如果你最近做 AI 應用最痛苦的事情是什麼? 大概率是這個場景: prompt 改了第 17 版, 跑了幾個測試用例感覺變好了, 上線後被用戶用一個你完全沒想到的邊緣 case 一擊即潰。這就是 OpenAI 在 2025 年 10 月發佈的 Cookbook 文章 "Building resilient prompts using an evaluation flywheel" 想要徹底解決的問題。
OpenAI 工程師 Neel Kapse 與社區著名 ML 教育者 Hamel Husain 在這篇文章裏提出了 Evaluation Flywheel (評估飛輪) 這個核心概念, 用一套來自社會學定性研究的成熟方法論, 把 AI 應用開發從"prompt-and-pray (改完然後祈禱)"提升到"工程紀律"。本文將用最通俗的視角解讀這個 OpenAI 評估飛輪 框架, 幫你判斷怎麼把它落地到自己的 AI 項目。
🎯 快速導覽: cookbook 用一個真實的"公寓租賃助手 AI"作爲示範案例, 完整展示了從失敗分析到自動 grader 再到 CI 集成的全套工作流。文章中提到的 Evals API 和 Prompt Optimizer 工具屬於 OpenAI 平臺高級能力, 通過 API易 apiyi.com 這類 OpenAI 官轉網關可以直接調用, 國內開發者照搬 cookbook 流程即可跑通。
公寓租賃助手案例: 一個被邊緣場景打爆的真實 AI 應用
cookbook 裏選取的案例非常貼近生活: 一個幫租客回答問題的 AI 助手, 包括公寓尺寸、看房預約、設施介紹等高頻諮詢。乍聽是個普通的客服機器人, 真正放到生產環境後翻車的姿勢卻千奇百怪。
文章裏枚舉的失敗案例非常有代表性, 每一個都讓人感同身受:
| 失敗類型 | 具體表現 | 後果 |
|---|---|---|
| 調度錯誤 | 推薦了不存在的看房時間段 | 租客白跑一趟, 投訴率飆升 |
| 狀態紊亂 | 改約時沒取消原預約 | 同一時段雙重預約, 銷售線索混亂 |
| 排版崩壞 | 設施列表全部擠成一坨文字 | 用戶體驗糟糕, 信息無法消費 |
| 鏈接失效 | 戶型圖鏈接 404 | 用戶流失到競品 |
| 數據漂移 | 回答的營業時間與真實數據不符 | 誤導用戶, 法律風險 |
如果你做過任何 AI 應用, 就知道這些都不是寫 prompt 時刻意忽略的, 而是根本沒意識到會發生。Fractional 團隊在配套的 Receipt Inspection 案例裏把這種現象總結得很到位: 單跑幾個 happy path 永遠抓不出生產環境的 long tail bug, 必須建立系統性的"失敗收集 → 模式歸納 → 自動度量"閉環。
這個閉環, 就是評估飛輪要解決的核心問題。
OpenAI 評估飛輪的核心定義: 替代 prompt-and-pray 的工程紀律
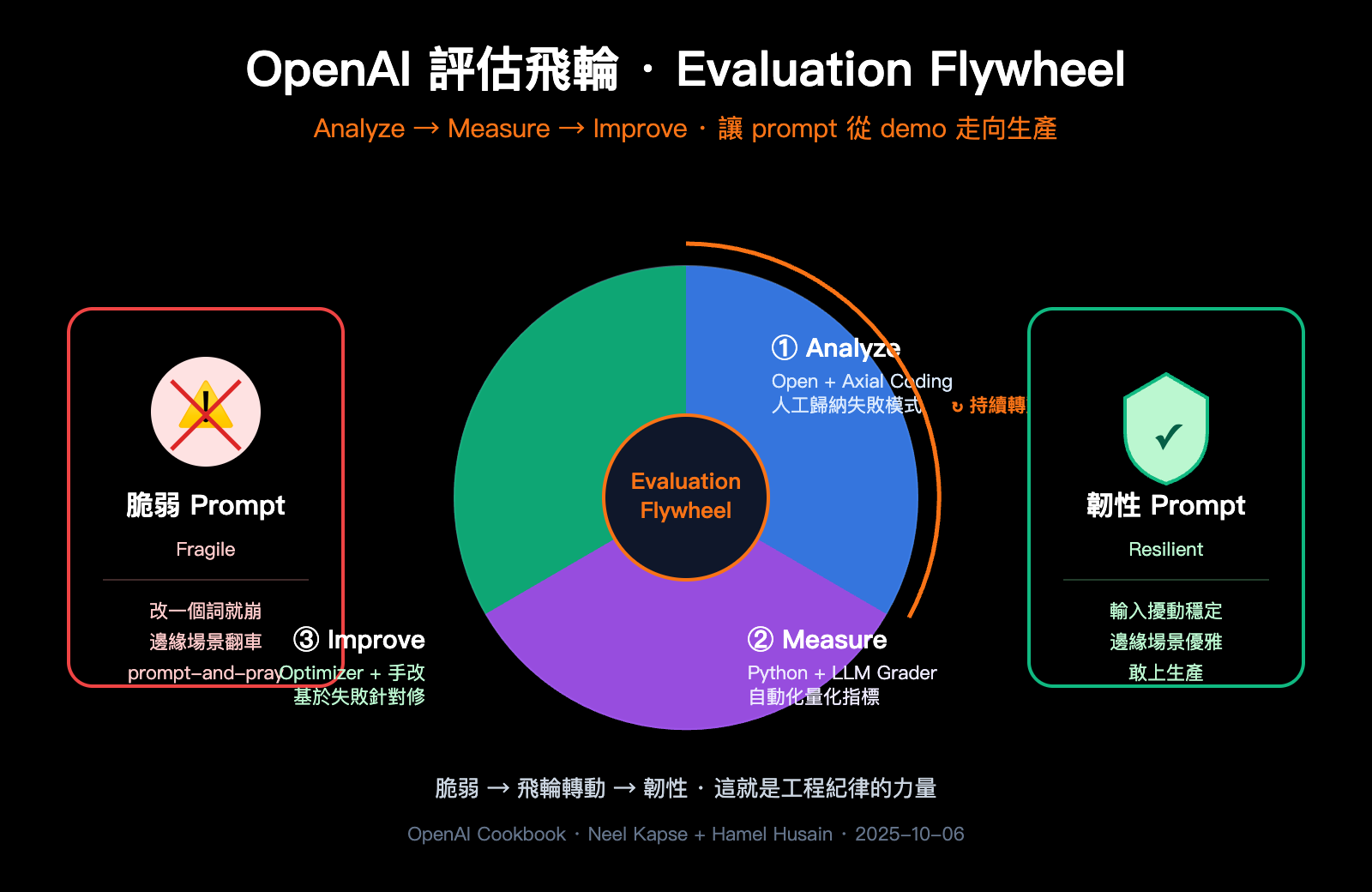
