Nota do autor: Desvendamos o motivo real por trás das sobrecargas frequentes da API do Nano Banana Pro. Da arquitetura dos chips TPU proprietários do Google às diferenças entre o AI Studio e o Vertex AI, entenda a verdade técnica por trás da escassez de oferta.
Desde o lançamento do Nano Banana Pro em novembro de 2025, os desenvolvedores notaram algo estranho: mesmo com o Google possuindo seus próprios chips TPU, essa API de geração de imagens continua apresentando o erro de "modelo sobrecarregado". Por que os chips próprios não resolvem o problema de poder computacional? Qual a diferença real entre o AI Studio e o Vertex AI? Neste artigo, vamos mergulhar na lógica fundamental da arquitetura computacional do Google para explicar o que está acontecendo nos bastidores.
Valor principal: Através de dados reais e análise de arquitetura, vamos te ajudar a entender a raiz dos problemas de estabilidade do Nano Banana Pro e como escolher a melhor forma de integrar essa API de maneira confiável.

Problemas Centrais de Estabilidade da API do Nano Banana Pro
Desde o seu lançamento em novembro de 2025, o Nano Banana Pro (gemini-2.0-flash-preview-image-generation) tem enfrentado uma crise contínua de estabilidade. Abaixo estão os dados dos principais problemas relatados pela comunidade de desenvolvedores:
| Tipo de Problema | Frequência | Comportamento Típico | Escopo do Impacto |
|---|---|---|---|
| 503 Sobrecarga do Modelo | Alta frequência (70%+ dos erros) | Tempo de resposta dispara de 30 para 60-100 segundos | Todos os níveis de usuários (incluindo usuários pagos Tier 3) |
| 429 Esgotamento de Recursos | Aprox. 70% dos erros de API | Acionado mesmo quando está bem abaixo dos limites de cota | Usuários do nível gratuito e Tier 1 pago |
| Redução Repentina de Cota | 07 de dezembro de 2025 | Nível gratuito caiu de 3 para 2 imagens/dia; 2.5 Pro removido do nível gratuito | Usuários do nível gratuito globalmente |
| Serviço Indisponível | Intermitente | Geração em alta velocidade em um dia, totalmente indisponível no outro | Desenvolvedores de apps que dependem do nível gratuito |
A Causa Raiz dos Problemas de Estabilidade do Nano Banana Pro
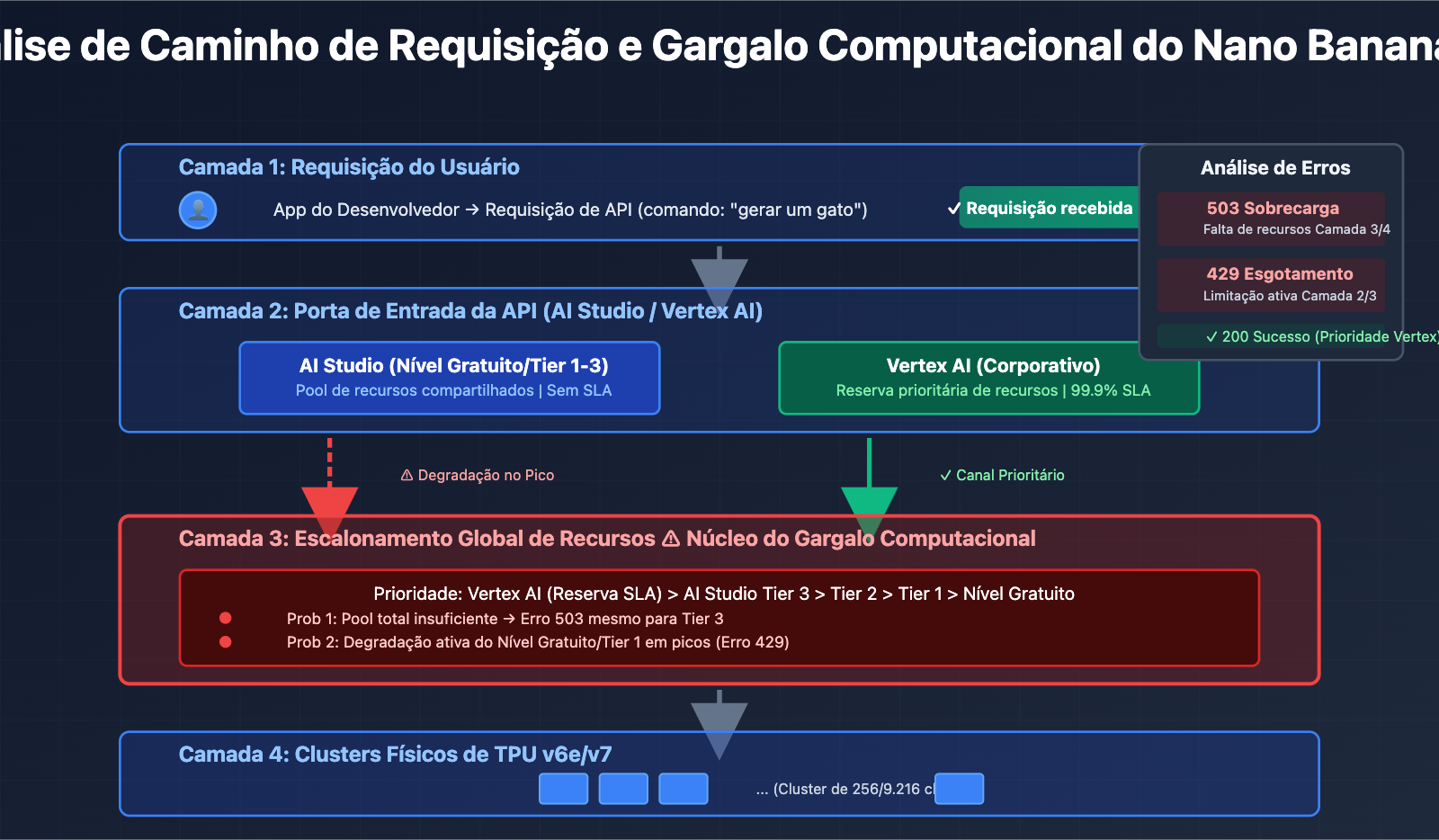
