaw ближе к "личному AI-секретарю", в то время как фреймворки вроде AutoGen больше подходят для разработчиков, создающих сложные системы из нескольких агентов. OpenClaw делает акцент на "готовом к использованию потребительском опыте", а AutoGen — на "гибком фреймворке для корпоративной разработки".
🎯 Независимо от выбранного фреймворка агента, вы можете использовать APIYI (apii.com) для унифицированного доступа к бэкенд-моделям, избегая необходимости настраивать API-ключи для каждого фреймворка по отдельности.
В: Как часто обновляется рейтинг успешности PinchBench?
Рейтинг PinchBench обновляется в реальном времени — каждый раз, когда новая модель проходит оценку, данные немедленно отображаются на pinchbench.com. Поскольку крупные производители постоянно выпускают новые версии, рейтинг будет часто меняться. Рекомендуется проверять самые свежие данные перед окончательным выбором. Данные в этой статье основаны на снимке от 13 марта 2026 года (49 моделей, 327 записей запусков).
В: Как выбрать наиболее подходящую модель для OpenClaw?
Рекомендуется трехэтапный метод выбора:
- Посмотрите на процент успешности PinchBench: Отфильтруйте топ-5 моделей по проценту выполнения задач.
- Учитывайте скорость и стоимость: Отфильтруйте дальше в зависимости от типа вашей задачи (в реальном времени против пакетной обработки, высокая частота против низкой).
- Проведите реальное A/B тестирование: Сравните 2-3 модели-кандидата на ваших реальных бизнес-задачах.
Через APIYI (apii.com) вы можете быстро переключаться между различными моделями, используя один и тот же
base_url, и принять окончательное решение после завершения A/B тестирования.
В: Могут ли открытые модели полностью заменить коммерческие модели для работы OpenClaw?
Судя по данным PinchBench, разница между Nvidia Nemotron-3-Super-120B (85,6%) и топовыми коммерческими моделями (86,9%) составляет около 1,3 процентных пункта. Для большинства задач агентов эта разница приемлема. Однако стоит отметить: для самостоятельного развертывания модели с 120 миллиардами параметров требуется 4-8 высокопроизводительных GPU, а первоначальные инвестиции в оборудование и затраты на обслуживание будут значительными. Рекомендуется сначала проверить жизнеспособность дизайна агента с помощью коммерческого API, а затем оценить, стоит ли переходить на самостоятельно развернутую открытую модель.
В: Как избежать рисков безопасности при использовании OpenClaw?
Основной принцип — минимальные привилегии: предоставляйте OpenClaw только минимальный набор разрешений, необходимых для выполнения задачи. Конкретные рекомендации:
- Разрешения только на чтение почты (а не полные права на чтение, запись и удаление)
- Разрешения только на чтение репозитория кода + создание Pull Request (а не прямой пуш в основную ветку)
- Ограничение файловой системы определенной рабочей директорией (а не всей файловой системой)
- Высокорисковые операции (отправка писем, удаление файлов) должны требовать шага ручного подтверждения.
При корпоративном развертывании также необходимо настроить полные журналы аудита операций, чтобы каждая операция агента имела отслеживаемую запись.
В: В чем разница между PinchBench и другими бенчмарками агентов?
Главная особенность PinchBench — это специфичность сценария: он разработан специально для сценариев использования OpenClaw, а не для общей оценки агентов. Это означает, что его ценность для пользователей OpenClaw выше, но он не подходит для прямой оценки выбора моделей для других фреймворков агентов. Другие известные бенчмарки агентов включают AgentBench (охватывает различные среды), SWE-Bench (фокусируется на задачах с кодом) и т.д., каждый из которых имеет свою специализацию.
Заключение: OpenClaw + PinchBench устанавливают новый стандарт для эры агентов
OpenClaw, начавшись как проект выходного дня австрийского разработчика, за два месяца превратился в одну из самых популярных платформ AI-агентов в мире. Это отражает сильное стремление всей индустрии к тому, чтобы "ИИ действительно выполнял работу".
Появление PinchBench заполнило ключевой пробел в области оценки агентов: у нас наконец-то появился инструмент, специально предназначенный для измерения возможностей агентов.
Краткий обзор основных выводов:
- Claude Sonnet 4.6 — лучший комплексный выбор для сценариев OpenClaw на данный момент (86,9% успешности, первое место в PinchBench).
- Успешность топовых моделей находится в диапазоне 85-87%, задачи агентов по-прежнему сложны, и отказоустойчивый дизайн незаменим.
- Скорость и стоимость одинаково важны, модель с высокой успешностью не всегда подходит для всех сценариев, требуется комплексная трехмерная оценка.
- PinchBench представляет будущее направления оценки ИИ: реальные сценарии задач заменяют синтетические тесты.
- Разница в выборе моделей составляет около 1-2%, влияние дизайна задачи и промпт-инжиниринга зачастую значительно больше.
Для разработчиков и компаний, желающих углубиться в экосистему OpenClaw, сейчас идеальное время:
Сообщество открытого исходного кода активно, инструменты оценки совершенствуются, а стоимость доступа к API ведущих моделей продолжает снижаться. Вам не нужно ждать появления "идеального решения"; вы можете начать прямо сейчас, проверяя жизнеспособность рабочего процесса агента на небольших задачах.
🎯 Действуйте прямо сейчас: Если вы создаете рабочий процесс ИИ на базе OpenClaw, рекомендуем использовать APIYI (apii.com) для унифицированного доступа.
Платформа поддерживает ведущие модели, такие как Claude Sonnet 4.6 (первое место в PinchBench) и GPT-5.4 (третье место),
используя единый API-интерфейс, без необходимости регистрироваться у нескольких провайдеров. Поддерживается оплата по мере использования, что идеально подходит для постепенного масштабирования, начиная с небольших тестов.
Посетите официальный сайт APIYI apiyi.com, чтобы зарегистрироваться и начать работу.
Данные в этой статье основаны на общедоступной информации, собранной в марте 2026 года. Актуальные данные рейтинга PinchBench можно найти на pinchbench.com.
Автор: Команда APIYI | Для получения подробной информации о подключении к API моделей ИИ, пожалуйста, посетите APIYI apiyi.com