cookbook 給評估飛輪下的定義很簡潔: 一個持續迭代的過程, 用結構化的工程紀律替代猜測。它由三個階段組成, 像一個真正的輪子一樣持續轉動, 每轉一圈系統就比上一圈更韌性一點。
三個階段的職責非常清晰, 各自解決一個特定問題:
| 階段 | 核心問題 | 主要活動 | 輸出物 |
|---|---|---|---|
| Analyze (分析) | "爲什麼會失敗?" | 人工讀失敗樣本, 歸納失敗模式 | 失敗分類清單 + 佔比 |
| Measure (度量) | "失敗有多嚴重?" | 創建 grader, 跑數據集 | 量化指標 + baseline |
| Improve (改進) | "如何修?" | 改 prompt, 重新跑評估 | 新版本 + 指標對比 |
很多團隊跳過 Analyze 階段直接搞自動評估, 這是評估飛輪失敗的最常見原因。沒有定性分析的自動度量都是空中樓閣, 因爲你根本不知道自己在度量什麼。這是這篇 cookbook 最核心的洞察, 也是它區別於普通 evals 教程的地方。
💡 類比理解: 評估飛輪像產品經理熟悉的 PDCA 循環, 但應用在 prompt 工程上有了具體的方法論支撐。Analyze 對應"找問題", Measure 對應"量問題", Improve 對應"修問題", 三步缺一不可。我們建議在 apiyi.com 調用 OpenAI Evals API 跑評估時, 先把 Analyze 階段做紮實再啓動度量。
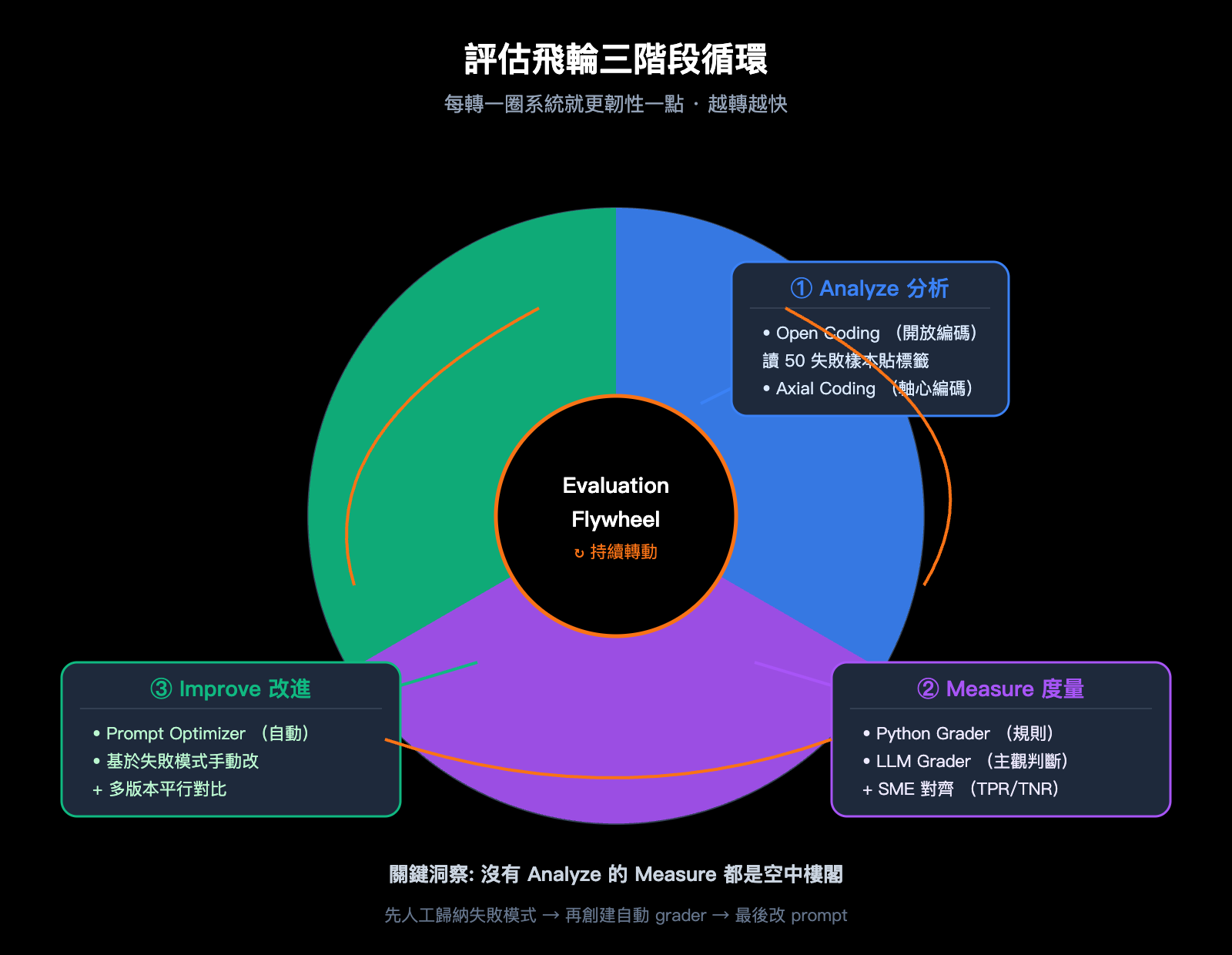
OpenAI 評估飛輪階段一: Analyze (分析) 的兩步標註法
Analyze 階段是評估飛輪最容易被忽視、卻最關鍵的環節。cookbook 在這裏搬出了一套非常專業的方法: Open Coding (開放編碼) → Axial Coding (軸心編碼), 這套方法源自社會學定性研究, 經過幾十年驗證, 是分析非結構化文本數據最成熟的範式之一。
第一步 Open Coding (開放編碼) 的工作很樸素: 讀 50 個失敗樣本, 不要預設任何分類, 直接給每個失敗貼一個描述性標籤。例如:
- "推薦了不存在的看房時間"
- "設施列表是一坨文字"
- "改約沒取消原約"
- "回答了不是這套公寓的尺寸"
- "戶型圖鏈接打不開"
注意這一步故意不追求分類的整齊, 你只需要誠實地描述你看到了什麼。Open Coding 像寫讀書筆記, 思路放飛、不必拘謹, 因爲過早歸類會讓你失去對邊緣模式的感知力。
第二步 Axial Coding (軸心編碼) 纔開始結構化, 你把第一步那些零散的標籤合併成有意義的高層分類。cookbook 給出的示例分類是:
- 看房調度類問題 (合併: 錯誤時間、未取消、雙重預約) → 佔失敗的 35%
- 格式錯誤類 (合併: 排版崩、鏈接失效) → 佔失敗的 10%
