作者注:手把手教你在 Chatbox 中通过自定义端点接入 gpt-image-2,并深度解析为什么 Chatbox 无法像 ChatGPT 网页版那样连续对话修改图片——背后是 images/generations、chat/completions、Responses API 三套端点的架构差异。
很多用户在 Chatbox 客户端中配置了 OpenAI API Key,输入 gpt-image-2 想直接生图,结果不是返回报错就是输出乱码。本文将给你两个答案:第一,Chatbox 接入 gpt-image-2 的正确做法(自定义端点配置 https://api.apiyi.com/v1/images/generations);第二,更重要的——为什么 Chatbox 无法像 ChatGPT 网页版那样"先生成一张图,再对话调整修改"。
这不是 Chatbox 的 bug,而是 OpenAI 官方把图像生成、对话补全、多轮编辑分配给了三个完全不同的 API 端点,Chatbox 默认走的那条路本身就不支持连续生图编辑。
核心价值:读完本文,你将彻底搞清楚 OpenAI 三个核心端点的边界与能力差异,知道什么场景下 Chatbox 够用、什么场景下必须切到 Responses API,以及如何用 APIYI 中转通道在国内稳定调用任意端点。
什么是 Chatbox 接入 gpt-image-2 的正确方式
先把最实用的内容放在前面——如果你只想立刻让 Chatbox 跑通 gpt-image-2 生图,按下面的步骤 5 分钟搞定。
Chatbox 接入 gpt-image-2 的核心配置
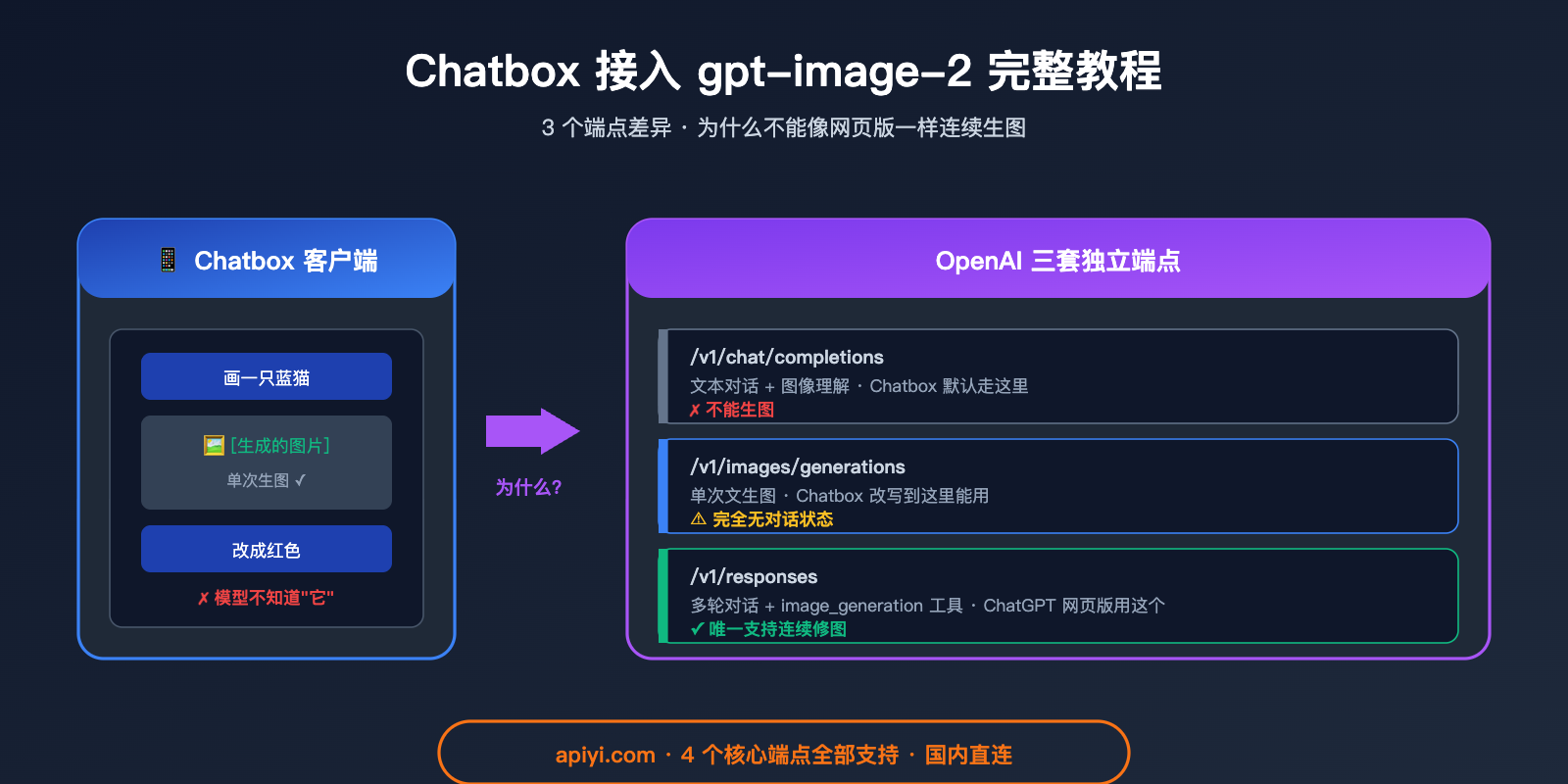
Chatbox 默认按"聊天对话补全"的方式调用 API(即 /v1/chat/completions 端点),但 gpt-image-2 不是一个对话模型,它是一个纯图像生成模型,调用端点是 /v1/images/generations。所以你必须用 Chatbox 的「自定义端点」功能改写默认地址。
完整配置步骤:
| 步骤 | 操作 | 关键参数 |
|---|---|---|
| 1 | 打开 Chatbox 设置 → 模型提供方 → 添加自定义提供方 | 选择 OpenAI API 兼容模式 |
| 2 | API Host | https://api.apiyi.com |
| 3 | API Path(关键改写) | /v1/images/generations |
