Recentemente, um desenvolvedor me perguntou sobre um problema recorrente: "Por que levo mais de 200 segundos para gerar uma imagem de 1024×1024 com o gpt-image-2? Será que estou sendo limitado?". Ao analisar o código dele, vi que os parâmetros estavam como quality="high" e size="1536x1024". Com essas configurações, os 235 segundos por imagem são, na verdade, o comportamento esperado.

O gpt-image-2 é a nova geração de modelos de imagem lançada pela OpenAI em 21 de abril de 2026. Ele traz, pela primeira vez, a capacidade de raciocínio da série O (pensamento agente) para o fluxo de geração de imagens. Isso significa que solicitações com quality="high" passam por quatro etapas completas: "compreensão — planejamento — geração — revisão", o que leva de 30 a 50 vezes mais tempo do que o quality="low". Este artigo, baseado em experiências reais de produção, detalha os três parâmetros mais críticos para que você encontre o equilíbrio ideal entre qualidade e velocidade.
Tabela de referência rápida: Parâmetros de invocação do gpt-image-2
Vamos direto ao ponto. A tabela abaixo cobre todos os parâmetros importantes do gpt-image-2 no SDK Python da OpenAI e seu impacto no tempo de processamento e no custo. Recomendo consultar esta tabela antes de realizar qualquer ajuste.
| Parâmetro | Valores possíveis | Valor padrão | Impacto no tempo | Impacto no custo |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
Extremo | Extremo |
size |
1024x1024 / 1536x1024 / 1024x1536 / qualquer ≤ 2K |
1024x1024 |
Alto | Médio |
output_format |
png / jpeg / webp |
png |
Baixo | Nenhum |
output_compression |
0–100 (apenas para jpeg/webp) | 100 | Mínimo | Nenhum |
n |
1–10 | 1 | Proporcional a n | Proporcional a n |
background |
transparent / opaque / auto |
auto |
Baixo | Nenhum |
prompt |
string | Obrigatório | Complexidade afeta tempo | Afeta tokens de entrada |
A lógica central para entender esta tabela é: quality e size são os fatores decisivos. Eles determinam diretamente qual caminho de raciocínio o modelo seguirá, quantos tokens serão gerados e quanto poder computacional visual será consumido. output_format e output_compression são apenas questões de serialização; ajustá-los não aumentará a velocidade.
🎯 Dica principal: Se o seu negócio permitir, altere
quality="auto"paralowoumediumexplicitamente. Só esse passo geralmente reduz o tempo de minutos para segundos. Ao invocar o gpt-image-2 via APIYI (apiyi.com), todos esses parâmetros são transmitidos nativamente, mantendo o comportamento idêntico ao endpoint oficial da OpenAI.
2 parâmetros cruciais que afetam o tempo de processamento do gpt-image-2: quality e size
Para entender por que as opções "high" e "low" podem ter uma diferença de dezenas de vezes no tempo de resposta, é preciso primeiro compreender o caminho de execução do gpt-image-2. Esta é a diferença mais fundamental entre ele e a geração anterior, o gpt-image-1.
