著者注:Kimi K2.5技術論文の核心的内容を深く読み解き、1TパラメータのMoEアーキテクチャ、384エキスパート構成、MLAアテンション機構を詳しく解説。さらに、ローカルデプロイのハードウェア要件とAPI連携プランの比較も提供します。
Kimi K2.5の技術的な詳細を知りたいですか?本記事は、Kimi K2.5公式技術論文に基づき、その1兆パラメータMoEアーキテクチャ、トレーニング方法、ベンチマークテストの結果を体系的に解説し、ローカルデプロイに必要なハードウェア要件についても詳しく説明します。
核心的な価値:この記事を読み終える頃には、Kimi K2.5の主要な技術パラメータ、アーキテクチャ設計の原理、そして自身のハードウェア条件に応じた最適なデプロイプランを選択する能力が身についているはずです。
Kimi K2.5 Paper 技術論文の核心ポイント
| 項目 | 技術的な詳細 | 革新的な価値 |
|---|---|---|
| 1兆パラメータ MoE | 総パラメータ 1T、有効パラメータ 32B | 推論時はわずか3.2%のみ有効化、極めて高い効率性 |
| 384エキスパートシステム | トークン毎に8エキスパート + 1共有エキスパートを選択 | DeepSeek-V3より50%多いエキスパート構成 |
| MLA アテンション | Multi-head Latent Attention | KVキャッシュを削減し、256Kコンテキストをサポート |
| MuonClip オプティマイザ | トークン効率の高い学習、Loss Spikeゼロ | 15.5Tトークンの学習で損失の急上昇なし |
| ネイティブ・マルチモーダル | MoonViT 400M 視覚エンコーダ | 15Tの視覚-テキスト混合学習 |
Kimi K2.5 Paper 論文の背景
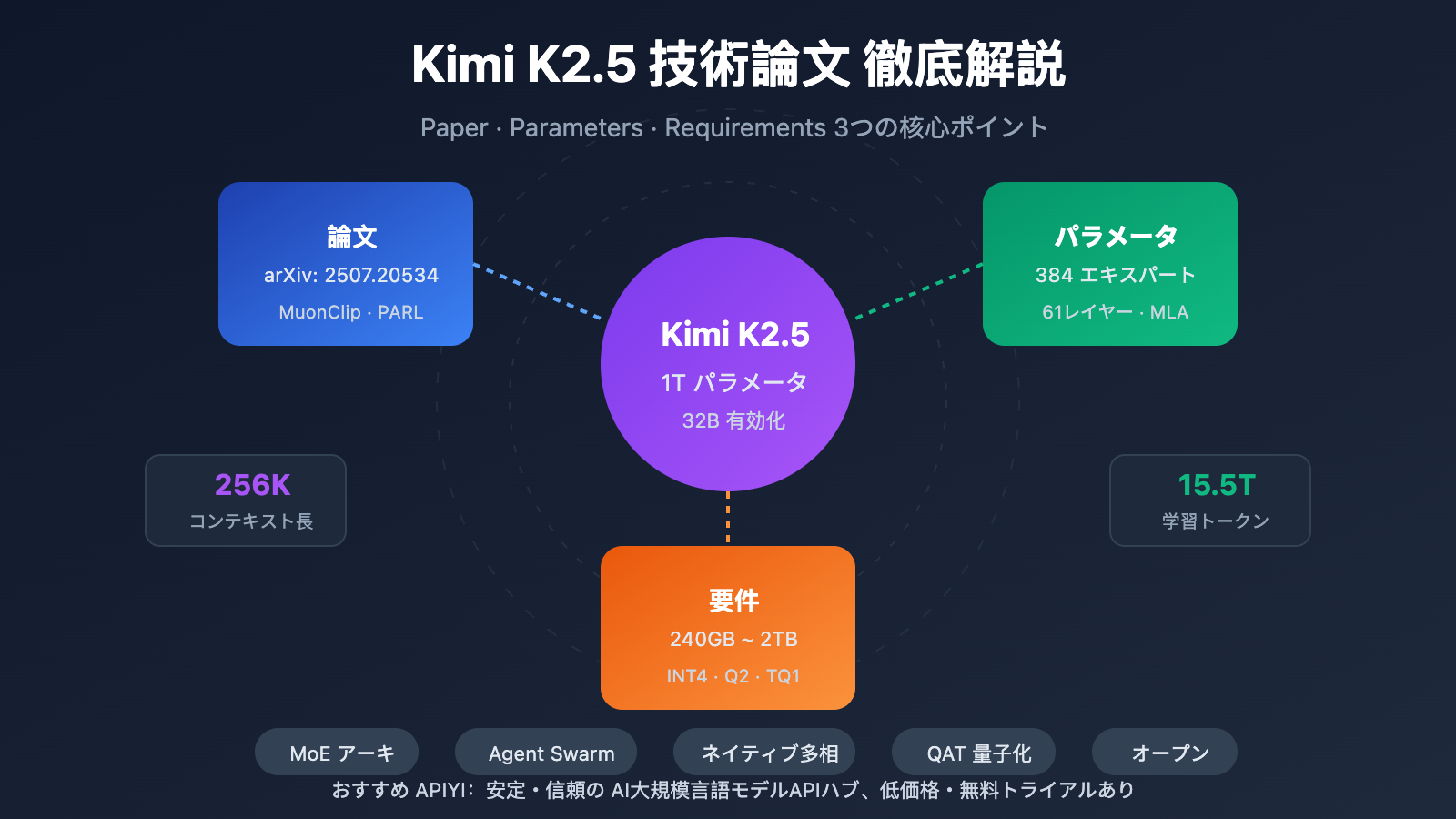
Kimi K2.5の技術論文は、月之暗面(Moonshot AI)チームによって発表され、arXiv番号は 2507.20534 です。この論文では、Kimi K2からK2.5への技術的な進化が詳細に述べられており、主な貢献は以下の通りです:
- 超疎なMoEアーキテクチャ:384エキスパート構成を採用し、DeepSeek-V3の256エキスパートより50%増加。
- MuonClip学習最適化:大規模学習におけるLoss Spike(損失の急上昇)問題を解決。
- Agent Swarmパラダイム:PARL (Parallel-Agent Reinforcement Learning) 学習手法の導入。