| 4 | API Key | APIYI 控制台获取的 Bearer Token |
| 5 | Model 字段 | gpt-image-2 |
| 6 | 超时时间 | 设置 ≥ 360 秒 |
Chatbox 接入 gpt-image-2 的最小调用示例
下面是官方推荐的 curl 调用示例,可以先用它验证你的 API Key 是否可用:
curl --request POST \
--url https://api.apiyi.com/v1/images/generations \
--header 'Authorization: Bearer sk-your-apiyi-key' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-image-2",
"prompt": "横版 16:9 电影画幅,黄昏时的海边老灯塔"
}'
跑通这条 curl 后,再去 Chatbox 里把端点改写为 /v1/images/generations,就能用了。
🎯 配置提示:第一次配置 Chatbox 自定义端点时,建议先用 curl 验证 API Key 和端点路径是否正常。我们建议通过 API易 apiyi.com 平台领取测试额度,免费额度足够你完成全套配置验证。
Chatbox 接入 gpt-image-2 的常见配置错误
收集了用户最常踩的 5 个坑:
| 错误现象 | 根因 | 解决方案 |
|---|---|---|
返回 model not found |
端点用了 /v1/chat/completions |
改为 /v1/images/generations |
返回 invalid prompt format |
用了 chat 的 messages 格式 | 改用 prompt 字段(字符串) |
| 60 秒后请求超时 | 默认超时太短 | 调到 ≥ 360 秒(high 画质需要) |
| 图片不显示 | Chatbox 不解析 b64_json | 让响应返回 url 格式 |
| 中文 prompt 报错 | 编码问题 | 确认 Content-Type: application/json; charset=utf-8 |
Chatbox 接入 gpt-image-2 后为什么不能连续修改图片
这是本文最核心的技术点——很多用户配置完成后会问:"为什么我在 Chatbox 里生成一张图,再说'把它的天空改成蓝色',模型就完全听不懂了?而 ChatGPT 网页版可以无限次连续修改?"