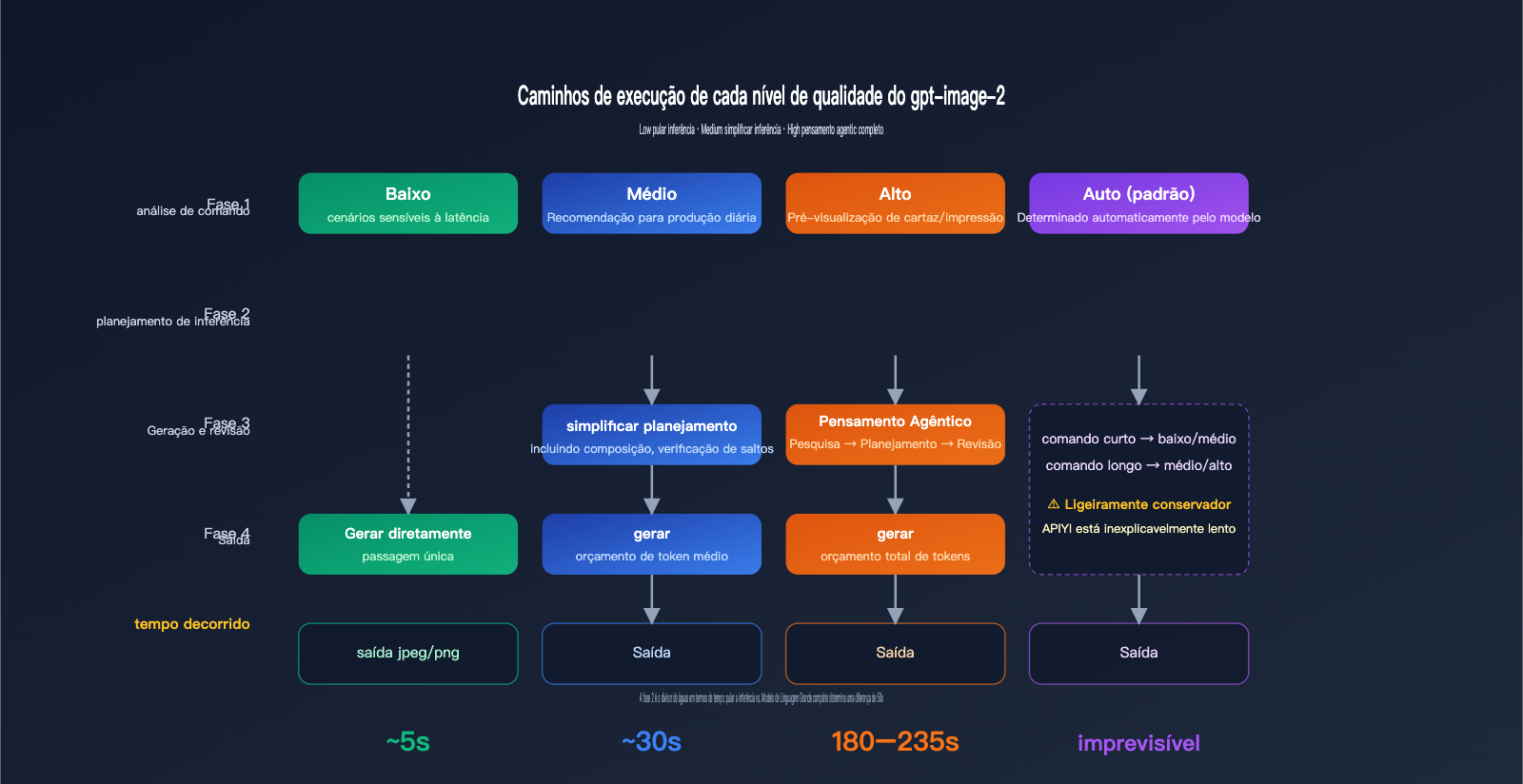
Mecanismo de funcionamento do parâmetro quality
A documentação oficial do gpt-image-2 deixa claro que quality="low" é voltado para cenários sensíveis à latência, oferecendo uma resposta em segundos com uma qualidade visual aceitável. Já o quality="high" ativa uma cadeia de pensamento (Agentic) completa — o modelo planeja internamente a composição, o layout do texto e a lógica de luz e sombra antes de começar a desenhar. Essa fase de inferência é invisível ao olho humano, mas consome cerca de 70–80% do tempo total.
O quality="medium" é um meio-termo: ele mantém um planejamento simplificado, mas pula a revisão detalhada. Quando o quality="auto" é usado, o modelo escolhe automaticamente com base na complexidade do comando, mas, na prática, ele tende a ser conservador e selecionar "medium" ou "high", o que explica por que muitos desenvolvedores acham que o "padrão é lento".
Mecanismo de funcionamento do parâmetro size
O gpt-image-2 suporta nativamente três tamanhos padrão: 1024x1024, 1536x1024 e 1024x1536, além da opção auto. Ele também aceita dimensões personalizadas, desde que o total de pixels não exceda 2K (2560×1440 = aprox. 3,69 milhões de pixels). Acima desse limite, entramos em uma área experimental onde a estabilidade dos resultados diminui.