- ネイティブ・マルチモーダル融合:プリトレーニング段階から視覚・言語能力を統合。
論文では、高品質な人間によるデータがますます希少になる中、トークン効率が大規模言語モデルのスケーリングにおける鍵となっており、それがMuonオプティマイザや合成データ生成の活用を後押ししていると指摘しています。
Kimi K2.5 Parameters パラメータ構成の詳細
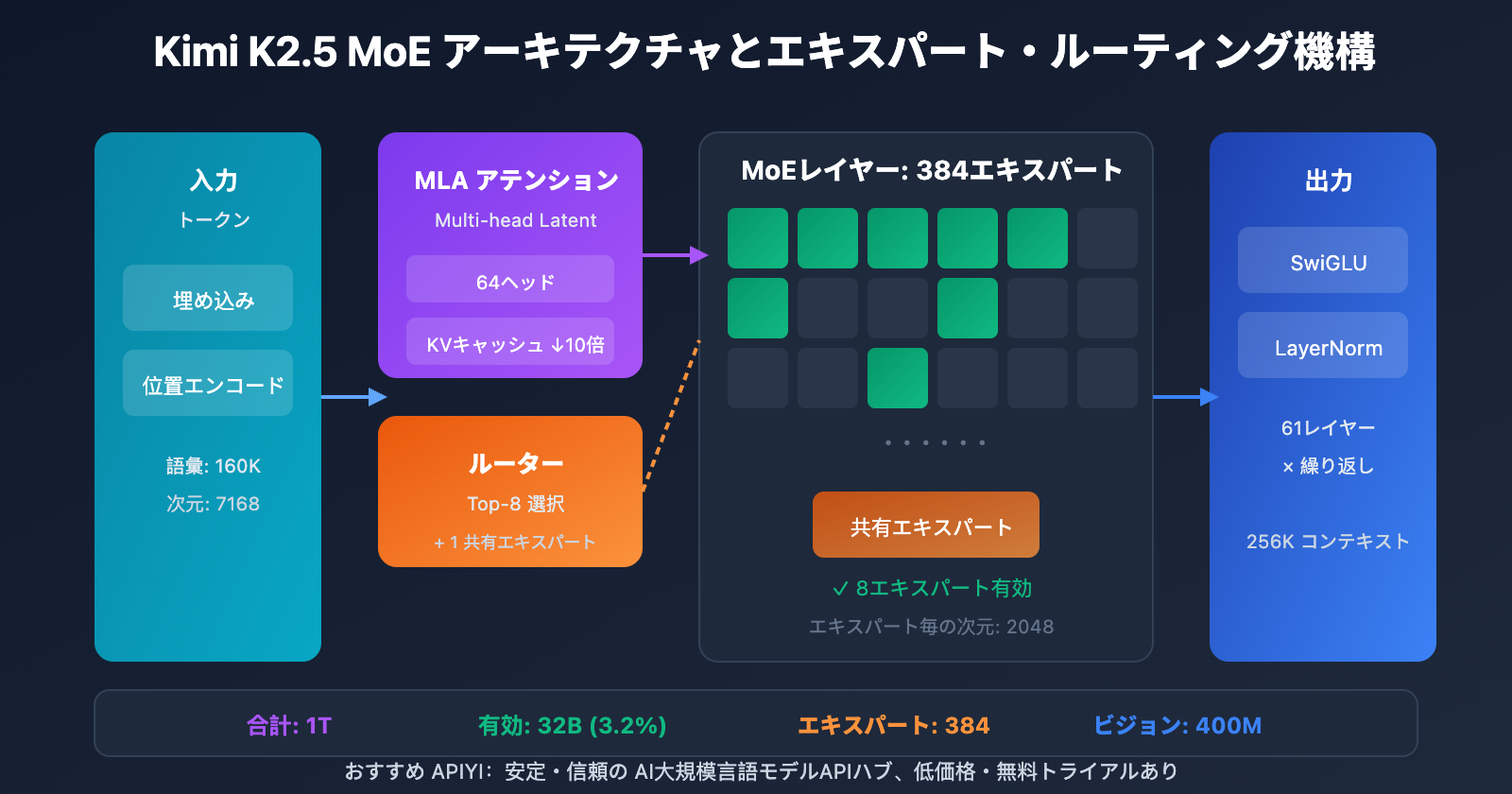
主要アーキテクチャパラメータ
| パラメータカテゴリ | パラメータ名 | 数値 | 説明 |
|---|---|---|---|
| 規模 | 総パラメータ数 | 1T (1兆400億) | モデル全体のサイズ |
| 規模 | アクティブパラメータ数 | 32B | 推論1回あたりの実際の使用量 |
| 構造 | レイヤー数 | 61 レイヤー | 1つのDenseレイヤーを含む |
| 構造 | 隠れ層の次元数 | 7168 | モデルバックボーンの次元 |
| MoE | エキスパート数 | 384 | DeepSeek-V3より128個多い |
| MoE | アクティブエキスパート | 8 + 1 共有 | Top-8 ルーティング選択 |
| MoE | エキスパート隠れ層の次元 | 2048 | 各エキスパートのFFN次元 |
| アテンション | アテンションヘッド数 | 64 | DeepSeek-V3の半分 |
| アテンション | メカニズムの種類 | MLA | Multi-head Latent Attention |
| その他 | ボキャブラリーサイズ | 160K | 多言語対応 |
| その他 | コンテキスト長 | 256K | 超長文ドキュメント処理 |
| その他 | 活性化関数 | SwiGLU | 効率的な非線形変換 |
Kimi K2.5 Parameters 設計の解説
なぜ384個のエキスパートを選択したのか?
論文内のスケーリング則(Scaling Law)の分析によると、スパース(疎)性を継続的に高めることで、顕著な性能向上が得られることが示されています。開発チームはエキスパート数をDeepSeek-V3の256から384に増やすことで、モデルの表現能力を向上させました。
なぜアテンションヘッドを減らしたのか?
推論時の計算コストを抑えるため、アテンションヘッド数は128から64に削減されました。MLAメカニズムと組み合わせることで、この設計はパフォーマンスを維持しつつ、KV Cacheのメモリ占有量を大幅に削減しています。