答案不是 Chatbox 的 bug,而是端点本身就不支持。
Chatbox 接入 gpt-image-2 的端点架构限制
要解释清楚这个问题,我们必须先理解 OpenAI 官方目前提供的三个完全独立的端点:
| 端点 | 路径 | 设计目的 | 是否支持图像生成 | 是否有对话状态 |
|---|---|---|---|---|
| Chat Completions | /v1/chat/completions |
文本对话补全 | ❌ 仅图像输入 | ❌ 客户端管理 |
| Image Generations | /v1/images/generations |
单次文生图 | ✅ 仅生成 | ❌ 完全无状态 |
| Image Edits | /v1/images/edits |
单次图生图/编辑 | ✅ 编辑 | ❌ 完全无状态 |
| Responses API | /v1/responses |
多轮对话+工具调用 | ✅ 工具调用 | ✅ 服务端管理 |
关键真相:
- Chatbox 默认走
/v1/chat/completions——这个端点根本不支持生图 - 你改写到
/v1/images/generations后能生图,但这个端点是完全无状态的——每次请求都是孤立的 - ChatGPT 网页版背后用的是
/v1/responses——它内置了image_generation工具调用 + 服务端对话状态

为什么 ChatGPT 网页版可以连续修改图片
ChatGPT 网页版背后的工作流程是这样的:
- 你输入"画一只蓝色的猫"
- ChatGPT 调用
/v1/responses端点,模型决定调用image_generation工具 - 工具返回图片 ID(例如
ig_abc123),同时记录到当前会话的服务端状态 - 你接着说"把它换成红色"
- ChatGPT 再次调用
/v1/responses,传入previous_response_id - 模型基于上下文识别"它"指的是上一张图,调用
image_generation工具的edit动作 - 工具基于上一张图做编辑,返回新图
整个过程的关键是 previous_response_id + 服务端对话状态 + 内置 image_generation 工具——这三个能力 /v1/images/generations 端点全都没有。
Chatbox 当前架构的局限
Chatbox 是一个 Chat Completions 风格的客户端——它的核心数据模型是「messages 数组」(system / user / assistant 多轮消息)。它的工作机制:
- 把用户每条消息追加到 messages 数组
- 调用一个 chat 风格端点(默认
/v1/chat/completions) - 把响应追加到 messages
- 循环
当你把端点改写为 /v1/images/generations 时,Chatbox 实际上只是把请求路径换了一下——但 messages 数组还在按 chat 格式发送,端点也只接受单次 prompt,对话状态完全无法传递。
💡 技术解读:Chatbox 的核心设计假设是"端点是 chat 风格的",而 OpenAI 把图像生成和图像编辑设计成了独立的 RESTful 资源端点,这是架构层面的不匹配。我们建议通过 API易 apiyi.com 平台先测试
/v1/images/generations单次生图,效果验证 OK 后再规划是否需要切换到 Responses API。
Chatbox 接入 gpt-image-2 的能力边界与替代方案
知道了限制后,我们可以给出一份清晰的"能做什么、不能做什么"清单。
Chatbox + gpt-image-2 能做的事
| 场景 | 是否支持 | 说明 |
