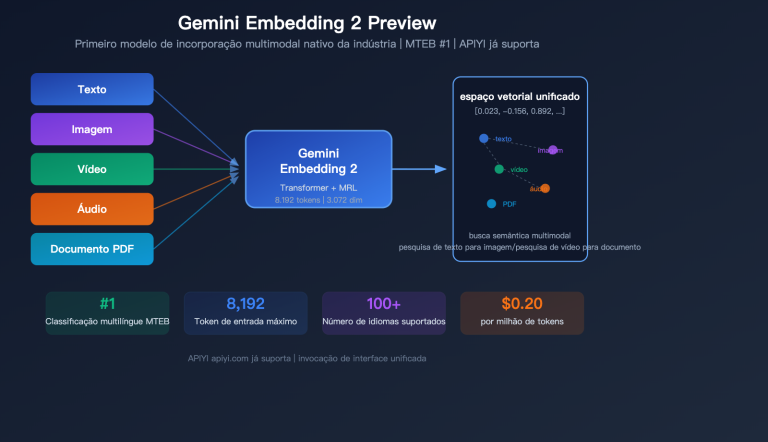
Nota do autor: GPT-5.4 ou Claude Opus 4.6? O confronto direto dos dois modelos de IA topo de linha mais aguardados de 2026. Este artigo reúne os dados reais mais recentes do Chatbot Arena, SWE-bench, ARC-AGI-2 e OpenClaw PinchBench, oferecendo recomendações claras de escolha baseadas em quatro dimensões: programação, raciocínio, tarefas de agentes e custo-benefício.

GPT-5.4 vs Claude Opus 4.6: Visão rápida das principais diferenças
Ao escolher um modelo de IA topo de linha, as dimensões mais críticas ficam claras num relance:
| Dimensão de Comparação | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Lançamento | Final de 2025 | Fevereiro de 2026 |
| Chatbot Arena ELO | 1463 | 1503 (#1) |
| Índice de Inteligência Geral | 57 | 53 |
| Preço de Entrada (API) | $2.50/M tokens | $5.00/M tokens |
| Preço de Saída (API) | $15.00/M tokens | $25.00/M tokens |
| Janela de Contexto | ~1M tokens | 200K (1M Beta) |
| Saída Máxima | — | 128K tokens |
| Status | Ativo | Ativo |
Conclusão principal: O GPT-5.4 possui um índice de inteligência geral superior e é cerca de 50% mais barato; o Claude Opus 4.6 lidera a satisfação do usuário no Chatbot Arena globalmente, sendo superior em programação complexa e tarefas de agentes.
🎯 Dica rápida: Se você é um desenvolvedor atento aos custos, o GPT-5.4 oferece o melhor custo-benefício; se o seu projeto exige geração de código complexo ou processamento de documentos longos, o Opus 4.6 vale o investimento. Recomendamos usar a APIYI (apiyi.com) para acessar ambos os modelos simultaneamente e realizar testes comparativos reais, já que a plataforma permite alternar rapidamente usando uma interface de API unificada.
Benchmarks Oficiais: GPT-5.4 vs Claude Opus 4.6 – Comparação Completa
Comparativo de Raciocínio e Conhecimento
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Descrição |
|---|---|---|---|
| GPQA Diamond (Ciências nível pós-graduação) | 93.2% | 91.3% | GPT-5.4 vence |
| MMLU (Conhecimento enciclopédico) | 89.6% | 91.1% | Opus 4.6 vence |
| ARC-AGI-2 (Raciocínio abstrato) | 52.9% | 68.8% | Opus 4.6 lidera com folga |
| BigLaw Bench (Especialização jurídica) | — | 90.2% | Vantagem específica do Opus 4.6 |
| MRCR v2 (1M de janela de contexto) | — | 76% | Opus 4.6 lidera em documentos longos |
| GDPval-AA ELO (Tarefas profissionais) | 1462 | 1606 | Opus 4.6 é visivelmente superior |
Análise: O GPT-5.4 possui uma leve vantagem em raciocínio científico (GPQA Diamond), mas o Claude Opus 4.6 apresenta um desempenho superior em raciocínio abstrato (com 16 pontos percentuais à frente no ARC-AGI-2), trabalhos de conhecimento especializado e processamento de janela de contexto longa.
