Nota do autor: Com base em 6 benchmarks essenciais, como SWE-bench Pro, Terminal-Bench 2.0 e LiveCodeBench, realizamos uma análise comparativa profunda entre o GPT-5.5 e o Claude Opus 4.7 em cenários de programação reais, oferecendo recomendações claras de seleção.
A disputa de habilidades de programação entre o GPT-5.5 e o Claude Opus 4.7 é o tema mais comentado na área de programação com IA em abril de 2026. Este artigo compara o OpenAI GPT-5.5 (codinome Spud) e o Anthropic Claude Opus 4.7, fornecendo recomendações de seleção claras em múltiplas dimensões, como SWE-bench Pro, Terminal-Bench 2.0, recuperação de contexto longo, eficiência de tokens e precificação de API.
Esta não é uma análise de "cada um tem suas virtudes" em tom conciliador. Com base nos dados oficiais dos benchmarks, daremos recomendações definitivas para diferentes cenários. A Anthropic lançou o Claude Opus 4.7 em 16 de abril de 2026, e a OpenAI seguiu logo após, em 23 de abril, com o GPT-5.5; dois modelos de elite lançados com apenas 7 dias de intervalo, dando início ao duelo de competências em programação.
Valor fundamental: Após ler este artigo, você saberá exatamente se deve escolher o GPT-5.5 ou o Claude Opus 4.7 para quatro cenários típicos: correção de issue no GitHub, programação por agentes, refatoração de contexto longo e codificação interativa.

Visão geral das diferenças fundamentais entre GPT-5.5 e Claude Opus 4.7
O posicionamento central dos dois modelos é diferente, o que leva a forças distintas em suas capacidades de programação. A tabela abaixo resume as principais diferenças em dimensões relacionadas à programação:
| Dimensão de Comparação | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Data de lançamento | 23-04-2026 | 16-04-2026 |
| Codinome | Spud | – |
| Janela de contexto | 1M tokens | 1M tokens |
| Saída máxima | 128K tokens | 128K tokens |
| Pontos fortes | Programação por agentes, recuperação de contexto longo | Correção de issue no GitHub, raciocínio de arquitetura |
| TTFT típico | ~3 segundos | ~0.5 segundos |
| Eficiência de tokens | 72% menos tokens de saída que o Opus | Consumo de tokens maior, porém alta precisão |
| Entrada de API | US$ 5/M tokens | US$ 5/M tokens |
| Saída de API | US$ 30/M tokens | US$ 25/M tokens |
| Adicional em prompts longos | >200K mantém o preço original | >200K dobra para US$ 10/US$ 37,50 |
Posicionamento da capacidade de programação do GPT-5.5
O GPT-5.5 é o modelo de programação por agentes mais forte da OpenAI até o momento. Ele se destaca em fluxos de trabalho de terminal, recuperação de contexto longo e coordenação entre ferramentas, sendo especialmente adequado para processos de programação automatizada que exigem múltiplas etapas e chamadas de ferramentas. A OpenAI posiciona o modelo como a primeira escolha para "tarefas de programação de longa duração", demonstrando no benchmark interno Expert-SWE a capacidade de processar tarefas equivalentes a 20 horas de esforço humano.
Posicionamento da capacidade de programação do Claude Opus 4.7
O Claude Opus 4.7 retomou o trono em tarefas reais de engenharia de software. Ele atingiu 87,6% no SWE-bench Verified e 64,3% no SWE-bench Pro, liderando significativamente todos os concorrentes existentes. Testes da Anthropic no Rakuten-SWE-Bench mostram que o volume de tarefas de produção resolvidas pelo Opus 4.7 é 3 vezes maior que o do Opus 4.6, tornando-o especialmente adequado para trabalhos que exigem raciocínio de arquitetura, como corrigir issues do GitHub e refatorar grandes bases de código.