|---|---|---|
| 一句 prompt 生成单张图 | ✅ | 标准用法 |
| 中英文 prompt | ✅ | gpt-image-2 原生支持 |
| 指定尺寸/比例 | ✅ | 通过 size 参数 |
| 指定画质(standard/high) | ✅ | 通过 quality 参数 |
| 输出 URL 或 base64 | ✅ | 通过 response_format 参数 |
Chatbox + gpt-image-2 不能做的事
| 场景 | 是否支持 | 替代方案 |
|---|---|---|
| 生图后说"把它改成红色"修改 | ❌ | 切到 Responses API |
| 多轮迭代调整画面细节 | ❌ | 切到 Responses API |
| 上传图片 + prompt 做局部编辑 | ❌ Chatbox 不支持 | 切到 /v1/images/edits 或 Responses API |
| 多张参考图融合生成 | ❌ Chatbox 不支持 | 切到 Responses API |
| 服务端记录对话历史 | ❌ | 切到 Responses API |
用 Responses API 实现连续生图的最小代码
如果你需要"对话式修改图片",必须放弃 Chatbox 客户端,自己写代码调 /v1/responses 端点:
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
# 第一轮:生成初始图片
resp1 = client.responses.create(
model="gpt-5", # Responses API 需要 gpt-5 系列
input="画一只在月光下漫步的蓝色猫咪,写实风格",
tools=[{"type": "image_generation"}]
)
response_id_1 = resp1.id
print("第一张图:", resp1.output[-1])
# 第二轮:基于上一轮做修改(关键是 previous_response_id)
resp2 = client.responses.create(
model="gpt-5",
previous_response_id=response_id_1, # 串联对话状态
input="把它的颜色改成橙色,背景换成日出",
tools=[{"type": "image_generation"}]
)
print("修改后:", resp2.output[-1])
注意几个关键点:
- 必须用
gpt-5或更新的模型(gpt-image-2 不能直接作为对话模型调用) - 必须传
tools=[{"type": "image_generation"}]启用工具 - 必须用
previous_response_id串联对话历史,否则模型不知道"它"指什么
🚀 接入建议:用 Responses API 做连续生图时,base_url 设置为
https://api.apiyi.com/v1,与 OpenAI 官方字段完全一致,已有的 OpenAI SDK 代码改一行 base_url 即可切换。我们建议通过 API易 apiyi.com 接入,国内直连稳定。
Chatbox 接入 gpt-image-2 的实战配置流程
把所有理论铺垫完,下面给你一份完整的"从零开始"操作指南。
第一步:获取 APIYI 平台 API Key
- 访问 APIYI 控制台
api.apiyi.com - 注册账户后进入「API 令牌」页面
- 创建新 Token(建议为不同项目使用独立 Token)
- 复制完整的 Bearer Token(以
sk-开头)
第二步:配置 Chatbox 自定义提供方
