Nota do autor: Comparação aprofundada dos 3 modelos de IA mais fortes para resolução de problemas matemáticos em 2026, incluindo dados de benchmarks autoritativos como AIME e MATH, para ajudá-lo a encontrar o modelo de raciocínio matemático mais adequado.
Escolher qual modelo de IA usar para resolver problemas matemáticos é uma das decisões mais importantes para desenvolvedores e estudantes. Este artigo compara os três modelos de raciocínio matemático mais recentes lançados em 2026: Gemini 3.1 Pro Preview, Claude Sonnet 4.6 e GPT-5.4, fornecendo recomendações claras com base em pontuações de benchmark, capacidade de raciocínio, preço da API e cenários de aplicação.
Valor principal: Após ler este artigo, você saberá qual modelo de IA escolher para diferentes cenários de resolução de problemas matemáticos e como invocá-los com o custo mais otimizado.
Visão Rápida das Principais Comparações de Modelos de IA para Resolução de Matemática
Antes de entrarmos na análise detalhada, veja uma tabela comparativa de dados essenciais para entender rapidamente as diferenças-chave entre os três modelos de IA para resolução de matemática.
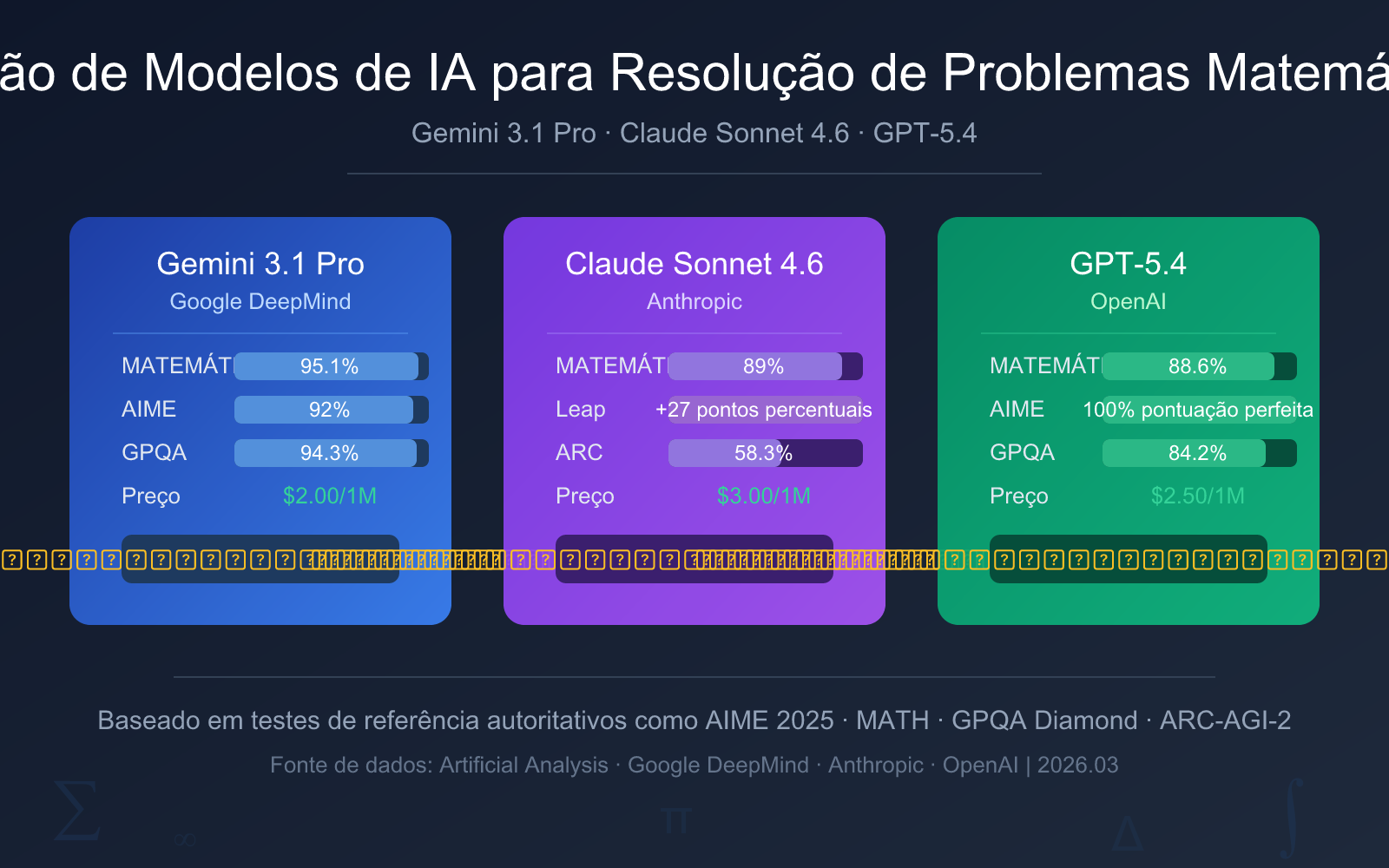
| Dimensão de Comparação | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Data de Lançamento | 19 de fevereiro de 2026 | Início de 2026 | 6 de março de 2026 |
| AIME 2025 | 92% (sem ferramentas) | — | 100% (pontuação perfeita) |
| Benchmark MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Preço de Entrada | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| Preço de Saída | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| Recomendação Geral | ⭐ Recomendação Principal | ⭐ Primeira Escolha para Aprendizado | ⭐ Primeira Escolha para Competições |
Ordenação Recomendada de Modelos de IA para Resolução de Matemática
Do ponto de vista da relação custo-benefício geral, sugerimos a seguinte ordem:
- Primeira Escolha: Gemini 3.1 Pro Preview: Lidera com 95.1% no benchmark MATH, preço mais baixo, capacidade matemática geral mais forte.
- Segunda Escolha: Claude Sonnet 4.6: Capacidade matemática aumentou 27 pontos percentuais, processo de resolução claro e fácil de entender, ideal para cenários de aprendizado.
- Nível Competição: GPT-5.4: Pontuação perfeita de 100% no AIME 2025, adequado para competições matemáticas de alta dificuldade e pesquisa profissional.
🎯 Recomendação Técnica: Todos os três modelos podem ser invocados de forma unificada através da plataforma APIYI apiyi.com. Recomendamos testar cada um em problemas matemáticos reais para escolher o modelo que melhor atende às suas necessidades.