O cerne desses problemas não são falhas no código, mas sim o gargalo de capacidade computacional nos servidores do Google. Mesmo usuários do Tier 3 (o nível de cota mais alto) encontram erros de sobrecarga quando a frequência de requisições está muito abaixo dos limites oficiais, o que indica que o problema reside na infraestrutura e não na gestão de cotas dos usuários.
De acordo com respostas oficiais do Google em fóruns de desenvolvedores, os recursos de computação estão sendo redistribuídos para os novos modelos da série Gemini 2.0, resultando em capacidade limitada para modelos de geração de imagem como o Nano Banana Pro. Essa estratégia de escalonamento de recursos leva diretamente à instabilidade do serviço.
🎯 Sugestão Técnica: Ao utilizar o Nano Banana Pro em ambientes de produção, recomendamos o acesso através da plataforma APIYI (apiyi.com). A plataforma oferece mecanismos inteligentes de balanceamento de carga e failover automático, o que pode aumentar significativamente a taxa de sucesso e a estabilidade das chamadas de API.
A verdade sobre a arquitetura dos chips TPU proprietários do Google
Muita gente acha que o Google, por ter seus próprios chips TPU (Tensor Processing Unit), deveria conseguir suprir tranquilamente a demanda de processamento de modelos de IA. Mas a realidade é bem mais complexa do que parece.
A arquitetura mais recente do TPU v7 (Ironwood)
Em abril de 2025, o Google anunciou na conferência Cloud Next a sétima geração do TPU — o Ironwood, que é a versão mais potente até agora:
| Parâmetros da arquitetura | TPU v7 (Ironwood) | TPU v6e (Trillium) | Nível de melhoria |
|---|---|---|---|
| Poder computacional de pico | 4.614 TFLOP/s | aprox. 2.300 TFLOP/s | ~100% |
| Eficiência energética | Base | Referência | +100% em desempenho/watt |
| Configuração de cluster | 256 chips / 9.216 chips | Configuração única | Capacidade de expansão flexível |
| Unidade de matriz | 256×256 MXU (systolic array) | 128×128 MXU | 4x densidade de computação |
| Cenário de aplicação | Foco em Inferência (Inference-first) | Híbrido Treino+Inferência | Otimizado para desempenho de inferência |
Componentes centrais da arquitetura TPU
Cada chip TPU contém um ou mais TensorCores, e cada TensorCore é composto pelas seguintes partes:
- Unidade de Multiplicação de Matriz (MXU): O TPU v6e e o v7x utilizam um array de multiplicadores-acumuladores de 256×256, enquanto as versões anteriores eram de 128×128.