- 數據準確性類 (合併: 營業時間錯、尺寸錯) → 佔失敗的若干 %
Axial Coding 像整理章節目錄, 讓你能看清失敗的"地形圖"。35% 這個數字立刻告訴你應該優先修哪個類別, 因爲它的 ROI 最高。
| 標註方法 | 目標 | 心態 | 輸出 |
|---|---|---|---|
| Open Coding | 發現 (Discovery) | 放飛、不預設分類 | 50+ 個描述性標籤 |
| Axial Coding | 結構化 (Structure) | 歸納、構建分類 | 5-8 個高層失敗類別 |
🔧 實操建議: 國內開發者做 Analyze 階段時, 可以把生產日誌通過 OpenAI 官轉 API (例如 apiyi.com) 直接接到 Evals API 平臺的 Dataset 標註界面, 不用自己寫後臺。Open Coding 用 Feedback 類型標註列, Axial Coding 用 Label 類型標註列, 流程與 cookbook 完全一致。
OpenAI 評估飛輪階段二: Measure (度量) 的兩類 grader 選型
Analyze 階段你已經知道"失敗長什麼樣", Measure 階段要把這些失敗轉化爲自動檢測代碼。cookbook 在這裏給出了兩類 grader 的選型指南, 這是工程師最容易混淆的地方。
| Grader 類型 | 適用場景 | 優勢 | 劣勢 |
|---|---|---|---|
| Python Grader | 確定性規則 (字符串、正則、API 校驗) | 結果穩定、零幻覺、零額外成本 | 寫不出來主觀維度 |
| LLM Grader | 主觀判斷 (格式美觀、語義對齊、推理質量) | 靈活、能評估難以編碼的維度 | 需要 SME 對齊校驗、有 token 成本 |
舉公寓助手的例子, 兩類 grader 各有用武之地:
- "推薦時間是否在真實可用時段內?" → Python Grader (查數據庫或 API)
- "設施列表是否排版美觀?" → LLM Grader (打 0-10 分)
- "戶型圖鏈接是否可訪問?" → Python Grader (HEAD 請求)
- "回答語氣是否符合品牌調性?" → LLM Grader (基於 rubric 打分)
cookbook 強調一個非常重要的工程實踐: LLM Grader 必須做 SME (Subject Matter Expert, 領域專家) 對齊校驗, 不能盲信 GPT-4o 的評分。具體方法是用 train/validation/test 數據拆分, 同時檢查兩個指標:
- High TPR (True Positive Rate, 真陽率): 抓得到真正的失敗
- High TNR (True Negative Rate, 真陰率): 不誤傷本來正確的樣本