Análise Detalhada da Capacidade de Resolução Matemática do Gemini 3.1 Pro Preview
O Gemini 3.1 Pro Preview é o mais recente modelo flagship lançado pelo Google DeepMind em 19 de fevereiro de 2026. Esta é a primeira vez que o Google usa um incremento de versão ".1" (anteriormente, atualizações intermediárias usavam ".5"), sinalizando que esta é uma atualização direcionada focada especificamente na capacidade de raciocínio inteligente.
Pontuações do Gemini 3.1 Pro em Testes de Benchmark Matemáticos
| Teste de Benchmark | Pontuação | Descrição |
|---|---|---|
| MATH | 95.1% | Teste matemático abrangente que cobre álgebra, geometria, cálculo e outras áreas. |
| AIME 2025 (sem ferramentas) | 92% | American Invitational Mathematics Examination, nível de dificuldade de competição do ensino médio. |
| AIME 2025 (execução de código) | 100% | O Gemini 3 Pro anterior alcançou pontuação perfeita ao habilitar a execução de código. |
| GPQA Diamond | 94.3% | Perguntas e respostas científicas de nível de pós-graduação, liderando todos os modelos do mesmo nível. |
| ARC-AGI-2 | 77.1% | Capacidade de raciocínio abstrato, o dobro da geração anterior 3 Pro. |
| MathArena Apex | Liderança significativa | Mais de 20 vezes melhor que a geração anterior. |
Dos 18 principais testes de benchmark divulgados oficialmente pelo Google, o Gemini 3.1 Pro alcançou o primeiro lugar em 12 deles. O desempenho de 95.1% no benchmark MATH é particularmente notável, indicando que ele possui uma capacidade de resolução de problemas extremamente forte em todas as subáreas da matemática, como álgebra, geometria, probabilidade e cálculo.
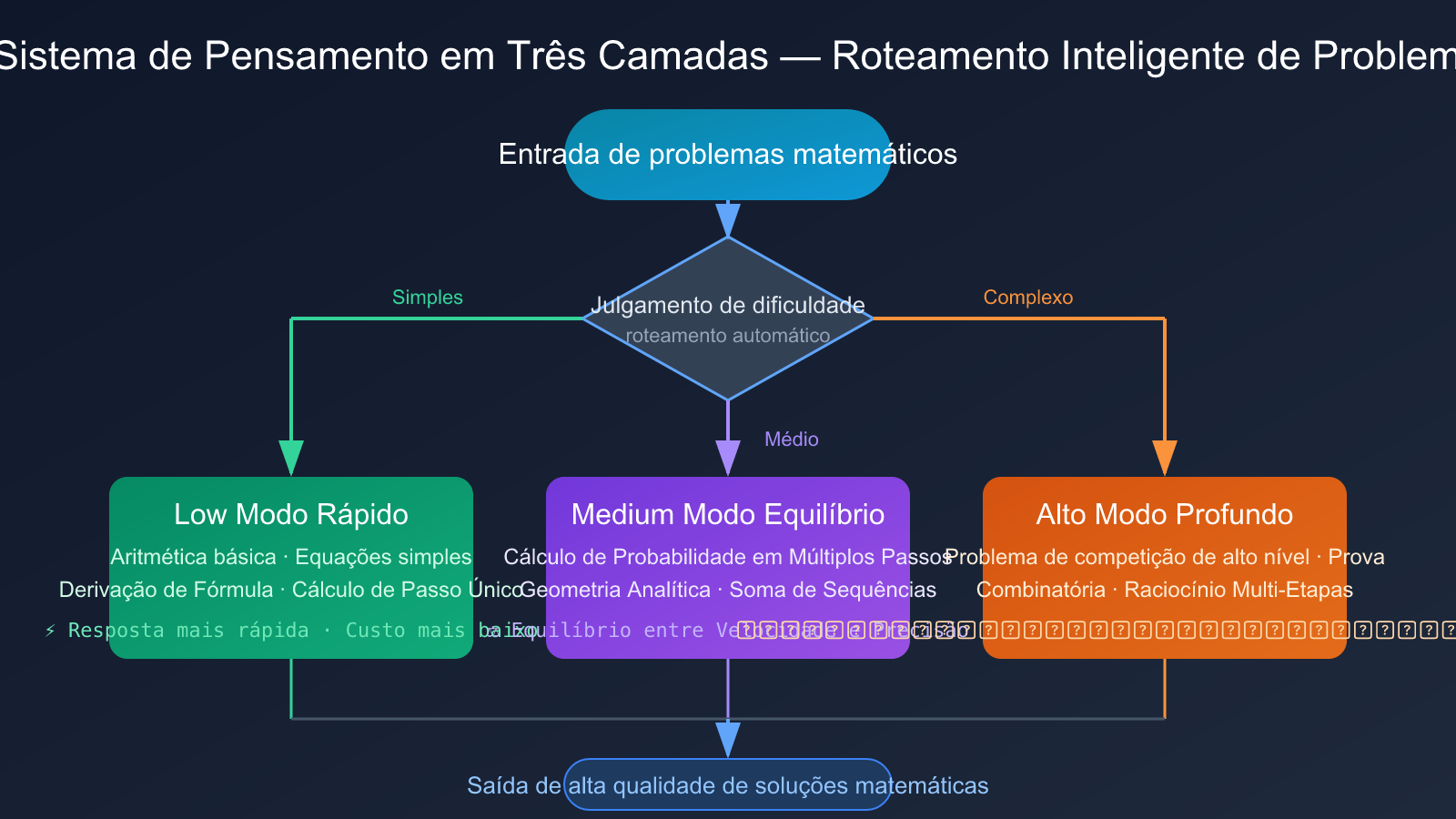
Sistema de Três Camadas de Pensamento do Gemini 3.1 Pro
O Gemini 3.1 Pro introduz uma inovação arquitetônica crucial: o sistema de três camadas de pensamento:
- Low (Modo Rápido): Processa cálculos matemáticos simples e derivação de fórmulas, com a velocidade de resposta mais rápida.
- Medium (Modo Equilibrado): Nova camada intermediária, processa problemas matemáticos de dificuldade média, equilibrando velocidade e precisão.
