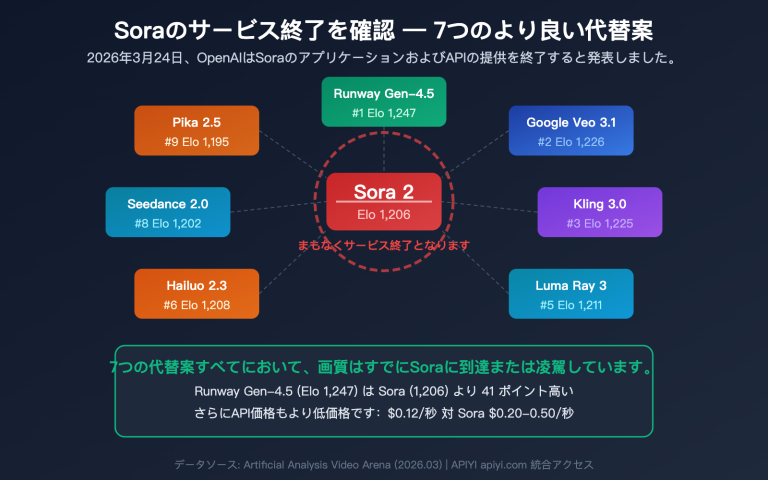
最近、「Magi AI」や「MAGI-1」という名前を耳にする機会が増えましたが、Sora、Kling、Veo と何が違うのか疑問に思っていませんか?この記事では、そんな方のために基礎から分かりやすく解説します。Magi AI は、Sand AI がオープンソース化した非常に興味深い動画生成モデルです。**世界初の一線級の性能を誇る「自己回帰型動画生成モデル」**であり、無限の長さの動画生成をサポートしています。
この記事の価値: 読み終える頃には、Magi AI とは何か、なぜ Sora や Kling とは異なるアプローチをとっているのか、何に使えるのか、そして 5 分で環境を構築する方法が明確になります。

Magi AI とは:核心ポイント
一言で定義すると:Magi AI = Sand AI がオープンソース化した、「自己回帰 + 拡散」混合アーキテクチャに基づく動画生成モデルです。
Sand.ai チーム(CEO は、名高い Swin Transformer 論文の共同著者である Yue Cao 氏)によって開発され、2025 年 4 月 21 日に MAGI-1 が初公開、2026 年には Magi-1.1 へと進化しました。コード、重み、推論ツールはすべて GitHub および Hugging Face にて Apache 2.0 ライセンスで公開されています。
| ポイント | 説明 | 価値 |
|---|---|---|
| オープンソースライセンス | Apache 2.0 | 商用利用可能 |
| モデル規模 | 4.5B / 24B の 2 バージョン | 個人から企業まで対応 |
| コアアーキテクチャ | 自己回帰 + Diffusion Transformer | 世界初の一線級自己回帰動画モデル |
| キラー機能 | 無限の長さの動画生成 | Sora/Kling には不可能 |
| 基本単位 | 24 フレームのチャンク単位生成 | ストリーミング生成に対応 |
| 物理的理解 | Physics-IQ 56.02% | 同類モデルを大幅に凌駕 |
| 制御性 | チャンクごとのプロンプト | フレーム単位での精密な制御 |
| GitHub | SandAI-org/MAGI-1 | 完全なコード + 重み |
💡 素早く理解する: Magi AI は、Sora、Veo、Kling とは全く異なる道を歩んでいます。これらの主要モデルは動画全体を一度に生成するため、長さに上限があります。一方、Magi-1 はチャンクごとに自己回帰的に生成するため、理論上は無限に生成を続けることができます。これは AI 動画分野における真の差別化イノベーションです。現在主流の動画生成モデルを比較検討したい場合は、APIYI (apiyi.com) を通じて Veo、Kling、Wan などを一括接続し、ローカルでオープンソースの Magi を実行するのが、最もコストパフォーマンスの高い比較手法です。