MLAアテンションメカニズムの利点:
従来の MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = レイヤー数, H = ヘッド数, D = 次元, B = バッチサイズ, C = 圧縮次元
MLAは潜在空間の圧縮を通じてKV Cacheを約10分の1に削減し、256Kという超長文コンテキストの処理を可能にしました。
ビジュアルエンコーダーのパラメータ
| コンポーネント | パラメータ | 数値 |
|---|---|---|
| 名称 | MoonViT | 自社開発ビジュアルエンコーダー |
| パラメータ数 | – | 400M |
| 特徴 | 時空間プーリング | ビデオ理解への対応 |
| 統合方式 | ネイティブ融合 | 事前学習フェーズでの統合 |
Kimi K2.5 Requirements 導入ハードウェア要件
ローカルデプロイのハードウェア要件
| 量子化精度 | ストレージ要件 | 最小ハードウェア | 推論速度 | 精度ロス |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | 最速 | なし |
| INT4 (QAT) | ~630GB | 8×A100 80GB | 高速 | ほぼなし |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | 標準的 | 軽微 |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | 低速 (1-2 t/s) | 顕著 |
Kimi K2.5 Requirements 詳細説明
エンタープライズ級デプロイ (推奨)
ハードウェア構成: 2× NVIDIA H100 80GB または 8× A100 80GB
ストレージ要件: 630GB以上 (INT4 量子化)
期待されるパフォーマンス: 50-100 tokens/s
適用シーン: 本番環境、高コンカレンシーサービス
極限圧縮デプロイ
ハードウェア構成: 1× RTX 4090 24GB + 256GB システムメモリ
ストレージ要件: 240GB (1.58-bit 量子化)
期待されるパフォーマンス: 1-2 tokens/s
適用シーン: 研究・テスト、機能検証
注意点: MoEレイヤーが完全にシステムメモリ(RAM)にオフロードされるため、速度は大幅に低下します。
なぜこれほどのメモリが必要なのか?