A quantidade de pixels determina diretamente o número de tokens visuais. 1024×1024 equivale a cerca de 1024 tokens visuais, enquanto 1536×1024 sobe para cerca de 1536 tokens. Dobrar o número de tokens significa dobrar o tempo de inferência e geração, além de dobrar o custo.
| Tamanho Padrão | Total de Pixels | Tokens Visuais (est.) | Tempo Relativo | Cenário de Uso |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | Geral, redes sociais, miniaturas |
1536x1024 |
1.57M | ~1536 | 1.5× | Banners, capas de artigos |
1024x1536 |
1.57M | ~1536 | 1.5× | Pôsteres, conteúdo vertical |
| Personalizado ≤ 2K | Até 3.69M | Até ~3686 | 2–3× | Prévia de impressão de alta res. |
🎯 Dica de tamanho: Na prática, recomendo usar
1024x1024em 95% das requisições, mudando para a série 1536 apenas quando precisar de proporções especiais para banners ou pôsteres. Ao usar via APIYI (apiyi.com), você pode definir qualquer tamanho, mas lembre-se de manter abaixo de 2K para garantir a estabilidade.
Efeito de acoplamento dos dois parâmetros
Os parâmetros quality e size possuem uma relação multiplicativa, não aditiva. A combinação "high" + 1536×1024 não é apenas algumas vezes mais lenta que "low" + 1024×1024, mas sim dezenas de vezes. Isso é fatal em cenários de concorrência — você pode achar que 10 requisições simultâneas serão processadas em 1 segundo, mas, na verdade, pode levar 200 segundos para gerar 10 imagens, fazendo com que o cliente HTTP exceda o tempo limite (timeout).
Um ponto ainda mais sutil é o acoplamento entre quality e a complexidade do comando. Mesmo no nível "high", um comando simples ("uma maçã vermelha") leva cerca de 100 segundos, enquanto um comando complexo ("cidade cyberpunk em noite chuvosa, letreiros de neon, formato cinematográfico, interação entre 6 personagens") pode facilmente ultrapassar 230 segundos. A fase de inferência do modelo expande dinamicamente o orçamento de tokens de acordo com os elementos da cena; portanto, quanto mais complexo o comando, mais lento o nível "high" e maior o custo.
🎯 Dica de escrita de comando: No nível "high", recomendo manter o comando abaixo de 200 caracteres e colocar os elementos principais nos primeiros 50 caracteres. Descrições longas não melhoram necessariamente o resultado e, pelo contrário, aumentam o tempo de inferência. Essa regra também se aplica ao usar via APIYI (apiyi.com), já que a camada de proxy transmite o comando integralmente, mantendo o comportamento do modelo idêntico ao oficial.
Comparativo de tempo de execução e preço por nível de qualidade do gpt-image-2
A tabela abaixo apresenta dados coletados na plataforma APIYI (apiyi.com) em diversos horários e com diferentes níveis de complexidade de comando. Embora os dados possam sofrer pequenas variações devido ao horário, ao comando e à rede, a ordem de grandeza é confiável.