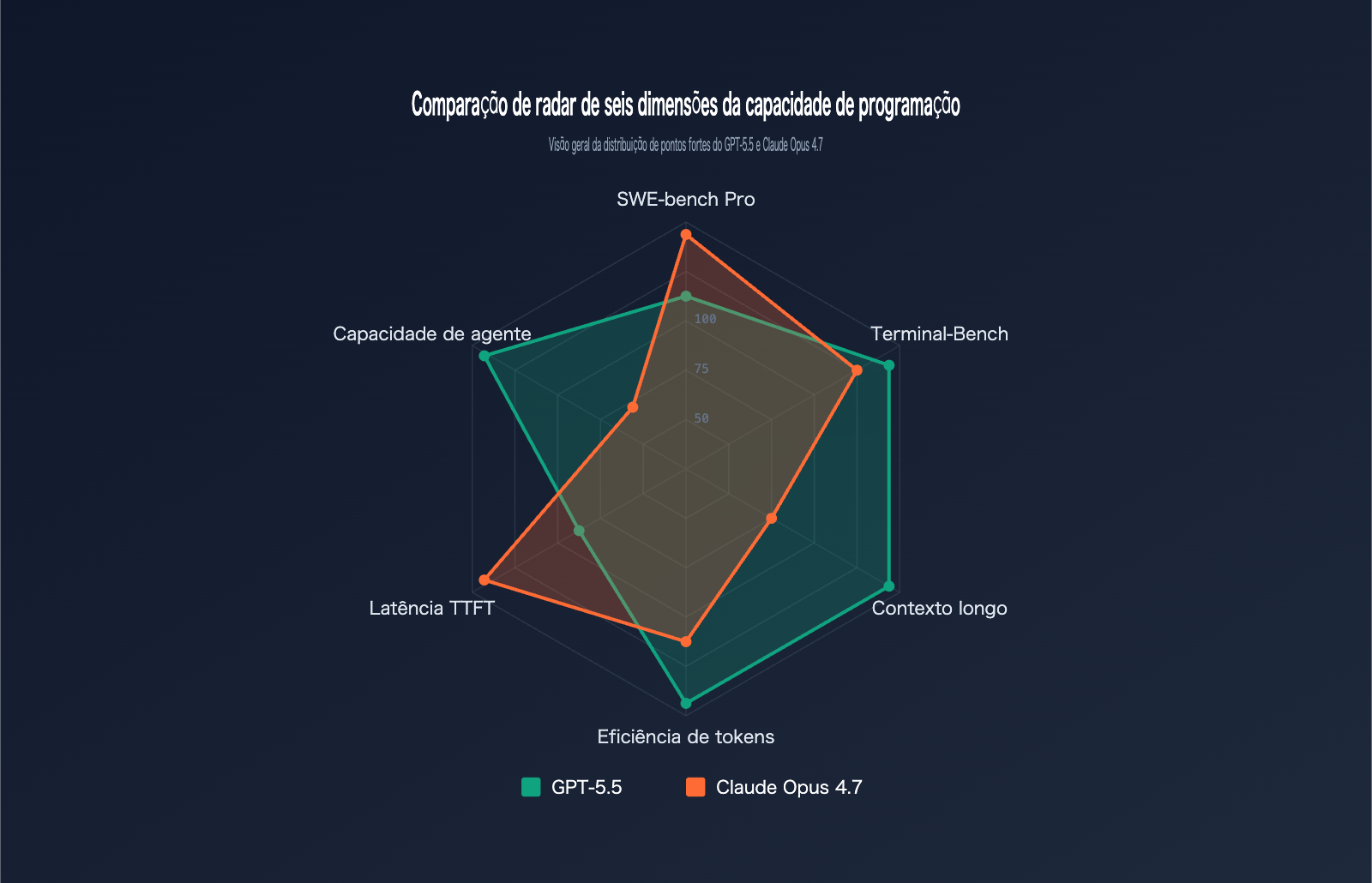
Comparativo de desempenho: GPT-5.5 vs. Claude Opus 4.7
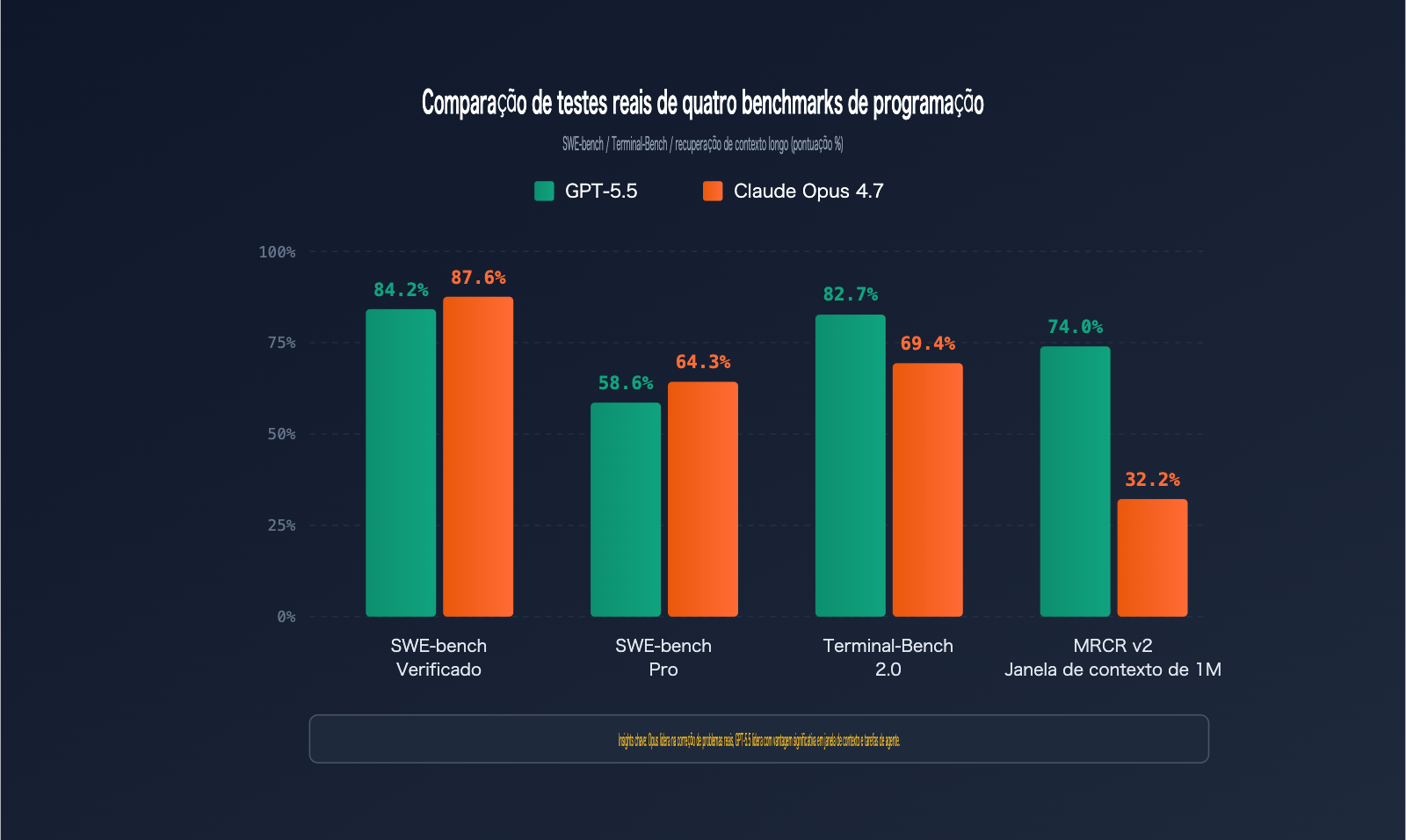
Os benchmarks são a régua mais objetiva para medir a capacidade de programação. Reunimos os dados oficiais dos dois modelos em 6 dos principais benchmarks de codificação:
| Benchmark | Conteúdo do teste | GPT-5.5 | Claude Opus 4.7 | Vencedor |
|---|---|---|---|---|
| SWE-bench Verified | Correção verificada de issue no GitHub | 84,2% | 87,6% | Opus 4.7 |
| SWE-bench Pro | Correção de issue complexa em múltiplos arquivos | 58,6% | 64,3% | Opus 4.7 |
| Terminal-Bench 2.0 | Fluxo de trabalho de comandos no terminal | 82,7% | 69,4% | GPT-5.5 |
| Expert-SWE | Programação de longa duração (mediana de 20h) | 73,1% | – | GPT-5.5 |
| OSWorld-Verified | Tarefas de agente em desktop | 78,7% | 78,0% | GPT-5.5 (por pouco) |
| MRCR v2 (512K-1M) | Recuperação de 8-needle em contexto longo | 74,0% | 32,2% | GPT-5.5 |
Análise prática: SWE-bench Pro
O SWE-bench Pro é o padrão ouro para avaliar a capacidade de um modelo de resolver issues reais no GitHub. O Claude Opus 4.7 lidera com 64,3% frente aos 58,6% do GPT-5.5, o que significa que, a cada 100 tarefas de correção de bugs reais, o Opus 4.7 consegue resolver cerca de 6 a mais.