只看準確率會被高 baseline 矇蔽, 必須雙指標對齊。這一點是把 LLM-as-Judge 從"看起來 work"提升到"真的 work"的分水嶺。
📊 校驗流程: SME 標註一份 100 條樣本作爲 ground truth → LLM Grader 對同一份樣本打分 → 計算 TPR / TNR → 調整 grader prompt 直到雙指標都達標。這套流程在 apiyi.com 的 Evals 平臺可以原生支持, 因爲 Evals API 完全兼容 OpenAI 官方協議。
OpenAI 評估飛輪階段三: Improve (改進) 的雙軌實驗
第三階段你終於可以動手改 prompt 了。cookbook 給出了兩條並行的改進路徑, 這兩條路徑不是二選一, 而是配合使用。
路徑一: Prompt Optimizer 自動優化
OpenAI 平臺內置了 Prompt Optimizer 工具, 你給它一個失敗樣本集和原始 prompt, 它會自動嘗試一系列改寫策略 (加 few-shot、加 chain-of-thought、調整指令順序等), 並在你的 grader 上評估改進效果。這條路徑的好處是省事, 適合作爲初步探索手段。
路徑二: 基於失敗模式手動改 prompt
針對 Analyze 階段總結出的具體失敗模式, 工程師手動針對性改 prompt。例如:
- 看房調度錯誤 → 在 prompt 里加入"檢查可用時間表"的強制步驟
- 排版崩壞 → 用 XML 標籤明確指定輸出格式
- 改約未取消 → 加入"先取消再預約"的狀態機說明
手動路徑的優勢是精準, 你知道每一處改動針對哪個失敗模式, debug 時心裏有數。
兩條路徑都跑完後, 你會有 N 個 prompt 候選版本。這時候 Improve 階段最關鍵的一步來了: 用同一個 grader 集合在同一個數據集上跑所有版本, 選指標最優的那個。這一步不能跳, 因爲人類對自己改的 prompt 有強烈的"自我感覺良好"偏見, 唯一能糾偏的就是數字。
跑完所有版本後, 飛輪轉完一圈。你會發現新的失敗模式 (因爲系統變好了, 暴露出更深層次的邊緣 case), 然後回到 Analyze 階段開始下一圈。這就是"飛輪"這個詞的精髓——它不會停, 越轉越快, 越轉越韌性。
韌性提示詞 (Resilient Prompt) 與脆弱提示詞的本質區別
文章標題裏的 resilient prompt (韌性提示詞) 是一個非常重要的概念, cookbook 給的定義是: 在所有可能的輸入上都能給出高質量響應的 prompt。聽起來簡單, 實際是一個非常高的工程標準。

韌性和脆弱的差異主要體現在五個維度上:
| 對比維度 | 脆弱 Prompt | 韌性 Prompt |
|---|---|---|
| 輸入魯棒性 | 改一個詞就崩 | 同義改寫依然穩定 |
| 邊緣場景 | 詭異輸出甚至幻覺 | 優雅降級或轉人工 |
| 可觀測性 | 黑盒, 出錯只能猜 | 有完整 grader 可定位 |