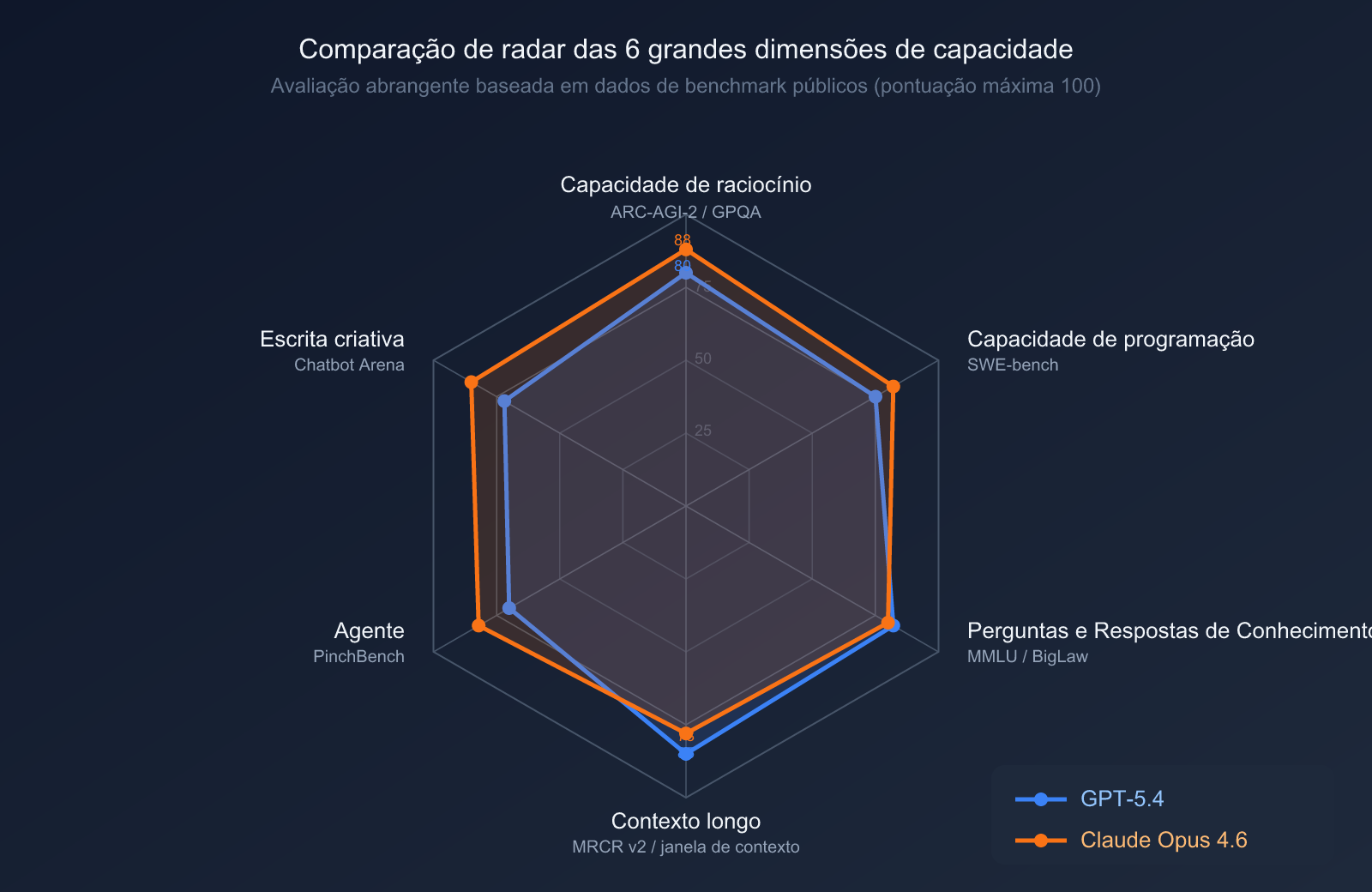
Comparativo de Programação e Capacidades de Agente
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Descrição |
|---|---|---|---|
| SWE-bench Verified (Correção de código real) | ~77.2% | 80.8% | Opus 4.6 vence |
| SWE-bench Pro (Código de nível profissional) | 57.7% | ~45% | GPT-5.4 vence |
| Terminal-Bench 2.0 (Operações de terminal) | 64.7% | 65.4% | Opus 4.6 vence por pouco |
| OSWorld (Controle de computador) | 75.0% | 72.7% | GPT-5.4 vence por pouco |
| BrowseComp (Pesquisa e navegação web) | 77.9% | 84.0% | Opus 4.6 vence |
| OpenRCA (Análise de causa raiz) | — | 34.9% | Vantagem específica do Opus 4.6 |
Análise: Ambos os modelos possuem focos distintos na área de programação. O Opus 4.6 é mais forte no SWE-bench Verified (correções de bugs cotidianos), enquanto o GPT-5.4 lidera no SWE-bench Pro (código complexo de nível empresarial). No controle de computador, o GPT-5.4 leva uma pequena vantagem, mas o Opus 4.6 se destaca em pesquisa web e análise de causa raiz.