- Unidade Vetorial: Processa operações não matriciais.
- Unidade Escalar: Executa a lógica de controle.
Essa arquitetura de systolic array (array sistólico) é perfeita para inferência de redes neurais, mas também tem suas limitações.
Por que chips próprios ainda não resolvem a escassez de poder computacional?
Mesmo com o desempenho do TPU v7, os problemas de estabilidade do Nano Banana Pro persistem por três motivos principais:
1. Ciclo de aumento de produção (Ramp-up)
O TPU v7 foi lançado em abril de 2025, mas a implantação em larga escala leva tempo. O Google anunciou uma parceria de 10 bilhões de dólares com a Anthropic no final de 2025, planejando colocar online mais de 1 GW de poder computacional de IA em 2026. Isso significa que o período entre novembro de 2025 e o início de 2026 é uma fase de transição, onde a troca de arquiteturas antigas pelas novas causa escassez de recursos.
2. Crescimento explosivo da demanda
Após o lançamento da série Gemini 2.0 no final de 2025, o volume de requisições de API disparou além das previsões iniciais do Google. A enxurrada de usuários na camada gratuita (especialmente para geração de imagens no Nano Banana Pro) acabou sobrecarregando o pool de recursos dos usuários pagos.
3. Prioridade na alocação de recursos
O Google precisa equilibrar a demanda entre várias linhas de produtos de IA: Gemini 2.5 Pro (texto), Gemini 2.0 Flash (multimodal), Nano Banana Pro (geração de imagens), etc. Quando o poder computacional é limitado, modelos com maior valor comercial recebem prioridade, o que resulta diretamente nas limitações de capacidade do Nano Banana Pro.