| 生產准入 | demo 表現≠生產表現 | 通過完整評估閉環 |
| 可演進性 | 改 A 改壞 B | 自動迴歸保護 |
工程師的直覺裏 prompt 看起來"差不多就行", 但放到生產環境就會出現 0.1% 概率的問題——0.1% 看似很小, 在百萬級調用下就是 1000 次事故。韌性提示詞的工程價值不是把 80% 提升到 90%, 而是把 99% 提升到 99.9%。
🚀 接入提示: 想把 prompt 推到 99.9% 韌性, 必須把評估閉環自動化, 這就需要穩定調用 OpenAI Evals API 和 Prompt Optimizer 工具。我們建議通過 apiyi.com 這類 OpenAI 官轉 API 平臺調用, 接口與官方完全同步, 國內 IDC 節點也保證了長時間評估任務不掉線。
OpenAI 評估飛輪的 CI/CD 集成與生產監控
cookbook 在結尾強調的最後一步是: 把評估飛輪變成日常工程紀律。具體落地分兩塊:
第一塊: CI/CD 集成
把 grader 套件接到 CI 流水線, 每次 prompt 變更都自動跑評估。如果指標退化超過閾值, PR 自動被阻塞合併。這一步把"評估"從研究行爲變成日常開發行爲, 是 prompt 真正走向工程化的標誌。
| CI 閾值類型 | 推薦設置 | 說明 |
|---|---|---|
| 整體準確率 | 退化 ≤ 1% | 防止整體迴歸 |
| 關鍵 grader | 退化 ≤ 0.5% | 高優先級失敗模式嚴控 |
| 新模式檢出 | 警告而非阻塞 | 鼓勵發現新問題 |
| 延遲 P95 | 增長 ≤ 10% | 控制成本和體驗 |
第二塊: 生產監控
CI 之外還要在生產環境持續採樣, 發現 CI 集合裏沒有的"野生失敗模式", 這些新模式會被加回評估集, 推動飛輪轉下一圈。
具體做法是把生產日誌按一定比例 (比如 1%) 採樣, 跑同一套 grader, 發現指標異常時拉出來人工分析。新發現的失敗模式經過 Open Coding → Axial Coding 處理後加入測試集, 飛輪再轉。
這套循環讓你的 prompt 系統永遠在變得更韌性, 而不是部署後就停滯。這是 cookbook 留給所有 AI 工程師的核心工程紀律。
OpenAI 評估飛輪給國內開發者的 5 個實操啓示
通讀 cookbook 後, 我提煉出 5 個對中文開發者有直接指導意義的啓示:
啓示一: 從 Analyze 開始, 不要從 Measure 開始
很多團隊上來就配 grader、刷指標, 跳過了人工分析。這導致 grader 度量的根本不是真正的失敗模式, 數字漂亮但用戶依然投訴。沒有 50 條人工 Open Coding, 別啓動自動評估。
啓示二: Open Coding 階段不要給 GPT 看
Open Coding 必須人類做, 因爲 GPT 在歸納模式時會用既有訓練數據的偏見污染你的標籤。讓 LLM 介入的最早時機是 Axial Coding 之後做 grader 實現, Analyze 的"發現"環節是人類獨佔的。