MoEアーキテクチャは、推論のたびに32Bのパラメータのみをアクティブにしますが、入力に基づいて適切なエキスパートへ動的にルーティングするために、1Tの全パラメータをメモリ上に保持する必要があります。これはMoEモデル固有の特性です。
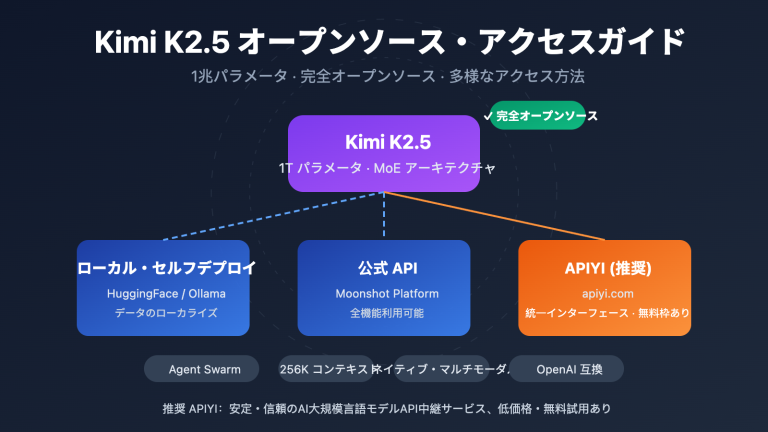
より実用的な選択肢:API 連携
多くの開発者にとって、Kimi K2.5をローカルでデプロイするためのハードウェアの壁は非常に高いです。API経由での利用が、より現実的で効率的な選択肢となります。
| プラン | コスト | メリット |
|---|---|---|
| APIYI (推奨) | $0.60/M 入力、$3/M 出力 | 統合インターフェース、複数モデルの切り替え、無料枠あり |
| 公式 API | 同上 | 全機能利用可能、最速アップデート |
| ローカル 1-bit | ハードウェアコスト + 電気代 | データの完全ローカル化 |
導入アドバイス:厳格なデータのローカル化が必要な場合を除き、高額なハードウェア投資を避けるため、APIYI (apiyi.com) を通じてKimi K2.5を利用することをお勧めします。
Kimi K2.5 論文 ベンチマーク結果
主要機能の評価
| ベンチマーク | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | 説明 |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | 数学競技 (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | 数学競技 (avg@32) |
| GPQA-Diamond | 87.6% | – | – | 科学的推論 (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | コード修正 |
| SWE-Bench Multi | 73.0% | – | – | 多言語コード |
| HLE-Full | 50.2% | – | – | 総合的な推論 (ツール使用) |
| BrowseComp | 60.2% | 54.9% | 24.1% | ウェブ操作 |
| MMMU-Pro | 78.5% | – | – | マルチモーダル理解 |
| MathVision | 84.2% | – | – | 視覚的数学 |
トレーニングデータと手法
| フェーズ | データ量 | 手法 |
|---|---|---|
| K2 Base 事前学習 | 15.5T トークン | MuonClip オプティマイザ、ロススパイク・ゼロ |
| K2.5 継続事前学習 | 15T 視覚・テキスト混合 | ネイティブ・マルチモーダル融合 |
| Agent トレーニング | – | PARL (並列エージェント強化学習) |
| 量子化トレーニング | – | QAT (量子化を考慮したトレーニング) |
論文では特に、MuonClip オプティマイザによって 15.5T トークンの事前学習プロセス全体で ロススパイク(Loss Spike)が全く発生しなかった ことが強調されています。これは、数兆パラメータ規模の大規模言語モデルのトレーニングにおいて重要な突破口となります。
Kimi K2.5 クイックアクセス例
最小限のコード例
APIYI プラットフォームを通じて、わずか 10 行のコードで Kimi K2.5 を呼び出すことができます:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # apiyi.com で取得
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "MoE アーキテクチャの動作原理を説明してください"}]
)
print(response.choices[0].message.content)
Thinking モードの呼び出しコードを表示
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking モード - 深い推論
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "あなたは Kimi です。問題を詳細に分析してください"},
{"role": "user", "content": "√2 が無理数であることを証明してください"}
],
temperature=1.0, # Thinking モード推奨
top_p=0.95,
max_tokens=8192
)
# 推論プロセスと最終回答の取得
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推論プロセス:\n{reasoning}\n")
print(f"最終回答:\n{answer}")
アドバイス:APIYI(apiyi.com)で無料テストクレジットを取得し、Kimi K2.5 の Thinking モードによる深い推論能力をぜひ体験してみてください。
よくある質問
Q1: Kimi K2.5の技術論文(Paper)はどこで入手できますか?