🎯 Insight da Arquitetura: Ter chips próprios não significa poder computacional infinito. Capacidade de fabricação, construção de data centers e fornecimento de energia são fatores limitantes. Recomendamos que usuários corporativos utilizem a plataforma APIYI (apiyi.com) para obter capacidades de orquestração multi-cloud, evitando riscos de falta de capacidade de um único fornecedor.
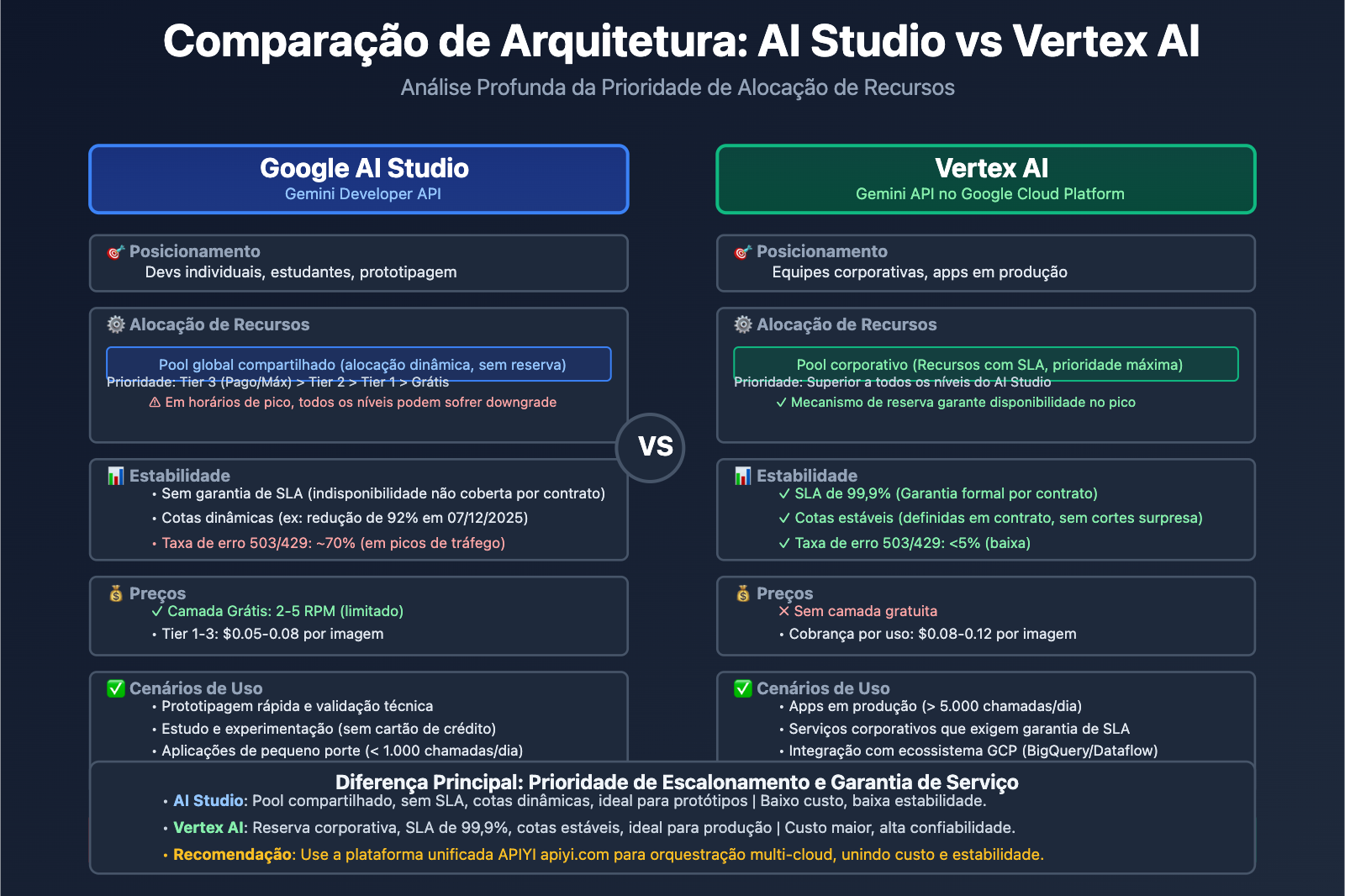
AI Studio vs Vertex AI: As diferenças fundamentais entre as duas plataformas
Muitos desenvolvedores ficam confusos: tanto o Gemini AI Studio quanto o Vertex AI permitem acessar os modelos Gemini, então por que a estabilidade e as cotas são tão diferentes? A resposta está no posicionamento arquitetural de cada um.
Comparação de posicionamento das plataformas
| Dimensão | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API no GCP) |
|---|---|---|
| Público-alvo | Devs individuais, estudantes, startups | Equipes corporativas, apps em produção |
| Requisitos | Basta uma chave de API para começar em minutos | Exige conta no Google Cloud e faturamento |
| Modelo de preços | Camada grátis (com limites) + Pago (Tier 1/2/3) | Pago por uso (sem camada grátis), integrado ao GCP |
| Garantia de SLA | Sem SLA (Acordo de Nível de Serviço) | SLA corporativo, 99,9% de disponibilidade |
| Escopo de funções | API de modelos + Ferramenta de prototipagem | Workflow de ML completo (Treino, Fine-tuning, MLOps) |
| Estabilidade de cotas | Cotas dinâmicas, afetadas pelo tráfego global | Reserva de cotas corporativas, prioridade máxima |
Vantagens e limitações do AI Studio
Vantagens:
- Início rápido: Você consegue sua chave de API na hora, sem configurar serviços de nuvem complexos.
- Ferramentas visuais: Interface embutida para testar comandos (prompts) e iterar rápido.
- Amigável para quem não quer gastar: Ótimo para aprendizado, experimentos e projetos pequenos.
Limitações:
- Sem garantia de SLA: A disponibilidade do serviço não é garantida por contrato.