啓示三: Python Grader 優先於 LLM Grader
只要能用確定性規則覆蓋, 就別用 LLM Grader。原因有三: 穩定、便宜、不需要 SME 對齊。LLM Grader 留給真正主觀、規則覆蓋不了的維度。
啓示四: 把指標綁定到業務影響
35% 調度問題、10% 格式問題——這些百分比要換算成"用戶流失率"或"投訴率"纔有決策價值。指標本身沒有意義, 它對應的業務後果纔有。
啓示五: 把飛輪做成自動化, 而不是一次性項目
轉一圈飛輪的 ROI 不一定特別高, 但長期複利非常可觀。把 grader 寫成 CI 任務、把生產採樣寫成定時任務、把新模式檢出寫成自動報警, 讓飛輪 24 小時自己轉。
OpenAI 評估飛輪國內復現的 Python 代碼骨架
雖然 cookbook 主要演示的是 OpenAI Platform 的 UI 工作流, 但 Evals API 的程序化調用同樣支持。下面這段 Python 代碼骨架展示瞭如何調用 Evals API 創建 grader 並跑評估, 適合喜歡代碼化工作流的國內開發者:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # 切換到 OpenAI 官轉網關
api_key="你的 API易 Key"
)
# 1. 創建評估任務 (定義 grader 集合)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Python Grader 示例
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # LLM Grader 示例
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "Score 0-10 on output formatting clarity"
}
]
)
# 2. 跑評估 run
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. 拉取評估結果
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"通過率: {result.report_url}")
這段代碼有三個關鍵點。第一個是 base_url 切換, 這一行決定了你能否在國內穩定跑長時間評估任務。第二個是 testing_criteria 數組, 你可以把所有 grader 配置成數組一次跑完。第三個是 Evals API 是異步的, 大數據集上跑評估可能需要幾分鐘到幾十分鐘, 程序裏要做好等待和重試。
OpenAI 評估飛輪 FAQ
Q1: 評估飛輪和 LangSmith / Weights&Biases 那種評估平臺有區別嗎?