Magi AIの核心技術アーキテクチャを理解するには、まずその「自己回帰型チャンク生成」メカニズムを知る必要があります。これは、他の主要な動画生成モデルと最も大きく異なる点です。
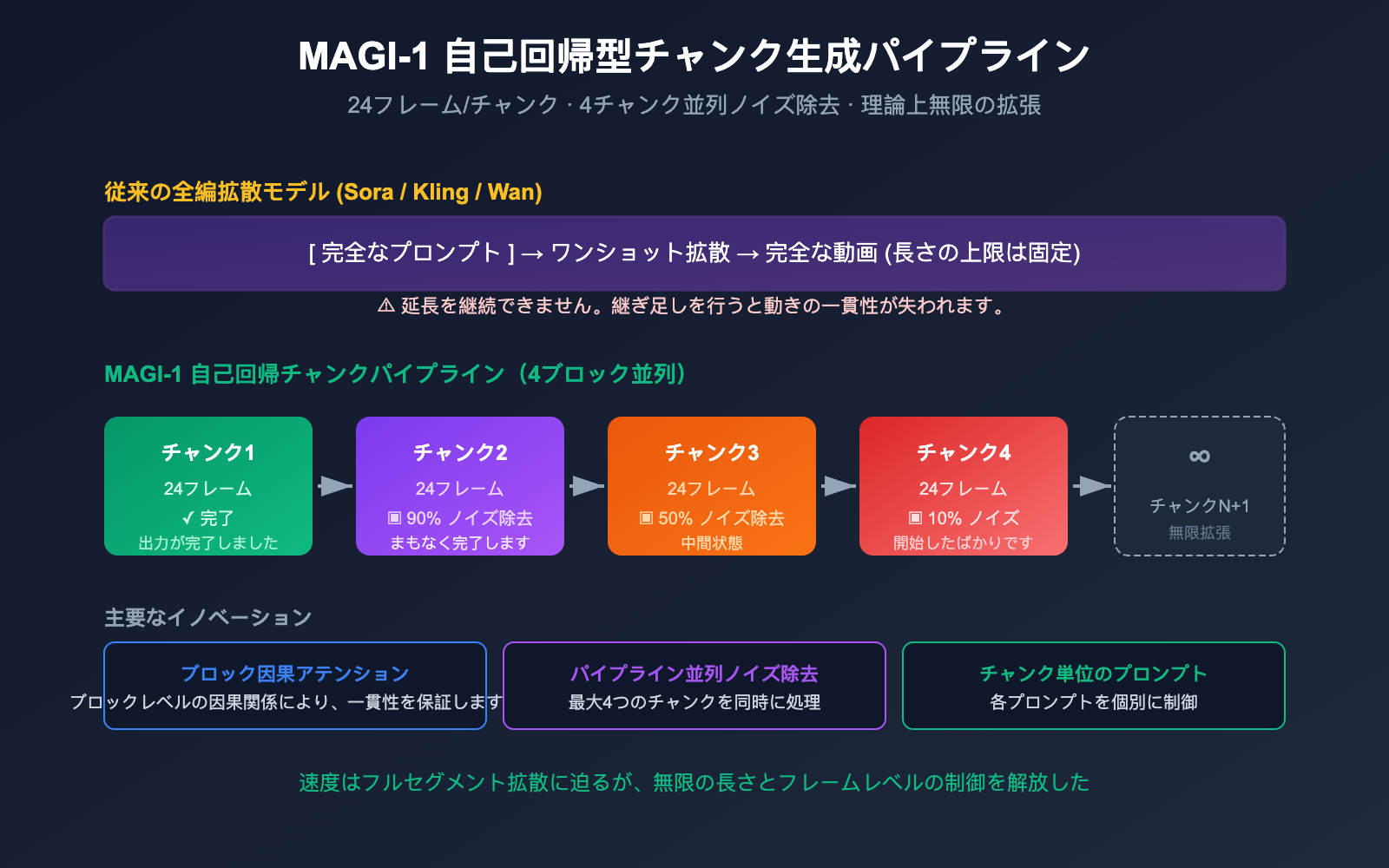
チャンク単位の自己回帰生成
Sora、Veo、Kling、Wan などの主要な動画生成モデルのほとんどは、**「動画全体を一括で拡散させる」**アプローチを採用しています。
[動画全体のプロンプト] → [一括拡散デノイズ] → [動画全体を出力]
この方式の問題点は、動画の長さの上限が固定されていることです。Sora 1.0 は一度に最大60秒、Kling は5〜10秒までであり、それ以上長くするには「動画の結合」が必要になりますが、結合すると動きの一貫性が失われがちです。
一方で Magi-1 は、自己回帰 + チャンク単位の拡散というハイブリッドな手法を採用しています。
プロンプト → 第1チャンク (24フレーム) 拡散デノイズ → 第2チャンク (24フレーム) → 第3チャンク → ... → ∞
各チャンク内部では拡散デノイズによって品質を担保しつつ、チャンク間は自己回帰によって、前のチャンクを基に次のチャンクを生成します。これにより、他のモデルでは実現困難な「無限の長さの動画生成」が可能になりました。
パイプライン並列処理:4つのチャンクを同時デノイズ
さらに賢いことに、Magi-1 は「第1チャンクが完全に終わるまで第2チャンクを待つ」必要はありません。そのパイプライン設計は、最大4つのチャンクを同時に処理することをサポートしています。現在のチャンクがある程度デノイズされると、次のチャンクの準備(プリヒート)を開始できるため、自己回帰生成であっても一括拡散と遜色ない生成速度を実現しています。
Diffusion Transformer + 多彩なイノベーション
Magi-1 は Diffusion Transformer (DiT) アーキテクチャをベースにしており、学習効率を最適化するための多くの工夫が盛り込まれています。
| 技術要素 | 役割 |
|---|---|
| Block-Causal Attention | チャンク単位の因果的アテンション。自己回帰の一貫性を保証 |
| Parallel Attention Block | 並列アテンションブロック。処理を高速化 |
| QK-Norm + GQA | 学習の安定化と推論の効率化 |
| Sandwich Normalization in FFN | 大規模言語モデルの学習安定化 |
| SwiGLU | 最新の活性化関数 |
| Softcap Modulation | アテンションスコアの爆発を抑制 |
この技術スタックは、Llama 3 や Mistral といった最先端の LLM で採用されている「現代の Transformer ツールキット」とほぼ一致しています。これが、Magi-1 が 4.5B/24B という「個人でも実行可能な」パラメータ規模で、トップクラスの動画品質を実現できている根本的な理由です。