O mais importante é que o Opus 4.7 teve um ganho expressivo de 10,9 pontos percentuais em relação à versão anterior (Opus 4.6, com 53,4%), um salto raro em uma única iteração. Para equipes cujo fluxo de trabalho principal é a correção de issues no GitHub, o Claude Opus 4.7 é a escolha ideal no momento.
Dica de teste: Quer verificar a diferença de desempenho entre os modelos no seu próprio código? Você pode fazer testes paralelos pela plataforma APIYI (apiyi.com), que suporta chamadas de interface unificadas para GPT-5.5 e Claude Opus 4.7, facilitando a comparação rápida.
Análise prática: Terminal-Bench 2.0
O Terminal-Bench 2.0 avalia a capacidade do modelo de concluir tarefas complexas em ambiente de terminal, incluindo planejamento, iteração e coordenação de ferramentas. O GPT-5.5 lidera com 82,7%, superando os 69,4% do Opus 4.7 por uma margem de 13 pontos percentuais.
Essa diferença vem das otimizações do GPT-5.5 nos fluxos de trabalho de agentes: ele é mais preciso na escolha de ferramentas, mais estável no manuseio de tarefas de várias etapas e mais confiável na recuperação de erros. Se o seu fluxo de trabalho envolve muitos comandos shell, operações de arquivo e integração de CI/CD, o GPT-5.5 é a escolha mais segura.
Diferença na capacidade de recuperação em contexto longo
No teste MRCR v2 de recuperação 8-needle em um intervalo de 512K a 1M de tokens, o GPT-5.5 superou o Opus 4.7 com 74,0% contra 32,2% — um abismo de 41,8 pontos percentuais.
Isso significa que, se você precisa que o modelo entenda todo o seu repositório de código (500K+ tokens), o GPT-5.5 possui uma precisão de recall significativamente maior para contextos profundos. Para cenários como "refatoração baseada em monorepo completo", a diferença não é apenas de qualidade, mas de viabilidade técnica.
Recomendações Práticas: GPT-5.5 vs. Claude Opus 4.7 em Cenários de Programação
Dados de benchmark só fazem sentido quando aplicados a cenários concretos. A tabela abaixo apresenta recomendações claras para 5 tipos de cenários típicos de programação:
| Cenário de Programação | Modelo Recomendado | Razão Principal | Ganho Esperado |
|---|---|---|---|
| Correção de Issue no GitHub | Claude Opus 4.7 | 5,7 pontos percentuais à frente no SWE-bench Pro | Aumento de 10% na taxa de sucesso |
| Refatoração de Codebase grande | Claude Opus 4.7 | Capacidade superior de raciocínio de arquitetura entre arquivos | Menor risco de quebra de arquitetura |
| Fluxos de automação Agentic | GPT-5.5 | 13,3 pontos percentuais à frente no Terminal-Bench | Maior estabilidade em tarefas de múltiplas etapas |
| Compreensão de longo contexto (>500K) | GPT-5.5 | 41,8 pontos percentuais à frente no MRCR v2 | Recuperação confiável de contexto profundo |
| Pair Programming interativo | Claude Opus 4.7 | TTFT de apenas 0,5s, resposta mais rápida | Ritmo de codificação mais fluido |
| Geração de código em massa | GPT-5.5 | 72% mais eficiente em tokens, menor custo | Melhor custo-benefício geral |
Cenário 1: Correção de Issues reais no GitHub → Escolha Claude Opus 4.7
Se a sua necessidade principal é "receber a descrição de uma issue e fazer com que a IA forneça um PR pronto para merge", o Claude Opus 4.7 é a escolha indiscutível. Sua pontuação de 87,6% no SWE-bench Verified significa que cerca de nove em cada dez tarefas de correção de bugs bem definidas podem ser entregues diretamente.
