Muitas equipes que integram a Gemini API para serviços de reconhecimento de imagem já se depararam com a mesma dúvida: ao enviar a mesma imagem e o mesmo comando na versão web (gemini.google.com), o modelo identifica detalhes com precisão e fornece respostas estruturadas; mas, ao fazer o mesmo via API gemini-1.5-flash, o resultado é visivelmente inferior, chegando a omitir informações cruciais. Essa diferença de percepção entre "web poderosa" e "API fraca" não significa que o modelo foi enfraquecido, mas sim que você está vendo a lacuna de engenharia entre a interface web e a API.
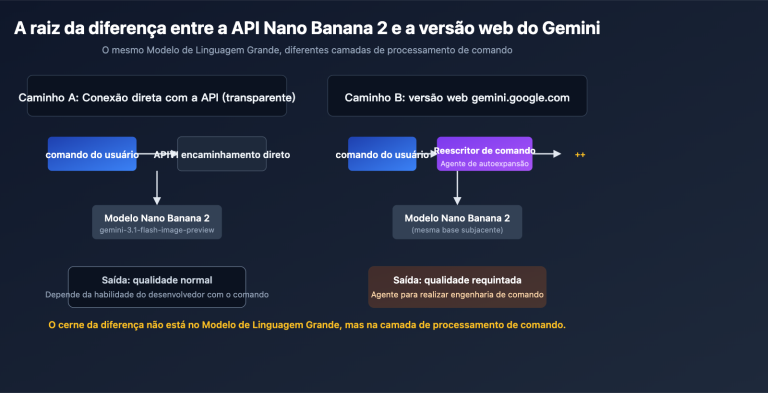
Este artigo foca em uma conclusão central: o Gemini na web é um Agente abrangente que realiza automaticamente a otimização de comandos, raciocínio em várias etapas, chamada de ferramentas e verificação de resultados; enquanto a chamada de API utiliza o modelo "puro", onde o que você envia é exatamente o que você recebe. Ao entender essa diferença, 6 técnicas de melhoria de API que vão além de apenas "ajustar o comando" permitirão que seus resultados de reconhecimento de imagem alcancem a estabilidade da versão oficial.
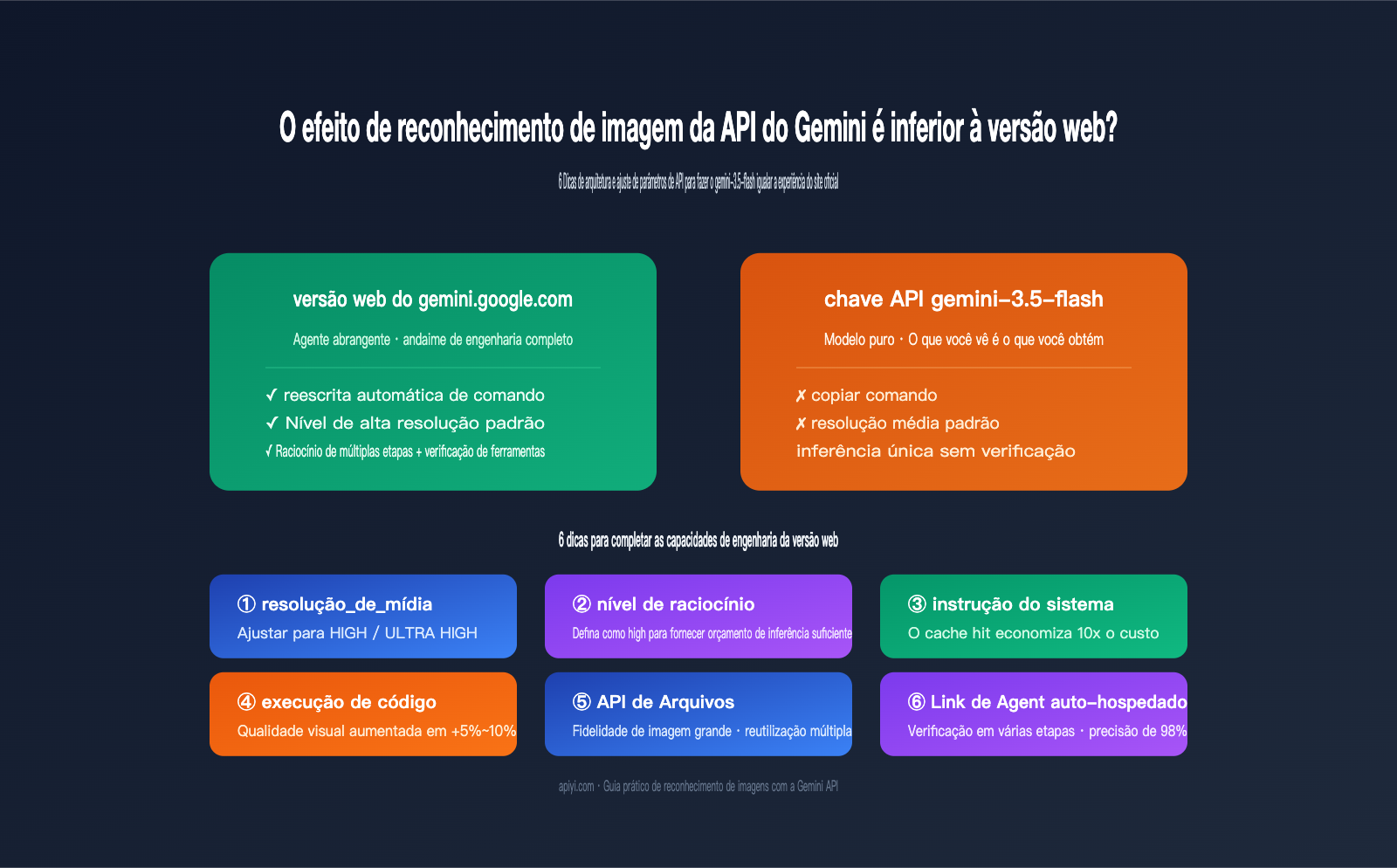
Por que o reconhecimento de imagem da Gemini API é inferior à versão web: A lacuna entre Agente e modelo puro
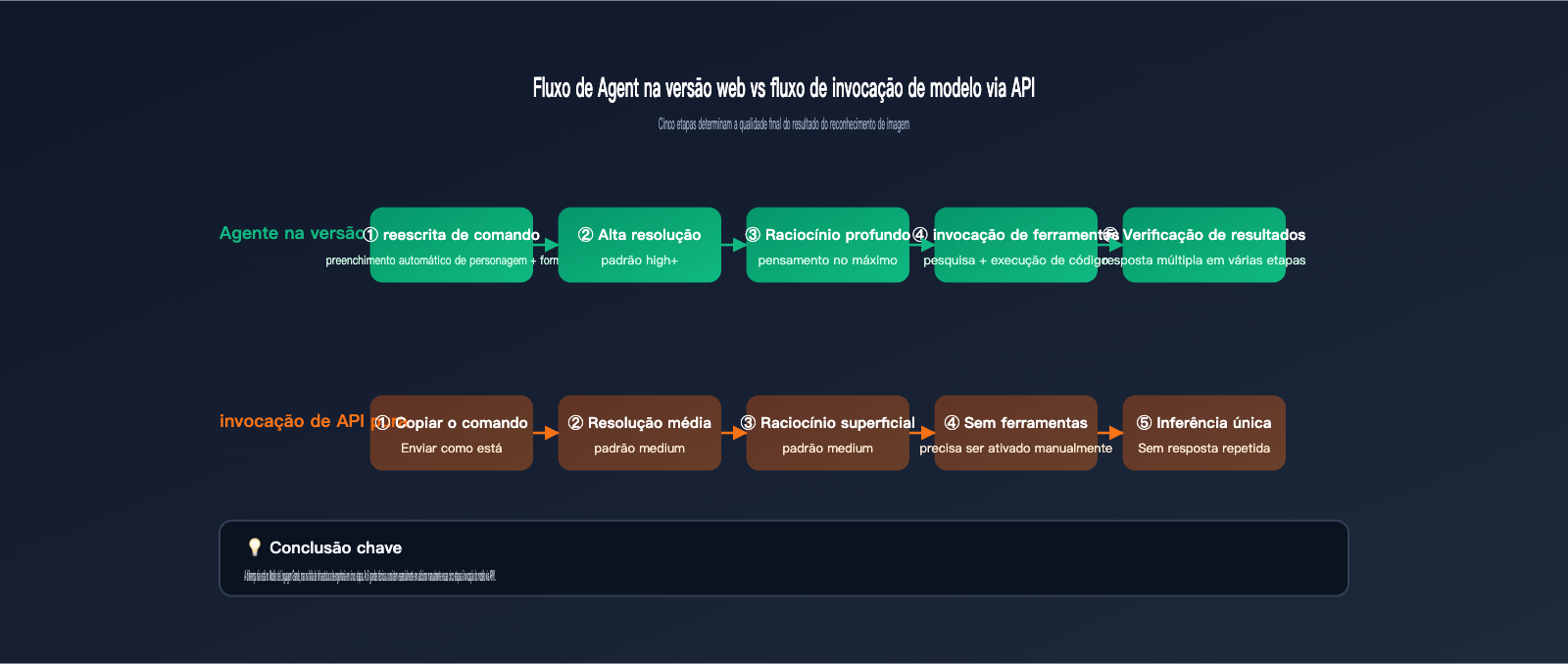