2つのバージョン:4.5B / 24B
| バージョン | パラメータ数 | 適した用途 | ハードウェア要件 |
|---|---|---|---|
| MAGI-1 4.5B | 4.5 B | 個人開発者、ローカル実験 | シングルGPUで動作 (24GB+) |
| MAGI-1 24B | 24 B | 本番環境へのデプロイ、最高品質 | マルチGPU / H100 推奨 |
Sand AI は同時に2つのバージョンをオープンソース化しました。4.5B は「個人開発者でも楽しめる」ことを目的としており、24B は性能を追求するフラッグシップモデルとして位置づけられています。
Magi AI のコア能力
能力 1: 無制限の動画生成
これは Magi-1 の最もユニークな能力であり、他の主要な動画生成モデルにはない特徴です。公式ドキュメントには明確にこう記されています:「Magi-1 は、AI 動画生成において無限の動画延長機能を提供する唯一のモデルです。」
実用的な意味として、Magi-1 を使えば 5 分、10 分、さらには 1 時間といった連続した動画を生成できます。従来の「つなぎ合わせ」手法よりも、動きやシーンの一貫性が格段に優れています。これは短編ドラマ、長尺広告、教育用動画などにとって大きなメリットです。
能力 2: 卓越した物理的理解
Physics-IQ ベンチマークにおいて、Magi-1 は 56.02% を記録し、同種のモデルを大きく引き離しました。Physics-IQ は「物理世界が今後どう動くか」を予測する能力を測定するもので、ボールがどこへ転がるか、水がどう流れるか、服がどう揺れるかといった挙動を評価します。
物理的理解が向上することで、画面上の「AI 特有の違和感」が減り、より現実世界の動きに近い映像が実現します。
能力 3: フレーム単位の精密制御 (チャンク単位のプロンプト)
チャンク単位(塊ごと)での生成を行うため、Magi-1 は 24 フレームの各チャンクに対して個別にプロンプトを指定できます。
チャンク 1: "猫が芝生の上を走っている"
チャンク 2: "猫がジャンプし始める"
チャンク 3: "猫が蝶に気を取られ、立ち止まる"
チャンク 4: "猫が蝶を追いかけて空へ向かう"
このようなレベルの精細な制御は、従来の動画全体を一度に拡散させるモデルではほぼ不可能です。これにより、「長尺動画の絵コンテ」作成という作業負荷が、実用レベルまで大幅に軽減されます。
能力 4: 強力な画像から動画生成 (I2V)
Magi-1 は、画像から動画生成(Image-to-Video)タスクで特に優れたパフォーマンスを発揮します。静止画 1 枚とテキストによる説明文を与えるだけで、画像と高度に一致した、自然な動きの動画を生成できます。これは純粋なテキストから動画生成(T2V)よりも制御しやすく、実際の制作現場により適しています。
能力 5: トップクラスのプロンプト忠実度
