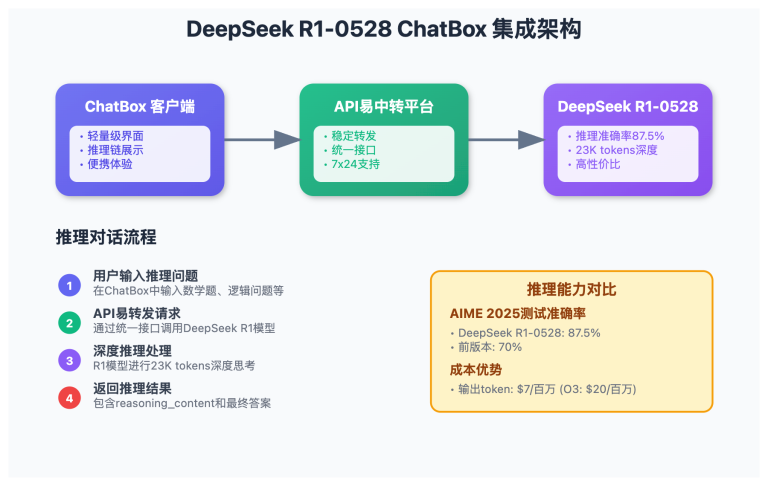
OpenClaw 联网搜索功能未开启时,AI 只能依赖训练数据作答,无法获取 2026 年的实时信息。本文手把手教你配置 OpenClaw 联网搜索,支持 Brave、Perplexity、Gemini、Grok、Kimi 5 大搜索引擎接入。
核心价值:读完本文,你将掌握 OpenClaw web_search 和 web_fetch 的完整配置方法,以及 3 种配置方式的适用场景,让 AI Agent 随时获取最新信息。

一、OpenClaw 是什么,为何联网搜索如此重要
OpenClaw 是 2025 年底由奥地利开发者 Peter Steinberger(@steipete,PSPDFKit 创始人)发布的开源 AI Agent 框架,前身为 Clawdbot 和 Moltbot。2026 年 3 月,项目在 GitHub 的 Star 数突破 25 万,60 天内超越了 React 用了十年才达到的记录,成为 GitHub 历史上增长最快的开源项目。
OpenClaw 的核心定位
OpenClaw 的口号是「Your own personal AI assistant. Any OS. Any Platform.」——它不是一个聊天机器人,而是一个能真正行动的 AI Agent:
- 消息优先:通过 WhatsApp、Telegram、Slack、Discord、Signal 等 20+ 平台发消息控制
- 模型无关:支持 Claude、GPT-4o、Gemini、Mistral,以及 Ollama 本地模型
- 全面自动化:浏览网页、管理邮件日历、执行终端命令、部署代码、自动化浏览器操作
没有联网搜索的 OpenClaw 是残缺的
安装 OpenClaw 后,默认情况下 AI 只能依赖语言模型的训练数据作答。这意味着:
- 问「今天有什么 AI 新闻」→ 得到的是几个月前的旧信息
- 问「OpenClaw 最新版本是什么」→ 模型根本不知道
- 问「某只股票今天的价格」→ 无法获取实时数据
联网搜索功能是让 OpenClaw 真正具备实用价值的关键能力。