Para explicar essa diferença, primeiro precisamos entender o quanto o gemini.google.com faz por você desde o momento em que você envia uma imagem até obter a resposta final. Com base na documentação oficial de Agentes de Visão do Google e nas diferenças de resposta que observamos na APIYI (apiyi.com) entre o site oficial e a API, a versão web é essencialmente um Agente de nível de produto construído em torno do modelo base. Ele realiza pelo menos 5 tarefas que você não solicitou explicitamente:
- Reescreve automaticamente seu comando, complementando-o com papéis, tarefas e formatos de saída.
- Processa a imagem internamente com uma resolução mais alta, garantindo que os detalhes não sejam comprimidos em pixels borrados.
- Ativa por padrão um orçamento de raciocínio de alta intensidade (similar a
thinking_level=high), dando ao modelo tempo para "pensar". - Invoca ferramentas integradas, como execução de código ou pesquisa na web, quando necessário, para realizar verificações cruzadas e confirmar a veracidade dos detalhes.
- Formata os resultados de saída e realiza julgamentos de "re-resposta", perguntando ao modelo novamente caso a resposta seja ambígua.
Ao chamar a API diretamente, nenhuma dessas 5 coisas acontece automaticamente. Em outras palavras, você está chamando um "modelo" completo, mas perdeu todo o "andaime de engenharia". A tabela abaixo detalha as diferenças entre as duas formas de uso nos links críticos:
| Dimensão de comparação | Versão web gemini.google.com | API gemini-1.5-flash |
|---|---|---|
| Processamento de comando | Reescrita automática, preenchimento de papel e formato | Segue exatamente a entrada do usuário |
