“gemini-3.1-flash-lite-image到底支不支持推理模式?”是最近在 API 调用群里被问得最多的问题之一。答案是肯定的,而且这不是猜测——我们结合 Google 官方文档,通过 APIYI 网关做了三组对照实验,拿到了真实的 token 消耗和延迟数据。本文将从参数结构、实测数据、计费规则三个角度,把 thinkingLevel 这个开关讲透。
核心价值: 读完本文,你会明确 gemini-3.1-flash-lite-image 的推理模式怎么开、开了之后多花多少 token、以及什么场景值得为这份延迟买单。

gemini-3.1-flash-lite-image 推理模式核心结论
先给结论,再讲细节。Google 官方文档明确写道,借助 gemini-3.1-flash-image 和 gemini-3.1-flash-lite-image,开发者可以控制模型使用的思考量,这意味着 flash-lite 这一档同样内置了推理能力,并非只有旗舰模型才有。但并不是所有图片模型都支持这个参数,下表是三款主流 Gemini 图片模型的支持情况对比。
| 模型 | 是否支持 thinkingLevel | 可调档位 | 默认档位 | 备注 |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ 支持 | minimal / high | minimal | 官方文档明确列出 |
| gemini-3.1-flash-lite-image | ✅ 支持 | minimal / high | minimal | 与 flash-image 共用同一套 thinkingConfig |
| gemini-3-pro-image | ⚠️ 参数无效 | 恒定,不可调 | 内部固定 | 传入 high 不报错,但实测无变化 |
需要特别说明的是,thinkingLevel 只有两档可选,不是像文本模型那样支持连续调节的思考预算。官方原文提到“minimal 思考并不代表模型完全不思考”,也就是说即便是默认档位,模型内部也会做一定量的基础推理,只是不会像 high 档那样进行多轮构图校验。
这也是一个值得关注的行业信号。在更早一代的图片生成模型里,无论是 nano banana 还是初版 flash-image,官方接口都没有暴露过思考等级这类参数,模型要么按固定策略出图,要么完全靠提示词工程去补偿构图缺陷。到了 3.1 这一代,Google 把“先规划、再生成”的推理机制开放给了 flash 系列,本质上是把此前只在文本模型里验证过的思考范式,迁移到了图片生成场景。理解这个背景,有助于判断未来其他厂商的图片模型是否也会走上同样的路线。
🎯 技术建议: 如果你正在通过 APIYI apiyi.com 调用 Gemini 图片系列模型,建议先用默认的 minimal 档位跑通业务流程,再根据实际出图质量决定是否需要切到 high。该平台提供统一接口,gemini-3.1-flash-image、flash-lite-image 和 pro-image 可以用同一套代码切换调用,便于做 A/B 对比。
thinkingLevel 参数详解与调用方式
thinkingLevel não é um parâmetro independente; ele fica dentro de thinkingConfig, aninhado em generationConfig, e é usado junto com includeThoughts. includeThoughts define se o resumo do pensamento do modelo vai ser retornado para quem chamou a API, enquanto thinkingLevel define a “intensidade” do raciocínio. São dois controles separados, então não misture os dois.