- High (Modo Profundo): Processa problemas complexos de raciocínio de múltiplos passos, como questões matemáticas de nível competitivo.
Esse sistema de três camadas permite que os desenvolvedores roteiem problemas de forma flexível com base na dificuldade da questão matemática, sem precisar escolher entre "rápido, mas grosseiro" e "lento, mas preciso". Essa vantagem arquitetônica é particularmente evidente em cenários que processam em lote questões matemáticas de diferentes dificuldades (como sistemas de geração de questões adaptativas em plataformas educacionais).
Experiência Prática de Resolução Matemática com o Gemini 3.1 Pro
Na prática de resolução de problemas matemáticos, o desempenho do Gemini 3.1 Pro Preview pode ser resumido como "abrangente e estável":
- Área de Álgebra: Operações polinomiais, resolução de sistemas de equações, provas de desigualdades, etc., praticamente sem erros, graças à alta cobertura de 95.1% no MATH.
- Área de Geometria: Cadeias de raciocínio completas para geometria analítica e geometria espacial, com desempenho excepcional especialmente em problemas de cálculo relacionados a coordenadas.
- Probabilidade e Estatística: Lógica de raciocínio clara para probabilidade condicional, permutações e combinações, capaz de lidar corretamente com cálculos complexos de múltiplas etapas.
- Cálculo: Resolução precisa de integrais definidas e indefinidas, capaz de identificar e aplicar corretamente técnicas de integração comuns.
A conquista do Gemini 3.1 Pro de ficar em primeiro lugar em 12 dos 18 principais benchmarks não é por acaso. Sua pontuação no Artificial Analysis Intelligence Index é de 57 pontos, empatando em primeiro lugar com o GPT-5.4 (xhigh) e muito acima da mediana de 28 pontos, refletindo uma vantagem abrangente em raciocínio inteligente.
Claude Sonnet 4.6: Capacidades de Resolução de Problemas Matemáticos
O Claude Sonnet 4.6 é o mais recente modelo de nível médio da Anthropic, que deu um salto qualitativo em seu raciocínio matemático – passando de 62% na geração anterior, Sonnet 4.5, para 89%, um aumento de impressionantes 27 pontos percentuais.
Desempenho do Claude Sonnet 4.6 em Benchmarks Matemáticos
| Benchmark | Sonnet 4.6 | Sonnet 4.5 (Geração Anterior) | Margem de Melhoria |
|---|---|---|---|
| Matemática Geral | 89% | 62% | +27 pontos percentuais |
| ARC-AGI-2 | 58.3% | 13.6% | Melhoria de 4.3x |
| GPQA Diamond | 74.1% | — | Raciocínio científico de nível de pós-graduação |
| Capacidade de Programação | 79.6% | — | Próximo aos 80.8% do Opus 4.6 |
| Análise Financeira | 63.3% | — | Melhor em sua classe |
O salto na capacidade matemática de 62% para 89% é uma das mudanças mais marcantes do Sonnet 4.6. Isso significa que ele evoluiu de um "modelo que ocasionalmente erra em problemas matemáticos" para um "modelo capaz de lidar de forma confiável com cálculos complexos".
Mecanismo de Pensamento Adaptativo do Claude Sonnet 4.6
Outro destaque do Claude Sonnet 4.6 é seu mecanismo de Profundidade de Pensamento Adaptativo (Adaptive Thinking):
- Problemas Simples: Resposta rápida, sem desperdiçar recursos de raciocínio. Ex.: aritmética básica, resolução de equações simples.
- Problemas de Dificuldade Média: Estende moderadamente a cadeia de raciocínio. Ex.: operações algébricas de múltiplos passos, cálculo de probabilidades.
- Problemas Complexos: Aciona automaticamente cadeias de raciocínio profundas. Ex.: matemática combinatória, problemas de prova, questões de nível de competição.
A vantagem prática desse mecanismo adaptativo é que você não precisa ajustar manualmente a profundidade do raciocínio. O modelo avalia automaticamente a dificuldade do problema matemático e aloca os recursos computacionais adequados, encontrando o equilíbrio ideal entre latência e custo.
Vantagem Única do Claude Sonnet 4.6: O Processo de Solução
Em cenários de resolução de problemas matemáticos, o Claude Sonnet 4.6 possui uma vantagem única amplamente reconhecida: a clareza do processo de solução. Várias avaliações apontam que os modelos Claude têm o melhor desempenho na explicação de conceitos matemáticos. Além disso, o Learning Mode (Modo de Aprendizado), introduzido pela Anthropic, foi projetado especificamente para guiar o processo de raciocínio do aluno, em vez de fornecer a resposta diretamente.
Isso torna o Claude Sonnet 4.6 especialmente adequado para:
- Cenários de educação e tutoria em matemática.
- Estudantes que precisam entender as etapas da solução.
- Pesquisadores que desejam verificar a linha de raciocínio de uma solução.
💡 Sugestão de Aprendizado: Se sua necessidade principal é "compreender o processo de resolução de um problema matemático", e não apenas obter a resposta, o Claude Sonnet 4.6 é a melhor escolha. Você pode experimentar o nível de detalhe do seu processo de solução obtendo créditos de teste gratuitos através do APIYI em apiyi.com.
GPT-5.4: Capacidades de Resolução de Problemas Matemáticos
O GPT-5.4 é o mais recente modelo carro-chefe da OpenAI, lançado em 6 de março de 2026. É o primeiro modelo de raciocínio da OpenAI a integrar, em um único modelo padrão, capacidades profissionais de ponta, capacidade de programação (do GPT-5.3-Codex), operação nativa de computador e uma janela de contexto de 1.05M.
Desempenho do GPT-5.4 em Benchmarks Matemáticos
| Benchmark | Pontuação | Observação |
|---|---|---|
| AIME 2025 | 100% (pontuação perfeita) | Nível de competição matemática do ensino médio, desempenho perfeito |
| GSM8K | 99% | Problemas de matemática do ensino fundamental, desempenho quase perfeito |
| MATH | 88.6% | Benchmark de raciocínio matemático geral |
| GPQA Diamond | 84.2% (padrão) / 92.8% (alto raciocínio) | Raciocínio científico de nível de pós-graduação |
| ARC-AGI-2 | 73.3% (padrão) / 83.3% (Pro) | Capacidade de raciocínio abstrato |
| FrontierMath (geração anterior 5.2) | 40.3% | Novo recorde em matemática de fronteira de nível especialista |
O GPT-5.4 alcançou a impressionante pontuação perfeita de 100% no AIME 2025, o que significa que ele pode resolver perfeitamente todas as questões de alta dificuldade da American Invitational Mathematics Examination. Para usuários que precisam resolver problemas matemáticos de nível de competição, esse desempenho é extremamente convincente.