| Resolução de imagem | Nível alto por padrão | Nível médio por padrão, requer ajuste manual |
| Orçamento de raciocínio | Alta intensidade, sem limite explícito | Médio por padrão, pode definir thinking_level manualmente |
| Chamada de ferramentas | Acesso a pesquisa e execução de código por padrão | Desativado por padrão, requer ativação explícita |
| Verificação de resultados | Verificação em várias etapas do Agente | Inferência única, sem verificação |
| Transparência de cobrança | Coberto pelo plano mensal | Cobrado separadamente por Token |
Recomendamos executar a mesma imagem e comando em um gateway de agregação como a APIYI (apiyi.com) e comparar os resultados de reconhecimento de imagem da API gemini-1.5-flash, Claude Opus e GPT-4o. Isso permite determinar rapidamente se a tarefa atual está sendo limitada pela capacidade do modelo ou pela cadeia de engenharia.
Dica de reconhecimento de imagem da API Gemini 1: Aumente o parâmetro media_resolution
A série Gemini 3 introduziu o parâmetro media_resolution, que controla diretamente quantos tokens a API aloca para "olhar" para uma imagem. Este parâmetro possui quatro níveis: low, medium, high e ultra high, sendo o padrão geralmente o medium. Para imagens com muitos detalhes, como letras pequenas, recibos, diagramas de circuitos ou capturas de tela de interfaces (UI), o nível medium muitas vezes não é suficiente; o modelo acaba comprimindo a imagem em um mapa de características grosseiro, resultando na perda de detalhes.