💡 Dica para Desenvolvedores: Para tarefas de geração de código voltadas à entrega de produtos, recomendamos testar ambos os modelos através da interface unificada da APIYI (apiyi.com). Assim, você pode decidir com base nas particularidades da sua base de código, com um custo de apenas 60-80% em comparação à invocação direta das APIs oficiais da Anthropic ou OpenAI.
OpenClaw na Prática: Dados Recentes do Benchmark PinchBench
O que são OpenClaw e PinchBench?
OpenClaw é uma plataforma de agentes de IA de código aberto e auto-hospedável (semelhante ao Claude Code), que suporta acesso via terminal, edição de múltiplos arquivos e integração com mais de 50 ferramentas como WhatsApp, Telegram e Slack. Criado pelo desenvolvedor austríaco Peter Steinberger em novembro de 2025, o projeto está crescendo rapidamente no GitHub.
PinchBench é um benchmark projetado especificamente para agentes OpenClaw, desenvolvido pela Kilo.ai. Diferente dos benchmarks tradicionais que testam perguntas e respostas simples, ele avalia o desempenho do modelo em tarefas do mundo real com múltiplos passos:
- Agendamento de reuniões e gerenciamento de calendário
- Escrita de projetos de código com múltiplos arquivos
- Classificação de e-mails e gerenciamento de arquivos
- Pesquisa na web e integração de informações
Este é um dos testes que mais se aproxima dos cenários reais de uso de Agentes de IA atualmente.