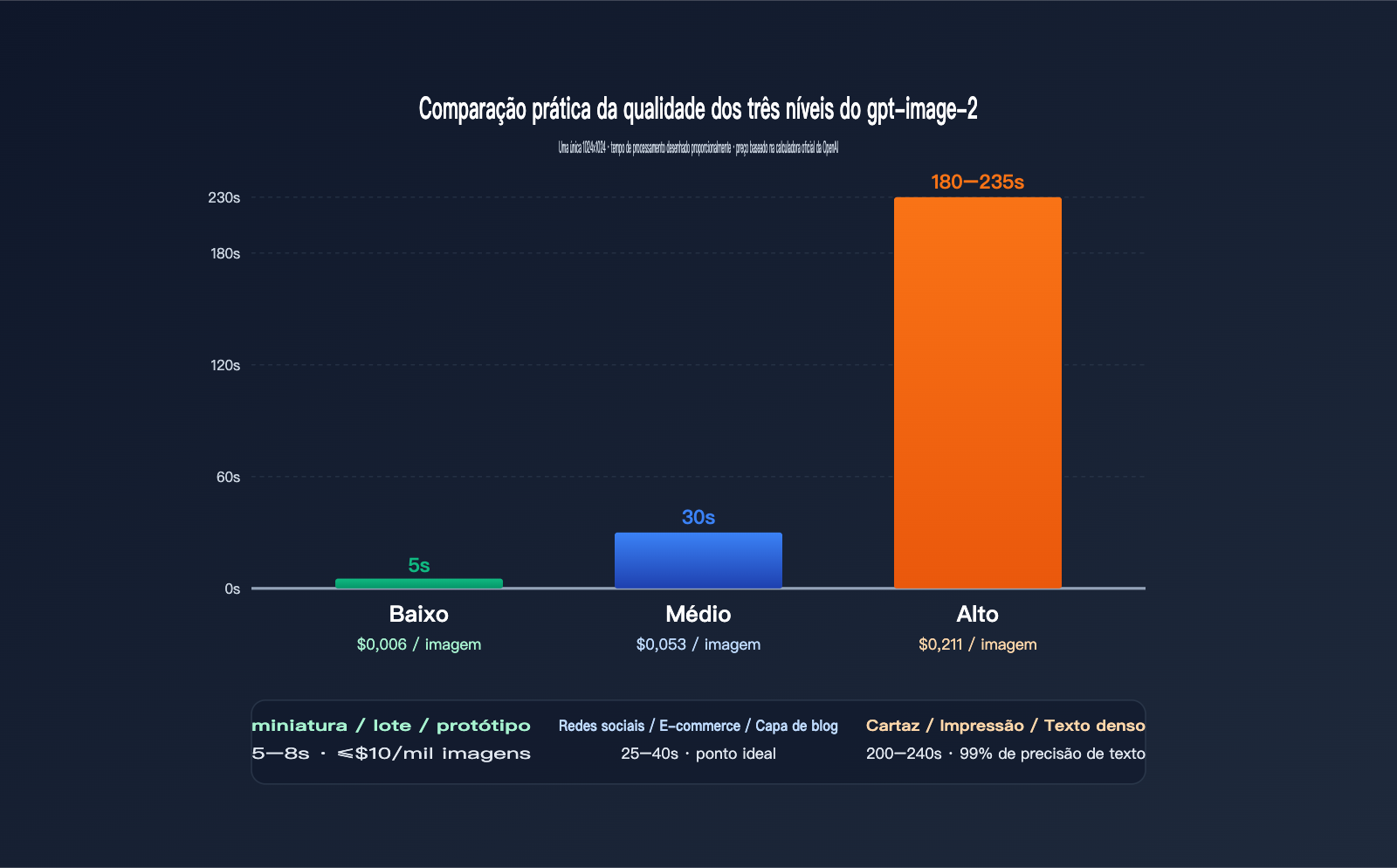
Dados reais para 1024×1024
| quality | Tempo médio | Preço (USD/imagem) | Precisão visual | Precisão de texto | Cenários de uso |
|---|---|---|---|---|---|
low |
3–8 s | $0.006 | Médio | Comum | Miniaturas, lote, protótipos |
medium |
20–40 s | $0.053 | Alto | Bom | Redes sociais, e-commerce, capas |
high |
150–235 s | $0.211 | Altíssima | Altíssima (99%+) | Cartazes, impressão, textos densos |
É possível observar uma relação não linear clara: o preço aumenta 9 vezes de "low" para "medium", mas o tempo aumenta apenas 5 vezes; de "medium" para "high", o preço aumenta 4 vezes, mas o tempo aumenta de 6 a 7 vezes. Em outras palavras, o custo marginal do nível "high" é pago com "tempo de espera".