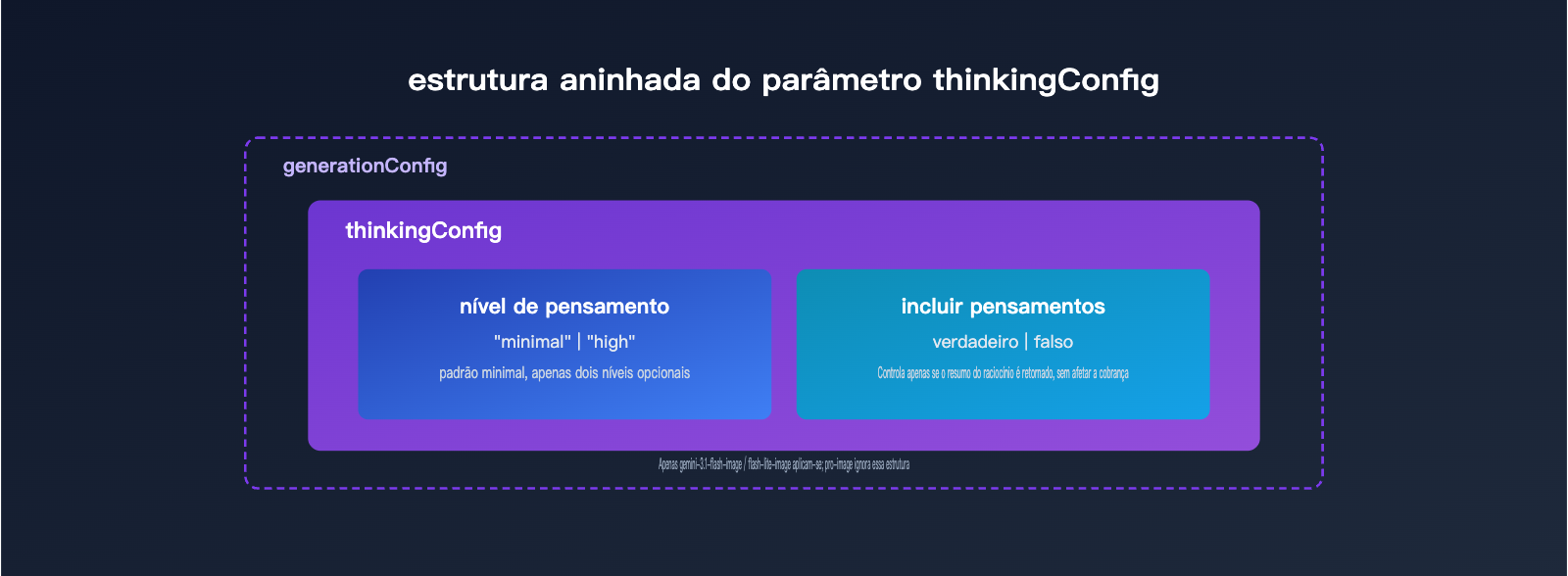
A tabela abaixo resume os tipos e os intervalos de valores de dois campos importantes dentro de thinkingConfig.
| Campo | Tipo | Valores possíveis | Valor padrão | Função |
|---|---|---|---|---|
| thinkingLevel | string enum | minimal / high |
minimal |
Controla a intensidade do raciocínio do modelo; só funciona nos modelos de imagem da série flash |
| includeThoughts | booleano | true / false |
false |
Define se o resumo do processo de pensamento vem na resposta; não afeta a cobrança |
Na chamada real, o padrão de implementação nas três linguagens principais é o mesmo: você coloca um objeto thinkingConfig dentro de config. Em Python, fica assim:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # chamada pelo gateway unificado da APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "Desenhe um gato tomando café aos pés de uma montanha nevada"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
Ver exemplo completo de chamada REST nativa
{
"contents": [{"parts": [{"text": "Desenhe um gato tomando café aos pés de uma montanha nevada"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
A escrita no SDK JavaScript segue a mesma estrutura; só muda a convenção de nomes do snake case do REST para o camelCase do objeto thinkingConfig. Os demais campos continuam iguais. Não tem diferença real entre as três linguagens, então basta lembrar de uma regra: thinkingConfig só deve ficar abaixo de generationConfig.
Tem um detalhe que pode confundir: o valor de thinkingLevel é uma enumeração de string sensível a maiúsculas e minúsculas. Nos exemplos oficiais, apareceram as duas formas, "High" e "high", mas nos testes as duas funcionaram corretamente através do gateway. Mesmo assim, para não depender de um comportamento de compatibilidade que não está documentado, o ideal é padronizar no seu código o uso de "high" e "minimal" em minúsculas. Assim, se no futuro a validação do upstream ficar mais rígida, sua integração não quebra.
Sugestão: use a APIYI em apiyi.com para pegar créditos grátis de teste e validar direto no gateway se o parâmetro
thinkingConfigestá sendo repassado corretamente. É bem mais prático do que pedir uma chave oficial só para depurar.