- Cotas instáveis: Como no corte repentino de dezembro de 2025, onde o Gemini 2.5 Pro saiu da camada gratuita e o limite do 2.5 Flash caiu de 250 para 20 requisições diárias (uma queda de 92%).
- Falta recursos corporativos: Não integra nativamente com BigQuery, Dataflow e outros serviços do GCP.
Capacidades corporativas do Vertex AI
Vantagens principais:
- Prioridade de recursos: As requisições de usuários pagos têm prioridade máxima nos sistemas de escalonamento do Google.
- Integração MLOps: Suporte para treinamento, gestão de versões, testes A/B e monitoramento.
- Soberania de dados: Você escolhe a região de armazenamento dos dados, atendendo a normas como LGPD e GDPR.
- Suporte especializado: Acesso a times técnicos e consultoria de arquitetura.
Cenários recomendados:
- Aplicações em produção com mais de 10.000 chamadas diárias.
- Necessidade de ajuste fino (fine-tuning) e treinamento personalizado.
- Empresas que exigem SLAs rígidos de disponibilidade e tempo de resposta.
🎯 Dica de escolha: Se o seu app já passou da fase de protótipo e tem mais de 5.000 chamadas por dia, é hora de migrar para o Vertex AI ou usar uma plataforma unificada como a APIYI (apiyi.com). Ela integra recursos de vários provedores de nuvem em uma única interface, mantendo a facilidade do AI Studio com a estabilidade do Vertex AI.
As razões profundas por trás da escassez do Nano Banana Pro
Com base nas análises anteriores, os motivos pelos quais o Nano Banana Pro continua com baixa disponibilidade podem ser resumidos em três níveis principais:
1. Nível Técnico: Desequilíbrio entre a capacidade de produção de chips e a demanda
- Ramp-up da produção do TPU v7: Lançado em abril de 2025, a implementação em larga escala só deve ser concluída em 2026.
- Prioridade para treinamento em vez de inferência: As tarefas de treinamento da série Gemini 3.0 estão consumindo uma quantidade enorme de recursos de TPU v6e e v7.
- Geração de imagens é computacionalmente intensiva: A inferência do Modelo de Difusão (Diffusion Model) do Nano Banana Pro exige de 5 a 10 vezes mais poder computacional do que os modelos de texto.
2. Nível de Negócios: Ajustes na estratégia do plano gratuito
| Momento | Mudança de Política | Motivo por trás |
|---|---|---|
| Novembro de 2025 | Lançamento do Nano Banana Pro, nível gratuito com 3 imagens/dia | Obter feedback rápido dos usuários e estabelecer posição no mercado |
| 7 de dezembro de 2025 | Nível gratuito reduzido para 2 imagens/dia, Gemini 2.5 Pro removido do plano gratuito | Custos de computação acima do orçamento, necessidade de controlar o crescimento de usuários gratuitos |
| Janeiro de 2026 | RPM do nível gratuito reduzido de 10 para 5 | Reservar recursos para clientes corporativos do Gemini 2.0 Flash |
O Google declarou explicitamente em fóruns oficiais que esses ajustes visam "garantir uma qualidade de serviço sustentável". Na verdade, o aumento explosivo de usuários no nível gratuito (especialmente ferramentas de automação e chamadas em lote) fez com que os custos saíssem do controle, forçando o Google a apertar as regras.
3. Nível de Arquitetura: Isolamento de recursos entre AI Studio e Vertex AI
Embora ambas as plataformas chamem o mesmo modelo subjacente, elas possuem prioridades diferentes no escalonamento de recursos internos do Google:
- Vertex AI: Conectado diretamente ao pool de computação de nível empresarial do GCP, desfrutando de reserva de recursos com garantia de SLA.
- AI Studio: Compartilha um pool de recursos global e sofre downgrade (redução de prioridade) em horários de pico.
Esse design de arquitetura faz com que os usuários do nível gratuito e do Tier 1 do AI Studio encontrem erros 429/503 com mais frequência, enquanto os usuários pagos do Vertex AI são menos afetados.
