如果你最近做 AI 应用最痛苦的事情是什么? 大概率是这个场景: prompt 改了第 17 版, 跑了几个测试用例感觉变好了, 上线后被用户用一个你完全没想到的边缘 case 一击即溃。这就是 OpenAI 在 2025 年 10 月发布的 Cookbook 文章 "Building resilient prompts using an evaluation flywheel" 想要彻底解决的问题。
OpenAI 工程师 Neel Kapse 与社区著名 ML 教育者 Hamel Husain 在这篇文章里提出了 Evaluation Flywheel (评估飞轮) 这个核心概念, 用一套来自社会学定性研究的成熟方法论, 把 AI 应用开发从"prompt-and-pray (改完然后祈祷)"提升到"工程纪律"。本文将用最通俗的视角解读这个 OpenAI 评估飞轮 框架, 帮你判断怎么把它落地到自己的 AI 项目。
🎯 快速导览: cookbook 用一个真实的"公寓租赁助手 AI"作为示范案例, 完整展示了从失败分析到自动 grader 再到 CI 集成的全套工作流。文章中提到的 Evals API 和 Prompt Optimizer 工具属于 OpenAI 平台高级能力, 通过 API易 apiyi.com 这类 OpenAI 官转网关可以直接调用, 国内开发者照搬 cookbook 流程即可跑通。
公寓租赁助手案例: 一个被边缘场景打爆的真实 AI 应用
cookbook 里选取的案例非常贴近生活: 一个帮租客回答问题的 AI 助手, 包括公寓尺寸、看房预约、设施介绍等高频咨询。乍听是个普通的客服机器人, 真正放到生产环境后翻车的姿势却千奇百怪。
文章里枚举的失败案例非常有代表性, 每一个都让人感同身受:
| 失败类型 | 具体表现 | 后果 |
|---|---|---|
| 调度错误 | 推荐了不存在的看房时间段 | 租客白跑一趟, 投诉率飙升 |
| 状态紊乱 | 改约时没取消原预约 | 同一时段双重预约, 销售线索混乱 |
| 排版崩坏 | 设施列表全部挤成一坨文字 | 用户体验糟糕, 信息无法消费 |
| 链接失效 | 户型图链接 404 | 用户流失到竞品 |
| 数据漂移 | 回答的营业时间与真实数据不符 | 误导用户, 法律风险 |
如果你做过任何 AI 应用, 就知道这些都不是写 prompt 时刻意忽略的, 而是根本没意识到会发生。Fractional 团队在配套的 Receipt Inspection 案例里把这种现象总结得很到位: 单跑几个 happy path 永远抓不出生产环境的 long tail bug, 必须建立系统性的"失败收集 → 模式归纳 → 自动度量"闭环。
这个闭环, 就是评估飞轮要解决的核心问题。
OpenAI 评估飞轮的核心定义: 替代 prompt-and-pray 的工程纪律
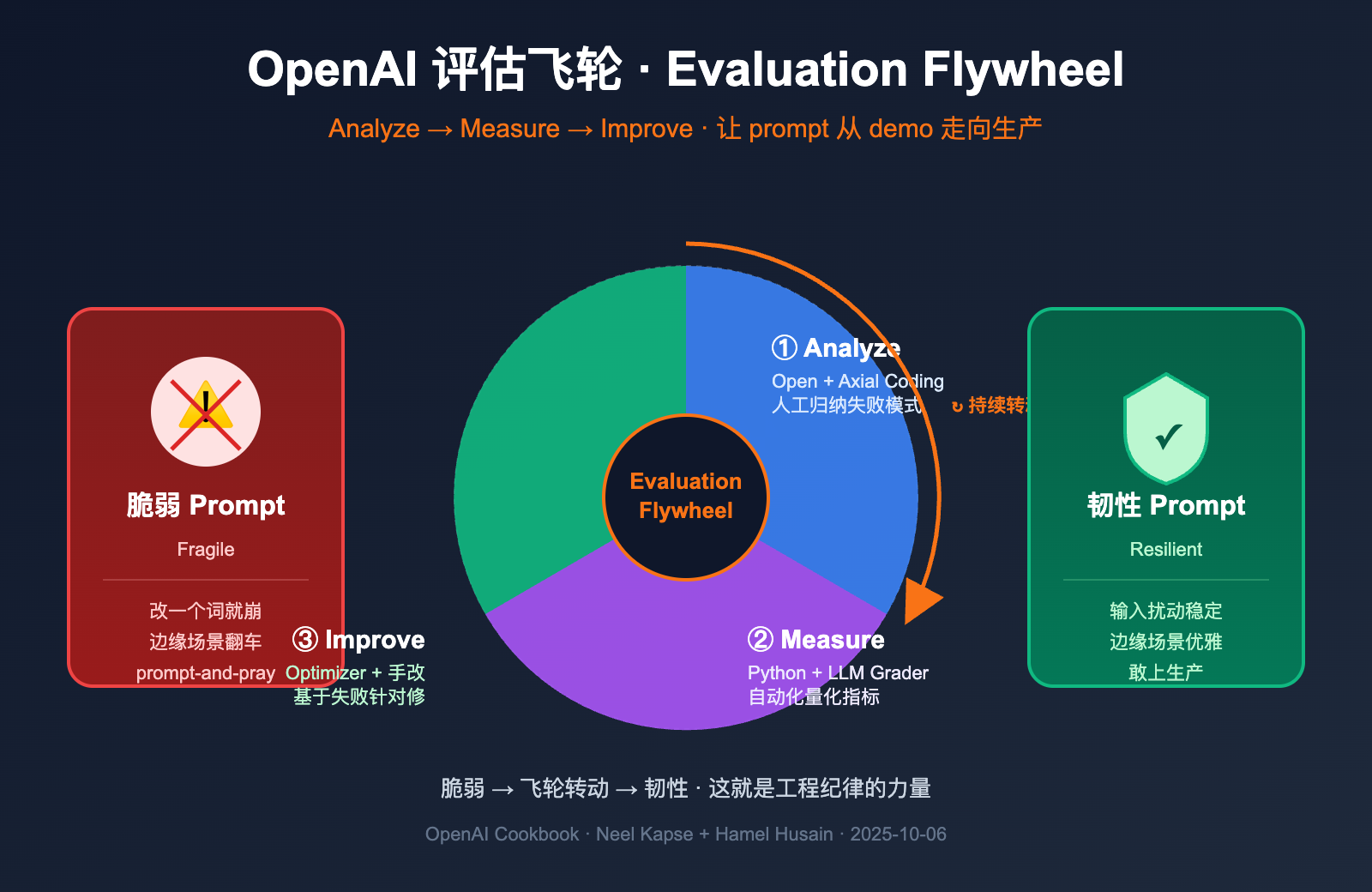
cookbook 给评估飞轮下的定义很简洁: 一个持续迭代的过程, 用结构化的工程纪律替代猜测。它由三个阶段组成, 像一个真正的轮子一样持续转动, 每转一圈系统就比上一圈更韧性一点。
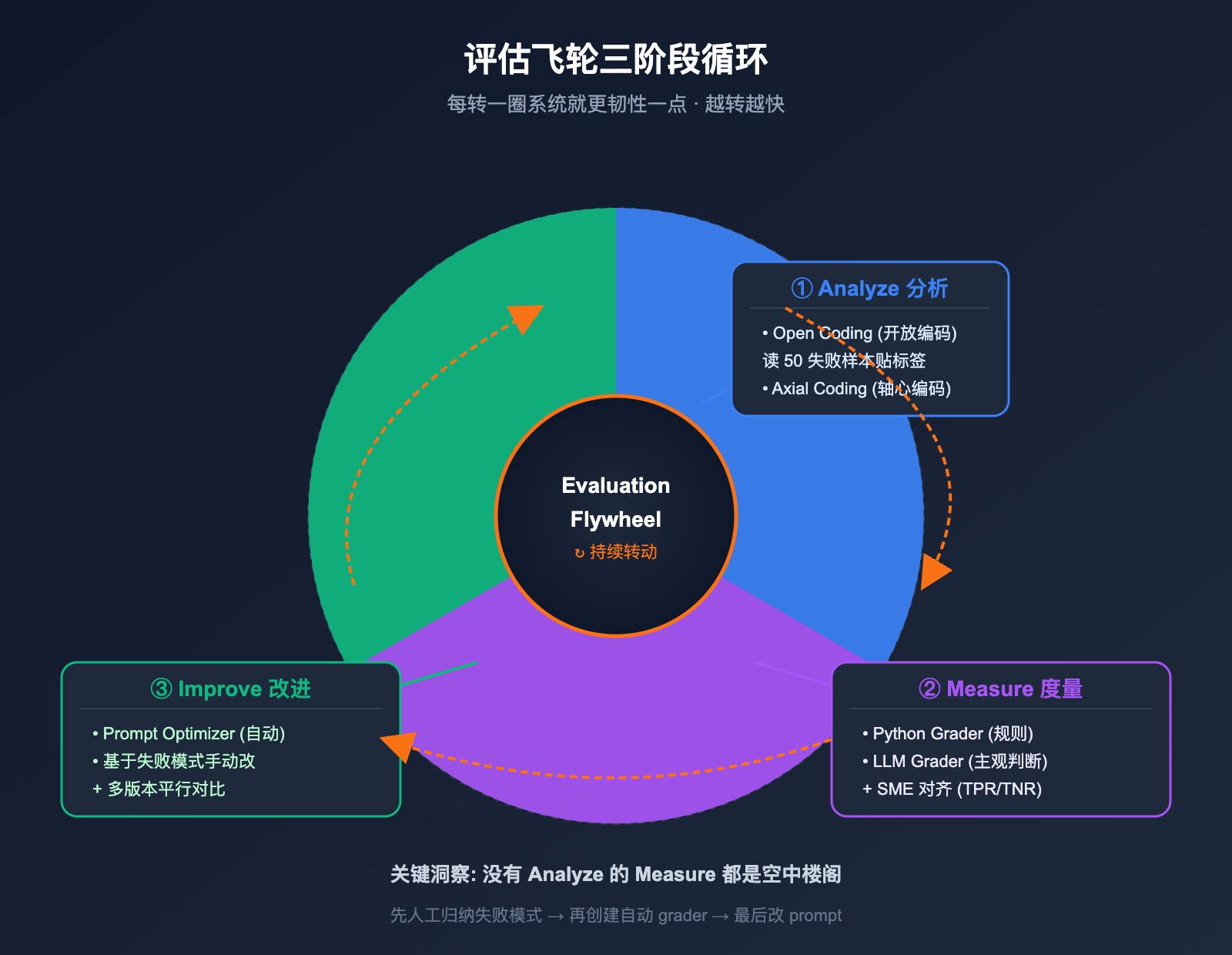
三个阶段的职责非常清晰, 各自解决一个特定问题:
| 阶段 | 核心问题 | 主要活动 | 输出物 |
|---|---|---|---|
| Analyze (分析) | "为什么会失败?" | 人工读失败样本, 归纳失败模式 | 失败分类清单 + 占比 |
| Measure (度量) | "失败有多严重?" | 创建 grader, 跑数据集 | 量化指标 + baseline |
| Improve (改进) | "如何修?" | 改 prompt, 重新跑评估 | 新版本 + 指标对比 |
很多团队跳过 Analyze 阶段直接搞自动评估, 这是评估飞轮失败的最常见原因。没有定性分析的自动度量都是空中楼阁, 因为你根本不知道自己在度量什么。这是这篇 cookbook 最核心的洞察, 也是它区别于普通 evals 教程的地方。
💡 类比理解: 评估飞轮像产品经理熟悉的 PDCA 循环, 但应用在 prompt 工程上有了具体的方法论支撑。Analyze 对应"找问题", Measure 对应"量问题", Improve 对应"修问题", 三步缺一不可。我们建议在 apiyi.com 调用 OpenAI Evals API 跑评估时, 先把 Analyze 阶段做扎实再启动度量。
OpenAI 评估飞轮阶段一: Analyze (分析) 的两步标注法
Analyze 阶段是评估飞轮最容易被忽视、却最关键的环节。cookbook 在这里搬出了一套非常专业的方法: Open Coding (开放编码) → Axial Coding (轴心编码), 这套方法源自社会学定性研究, 经过几十年验证, 是分析非结构化文本数据最成熟的范式之一。
第一步 Open Coding (开放编码) 的工作很朴素: 读 50 个失败样本, 不要预设任何分类, 直接给每个失败贴一个描述性标签。例如:
- "推荐了不存在的看房时间"
- "设施列表是一坨文字"
- "改约没取消原约"
- "回答了不是这套公寓的尺寸"
- "户型图链接打不开"
注意这一步故意不追求分类的整齐, 你只需要诚实地描述你看到了什么。Open Coding 像写读书笔记, 思路放飞、不必拘谨, 因为过早归类会让你失去对边缘模式的感知力。
第二步 Axial Coding (轴心编码) 才开始结构化, 你把第一步那些零散的标签合并成有意义的高层分类。cookbook 给出的示例分类是:
- 看房调度类问题 (合并: 错误时间、未取消、双重预约) → 占失败的 35%
- 格式错误类 (合并: 排版崩、链接失效) → 占失败的 10%
- 数据准确性类 (合并: 营业时间错、尺寸错) → 占失败的若干 %
Axial Coding 像整理章节目录, 让你能看清失败的"地形图"。35% 这个数字立刻告诉你应该优先修哪个类别, 因为它的 ROI 最高。
| 标注方法 | 目标 | 心态 | 输出 |
|---|---|---|---|
| Open Coding | 发现 (Discovery) | 放飞、不预设分类 | 50+ 个描述性标签 |
| Axial Coding | 结构化 (Structure) | 归纳、构建分类 | 5-8 个高层失败类别 |
🔧 实操建议: 国内开发者做 Analyze 阶段时, 可以把生产日志通过 OpenAI 官转 API (例如 apiyi.com) 直接接到 Evals API 平台的 Dataset 标注界面, 不用自己写后台。Open Coding 用 Feedback 类型标注列, Axial Coding 用 Label 类型标注列, 流程与 cookbook 完全一致。
OpenAI 评估飞轮阶段二: Measure (度量) 的两类 grader 选型
Analyze 阶段你已经知道"失败长什么样", Measure 阶段要把这些失败转化为自动检测代码。cookbook 在这里给出了两类 grader 的选型指南, 这是工程师最容易混淆的地方。
| Grader 类型 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| Python Grader | 确定性规则 (字符串、正则、API 校验) | 结果稳定、零幻觉、零额外成本 | 写不出来主观维度 |
| LLM Grader | 主观判断 (格式美观、语义对齐、推理质量) | 灵活、能评估难以编码的维度 | 需要 SME 对齐校验、有 token 成本 |
举公寓助手的例子, 两类 grader 各有用武之地:
- "推荐时间是否在真实可用时段内?" → Python Grader (查数据库或 API)
- "设施列表是否排版美观?" → LLM Grader (打 0-10 分)
- "户型图链接是否可访问?" → Python Grader (HEAD 请求)
- "回答语气是否符合品牌调性?" → LLM Grader (基于 rubric 打分)
cookbook 强调一个非常重要的工程实践: LLM Grader 必须做 SME (Subject Matter Expert, 领域专家) 对齐校验, 不能盲信 GPT-4o 的评分。具体方法是用 train/validation/test 数据拆分, 同时检查两个指标:
- High TPR (True Positive Rate, 真阳率): 抓得到真正的失败
- High TNR (True Negative Rate, 真阴率): 不误伤本来正确的样本
只看准确率会被高 baseline 蒙蔽, 必须双指标对齐。这一点是把 LLM-as-Judge 从"看起来 work"提升到"真的 work"的分水岭。
📊 校验流程: SME 标注一份 100 条样本作为 ground truth → LLM Grader 对同一份样本打分 → 计算 TPR / TNR → 调整 grader prompt 直到双指标都达标。这套流程在 apiyi.com 的 Evals 平台可以原生支持, 因为 Evals API 完全兼容 OpenAI 官方协议。
OpenAI 评估飞轮阶段三: Improve (改进) 的双轨实验
第三阶段你终于可以动手改 prompt 了。cookbook 给出了两条并行的改进路径, 这两条路径不是二选一, 而是配合使用。
路径一: Prompt Optimizer 自动优化
OpenAI 平台内置了 Prompt Optimizer 工具, 你给它一个失败样本集和原始 prompt, 它会自动尝试一系列改写策略 (加 few-shot、加 chain-of-thought、调整指令顺序等), 并在你的 grader 上评估改进效果。这条路径的好处是省事, 适合作为初步探索手段。
路径二: 基于失败模式手动改 prompt
针对 Analyze 阶段总结出的具体失败模式, 工程师手动针对性改 prompt。例如:
- 看房调度错误 → 在 prompt 里加入"检查可用时间表"的强制步骤
- 排版崩坏 → 用 XML 标签明确指定输出格式
- 改约未取消 → 加入"先取消再预约"的状态机说明
手动路径的优势是精准, 你知道每一处改动针对哪个失败模式, debug 时心里有数。
两条路径都跑完后, 你会有 N 个 prompt 候选版本。这时候 Improve 阶段最关键的一步来了: 用同一个 grader 集合在同一个数据集上跑所有版本, 选指标最优的那个。这一步不能跳, 因为人类对自己改的 prompt 有强烈的"自我感觉良好"偏见, 唯一能纠偏的就是数字。
跑完所有版本后, 飞轮转完一圈。你会发现新的失败模式 (因为系统变好了, 暴露出更深层次的边缘 case), 然后回到 Analyze 阶段开始下一圈。这就是"飞轮"这个词的精髓——它不会停, 越转越快, 越转越韧性。
韧性提示词 (Resilient Prompt) 与脆弱提示词的本质区别
文章标题里的 resilient prompt (韧性提示词) 是一个非常重要的概念, cookbook 给的定义是: 在所有可能的输入上都能给出高质量响应的 prompt。听起来简单, 实际是一个非常高的工程标准。

韧性和脆弱的差异主要体现在五个维度上:
| 对比维度 | 脆弱 Prompt | 韧性 Prompt |
|---|---|---|
| 输入鲁棒性 | 改一个词就崩 | 同义改写依然稳定 |
| 边缘场景 | 诡异输出甚至幻觉 | 优雅降级或转人工 |
| 可观测性 | 黑盒, 出错只能猜 | 有完整 grader 可定位 |
| 生产准入 | demo 表现≠生产表现 | 通过完整评估闭环 |
| 可演进性 | 改 A 改坏 B | 自动回归保护 |
工程师的直觉里 prompt 看起来"差不多就行", 但放到生产环境就会出现 0.1% 概率的问题——0.1% 看似很小, 在百万级调用下就是 1000 次事故。韧性提示词的工程价值不是把 80% 提升到 90%, 而是把 99% 提升到 99.9%。
🚀 接入提示: 想把 prompt 推到 99.9% 韧性, 必须把评估闭环自动化, 这就需要稳定调用 OpenAI Evals API 和 Prompt Optimizer 工具。我们建议通过 apiyi.com 这类 OpenAI 官转 API 平台调用, 接口与官方完全同步, 国内 IDC 节点也保证了长时间评估任务不掉线。
OpenAI 评估飞轮的 CI/CD 集成与生产监控
cookbook 在结尾强调的最后一步是: 把评估飞轮变成日常工程纪律。具体落地分两块:
第一块: CI/CD 集成
把 grader 套件接到 CI 流水线, 每次 prompt 变更都自动跑评估。如果指标退化超过阈值, PR 自动被阻塞合并。这一步把"评估"从研究行为变成日常开发行为, 是 prompt 真正走向工程化的标志。
| CI 阈值类型 | 推荐设置 | 说明 |
|---|---|---|
| 整体准确率 | 退化 ≤ 1% | 防止整体回归 |
| 关键 grader | 退化 ≤ 0.5% | 高优先级失败模式严控 |
| 新模式检出 | 警告而非阻塞 | 鼓励发现新问题 |
| 延迟 P95 | 增长 ≤ 10% | 控制成本和体验 |
第二块: 生产监控
CI 之外还要在生产环境持续采样, 发现 CI 集合里没有的"野生失败模式", 这些新模式会被加回评估集, 推动飞轮转下一圈。
具体做法是把生产日志按一定比例 (比如 1%) 采样, 跑同一套 grader, 发现指标异常时拉出来人工分析。新发现的失败模式经过 Open Coding → Axial Coding 处理后加入测试集, 飞轮再转。
这套循环让你的 prompt 系统永远在变得更韧性, 而不是部署后就停滞。这是 cookbook 留给所有 AI 工程师的核心工程纪律。
OpenAI 评估飞轮给国内开发者的 5 个实操启示
通读 cookbook 后, 我提炼出 5 个对中文开发者有直接指导意义的启示:
启示一: 从 Analyze 开始, 不要从 Measure 开始
很多团队上来就配 grader、刷指标, 跳过了人工分析。这导致 grader 度量的根本不是真正的失败模式, 数字漂亮但用户依然投诉。没有 50 条人工 Open Coding, 别启动自动评估。
启示二: Open Coding 阶段不要给 GPT 看
Open Coding 必须人类做, 因为 GPT 在归纳模式时会用既有训练数据的偏见污染你的标签。让 LLM 介入的最早时机是 Axial Coding 之后做 grader 实现, Analyze 的"发现"环节是人类独占的。
启示三: Python Grader 优先于 LLM Grader
只要能用确定性规则覆盖, 就别用 LLM Grader。原因有三: 稳定、便宜、不需要 SME 对齐。LLM Grader 留给真正主观、规则覆盖不了的维度。
启示四: 把指标绑定到业务影响
35% 调度问题、10% 格式问题——这些百分比要换算成"用户流失率"或"投诉率"才有决策价值。指标本身没有意义, 它对应的业务后果才有。
启示五: 把飞轮做成自动化, 而不是一次性项目
转一圈飞轮的 ROI 不一定特别高, 但长期复利非常可观。把 grader 写成 CI 任务、把生产采样写成定时任务、把新模式检出写成自动报警, 让飞轮 24 小时自己转。
OpenAI 评估飞轮国内复现的 Python 代码骨架
虽然 cookbook 主要演示的是 OpenAI Platform 的 UI 工作流, 但 Evals API 的程序化调用同样支持。下面这段 Python 代码骨架展示了如何调用 Evals API 创建 grader 并跑评估, 适合喜欢代码化工作流的国内开发者:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # 切换到 OpenAI 官转网关
api_key="你的 API易 Key"
)
# 1. 创建评估任务 (定义 grader 集合)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Python Grader 示例
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # LLM Grader 示例
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "Score 0-10 on output formatting clarity"
}
]
)
# 2. 跑评估 run
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. 拉取评估结果
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"通过率: {result.report_url}")
这段代码有三个关键点。第一个是 base_url 切换, 这一行决定了你能否在国内稳定跑长时间评估任务。第二个是 testing_criteria 数组, 你可以把所有 grader 配置成数组一次跑完。第三个是 Evals API 是异步的, 大数据集上跑评估可能需要几分钟到几十分钟, 程序里要做好等待和重试。
OpenAI 评估飞轮 FAQ
Q1: 评估飞轮和 LangSmith / Weights&Biases 那种评估平台有区别吗?
定位不同。LangSmith 主要解决"评估的工具化", 评估飞轮解决"评估的方法论"。前者告诉你怎么实现, 后者告诉你怎么思考。两者可以叠加使用, 用工具承载方法论。
Q2: 50 个失败样本够吗, 是不是太少?
Open Coding 阶段 50 个就够了, 因为目标是发现模式而非穷尽统计。Measure 阶段需要的样本数取决于失败率: 如果失败率 5%, 要 1000 条样本才能给出稳定的指标置信区间; 失败率 30% 则 200 条就够。
Q3: Prompt Optimizer 自动优化能不能完全替代手动改?
不能。自动工具擅长在已知 grader 上做局部优化, 但不擅长理解业务约束 (比如"客户要求每条响应不超过 80 字"这种隐式规则)。手动改 + 自动优化结合是最佳实践。
Q4: 国内调用 Evals API 稳定吗?
直连 OpenAI 在国内调用长时间任务 (评估通常要跑几分钟到几小时) 经常会遇到连接重置。我们建议通过 apiyi.com 这类 OpenAI 官转网关调用, 国内 IDC 节点对长连接做了专门优化, 评估任务中断率显著降低。
Q5: 评估飞轮适合什么规模的团队?
从 1 人项目到 100 人团队都适用, 区别只是飞轮转动的频率。1 人项目可能两周转一圈, 大团队可以做到天级别甚至小时级别的迭代。关键是建立纪律, 不是规模。
Q6: Hamel Husain 是谁, 为什么这篇 cookbook 这么受关注?
Hamel 是机器学习社区非常有影响力的教育者, 长期推动 LLM 应用的工程化最佳实践。这篇 cookbook 是 OpenAI 官方第一次系统性引入定性研究方法论 (Open Coding 等) 到 prompt 工程, 所以业界讨论非常多。
总结
OpenAI 评估飞轮 这套方法论的真正价值, 是给中文 AI 工程师社区补上了"prompt 工程怎么做才算专业"这道题的标准答案。它不是一个具体的工具, 而是一种工程纪律, 让 prompt 开发从"凭感觉的手艺活"变成"有迹可循的工程实践"。
把 Analyze → Measure → Improve 这三个阶段刻进开发流程, 你的 AI 应用就从"demo 看着挺像那么回事"升级成了"敢放上生产、敢承诺 SLA"的产物。这个升级背后, 是失败被系统性收集、模式被结构化归纳、改进被自动度量验证的完整闭环。
如果你正在做任何 prompt-driven 的 AI 应用, 强烈建议把这套飞轮搭起来。我们建议通过 apiyi.com 这类 OpenAI 官转 API 平台直接调用 Evals API 和 Prompt Optimizer, 一行 base_url 切换就能跑通整套 cookbook 流程, 不用费心解决国内网络稳定性的问题。
把"飞轮"刻进肌肉记忆, 你的 prompt 就从今天开始, 走在变韧性的路上。
📌 作者: APIYI Team — 长期跟踪 OpenAI / Anthropic / Google 多模态 API 的工程实践案例, 更多 cookbook 实战解读和 Evals API 接入指南见 apiyi.com 文档中心。