🎯 模型推荐:配置联网搜索后,建议搭配 Claude 3.7 Sonnet 或 GPT-4o 等工具使用能力强的模型。通过 API易 apiyi.com 可以一个 API Key 统一接入所有主流模型,无需单独申请多个账号,大幅降低配置成本。
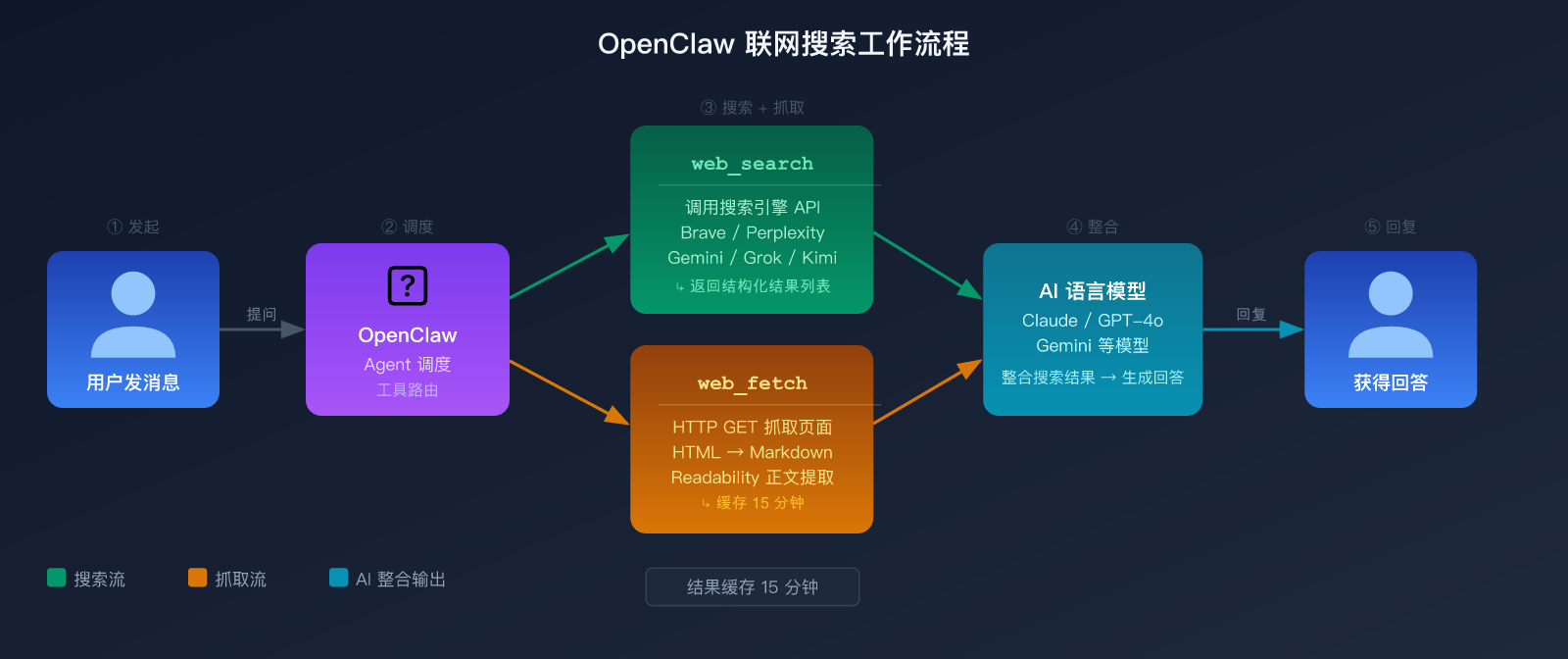
二、OpenClaw 联网搜索的两大核心工具
OpenClaw 联网搜索功能由两个独立工具协作实现,理解它们的区别对正确配置至关重要。
web_search 和 web_fetch 功能对比
| 工具 | 核心功能 | 工作方式 | 适用场景 |
|---|---|---|---|
web_search |
调用搜索引擎 API,返回相关结果列表 | 发送查询 → 返回结构化结果 | 查询最新信息、事件检索 |
web_fetch |
HTTP GET 抓取指定网页内容 | HTML → Markdown 正文提取 | 读取具体页面详细内容 |
这两个工具分工明确:web_search 负责「找到哪里有信息」,web_fetch 负责「读取那个页面的具体内容」。
web_search 工具详解
web_search 的核心职责是调用你配置的搜索引擎 API,返回结构化的搜索结果。
主要特性:
- 支持 5 大搜索提供商(Brave、Perplexity、Gemini、Grok、Kimi)
- 默认缓存 15 分钟,相同查询不重复消耗 API 额度
- 支持高级过滤:国家/语言、时间范围(freshness)、域名白/黑名单
- Perplexity 提供商返回 AI 合成摘要 + 实时引用来源,而非原始 URL 列表
自动检测顺序(未指定提供商时):
Brave → Gemini → Perplexity → Grok → Kimi
只要对应的 API Key 存在于环境变量或配置文件中,OpenClaw 会按此顺序自动启用第一个可用的提供商。
web_fetch 工具详解
web_fetch 是一个底层的网页抓取工具,执行 HTTP GET 请求并将 HTML 转换为可读的 Markdown 格式。
关键特性:
- 使用 Readability 算法提取正文(自动去除导航栏、广告、侧边栏等噪音)
- 不执行 JavaScript(无法抓取 React/Vue 等 SPA 动态渲染内容)
- 默认使用 Chrome-like User-Agent,模拟正常浏览器访问
- 自动屏蔽内网/私有 IP 地址(安全保护机制)
- 支持 Firecrawl 集成,可处理 JS 渲染页面(需额外配置)
- 默认限制重定向次数(可通过
maxRedirects调整)
💡 两者搭配的标准用法:先用
web_search找到相关 URL 列表,再用web_fetch读取具体页面的完整内容。这是 OpenClaw Agent 获取完整准确信息的标准工作流。
三、5 大搜索引擎提供商全面对比
选择合适的搜索提供商直接影响联网搜索的质量和成本。
OpenClaw 支持的联网搜索提供商对比表
| 提供商 | 环境变量 | 免费额度 | 核心优势 | 最适合场景 |
|---|---|---|---|---|
| Brave Search | BRAVE_API_KEY |
2000 次/月 | 独立索引,无追踪,隐私保护 | 日常搜索,新手首选 |
| Perplexity | PERPLEXITY_API_KEY |
按量计费 | AI 合成摘要 + 引用来源 | 研究型深度查询 |
| Gemini | GEMINI_API_KEY |
免费额度充足 | Google 全量索引,覆盖广 | 综合信息查询 |
| Grok | XAI_API_KEY |
按量计费 | 实时 X/Twitter 数据 | 社交媒体热点追踪 |
| Kimi | KIMI_API_KEY / MOONSHOT_API_KEY |
按量计费 | 中文内容优化 | 中文场景搜索 |
各提供商使用建议
Brave Search — 推荐新手首选
Brave Search 拥有完全独立的搜索索引(非 Google/Bing 代理),是目前规模最大的独立搜索引擎之一。每月 2000 次免费查询额度对个人用户完全够用,注册地址:brave.com/search/api/,选择 Search 计划生成 API Key。