定位不同。LangSmith 主要解決"評估的工具化", 評估飛輪解決"評估的方法論"。前者告訴你怎麼實現, 後者告訴你怎麼思考。兩者可以疊加使用, 用工具承載方法論。
Q2: 50 個失敗樣本夠嗎, 是不是太少?
Open Coding 階段 50 個就夠了, 因爲目標是發現模式而非窮盡統計。Measure 階段需要的樣本數取決於失敗率: 如果失敗率 5%, 要 1000 條樣本才能給出穩定的指標置信區間; 失敗率 30% 則 200 條就夠。
Q3: Prompt Optimizer 自動優化能不能完全替代手動改?
不能。自動工具擅長在已知 grader 上做局部優化, 但不擅長理解業務約束 (比如"客戶要求每條響應不超過 80 字"這種隱式規則)。手動改 + 自動優化結合是最佳實踐。
Q4: 國內調用 Evals API 穩定嗎?
直連 OpenAI 在國內調用長時間任務 (評估通常要跑幾分鐘到幾小時) 經常會遇到連接重置。我們建議通過 apiyi.com 這類 OpenAI 官轉網關調用, 國內 IDC 節點對長連接做了專門優化, 評估任務中斷率顯著降低。
Q5: 評估飛輪適合什麼規模的團隊?
從 1 人項目到 100 人團隊都適用, 區別只是飛輪轉動的頻率。1 人項目可能兩週轉一圈, 大團隊可以做到天級別甚至小時級別的迭代。關鍵是建立紀律, 不是規模。
Q6: Hamel Husain 是誰, 爲什麼這篇 cookbook 這麼受關注?
Hamel 是機器學習社區非常有影響力的教育者, 長期推動 LLM 應用的工程化最佳實踐。這篇 cookbook 是 OpenAI 官方第一次系統性引入定性研究方法論 (Open Coding 等) 到 prompt 工程, 所以業界討論非常多。
總結
OpenAI 評估飛輪 這套方法論的真正價值, 是給中文 AI 工程師社區補上了"prompt 工程怎麼做纔算專業"這道題的標準答案。它不是一個具體的工具, 而是一種工程紀律, 讓 prompt 開發從"憑感覺的手藝活"變成"有跡可循的工程實踐"。
把 Analyze → Measure → Improve 這三個階段刻進開發流程, 你的 AI 應用就從"demo 看着挺像那麼回事"升級成了"敢放上生產、敢承諾 SLA"的產物。這個升級背後, 是失敗被系統性收集、模式被結構化歸納、改進被自動度量驗證的完整閉環。
如果你正在做任何 prompt-driven 的 AI 應用, 強烈建議把這套飛輪搭起來。我們建議通過 apiyi.com 這類 OpenAI 官轉 API 平臺直接調用 Evals API 和 Prompt Optimizer, 一行 base_url 切換就能跑通整套 cookbook 流程, 不用費心解決國內網絡穩定性的問題。
把"飛輪"刻進肌肉記憶, 你的 prompt 就從今天開始, 走在變韌性的路上。
📌 作者: APIYI Team — 長期跟蹤 OpenAI / Anthropic / Google 多模態 API 的工程實踐案例, 更多 cookbook 實戰解讀和 Evals API 接入指南見 apiyi.com 文檔中心。