Dados reais testados na APIYI: impacto de thinkingLevel em tokens e latência
Por mais clara que a documentação seja, nada substitui rodar um teste de verdade. Usamos o mesmo comando, com geração de imagens em 1K de resolução, e testamos via gateway da APIYI três cenários: minimal no gemini-3.1-flash-image, high no mesmo modelo, e a tentativa de passar high para o gemini-3-pro-image.
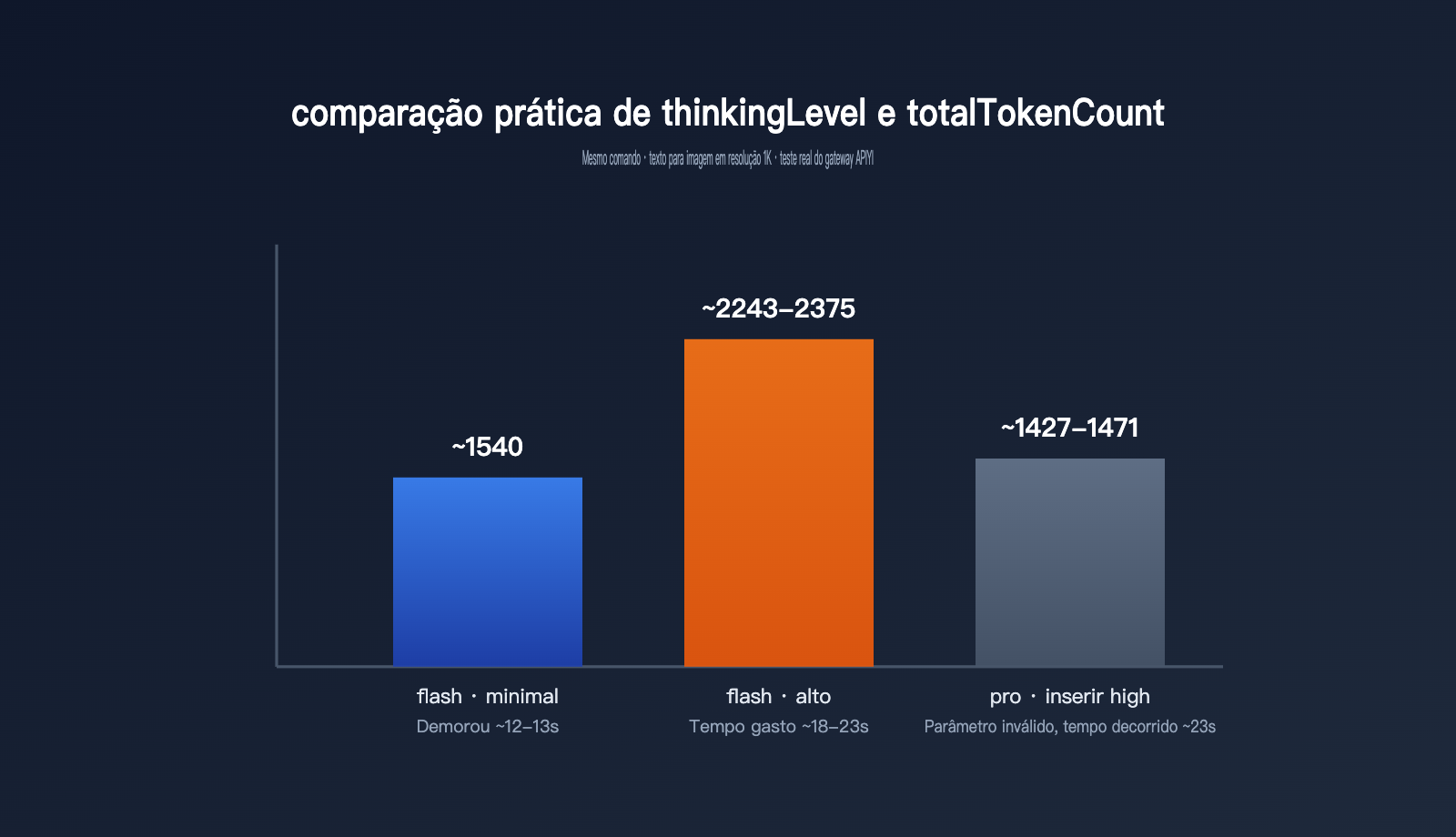
| Modelo / configuração | thoughtsTokenCount | tokens da imagem | totalTokenCount | tempo gasto |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (padrão) | sem esse campo | 1120 | cerca de 1540 | cerca de 12–13 s |
| gemini-3.1-flash-image · high | 700–792 | 1120 | cerca de 2243–2375 | cerca de 18–23 s |
| gemini-3-pro-image · com high | 181–214 (igual ao padrão) | 1120 | cerca de 1427–1471 | cerca de 23 s |
Esses dados mostram três coisas importantes. Primeiro: quando você muda thinkingLevel para high, o thoughtsTokenCount sai do zero padrão — no retorno, às vezes nem aparece esse campo — e sobe para a faixa de 700–800. O consumo total de tokens cresce quase 50%, e a latência também aumenta de 12–13 segundos para 18–23 segundos. Ou seja, pensar de verdade custa tempo e dinheiro. Segundo: tanto em minimal quanto em high, a saída final da imagem continua com 1120 tokens, então thinkingLevel só altera “como o modelo pensa”, e não a resolução da imagem nem o valor cobrado pela imagem em si. Terceiro: quando passamos high para gemini-3-pro-image, não acontece erro, mas os 181–214 tokens de pensamento ficam praticamente iguais ao padrão, o que confirma o que a documentação oficial diz: o comportamento de raciocínio do pro-image é fixo e não aceita ajuste externo.
Em outras palavras, se a sua lógica de negócio enviar sempre o mesmo thinkingConfig para vários modelos em lote — flash, flash-lite e pro — o pro-image vai simplesmente ignorar esse parâmetro sem quebrar a requisição. Ele não vai falhar, mas também não vai obedecer ao ajuste de intensidade que você tentou definir.