Ranking PinchBench (13 de março de 2026, 47 modelos, 277 execuções)
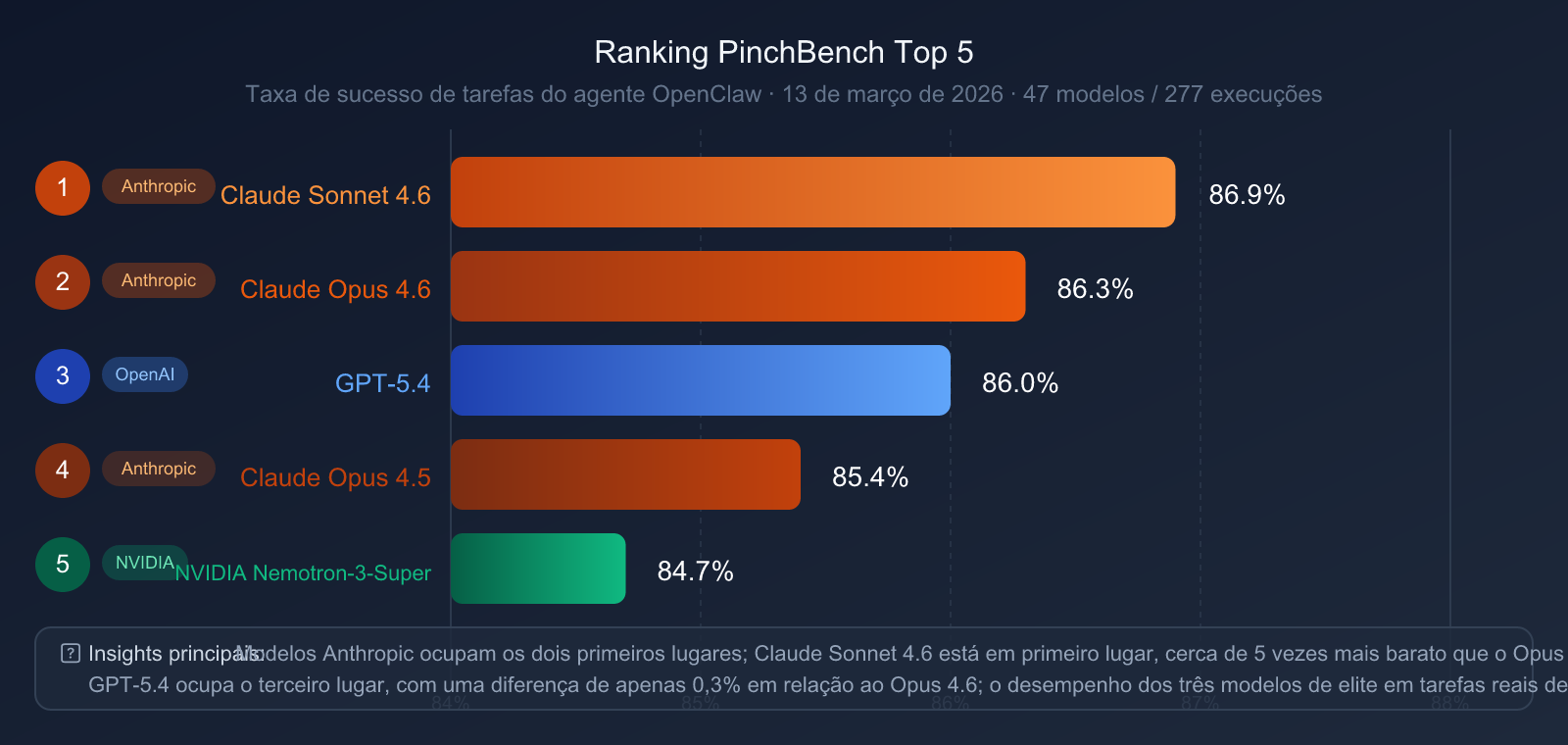
| Ranking | Modelo | Taxa de Sucesso PinchBench |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% |
| 🥈 2 | Claude Opus 4.6 | 86.3% |
| 🥉 3 | GPT-5.4 | 86.0% |
| 4 | Claude Opus 4.5 | 85.4% |
| 5 | NVIDIA Nemotron-3-Super | 84.7% |
Principais Descobertas:
- Série Claude domina o Top 2: Sonnet 4.6 e Opus 4.6 ocupam o primeiro e segundo lugares, respectivamente, demonstrando a vantagem sistemática da Anthropic em engenharia de agentes.
- GPT-5.4 em terceiro lugar: Apenas 0,3 pontos percentuais atrás do Opus 4.6, uma diferença mínima.
- Destaque no custo-benefício: O Claude Sonnet 4.6 (cerca de 5 vezes mais barato que o Opus 4.6) teve um desempenho superior no PinchBench, provando que nem sempre o mais caro é o melhor.
- Reavaliando o Claude Sonnet 4.6: Para tarefas de agentes como as do OpenClaw, o Sonnet 4.6 é a escolha com melhor custo-benefício.
🔍 Recomendação para Projetos de Agentes: Se você está construindo um Agente de IA baseado no OpenClaw, a diferença entre os três principais modelos (Sonnet 4.6, Opus 4.6, GPT-5.4) é inferior a 1%. Recomendamos o acesso sob demanda via APIYI (apiyi.com), permitindo escolher o modelo dinamicamente conforme o tipo de tarefa, reduzindo custos e mantendo uma alta taxa de sucesso.
