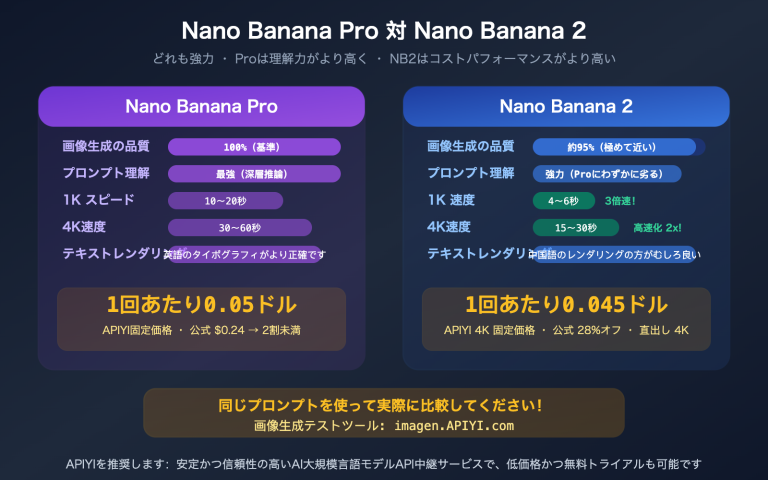
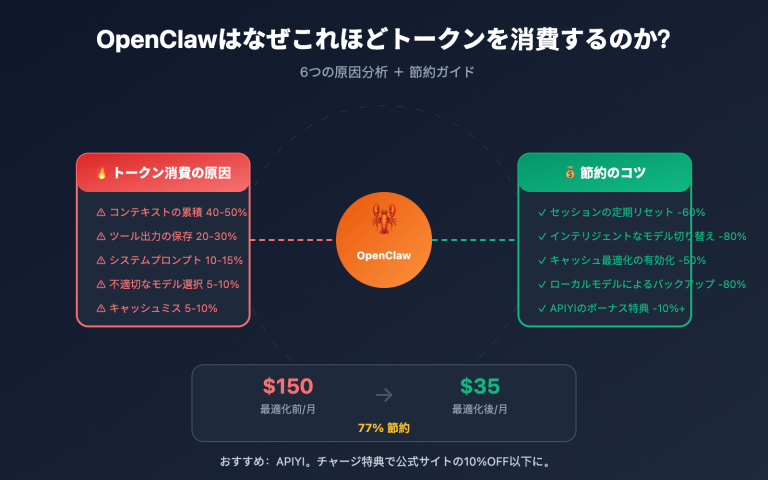
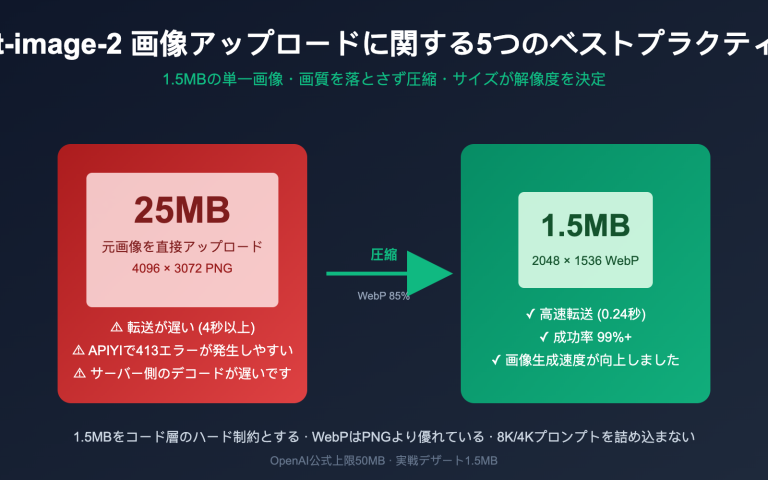
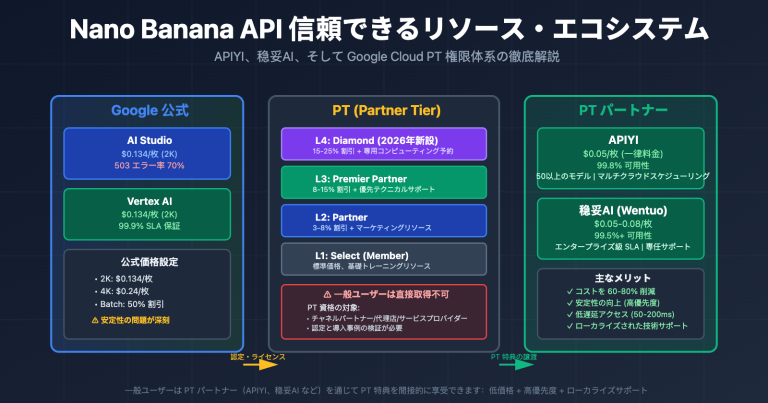
興味深い発見がありました。最近、多くの開発者が MiniMax が 2026 年 3 月にリリースした「M2.7」モデルを試用する中で、直感に反する問題に直面しています。「コードと Agent ワークフローの王者」と称されるこのフラッグシップモデルが、なんと画像入力をサポートしていないのです。Claude 4、GPT-5、Gemini 3 がマルチモーダル能力を標準装備している現在、230B パラメータを持つフラッグシップモデルが画像を認識できないというのは、確かに驚きです。本記事では、MiniMax 公式ドキュメント、NVIDIA NIM モデルカード、OpenRouter の公開仕様に基づき、APIYI (apiyi.com) での実際のデプロイ経験を交えながら、M2.7 が「純テキスト」に特化している背景にある製品ロジックを深く掘り下げます。
一、MiniMax M2.7 は画像入力をサポートしていないのか?
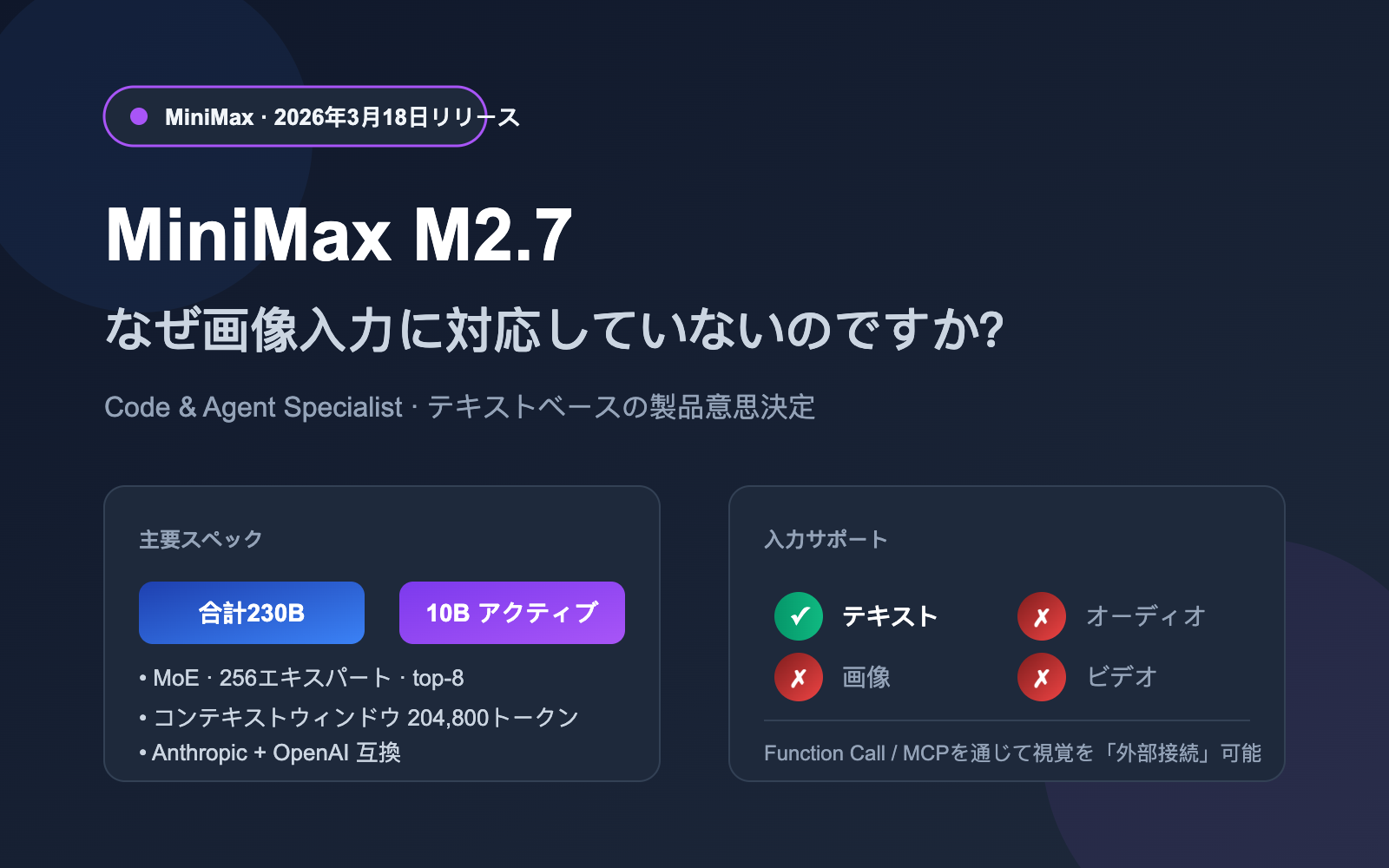
まず結論からお答えします。サポートしていません。 MiniMax 公式プラットフォームおよび NVIDIA NIM モデルカードの公開仕様によると、M2.7(M2.7-highspeed バージョンを含む)は現在テキスト入力のみをサポートしており、画像、音声、動画を直接処理することはできません。これは前世代の M2.5 の純テキストという位置付けと一致していますが、同時期にリリースされた Claude 4 Opus、GPT-5、Gemini 3 シリーズの「ネイティブ・マルチモーダル」という主流とは対照的です。
1.1 MiniMax M2.7 の主な仕様
M2.7 は 2026 年 3 月 18 日に API が正式公開されました。MoE(混合専門家)アーキテクチャを採用し、総パラメータ数は 230B、アクティブパラメータ数は 10B で、「高性能かつ低コスト」を売りにしています。
| 項目 | 内容 |
|---|---|
| リリース日 | 2026-03-18 |
| アーキテクチャ | MoE Transformer(256 専門家、1 トークンあたり 8 つをアクティブ化) |
| 総パラメータ数 / アクティブ数 | 230B / 10B |
| コンテキストウィンドウ | 204,800 トークン |
| 最大出力 | 131,072 トークン |
| 入力料金 | $0.279 / 100万トークン |
| 出力料金 | $1.20 / 100万トークン |
| マルチモーダル対応 | ❌ テキストのみ対応 |
| API 互換性 | Anthropic API + OpenAI API |
1.2 どのような場面で「落とし穴」にはまるか
スクリーンショットの質問回答、PDF スクリーンショットの解析、商品画像の理解、UI 自動化の視覚的検出、マルチモーダル RAG における画像検索などのシナリオで M2.7 を直接呼び出すと、エラーが発生するか、意味のない出力が返されます。ルーティング層(LiteLLM、One API、または APIYI (apiyi.com) のような統一 API 中継サービスなど)でモデルタイプを判定し、画像を含むリクエストは Claude、GPT-5、または Gemini 3 シリーズへルーティングすることをお勧めします。
二、なぜ MiniMax M2.7 は「純テキスト」路線を選んだのか
M2.7 が純テキストに特化しているのは、技術力が不足しているからではなく、非常に明確な製品戦略に基づいています。MiniMax は以前、マルチモーダル能力を備えた abab シリーズをリリースしており、M シリーズにビジュアルモジュールを追加する能力は十分にあります。しかし、彼らは M2.7 の学習リソースをすべて「コード + エージェント」という2つの領域に集中させ、これらの方向性で究極のパフォーマンスを引き出すことを選択しました。
2.1 コードとエージェントが M2.7 の主戦場
公式 README と NVIDIA の技術ブログによると、M2.7 は「複数ファイルの編集、コードの実行と修正のループ、テスト駆動型の修正、シェル/ブラウザ/検索/コード実行環境を跨ぐ長いチェーンのツール呼び出し」に特化して最適化されています。SWE-bench、Aider Polyglot、Terminal Bench といった実際のコーディングタスクにおいて、M2.7 のスコアは Claude 4 Sonnet に肉薄していますが、アクティブパラメータ数はわずか 10B であり、推論コストは後者の約 8 分の 1 に抑えられています。
2.2 純テキスト路線 vs マルチモーダル路線のトレードオフ
学習リソースを特定の方向に集中させることは、確実な利益と損失をもたらします。以下の表は、両路線の主要なトレードオフをまとめたものです。
| 項目 | 純テキスト路線(M2.7 / DeepSeek-R1) | マルチモーダル路線(Claude/GPT/Gemini) |
|---|---|---|
| 学習コスト | 集中型で効率が高い | 分散型でデータコストが高い |
| 1トークンあたりの価格 | 低い($0.28-2 / M) | 高い($3-15 / M) |
| テキスト/コード推論の深さ | 通常はより強力 | やや弱いが十分 |
| 画像/動画理解 | 非対応 | ネイティブ対応 |
| 適用範囲の広さ | フォーカス型 | より汎用的 |
| エンジニアリングの複雑さ | 低い | 低~中 |
2.3 ツール呼び出しによるマルチモーダル能力の「補完」
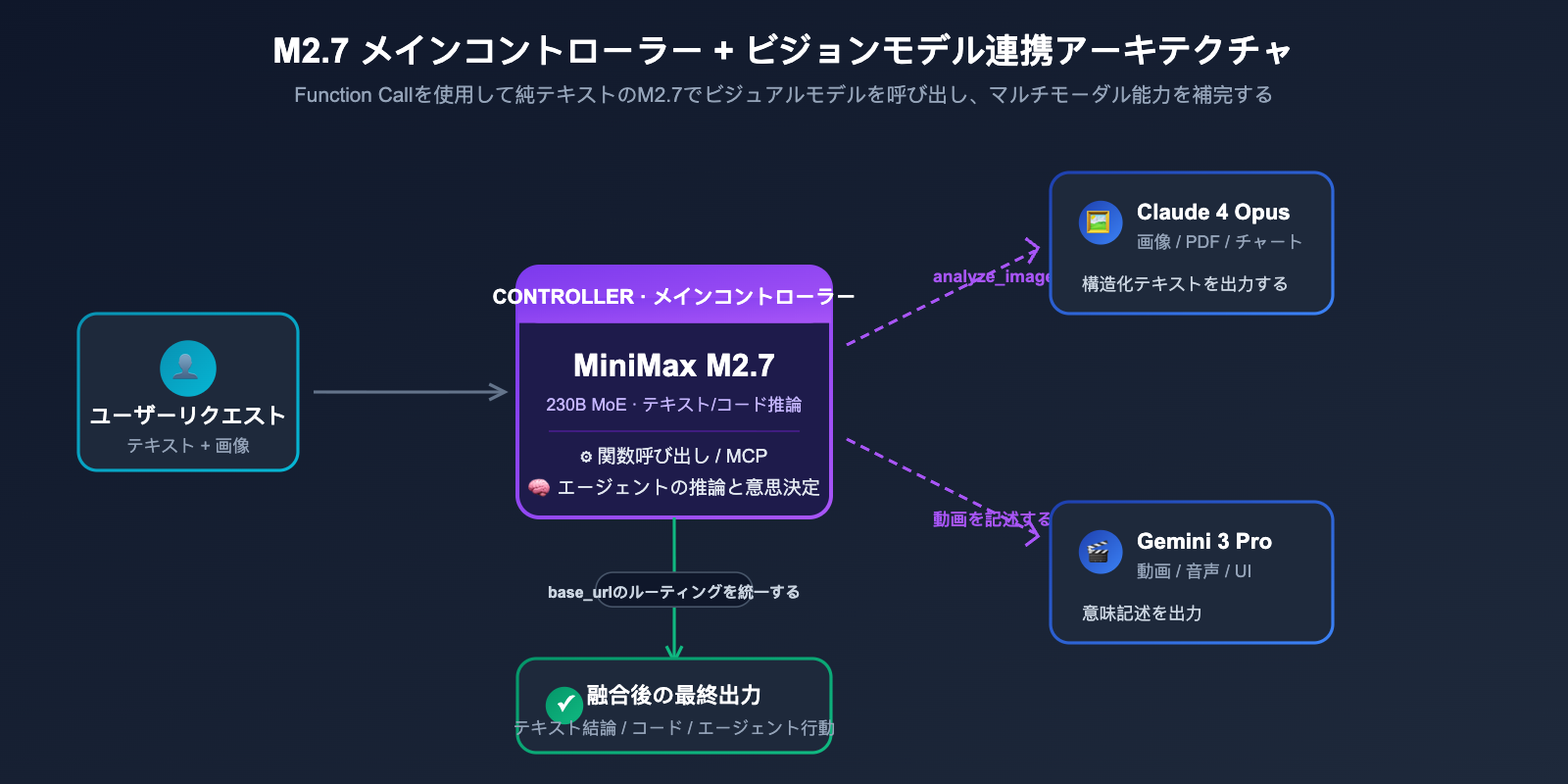
M2.7 自体は画像を認識できませんが、MCP(Model Context Protocol)と Function Calling をネイティブでサポートしています。つまり、開発者は M2.7 に画像理解タスクを専門の視覚モデル(Claude 4 Opus や Gemini 3 Vision など)へ「アウトソーシング」させ、自身はスケジューリングと最終的な推論のみを担当させることが可能です。このような「メインコントローラー + 視覚連携」というアーキテクチャは、エージェントシステムにおいて非常に一般的です。
三、2026 年、マルチモーダル API は本当に業界標準なのか
直感的には「マルチモーダル = 標準」という認識が 2026 年の業界の共通認識になっているように感じられます。しかし、主要なモデル陣営を深く観察すると、この判断には層ごとの理解が必要であることがわかります。
3.1 主要なクローズドソースのフラッグシップはほぼ全てマルチモーダル対応
Anthropic の Claude 4 シリーズ、OpenAI の GPT-5 シリーズ、Google の Gemini 3 Pro/Ultra は、いずれも画像を基本的な入力能力として備えています。Gemini 3 は ScreenSpot-Pro テストにおいて前世代の 11.4% から 72.7% へと飛躍的に向上し、スクリーンショットを直接「理解」して UI 操作を行うことが可能です。Claude 4 もグラフ認識や PDF 解析能力が強化されています。
3.2 オープンソース/コストパフォーマンス陣営で明確な分化
一方、オープンソース陣営では明確な分化が見られます。Llama 3.2 Vision、Qwen3-VL、InternVL といった「フルスタック・マルチモーダル」モデルと、DeepSeek-R1 や MiniMax M2.7 のような「テキスト/推論特化」モデルです。これら2つのモデルは単なる「優劣」ではなく、異なるアプリケーション形態に向けた差別化された選択肢と言えます。
3.3 主要モデルのマルチモーダル能力比較
以下の表は、2026 年 5 月時点での主要大規模言語モデルのマルチモーダル能力の違いをまとめたものです。M2.7 が陣営の中でどのような位置付けにあるかが一目でわかります。
| モデル | 画像入力 | 動画入力 | 音声入力 | 主なポジショニング |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | コード/エージェント推論 |
| Claude 4 Opus | ✅ | ❌ | ❌ | 汎用 + 長文 + コード |
| GPT-5 | ✅ | ✅ | ✅ | 汎用マルチモーダル |
| Gemini 3 Pro | ✅ | ✅ | ✅ | マルチモーダル + UI 理解 |
| DeepSeek-R1 | ❌ | ❌ | ❌ | 数理推論 |
| Qwen3-VL | ✅ | ✅ | ❌ | オープンソース・マルチモーダル |
ご覧の通り、「マルチモーダル標準化」は主にクローズドソースのフラッグシップ陣営に集中しています。オープンソースやコストパフォーマンスを重視する陣営において、テキスト特化は依然として有効な差別化戦略となっています。

四、ネイティブの視覚機能がない場合、MiniMax M2.7 で画像を処理する方法
M2.7 自体は画像を読み取ることができませんが、ツール呼び出しとルーティングを組み合わせることで、「M2.7 をメインコントローラーとし、視覚モデルと連携する」ハイブリッドアーキテクチャを構築できます。これにより、M2.7 の低コストというメリットを享受しつつ、マルチモーダルな体験を損なうことはありません。
4.1 推奨されるハイブリッド呼び出しアーキテクチャ
最も一般的な方法は、APIYI (apiyi.com) が提供するような統合ゲートウェイ(マルチモデルルーティング)を使用して、リクエストの内容に応じて振り分ける手法です。テキストやコードのリクエストは M2.7 に、画像リクエストは Claude 4 や Gemini 3 に送信し、視覚モデルが生成したテキストを M2.7 に戻して最終的な推論や意思決定を行わせます。このアーキテクチャはフロントエンドに対して透過的であり、ビジネス側の SDK 呼び出し方法を変更する必要はありません。
4.2 Function Calling での視覚モデルの統合
アプリケーションで Function Calling を使用している場合、M2.7 に analyze_image ツールを登録し、その内部で Claude/GPT/Gemini の視覚インターフェースを呼び出し、認識結果を JSON で返すように設定できます。M2.7 はユーザーのリクエストに応じて、いつこのツールを呼び出すべきかを自動的に判断するため、プロンプト層で明示的に判断させる必要はありません。このモデルは、LangGraph、CrewAI、OpenAI Agents SDK などのエージェントフレームワークに適しています。
🎯 導入のアドバイス: APIYI (apiyi.com) を経由して、1つの
base_urlで M2.7 とマルチモーダルモデル(Claude 4 Opus、Gemini 3 Pro など)を同時に利用することをお勧めします。ベンダーごとに SDK や API キーを個別に管理する必要がなくなり、ハイブリッドアーキテクチャのエンジニアリングの複雑さを大幅に軽減できます。また、トークン消費量やコストの統合管理も容易になります。
4.3 推奨される推論パラメータ
MiniMax は M2.7 に対して、比較的高めのサンプリングパラメータ(temperature=1.0、top_p=0.95、top_k=40)を推奨しています。これは多くのモデルで推奨される低い温度設定とは異なりますが、実際のコーディングやエージェントのシナリオでは、このパラメータ設定の方がより高品質で創造的なコード補完が可能です。もし以前のプロンプトテンプレートで temperature=0 をデフォルトにしていた場合、M2.7 では硬直的で繰り返しが多い出力になる可能性があるため、再調整が必要です。
5. MiniMax M2.7 対 マルチモーダルモデルの選定基準
M2.7 を選ぶべきか、それともマルチモーダル対応のフラッグシップモデルを選ぶべきか。その判断の核心は、単なるパラメータの大きさの比較ではなく、アプリケーションが「テキスト/コード主導」なのか「マルチモーダル主導」なのかという点にあります。
5.1 テキスト/コード主導のシナリオには M2.7 が最適
製品のリクエストの 90% 以上がテキスト関連(コード生成、ドキュメントの質問応答、エージェントのオーケストレーション、長文要約)である場合、M2.7 は現在最もコストパフォーマンスに優れた選択肢の一つです。230B の総パラメータがもたらす能力の上限は Claude 4 Sonnet に匹敵しますが、トークン単価は後者のわずか数分の一であり、高負荷な SaaS バックエンドにとって非常に魅力的です。
5.2 マルチモーダル高頻度シナリオには Claude / Gemini が最適
画像認識(OCR、UI 自動化、商品識別、医療画像診断支援)、動画解析、または音声処理が主要なシナリオである場合、Claude 4 Opus、GPT-5、または Gemini 3 Pro を直接選択する方が、「M2.7 + 視覚モデル」という混合アーキテクチャよりもシンプルで信頼性が高く、モデル間呼び出しによる遅延や失敗率を低減できます。
5.3 シナリオ別選定ガイド
| アプリケーションシナリオ | 推奨モデル | 代替案 |
|---|---|---|
| コード生成 / リファクタリング | MiniMax M2.7 | Claude 4 Sonnet |
| エージェントのツール呼び出し | MiniMax M2.7 | GPT-5 |
| 長文ドキュメントの質問応答(200K以内) | MiniMax M2.7 | Claude 4 Opus |
| 画像 OCR / スクリーンショット質問応答 | Gemini 3 Pro | Claude 4 Opus |
| 動画解析 | Gemini 3 Pro | GPT-5 |
| マルチモーダル RAG | Claude 4 Opus | Gemini 3 Pro |
| 混合タスク(テキスト主導 + 少量の画像) | M2.7 + 視覚モデルの組み合わせ | Claude 4 Opus 単体 |
🎯 選定のアドバイス: どのモデルを選ぶかは「どちらが優れているか」ではなく「どちらがあなたのリクエスト分布に適合しているか」という問題です。APIYI (apiyi.com) プラットフォームを活用し、実際のトラフィックで A/B テストを行い、同じタスクにおけるコストと品質を比較した上で、最終的な主力モデルの組み合わせを決定することをお勧めします。
6. MiniMax M2.7 に関するよくある質問(FAQ)
6.1 M2.7 は本当に画像を一切処理できないのですか?
はい。画像ファイル(base64 または URL)を直接 messages に含めても、インターフェース側で拒否されるかエラーが返されます。唯一の実行可能な方法は、まず他の視覚モデルを使用して画像をテキストによる説明に変換し、その説明を M2.7 に渡して推論を行うことです。
6.2 M2.7 と M2.7-highspeed の違いは何ですか?
どちらも出力結果は同じですが、応答速度が異なります。M2.7-highspeed は遅延に敏感なシナリオ(IDE のリアルタイム補完など)に適しており、M2.7 標準版は大量の非同期タスクに適しています。両バージョンは APIYI (apiyi.com) コンソールでモデル名を切り替えるだけで利用でき、インターフェースのパラメータは完全に互換性があります。
6.3 M2.7 はオープンソースモデルですか?ローカルデプロイは可能ですか?
可能です。M2.7 は重みが公開されているモデルであり、HuggingFace からダウンロードしてセルフホストできます。ただし、200K のコンテキストをフル活用するには少なくとも 8 基の A100 / H100 GPU が必要となり、ローカルデプロイのコストは API 呼び出しよりもはるかに高くなります。厳格なデータコンプライアンス要件がない限り、自前での構築は推奨されません。
6.4 M2.7 は Anthropic / OpenAI の公式 SDK と互換性がありますか?
完全に互換性があります。anthropic や openai の公式 SDK をそのまま使用し、base_url を API中継サービス(APIYI (apiyi.com) の統一アクセスエンドポイントなど)に向け、モデル名を切り替えるだけで利用可能です。ビジネスロジックを書き直す必要はありません。これは混合アーキテクチャを構築する上で最も手間のかからない方法です。
6.5 マルチモーダルのニーズが多いチームは M2.7 を検討すべきではないのでしょうか?
必ずしもそうではありません。マルチモーダルアプリケーションであっても、テキスト推論やオーケストレーションがリクエストの大半を占めることは珍しくありません。マルチモーダルな部分は Claude/Gemini に任せ、テキストのオーケストレーションや意思決定の部分を M2.7 に割り当てることで、全体の推論コストを大幅に削減できます。混合ソリューションのカスタマイズが必要な場合は、APIYI (apiyi.com) のビジネスチームまでお問い合わせいただければ、アーキテクチャの提案が可能です。
7. まとめ:マルチモーダルはトレンドだが、「特化型」も依然として有効な戦略
MiniMax M2.7 が画像入力をサポートしていないことは、事実であると同時に、意図的なプロダクト戦略でもあります。マルチモーダルがクローズドソースのフラッグシップモデルにおける標準装備となった2026年という現在、MiniMax はすべてのトレーニングリソースを「コード」と「エージェント」という、最も差別化が図れる2つの領域に集中させることを選択しました。その結果、Claude 4 Sonnet に迫るコーディング能力と、それを大幅に下回る推論コストを実現しています。
開発者にとって、これはモデル選定が「誰がより万能か」という単純な比較ではなく、「誰が自分のリクエスト分布に最適か」という判断に変わったことを意味します。テキストやコードが主導するシナリオでは、M2.7 は依然として現在最もコストパフォーマンスの高い選択肢の一つです。一方で、マルチモーダルの利用頻度が高いシナリオでは、Claude 4 Opus、GPT-5、Gemini 3 といった専門的なモデルに任せるべきでしょう。これらを統一されたゲートウェイを通じて組み合わせることで、コストとパフォーマンスの最適なバランスを手にすることができます。
同一の base_url で M2.7 と各社のマルチモーダル・フラッグシップモデルを統一して利用したい場合は、APIYI (apiyi.com) の公式ドキュメントから、モデルリストと接続例をご確認ください。
著者: APIYI Team — 世界中の AI 開発者に向けて、安定かつ効率的な API 中継サービスとマルチモデルルーティングサービスを提供しています。詳細は apiyi.com をご覧ください。