Nano Bananaで画像を生成する際、多くの開発者が頭を悩ませる問題に直面してきました。それは、画像は美しく描かれているのに、その上の文字がスペルミスをしていたり、ぼやけていたり、あるいは完全に文字化けしてしまったりするというものです。
しかし、良いニュースがあります。Googleの公式ドキュメントには、実は重要なヒントが示されています。まずモデルに文字コンテンツを生成させ、その後、その文字を含む画像を生成するよう要求するというものです。これが「二段階アプローチ」(Two-Step Approach)と呼ばれるもので、文字レンダリングの精度を大幅に向上させることができます。
本記事では、この現象の背後にある技術的な原因を深く分析し、そして、実証済みの効果的な文字レンダリングテクニックを6つご紹介します。これにより、Nano Bananaで生成される画像の文字を鮮明かつ正確にすることができます。
主な価値:この記事を読み終えることで、Nano Bananaの文字レンダリングの仕組みを理解し、二段階アプローチを含む6つの実用的なテクニックを習得し、画像文字の精度を「運任せ」から「制御可能なレベル」へと引き上げることができるでしょう。
Nano Banana のテキストレンダリングの現状:高い能力とテクニックの必要性
まず結論から申し上げます。Nano Banana シリーズモデルのテキストレンダリング能力は、AI画像生成分野において最高レベルにありますが、「適当なプロンプトで完璧な文字が出力される」というわけではありません。
Nano Banana のテキストレンダリング精度データ
| モデル | テキスト精度 | 多言語サポート | 最長信頼文字数 | 説明 |
|---|---|---|---|---|
| Nano Banana Pro | 約 94% | 優秀 | 約 25 文字 | 最高精度、商用レベルのポスターに最適 |
| Nano Banana 2 | 約 87% | 優秀 | 約 20 文字 | 高速、費用対効果が高い |
| DALL-E 3 | 約 78% | 良好 | 約 15 文字 | 長いテキストは間違いやすい |
| Stable Diffusion XL | 約 45% | やや劣る | 約 8 文字 | 基本的に信頼できない |
| Midjourney v6 | 約 65% | 普通 | 約 12 文字 | スタイルは良いがテキストは弱い |
ご覧の通り、Nano Banana Pro の 94% という精度は業界最高水準です。しかし、残りの 6% の失敗シナリオ(スペルミス、文字のぼやけ、文字の欠落)は、ビジネスシーンでは許容できません。
AI画像生成におけるテキストレンダリングがなぜこれほど難しいのか
「2段階アプローチ」が必要な理由を理解するために、AIによる画像生成におけるテキストの難しさをまず把握しましょう。
- ピクセルレベルの正確性要件: 画像内のテキストはピクセルレベルで正確でなければなりません。一画でも異なれば誤字となります。一方、AIが生成する他のコンテンツ(風景、人物)は、ある程度の曖昧さが許容されます。
- 文字の組み合わせの爆発: 英語の26文字、日本語の数千の漢字に加え、大文字小文字、フォント、配置の組み合わせを考えると、その可能性はほぼ無限です。
- コンテキストの干渉: モデルが画像全体の構図を生成する際、「気が散りやすい」傾向があります。背景をうまく描き、同時にテキストを配置するという2つのタスクが互いに注意を奪い合います。
- トレーニングデータの偏り: トレーニングセットに含まれる完璧なテキストを含む画像の割合は限られており、モデルが特定のフォントやレイアウトの組み合わせを十分に学習できていないことがあります。
🎯 技術的アドバイス: テキストレンダリングの難しさを理解することで、プロンプトを効果的に最適化できます。APIYI (apiyi.com) プラットフォームを通じて Nano Banana Pro と Nano Banana 2 を呼び出すことで、両モデルのテキストレンダリング効果を素早く比較し、あなたのシナリオに最適なソリューションを選択できます。
核心テクニック1:2段階アプローチ——公式推奨のテキストレンダリングのベストプラクティス
これは Google の公式ドキュメントで明確に推奨されている方法であり、この記事で最も重要なテクニックです。
2段階アプローチの原理
従来の1段階アプローチ(効果が低い):
「『SUMMER SALE 50% OFF』と書かれたポスターを生成してください」
→ モデルが構図とテキストを同時に処理 → テキストが間違いやすい
2段階アプローチ(効果が高い):
ステップ1: 「ポスターのコピーを作成してください:夏のセール50%割引」
→ モデルがテキストを出力: 「SUMMER SALE 50% OFF」
ステップ2: 「『SUMMER SALE 50% OFF』というテキストを正確に表示するポスター画像を生成してください」
→ モデルは確定したテキストを画像にレンダリングすることに集中 → 精度が大幅に向上
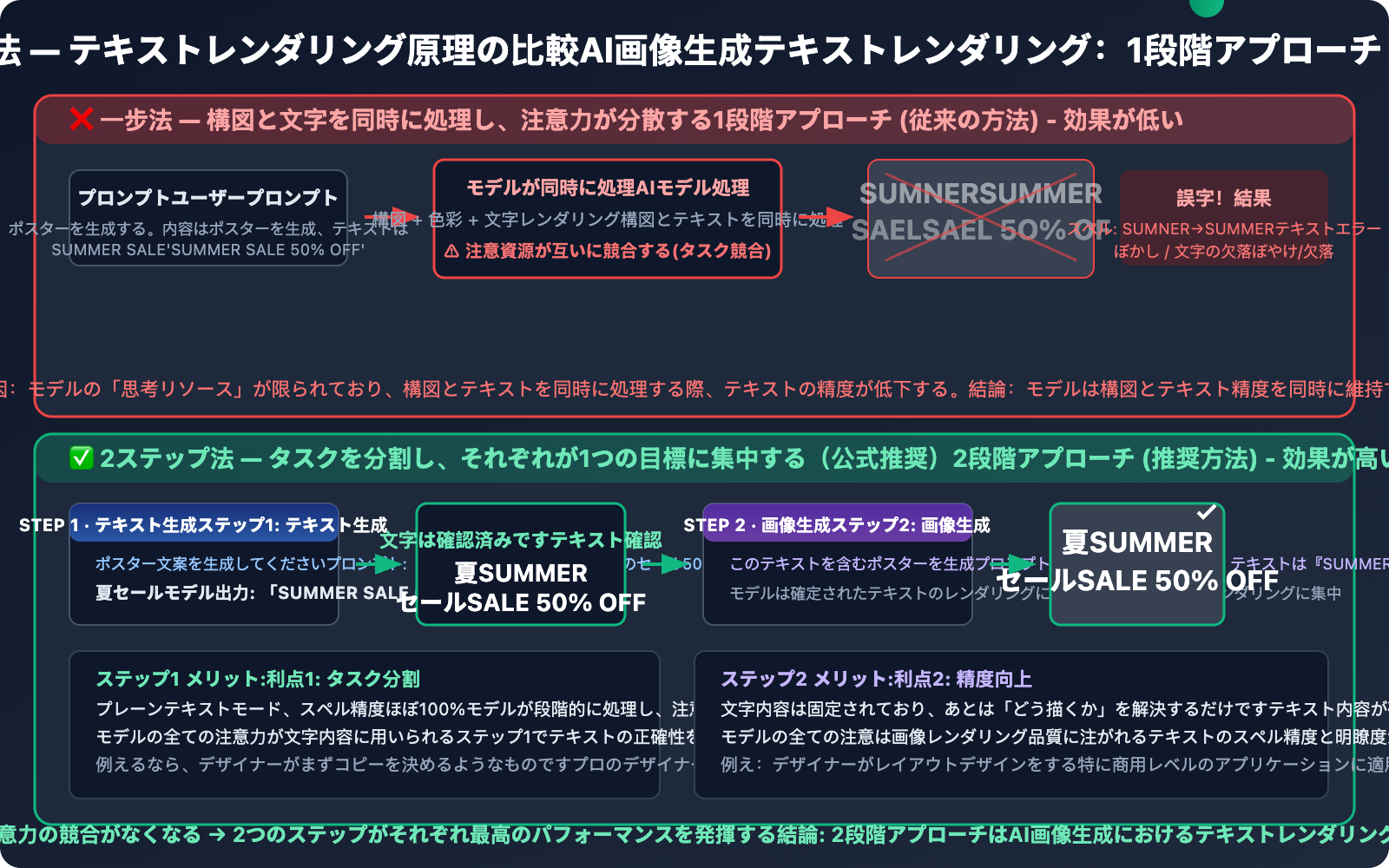
なぜ2段階アプローチが有効なのか——技術的な説明
Nano Banana は Gemini マルチモーダル大規模言語モデルに基づいて構築されています。1段階アプローチで「特定のテキストを含む画像を生成する」と直接要求すると、モデルは同時に2つのタスクを完了する必要があります。
- 画像構図の理解と計画 — シーン、色彩、レイアウト
- テキスト文字の正確なレンダリング — スペル、フォント、位置
これら2つのタスクは、モデルの注意メカニズムにおいて互いに競合します。モデルの「思考リソース」は限られており、同時に2つの高精度タスクを処理する場合、テキスト部分が犠牲になることがよくあります。
一方、2段階アプローチの核心的な考え方はタスクの分割です。
- ステップ1では、モデルがテキストコンテンツの生成と確認に集中します — このときモデルは純粋なテキストモードにあり、スペル精度は極めて高くなります。
- ステップ2では、モデルが確定したテキストを画像にレンダリングすることに集中します — テキスト内容はすでに固定されているため、モデルは「どのように描画するか」という問題だけを解決すればよいのです。
これは、画家がまずポスターに何を書くか(コピー作成段階)を決め、それからポスターを描く(デザイン段階)ようなものです。2つの段階を分けて行うことで、効率と精度が向上します。
2段階アプローチの API コード実装
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統一インターフェース
)
# ========== ステップ1: モデルにテキストコンテンツを生成/確認させる ==========
text_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": "我需要一张咖啡店的宣传海报。请帮我生成海报上需要展示的英文文案,要求简洁有力,不超过 20 个字符。只输出文案文字,不要其他内容。"
}]
)
poster_text = text_response.choices[0].message.content.strip()
print(f"第一步 - 生成文案: {poster_text}")
# 出力例: "BREW YOUR PERFECT DAY"
# ========== ステップ2: 確定したテキストで画像を生成する ==========
image_response = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=[{
"role": "user",
"content": f'Generate an image: A warm-toned coffee shop promotional poster. Display the exact text "{poster_text}" in bold serif font, centered at the top. Background shows a cozy cafe interior with warm lighting.'
}]
)
print("第二步 - 图片生成完成")
2段階アプローチの重要な詳細
| 詳細 | 説明 | 理由 |
|---|---|---|
| ステップ1では純粋なテキストモードを使用 | ステップ1で画像を生成するよう要求しない | モデルがテキストの品質に集中できるようにするため |
| テキストを二重引用符で囲む | ステップ2のプロンプトでテキストを “...” で囲む |
モデルに、これがそのままレンダリングされるべき内容であることを明確に伝えるため |
| ステップ2では英語のプロンプトを使用 | 画像生成の指示は英語を推奨 | 英語のプロンプトの方が理解精度が高いため |
| フォントスタイルを指定 | bold serif font などの記述を追加する |
モデルがレンダリングしやすいフォントを選択するのに役立つため |
| テキストの長さを制限 | ステップ1で25文字以内に制御する | 25文字を超えると精度が著しく低下するため |
主要テクニック2:25文字の黄金律
これはNano Bananaのテキストレンダリングにおいて最も重要な制約です。
Nano Bananaのテキストレンダリング精度と文字数の関係
| 文字数範囲 | 精度 | 推奨事項 |
|---|---|---|
| 1-10文字 | ~98% | 最適な範囲、ほとんどエラーなし |
| 11-20文字 | ~92% | 安全な範囲、まれに小さな問題が発生 |
| 21-25文字 | ~85% | 使用可能だが確認が必要、再試行の可能性あり |
| 26-40文字 | ~60% | 高リスク範囲、頻繁にエラーが発生 |
| 40文字以上 | <40% | 非推奨、基本的に信頼できない |
25文字を超える場合の対処法
実際に25文字を超えるテキストがある場合、3つの処理方法があります。
戦略1:複数の短い行に分割する
# ❌ 長いテキストを一度にレンダリングする
prompt = 'Generate a poster with text "ANNUAL SUMMER CLEARANCE SALE - UP TO 70% OFF ALL ITEMS"'
# ✅ 複数の短い行に分割する
prompt = '''Generate a poster with two lines of text:
Line 1 (large, bold): "SUMMER SALE 70% OFF"
Line 2 (smaller, below): "ALL ITEMS INCLUDED"'''
戦略2:複数回の対話で段階的に追加する
# 第1ラウンド: メインタイトルのみの画像を生成
# 第2ラウンド: 前回の結果にサブタイトルを追加
# 第3ラウンド: さらに下部の説明テキストを追加
戦略3:重要なテキストは画像で、長いテキストは後処理で合成する
実際に大量のテキストが必要なシナリオ(インフォグラフィックなど)では、Nano Bananaで重要な短いタイトルのみを生成し、長い段落テキストは後でデザインツールを使用して重ね合わせることをお勧めします。
主要テクニック3:二重引用符で囲む + フォントの明示的な指定
これら2つの小さなテクニックを組み合わせることで、テキストレンダリングの精度をさらに一段階向上させることができます。
二重引用符の役割
二重引用符はモデルに、引用符内の内容は一般的な説明ではなく、文字通り正確にレンダリングする必要があるテキストであることを伝えます。
# ❌ 引用符がない場合、モデルは自由に解釈する可能性がある
prompt = "Generate a sign that says Welcome to Tokyo"
# 出力例: "WELCOME TO TOKIO" (スペルミス) または全く異なるテキスト
# ✅ 二重引用符で囲み、文字通りレンダリングを強制する
prompt = 'Generate a sign that displays the exact text "Welcome to Tokyo"'
# 出力: "Welcome to Tokyo" (高確率で正確)
フォントの明示的な指定
フォントタイプを明確に指定することで、モデルがよりレンダリングしやすいフォント形状を選択するのに役立ちます。
| フォント指定 | プロンプトの書き方 | 効果 |
|---|---|---|
| 太字セリフ体 | bold serif font |
最も鮮明で、ポスターのタイトルに推奨 |
| サンセリフ体 | clean sans-serif font |
モダンな印象で、テクノロジー関連のテーマに適している |
| 手書き体 | handwritten script |
テキストの精度が低いため、慎重に使用 |
| 等幅フォント | monospace font |
コードのスクリーンショットのシナリオに適している |
| 特定のフォント | in Helvetica style |
スタイルの参考であり、完全な一致は保証されない |
💡 ヒント: 太字セリフ体(bold serif)は、テキストレンダリングの精度が最も高いフォントタイプです。筆画が太く、構造が明確なため、モデルがより正確に生成しやすくなります。手書き体や装飾的なフォントは精度が最も低いため、重要なテキストには極力使用を避けてください。
コアテクニック4:多言語テキストレンダリングの特殊処理
Nano Bananaは多言語テキストレンダリングにおいて優れた性能を発揮しますが、言語によって処理戦略が異なります。
言語ごとのテキストレンダリング性能
| 言語 | レンダリング精度 | 最適文字数 | 特記事項 |
|---|---|---|---|
| 英語 | ~94% | ≤25 | 全て大文字が最も効果的 |
| 中国語 | ~85% | ≤8文字 | 簡体字が繁体字より優れる |
| 日本語 | ~82% | ≤10 | ひらがなが漢字より優れる |
| 韓国語 | ~80% | ≤12 | 韓国語であることを明示する必要あり |
| アラビア語 | ~75% | ≤8 | 右から左への配置に注意 |
多言語テキストレンダリングのプロンプトテンプレート
# 英語 — 最も信頼性が高い
prompt = 'Generate a poster with bold text "HELLO WORLD" in white serif font'
# 中国語 — 言語指定 + 簡潔に
prompt = 'Generate a poster with Chinese text "欢迎光临" in bold Chinese calligraphy style font, centered'
# 日本語 — 言語を明確に指定
prompt = 'Generate a Japanese store sign with text "いらっしゃいませ" in clean sans-serif Japanese font'
# 混合言語 — 行ごとに処理
prompt = '''Generate a bilingual poster:
Top line in English: "GRAND OPENING"
Bottom line in Chinese: "盛大开业"
Both in bold, high contrast against dark background'''
🎯 技術的アドバイス: 多言語テキストレンダリングは、APIYI apiyi.com プラットフォームで繰り返しテストし、比較することをお勧めします。言語によって効果に大きな差があるため、理論的なパラメーターよりも実際のテストが信頼できます。このプラットフォームは、Nano Banana Pro と Nano Banana 2 の2つのモデルの迅速な切り替えをサポートしています。
コアテクニック5:プロンプト構造化テンプレート(実践必須)
これまでの全てのテクニックを組み合わせて、様々なシナリオに対応する標準化されたプロンプトテンプレートを作成します。
Nano Banana テキストレンダリング汎用プロンプトテンプレート
Generate an image:
[シーンの説明, 100文字以内].
Display the exact text "[あなたのテキスト, ≤25文字]" in [フォントスタイル] font,
positioned at [位置], [サイズの説明].
The text should be [色] with high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.
シナリオ別の実践例
シナリオ1:商業ポスター
prompt = '''Generate an image:
A vibrant summer sale promotional poster with tropical beach background.
Display the exact text "SUMMER SALE" in bold white serif font,
positioned at the center top, large and prominent.
Below it, display "50% OFF" in bold yellow sans-serif font.
The text should have high contrast against the background.
Ensure all text is perfectly legible and correctly spelled.'''
シナリオ2:ロゴデザイン
prompt = '''Generate an image:
A minimalist tech company logo on a clean white background.
Display the exact text "NEXUS" in modern bold sans-serif font,
positioned at the center, medium size.
The text should be dark navy blue (#1a1a2e).
Ensure the text is perfectly legible and correctly spelled.'''
シナリオ3:ソーシャルメディア用画像
prompt = '''Generate an image:
An inspirational quote card with soft gradient background (blue to purple).
Display the exact text "START NOW" in elegant white serif font,
positioned at the center, large and prominent.
The text should be pure white with subtle drop shadow.
Ensure the text is perfectly legible and correctly spelled.'''

コアテクニック6:多段階会話による反復修正
これまでの5つのテクニックを使っても、テキストのレンダリングが完璧ではない場合があります。Nano Bananaの大きな利点の一つは、多段階会話編集をサポートしていることです。満足できない場合は、前回の結果を基に直接修正できます。
テキスト修正の会話フロー
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
messages = []
# 第1ラウンド: 初期画像を生成
messages.append({
"role": "user",
"content": 'Generate an image: A coffee shop menu board with text "TODAY\'S SPECIAL" in chalk-style white font on dark background'
})
response_1 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
messages.append({"role": "assistant", "content": response_1.choices[0].message.content})
# 第2ラウンド: テキストを確認・修正
messages.append({
"role": "user",
"content": 'The text is slightly blurry. Please regenerate with the text "TODAY\'S SPECIAL" rendered more sharply and clearly. Make the font bolder and increase the contrast.'
})
response_2 = client.chat.completions.create(
model="gemini-3.1-flash-image-preview",
messages=messages
)
よく使う修正指示
| 問題 | 修正プロンプト |
|---|---|
| テキストのぼやけ | "Make the text sharper and bolder, increase contrast" |
| スペルミス | "Fix the spelling. The correct text should be exactly '[正确文字]'" |
| テキストの欠落 | "The text '[文字]' is missing. Add it at [位置] in [字体]" |
| フォントの不一致 | "Change the font to bold serif, keep the same text content" |
| 位置ずれ | "Move the text to the center of the image, keep everything else" |
| サイズ不適切 | "Make the text larger/smaller while keeping it legible" |
🚀 クイックスタート: 多段階会話編集は、テキスト効果に高い要件があるシナリオに非常に適しています。APIYI (apiyi.com) プラットフォームを通じてNano Bananaを呼び出すことで、1ラウンドあたりの編集は約$0.02で、3〜4回の反復で満足のいく結果が得られます。
Nano Banana テキストレンダリングの完全なワークフロー
6つのテクニックを標準化されたワークフローに統合します:
ステップ1:テキストコンテンツの計画
- レンダリングするテキストを決定します(25文字以内)
- 25文字を超える場合は複数行に分割します
- スペルが正確であることを確認します
ステップ2:2段階生成
- まずモデルにテキストコンテンツを確認/最適化させます
- 次に、確定したテキストで画像を生成します
ステップ3:プロンプトの最適化
- テキストを二重引用符で囲む
- フォントスタイルを明示的に指定する
- 構造化されたテンプレートを使用する
"Ensure text is perfectly legible"という制約を追加する
ステップ4:確認と反復
- 生成された結果のテキストが正確であるかを確認します
- 満足できない場合は、多段階会話で修正します
- 通常、1〜3回の反復で満足のいく結果が得られます
**完全なテキストレンダリングワークフローコードを見る**
#!/usr/bin/env python3
"""
Nano Banana テキストレンダリング最適化ワークフロー
2段階法 + 6つの主要テクニックの完全な実装
"""
import openai
import base64
import re
from datetime import datetime
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://api.apiyi.com/v1"
client = openai.OpenAI(api_key=API_KEY, base_url=BASE_URL)
def render_text_in_image(
scene_description: str,
desired_text: str,
font_style: str = "bold serif",
text_color: str = "white",
text_position: str = "centered",
model: str = "gemini-3.1-flash-image-preview",
max_fix_rounds: int = 2
):
"""
2段階法を使用して正確なテキストを含む画像を生成する
Args:
scene_description: シーンの説明(テキスト要件を含まない)
desired_text: レンダリングするテキスト(25文字以内を推奨)
font_style: フォントスタイル
text_color: テキストの色
text_position: テキストの位置
model: 使用するモデル
max_fix_rounds: 最大修正ラウンド数
"""
# テキストの長さを確認
if len(desired_text) > 25:
print(f"⚠️ テキスト長 {len(desired_text)} が25文字を超えています。精度が低下する可能性があります")
# ===== ステップ1: テキストコンテンツの確認 =====
print(f"📝 ステップ1: テキストコンテンツの確認 → '{desired_text}'")
text_check = client.chat.completions.create(
model=model,
messages=[{
"role": "user",
"content": f"Please verify this text is correctly spelled and formatted: '{desired_text}'. Only reply with the verified text, nothing else."
}]
)
verified_text = text_check.choices[0].message.content.strip().strip("'\"")
print(f"✅ 確認済みテキスト: '{verified_text}'")
# ===== ステップ2: テキストを含む画像を生成 =====
print(f"🎨 ステップ2: 画像を生成中...")
image_prompt = f'''Generate an image:
{scene_description}.
Display the exact text "{verified_text}" in {font_style} font,
positioned at {text_position}, with {text_color} color.
The text should have high contrast against the background.
Ensure the text is perfectly legible and correctly spelled.'''
messages = [{"role": "user", "content": image_prompt}]
response = client.chat.completions.create(
model=model,
messages=messages
)
content = response.choices[0].message.content
print(f"✅ 画像生成完了")
# 画像を保存
save_image(content, f"text_render_{datetime.now().strftime('%H%M%S')}.png")
return content
def save_image(content, filename):
"""レスポンスから画像を抽出し保存する"""
patterns = [
r'data:image/[^;]+;base64,([A-Za-z0-9+/=]+)',
r'([A-Za-z0-9+/=]{1000,})'
]
for pattern in patterns:
match = re.search(pattern, content)
if match:
data = base64.b64decode(match.group(1))
with open(filename, 'wb') as f:
f.write(data)
print(f"💾 保存先: {filename} ({len(data):,} バイト)")
return True
print("⚠️ 画像データが見つかりませんでした")
return False
# ===== 使用例 =====
if __name__ == "__main__":
# 例1: 商業ポスター
render_text_in_image(
scene_description="A vibrant promotional poster with tropical beach background, summer vibes",
desired_text="SUMMER SALE",
font_style="bold white serif",
text_position="top center, large and prominent"
)
# 例2: ロゴ
render_text_in_image(
scene_description="A minimalist tech company logo on clean white background",
desired_text="NEXUS",
font_style="modern bold sans-serif",
text_color="dark navy blue",
text_position="centered"
)
# 例3: 中国語
render_text_in_image(
scene_description="A traditional Chinese restaurant sign with red and gold decorations",
desired_text="福満楼",
font_style="bold Chinese calligraphy",
text_color="gold",
text_position="centered, large"
)
Nano Banana Pro 与 Nano Banana 2 文字渲染对比
两个模型在文字渲染上各有侧重:
| 对比维度 | Nano Banana Pro | Nano Banana 2 | 选择建议 |
|---|---|---|---|
| 文字准确率 | ~94% | ~87% | 商业级要求选 Pro |
| 最大可靠字符 | ~25 | ~20 | Pro 容错空间更大 |
| 多语言支持 | 优秀 | 优秀 | 两者持平 |
| 字体风格多样性 | 更丰富 | 够用 | Pro 更多字体选择 |
| 生成速度 | 10-20 秒 | 3-8 秒 | 快速迭代选 Banana 2 |
| API 价格 | ~$0.04/次 | ~$0.02/次 | 成本敏感选 Banana 2 |
| 迭代修正能力 | 优秀 | 优秀 | 两者持平 |
| 模型 ID | gemini-3.0-pro-image |
gemini-3.1-flash-image-preview |
可通过 APIYI apiyi.com 同时调用 |
文字渲染的模型选择建议
- 商业海报/品牌物料: 选 Nano Banana Pro — 94% 准确率 + 更多字体风格
- 社交媒体配图/快速原型: 选 Nano Banana 2 — 速度快 + 性价比高
- 需要反复迭代的场景: 选 Nano Banana 2 — 速度快意味着迭代成本低
- 多语言文字: 两者差异不大,按速度/成本需求选择
常见问题
Q1: 为什么 Google 官方建议”先生成文字再生成图片”?
这是因为多模态模型同时处理"生成文字内容"和"渲染文字到图片"两个任务时,注意力资源会互相竞争,导致文字准确率下降。两步法通过任务拆分,让模型在第一步专注于文字的正确性(纯文本模式,接近 100% 准确),第二步专注于将已确定的文字渲染进图片。这个原理类似于人类设计师先定文案再做设计。通过 APIYI apiyi.com 平台两步法调用非常方便,两次 API 调用总成本也不到 $0.05。
Q2: 25 字符的限制是硬性的吗?超过就一定出错?
不是硬性限制,而是准确率的分水岭。25 字符以内准确率在 85%-98% 之间,超过 25 字符后准确率会显著下降到 60% 以下。如果必须使用较长文字,建议拆分为多行(每行 ≤15 字符),或使用多轮对话逐步添加。
Q3: 中文文字渲染效果怎么样?比英文差很多吗?
Nano Banana 的中文文字渲染效果比大多数竞品好得多,但确实比英文略逊。实测中文准确率约 85%(英文 94%)。建议中文控制在 8 个汉字以内,使用粗体风格,并在 prompt 中明确指定 "Chinese text" 和 "Chinese calligraphy font" 或 "bold Chinese font"。通过 APIYI apiyi.com 平台可以快速测试不同 prompt 写法的中文渲染效果。
Q4: 两步法会不会增加很多成本?
两步法确实需要调用两次 API,但第一步是纯文本生成(不涉及图片),成本极低(不到 $0.001)。第二步才是图片生成($0.02-$0.04)。所以总成本只增加了不到 5%,但文字准确率提升非常显著。考虑到不用两步法时可能需要重试 3-5 次才能得到正确的文字,两步法实际上更省钱。
Q5: 有没有完全不出错的方法?
目前 AI 图像生成的文字渲染还不能保证 100% 准确。即使用了所有优化技巧,仍然建议在工作流中加入人工检查环节——尤其是商业用途的图片。对于要求绝对准确的场景(如法律文档截图、正式证书),建议用 AI 生成背景和构图,文字部分用设计工具后期叠加。
まとめ
Nano Banana のテキストレンダリング能力は、AI画像生成の分野ですでにトップレベルにあります (Pro 94%、Banana 2 87%)。しかし、この能力を安定して発揮するには、正しいテクニックを習得する必要があります。
重要度順に6つの主要テクニックをご紹介します。
- 二段階生成法 — まずテキストを生成し、次に画像を生成します。公式に推奨されており、最も効果的です。
- 25文字ルール — テキストの長さを制御し、長すぎるテキストは分割して処理します。
- 二重引用符 + フォント指定 — 強制的な逐語レンダリング + 高精度フォントの選択。
- 多言語の特殊処理 — 言語ごとに異なる戦略を使用します。
- 構造化プロンプトテンプレート — 標準化により安定性を向上させます。
- 複数回対話による修正 — 満足できない場合は、繰り返し最適化します。
これらのテクニックを習得すれば、Nano Banana のテキストレンダリングは「運任せ」から、制御可能で予測可能な能力へと変わります。APIYI apiyi.com を通じて迅速にテストを開始し、あなたのシナリオに最適なパラメータの組み合わせを見つけることをお勧めします。
参考資料
-
Google 公式 – Nano Banana 画像生成ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/image-generation - 説明: 「まずテキストを生成し、次に画像を生成する」という公式の推奨事項が含まれています。
- リンク:
-
Google Developers Blog – Nano Banana Pro のプロンプトヒント
- リンク:
blog.google/products/gemini/prompting-tips-nano-banana-pro/ - 説明: 公式のプロンプト最適化テクニックです。
- リンク:
-
Google Developers Blog – Gemini 2.5 Flash 画像生成の最適なプロンプト方法
- リンク:
developers.googleblog.com/how-to-prompt-gemini-2-5-flash-image-generation-for-the-best-results/ - 説明: Flash シリーズモデルの画像出力最適化戦略です。
- リンク:
📝 著者: APIYI Team | 技術交流およびAPI連携については apiyi.com をご覧ください。