Chatbot Arena ELO: Os modelos mais fortes escolhidos por votos reais de usuários
O Chatbot Arena (antigo LMSYS) é atualmente o ranking mais respeitado de preferência de usuários para modelos de IA, gerando pontuações ELO através de milhões de votos em testes cegos de conversas reais.
Ranking mais recente de fevereiro de 2026 (Top 5):
| Posição | Modelo | Pontuação ELO |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
O Claude Opus 4.6 lidera com uma vantagem de 40 pontos ELO sobre o GPT-5.4, destacando-se especialmente em diálogos de múltiplos turnos, controle de estilo e escrita criativa. Essa diferença é considerada uma vantagem significativa no sistema de avaliação do Chatbot Arena.
GPT-4.5 (Referência histórica): O GPT-4.5 (codinome "Orion"), lançado pela OpenAI em fevereiro de 2025, focava em inteligência emocional e qualidade de diálogo, chegando a liderar brevemente o Chatbot Arena no início. No entanto, esse modelo foi descontinuado da API em 14 de julho de 2025 e removido completamente do ChatGPT em agosto de 2025. O GPT-5.4 é seu sucessor atual, superando-o em todas as capacidades.
Preços de API e Custo-benefício: Como escolher para projetos sensíveis a custos
| Item de Custo | GPT-5.4 | Claude Opus 4.6 | Diferença |
|---|---|---|---|
| Preço de entrada (por milhão de tokens) | $2.50 | $5.00 | Opus 4.6 é 2x mais caro |
| Preço de saída (por milhão de tokens) | $15.00 | $25.00 | Opus 4.6 é 1.67x mais caro |
| Janela de contexto | ~1M tokens | 200K (1M Beta) | GPT-5.4 vence |
| Comprimento máximo de saída | — | 128K tokens | Opus 4.6 vence |
| Suporte multimodal | ✅ Entrada de imagem | ✅ Entrada de imagem | Equivalente |
Estimativa de custo (processamento diário de 1 milhão de tokens de entrada + 200 mil tokens de saída):
- GPT-5.4: cerca de $5.50/dia (média mensal de $165)
- Claude Opus 4.6: cerca de $10.00/dia (média mensal de $300)
💰 Plano de otimização de custos: Para projetos de alta concorrência ou com orçamento limitado, recomendamos usar o Claude Sonnet 4.6 no APIYI (apiyi.com) para tarefas rotineiras, reservando a invocação do modelo Opus 4.6 apenas quando a capacidade de raciocínio mais forte for necessária. Isso pode reduzir os custos de API em 60-75%. O APIYI suporta faturamento unificado para múltiplos modelos na mesma conta, facilitando o gerenciamento detalhado de custos.
Recomendação de Cenários: GPT-5.4 vs Claude Opus 4.6 – Qual escolher?
Cenários para priorizar o GPT-5.4
✅ Tarefas gerais com alto custo-benefício
- Orçamento limitado, mas com necessidade de capacidades de nível flagship.
- Criação de conteúdo diário, FAQ de atendimento ao cliente, extração de informações.
- Economia de custos significativa quando o gasto mensal com invocação do modelo via API ultrapassa US$ 500.
✅ Pesquisa científica e perguntas técnicas
- Liderança no GPQA Diamond, com raciocínio científico de nível de doutorado mais robusto.
- Perguntas e respostas especializadas em áreas acadêmicas como química, física e biologia.
✅ Código complexo de nível empresarial (Liderança no SWE-bench Pro)
- Processamento de modificações em nível de arquitetura em bases de código de escala ultra-grande.
- Tarefas de refatoração que exigem compreensão profunda de dependências complexas.
✅ Cenários de contexto ultra-longo
- Necessidade de processar documentos ou bases de código próximos a 1 milhão de tokens.
- A janela de contexto de 1M do Opus 4.6 ainda está em fase Beta.
Cenários para priorizar o Claude Opus 4.6
✅ Geração e correção de código em nível de produção
- SWE-bench Verified de 80,8%, tornando a correção de bugs e o desenvolvimento de funcionalidades no dia a dia mais confiáveis.
- Capacidade de pesquisa web de 84% no BrowseComp, ideal para aplicações aprimoradas com RAG.