A tabela abaixo mostra as diferenças reais entre os quatro níveis para ajudar você a escolher de acordo com o tipo de tarefa:
| Nível de Resolução | Custo de Token | Cenário de Uso | Problema Típico |
|---|---|---|---|
| low | Mínimo | Miniaturas, reconhecimento de Logo | Letras pequenas quase invisíveis |
| medium (padrão) | Médio | Fotos comuns, retratos | Detalhes borrados |
| high | Alto | Documentos, tabelas, recibos | Informações legíveis |
| ultra high | Máximo | Diagramas complexos, UI densa | Próximo ao reconhecimento do site oficial |
Para tarefas de reconhecimento de imagem, ajustar este parâmetro de medium para high geralmente eleva a precisão do reconhecimento imediatamente. Se o seu orçamento permitir e a tarefa envolver letras pequenas ou tabelas densas, usar ultra high também é uma escolha sensata.
# Chamada do gemini-3.5-flash via APIYI, especificando a resolução de mídia como high
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Extraia todo o texto visível da imagem e formate como uma tabela"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
Ao realizar chamadas através da APIYI (apiyi.com), os parâmetros são passados diretamente para a camada inferior sem serem reempacotados pelo gateway, então você pode definir os valores conforme a documentação oficial sem preocupações.
Dica de reconhecimento de imagem da API Gemini 2: Ative explicitamente thinking_level=high
O Gemini 3.5 Flash introduziu o parâmetro thinking_level, que controla a profundidade do raciocínio interno do modelo antes de gerar uma resposta. Em tarefas de reconhecimento de imagem, "pensar por mais tempo" e "pensar com mais cuidado" é o que separa a capacidade de ver detalhes da falha. O nível padrão da API é focado em velocidade em vez de qualidade; para reconhecimento de imagem, recomenda-se definir como high, permitindo que o modelo tenha tempo suficiente para realizar raciocínio espacial e contagem, assim como na versão web.
| thinking_level | Cenário Recomendado | Diferença Percebida |
|---|---|---|
| low | Conversas simples, julgamento de estilo | Rápido, reconhecimento bruto |
| medium | Perguntas e respostas comuns | Nível médio |
| high (recomendado) | Documentos, recibos, contagem, raciocínio espacial | Sensação próxima à versão web |
A documentação oficial destaca um ponto contraintuitivo: após usar thinking_level=high, você deve escrever comandos mais diretos e concisos, evitando aqueles velhos truques de "pense passo a passo" ou "considere todas as situações". Esses truques eram para compensar limitações de modelos antigos; na série Gemini 3, isso pode levá-lo a "analisar demais".
🎯 Dica de seleção de parâmetros: Defina
media_resolution=HIGHethinking_level=highcomo a combinação padrão para suas tarefas de reconhecimento de imagem e salve-as em seus modelos de chamada na APIYI (apiyi.com). Ajuste posteriormente para ultra high ou low conforme a necessidade do seu negócio, evitando testar parâmetros repetidamente em cada requisição.
Dica de visão da API Gemini 3: coloque o comando no system_instruction em vez do user prompt
Um erro comum ao usar a API é colocar tudo no user prompt: definição de persona, instruções da tarefa, formato de saída e a pergunta do usuário, tudo misturado em um único bloco de texto. Essa abordagem força o Modelo de Linguagem Grande a reler todo o contexto a cada vez, enquanto o "comando do sistema" na versão web é armazenado em cache e reutilizado.
A forma correta é colocar suas "instruções estáveis" dentro do system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Você é um assistente de análise de imagem rigoroso."
"Ao responder, cite apenas detalhes claramente visíveis na imagem, sem suposições."
"Forneça uma saída em JSON estruturado, com os campos fixos: entities/attributes/text."
)
)
Isso traz dois benefícios: o modelo responde seguindo regras consistentes, tornando o resultado mais estável; e, com o System Prompt Caching ativado, o custo de entrada pode cair até 10 vezes, o que é extremamente valioso para operações de processamento de imagem em lote de longa duração. No painel da APIYI (apiyi.com), você pode visualizar a taxa de acerto do cache por ID de modelo, facilitando o monitoramento da otimização.
Dica de visão da API Gemini 4: ative a execução de código para o modelo "ampliar a imagem"
O Google forneceu um dado claro no anúncio do Agentic Vision para o Gemini 3 Flash: ao ativar a ferramenta de execução de código sobre o modelo nativo, tarefas de visão obtêm um ganho de qualidade de 5% a 10%. O princípio é que o modelo pode gerar código Python internamente para recortar, ampliar, rotacionar ou ler pixels da imagem, alimentando-se novamente com a subimagem processada para análise. É exatamente isso que a versão web faz por padrão.
A API não ativa a execução de código por padrão, sendo necessário declará-la explicitamente:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Conte todos os botões vermelhos na imagem e liste suas posições"],
config=config
)
Para tarefas como contagem, raciocínio espacial e análise densa de UI — reconhecidas oficialmente como pontos fortes da execução de código — esta é a otimização com melhor custo-benefício. Na APIYI (apiyi.com), observamos que a latência geral aumenta ligeiramente após a ativação da execução de código; portanto, recomendamos ativá-la por padrão em processos assíncronos e conforme a necessidade em processos síncronos.
Dicas de API do Gemini 5: Use a File API para imagens grandes, não base64 inline
Para imagens com mais de alguns MBs, muitas equipes incorporam a imagem diretamente no corpo da requisição usando base64. Essa abordagem funciona bem para arquivos pequenos, mas quando o tamanho total da requisição ultrapassa 20 MB, os limites do Gemini são atingidos. Isso faz com que algumas imagens sejam compactadas silenciosamente, o que, naturalmente, reduz a qualidade da identificação.
Os limites definidos oficialmente são bem claros:
| Tamanho da imagem | Método de transmissão recomendado | Motivo |
|---|---|---|
| Menor que 5 MB | base64 inline | Requisição leve, chamada simples |
| 5~20 MB | Upload via File API | Evita o aumento do volume da requisição |
| Maior que 20 MB | Obrigatório File API | A codificação base64 corrompe a requisição |
| Reutilização múltipla | File API recomendado | Um upload, múltiplas referências, economiza Tokens |
Outra vantagem da File API é que a mesma imagem pode ser reutilizada em várias requisições, eliminando o custo de uploads repetidos. Ao utilizar o gateway da APIYI (apiyi.com), o endpoint da File API utiliza o mesmo conjunto de credenciais, sem a necessidade de abrir uma conta separada no Google Cloud apenas para o upload de imagens.

Dica 6 da API Gemini para Visão Computacional: Monte seu próprio fluxo de Agente para verificação em várias etapas
Depois de seguir as 5 dicas anteriores, suas chamadas de API individuais já devem estar bem próximas da experiência da interface web oficial. Mas a versão web tem um "truque de mestre": a verificação em várias etapas. Ela gera a resposta e, em seguida, realiza um segundo raciocínio para validar fatos cruciais, fazendo uma "reescrita" caso encontre algo incerto. Essa capacidade não tem um botão pronto na API, então você precisa montar um fluxo de Agente simples.
Um fluxo mínimo de duas etapas seria:
- Primeira chamada: peça ao
gemini-3.5-flashpara gerar um resultado de reconhecimento estruturado (saída JSON). - Segunda chamada: envie o resultado da primeira etapa junto com a imagem original e pergunte ao modelo: "Com base nesta imagem, as conclusões a seguir estão todas corretas?"
Se a segunda chamada identificar qualquer campo "incorreto", você dispara uma terceira chamada de "reescrita". Esse fluxo pode ser encadeado diretamente no APIYI (apiyi.com) usando a mesma base_url e chave API, sem precisar de serviços extras. Para negócios que exigem alta precisão (reconhecimento de contratos, anotação assistida de imagens médicas, revisão de conformidade de segurança), a verificação em várias etapas é o passo fundamental para elevar a precisão de 90% para 98%.
| Tipo de Tarefa | Fluxo Sugerido | Parâmetros de Etapa Única |
|---|---|---|
| Perguntas e respostas gerais | Etapa única | high + thinking_high |
| Extração de documentos | Etapa única + validação JSON | ultra high + thinking_high |
| Contagem complexa | Duas etapas + execução de código | high + thinking_high + tools |
| Negócios de alta precisão | Fluxo de três etapas (reconhecimento → validação → reescrita) | ultra high + thinking_high + tools |
Modelo de parâmetros prático: encadeie as 6 dicas em uma chamada reutilizável
Para facilitar a aplicação, aqui está um "modelo padrão para tarefas de reconhecimento de imagem" que já integra as 6 dicas anteriores, servindo como um ótimo ponto de partida para a maioria dos casos:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Você é um assistente de análise de imagem rigoroso. Cite apenas o que está claramente visível na imagem, "
"não faça suposições. Saída em JSON estrito, com os campos entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Reconheça esta imagem seguindo os requisitos do SYSTEM"],
config=config
)
print(resp.text)
Ao implementar, sugerimos extrair o modelo para uma camada de chamada de SDK unificada no APIYI (apiyi.com). Assim, a equipe de negócios apenas envia a imagem e a pergunta, enquanto os parâmetros são injetados uniformemente pelo gateway, evitando que cada projeto precise lidar com os mesmos problemas repetidamente.

FAQ: Perguntas frequentes sobre a diferença entre a API do Gemini e a versão web
P1: Após ativar todos esses parâmetros, a API ainda será inferior à versão web?
A grande maioria das tarefas de negócios consegue igualar o desempenho do site oficial, mas algumas tarefas de alta complexidade (textos minúsculos, baixa luminosidade, estilos artísticos específicos) ainda podem apresentar um desempenho ligeiramente inferior, pois a versão web utiliza pipelines de aprimoramento internos não divulgados. Para esses cenários, você pode realizar comparações horizontais com outros modelos visuais no APIYI (apiyi.com) para encontrar o modelo de trabalho mais adequado.
P2: O thinking_level=high fará com que o custo dobre?
Ele aumentará o uso de tokens de raciocínio interno, mas isso afeta apenas a fase de saída, e nos custos gerais de tarefas de reconhecimento de imagem, os tokens de imagem geralmente representam a maior parte. O aumento na precisão trazido pelo ajuste do thinking para high é muito superior ao aumento de custo, especialmente em operações que substituem a revisão humana.
P3: Como alterar a base_url? Estou usando o SDK oficial do Google.
O SDK google-genai permite redirecionar as solicitações para o gateway do APIYI (apiyi.com) através de http_options={"base_url": "https://api.apiyi.com"}. Basta usar a chave API gerada no painel do APIYI; não é necessário ter um projeto separado no Google Cloud.
P4: É possível resolver o problema apenas otimizando o comando?
O limite de apenas ajustar o comando é muito claro; ele não consegue cobrir capacidades "fora do modelo", como resolução, profundidade de raciocínio e chamadas de ferramentas. Das 6 dicas deste artigo, apenas a terceira está relacionada ao comando; as outras 5 são alavancas de nível de engenharia.
P5: O que fazer se a API sempre ignora "marcas d'água em chinês" que a versão web consegue identificar?
Detalhes como marcas d'água geralmente dependem da combinação de alta resolução com o recorte via execução de código. Ajuste media_resolution para ultra high, ative a code execution e use um fluxo de verificação em duas etapas; isso geralmente estabiliza a identificação.
Conclusão: Integrando as capacidades de engenharia da versão web nas chamadas de API
Voltando à pergunta inicial: por que o reconhecimento de imagem da API do Gemini parece inferior à versão web? A resposta não é que o modelo ficou mais fraco, mas sim que a versão web possui uma infraestrutura de engenharia muito robusta. Ao chamar a API do gemini-3.5-flash diretamente, a reescrita de comandos, níveis de resolução, orçamento de raciocínio, chamadas de ferramentas e validação de resultados precisam ser complementados explicitamente por você. Entendendo isso, a essência das 6 dicas é "trazer para a sua própria cadeia de chamadas de API aquilo que a versão web faz por você".
O caminho prático é claro: primeiro, maximize media_resolution e thinking_level, mova as instruções para system_instruction e ative o cache. Para tarefas complexas de reconhecimento, habilite a code execution, envie imagens grandes via File API e, finalmente, utilize uma cadeia de agentes de duas ou três etapas para garantir a precisão em operações críticas. Com essa combinação, ao comparar a taxa de acerto e a latência no painel do APIYI (apiyi.com), a maioria das equipes conseguirá reduzir a diferença entre a versão web e a API a um nível quase imperceptível.
📌 Autoria: Este artigo foi organizado pela equipe técnica do APIYI (apiyi.com). Para mais guias práticos de integração e ajuste de parâmetros das séries Gemini, Claude e GPT, acompanhe a Central de Ajuda do APIYI.