Sand AI が論文内で実施した指示追従(instruction following)のテスト結果によると、Magi-1 の指示に従う能力は Wan 2.1 や HunyuanVideo よりも明らかに優れており、クローズドソースの Hailuo i2v-01 と肩を並べるレベルです。つまり、あなたが書いたプロンプトは「自由解釈」されることなく、モデルによってしっかりと反映されることを意味します。
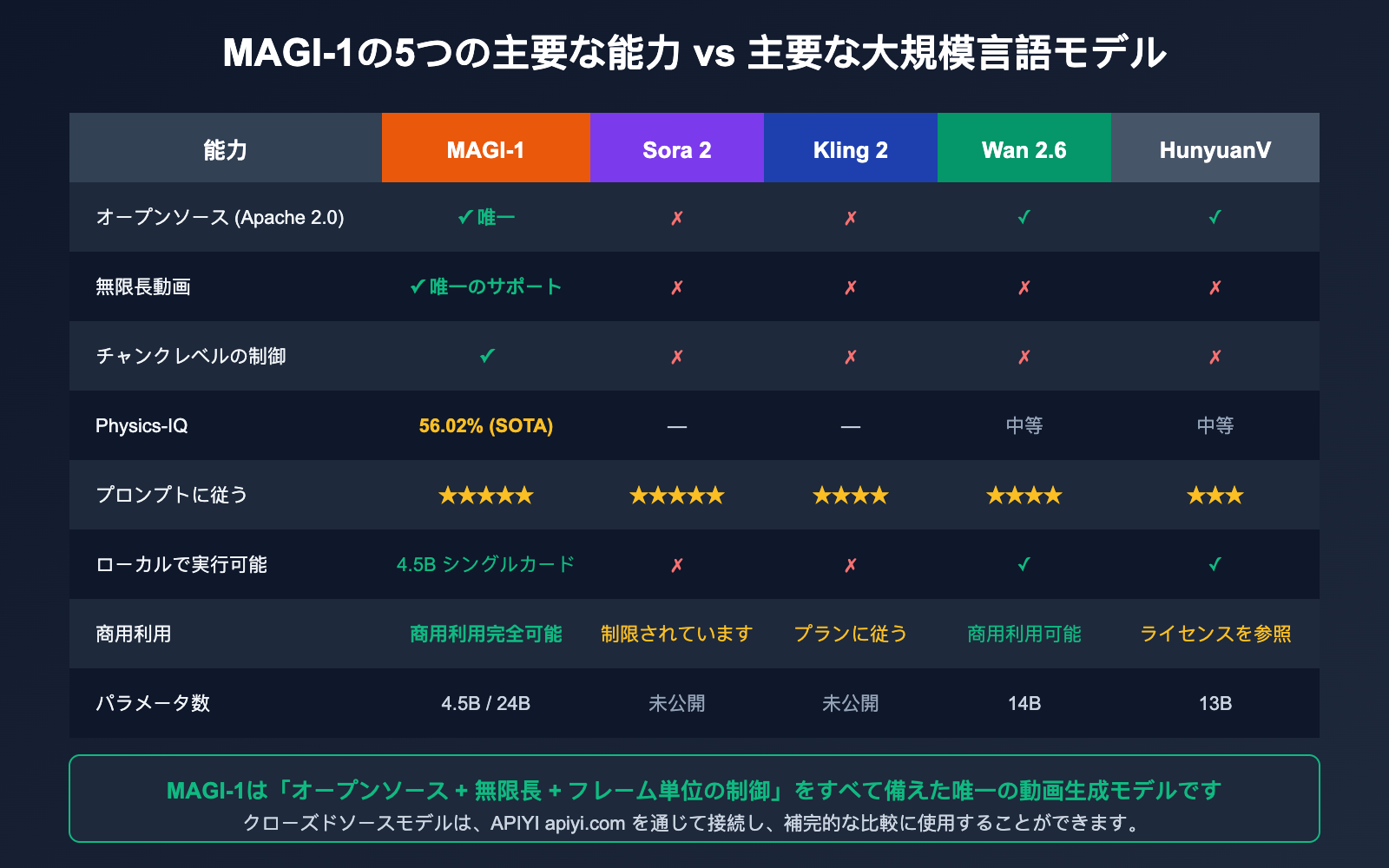
Magi AI と主要な動画生成モデルの比較
多くの新規ユーザーが最も気にされるのは、「Magi は Sora、Kling、Wan と比べてどうなのか?」という点です。以下に明確な比較表をまとめました。
| 比較項目 | MAGI-1 | Sora 2 | Kling 2 | Wan 2.6 | HunyuanVideo |
|---|---|---|---|---|---|
| オープンソース | ✅ Apache 2.0 | ❌ | ❌ | ✅ | ✅ |
| アーキテクチャ | 自己回帰 + Diffusion | Diffusion | Diffusion | Diffusion | Diffusion |
| 無限長生成 | ✅ 唯一対応 | ❌ | ❌ | ❌ | ❌ |
| チャンク単位制御 | ✅ | ❌ | ❌ | ❌ | ❌ |
| パラメータ数 | 4.5B / 24B | 非公開 | 非公開 | 14B | 13B |
| Physics-IQ | 56.02% | — | — | 中程度 | 中程度 |
| プロンプト追従性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| ローカル実行 | ✅ 4.5B 単一GPU | ❌ | ❌ | ✅ | ✅ |
| 商用利用 | ✅ Apache 2.0 | ⚠ 商用制限あり | ⚠ プランによる | ✅ | ⚠ ライセンス確認 |
🎯 結論: 「最高画質 + 一発撮りの短尺動画」を求めるなら、Sora 2 や Kling 2 が依然として第一選択肢です。「オープンソース + 長尺動画 + フレーム単位の制御」を求めるなら、Magi AI が現時点で唯一の回答となります。「ローカル実行とAPI呼び出しの両方で比較したい」場合は、MAGI-1 4.5B をローカル環境に導入し、APIYI (apiyi.com) を通じて Veo や Sora などのクローズドなモデルを同時に呼び出し、最も包括的な比較テストを行うことをお勧めします。
Magi AI クイックスタート

方法 1: Web オンライン試用 (最速)
最も簡単な方法は、公式 Web アプリに直接アクセスすることです:
- URL:
magi.sand.ai/app/projects - アカウント登録ですぐに使用可能
- 環境構築は一切不要、ブラウザだけで実行可能
「まずは効果を確認したい」というユーザーに最適です。
方法 2: GitHub ソースコードによるローカルデプロイ
研究目的や長期的なローカル利用を検討されている場合は、GitHub からソースコードをクローンしてください:
# リポジトリのクローン
git clone https://github.com/SandAI-org/MAGI-1.git
cd MAGI-1
# 依存関係のインストール
pip install -r requirements.txt
# 4.5B 重みデータのダウンロード (約 9GB)
huggingface-cli download sand-ai/MAGI-1 --local-dir ./ckpt/
# 最小構成での実行テスト
python inference.py \
--model_path ./ckpt/4.5B_base \
--prompt "A cat walking on the snow, cinematic lighting" \
--output ./output/cat.mp4 \
--num_chunks 4
💡 アドバイス: 初めてローカルで実行する場合は、まず 4.5B モデル + 24GB VRAM の単一GPU (RTX 3090/4090 等) で試すことをお勧めします。24B バージョンは品質が高いですが、H100 などのマルチGPU環境が必要となり、コストが一段階上がります。
方法 3: Hugging Face から直接重みをダウンロード
huggingface-cli download sand-ai/MAGI-1 \
--include "ckpt/magi/4.5B_base/*" \
--local-dir ./
重みは標準的な safetensors 形式で保存されており、diffusers や transformers で直接読み込み可能です。
推奨ワークフロー: Magi ローカル環境 + 主要クローズド API の比較
開発者にとって最も実用的なワークフローは以下の通りです:
- MAGI-1 4.5B をローカルで実行: 無限長動画やフレーム単位の制御といった独自の能力を活用
- Veo / Sora / Kling を API 呼び出し: 最高品質の単一動画生成を追求
- 一元管理: APIYI (apiyi.com) を通じて海外のトップクラスのクローズド動画生成モデルを一括で利用し、アカウント管理、ネットワーク制限、決済の手間を解消
- 横断的比較: 同じプロンプトで両方の環境を実行し、現在のタスクに最適な出力を選択する
Magi AI はどのような人に向いているか
シーン 1: 長尺動画が必要なクリエイター
ショートドラマ、長尺広告、教育用動画、ドキュメンタリーなど —— こうしたシーンでは、「5秒ごとにカットをつなぐ」という従来の手法は限界を迎えています。Magi-1 の無限長生成は、現在唯一のすぐに使えるソリューションです。
シーン 2: 精密な絵コンテ制御が必要な監督
「チャンク単位のプロンプト(chunk-wise prompting)」により、絵コンテを書くように各シーンを制御できます。これはショート動画クリエイター、アニメの絵コンテ担当者、広告監督にとって非常に有用です。
シーン 3: 動画生成の研究者 / オープンソース貢献者