4. Estratégia de Produto: De "conquistar o mercado" a "otimizar a lucratividade"
No início do Nano Banana Pro, o Google adotou uma estratégia agressiva de gratuidade para competir com nomes como DALL-E 3 e Midjourney. No entanto, com o crescimento explosivo da base de usuários, o Google percebeu que o modelo de negócios do nível gratuito era insustentável e começou a priorizar recursos para "usuários pagos de alto valor".
O evento marcante dessa transição foi o corte de cotas e a remoção do plano gratuito do 2.5 Pro em dezembro de 2025, que a comunidade de desenvolvedores apelidou de "Free Tier Fiasco" (O Fiasco do Nível Gratuito).
🎯 Estratégia de Resposta: Para aplicações em produção que dependem do Nano Banana Pro, recomendamos adotar uma estratégia de backup multi-cloud. Através da plataforma APIYI (apiyi.com), você pode configurar regras de alternância automática entre vários modelos como Nano Banana Pro, DALL-E 3 e Stable Diffusion em uma única interface. Quando um serviço estiver sobrecarregado, ele muda automaticamente para a alternativa, garantindo a continuidade do seu negócio.
Como desenvolvedores podem lidar com a instabilidade do Nano Banana Pro
Com base na análise anterior, aqui estão quatro soluções técnicas comprovadas:
Solução 1: Implementar um mecanismo de retentativa com backoff exponencial
import time
import random
def call_nano_banana_with_retry(comando, max_retries=5):
"""Utiliza estratégia de backoff exponencial para chamar a API do Nano Banana Pro"""
for attempt in range(max_retries):
try:
response = call_api(comando) # Sua função real de chamada de API
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Erro de sobrecarga encontrado, tentando novamente em {wait_time:.2f} segundos...")
time.sleep(wait_time)
else:
raise e
raise Exception("Número máximo de tentativas atingido")
Ideia central: Quando encontrar erros 503/429, o tempo de espera aumenta exponencialmente (1s → 2s → 4s → 8s), evitando um efeito cascata de falhas.
Implementação completa de nível de produção (clique para expandir)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, comando: str, **kwargs) -> Optional[Dict[str, Any]]:
"""Método de geração de imagem de nível de produção com tratamento de erro e monitoramento"""
for attempt in range(self.max_retries):
try:
# Lógica real de chamada da API
response = self._call_api(comando, **kwargs)
logger.info(f"Requisição bem-sucedida (Tentativa {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"Erro {error_code}: {str(e)[:100]} | "
f"Aguardando {wait_time:.2f}s (Tentativa {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"Número máximo de tentativas atingido, falha final: {str(e)}")
raise
else:
logger.error(f"Erro não passível de retentativa: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""Calcula o tempo de backoff exponencial com jitter para evitar retentativas síncronas"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # Espera máxima de 60 segundos
def _parse_error_code(self, error: Exception) -> int:
"""Extrai o código de status HTTP da exceção"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, comando: str, **kwargs) -> Dict[str, Any]:
"""Lógica real de chamada da API (precisa ser substituída pela implementação real)"""
# Coloque aqui o seu código de chamada de API real
pass
# Exemplo de uso
client = NanoBananaClient(api_key="sua_chave_api")
result = client.generate_image("um gato fofo tocando piano")
Solução 2: Controle de intervalo entre requisições
De acordo com o feedback da comunidade de desenvolvedores, adicionar um atraso fixo de 5 a 10 segundos entre as requisições pode reduzir significativamente a taxa de erro 503:
import time
def batch_generate_images(comandos):
"""Geração de imagens em lote com controle rigoroso de frequência"""
results = []
for i, comando in enumerate(comandos):
result = call_api(comando)
results.append(result)
if i < len(comandos) - 1: # A última requisição não precisa esperar
time.sleep(7) # Intervalo fixo de 7 segundos
return results
Cenário ideal: Aplicações que não são em tempo real, como geração de conteúdo em lote, processamento de dados offline, etc.