Se o seu negócio não exige 99% de precisão em textos (como ilustrações, design abstrato ou conceitos), o nível "medium" é suficiente, economizando tempo e dinheiro. Apenas cenários como cartazes, design de IP e pré-visualização para impressão justificam a espera de 200 segundos do nível "high".
🎯 Dica de estimativa de custos: Antes de colocar em produção, recomendo usar a APIYI (apiyi.com) para gerar 100 imagens em cada nível (low/medium/high), criar um relatório interno de A/B com a distribuição de tempo, preço e qualidade, e então decidir qual nível usar para o tráfego principal. O custo não passará de $30, mas evitará que requisições lentas prejudiquem seu SLA.
Diferença de tempo: 1024×1024 vs 1536×1024
No nível "medium", 1024×1024 leva em média 25 segundos, enquanto 1536×1024 (ou 1024×1536) leva cerca de 38 segundos. A diferença segue a proporção de 1,5x dos tokens visuais. No nível "high", essa diferença é amplificada: "high" + 1024×1024 leva cerca de 180 segundos, enquanto "high" + 1536×1024 pode facilmente ultrapassar 240 segundos. O nível "high" não deve ser usado em chamadas síncronas bloqueantes; prefira tarefas assíncronas, retornando um ID de tarefa e usando polling ou callback.
Equívoco comum: Resolução maior não significa necessariamente melhor qualidade
Muitos desenvolvedores acham que quanto maior a resolução, melhor a qualidade, optando pelo padrão 1536. Isso é um erro. O gpt-image-2 já entrega uma qualidade excelente em 1024×1024. Mudar para 1536 apenas altera o formato, sem aumentar a densidade de detalhes. A menos que precise de uma proporção específica, 1024×1024 é a escolha mais eficiente.
Exemplo completo de chamada do gpt-image-2 via Python SDK
Abaixo, apresento três níveis de código, do básico ao pronto para produção, utilizando o SDK oficial da OpenAI com o base_url apontando para a APIYI (apiyi.com).
Exemplo básico: Geração simples de texto para imagem
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="Cidade cyberpunk em noite chuvosa, letreiros de neon, formato cinematográfico",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
Exemplo de produção: Timeout explícito e retentativas
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
Exemplo em lote: Geração assíncrona e concorrente
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["gato", "cachorro", "pássaro", "peixe", "coelho"] * 4))
A concorrência é a melhor técnica para geração em lote. No nível "low", 20 imagens sequenciais levam 100 segundos; com 5 vias de concorrência, levam apenas 20 segundos. Evite usar concorrência com o nível "high" para não causar estouro de timeout.
Recomendações de parâmetros para o gpt-image-2 em diferentes cenários de negócio
Depois de analisar os dados teóricos, é hora de aplicá-los a cenários reais. Abaixo, organizei as combinações de parâmetros ideais para os casos de uso mais frequentes.
| Cenário de Negócio | quality | size | output_format | Tempo esperado | Preço unitário |
|---|---|---|---|---|---|
| Imagens principais de e-commerce, Banners | medium | 1024×1024 | jpeg+85 | 25–35s | $0,053 |
| Imagens para redes sociais (ex: Xiaohongshu) | medium | 1024×1536 | jpeg+85 | 30–40s | ~$0,06 |
| Capas de artigos, cabeçalhos de blog | medium | 1536×1024 | webp+90 | 30–40s | ~$0,06 |
| Pôsteres, pré-visualização de impressão | high | 1024×1536 | png | 200–240s | ~$0,21 |
| Legendas / Capas de PPT | high | 1536×1024 | png | 200–240s | ~$0,21 |
| Miniaturas, testes de protótipo | low | 1024×1024 | jpeg+75 | 3–8s | $0,006 |
| Esboços em lote, painéis de inspiração | low | 1024×1024 | jpeg+75 | 3–8s × N | $0,006 × N |
| Geração instantânea por assistente de IA | low | 1024×1024 | webp+85 | 5–10s | $0,006 |
Cenário 1: E-commerce e Redes Sociais — "medium" é o ponto ideal
Imagens principais de e-commerce e posts para redes sociais são sensíveis ao tempo (o usuário não pode esperar 4 minutos após fazer o upload do produto), mas precisam ser nítidas e atraentes. O nível medium é a melhor escolha: gera a imagem em cerca de 30 segundos por 5 centavos. Rodar 1.000 imagens por dia custaria apenas US$ 53.