Vale ressaltar que 87,6% não significa que 87,6% do seu trabalho de engenharia pode ser automatizado — este é um teste ideal baseado em "especificações de tarefas perfeitas". No fluxo de trabalho real, a qualidade da descrição da issue afetará significativamente a taxa de sucesso.
Cenário 2: Compreensão de código com longo contexto → Escolha GPT-5.5
Quando você precisa que o modelo leia todo o monorepo (geralmente 500K-1M tokens) antes de tomar uma decisão, o GPT-5.5 é a única opção confiável no momento. A precisão de busca "8-needle" do Opus 4.7 no intervalo de 1M de contexto é de apenas 32,2%, o que significa que o modelo provavelmente "não enxergará" definições cruciais escondidas nas profundezas do código.
Essa lacuna é de nível arquitetural — se o seu fluxo de trabalho depende de uma visão completa da base de código (como renomeação global ou verificação de compatibilidade de API), o uso do Opus 4.7 pode simplesmente impedir o funcionamento do processo.
Cenário 3: Fluxo de trabalho de programação Agentic → Escolha GPT-5.5
Programação "Agentic" refere-se a fluxos onde a IA planeja, invoca ferramentas e corrige erros autonomamente. A pontuação de 82,7% do GPT-5.5 no Terminal-Bench 2.0 supera em muito o Opus 4.7, com desempenho estável especialmente em:
- Escrita e execução de scripts de implantação automatizada
- Depuração de múltiplos serviços e análise de logs
- Resolução de problemas em pipelines de CI/CD
- Construção e monitoramento de pipelines de dados
Dica de integração: Ao construir fluxos de programação Agentic, recomendo usar o GPT-5.5 através de plataformas agregadoras como a APIYI (apiyi.com), facilitando o gerenciamento unificado da chave API, o monitoramento de custos de invocação e a alternância entre modelos reserva conforme a necessidade.
Cenário 4: Pair Programming interativo → Escolha Claude Opus 4.7
A experiência de codificação interativa é extremamente sensível à latência. O TTFT (latência até o primeiro token) do Opus 4.7 é de cerca de 0,5 segundos, enquanto o do GPT-5.5 é de aproximadamente 3 segundos. Essa diferença de 6 vezes é muito perceptível em cenários de interação frequente.
Se você usa ferramentas como Cursor, Claude Code ou Continue para preenchimento frequente de pequenos blocos de código, a baixa latência do Opus 4.7 proporcionará um ritmo de codificação muito mais fluido.

Exemplos de invocação do GPT-5.5 e do Claude Opus 4.7
Abaixo, apresento exemplos de invocação extremamente simplificados para você testar os dois modelos rapidamente. Ambos são compatíveis com o formato do SDK da OpenAI, o que torna a migração muito fácil.
Invocação simplificada do GPT-5.5
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implemente um quicksort em Python"}]
)
print(response.choices[0].message.content)
Invocação simplificada do Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implemente um quicksort em Python"}]
)
print(response.choices[0].message.content)
Ver código de teste comparativo paralelo entre os dois modelos
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Testa o tempo de resposta e o tamanho da saída de um único modelo"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Teste comparativo de capacidade de programação
test_prompt = """
Por favor, implemente uma classe de cache LRU em Python, garantindo que:
1. Suporte aos métodos get(key) e put(key, value)
2. Descarte automaticamente o item usado há mais tempo quando a capacidade estiver cheia
3. Complexidade de tempo O(1) para todas as operações
4. Inclua testes unitários completos
"""
# Teste paralelo dos dois modelos
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
Dica de teste: Obtenha créditos de teste gratuitos através da APIYI (apiyi.com). Você pode testar o GPT-5.5 e o Claude Opus 4.7 em paralelo na mesma conta, usando o mesmo
base_urlechave API, sem a necessidade de solicitar contas separadas na OpenAI ou na Anthropic.