Solução 3: Estratégia de backup multi-cloud
Implemente o failover automático através de uma plataforma de API unificada:
| Passo | Implementação Técnica | Resultado Esperado |
|---|---|---|
| 1. Configurar modelos principal e reserva | Nano Banana Pro (Principal) + DALL-E 3 (Reserva) | Tolerância a falha de ponto único |
| 2. Definir regras de alternância | 3 erros 503 consecutivos → Muda automaticamente para reserva | Redução da latência percebida pelo usuário |
| 3. Monitorar status de recuperação | Sondar saúde do serviço principal a cada 5 minutos | Recuperação automática para o serviço principal |
🎯 Implementação Recomendada: A plataforma APIYI (apiyi.com) suporta nativamente essa estratégia de escalonamento multi-cloud. Você só precisa configurar as regras no painel de controle e o sistema cuidará automaticamente da detecção de falhas, alternância de tráfego e otimização de custos, sem a necessidade de modificar o código da sua aplicação.
Solução 4: Upgrade para Vertex AI ou plataformas empresariais
Se a sua aplicação se enquadra em qualquer um dos critérios abaixo, recomendamos considerar o upgrade:
- Volume médio de chamadas de API por dia > 5.000
- Requisitos rígidos de SLA para tempo de resposta (ex: 95º percentil < 10 segundos)
- Incapacidade de aceitar interrupções de serviço (ex: geração de imagens para e-commerce, moderação de conteúdo em tempo real)
Comparação de custos:
AI Studio Tier 1: $0.05/imagem (mas sobrecarrega com frequência)
Vertex AI: $0.08/imagem (estável, com SLA)
Plataforma APIYI: $0.06/imagem (escalonamento multi-cloud, tolerância a falhas automática)
Embora o preço unitário do Vertex AI seja mais alto, considerando o custo das retentativas, o tempo de desenvolvimento e as perdas de negócio, o TCO real (Custo Total de Propriedade) pode ser menor.
Perguntas Frequentes (FAQ)
Q1: Por que usuários pagos também encontram o erro de "modelo sobrecarregado"?
A: O gargalo de capacidade do Nano Banana Pro ocorre na camada de escalonamento de computação global do Google, e não na camada de cota do usuário. Mesmo que você seja um usuário pago Tier 3, ainda poderá receber um erro 503 quando o pool de processamento global estiver saturado. Isso é diferente do tradicional erro 429 de excesso de cota.
A diferença é:
- Erro 429: Sua cota pessoal esgotou (como o limite de RPM).
- Erro 503: Falta de poder computacional no lado do servidor do Google, independentemente da sua cota.
Q2: O AI Studio e o Vertex AI utilizam o mesmo modelo?
A: Sim, o modelo Nano Banana Pro subjacente (gemini-2.0-flash-preview-image-generation) chamado por ambos é exatamente o mesmo. No entanto, eles possuem prioridades de escalonamento de recursos diferentes:
- Vertex AI: Garantia de SLA de nível empresarial, com prioridade na alocação de poder computacional.
- AI Studio: Pool de recursos compartilhados, que pode sofrer degradação durante horários de pico.
Isso é semelhante à diferença entre "pay-as-you-go" e "instâncias reservadas" em servidores de nuvem.
Q3: O Google continuará reduzindo as cotas do nível gratuito?
A: Com base nas tendências históricas, o Google pode continuar ajustando suas políticas para o nível gratuito:
- Novembro de 2025: Nível gratuito passa para 3 imagens/dia.
- 7 de dezembro de 2025: Redução para 2 imagens/dia, remoção do 2.5 Pro.
- Janeiro de 2026: RPM reduzido de 10 para 5.
A declaração oficial do Google é "garantir a qualidade de serviço sustentável", mas, na prática, eles estão buscando um equilíbrio entre controle de custos e crescimento de usuários. Recomendamos que aplicações em produção não dependam do nível gratuito e planejem planos pagos ou backups multi-cloud com antecedência.
Q4: Quando a estabilidade do Nano Banana Pro vai melhorar?
A: De acordo com informações públicas do Google, os marcos temporais críticos são em meados de 2026:
- Q2 de 2026: Conclusão da implantação em larga escala do TPU v7 (Ironwood).
- Q3 de 2026: Entrada em operação de 1 GW de poder computacional em colaboração com a Anthropic.