Cenário 2: Pôsteres e Impressão — Vale a pena esperar pelo "high"
Pôsteres e capas que contêm muito texto, layout complexo e exigem consistência facial de personagens precisam do raciocínio Agentic completo do nível high. Nesses casos, não tente apressar o processo; configure o front-end com uma abordagem de "tarefa" — informe ao usuário que o resultado estará disponível em 3 a 5 minutos.
Cenário 3: Lotes e Protótipos — O nível "low" é essencial
Sempre que precisar "gerar 10 mil esboços durante a noite", use o nível low, sem exceções. Combinado com processamento assíncrono e compressão jpeg+75, um único nó de GPU consegue atingir uma produtividade impressionante.
Cenário 4: Interação instantânea com o usuário — Use "low" ou "medium"
Em cenários onde o usuário está esperando, como chatbots, assistentes de IA integrados ou respostas automáticas de suporte, nunca use o nível high. Fazer um usuário esperar 4 minutos significa que pelo menos 50% deles atualizarão a página ou sairão, o que é um desastre para a experiência. Recomendo fixar no nível low com uma animação de "Carregando…", entregando o resultado em 5 a 8 segundos. Se a qualidade não for suficiente, ofereça um botão de "Otimização HD" que dispara uma nova geração no nível medium.
Cenário 5: Moderação de conteúdo e re-geração
Caso uma solicitação seja bloqueada pela política de conteúdo da OpenAI, recomendo usar o nível low para testar se o novo comando passa pela moderação. Só após a confirmação, suba para medium ou high para a imagem final. Essa estratégia de dois estágios minimiza custos com falhas de moderação, evitando desperdiçar 200 segundos no nível high apenas para descobrir que o conteúdo foi bloqueado.
🎯 Estratégia Híbrida: Muitos sistemas de produção utilizam a "geração de dois níveis" — primeiro, gera-se uma prévia em nível
lowpara o usuário escolher e, após a seleção, gera-se o resultado final emhigh. Essa estratégia funciona perfeitamente na APIYI (apiyi.com), pois a mesma chave API cobre todos os níveis dequality, sem necessidade de trocar de conta.
Perguntas Frequentes (FAQ)
Q1: Por que minhas solicitações no nível "high" sempre dão timeout?
O SDK Python da OpenAI tem um timeout padrão de 600 segundos, o que teoricamente é suficiente, mas muitos frameworks (FastAPI, Flask, Celery) adicionam seus próprios timeouts na camada externa. Verifique as configurações de tempo limite em cada etapa da sua cadeia de chamadas; para o nível high, recomendo pelo menos 300 segundos em todo o fluxo. Se usar httpx, lembre-se de definir explicitamente httpx.Timeout(300.0).
Q2: Qual o valor ideal para output_compression?
Para o formato JPEG, 85 é o ponto ideal — a olho nu, é quase impossível notar a diferença para 100, mas o tamanho do arquivo reduz de 30% a 40%. Para WebP, 90 também é um valor comum. Valores abaixo de 70 podem gerar blocos de cor visíveis, especialmente em áreas com degradês. Esse parâmetro não afeta o tempo de geração, apenas a serialização final.
Q3: Existe diferença entre chamar o gpt-image-2 via APIYI (apiyi.com) e o endpoint oficial?
Os parâmetros e comportamentos são totalmente transparentes, incluindo quality, size, output_format, output_compression, n, background, entre outros. A diferença é que a APIYI (apiyi.com) oferece nós de alta velocidade acessíveis localmente, faturamento unificado e pagamento por uso sem consumo mínimo, sendo mais amigável para desenvolvedores.
Q4: O parâmetro n pode retornar várias imagens de uma vez?