Análise abrangente de custos: GPT-5.5 vs. Claude Opus 4.7
O preço da API é um fator decisivo na seleção de um modelo. À primeira vista, o Opus 4.7 parece 17% mais barato na saída de tokens, mas a análise detalhada revela uma realidade diferente:
| Dimensão de custo | GPT-5.5 | Claude Opus 4.7 | Impacto real |
|---|---|---|---|
| Preço de entrada | $5/M tokens | $5/M tokens | Empatado |
| Preço de saída | $30/M tokens | $25/M tokens | Opus 17% mais barato |
| >200K de prompt | Mantém preço original | Dobra para $10/$37.50 | GPT superior em contexto longo |
| Tokens de saída p/ tarefa | 100% (base) | 72% a mais que GPT | GPT é mais barato no geral |
| Latência TTFT | ~3 segundos | ~0.5 segundos | Melhor experiência com Opus |
| Custo real em volume | 1.0x (base) | 1.4-1.5x (base) | GPT gera mais economia |
Descobertas chave na comparação de custos
A eficiência dos tokens altera a essência da comparação de preços. Em tarefas de programação equivalentes, o GPT-5.5 consome, em média, 72% menos tokens de saída do que o Opus 4.7. Mesmo com o preço unitário do Opus sendo 17% menor, ao multiplicar pelo volume de tokens 1,72 vezes maior, o custo real da tarefa no GPT-5.5 acaba sendo mais baixo.
A diferença se amplia em cenários de contexto longo. Quando o comando excede 200 mil tokens, os preços de entrada e saída do Opus 4.7 dobram para $10 e $37,50, enquanto o GPT-5.5 mantém seus preços originais. Para fluxos de trabalho que exigem compreensão de contextos extensos (como a análise completa de um monorepo), a vantagem de custo do GPT-5.5 pode ser de 2 a 3 vezes superior.
Interpretação da comparação
Características de custo do Claude Opus 4.7: O preço por token é competitivo entre os modelos de ponta. No entanto, em cenários de geração em larga escala, o alto consumo de tokens eleva o custo total; em contextos longos, o mecanismo de dobrar o preço após 200 mil tokens aumenta significativamente a pressão orçamentária.
Características de custo do GPT-5.5: O preço por token é ligeiramente superior, mas sua excelente eficiência de uso de tokens e a política de não aumentar o preço em contextos longos tornam o custo total mais baixo em cenários de escala e longa duração. A OpenAI claramente projetou sua precificação considerando a estrutura de custos de fluxos de trabalho do tipo Agente.
Sugestão de estimativa de custos: O custo real do projeto depende de vários fatores, como o tamanho do comando, o tamanho da saída e a frequência de invocação. Recomendamos acessar ambos os modelos pela plataforma APIYI (apiyi.com), que oferece faturas detalhadas de consumo, facilitando a tomada de decisão baseada em dados reais.
Perguntas Frequentes (FAQ)
Q1: Qual dos modelos, GPT-5.5 ou Claude Opus 4.7, tem maior capacidade de programação?
Não existe um "melhor" absoluto; tudo depende da tarefa específica. O Claude Opus 4.7 lidera no SWE-bench Pro (64,3% vs 58,6%) e no Verified (87,6%), sendo mais adequado para corrigir problemas reais no GitHub e realizar refatoração de grandes bases de código. O GPT-5.5 se destaca no Terminal-Bench 2.0 (82,7% vs 69,4%) e na recuperação de contextos longos (74,0% vs 32,2%), sendo ideal para fluxos de programação com agentes (Agentic) e compreensão de código em todo um monorepo.
Q2: Quais são as diferenças de preços da API entre o GPT-5.5 e o Claude Opus 4.7?