Apache 2.0 ライセンス、完全な重みデータ、論文、GitHub リポジトリが公開されている Magi は、現在「自己回帰型動画生成」を研究する上で最高のオープンソース実装例です。この分野の研究をしているなら、Magi-1 は必読かつ必携のプロジェクトと言えるでしょう。
シーン 4: ローカル環境でデプロイしたい中小チーム
Sora や Kling といったクローズドなモデルは API 経由でしか利用できず、データを完全に自社で制御することはできません。Magi-1 は Apache 2.0 ライセンスで重みもダウンロード可能なため、自社のプライベートクラウドに完全にデプロイ可能です。データ保護が重要な業界(医療、金融、教育)にとって非常に親和性が高いモデルです。
Magi AI よくある質問
Q1: Magi AI は無料ですか?商用利用は可能ですか?
完全に無料であり、Apache 2.0 ライセンスの下で商用利用も可能です。これは Sora や Kling などのクローズドなモデルに対する Magi の最大の強みの一つです。必要なのはハードウェアや GPU の計算コストのみで、API 呼び出し料金や月額費用、商用利用の制限はありません。
Q2: Magi-1 と Wan 2.6、HunyuanVideo はどれが良いですか?
Sand AI の論文の比較データによると、Magi-1 は Physics-IQ(物理理解)、プロンプトの忠実度、モーション品質の3項目で Wan 2.1 や HunyuanVideo を上回っています。ただし、Wan 2.6 はより新しいバージョンであり、コミュニティのエコシステムやツールチェーンがより成熟しています。現実的なアドバイス: ショート動画や高画質が求められるシーンには Wan 2.6 を、長尺動画や精密な制御が必要なシーンには Magi-1 を選ぶのがおすすめです。両者は競合するものではなく、使い分けが可能です。
Q3: 「無限長動画」は本当に無限ですか?
理論上はそうです。Magi-1 の自己回帰的なチャンク生成メカニズム自体には長さの上限がないため、生成し続けることが可能です。実際上の制限は主にビデオメモリ(VRAM)と時間です。VRAM は現在の数チャンクの状態を保持するだけで済むためパンクすることはありませんが、時間は線形に増加します。つまり、5分間の動画は1分間の動画の約5倍の時間がかかります。
Q4: 4.5B バージョンと 24B バージョンの違いはどれくらいですか?
4.5B は「コンシューマー向けグラフィックボードで動作する最強の自己回帰型動画モデル」であり、その品質は初期の多くのクローズドモデルを凌駕していますが、Sora 2 や Kling 2 といった最高峰のフラッグシップモデルにはまだ差があります。24B こそが「ランキング上位を狙うためのバージョン」であり、品質面でトップクラスのクローズドモデルに肉薄しています。個人制作や研究目的であれば 4.5B で十分ですが、商用レベルの制作であれば 24B と H100 GPU 複数枚の環境を推奨します。
Q5: 今使っている Sora / Kling を Magi に置き換えるべきですか?