Sim, o gpt-image-2 suporta de n=1 a n=10. Mas atenção: o tempo total para múltiplas imagens é cerca de 0,7 a 0,9 vezes o tempo de uma imagem multiplicado por n (não é totalmente paralelo), e o preço total é calculado por n. Se precisar de um "conjunto de personagens coerentes", usar n=4 para que o modelo gere tudo em uma única inferência é mais estável do que fazer 4 chamadas separadas, pois o gpt-image-2 mantém a consistência facial dentro da mesma inferência.
Q5: O que o quality="auto" realmente faz?
Em testes, o auto tende a escolher medium ou high, dependendo do tamanho e da complexidade do comando. Comandos curtos ("um gato") provavelmente usarão low/medium, enquanto comandos longos (com personagens, cenários, texto, estilo) provavelmente usarão high. Em produção, recomendo especificar explicitamente em vez de depender da decisão implícita do auto.
Q6: Qual qualidade é melhor: 1024×1536 ou 1536×1024?
Ambos possuem o mesmo número total de pixels (cerca de 1,57 milhão), então a qualidade é essencialmente a mesma. A diferença está apenas na proporção: vertical (1024×1536) é ideal para pôsteres, retratos de corpo inteiro e conteúdo mobile; horizontal (1536×1024) é ideal para banners, paisagens e capas para PC. A escolha depende da composição, não afetando a velocidade ou o preço.
Q7: Posso pular a inferência e acessar o modelo base diretamente?
Não, o raciocínio Agentic do gpt-image-2 é parte integrante da arquitetura do modelo e não pode ser desativado. Se você realmente precisa apenas de uma geração rápida estilo SD tradicional, sem renderização de texto ou raciocínio, use o nível low, que ignora a cadeia de inferência completa. Ou considere o nano-banana-pro do Google; seu nível rápido é ainda mais veloz que o low do gpt-image-2, e este modelo também já está disponível na APIYI (apiyi.com).
🎯 Sugestão de colaboração entre modelos: Sistemas de geração de imagem maduros geralmente não usam apenas um modelo. Recomendo usar o nano-banana-pro para pré-visualizações rápidas (resposta em 5 segundos), o gpt-image-2 medium para o fluxo principal de imagens e o gpt-image-2 high para cenários premium. Os três modelos compartilham a mesma chave na APIYI (apiyi.com) com cobrança por uso, sendo a combinação mais econômica para APIs de imagem em 2026.
Resumo: trate os parâmetros como interruptores de desempenho, não como decoração
A filosofia de design do gpt-image-2 é completamente diferente da geração anterior de modelos de imagem — ele transformou a inferência em uma etapa central da geração de imagens. Portanto, o parâmetro quality não é mais uma opção simples de "qualidade de imagem", mas sim um interruptor que define "quão profundo será o caminho de inferência". Ao entender isso, você compreende por que a mesma API pode variar de 5 a 235 segundos, uma diferença de 50 vezes no tempo de processamento.
Na prática, sugerimos que a "seleção de parâmetros" seja o primeiro passo do seu design de negócio: pense claramente em qual latência o seu cenário pode tolerar, qual nível de qualidade é necessário e qual é o limite de custo por unidade. Em seguida, consulte a tabela para escolher quality e size. Definir esses parâmetros com antecedência é muito mais tranquilo do que tentar otimizá-los após o lançamento.
🎯 Recomendação final: Ao começar a integrar o gpt-image-2, sugerimos que você se registre no APIYI (apiyi.com) e execute uma rodada de testes comparativos entre os níveis low/medium/high. Atribua uma nota ao tempo de resposta real e à qualidade da imagem antes de decidir os parâmetros para o tráfego principal. Usar uma única chave API para cobrir os três níveis, com cobrança por uso e sem consumo mínimo, é a forma mais eficiente de integrar APIs de imagem em 2026.
— Equipe técnica da APIYI | Acompanhando continuamente as dinâmicas dos modelos de geração de imagens. Para mais tutoriais detalhados, visite a central de ajuda do APIYI em apiyi.com.