Vale reforçar um ponto: esses números não vêm de uma única execução. Eles são faixas obtidas depois de fazer várias requisições com o mesmo comando em cada configuração. É por isso que o thoughtsTokenCount do high aparece como 700–792, em vez de um valor exato. Tarefas de raciocínio têm um grau natural de aleatoriedade; a trajetória intermediária de pensamento do modelo muda um pouco a cada geração, então o consumo de tokens também varia levemente. Ainda assim, a ordem de grandeza e a tendência de latência são estáveis e reproduzíveis. Você não deve esperar que o high fique mais rápido que o minimal, nem que os tokens de pensamento explodam para milhares em condições normais.
Pensando em token e regras de cobrança em modelos de imagem
Muitos desenvolvedores, quando veem pela primeira vez o campo thoughtsTokenCount, acabam comparando com o custo de raciocínio dos modelos de texto. Mas, em modelos de imagem, o mecanismo de pensamento é dividido em duas partes na cobrança, e entender isso é importante para controlar custo.
| Dimensão | Pensamento em modelo de texto | Pensamento em modelo de imagem |
|---|---|---|
| Formato do resultado do pensamento | Cadeia de raciocínio só em texto | Resumo em texto + no máximo dois esboços temporários de composição |
| Volume de token do texto de pensamento | Pode chegar a milhares | Na versão Pro não passa de 400; na high do Flash fica em torno de 700–800 |
| Principal campo que absorve o custo | thoughtsTokenCount | Os esboços entram em candidatesTokenCount, cobrados como um image part normal |
| Padrão de cobrança por esboço | Não se aplica | Resolução 1K: cerca de 1120 tokens, ou US$ 0,0336 por imagem |
| Impacto de includeThoughts na cobrança | Nenhum, cobrança fixa | Nenhum, cobrança fixa |
A documentação oficial destaca que, seja includeThoughts definido como true ou false, os tokens gerados no pensamento continuam sendo cobrados normalmente. Nos testes que fizemos, isso também se confirmou: ao ligar includeThoughts, a estrutura de retorno e a cobrança total não mudaram em nada; só apareceu um trecho extra de resumo do pensamento para referência de debug. Em outras palavras, includeThoughts é só um botão de “mostrar ou não mostrar”, não de “pagar ou não pagar”. Esse detalhe é fácil de interpretar errado.