在 Chatbox 中操作:
- 打开「设置」→ 「模型提供方」
- 点击「添加」→ 选择「自定义 OpenAI 兼容提供方」
- 填写以下字段:
名称: APIYI - 图像生成
API Host: https://api.apiyi.com
API Path: /v1/images/generations # 关键!必须改写
API Key: sk-your-apiyi-key
默认模型: gpt-image-2
- 高级设置:
- 请求超时:600 秒
- 重试次数:2
- 字符编码:UTF-8
第三步:发送测试 prompt
在 Chatbox 对话框中输入:
横版 16:9 电影画幅,黄昏时的海边老灯塔,
柔和的暖色调,海面有薄雾,2K 分辨率
如果配置正确,应该在 1-3 分钟内收到返回的图片。
第四步:常见问题快速排查
| 问题 | 检查项 |
|---|---|
| 不返回任何内容 | 检查 API Key 是否完整、是否有图像生成权限 |
| 返回错误码 401 | API Key 错误或过期,重新获取 |
| 返回错误码 404 | API Path 拼写错误,确认 /v1/images/generations |
| 返回错误码 429 | 触发速率限制,等待几分钟后重试 |
| 返回 timeout | 超时太短,调到 600 秒 |
💡 进阶建议:如果你需要把 gpt-image-2 集成到自己的应用而非桌面客户端,建议直接用 OpenAI 官方 SDK 调用
/v1/images/generations——比 Chatbox 灵活得多。我们建议通过 API易 apiyi.com 接入,base_url 替换为https://api.apiyi.com/v1即可。
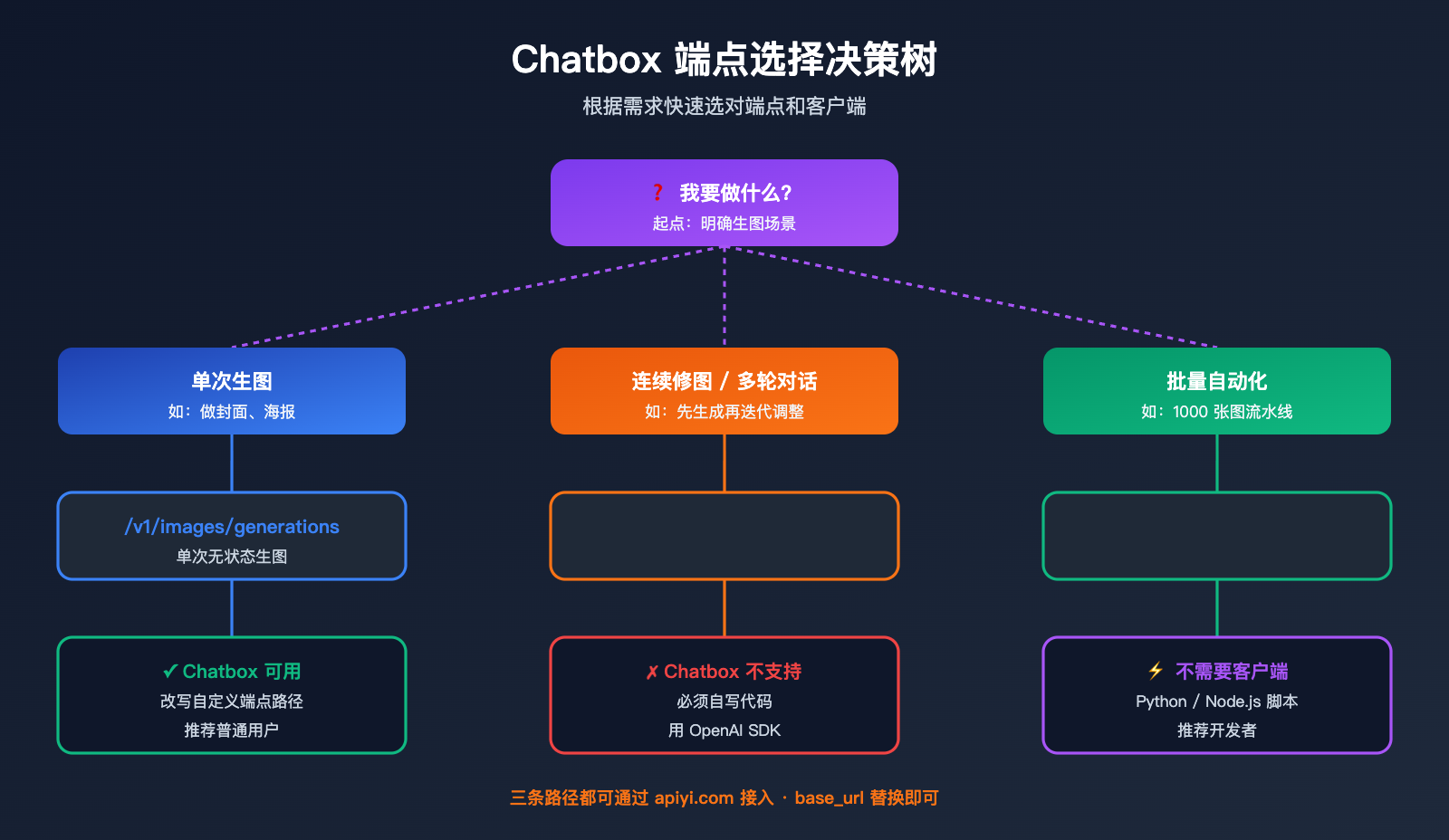
三大端点选型决策指南
下面这份决策表帮你快速判断什么场景该用什么端点:
| 你的需求 | 推荐端点 | 适用客户端 |
|---|---|---|
| 单次文生图(如做封面图) | /v1/images/generations |
Chatbox / curl / SDK |
| 单次图片编辑(带 mask) | /v1/images/edits |
curl / SDK(Chatbox 不友好) |
| 连续对话修改图片 | /v1/responses |
自写代码(Chatbox 不支持) |
| 仅文本对话 | /v1/chat/completions |
Chatbox / 任意 chat 客户端 |
| 文本对话 + 图像理解(看图说话) | /v1/chat/completions |
Chatbox 支持 |

Chatbox 接入 gpt-image-2 常见问题(FAQ)
问题 1:为什么 Chatbox 官方不直接支持 gpt-image-2 连续生图?
这不是 Chatbox 的设计缺陷,而是整个客户端类型的局限。Chatbox 的数据模型是 messages 数组(chat 风格),而 Responses API 的数据模型是 previous_response_id + 服务端对话状态——两者是根本不兼容的两种范式。Chatbox 要支持这个能力,相当于要重写整套对话引擎。
问题 2:Chatbox 自定义端点配置后,能上传图片让 gpt-image-2 编辑吗?
理论可以,实际很麻烦。/v1/images/edits 端点要求 multipart/form-data 格式上传图像文件,而 Chatbox 的对话框只支持文本输入。强行配置会出现 415 错误。推荐替代:用 curl/Postman 或自写脚本调 /v1/images/edits。
问题 3:APIYI 中转通道支持 Responses API 吗?
完全支持。APIYI 是官转通道,请求/响应字段与 OpenAI 官方 100% 同步,包括 /v1/responses、/v1/images/generations、/v1/images/edits、/v1/chat/completions 全部 4 个核心端点。我们建议通过 API易 apiyi.com 调用 Responses API 实现连续生图,国内直连稳定,无需代理。
问题 4:用 Chatbox 调 gpt-image-2 时,prompt 字段最长能多长?
OpenAI 官方限制 prompt 字段最长 32000 字符,实际使用建议控制在 1000 字符以内——超长 prompt 容易让模型注意力分散,反而生成质量下降。
问题 5:能否在 Chatbox 中同时配置 Chat 模型和图像生成模型?
可以——Chatbox 支持配置多个「自定义提供方」。建议你创建两个:
APIYI - 对话→ 端点/v1/chat/completions→ 模型gpt-5/claude-sonnet-4-6等APIYI - 生图→ 端点/v1/images/generations→ 模型gpt-image-2
切换提供方就能在两种模式间切换。
问题 6:Chatbox 调用 gpt-image-2 失败时,怎么定位是 Chatbox 还是 API 的问题?
最快的方法是先用 curl 直接调 API——如果 curl 能跑通,问题在 Chatbox 配置;如果 curl 也失败,问题在 API Key 或网络。本文开头的 curl 示例可以直接复制使用。
问题 7:通过 APIYI 调用与 OpenAI 官方有什么差别?
字段完全一致——APIYI 是官转通道。区别主要在三个方面:国内直连不需要代理、有专门的中文技术支持、计费透明可见。我们建议国内开发者通过 API易 apiyi.com 接入 gpt-image-2,避免网络稳定性问题。
问题 8:什么时候应该放弃 Chatbox,改用 Responses API 自写代码?
三个明确信号:
- 你需要"对话式修图"——一次生成,多次细调
- 你需要图片+文本的混合输出(先讲解一段然后生图,再讲解再生图)
- 你做的是产品而不是个人玩,需要服务端管理对话状态
满足任一条件就该切到 Responses API。
Chatbox 接入 gpt-image-2 Key Takeaways
- Chatbox 默认走
/v1/chat/completions——这个端点根本不支持生图,必须改写为/v1/images/generations /v1/images/generations是无状态端点——每次请求都是独立的,无法实现"连续修改"- ChatGPT 网页版的连续生图能力来自 Responses API——内置
image_generation工具 +previous_response_id对话状态 - Chatbox 无法实现连续生图不是 bug——是 chat 风格客户端与 Responses API 范式的根本差异
- 替代方案:需要连续生图时用 OpenAI SDK 自写代码调
/v1/responses,必须用 gpt-5 系列模型 - 国内调用建议:通过 API易 apiyi.com 接入,4 个核心端点全部支持,base_url 替换即可
- 快速排查:配置失败时先用 curl 验证,curl 能跑通问题就在客户端而非 API
总结
Chatbox 接入 gpt-image-2 的"配置"问题只是表象,真正值得开发者理解的是 OpenAI 三套独立端点架构——它们分别为不同的使用场景设计,能力边界完全不同:
- Chat Completions 是"文本对话 + 图像理解"的端点,不能生图
- Images Generations / Edits 是"单次生图/编辑"的无状态端点,简单直接但不能多轮迭代
- Responses API 是"多轮对话 + 工具调用"的端点,唯一能实现"对话式修图"的途径
Chatbox 因为是 chat 风格客户端,只能完美适配前两种模式中的一种——通过自定义端点改写支持单次生图。但要做到 ChatGPT 网页版那种"无限对话修改",必须放弃客户端工具,自己写代码调 Responses API。
理解这一点之后,你的工作流选择就会清晰:
- 小规模、单次生图、个人玩 → Chatbox +
/v1/images/generations - 需要连续修图、产品级集成 → Responses API + 自写代码
- 批量生图、自动化流水线 → 直接 SDK 调
/v1/images/generations
✨ 最后的建议:对于国内开发者,无论选择哪条路,我们建议通过 API易 apiyi.com 平台接入——4 个核心端点全部支持、与 OpenAI 官方字段 100% 一致、国内直连稳定、按 token 透明计费。新用户还有免费测试额度,足够你完成 Chatbox 配置和 Responses API 双路验证。
作者:APIYI Team
最后更新:2026-05-02