Vale notar que a pontuação do GPT-5.4 no benchmark MATH é de 88.6%, apresentando uma certa diferença em relação aos 95.1% do Gemini 3.1 Pro. Isso indica que, embora o GPT-5.4 tenha um desempenho perfeito em problemas de competição de alto nível, ele não é o mais forte em testes abrangentes que cobrem uma ampla gama de áreas matemáticas.
Opções de Configuração de Raciocínio do GPT-5.4
O GPT-5.4 oferece várias configurações de raciocínio para se adaptar a diferentes tipos de problemas matemáticos:
- GPT-5.4 Padrão: Adequado para cálculos matemáticos do dia a dia e problemas de dificuldade média.
- GPT-5.4 Thinking: Ativa o raciocínio avançado, adequado para raciocínios complexos de múltiplos passos e provas.
- GPT-5.4 Pro: Configuração de mais alto desempenho, atinge 83.3% no ARC-AGI-2, adequado para cenários de maior dificuldade.
No entanto, é importante observar que o preço do GPT-5.4 Pro é de $30.00/1M de entrada + $180.00/1M de saída, um custo muito superior ao da versão padrão. Para a maioria dos cenários de resolução de problemas matemáticos, a versão padrão já é suficiente.
Experiência Prática com Resolução Matemática do GPT-5.4
O desempenho do GPT-5.4 em problemas matemáticos de nível de competição é especialmente impressionante:
- Matemática de Competição: Responde quase perfeitamente questões abrangentes de teoria dos números, combinatória e geometria de nível AMC/AIME. A pontuação perfeita de 100% no AIME é bem merecida.
- Problemas de Prova: Capaz de construir cadeias completas de prova matemática, com lógica rigorosa e transições naturais entre os passos.
- Matemática Aplicada: A pontuação de 99% no GSM8K mostra que ele também é muito confiável em problemas aplicados (como cálculos de engenharia, modelagem econômica).
- Raciocínio de Múltiplos Passos: Graças à janela de contexto ultra-longa de 1.05M, consegue manter uma cadeia de raciocínio completa enquanto processa problemas matemáticos extremamente complexos e de múltiplos passos.
Uma vantagem única do GPT-5.4 é que sua geração anterior, o GPT-5.2, estabeleceu um novo recorde de 40.3% no FrontierMath (matemática de fronteira de nível especialista). Isso significa que a série GPT também possui uma certa capacidade de exploração em problemas matemáticos verdadeiramente de fronteira e não resolvidos, algo que outros modelos atualmente têm dificuldade em alcançar.
Interpretação de Benchmarks de Modelos de IA para Resolução de Problemas Matemáticos
Antes de comparar os modelos de IA para resolução de problemas matemáticos, é essencial compreender o significado e o foco de cada benchmark para avaliar com precisão as capacidades dos modelos:
| Benchmark | Nome Completo | Conteúdo Testado | Nível de Dificuldade |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Questões reais da competição americana, abrangendo teoria dos números, combinatória, geometria, etc. | Nível de competição do ensino médio (Top 5% dos estudantes) |
| MATH | Mathematics Aptitude Test of Heuristics | Teste abrangente cobrindo 7 grandes áreas como álgebra, geometria, cálculo, etc. | Nível do ensino médio ao superior |
| GSM8K | Grade School Math 8K | 8000 problemas de matemática aplicada do ensino fundamental ao médio | Nível básico |
| GPQA Diamond | Graduate-Level Google-Proof QA | Questões de raciocínio científico em nível de pós-graduação, elaboradas por especialistas da área | Nível de pós-graduação/doutorado |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Reconhecimento de novos padrões lógicos, testando a capacidade de raciocínio abstrato | Nível de inteligência geral |
| FrontierMath | Frontier Mathematics | Problemas matemáticos de ponta em nível de especialista, envolvendo áreas não resolvidas ou novas | Nível de especialista/pesquisador |
Compreensão-chave: O AIME enfatiza mais técnicas matemáticas de nível competitivo e pensamento criativo, enquanto o MATH foca mais na capacidade de cobertura abrangente em diversas áreas. Um modelo que atinge pontuação perfeita no AIME mas não a pontuação mais alta no MATH (como o GPT-5.4) indica que ele é extremamente forte em problemas complexos de competição, mas pode ter uma cobertura ligeiramente inferior em algumas áreas fundamentais em comparação com modelos com pontuação mais alta no MATH.
É por isso que recomendamos o Gemini 3.1 Pro Preview como a escolha abrangente preferida – 95.1% no MATH significa que ele tem um desempenho mais equilibrado em todas as subáreas da matemática.
É importante notar que o benchmark AIME 2025 atualmente está se aproximando da saturação – vários modelos de ponta (combinados com execução de código) podem atingir mais de 95% ou mesmo pontuação perfeita. Portanto, benchmarks de maior dificuldade como MathArena Apex e FrontierMath são mais capazes de diferenciar a verdadeira capacidade matemática dos modelos. No MathArena Apex, o Gemini 3.1 Pro demonstrou uma melhoria de mais de 20 vezes em relação à geração anterior, mostrando uma base de raciocínio matemático intrínseco extremamente forte.
Outra dimensão que merece atenção é a ARC-AGI-2 (capacidade de raciocínio abstrato). Este teste avalia a capacidade do modelo de reconhecer novos padrões lógicos – padrões que o modelo nunca viu durante seu treinamento. O Gemini 3.1 Pro Preview lidera com 77.1%, indicando que ele não apenas resolve tipos de problemas conhecidos, mas também possui uma capacidade de raciocínio de generalização mais forte, apresentando melhor desempenho ao enfrentar novos tipos de problemas matemáticos.
Prática de Invocação de API para Modelos de IA de Resolução Matemática
Aqui está um exemplo de código mínimo para invocar um modelo de IA de resolução matemática via API, funcionando com apenas 10 linhas de código:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interface unificada da APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Pode ser trocado por claude-sonnet-4.6 ou gpt-5.4
messages=[{"role": "user", "content": "Resolver: Dada a progressão aritmética {an} com primeiro termo a1=2 e razão d=3, encontre a soma S20 dos primeiros 20 termos"}]
)
print(response.choices[0].message.content)
Ver código completo de invocação para resolução matemática (com comparação de múltiplos modelos)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Invoca um modelo de IA para resolver um problema matemático
Args:
problem: Descrição do problema matemático
model: Nome do modelo, suporta gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4
system_prompt: Comando do sistema, pode especificar o estilo de resolução
Returns:
Resposta do modelo com a solução
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interface unificada da APIYI
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Você é um especialista em resolução de problemas matemáticos. Por favor, resolva o problema matemático com etapas claras, explicando a base do raciocínio em cada passo."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Erro: {str(e)}"
# Exemplo de uso: comparar a solução do mesmo problema por três modelos
problem = "No triângulo ABC, dados a=5, b=7, C=60°, encontre a área do triângulo e o comprimento do terceiro lado c"
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Modelo: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Sugestão: Obtenha créditos de teste gratuitos através da APIYI apiyi.com. Com uma única chave API, você pode invocar os três modelos de resolução matemática mencionados acima e comparar rapidamente as diferenças de desempenho deles em seus problemas reais.
Comparação de Preços e Custo-benefício de Modelos de IA para Resolução de Problemas Matemáticos
Ao escolher um modelo de IA para resolver problemas matemáticos, o preço é um fator que não pode ser ignorado. Aqui está uma comparação detalhada de preços de três modelos:
| Dimensão de Preço | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Preço de Entrada | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| Preço de Saída | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| Preço Misturado (3:1) | $4.50/1M tokens | $6.00/1M tokens | $5.63/1M tokens |
| Acréscimo para Contexto Longo | >200K dobra | Nenhum | >272K dobra |
| Janela de Contexto | 1M tokens | Janela padrão | 1.05M tokens |
| Saída Máxima | 65,536 tokens | Saída padrão | 128,000 tokens |
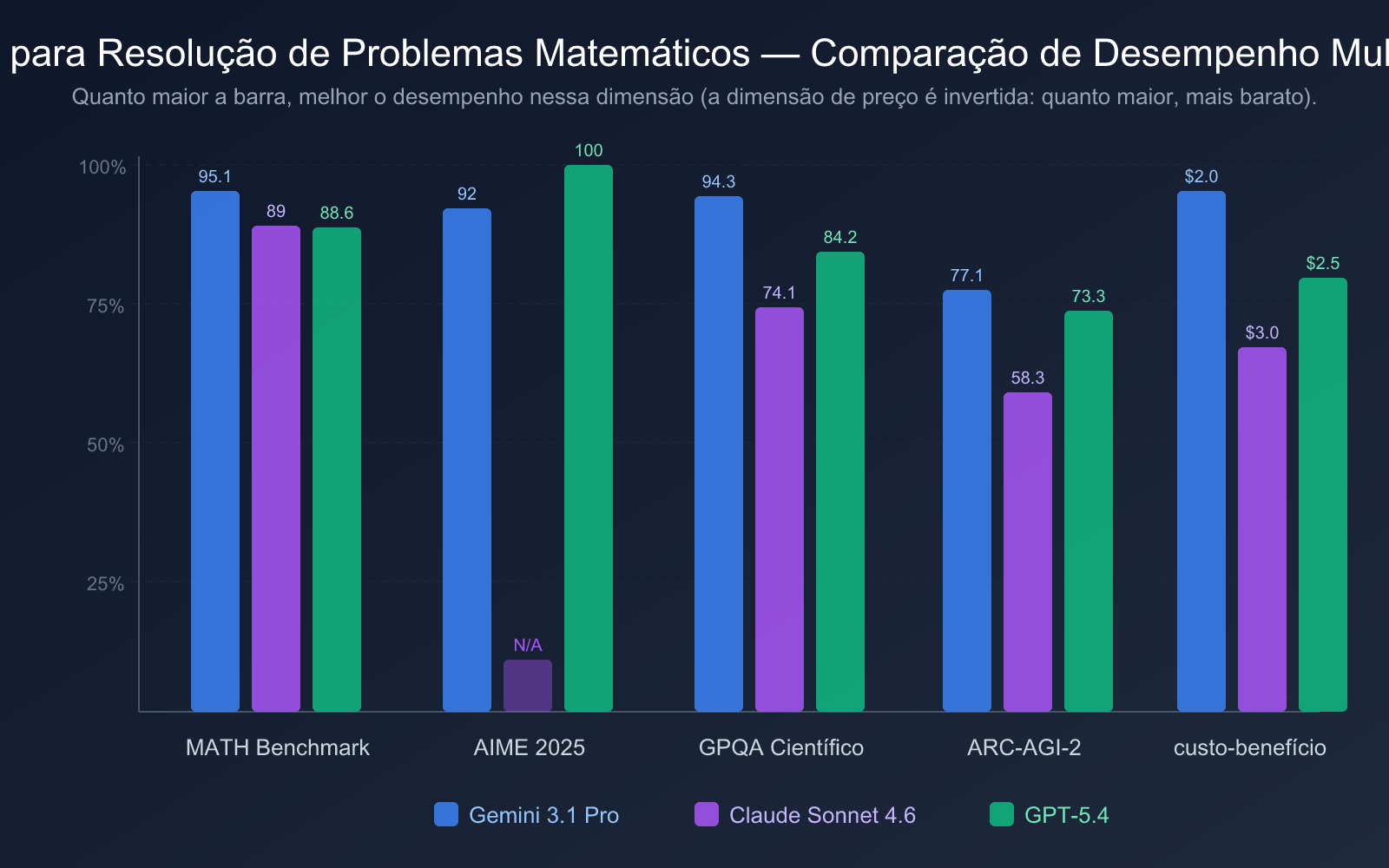
Analisando do ponto de vista do custo-benefício:
- Gemini 3.1 Pro Preview tem o melhor custo-benefício: Preço de entrada de apenas $2.00/1M tokens, e pontuação de referência MATH de 95.1% na liderança. De acordo com a análise da Artificial Analysis, seu custo operacional é cerca de 1/7.5 do Claude Opus 4.6, mas se iguala ou supera em benchmarks de matemática e programação.
- Claude Sonnet 4.6 tem preço moderado: A precificação de $3.00/$15.00 é a mesma da geração anterior Sonnet 4.5, mas a capacidade matemática melhorou 27 pontos percentuais, com uma melhoria significativa no custo-benefício.
- GPT-5.4 Standard tem preço razoável: A precificação de $2.50/$15.00 está dentro de uma faixa razoável, mas se usar o GPT-5.4 Pro ($30/$180), o custo aumentará significativamente.
💰 Recomendação de custo: Para necessidades diárias de resolução de problemas matemáticos, recomenda-se usar o Gemini 3.1 Pro Preview para obter o melhor custo-benefício. Se precisar otimizar ainda mais os custos, considere usar uma plataforma de agregação de APIs para obter opções de recarga mais flexíveis.
Estimativa de Custo Real para Resolução de Problemas Matemáticos
Para ajudá-lo a entender melhor a diferença de custos, aqui está uma estimativa de custo para um cenário típico de resolução de problemas matemáticos:
Suposição do cenário: Resolver 100 problemas de matemática de dificuldade média por dia, cada um consumindo em média 500 tokens de entrada + 1500 tokens de saída.
| Modelo | Custo Diário de Entrada | Custo Diário de Saída | Custo Diário Total | Custo Mensal (30 dias) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
A partir da estimativa de custos, podemos ver claramente:
- O custo mensal do Gemini 3.1 Pro Preview é de cerca de $57, sendo o mais econômico entre os três modelos principais.
- Os custos do Claude Sonnet 4.6 e do GPT-5.4 Standard são semelhantes, cerca de $71-72/mês.
- O custo do GPT-5.4 Pro chega a $855/mês, adequado apenas para cenários com orçamento generoso que exigem precisão extrema.
- O DeepSeek R2 oferece uma solução altamente competitiva com um custo ultrabaixo de $10.80/mês.
Comparação do Índice de Inteligência Abrangente dos Modelos de IA para Resolução de Problemas Matemáticos
Além dos testes de referência individuais, o Índice de Inteligência Abrangente reflete de forma mais completa o potencial de raciocínio matemático dos modelos. O Artificial Analysis Intelligence Index é atualmente um dos sistemas de avaliação abrangente mais autorizados, calculando a pontuação geral do modelo com base em quatro dimensões: raciocínio, conhecimento, matemática e programação.
| Modelo | Índice de Inteligência Abrangente | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Avaliação Geral |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Rei das questões de competição, índice geral empatado em 1º |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Índice geral empatado em 1º, cobertura matemática mais completa |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Capacidade de raciocínio e explicação científica de ponta |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Excelente custo-benefício, processo de resolução mais claro |
Do ponto de vista do Índice de Inteligência Abrangente, o GPT-5.4 (xhigh) e o Gemini 3.1 Pro Preview empatam em primeiro lugar com 57 pontos, mas cada um tem um foco diferente:
- GPT-5.4: Desempenho perfeito (100%) em questões de competição como AIME, mas pontuação ligeiramente menor no benchmark geral MATH (88.6%)
- Gemini 3.1 Pro: Mais equilibrado no benchmark geral MATH (95.1%) e no raciocínio científico GPQA Diamond (94.3%)
Isso significa que se suas necessidades matemáticas forem voltadas para competições e problemas extremamente difíceis, o GPT-5.4 é superior; se você precisa de um desempenho estável cobrindo uma ampla gama de áreas matemáticas, o Gemini 3.1 Pro Preview é a escolha mais segura.
Recomendações por Cenário para Modelos de IA de Resolução de Problemas Matemáticos
Diferentes cenários de aplicação matemática têm diferentes demandas dos modelos. Aqui estão as recomendações baseadas em cenários de uso real:
Cenários Matemáticos para Escolher o Gemini 3.1 Pro Preview
- Plataforma de Tutoria Matemática Abrangente: Cobre todas as áreas como álgebra, geometria, cálculo, etc., com a melhor capacidade geral MATH de 95.1%
- Processamento em Lote de Problemas Matemáticos: Preço mais baixo, sistema de três camadas de pensamento adapta-se automaticamente à dificuldade, reduzindo custos
- Cenários que Combinam Cálculo Científico: Capacidade de raciocínio científico GPQA Diamond de 94.3%, ideal para problemas que cruzam física, química e matemática
- Problemas Matemáticos com Visualização: Capacidade multimodal do Gemini é vantajosa para problemas que incluem diagramas e gráficos geométricos
Cenários Matemáticos para Escolher o Claude Sonnet 4.6
- Educação e Tutoria Matemática: Processo de resolução mais claro, o "Learning Mode" guia especificamente o raciocínio do aluno, não dando a resposta diretamente, mas orientando o pensamento
- Aprendizado de Etapas de Solução: Cenários que exigem entender "por que fazer assim". A capacidade de explicação do Claude é reconhecida como a melhor. 70% dos usuários preferem o Sonnet 4.6 em vez da versão anterior 4.5, indicando um salto qualitativo na experiência do usuário
- Assistência à Pesquisa Matemática: Ideal para pesquisadores que precisam verificar ideias com processos dedutivos detalhados, a profundidade de pensamento adaptativa corresponde automaticamente à complexidade do problema
- Cálculos de Escritório e Finanças: Análise financeira de 63.3% é a melhor da classe, produtividade em escritório GDPval-AA com pontuação 1633 Elo supera até o Opus 4.6 mais caro
- Combinação de Programação + Matemática: Capacidade de programação de 79.6% próxima do Opus 4.6, ideal para desenvolvedores que precisam escrever programas de cálculo matemático
Cenários Matemáticos para Escolher o GPT-5.4
- Competições Matemáticas de Alta Dificuldade: Pontuação perfeita de 100% no AIME, modelo preferido para problemas de nível competitivo
- Raciocínio Matemático em Documentos Longos: Janela de contexto de 1.05M tokens, ideal para processar problemas complexos que exigem muita informação de fundo matemático
- Pesquisa Matemática Profissional: A versão anterior GPT-5.2 estabeleceu um novo recorde de 40.3% no FrontierMath, com forte capacidade matemática de ponta em nível de especialista
- Banco de Investimento e Finanças Quantitativas: Alta pontuação de 87.3% em tarefas de modelagem para banco de investimento, adequado para cenários de matemática financeira de alto nível
Estratégia de Uso Misto: Melhor Combinação de Modelos para Resolução Matemática
Em ambientes de produção real, muitas equipes adotam uma estratégia de uso misto para obter os melhores resultados:
Estratégia Um: Roteamento por Nível de Dificuldade
- Problemas básicos (aritmética, equações simples) → Modo "Low" do Gemini 3.1 Pro, custo mais baixo
- Problemas médios (raciocínio de múltiplos passos, problemas aplicados) → Modo adaptativo do Claude Sonnet 4.6, processo de resolução claro
- Problemas de alta dificuldade (competições, provas) → Modo "Thinking" do GPT-5.4, maior precisão
Estratégia Dois: Validação Cruzada
- Primeiro, resolver rapidamente com o Gemini 3.1 Pro (baixo custo, alta velocidade)
- Validar resultados críticos uma segunda vez com o GPT-5.4 (alta precisão)
- Reexplicar para o usuário com o Claude Sonnet 4.6 quando necessário (clareza na expressão)
🚀 Recomendação de Implementação: A estratégia de uso misto acima pode ser facilmente implementada através da plataforma APIYI apiyi.com. Uma única chave API permite chamar todos os modelos, bastando alternar o parâmetro
modelno código.
Recomendações de Decisão para Modelos de IA de Resolução de Problemas Matemáticos
Com base na análise acima, aqui estão as recomendações de decisão para diferentes grupos de usuários:
| Tipo de Usuário | Modelo Recomendado | Motivo da Recomendação |
|---|---|---|
| Estudantes/Autodidatas | Claude Sonnet 4.6 | Processo de resolução claro, modo "Learning Mode" guia o pensamento |
| Desenvolvedores de Plataformas Educacionais | Gemini 3.1 Pro Preview | Capacidade geral mais forte, preço mais baixo, três níveis de pensamento adaptam-se à dificuldade |
| Competidores/Treinadores | GPT-5.4 | Pontuação perfeita no AIME, capacidade mais forte para problemas de nível competitivo |
| Pesquisadores | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%, capacidade líder em ciência + matemática interdisciplinar |
| Processamento em Lote Empresarial | Gemini 3.1 Pro Preview | Melhor custo-benefício, preço de entrada $2.00/1M tokens |
| Equipes de Quant Financeiro | GPT-5.4 | Modelagem de Investment Banking 87.3%, mais forte em cenários de matemática financeira |
💡 Sugestão de Escolha: A escolha de qual modelo de IA para resolução de problemas matemáticos depende principalmente do seu cenário de aplicação específico. Se você não tem certeza de qual é o mais adequado, recomendamos testar os três modelos com o mesmo problema matemático através da plataforma APIYI apiyi.com, e fazer a escolha final com base na qualidade da solução e na velocidade de resposta. A plataforma suporta chamadas de API unificadas, facilitando a comparação rápida e a troca de modelos.
Outros Modelos de Resolução de Problemas Matemáticos Dignos de Nota
Além dos três modelos principais mencionados acima, existem outros modelos de IA para resolução de problemas matemáticos que merecem atenção em cenários específicos:
| Nome do Modelo | AIME 2025 | Vantagem Central | Preço da API (Entrada/Saída) | Cenário Adequado |
|---|---|---|---|---|
| DeepSeek R2 | Superou Gemini 3.1 Pro | Custo-benefício extremo | $0.55/$2.19 por 1M | Processamento matemático em lote sensível ao orçamento |
| Claude Opus 4.6 | — | GPQA 91.3%, explicações mais profundas | $15/$75 por 1M | Pesquisa de ponta e raciocínio profundo |
| Qwen3-235B | 89.2% | Mais forte em código aberto | Custo de implantação própria | Cenários que exigem implantação privada |
| DeepSeek R1 | Aprox. 87.5% | Referência em código aberto, 671B MoE | Custo de implantação própria | Pesquisa da comunidade de código aberto e desenvolvimento secundário |
| MiMo-V2-Flash | 94.1% | Custo de inferência apenas 2.5% do Claude | Extremamente baixo | Inferência de baixo custo em grande escala |
Entre eles, o DeepSeek R2 merece atenção especial, pois superou o Gemini 3.1 Pro Preview no AIME, com um preço cerca de 1/4 do último. Se o seu cenário de resolução de problemas matemáticos for extremamente sensível ao orçamento, o DeepSeek R2 é uma escolha altamente competitiva.
Já o MiMo-V2-Flash alcançou uma alta pontuação de 94.1% no AIME 2025, enquanto seu custo de inferência é apenas 2.5% do Claude, sendo muito adequado para plataformas de tecnologia educacional que precisam processar grandes volumes de problemas matemáticos em lote.
Técnicas de Otimização de Comandos para Modelos de IA de Resolução de Problemas Matemáticos
Independentemente do modelo escolhido, bons comandos podem melhorar significativamente a qualidade da resolução de problemas matemáticos. Aqui estão técnicas de comandos comprovadas:
- Especifique o Tipo de Problema: No comando, indique "Este é um problema de matemática combinatória" ou "Este é um problema de geometria analítica", ajudando o modelo a invocar a estratégia de resolução correta.
- Exija Solução Passo a Passo: Adicione "Por favor, derive passo a passo, identificando o teorema ou fórmula usado em cada etapa", melhorando a legibilidade do processo de resolução.
- Especifique o Formato de Saída: Como "Por favor, use o formato LaTeX para fórmulas matemáticas" ou "Marque a resposta final com uma caixa".
- Forneça Restrições de Contexto: Como "Assuma que x é um número inteiro positivo" ou "Resolva no conjunto dos números reais", evitando que o modelo gere discussões de classificação desnecessárias.
- Validação Cruzada com Múltiplos Modelos: Para resultados críticos, valide a consistência da resposta com diferentes modelos, aumentando a confiança.
Perguntas Frequentes
Q1: Os resultados de benchmark dos modelos de IA para resolução de problemas matemáticos são confiáveis?
Os benchmarks fornecem uma base padronizada para comparação horizontal, mas a eficácia real também é afetada por fatores como o tipo de problema e a qualidade do comando. AIME e MATH são atualmente os benchmarks de raciocínio matemático mais autorizados, amplamente reconhecidos pela academia e pela indústria. Recomenda-se usar seus próprios problemas reais para teste e validação, além de consultar os dados de benchmark.
Q2: Sou estudante, qual modelo de IA para resolução de problemas matemáticos devo escolher?
Recomenda-se o Claude Sonnet 4.6 como primeira escolha. Seu processo de resolução é o mais claro, com explicações de raciocínio explícitas para cada etapa, sendo ideal para aprender e entender a lógica de resolução de problemas matemáticos. O recurso Learning Mode da Anthropic pode até guiar seu próprio pensamento, em vez de dar a resposta diretamente. Se encontrar problemas de competição particularmente difíceis, pode alternar para o GPT-5.4 em busca de ajuda.
Q3: Como começar rapidamente a testar esses modelos de IA para resolução de problemas matemáticos?
Recomenda-se usar uma plataforma de agregação de APIs que suporte uma interface unificada para múltiplos modelos:
- Acesse a APIYI (apiyi.com) e registre uma conta
- Obtenha uma chave API e créditos de teste gratuitos
- Use os exemplos de código Python fornecidos neste artigo, modificando apenas o parâmetro
modelpara alternar entre diferentes modelos - Teste os três modelos com o mesmo problema matemático e compare a qualidade da solução e a velocidade de resposta
Q4: Esses modelos de IA para resolução de problemas matemáticos suportam saída de fórmulas em LaTeX?
Todos os três modelos suportam a saída de fórmulas matemáticas no formato LaTeX. Basta adicionar "Por favor, use o formato LaTeX para todas as fórmulas matemáticas" ao comando. O Gemini 3.1 Pro e o GPT-5.4 têm uma formatação LaTeX mais padronizada, enquanto o Claude Sonnet 4.6 oferece explicações textuais mais detalhadas entre as fórmulas. Para cenários que exigem copiar fórmulas diretamente para artigos, recomenda-se usar o Gemini ou o GPT.
Q5: Os modelos de IA para resolução de problemas matemáticos conseguem processar problemas em imagens?
O Gemini 3.1 Pro Preview e o GPT-5.4 suportam entrada multimodal, permitindo fazer upload direto de imagens contendo problemas matemáticos para resolução. O Gemini se destaca especialmente no processamento de imagens com figuras geométricas e fórmulas manuscritas. O Claude Sonnet 4.6 também suporta entrada de imagem, mas é um pouco inferior ao Gemini no reconhecimento de figuras geométricas complexas. Se seus problemas matemáticos frequentemente aparecem em formato de imagem (como em buscas por foto), o Gemini 3.1 Pro Preview é a melhor escolha.
Conclusão
Pontos-chave para a escolha de modelos de IA para resolução de problemas matemáticos:
- Melhor escolha geral: Gemini 3.1 Pro Preview: Liderança geral com 95,1% no MATH, preço mais vantajoso a $2,00/1M tokens, sistema de pensamento em três níveis adapta-se flexivelmente a diferentes dificuldades.
- Melhor para aprendizado e compreensão: Claude Sonnet 4.6: Capacidade matemática aumentou 27 pontos percentuais para 89%, etapas de resolução claras, profundidade de pensamento adaptativa equilibra custo e qualidade.
- Melhor para problemas de competição: GPT-5.4: Pontuação perfeita de 100% no AIME 2025, contexto super longo de 1,05M, capacidade de raciocínio de alta dificuldade incomparável.
Nenhum modelo é a solução ideal para todos os cenários matemáticos. O cenário competitivo dos modelos de IA para resolução de problemas matemáticos em 2026 pode ser resumido assim:
- Cobertura geral: O Gemini 3.1 Pro Preview ocupa a posição de primeira escolha geral com 95,1% no MATH e o menor preço.
- Educação e aprendizado: O Claude Sonnet 4.6, com seu aumento de 27 pontos percentuais em matemática e capacidade de explicação incomparável, torna-se a melhor escolha para cenários educacionais.
- Competições de elite: O GPT-5.4, com sua pontuação perfeita no AIME, é insuperável no campo de competições matemáticas de alta dificuldade.
- Prioridade orçamentária: O DeepSeek R2 oferece capacidade de raciocínio matemático comparável a menos de 1/4 do preço do Gemini.
A estratégia mais inteligente é escolher o modelo adequado às suas necessidades reais, ou até mesmo usar vários modelos misturados para problemas de diferentes dificuldades, aproveitando ao máximo as vantagens únicas de cada um.
Recomenda-se testar e comparar rapidamente esses modelos através da APIYI (apiyi.com). A plataforma oferece créditos gratuitos e uma interface de API unificada; uma única integração permite invocar de forma flexível todos os principais modelos de raciocínio matemático, facilitando a implementação de uma estratégia de uso misto de múltiplos modelos.
📚 Referências
-
Model Card do Google DeepMind Gemini 3.1 Pro: Dados de benchmark oficiais e detalhes técnicos
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Descrição: Contém os resultados completos dos testes de benchmark e explicações sobre a arquitetura
- Link:
-
Notas de Lançamento do Anthropic Claude Sonnet 4.6: Detalhes sobre a melhoria da capacidade de raciocínio matemático
- Link:
docs.anthropic.com - Descrição: Inclui dados comparativos do Sonnet 4.6 com a geração anterior e explicações sobre o mecanismo de pensamento adaptativo
- Link:
-
Anúncio de Lançamento do OpenAI GPT-5.4: Dados de benchmark e funcionalidades do modelo mais recente
- Link:
openai.com/index/introducing-gpt-5-4/ - Descrição: Contém os resultados completos dos testes de benchmark do GPT-5.4 e explicações sobre a configuração de raciocínio
- Link:
-
Avaliação de Modelos da Artificial Analysis: Plataforma independente de comparação de benchmarks de terceiros
- Link:
artificialanalysis.ai/evaluations/aime-2025 - Descrição: Fornece rankings independentes e análises para testes de benchmark como o AIME 2025
- Link:
-
Ranking de Benchmark AIME 2025: Comparação autoritativa da capacidade de raciocínio matemático
- Link:
vals.ai/benchmarks/aime - Descrição: Dados de ranking de benchmark de raciocínio matemático em IA, atualizados continuamente
- Link:
Autor: Equipe Técnica da APIYI
Discussão Técnica: Compartilhe sua experiência com IAs de resolução de problemas matemáticos nos comentários. Para mais tutoriais sobre invocação de modelos, visite o centro de documentação da APIYI em docs.apiyi.com