Nesse momento, a oferta de processamento aumentará significativamente, mas a demanda também pode crescer simultaneamente. Uma estimativa conservadora é que a estabilidade terá uma melhoria substancial no segundo semestre de 2026.
Q5: Como escolher a forma de acesso ao Nano Banana Pro?
A: Escolha de acordo com a fase da sua aplicação:
| Fase | Solução Recomendada | Motivo |
|---|---|---|
| Desenvolvimento de Protótipo | Nível gratuito do AI Studio | Menor custo, validação rápida de ideias |
| Lançamento em Pequena Escala | AI Studio Tier 1 + Mecanismo de reatentativa | Equilíbrio entre custo e estabilidade |
| Ambiente de Produção | Vertex AI ou plataforma APIYI | Garantia de SLA, suporte empresarial |
| Negócios Críticos | Estratégia de backup multi-cloud (ex: APIYI) | Máxima disponibilidade, failover automático |
🎯 Sugestão de Decisão: Se você não tem certeza de qual escolher, recomendamos realizar testes A/B através da plataforma APIYI (apiyi.com). A plataforma permite comparar o desempenho real de modelos como Nano Banana Pro (AI Studio), Nano Banana Pro (Vertex AI) e DALL-E 3 sob a mesma requisição, ajudando você a decidir com base em dados reais.
Resumo: Encarando com racionalidade os desafios de processamento do Nano Banana Pro
Os problemas de estabilidade do Nano Banana Pro não são eventos isolados, mas um reflexo da contradição entre oferta e demanda de poder computacional que toda a indústria de IA enfrenta:
Contradições Centrais:
- Lado da Demanda: Crescimento explosivo de aplicações de IA generativa, especialmente na área de geração de imagens.
- Lado da Oferta: Aumento lento da capacidade de produção de chips e longo ciclo de construção de data centers (12 a 18 meses).
- Modelo Econômico: A estratégia de nível gratuito é insustentável, mas a taxa de conversão para planos pagos ainda é baixa.
Três Verdades Técnicas:
-
TPU Próprio ≠ Poder Computacional Infinito: Embora o Google possua chips avançados como o TPU v7, o aumento da produção, o fornecimento de energia e a construção de data centers levam tempo. 2026 será o ponto de virada crucial.
-
A Essência do AI Studio vs Vertex AI: Não se trata apenas de uma relação entre "versão gratuita" e "versão paga", mas sim de diferentes prioridades de escalonamento de recursos. Por trás do SLA empresarial do Vertex AI, existe um mecanismo independente de reserva de processamento.
-
A Escassez será Longa: Com o lançamento de modelos de nova geração como Gemini 3.0 e GPT-5, a demanda por processamento continuará crescendo. No curto prazo (2026-2027), a situação de aperto entre oferta e demanda não mudará fundamentalmente.
Conselhos Práticos:
- Curto Prazo: Adote meios de engenharia como mecanismos de reatentativa e controle de intervalo de requisições para mitigar o problema.
- Médio Prazo: Avalie o ROI de migrar para o Vertex AI ou para plataformas multi-cloud.
- Longo Prazo: Fique atento ao progresso da expansão de capacidade do Google em meados de 2026 e ajuste sua estratégia oportunamente.
Para aplicações de nível empresarial, recomendamos fortemente a adoção de uma estratégia de backup multi-cloud para evitar riscos de capacidade de um único fornecedor. Através de uma plataforma unificada como a APIYI (apiyi.com), você pode obter recursos de escalonamento entre nuvens, failover automático e otimização de custos sem aumentar a complexidade do seu código.
Reflexão Final: Os desafios do Nano Banana Pro nos lembram que a estabilidade de uma aplicação de IA não depende apenas da capacidade do modelo, mas também da maturidade da infraestrutura subjacente. Nesta era onde o poder computacional é rei, a robustez do design de arquitetura e a diversificação de fornecedores estão se tornando a chave para a competitividade do produto.
Leituras Relacionadas:
- Guia de Uso da API do Nano Banana Pro
- Análise Profunda da Arquitetura Google TPU v7
- Como escolher uma API de Geração de Imagens por IA: Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 10 Melhores Práticas para chamadas de API de IA em ambiente de produção