Kimi K2シリーズの公式技術論文はarXivで公開されており、論文番号は2507.20534です。arxiv.org/abs/2507.20534からアクセス可能です。Kimi K2.5の技術レポートは、公式ブログkimi.com/blog/kimi-k2-5.htmlで公開されています。
Q2: Kimi K2.5をローカルでデプロイするための最小要件(Requirements)は何ですか?
極限まで圧縮した構成では、VRAM 24GBのGPU 1枚 + システムメモリ 256GB + ストレージ容量 240GBが必要です。ただし、この構成での推論速度はわずか1〜2 tokens/sにとどまります。推奨構成はH100×2基またはA100×8基で、INT4量子化を使用することで商用レベルのパフォーマンスを実現できます。
Q3: Kimi K2.5の実力を素早く検証する方法は?
ローカルへのデプロイを行わなくても、APIを通じて迅速にテストが可能です:
- APIYI(apiyi.com)にアクセスしてアカウントを登録
- APIキーと無料クレジットを取得
- 本文のコード例を使用し、モデル名に
kimi-k2.5を指定 - Thinkingモードによる深い推論能力を体験
まとめ
Kimi K2.5技術論文の核心的なポイントは以下の通りです:
- Kimi K2.5 Paperの核心的な革新:384エキスパートのMoEアーキテクチャ + MLAアテンション + MuonClipオプティマイザにより、1兆パラメータ規模の損失のない安定したトレーニングを実現。
- Kimi K2.5 Parameters(主要パラメータ):総パラメータ数1T、アクティブパラメータ数32B、61層、256Kコンテキスト。推論ごとにアクティブになるのは全パラメータのわずか3.2%です。
- Kimi K2.5 Requirements(デプロイ要件):ローカルデプロイのハードルは非常に高く(最低240GB以上)、API経由での利用がより現実的で実用的な選択肢です。
Kimi K2.5はすでにAPIYI(apiyi.com)でリリースされています。まずはAPIを通じてモデルの能力を素早く検証し、ご自身のビジネスシーンに適しているか評価されることをお勧めします。
参考資料
⚠️ リンク形式の説明: すべての外部リンクは
資料名: domain.com形式を使用しています。コピーには便利ですが、SEO評価の流出を避けるためクリックによるジャンプはできないようになっています。
-
Kimi K2 arXiv 論文: アーキテクチャとトレーニング方法を詳述した公式技術レポート
- リンク:
arxiv.org/abs/2507.20534 - 説明: 技術的な詳細と実験データの全容を確認できます。
- リンク:
-
Kimi K2.5 技術ブログ: 公式に発表された K2.5 技術レポート
- リンク:
kimi.com/blog/kimi-k2-5.html - 説明: Agent Swarm とマルチモーダル機能について解説しています。
- リンク:
-
HuggingFace モデルカード: モデルの重みと使用説明
- リンク:
huggingface.co/moonshotai/Kimi-K2.5 - 説明: モデルの重みのダウンロードや、デプロイガイドの参照が可能です。
- リンク:
-
Unsloth ローカルデプロイガイド: 量子化デプロイの詳細チュートリアル
- リンク:
unsloth.ai/docs/models/kimi-k2.5 - 説明: さまざまな量子化精度におけるハードウェア要件を確認できます。
- リンク:
著者: 技術チーム
技術交流: コメント欄で Kimi K2.5 の技術的な詳細についてディスカッションしましょう。さらなるモデルの解説は APIYI apiyi.com 技術コミュニティをご覧ください。