O ponto mais importante é que o maior pedaço do custo de pensamento em modelos de imagem nem está no campo thoughtsTokenCount, e sim nas imagens temporárias de composição geradas durante a inferência. A documentação oficial diz que, na fase de pensamento, o modelo pode gerar no máximo duas imagens temporárias para testar composição e coerência lógica. Esses esboços retornam como image part normal e entram em candidatesTokenCount, cobrados pelo preço padrão de saída de imagem. Ou seja: uma geração de imagem em modo high pode, discretamente, incluir uma ou duas cobranças de “esboços invisíveis”, algo que costuma passar batido na estimativa de custo.
Fazendo a conta fica mais claro. Suponha uma solicitação de geração de imagem em 1K usando o modo high: o texto de pensamento consome cerca de 750 tokens. Se o modelo realmente gerar duas imagens temporárias durante a inferência, somando a imagem final, você terá teoricamente três image parts. Considerando 1120 tokens por imagem, ou cerca de US$ 0,0336 por unidade, o custo de saída dessas três imagens chega perto de US$ 0,10. Somando o custo do texto de pensamento, o gasto total pode ficar em 2 a 3 vezes o do modo minimal. Na prática, se o modelo vai ou não gerar as duas imagens depende do que ele entende do comando; não é toda chamada em high que vai produzir exatamente duas imagens temporárias. É por isso que, nos testes, o total de tokens costuma ficar numa faixa como 2243–2375, e não dobrar de forma exata.
💰 Otimização de custo: para times sensíveis a custo de token, vale a pena conferir o totalTokenCount real nos logs de chamada da plataforma APIYI apiyi.com antes de deixar o modo high ligado permanentemente. Assim você evita estourar o orçamento por não considerar a cobrança dos esboços.
Em que cenários usar high e em quais ficar no minimal padrão
Com base nos dados de teste, aqui vai uma referência simples de decisão.

| Cenário de negócio | Plano recomendado | Motivo |
|---|---|---|
| Geração em lote de criativos para marketing, sem grande exigência de precisão de composição | minimal (padrão) | Menor latência, custo de token controlado e suficiente para o uso diário |
| Composição complexa com vários sujeitos, exigindo seguir com precisão a diagramação do texto ou a relação espacial | high | O pensamento extra aumenta a precisão da composição e compensa pelo ganho de qualidade |
| Páginas de detalhe de e-commerce, pôsteres e outros cenários com baixa tolerância a erro nos detalhes | high | Reduz retrabalho e re-geração, então o custo total pode até cair |
| Cenários interativos em tempo real que exigem resposta muito rápida | minimal | No high a latência aumenta em 5–10 segundos, o que atrapalha a experiência |
| Chamada do gemini-3-pro-image | Não precisa configurar | O comportamento de pensamento desse modelo é fixo; passar parâmetro não tem efeito |
De forma simples, o high é mais indicado quando “acertar de primeira” importa mais do que “gerar rápido”. Se o seu aplicativo precisa fazer várias tentativas, ajustando o comando várias vezes até chegar numa composição boa, talvez valha mais a pena já usar high e trocar um custo unitário um pouco maior por uma taxa de acerto melhor na primeira tentativa. No fim, isso costuma sair mais em conta.
Na implementação real, o caminho mais seguro é tratar thinkingLevel como uma opção configurável, em vez de deixar isso fixo no código. Por exemplo: roteie automaticamente pelo tipo de negócio recebido na chamada da API — tarefas em lote ficam em minimal por padrão, enquanto requisições com diagramação precisa ou múltiplos sujeitos vão para high. Assim você controla o custo médio sem sacrificar qualidade nos cenários críticos. Se o time mantém ao mesmo tempo a lógica de chamada dos modelos flash, flash-lite e pro, a recomendação é centralizar o tratamento na camada de encapsulamento de parâmetros, e só enviar thinkingLevel para os modelos que realmente aceitam isso, evitando repassar parâmetro inútil para o pro-image e complicar a depuração.