Ambos cobram $5/M para tokens de entrada. Nos tokens de saída, o Opus 4.7 ($25/M) é 17% mais barato que o GPT-5.5 ($30/M). No entanto, o preço do Opus 4.7 dobra quando o comando (prompt) ultrapassa 200K, enquanto o GPT-5.5 mantém o preço original. Considerando ainda que o GPT-5.5 consome 72% menos tokens de saída, o custo total do GPT-5.5 é menor em tarefas de grande escala.
Q3: Quando o GPT-5.5 e o Claude Opus 4.7 foram lançados?
O Claude Opus 4.7 foi lançado pela Anthropic em 16 de abril de 2026, estando disponível em Claude API, Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry. O GPT-5.5 (codinome interno Spud) foi lançado pela OpenAI em 23 de abril de 2026. Os dois modelos de programação de elite foram lançados com apenas 7 dias de diferença, marcando uma competição acirrada.
Q4: Em quais cenários de programação devo escolher o Claude Opus 4.7?
Priorize o Opus 4.7 nos seguintes cenários:
- Correção de issues do GitHub: Liderança de 5,7 pontos percentuais no SWE-bench Pro.
- Refatoração de grandes bases de código: Capacidade superior de inferência de arquitetura entre arquivos.
- Programação em dupla (Pair Programming) interativa: TTFT de apenas 0,5 segundos, sendo 6 vezes mais rápido na resposta.
- Revisão de qualidade de código: Pontuações mais altas em testes reais de Rakuten-SWE-Bench.
Q5: Como realizar chamadas de API rapidamente para o GPT-5.5 e o Claude Opus 4.7?
Recomendamos utilizar uma plataforma de agregação de API que suporte ambos os modelos para realizar testes:
- Acesse a APIYI em apiyi.com para criar uma conta.
- Obtenha sua chave API unificada e créditos de teste gratuitos.
- Utilize o código de exemplo deste artigo (substituindo o
base_urlporhttps://vip.apiyi.com/v1) e especifique o modelo comogpt-5.5ouclaude-opus-4-7para realizar a invocação do modelo.
A APIYI suporta interfaces unificadas para modelos populares como OpenAI, Anthropic e Google, permitindo que você compare o desempenho real do GPT-5.5 e do Claude Opus 4.7 sem a necessidade de solicitar várias contas separadamente.
Q6: Quais são as limitações conhecidas do GPT-5.5 e do Claude Opus 4.7?
Limitações do GPT-5.5:
- Latência TTFT de cerca de 3 segundos, tornando a experiência em cenários interativos mais lenta.
- Desempenho inferior ao Opus 4.7 na correção de problemas reais no SWE-bench.
Limitações do Claude Opus 4.7:
- Capacidade de recuperação de contexto longo limitada (32,2% no alcance de 1M).
- Dobro do preço quando o comando (prompt) >200K, gerando pressão de custo em contextos longos.
- Alto consumo de tokens de saída, elevando o custo em tarefas de grande volume.
- Desempenho em tarefas de agentes (Agentic) no Terminal-Bench inferior ao GPT-5.5.
Q7: É necessário utilizar o GPT-5.5 e o Claude Opus 4.7 simultaneamente?
Para equipes de desenvolvimento profissional, recomendamos fortemente o uso de ambos. Uma estratégia de divisão de trabalho típica seria: usar o Opus 4.7 para correção de issues do GitHub, revisão de código e decisões arquiteturais cruciais; e usar o GPT-5.5 para análise de contexto longo, fluxos de automação de agentes e geração de código em grande escala. Esse modelo híbrido permite aproveitar as forças de cada um, alcançando um equilíbrio entre custo e experiência.
Pontos Principais do GPT-5.5 e Claude Opus 4.7
- Para correção de Issues reais, use o Opus: O Claude Opus 4.7 lidera no SWE-bench Pro e Verified, sendo a escolha ideal para corrigir problemas reais no GitHub.
- Para programação com Agentes, use o GPT: O GPT-5.5 lidera com 13 pontos percentuais no Terminal-Bench 2.0, oferecendo invocações de ferramentas mais estáveis.