Perplexity — 推荐研究型用户
Perplexity 使用 sonar-pro 模型,返回的不是原始 URL 列表,而是 AI 合成的答案摘要加引用来源。2026 年 3 月更新后新增了语言、地区、时间过滤器,适合需要深度研究的场景。注册地址:perplexity.ai/settings/api
Gemini — 推荐 Google 生态用户
通过内置的 Google Search grounding 功能实现联网,依托 Google 最强大的索引数据库,综合覆盖面最广。已有 Google Cloud 账号的用户可直接复用现有 API Key。
Grok — 推荐追踪实时热点
xAI 的 Grok 拥有访问 X(原 Twitter)实时数据的独特优势,是追踪社交媒体动态、行业舆论、科技新闻最快的选择。
Kimi — 推荐中文场景
月之暗面的 Kimi 对中文内容有专项优化,同时支持 KIMI_API_KEY 和 MOONSHOT_API_KEY 两种环境变量名(兼容不同版本)。
🎯 搭配建议:搜索提供商决定「用什么引擎找信息」,AI 模型决定「如何理解和整合信息」。建议通过 API易 apiyi.com 接入 Claude 3.7 Sonnet,其工具调用能力特别出色,能准确判断何时启用联网搜索、如何整合多个搜索结果。API易 支持按量计费,测试成本极低。
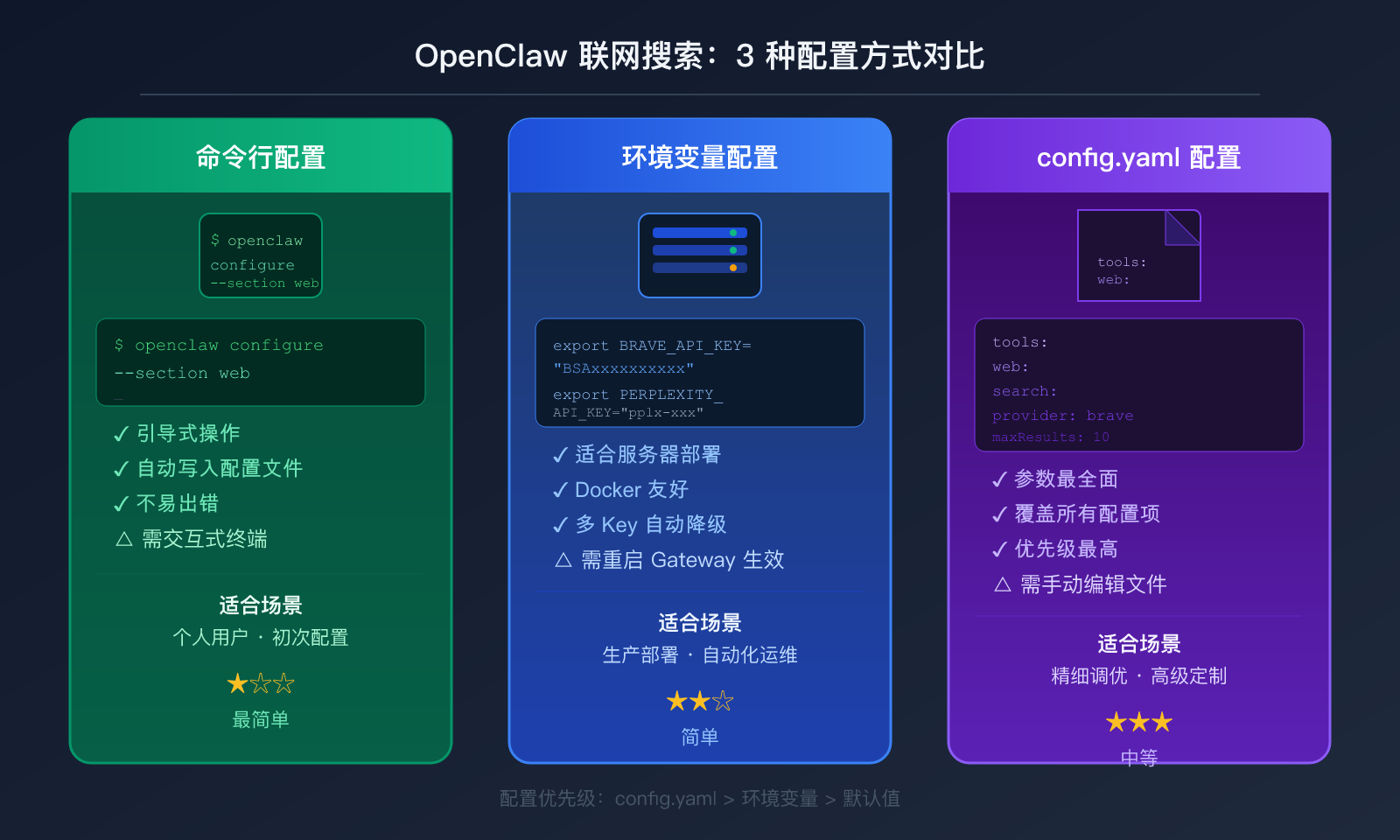
四、OpenClaw 联网搜索 3 种配置方式详解
方式一:命令行交互式配置(推荐新手)
最简单直观的配置方式,OpenClaw 内置专用配置命令:
openclaw configure --section web
执行后进入交互式界面,按提示选择搜索提供商并输入 API Key:
? Select web search provider:
❯ brave
perplexity
gemini
grok
kimi
? Enter your Brave Search API key: BSA**********************
✅ Web search configured successfully!
Provider: brave
Test with: openclaw "search for latest AI news"
配置完成后,设置自动写入 ~/.openclaw/config.yaml,重启 Gateway 后即时生效。
验证配置是否成功:
# 查看当前配置
openclaw config show --section web
# 测试联网搜索
openclaw "use web_search to find the latest OpenClaw release version"
方式二:环境变量配置(推荐生产/服务器部署)
环境变量方式适合在 Linux 服务器、Docker 容器、CI/CD 环境中部署,便于密钥统一管理:
# ========== 选择一个提供商设置,或同时设置多个用于自动降级 ==========
# Brave Search(首选,免费额度充足)
export BRAVE_API_KEY="BSAxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Perplexity(深度研究场景)
export PERPLEXITY_API_KEY="pplx-xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Gemini(Google 全量索引)
export GEMINI_API_KEY="AIzaxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Grok / xAI(实时社交数据)
export XAI_API_KEY="xai-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Kimi / 月之暗面(中文优化)
export KIMI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 或兼容旧版本:
export MOONSHOT_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
将以上内容添加到 ~/.bashrc 或 ~/.zshrc,然后执行 source ~/.bashrc 立即生效。
自动检测机制说明:
设置多个提供商的 Key 时,OpenClaw 按固定优先级自动选择第一个可用的:
检测顺序: Brave → Gemini → Perplexity → Grok → Kimi
若想强制使用特定提供商,需在 config.yaml 中显式指定(见方式三)。
🎯 密钥管理建议:如果你同时运行 OpenClaw 和直接调用 AI API,建议通过 API易 apiyi.com 作为统一的 AI 模型接入层——只需维护一个 API Key 就能接入 Claude、GPT-4o、Gemini 等所有主流模型,大幅简化密钥管理和成本控制。访问 apiyi.com 注册即可免费获取体验额度。
方式三:config.yaml 文件配置(推荐高级用户)
直接编辑配置文件,提供最精细的参数控制,适合需要自定义缓存时间、超时、最大结果数的场景:
# 文件位置: ~/.openclaw/config.yaml
tools:
web:
search:
enabled: true
provider: brave # 明确指定提供商(优先级高于环境变量)
maxResults: 10 # 最大返回结果数(5/10/20,影响token消耗)
timeoutSeconds: 15 # 搜索超时时间
cacheTtlMinutes: 15 # 结果缓存时长(实时数据建议设为1)
apiKey: "BSAxxxxxxxxxx" # Brave API Key
# ---- 切换为 Perplexity 时的配置 ----
# provider: perplexity
# perplexity:
# apiKey: "pplx-xxxxxxxxxx"
# model: "sonar-pro"
# ---- 切换为 Gemini 时的配置 ----
# provider: gemini
# gemini:
# apiKey: "AIzaxxxxxxxxxx"
fetch:
enabled: true
timeoutSeconds: 20 # 页面抓取超时(复杂页面可适当延长)
cacheTtlMinutes: 30 # 页面缓存(页面内容变化慢,可设更长)
maxRedirects: 5 # 最大重定向次数
# ---- Firecrawl 集成(处理 JS 渲染页面)----
# firecrawl:
# apiKey: "fc-xxxxxxxxxxxxxxxxxxxx"
# baseUrl: "https://api.firecrawl.dev"
三种配置方式适用场景汇总:
| 配置方式 | 操作难度 | 适用场景 | 优点 |
|---|---|---|---|
| 命令行交互 | ⭐ 最简单 | 个人用户初次配置 | 引导式操作,不易出错 |
| 环境变量 | ⭐⭐ 简单 | 服务器/Docker 部署 | 便于自动化管理 |
| config.yaml | ⭐⭐⭐ 中等 | 精细调优、多参数定制 | 参数最全,优先级最高 |
五、高级配置:过滤参数、缓存优化与 Firecrawl 集成
OpenClaw 联网搜索高级过滤参数
web_search 提供丰富的过滤选项,可以大幅提升搜索结果的精准度:
| 参数名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
country |
string | 限定结果来源国家 | "US", "CN", "JP" |
language |
string | 限定结果语言 | "en", "zh", "ja" |
freshness |
string | 时间范围快捷过滤 | "day", "week", "month" |
startDate |
string | 自定义起始日期 | "2026-01-01" |
endDate |
string | 自定义截止日期 | "2026-03-14" |
includeDomainsFilter |
array | 只搜索指定域名 | ["github.com", "arxiv.org"] |
excludeDomainsFilter |
array | 排除指定域名 | ["reddit.com", "quora.com"] |
maxResults |
number | 本次查询返回结果数 | 5 / 10 / 20 |
这些参数由 Agent 在调用 web_search 时动态传入,无需修改配置文件。
缓存机制深度配置
OpenClaw 对 web_search 和 web_fetch 均实现了查询级缓存,合理配置缓存可以显著降低 API 成本:
tools:
web:
search:
cacheTtlMinutes: 15 # 搜索结果缓存15分钟(默认)
fetch:
cacheTtlMinutes: 30 # 页面内容缓存30分钟(默认)
按场景调整建议:
- 追踪实时股价/新闻 →
cacheTtlMinutes: 1(几乎不缓存) - 查询技术文档/规范 →
cacheTtlMinutes: 60(文档更新慢) - 通用搜索场景 → 保持默认 15 分钟即可
Firecrawl 集成配置
web_fetch 默认不执行 JavaScript,无法抓取 React/Vue 等 SPA 动态渲染的网站。集成 Firecrawl 可以解决这个限制:
tools:
web:
fetch:
firecrawl:
apiKey: "fc-xxxxxxxxxxxxxxxxxxxx"
baseUrl: "https://api.firecrawl.dev" # 或自托管实例地址
Firecrawl 相比默认 web_fetch 的优势:
- 支持完整 JavaScript 渲染(使用无头浏览器)
- 更强的反爬绕过能力
web_search+ Firecrawl 模式:单次 API 调用同时返回搜索结果列表 + 每个页面的完整抓取内容
注册 Firecrawl API Key:访问 firecrawl.dev 注册账号即可。
多提供商备份配置最佳实践
建议同时配置 2-3 个提供商的 API Key 作为备份,防止某个服务临时不可用:
# 推荐的备份配置组合
export BRAVE_API_KEY="xxx" # 主要提供商(免费额度)
export PERPLEXITY_API_KEY="xxx" # 深度研究备用
export GEMINI_API_KEY="xxx" # Google索引备用
🎯 运维提示:API Key 轮换和额度监控很容易被忽视。如果你用 OpenClaw 处理工作任务,建议设置一个统一的 API 网关来管理所有 Key 的用量。API易 apiyi.com 提供完整的用量统计和余额预警功能,支持多个 AI 提供商统一管理。
六、常见问题排查(FAQ)
Q1:配置了 API Key 但 OpenClaw 联网搜索还是不生效?
逐步排查流程:
# 第一步:确认环境变量已生效
echo $BRAVE_API_KEY # 应输出非空内容
# 第二步:确认 Gateway 是否读取到配置
openclaw status --verbose
# 第三步:以调试模式启动 Gateway 查看详细日志
openclaw gateway --log-level debug
# 第四步:直接测试搜索功能
openclaw "please use web_search to search for 'OpenClaw latest release 2026'"
最常见原因:
- 环境变量在 Gateway 启动「之后」才设置 → 必须重启 Gateway
config.yaml格式错误(YAML 对缩进极为敏感)→ 用 YAML 验证器检查- API Key 已过期或本月免费额度已用完 → 登录对应平台检查
Q2:如何在不同搜索提供商之间快速切换?
方法一(最简单):重新运行配置命令
openclaw configure --section web
方法二:修改 config.yaml 中的 provider 字段,然后重启 Gateway
tools:
web:
search:
provider: perplexity # 从 brave 切换到 perplexity
方法三(环境变量配置场景):只保留目标提供商的 Key,移除其他提供商的 Key,重启 Gateway
Q3:web_fetch 无法抓取某些网站怎么办?
常见原因和解决方案:
- 网站是 SPA(单页应用) → 配置 Firecrawl 集成,支持 JS 渲染
- 网站有强力反爬机制 → 尝试 Firecrawl 或通过 web_search 获取该网站的搜索摘要
- 重定向次数过多 → 适当增大
maxRedirects配置值 - 内网/私有地址 → OpenClaw 默认屏蔽(安全保护),需要访问内网请参考安全配置文档
🎯 模型搭配提示:处理复杂网页抓取任务时,AI 模型的理解能力同样重要。Claude 3.7 Sonnet 在解析和整合网页内容方面表现出色。通过 API易 apiyi.com 接入,免去繁琐的 Anthropic 官方注册流程,国内用户也可稳定访问,按量计费零门槛。
Q4:OpenClaw 联网搜索安全吗?
OpenClaw 联网搜索涉及以下安全注意事项:
已知历史漏洞(已修复):「ClawJacked」漏洞曾允许恶意网站通过 web_fetch 劫持 OpenClaw 实例,窃取 API Key 并执行任意命令。该漏洞在 2026.2.x 版本后已修复。
当前安全最佳实践:
# 始终保持最新版本
openclaw update
# 检查安全状态
openclaw security-check
# 不要将 Gateway 端口直接暴露到公网
# 推荐使用 Tailscale 或 ngrok 等安全隧道
注意:公网上约有 4.2 万个暴露的 OpenClaw 实例存在安全风险。强烈建议不要将 openclaw gateway 的端口(默认 3000)直接开放到互联网。
Q5:如何确认 Agent 正在使用联网搜索而非训练数据?
在对话中明确指定使用 web_search 工具:
请用 web_search 搜索 "OpenClaw latest release 2026 March",然后告诉我最新版本号
如果 Agent 正确使用了联网搜索,回答中会包含具体的搜索结果引用、发布时间,以及「根据搜索结果」等说明。如果 Agent 直接说「我的知识截止到…」,则说明联网搜索未正确启用。
🎯 工具调用能力对比:不同 AI 模型的工具调用能力差异显著。Claude 3.7 Sonnet 在理解何时以及如何使用 web_search 工具方面表现最优秀。通过 API易 apiyi.com 可以轻松对比不同模型的工具调用效果,免费额度足够完成初期测试。
七、总结:OpenClaw 联网搜索配置要点回顾
完成本文所有配置后,你的 OpenClaw 将具备完整的实时联网搜索能力。
核心配置要点汇总
| 配置项 | 推荐值 | 说明 |
|---|---|---|
| 新手首选提供商 | Brave Search | 免费 2000 次/月,独立索引 |
| 研究型查询 | Perplexity sonar-pro | AI 合成摘要 + 引用来源 |
| 中文场景 | Kimi(月之暗面) | 中文内容专项优化 |
| 配置命令 | openclaw configure --section web |
交互式引导,最简单 |
| 缓存时长 | 默认 15 分钟 | 实时数据建议设为 1 分钟 |
| JS 渲染页面 | 集成 Firecrawl | 处理 SPA 动态内容 |
| 安全建议 | 保持最新版 + 不暴露公网端口 | 防止 ClawJacked 类漏洞 |
OpenClaw 联网搜索工作流最佳实践
- 精准搜索词优于泛化词:「OpenClaw changelog February 2026」比「OpenClaw 新闻」效果好 10 倍
- 合理设置 maxResults:日常查询用 5 条(省 token),深度研究用 10-20 条
- web_search + web_fetch 组合使用:找到 URL 再深入读取,获取完整信息
- 配置多个备用提供商:防止单一提供商故障导致联网功能完全失效
- 定期更新 OpenClaw:安全补丁和新功能持续迭代,保持最新版本
🎯 一站式 AI 接入推荐:OpenClaw 需要搭配强大的语言模型才能发挥最大价值。推荐使用 API易 apiyi.com 统一接入 Claude 3.7 Sonnet、GPT-4o、Gemini 2.0 Flash 等顶级模型——一个 API Key,兼容 OpenAI 接口格式,轻松在不同模型间切换。访问 apiyi.com 注册即可免费领取体验额度,配合 OpenClaw 联网搜索,构建真正强大的个人 AI Agent。
本文基于 OpenClaw 2026.3.x 版本整理,配置方式可能随版本迭代有所调整。最新信息请参考官方文档 docs.openclaw.ai 获取权威说明。如需通过统一 API 接入多个 AI 模型,推荐 API易 apiyi.com。