🚀 Começo rápido: recomendamos usar a plataforma APIYI apiyi.com para montar um protótipo rápido. Com o mesmo base_url, dá para alternar entre minimal e high e comparar os testes sem precisar configurar credenciais separadas para cada modo.
Perguntas frequentes
P1: O desempenho de inferência do gemini-3.1-flash-lite-image e do gemini-3.1-flash-image é o mesmo?
Os dois compartilham a mesma estrutura de parâmetros do thinkingConfig, e os níveis suportados também são minimal e high. Mas o flash-lite é posicionado como uma versão mais leve, então a profundidade real de raciocínio e o nível de detalhe da imagem final normalmente ficam abaixo do flash-image. Dá até para perceber isso pela lógica do nome: a série flash-lite nos modelos de texto sempre teve a proposta de ser “mais rápida, mais econômica e com leve perda de precisão”; a série de imagens segue a mesma lógica de trade-off. Ativar o nível high pode compensar até certo ponto as limitações do modelo leve em composições complexas, mas é difícil igualar totalmente o desempenho do flash-image. Se quiser fazer uma comparação quantitativa, você pode usar a plataforma APIYI apiyi.com para chamar os dois modelos com o mesmo conjunto de comandos e comparar diretamente o thoughtsTokenCount e o resultado das imagens.
P2: Se eu passar o parâmetro `thinkingLevel` para o gemini-3-pro-image, vai dar erro?
Não vai dar erro. Nossos testes mostram que, ao passar o parâmetro high, a requisição retorna normalmente, mas o thoughtsTokenCount continua na faixa de 181-214, quase igual ao caso sem parâmetro. Isso indica que o comportamento interno de raciocínio desse modelo é fixo e não aceita ajuste externo. Ao fazer chamadas em lote com vários modelos, é melhor tratar o nome do modelo separadamente na lógica de negócio, para não achar que o parâmetro já teve efeito.
P3: Depois de ativar o nível `high`, preciso ajustar também a resolução ou os parâmetros de qualidade da imagem?
Não precisa. Os dados de teste mostram que os tokens de imagem nas duas opções, minimal e high, ficaram estáveis em 1120. Isso indica que o thinkingLevel só afeta o processo interno de inferência do modelo e não altera a configuração de resolução da imagem de saída. A resolução continua sendo controlada separadamente pelos parâmetros de tamanho em imageConfig, sem relação com o nível de raciocínio. Em outras palavras, thinkingLevel e os parâmetros de resolução são dois eixos independentes: um controla se o modelo “pensou com mais cuidado”, e o outro controla se ele “desenhou maior e com mais detalhe”. Dá para combinar os dois livremente, sem relação de exclusão ou efeito cascata.
Resumo
O gemini-3.1-flash-lite-image realmente suporta o modo de inferência, e isso já foi confirmado tanto pela documentação oficial quanto pelos dados de teste da APIYI. O thinkingLevel só tem duas opções, minimal e high; ao ativar high, os tokens de pensamento sobem para mais de 700 e o tempo total aumenta em cerca de 5 a 10 segundos, mas isso não muda o consumo de tokens da imagem final. Já o gemini-3-pro-image, embora aceite esse parâmetro sem erro, na prática não aplica o ajuste. Entender essa lógica de cobrança em duas frentes — “texto do raciocínio” indo para thoughtsTokenCount e “rascunho de composição” indo para candidatesTokenCount — é uma parte essencial para controlar o custo da geração de imagens. Se você precisa alternar e validar rapidamente entre vários modelos de imagem do Gemini, a recomendação é usar o gateway unificado da APIYI apiyi.com para fazer os testes, evitando ter que solicitar uma chave separada e manter códigos de chamada diferentes para cada modelo.
Os dados deste artigo vêm de testes práticos da equipe técnica da APIYI. Se quiser trocar uma ideia sobre mais detalhes de invocação dos modelos de imagem do Gemini, entre em contato com o suporte técnico pela APIYI apiyi.com.
Material de referência
- Documentação oficial da Gemini API – Geração de imagens: explicação do parâmetro de níveis de raciocínio (thinking levels)
- Link:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- Link: