著者注:Gemini 3.1 Pro Previewの出力Tokenが表示される文字数を大幅に超える理由の詳細解説:Thinking Tokens(思考トークン)の推論チェーンメカニズム、課金ルール、thinking_levelパラメータでコストを削減するテクニック
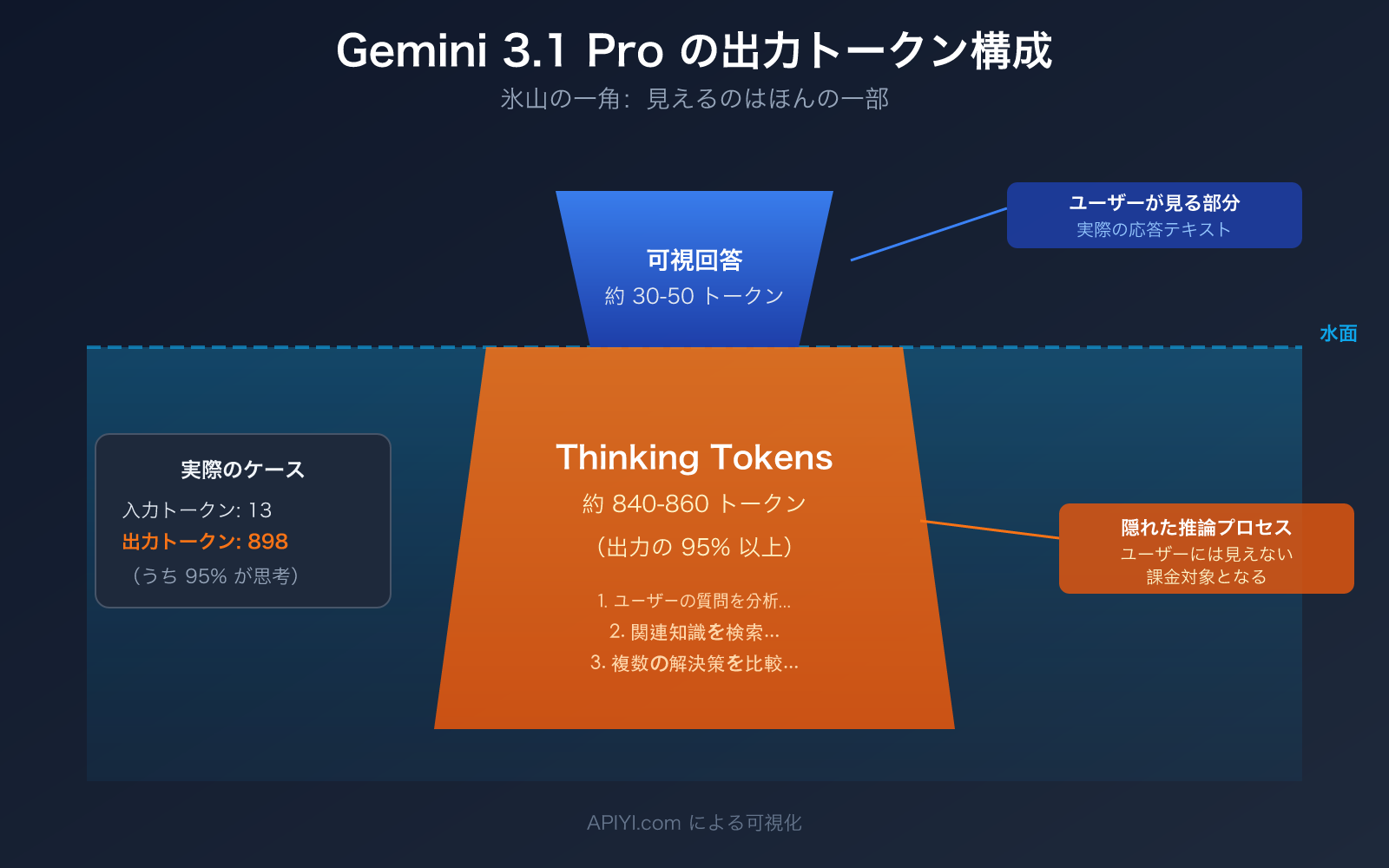
「たった一文を送っただけで、モデルの返答も十数文字なのに、なぜ出力Tokenが約900も表示されるの?お金はどこに消えたの?」——これは多くの開発者が初めてGemini 3.1 Pro Previewを使用する際に抱く実際の疑問です。スクリーンショットのデータもこの現象を明確に示しています:入力は13トークンなのに、出力は898トークンにも達しています。
答えは、Thinking Tokens(推論トークン)です。Gemini 3.1 Proは推論モデルであり、あなたに回答を返す前に、「頭の中」で長い推論プロセスを実行します。この推論内容はデフォルトでは表示されませんが、出力トークンとしてカウントされ、通常通り課金されます。
本記事の価値: この記事を読むことで、推論モデルのThinking Tokensメカニズムを完全に理解し、thinking_levelパラメータを使って推論の深さを制御し、品質を保証しながら出力トークンのコストを50〜80%削減する方法を学べます。
Gemini 3.1 Pro Thinking Tokens の核心ポイント
推論モデルと通常の対話モデルの最大の違いは、出力トークンの構成が全く異なる点にあります。以下は理解すべき核心概念です:
| 要点 | 説明 | 実際の影響 |
|---|---|---|
| 出力トークン = 思考 + 回答 | Gemini 3.1 Pro の出力トークンは、Thinking Tokens(推論チェーン)と実際の回答の2つを含みます | 表示される文字は少ないが、総トークン数は高い |
| Thinking Tokens は通常通り課金 | 推論プロセスは見えませんが、出力トークン価格で課金されます($12/百万トークン) | 簡単な質問でも、通常モデルの5〜10倍の費用がかかる可能性があります |
thinking_level は調整可能 |
LOW/MEDIUM/HIGH の3段階の推論深度制御をサポートします | LOW設定で出力トークンを80%以上削減可能 |
| 非推論モデルにはこの問題なし | GPT-4o、Claude Sonnet 4.6(Extended Thinking オフ)などのモデルは「見たままが支払い」です | 単純なタスクには非推論モデルの方がコスト効率が良い |
Gemini 3.1 Pro Thinking Tokens の実際の消費例
スクリーンショットの例に戻りましょう。ユーザーが簡単な質問を送信し、モデルは約十数文字を返答しましたが、出力トークンは891-898と表示されています。これらのトークンの構成はおおよそ以下の通りです:
- 可視回答: 約 30-50 トークン(あなたが見た十数文字)
- Thinking Tokens: 約 840-860 トークン(モデル内部の推論プロセス)
つまり、出力トークンの95%以上はあなたには見えません。それらはモデルの推論チェーンで消費されています。これは、数学の先生に「1+1は?」と尋ね、先生が口では「2です」とだけ言ったのに、頭の中では「これは基礎的な算術問題で、加算演算が必要だ…」と考えていた——そしてあなたが先生の思考プロセス全体に対して支払いをしたようなものです。
このメカニズムはバグではなく、推論モデルの設計特性です。Gemini 3.1 Proが複雑な問題で優れたパフォーマンス(MATHベンチマーク95.1%、ARC-AGI-2で77.1%)を発揮する理由は、まさに回答前に深い推論を行うからです。

Gemini 3.1 Pro 推論モデル Thinking Tokens の仕組み
推論モデルと通常モデルの本質的な違い
通常モデル(例:GPT-4o)は、あなたの質問を受け取ると、直接回答を生成します。あなたが見ている文字数が、そのまま消費される出力トークン数になります。これが「見たままが得られる」という仕組みです。
推論モデル(例:Gemini 3.1 Pro Preview)は、質問を受け取ると、まず内部で推論チェーン(Chain of Thought)を生成し、その推論結果に基づいて最終的な回答を生成します。あなたが見るのは最終回答のみですが、課金されるのは「推論チェーン + 回答」の合計トークン数です。
| モデルタイプ | 代表モデル | 出力トークンの構成 | 簡単な質問のコスト | 複雑な問題での強み |
|---|---|---|---|---|
| 通常モデル | GPT-4o、Claude Sonnet 4.6 | 100% 表示される回答 | 低い(見たままが得られる) | 推論能力は一般的 |
| 推論モデル | Gemini 3.1 Pro、GPT-5.4 Thinking | 推論チェーン + 表示される回答 | 高い(5-10倍以上) | 複雑な推論能力が高い |
| 切り替え可能モデル | Claude Sonnet 4.6(Extended Thinking) | 推論の有無をオプションで選択可能 | 柔軟に切り替え可能 | 必要に応じて推論を有効化 |
Gemini 3.1 Pro Thinking Tokens の 3 つの重要な詳細
詳細1: Thinking Tokens の課金方法。 Google の公式ドキュメントによると、Thinking Tokens は出力トークンの標準価格で課金されます。Gemini 3.1 Pro の出力トークン価格は $12/百万トークンです。モデルが4000トークンを推論に使い、500トークンを回答に使った場合、あなたは4500出力トークン分の料金を支払うことになります——500トークン分ではありません。
詳細2: APIレスポンスでの区別方法。 Gemini API のレスポンスでは、usage_metadata フィールドに thoughts_token_count(推論トークン数)と candidates_token_count(総出力トークン数)が別々に返されます。ただし注意点として、Gemini API の candidatesTokenCount は Thinking Tokens を含みますが、Vertex AI の candidatesTokenCount は含みません。
詳細3: 推論チェーンの内容はデフォルトでは見えない。 includeThoughts: true を設定することで推論プロセスの要約(完全な推論チェーンではありません)を取得できます。また、Cherry Studio などのツールで推論チェーン表示機能を有効にすれば、モデルの思考過程を確認できます。
🎯 コスト削減の提案: 単純な会話や翻訳タスクなど、深い推論を必要としない場合は、通常モデル(例:GPT-4o-mini や Claude Sonnet 4.6)への切り替えをお勧めします。APIYI apiyi.com では、
modelパラメータを1つ変更するだけでモデルを切り替えられ、他のコードを変更する必要はありません。
Gemini 3.1 Pro Thinking Tokens の最適化:3 つのコスト削減戦略
戦略1: thinking_level パラメータで推論の深さを制御する
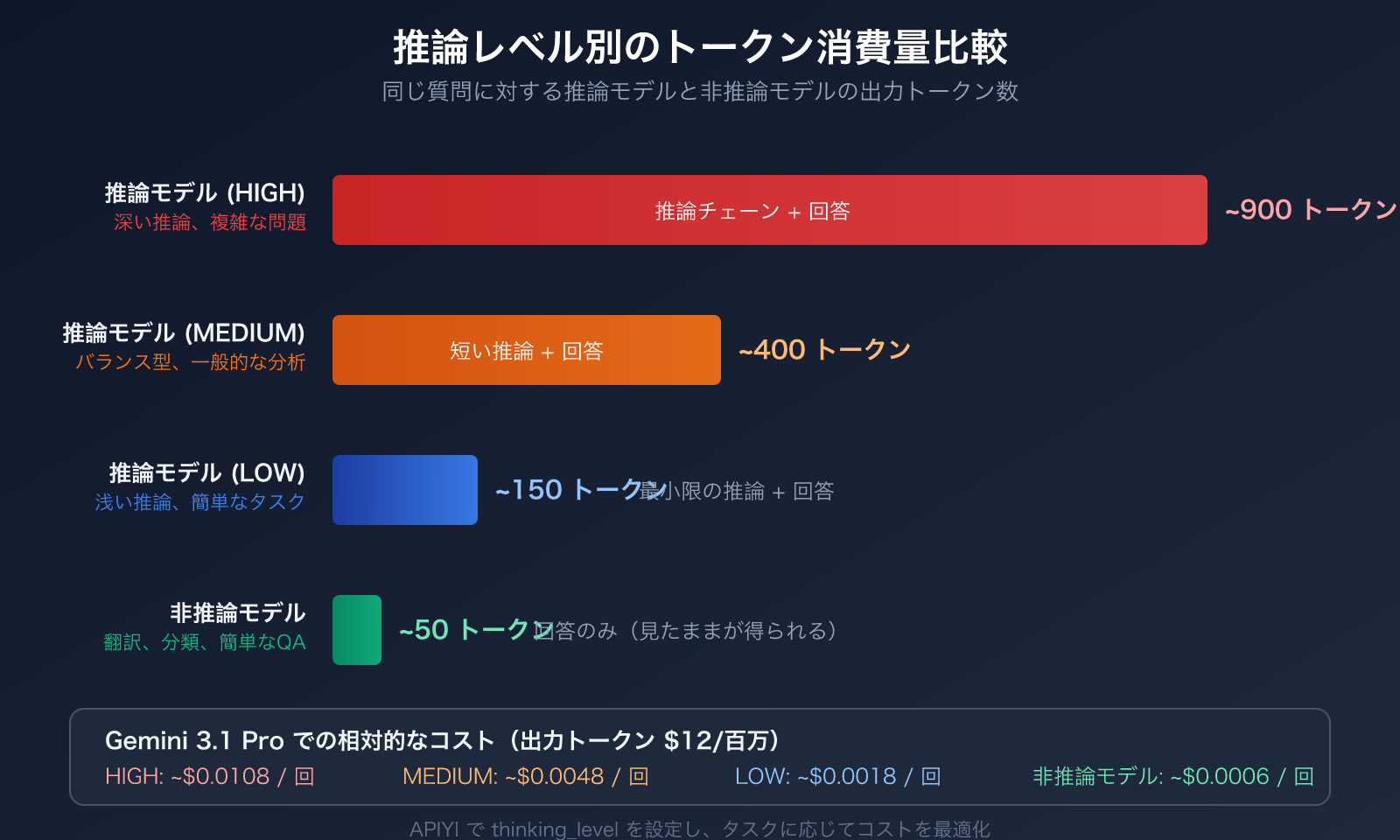
Gemini 3.1 Pro は thinking_level パラメータを提供しており、LOW、MEDIUM、HIGH の3段階をサポートしています。各段階でのトークン消費量は大きく異なります:
| thinking_level | 推論の深さ | トークン消費量 | 適用シーン | HIGH との比較 |
|---|---|---|---|---|
| LOW | 浅い推論 | 最低 | 翻訳、分類、簡単な質疑応答 | 約 80%+ 削減 |
| MEDIUM | バランス型推論 | 中程度 | 日常的なプログラミング、ドキュメント生成、一般的な分析 | 約 50% 削減 |
| HIGH | 深い推論 | 最高 | 数学的導出、科学的問題、複雑な論理 | 基準線 |
以下は thinking_level を設定するコード例です:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 簡単なタスクには LOW を使用し、Thinking Tokens を大幅に削減
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"総出力トークン: {response.usage.completion_tokens}")
完全なインテリジェントルーティングコードを見る(問題の複雑さに基づいて推論の深さを自動選択)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Gemini 3.1 Pro をインテリジェントに呼び出し、タスクの複雑さに基づいて推論の深さを自動選択
Args:
prompt: ユーザー入力
complexity: "low" / "medium" / "high" / "auto"
api_key: APIキー
Returns:
回答とトークン使用統計を含む辞書
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# 複雑さを自動判断
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# 使用例
# 簡単なタスク → 自動で LOW を選択
result = smart_gemini_call("翻译:今天天气真好")
print(f"推論の深さ: {result['thinking_level']}, 出力トークン: {result['output_tokens']}")
# 複雑なタスク → 自動で HIGH を選択
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推論の深さ: {result['thinking_level']}, 出力トークン: {result['output_tokens']}")
提案: APIYI apiyi.com を通じて Gemini 3.1 Pro を呼び出す際は、
thinking_levelパラメータの指定をサポートしています。日常使用では MEDIUM に設定し、数学/科学などの複雑な推論シーンのみ HIGH を使用することをお勧めします。
戦略2: 簡単なタスクには非推論モデルを直接使用する
すべてのシーンで推論モデルが必要なわけではありません。翻訳、フォーマット変換、簡単な質疑応答などのタスクでは、非推論モデルを使用することで5〜10倍のトークンコストを削減できます:
- GPT-4o-mini: コストパフォーマンスが非常に高く、日常会話に最適
- Claude Sonnet 4.6(Extended Thinking をオフ): 出力品質が高く、トークンは見たままが得られる
- Gemini 3.1 Flash: Google の軽量モデル、高速でコストが低い
戦略3: max_tokens を設定して出力上限を制限する
API呼び出しに max_tokens パラメータを追加することで、推論モデルが「過度に思考する」ことを防げます。ただし注意点として、max_tokens は総出力(推論 + 回答)を制限するため、低く設定しすぎると回答が途中で切れる可能性があります。予想される回答の長さの2〜3倍に設定することをお勧めします。
🎯 総合的な提案: APIYI apiyi.com プラットフォームでは、統一されたインターフェースで推論モデルと非推論モデルの両方に同時に接続でき、タスクの種類に応じて動的に切り替えることができます。1つのAPIキーでGemini、Claude、GPTの全シリーズモデルを呼び出せます。
よくある質問
Q1: Gemini 3.1 Pro の Thinking Tokens は、なぜデフォルトで推論過程を表示しないのですか?
これは Google の製品設計上の選択です。完全な推論チェーンには数千トークンの中間導出が含まれる可能性があり、直接表示するとユーザー体験に大きな悪影響を与えます。includeThoughts: true を設定して推論の要約を取得するか、Cherry Studio などのクライアントで推論チェーン表示機能を有効にすることで、思考過程を確認できます。
Q2: API レスポンスで Thinking Tokens が具体的にどれだけ消費されたかを確認するには?
Gemini API が返す usage_metadata 内の thoughts_token_count フィールドを確認してください。APIYI apiyi.com 経由で呼び出す場合は、プラットフォームの使用量統計ページで、各呼び出しの詳細なトークン内訳(入力/出力/推論)を確認でき、コストの監視と最適化に便利です。
Q3: Gemini 3.1 Pro 以外に、同様の Thinking Tokens メカニズムを持つモデルはありますか?
主要な推論モデルには類似のメカニズムがあります:
- GPT-5.4 Thinking: OpenAI の推論モデル。推論トークンも出力トークンとして課金されます。
- Claude Sonnet 4.6 Extended Thinking: Anthropic の推論モード。選択的に有効にできます。
- DeepSeek-R1: オープンソースの推論モデル。推論チェーンが完全に可視化されます。
重要な違いは、一部のモデル(Claude など)では推論モードを柔軟にオン/オフできるのに対し、一部のモデル(Gemini 3.1 Pro など)ではデフォルトで推論が有効になっている点です。APIYI apiyi.com を使用すると、統一されたインターフェースでこれらのモデルの実際のトークン消費量をテスト・比較できます。
まとめ
Gemini 3.1 Pro Thinking Tokens の核心ポイント:
- 出力トークンには隠れた推論チェーンが含まれる: 目に見えるのは回答部分のみで、出力トークン消費の 95% 以上は不可視の Thinking Tokens に費やされています。
- Thinking Tokens は通常通り課金される: 出力トークンの標準価格で課金されます。単純な問題でも、非推論モデルに比べて 5〜10 倍のコストになる可能性があります。
thinking_levelパラメータで節約: LOW 設定で 80% 以上のトークンを節約可能。日常使用には MEDIUM、複雑なタスクのみに HIGH を使用するのがおすすめです。- 単純なタスクには非推論モデルを選択: 翻訳、分類、簡単な質疑応答などのシナリオでは、GPT-4o-mini や Claude Sonnet 4.6 を直接使用する方がコスト効率が良いです。
Thinking Tokens の仕組みを理解すれば、推論予算を適切に配分できます。複数モデルの呼び出しを APIYI apiyi.com の統一インターフェースで管理し、タスクの複雑さに応じて推論モデルと非推論モデルを動的に選択することで、最適な品質とコストのバランスを実現することをおすすめします。
📚 参考文献
-
Google Cloud ドキュメント – Thinking 推論モード: Gemini 推論モデルの公式技術ドキュメント
- リンク:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - 説明: Thinking Tokens の課金ルールと thinking_level パラメータ設定の信頼できる情報源
- リンク:
-
Google AI 開発者ドキュメント – Token カウント: 公式 Token カウントと usage_metadata フィールドの説明
- リンク:
ai.google.dev/gemini-api/docs/tokens - 説明: API レスポンスで thoughts_token_count と candidates_token_count を区別する方法
- リンク:
-
Google DeepMind – Gemini 3.1 Pro モデルカード: モデル能力と推論ベンチマークの詳細
- リンク:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 説明: MATH 95.1%、ARC-AGI-2 77.1% などのパフォーマンスデータの公式情報源
- リンク:
-
OpenRouter – 推論 Token ベストプラクティス: 推論モデルの Token 管理に関するコミュニティのベストプラクティス
- リンク:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - 説明: モデル間での推論 Token 課金ルール比較と最適化のアドバイス
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄で推論モデルの Token 最適化の経験について議論を歓迎します。より多くのモデル呼び出しチュートリアルは、APIYI docs.apiyi.com ドキュメントセンターをご覧ください。