置き換える必要はなく、補完的に使用することをおすすめします。Sora や Kling は単一シーンの画質やカメラワークにおいて依然として優位性があります。一方、Magi は長さ、制御性、オープンソースとしての自主性に独自の強みがあります。最適な戦略は、APIYI (apiyi.com) を通じて海外のクローズドモデルで高品質な短編動画を作成し、Magi をローカルにデプロイして長尺動画や精密な制御を行うなど、シーンに応じて最適なツールを選択することです。
Q6: 中国の開発者はどのように Magi-1 の重みをダウンロードできますか?
Hugging Face (huggingface.co/sand-ai/MAGI-1) から直接ダウンロードできます。ネットワークの問題が発生した場合は、hf-mirror や modelscope のミラーサイトを利用してください。Sand AI は中国の AI スタートアップであり、中国の開発者に対して非常に友好的です。コミュニティには中国語のチュートリアルや議論が豊富に存在します。
まとめ
Magi AI は、2025年から2026年にかけてのオープンソース動画生成分野において、最も革新的なプロジェクトの一つです。このプロジェクトは、以下の3つの重要な意義を持っています。
- 自己回帰型動画生成の実現可能性を証明: Magi-1 は、世界で初めてトップレベルの性能に達した自己回帰型動画モデルです。「チャンク単位(chunk-by-chunk)+拡散モデル(Diffusion)」という手法が、「全編拡散(整段拡散)」以外のもう一つの有力な選択肢であることを証明しました。
- 無限の動画生成がSFから現実に: Sora、Kling、Veo といった既存モデルでも実現できなかった「無限の長さの動画生成」を、Magi は初めてオープンソースとして提供しました。
- オープンソース動画エコシステムのさらなる向上: Apache 2.0 ライセンス、完全なモデルウェイト、そして4.5B(45億パラメータ)のコンシューマー向けバージョンの提供により、「個人開発者でも最高峰の動画モデルを扱える」という環境が現実のものとなりました。
🚀 アクションアドバイス: 今すぐ Magi AI の能力を体験したい場合は、以下のステップが最短ルートです。まず
magi.sand.ai/app/projectsにアクセスしてアカウントを登録し、オンラインで試してみましょう。次に、結果に満足できたら GitHub の README に従って 4.5B バージョンをローカル環境にデプロイします。最後に、Magi(ローカル)と Veo / Sora / Kling(APIYI apiyi.com 経由で接続)の出力を比較し、自分だけの「モデルツールボックス」を構築してみてください。長尺動画の作成、緻密なコンテ制作、あるいは最高品質の単一カットの追求など、目的に応じて最適なツールを使い分けられるようになります。
著者: APIYI Team — 開発者向けに主要な大規模言語モデルへの安定したアクセスを提供しています。詳細は apiyi.com をご覧ください。
参考資料
-
MAGI-1 GitHub メインリポジトリ
- リンク:
github.com/SandAI-org/MAGI-1 - 説明: ソースコード、ウェイトダウンロードスクリプト、推論サンプル
- リンク:
-
MAGI-1 Hugging Face モデルカード
- リンク:
huggingface.co/sand-ai/MAGI-1 - 説明: 4.5B / 24B の2バージョン、ウェイトおよび説明
- リンク:
-
MAGI-1 公式論文 (PDF)
- リンク:
static.magi.world/static/files/MAGI_1.pdf - 説明: 技術的な詳細とベンチマーク結果
- リンク:
-
Sand AI 公式 Magi 紹介ページ
- リンク:
sand.ai/magi - 説明: プロジェクトホームページおよび製品紹介
- リンク:
-
MAGI-1 オンライン Web アプリ
- リンク:
magi.sand.ai/app/projects - 説明: ブラウザ上で直接試用可能
- リンク:
-
ComfyUI Wiki – MAGI-1 レポート
- リンク:
comfyui-wiki.com/en/news/2025-04-23-magi-1-autoregressive-video-generation-model-released - 説明: サードパーティによる詳細なレポートと比較分析
- リンク: