Nota do autor: O Gemini 3.1 Flash-Lite Preview foi lançado com uma velocidade de saída de 380 tok/s e um custo ultrabaixo de $0,25/M. Este artigo faz uma análise profunda de suas 5 principais vantagens, dados de benchmark, comparação com concorrentes e métodos de integração via API.
O Google DeepMind lançou oficialmente em 3 de março de 2026 o Gemini 3.1 Flash-Lite Preview — o modelo mais rápido e de menor custo da série Gemini 3. Baseado na arquitetura do Gemini 3 Pro, sua velocidade de saída atinge cerca de 380 tokens/s, sendo 2,5 vezes mais rápido na resposta do primeiro token e 45% mais rápido na velocidade de saída em comparação com o Gemini 2.5 Flash.
Valor Principal: Este artigo irá ajudá-lo a entender completamente este novo modelo leve recém-lançado, avaliando se ele é adequado para o seu cenário de negócios, através de 5 dimensões: benchmark de desempenho, comparação de custos, características funcionais, cenários de aplicação e integração via API.

Visão Rápida dos Parâmetros Principais do Gemini 3.1 Flash-Lite Preview
A seguir estão os principais parâmetros técnicos extraídos da documentação oficial do Google AI e do modelo card do DeepMind:
| Parâmetro | Gemini 3.1 Flash-Lite Preview | Descrição |
|---|---|---|
| ID do Modelo | gemini-3.1-flash-lite-preview |
Use este ID para invocação da API |
| Base Arquitetural | Gemini 3 Pro | Herda a arquitetura multimodal de nível Pro |
| Janela de Contexto | 1.048.576 tokens (1M) | Aproximadamente 1.500 páginas de documento A4 |
| Saída Máxima | 65.536 tokens (64K) | Suporta geração de texto longo |
| Velocidade de Saída | ~380 tokens/s | Classificado em 2º lugar entre 132 modelos |
| Preço de Entrada | $0,25 / milhão de tokens | O mais baixo da série Gemini 3 |
| Preço de Saída | $1,50 / milhão de tokens | 1/8 do preço da versão Pro |
| Corte de Conhecimento | Janeiro de 2025 | Consistente com o Gemini 3 Pro |
| Status | Preview | Versão de prévia, versão final a ser lançada |
Vale destacar que o Gemini 3.1 Flash-Lite Preview é construído sobre a arquitetura do Gemini 3 Pro, o que significa que, em um tamanho "reduzido", ele mantém a capacidade de compreensão multimodal de nível Pro. O Google o posiciona como o modelo preferencial para "tarefas leves e de alta frequência".
🎯 Recomendação de Integração: O Gemini 3.1 Flash-Lite Preview já está disponível no APIYI apiyi.com, com preços iguais aos oficiais do Google. Recarregue a partir de US$ 100 e ganhe US$ 10 de bônus, com descontos de até 20%. Use mais de 400 Modelos de Linguagem Grande em um só lugar.
As 5 principais vantagens do Gemini 3.1 Flash-Lite Preview
Vantagem 1: Inferência ultrarrápida — velocidade de saída de 380 tok/s
A velocidade de saída do Gemini 3.1 Flash-Lite Preview atinge cerca de 380 tokens/s, ocupando a 2ª posição entre 132 modelos principais de acordo com os dados de avaliação do Artificial Analysis. Em comparação com os 249 tok/s da geração anterior, Gemini 2.5 Flash, o desempenho melhorou aproximadamente 45%.
O Tempo de Resposta do Primeiro Token (TTFT) é ainda mais impressionante — 2,5 vezes mais rápido que o Gemini 2.5 Flash. Essa melhoria é significativa para cenários de aplicação que exigem feedback instantâneo, como chatbots e tradução em tempo real.
Vantagem 2: Custo extremamente baixo — entrada apenas $0,25/M tokens
Na série Gemini 3, o preço do Flash-Lite é apenas 1/8 do da versão Pro. Especificamente:
| Modelo | Preço de Entrada | Preço de Saída | Taxa Mista (3:1) |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0,25/M | $1,50/M | $0,56/M |
| Gemini 3 Pro | $2,00/M | $12,00/M | $4,50/M |
| Claude 4.5 Haiku | $1,00/M | $5,00/M | $2,00/M |
| GPT-5 mini | $0,15/M | $0,60/M | $0,26/M |
O Flash-Lite alcança um equilíbrio excepcional entre preço e desempenho — embora não seja o mais barato em termos absolutos, sua velocidade de saída de 380 tok/s combinada com uma janela de contexto de 1M oferece uma relação custo-benefício extremamente alta.
Vantagem 3: Janela de contexto de nível milhão
Uma janela de contexto de 1.048.576 tokens significa que você pode processar em uma única solicitação:
- Aproximadamente 1.500 páginas de documentos A4
- Um repositório de código completo
- Conteúdo de áudio/vídeo com várias horas de duração
Esta é uma configuração muito rara em modelos leves. Em comparação, o GPT-5 mini suporta apenas 128K, e o Claude 4.5 Haiku suporta 200K.
Vantagem 4: Suporte a entrada multimodal completa
Apesar de ser posicionado como um modelo leve, o Gemini 3.1 Flash-Lite Preview suporta 5 modalidades de entrada:
- Texto: Capacidade central
- Imagem: Análise e compreensão de conteúdo de imagens
- Áudio: Transcrição e análise de fala
- Vídeo: Compreensão de conteúdo de vídeo
- PDF: Análise e resumo de documentos
A saída suporta apenas texto, mas isso já é suficiente para a maioria das tarefas de processamento e análise de dados.
Vantagem 5: Suporte ao Thinking Mode
Para um modelo leve, é quase único que o Gemini 3.1 Flash-Lite Preview suporte o Thinking Mode (modo de pensamento estendido). Quando ativado, o modelo realiza raciocínio passo a passo, melhorando significativamente a precisão em tarefas como conhecimento científico e cálculos matemáticos.
🎯 Recomendação de plataforma: Quer testar rapidamente o desempenho do Thinking Mode do Gemini 3.1 Flash-Lite Preview? Você pode invocá-lo diretamente através do APIYI apiyi.com, que oferece uma interface unificada para mais de 400 modelos principais de linguagem grandes.
Dados de benchmark do Gemini 3.1 Flash-Lite Preview
A seguir estão os dados de avaliação do modelo card do Google DeepMind e do Artificial Analysis:
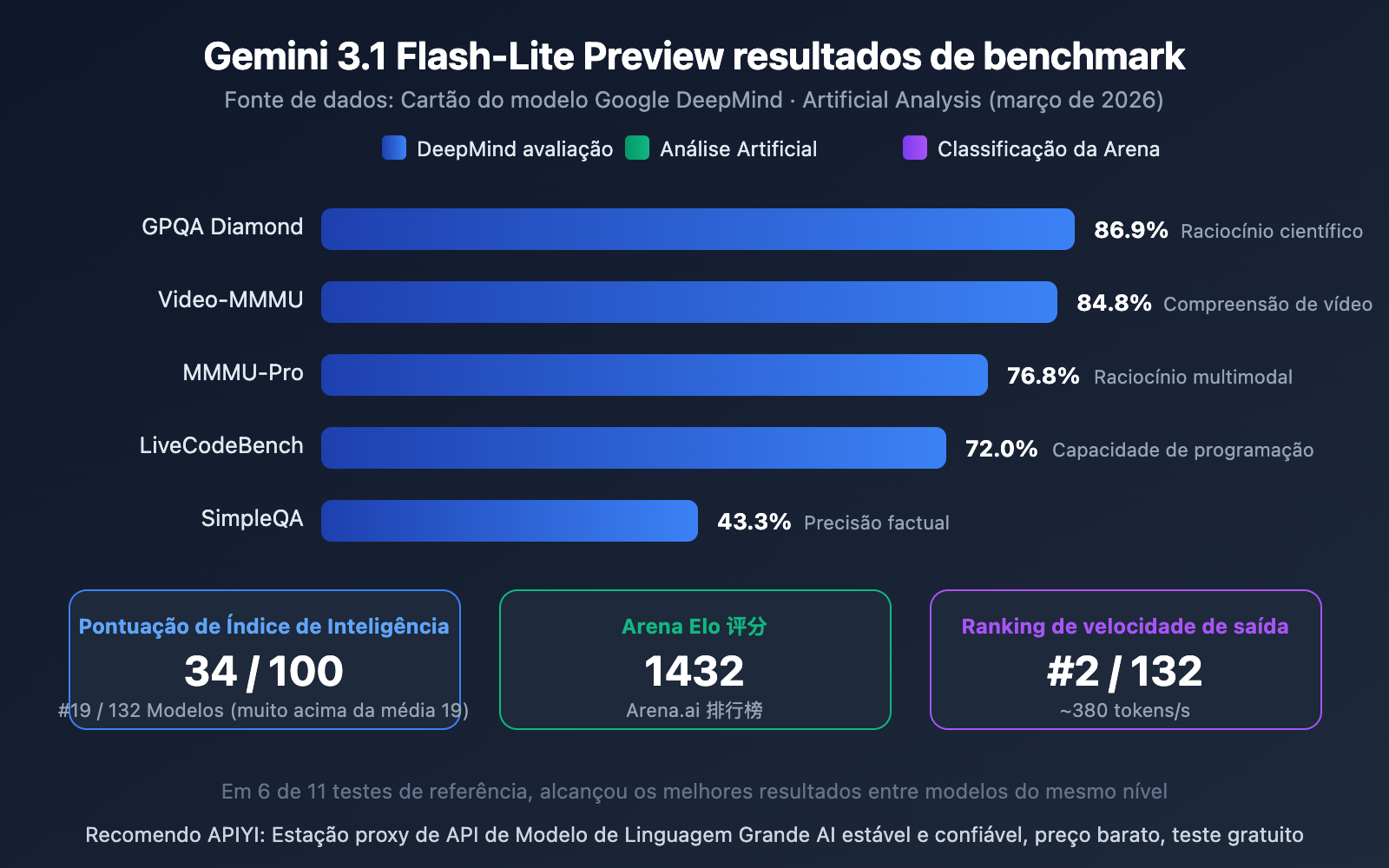
Interpretação dos benchmarks do Gemini 3.1 Flash-Lite Preview
A partir dos dados, o desempenho do Flash-Lite entre os modelos leves é bastante impressionante:
- GPQA Diamond 86,9%: Capacidade de raciocínio em conhecimento científico lidera entre modelos do mesmo nível
- Video-MMMU 84,8%: A capacidade de compreensão de vídeo reflete sua vantagem multimodal
- MMMU-Pro 76,8%: Excelente desempenho em raciocínio multimodal
- Arena Elo 1432: Pontuação alta no ranking Arena.ai, comprovando uma boa experiência de uso real
- Índice de Inteligência 34/100: Muito superior à média de 19 dos modelos do mesmo nível, ocupando a 19ª posição entre 132 modelos
Em 11 testes de benchmark, o Flash-Lite obteve os melhores resultados em sua categoria em 6 deles, um desempenho muito bom para um modelo leve.
🎯 Sugestão para testes práticos: Os dados de benchmark são apenas para referência; o efeito real varia conforme o cenário. Recomenda-se testar em cenários reais através do APIYI apiyi.com. A plataforma oferece crédito gratuito e suporta a comparação rápida de vários modelos.
Gemini 3.1 Flash-Lite Preview em comparação com a concorrência

| Dimensão de Comparação | Gemini 3.1 Flash-Lite | Claude 4.5 Haiku | GPT-5 mini |
|---|---|---|---|
| Velocidade de Saída | ~380 tok/s ⚡ | ~108 tok/s | ~71 tok/s |
| Preço de Entrada | $0.25/M | $1.00/M | $0.15/M ⚡ |
| Preço de Saída | $1.50/M | $5.00/M | $0.60/M ⚡ |
| Janela de Contexto | 1M tokens ⚡ | 200K tokens | 128K tokens |
| Entrada Multimodal | 5 tipos ⚡ | 2 tipos | 2 tipos |
| Thinking Mode | ✅ | ❌ | ❌ |
| Function Calling | ✅ | ✅ | ✅ |
| Batch API | ✅ | ✅ | ✅ |
Resumo da Comparação:
- Prioridade em Velocidade: Os 380 tok/s do Flash-Lite são 3.5x mais rápidos que o Haiku e 5.4x mais rápidos que o GPT-5 mini.
- Prioridade em Custo: O GPT-5 mini tem preços absolutos mais baixos, mas a vantagem de velocidade do Flash-Lite pode compensar a diferença de custo.
- Prioridade em Funcionalidades: O Flash-Lite lidera claramente em comprimento de contexto (1M) e suporte multimodal (5 tipos).
🎯 Recomendação de Escolha: Qual modelo leve escolher depende do cenário específico. Recomendamos fazer testes práticos de comparação através da APIYI apiyi.com. A plataforma suporta uma interface unificada para invocação de todos os modelos acima, facilitando a troca rápida e a avaliação.
Guia Rápido para o Gemini 3.1 Flash-Lite Preview
Exemplo Mínimo
Aqui está o código mais simples para invocar o Gemini 3.1 Flash-Lite Preview através da plataforma APIYI, funcionando em apenas 10 linhas:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[{"role": "user", "content": "Explique computação quântica em uma frase"}]
)
print(response.choices[0].message.content)
Ver código de implementação completo (incluindo Thinking Mode)
from openai import OpenAI
from typing import Optional
def call_flash_lite(
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
enable_thinking: bool = False
) -> str:
"""
Invoca o Gemini 3.1 Flash-Lite Preview
Args:
prompt: Entrada do usuário
system_prompt: Comando do sistema
max_tokens: Número máximo de tokens de saída
enable_thinking: Se deve habilitar o Thinking Mode
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
except Exception as e:
return f"Erro: {str(e)}"
# Exemplo de uso
result = call_flash_lite(
prompt="Analise a complexidade de tempo do código abaixo e dê sugestões de otimização",
system_prompt="Você é um engenheiro de algoritmos sênior"
)
print(result)
Sugestão: Obtenha uma chave API e créditos de teste gratuitos através da APIYI apiyi.com para validar rapidamente o desempenho do Gemini 3.1 Flash-Lite Preview no seu cenário. Recargas a partir de US$ 100 dão direito a um bônus de US$ 10, com descontos de até 20%.
Cenários de aplicação do Gemini 3.1 Flash-Lite Preview
Cenários de uso recomendados
| Cenário | Descrição | Por que escolher o Flash-Lite |
|---|---|---|
| Tradução em larga escala | Fluxo de trabalho de tradução de conteúdo multilíngue | Saída ultrarrápida de 380 tok/s + baixo custo |
| Moderação de conteúdo | Classificação e filtragem de conteúdo gerado pelo usuário | Chamadas de alta frequência + custo controlável |
| Extração de dados | Extração e organização de dados estruturados | Suporte a saída em JSON Schema |
| Roteamento de Agent | Atuar como camada de roteamento para distribuir solicitações | Latência ultrabaixa + Function Calling |
| Processamento de documentos | Análise e resumo de PDFs/documentos longos | Contexto de 1M + entrada multimodal |
| Transcrição de áudio | Conversão de fala em texto e análise | Suporte nativo a entrada de áudio |
Cenários não recomendados
- Escrita criativa complexa: Modelos de nível Pro têm mais vantagens em criação profunda
- Geração de imagens/áudio: Flash-Lite suporta apenas saída de texto
- Diálogo em streaming em tempo real: Não suporta Live API
- Necessidade de precisão máxima de raciocínio: Para cenários que exigem extrema precisão, é recomendável usar o Gemini 3.1 Pro
🎯 Sugestão de cenário: Não tem certeza de qual modelo é o melhor para o seu caso? Através da APIYI em apiyi.com você pode alternar e comparar rapidamente entre Gemini 3.1 Flash-Lite, Claude Haiku e GPT-5 mini para encontrar a solução ideal.
Perguntas frequentes
Q1: Qual é a diferença entre o Gemini 3.1 Flash-Lite Preview e o Gemini 2.5 Flash?
A diferença central está na arquitetura e no desempenho: o Flash-Lite é baseado na arquitetura do Gemini 3 Pro (e não na arquitetura do Gemini 2), com resposta do primeiro token 2.5 vezes mais rápida e velocidade de saída aumentada em 45%, atingindo ~380 tok/s. Além disso, adicionou recursos avançados como Thinking Mode e execução de código.
Q2: Qual é a estabilidade da versão Preview? É adequada para uso em ambiente de produção?
A funcionalidade e o desempenho da versão Preview podem ser ajustados na versão final. Recomenda-se testar primeiro em negócios não críticos; para negócios críticos, pode-se configurar um plano de fallback. Ao chamar através da APIYI em apiyi.com, você pode alternar facilmente entre modelos, implementando uma estratégia de fallback flexível.
Q3: Como começar rapidamente a testar o Gemini 3.1 Flash-Lite Preview?
Recomenda-se testar através de uma plataforma de agregação de API que suporte vários modelos:
- Acesse a APIYI em apiyi.com e registre uma conta
- Obtenha uma chave API e crédito gratuito
- Use os exemplos de código deste artigo, definindo o modelo como
gemini-3.1-flash-lite-preview - Recarregue a partir de 100 dólares e ganhe 10 dólares de bônus, com descontos de até 20%
Resumo
Os pontos principais do Gemini 3.1 Flash-Lite Preview:
- Desempenho ultrarrápido: Velocidade de saída de ~380 tok/s, classificado em 2º lugar entre 132 modelos, resposta do primeiro Token 2,5 vezes mais rápida que o Flash 2.5.
- Alto custo-benefício: Entrada a $0,25/M, saída a $1,50/M, apenas 1/8 do custo do Gemini 3 Pro, ideal para invocações de alta frequência e em grande escala.
- Funcionalidade abrangente: Contexto de 1M + 5 modalidades de entrada + Modo Thinking + Function Calling, a configuração mais completa entre os modelos leves.
- Genética de nível Pro: Baseado na arquitetura do Gemini 3 Pro, com excelente desempenho em benchmarks como GPQA Diamond (86,9%).
Para cenários de aplicação de IA que exigem grande escala, baixo custo e alta velocidade, o Gemini 3.1 Flash-Lite Preview é um dos modelos leves mais dignos de atenção atualmente.
Recomendamos testar rapidamente através do APIYI apiyi.com. Os preços da plataforma são consistentes com os oficiais do Google, com um bônus de $10 para recargas a partir de $100, e descontos de até 20%. Acesso unificado a mais de 400 Modelos de Linguagem Grande.
📚 Referências
-
Documentação oficial de modelos do Google AI: Especificações técnicas completas do Gemini 3.1 Flash-Lite Preview
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview - Descrição: Documentação oficial da API, contendo a lista mais recente de parâmetros e funcionalidades.
- Link:
-
Model Card do Google DeepMind: Dados de benchmark e avaliação de segurança
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/ - Descrição: Model Card oficial, contendo resultados detalhados de benchmarks e informações de treinamento.
- Link:
-
Avaliação do Artificial Analysis: Análise independente de desempenho e preço por terceiros
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview - Descrição: Contém dados de avaliação independente como velocidade de saída, TTFT, índice de inteligência, etc.
- Link:
-
Blog oficial do Google: Anúncio de lançamento do Gemini 3.1 Flash-Lite
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/ - Descrição: Artigo oficial de lançamento, apresentando o posicionamento do produto e características principais.
- Link:
Autor: Equipe Técnica do APIYI
Discussão técnica: Bem-vindo(a) para discutir na seção de comentários. Mais materiais podem ser encontrados no centro de documentação do APIYI docs.apiyi.com.