✅ Projetos de agentes inteligentes (tipo OpenClaw)
- Top 2 no PinchBench; os modelos da Anthropic são sistematicamente superiores em tarefas reais de Agent.
✅ Produtos que exigem alta qualidade de diálogo
- Chatbot Arena ELO 1503, ocupando o primeiro lugar mundial em satisfação do usuário.
- Maior coerência em diálogos de múltiplos turnos e melhor capacidade de adaptação de estilo.
✅ Trabalho de conhecimento especializado
- Liderança de 16 pontos percentuais no ARC-AGI-2, demonstrando raciocínio abstrato mais forte.
- BigLaw Bench de 90,2%, sendo mais confiável para análise jurídica, conformidade e documentos técnicos.
✅ Saída de documentos longos
- Saída máxima de 128K, ideal para gerar relatórios completos e documentos extensos.
🎯 Sugestão de decisão: Ambos os modelos têm seus pontos fortes, e a diferença se manifesta principalmente em tarefas específicas. Recomendamos realizar testes A/B através da plataforma APIYI (apiyi.com) antes do lançamento oficial. A plataforma oferece uma interface unificada que permite alternar rapidamente entre os modelos, ajudando você a encontrar a escolha ideal para o seu cenário de negócio.
Acesso Rápido: Use ambos os modelos simultaneamente via API unificada
Não é necessário registrar contas separadas na OpenAI e Anthropic. Através da APIYI, você pode acessar todos os modelos principais com uma interface unificada:
from openai import OpenAI
# Através da interface unificada da APIYI, suporte para GPT-5.4 e Claude Opus 4.6
client = OpenAI(
api_key="sua-chave-apiyi",
base_url="https://vip.apiyi.com/v1" # Endereço de acesso unificado da APIYI
)
# Invocação do Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Por favor, ajude-me a analisar possíveis bugs no código a seguir..."}
],
max_tokens=4096
)
# Invocação do GPT-5.4 (mesma interface, basta alterar o nome do modelo)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Por favor, ajude-me a analisar possíveis bugs no código a seguir..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Instruções de acesso: Defina o
base_urlcomohttps://vip.apiyi.com/v1e substitua aapi_keypela chave que você solicitou na APIYI (apiyi.com) para alternar com um clique. Há bônus no primeiro carregamento, facilitando o teste das diferenças reais entre os dois modelos antes da implementação oficial.
Tabela de Referência de Modelos:
| Modelo | Nome de chamada da API | Custo mensal médio (100M tokens/mês) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Aprox. $500+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
Aprox. $100+ |
| GPT-5.4 | gpt-5-4 |
Aprox. $250+ |
Perguntas Frequentes
P: O GPT-4.5 e o GPT-5.4 são o mesmo modelo?
Não. O GPT-4.5 (codinome "Orion") foi um modelo de transição lançado pela OpenAI em fevereiro de 2025, focado em inteligência emocional e qualidade de diálogo, com um preço extremamente elevado ($75/$150 por milhão de tokens). Ele foi oficialmente descontinuado da API em 14 de julho de 2025. O GPT-5.4 é o atual modelo flagship da OpenAI, com capacidades que superam totalmente o GPT-4.5 e um preço significativamente menor ($2.50/$15 por milhão de tokens). Se você precisa invocar o modelo mais potente da OpenAI, deve usar o GPT-5.4, disponível via APIYI (apiyi.com).
P: O que é o OpenClaw? Qual a diferença para o Cursor ou o Claude Code?
O OpenClaw é uma plataforma de agentes de IA de código aberto e auto-hospedada. Ele suporta acesso via terminal, edição de código em múltiplos arquivos e integração com mais de 50 ferramentas como WhatsApp, Telegram e Slack. Além disso, possui uma capacidade de "auto-evolução" para gerar novas habilidades automaticamente. Comparado ao Cursor (um plugin de IDE comercial) e ao Claude Code (CLI oficial da Anthropic), a principal vantagem do OpenClaw é ser totalmente open-source e permitir implantação privada, ideal para empresas com exigências rigorosas de segurança de dados. O PinchBench é o benchmark especializado em avaliar o desempenho de modelos de linguagem grande em tarefas de agentes no OpenClaw.