- Para contexto longo, use o GPT: Nos testes MRCR v2, o GPT-5.5 (74%) supera amplamente o Opus (32,2%), sendo a única escolha confiável para um contexto de 1M.
- Para baixa latência, use o Opus: O TTFT do Opus é de apenas 0,5 segundos, 6 vezes mais rápido que o GPT, proporcionando uma experiência de codificação mais fluida.
- Para sensibilidade a custos, use o GPT: O GPT-5.5 consome 72% menos tokens de saída que o Opus, tornando o custo de tarefas complexas menor.
- Testes paralelos rápidos: Através da APIYI (apiyi.com), você pode invocar ambos os modelos com uma única conta, facilitando comparações em cenários reais.
Resumo
Conclusões principais sobre a comparação das capacidades de programação entre o GPT-5.5 e o Claude Opus 4.7:
- Não existe um campeão absoluto: Ambos os modelos possuem áreas de força bem definidas; buscar cegamente pelo "melhor modelo" é um equívoco.
- Seleção baseada em tarefas: Defina primeiro o seu cenário principal de programação (correção de issues / fluxos Agentic / contexto longo / interatividade) antes de decidir qual será o seu modelo principal.
- Recomendamos o uso paralelo: Equipes de desenvolvimento profissional devem integrar ambos os modelos, roteando as tarefas para a opção ideal conforme o cenário, maximizando a produtividade.
Se você puder escolher apenas um: para tarefas diárias focadas em correção de issues no GitHub e revisão de código, escolha o Claude Opus 4.7; para automação via Agentic e análise de janelas de contexto longas, escolha o GPT-5.5.
Recomendamos utilizar o APIYI (apiyi.com) para validar rapidamente a sua escolha. A plataforma oferece interfaces unificadas para o GPT-5.5 e o Claude Opus 4.7, além de créditos de teste gratuitos e faturamento detalhado, sendo o caminho mais prático para tomar decisões de seleção baseadas em dados.
Leitura Complementar
Se você se interessou pela comparação de programação entre o GPT-5.5 e o Claude Opus 4.7, recomendamos a leitura dos artigos a seguir:
- 📘 Análise completa do Claude Opus 4.7: A engenharia por trás dos 87,6% no SWE-bench – Uma análise profunda sobre a origem das capacidades do Opus 4.7.
- 📊 Guia prático do GPT-5.5 Spud: 8 dicas para dominar o novo rei da programação Agentic – Domine o uso avançado do GPT-5.5.
- 🚀 Guia de seleção de modelos de programação com IA 2026: Comparativo panorâmico de GPT a Claude – Explore uma metodologia mais abrangente para a seleção de modelos.
📚 Referências
-
Introdução oficial do GPT-5.5 da OpenAI: Benchmark principal e descrição de capacidades
- Link:
openai.com/index/introducing-gpt-5-5 - Descrição: Documentação oficial de lançamento do GPT-5.5, incluindo benchmarks centrais como SWE-bench e Terminal-Bench.
- Link:
-
Notas de lançamento do Claude Opus 4.7 da Anthropic: Posicionamento do modelo e dados de desempenho
- Link:
anthropic.com/news/claude-opus-4-7 - Descrição: Documentação oficial de lançamento do Opus 4.7, contendo dados detalhados do SWE-bench Verified/Pro.
- Link:
-
Ranking público do SWE-Bench Pro: Validação independente de terceiros
- Link:
labs.scale.com/leaderboard/swe_bench_pro_public - Descrição: Ranking público do SWE-Bench Pro mantido pela Scale AI, onde é possível verificar a classificação real de ambos os modelos.
- Link:
-
Vellum LLM Leaderboard 2026: Comparação abrangente de Modelos de Linguagem Grande
- Link:
vellum.ai/llm-leaderboard - Descrição: Plataforma de comparação abrangente que cobre múltiplas dimensões, como programação, raciocínio e janela de contexto.
- Link:
-
Comparação de modelos da Artificial Analysis: Análise de desempenho e custo
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Descrição: Oferece dados de comparação granulares sobre TTFT, taxa de transferência (throughput) e custo total.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimento técnico: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite o centro de documentação da APIYI em docs.apiyi.com