P: Para tarefas de escrita com IA, qual modelo é melhor?
De acordo com a pontuação ELO do Chatbot Arena, o Claude Opus 4.6 ocupa o primeiro lugar mundial com 1503 pontos nos testes de preferência dos usuários. Ele se destaca especialmente em escrita criativa, diálogos de múltiplos turnos e adaptação de estilo. O GPT-5.4 também é excelente em escrita, mas sua classificação de satisfação do usuário é ligeiramente inferior. Recomendamos testar ambos no seu cenário específico de escrita através da APIYI (apiyi.com), pois diferentes estilos e tipos de tarefas podem apresentar resultados variados.
P: Qual é a real diferença entre o Claude Sonnet 4.6 e o Claude Opus 4.6?
Olhando para os testes de agentes do PinchBench, o Sonnet 4.6 (86,9%) teve um desempenho ligeiramente superior ao Opus 4.6 (86,3%). No ELO do Chatbot Arena, o Sonnet 4.6 fica em torno de 1438, enquanto o Opus 4.6 atinge 1503 — uma diferença de cerca de 65 pontos. Para a maioria das tarefas de programação e análise, o Sonnet 4.6 é a escolha com melhor custo-benefício (custando cerca de 20% do preço do Opus 4.6). O upgrade para o Opus 4.6 só vale a pena em cenários de raciocínio complexo, processamento de documentos longos e requisitos de precisão extrema.
Resumo: Como escolher o modelo flagship em 2026?
| Cenário de Uso | Modelo Recomendado | Motivo Principal |
|---|---|---|
| Desenvolvimento diário + controle de custos | GPT-5.4 | 50% mais barato, capacidade geral forte |
| Correção de código complexo (SWE-bench) | Claude Opus 4.6 | 80,8% de eficácia, liderando contra 77,2% do GPT-5.4 |
| Tarefas de agentes de IA (OpenClaw) | Claude Sonnet 4.6 | 1º lugar no PinchBench e mais barato que o Opus |
| Produtos de chat / Satisfação do usuário | Claude Opus 4.6 | #1 no Chatbot Arena ELO (1503) |
| Pesquisa científica / Perguntas acadêmicas | GPT-5.4 | GPQA Diamond de 93,2%, liderança sutil |
| Análise de documentos ultra-longos | Claude Opus 4.6 | Saída de 128K + MRCR v2 de 76% |
| Raciocínio abstrato / Tarefas de AGI | Claude Opus 4.6 | ARC-AGI-2 de 68,8% vs 52,9% |
Conclusões principais:
- O GPT-5.4 é a escolha com o melhor custo-benefício geral. Seu índice de inteligência integrada é ligeiramente superior (57 vs 53) e o preço é quase metade do Opus 4.6.
- O Claude Opus 4.6 é o modelo com a maior satisfação do usuário no mundo (ELO 1503), apresentando vantagens claras em código complexo, agentes e raciocínio abstrato.
- Para a maioria dos projetos práticos, o Claude Sonnet 4.6 é a solução ideal — lidera o ranking PinchBench e custa muito menos que o Opus 4.6.
Não existe um modelo "sempre melhor", apenas o modelo mais adequado para o seu cenário.
🚀 Teste agora: Na plataforma APIYI (apiyi.com), você pode usar uma única chave API para acessar simultaneamente o GPT-5.4, Claude Opus 4.6 e Claude Sonnet 4.6. Compare o desempenho e o custo dos três modelos com seus dados reais de negócio. Novos usuários ganham créditos de teste ao se cadastrar para ajudar na melhor decisão antes do lançamento oficial.
Fonte dos dados: Documentação oficial da Anthropic, documentação da API da OpenAI, ranking Chatbot Arena (fevereiro de 2026), ranking PinchBench (13 de março de 2026), comparativos da Artificial Analysis e avaliações técnicas da DigitalApplied. Os dados podem mudar conforme as atualizações dos modelos; recomendamos consultar a documentação oficial mais recente.
Autor: Equipe APIYI | Publicado em AI123.dev